【计算机视觉】人脸识别
一、简介
人脸识别是将图像或者视频帧中的人脸与数据库中的人脸进行对比,判断输入人脸是否与数据库中的某一张人脸匹配,即判断输入人脸是谁或者判断输入人脸是否是数据库中的某个人。
人脸识别属于1:N的比对,输入人脸身份是1,数据库人脸身份数量为N,一般应用在办公室门禁,疑犯追踪;人脸验证属于1:1的比对,输入人脸身份为1,数据库中为同一人的数据,在安全领域应用比较多。
一个完整的人脸识别流程主要包括人脸检测、人脸对齐、特征提取、人脸对比几个部分。
二、人脸检测
人脸检测是寻找并定位人脸在输入图像中的位置。
传统人脸检测算法
Viola-Jones人脸检测活Haar特征级联分类器
import cv2# 加载预训练模型
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')# 读取输入图像
image_path = "path_to_image.jpg" # 替换为你的图片路径
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转为灰度图# 检测人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))# 绘制人脸矩形框
for (x, y, w, h) in faces:cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)roi_gray = gray[y:y+h, x:x+w]roi_color = image[y:y+h, x:x+w]# 在每张人脸区域内检测眼睛eyes = eye_cascade.detectMultiScale(roi_gray)for (ex, ey, ew, eh) in eyes:cv2.rectangle(roi_color, (ex, ey), (ex+ew, ey+eh), (0, 255, 0), 2)# 显示结果
cv2.imshow("Detected Faces and Eyes", image)
cv2.waitKey(0)
cv2.destroyAllWindows()1. 加载预训练模型
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
- 功能:加载 OpenCV 提供的预训练 Haar 级联分类器模型,用于检测人脸和眼睛。
- 参数:
cv2.CascadeClassifier:加载 XML 模型文件。cv2.data.haarcascades:OpenCV 提供的 Haar 分类器模型的默认路径。'haarcascade_frontalface_default.xml':用于检测正面人脸。'haarcascade_eye.xml':用于检测眼睛。
2. 读取并预处理图像
image_path = "path_to_image.jpg" # 替换为你的图片路径
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转为灰度图
- 功能:
- 使用
cv2.imread读取图像。 - 转换为灰度图(灰度图检测效率更高,级联分类器对彩色图像没有直接支持)。
- 使用
- 原因:级联分类器的训练和使用都基于灰度图像。
3. 检测人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
- 功能:检测图像中的所有人脸。
- 参数:
gray:输入的灰度图。scaleFactor=1.1:每次图像缩小时的比例因子,较大的值降低检测时间但可能错过较小的人脸。minNeighbors=5:每个候选矩形需满足的邻近矩形数量。值越大,检测结果越严格。minSize=(30, 30):目标检测框的最小尺寸,用于过滤过小的区域。
- 输出:返回一个列表,每个元素是一个
(x, y, w, h)元组,表示检测到的人脸的矩形框。
4. 绘制人脸矩形框并检测眼睛
for (x, y, w, h) in faces:cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)roi_gray = gray[y:y+h, x:x+w]roi_color = image[y:y+h, x:x+w]
- 功能:
- 遍历
faces中的每个人脸检测框(x, y, w, h)。 - 使用
cv2.rectangle在原图上绘制蓝色框((255, 0, 0))表示人脸区域。 - 提取每个人脸的灰度子图
roi_gray和原图的子图roi_color,用于后续的眼睛检测。
- 遍历
- 原因:减少检测区域,提高眼睛检测的精度和速度。
5. 在每张人脸区域内检测眼睛
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex, ey, ew, eh) in eyes:cv2.rectangle(roi_color, (ex, ey), (ex+ew, ey+eh), (0, 255, 0), 2)
- 功能:使用
eye_cascade.detectMultiScale在人脸区域内检测眼睛。 - 参数:同人脸检测,输入的灰度子图为
roi_gray。 - 绘制结果:用绿色框(
(0, 255, 0))表示检测到的眼睛。
6. 显示结果
cv2.imshow("Detected Faces and Eyes", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 功能:
- 使用
cv2.imshow显示图像。 cv2.waitKey(0):等待用户按键关闭窗口。cv2.destroyAllWindows:销毁所有窗口,释放资源。
- 使用
总结
- 输入:一张图片(RGB 格式)。
- 处理:
- 转为灰度图。
- 使用预训练的 Haar 级联模型检测人脸和眼睛。
- 在检测到的区域绘制矩形框。
- 输出:在窗口中显示标注了人脸和眼睛的图片。
基于深度学习的人脸检测算法
基于深度学习的人脸检测算法经历了从传统方法到现代深度学习方法的演变,其发展历程可以划分为几个重要阶段。以下是基于深度学习的人脸检测算法的主要发展历史:
1. 传统方法阶段(2000年以前)
- 特点:
- 依赖于手工设计特征和传统机器学习方法(如 Haar 特征、HOG 特征)。
- 算法代表:Haar 级联分类器(Viola-Jones,人脸检测的重要突破)。
- 局限:
- 对光照、姿态、遮挡等情况敏感。
- 检测速度快但精度有限。
这一阶段虽然不基于深度学习,但奠定了人脸检测的基础。
2. 深度学习的初步应用(2012年左右)
- 背景:2012年 AlexNet 在 ImageNet 比赛中获胜,深度学习开始广泛应用于计算机视觉。
- 特点:
- 使用卷积神经网络(CNN)作为特征提取器。
- 算法代表:DeepFace(Facebook, 2014)
- 使用深度神经网络(DNN)对人脸检测和识别进行处理。
- 首次将深度学习应用于人脸检测和识别任务,性能显著提升。
- 局限:
- 网络规模较小,无法应对复杂场景(如多角度、遮挡)
3. 基于回归的方法(2015年左右)
- 背景:深度学习框架和硬件性能的进步,使得更复杂的网络架构成为可能。
- 特点:
- 使用 CNN 直接回归人脸框的坐标。
- 算法代表:
- Cascade CNN(2015):使用多个 CNN 逐步回归人脸位置,提高检测精度。
- MTCNN(Multi-task Cascaded CNN, 2016):结合多任务学习,联合进行人脸检测和关键点定位。
- 特点:多阶段检测框架,利用级联网络逐步细化结果。
- 优点:检测速度和精度兼顾,成为经典方法。
4. 单阶段和双阶段目标检测器的引入(2016年-2018年)
- 背景:通用目标检测器如 Faster R-CNN、SSD、YOLO 等在物体检测任务中的成功,推动了它们在人脸检测领域的应用。
- 特点:
- 单阶段方法:如 SSD 和 YOLO,将人脸检测视为通用物体检测任务。
- 双阶段方法:如 Faster R-CNN,将区域建议网络(RPN)与分类器结合。
- 算法代表:
- Face R-CNN:使用 Faster R-CNN 对人脸进行检测。
- S3FD(Single Shot Scale-invariant Face Detector, 2017):基于 SSD 的改进,解决了人脸大小变化的问题。
- RetinaFace(2019):结合关键点检测,性能优异。
5. 基于关键点检测和自监督学习(2018年后)
- 特点:
- 强调对复杂场景(如遮挡、多角度、低光照)的鲁棒性。
- 将人脸关键点检测和人脸检测结合,进一步提升精度。
- 算法代表:
- DSFD(Dual Shot Face Detector, 2019):多分辨率特征融合,更适合检测小人脸。
- CenterFace(2020):轻量级人脸检测器,结合人脸框和关键点检测,适合实时应用。
- SCRFD(2021):针对边缘设备优化的高效人脸检测器。
6. 大模型和自监督学习的影响(2021年后)
- 背景:大规模预训练模型(如 Vision Transformer, CLIP)的兴起,为人脸检测带来了新的可能性。
- 特点:
- 使用自监督学习方法,通过大规模无标签数据学习强大的特征表征。
- 将 Transformer 等新架构引入人脸检测任务。
- 算法代表:
- DEtection TRansformer (DETR):结合 Transformer 架构的人脸检测方法。
- YOLO 系列最新版本:如 YOLOv5、YOLOv8,在人脸检测任务中的应用。
三、人脸对齐
人脸对齐是将检测得到的人脸图像变换到标准正脸姿态,在实际图片中,由于头部姿态各异、人脸尺度不一,所呈现的形式也各不相同。
- 人脸检测:
- 检测人脸框,提取人脸区域。
- 使用 OpenCV 提供的 Haar 或 DNN 检测器。
- 关键点检测:
- 使用关键点检测模型提取人脸的关键点(如眼睛、鼻尖等)。
- 关键点可以用 Dlib 或深度学习模型(如 MTCNN)提取。
- 仿射变换:
- 根据检测到的关键点,定义源点(人脸关键点)和目标点(标准模板关键点)。
- 计算仿射变换矩阵并应用变换,将人脸对齐。
四、特征提取
特征提取是将输入的人脸图像用一个高维特征向量来表示;如果同一个人,则两个高维特征向量的距离近;如果不同,则距离远。人脸特征提取的方法也可以分为传统方法和深度学习两大类。
人脸特征提取算法经历了从早期的几何特征分析到现代深度学习的转变,其发展历史可以分为以下几个阶段:
1. 几何特征阶段(20世纪70-90年代)
代表方法:
- 几何特征分析:
- 利用人脸的几何属性(如眼睛间距、鼻梁长度、脸型轮廓)作为特征。
- 通过手工定义的特征点计算欧氏距离等度量方式。
- 模板匹配:
- 使用平均脸模板,匹配输入人脸与模板的相似度。
优缺点:
- 优点:简单直观,计算量小。
- 缺点:对光照、姿态和遮挡不鲁棒,特征维度较低。
代表研究:
- 1973年,Bledsoe 提出的人脸几何模型匹配方法。
- 1987年,Sirovich 和 Kirby 提出的脸空间方法,为 PCA 奠定了基础。
2. 统计学习阶段(1990-2010年)
代表方法:
- 主成分分析(PCA):
- 把人脸图像作为高维向量,降维成低维特征表示(如特征脸)。
- 1991年,Turk 和 Pentland 提出了Eigenfaces 方法。
- 线性判别分析(LDA):
- 增强类间区分能力,用于人脸识别。
- 解决了 PCA 的类间可分性不足问题。
- 独立成分分析(ICA):
- 分离人脸的非高斯成分,适合表情和姿态变化分析。
- 局部二值模式(LBP):
- 基于纹理模式的人脸描述,提取局部区域的纹理特征。
- Fisherfaces:
- 综合 PCA 和 LDA 方法,提升对光照变化的鲁棒性。
优缺点:
- 优点:提出了许多经典算法,对光照、姿态变化有一定鲁棒性。
- 缺点:对非线性特征无法很好建模,提取的特征不够高维,难以处理复杂场景。
代表研究:
- 1991年,Eigenfaces。
- 1997年,Belhumeur 提出的 Fisherfaces。
- 2002年,LBP 被引入人脸识别领域。
3. 局部特征阶段(2000-2015年)
代表方法:
- SIFT (Scale-Invariant Feature Transform):
- 提取图像中的局部关键点和特征描述。
- 对光照、尺度、旋转变化鲁棒。
- HOG (Histogram of Oriented Gradients):
- 提取梯度方向分布,用于描述人脸的全局形状。
- Gabor 特征:
- 模拟人类视觉皮层特性,用 Gabor 滤波器提取人脸纹理。
优缺点:
- 优点:提升了对光照和局部细节的鲁棒性。
- 缺点:局部特征无法很好表达全局信息,算法复杂度较高。
代表研究:
- 2004年,Lowe 提出的 SIFT。
- 2005年,Dalal 和 Triggs 提出的 HOG。
- 2006年,Gabor 特征被广泛应用于人脸识别。
4. 深度学习阶段(2014年至今)
关键技术:
- 卷积神经网络(CNN):
- 自适应提取多层次特征,捕捉人脸的纹理、形状、表情等信息。
- 提取的特征更具辨别性。
- 预训练模型:
- 使用大规模人脸数据集进行训练,如 LFW、CASIA-WebFace 等。
- 模型具备迁移学习能力。
代表算法:
- DeepFace (2014, Facebook):
- 首个端到端人脸识别深度学习模型。
- 采用卷积神经网络,实现接近人类的识别精度。
- DeepID (2014-2015, 中国科学院):
- 提出多层 CNN 架构,特征更加鲁棒。
- 引入多个子网络对不同区域进行特征提取。
- FaceNet (2015, Google):
- 基于深度学习的人脸特征提取算法。
- 使用 Triplet Loss 学习特征嵌入,支持高效人脸验证和聚类。
- ArcFace (2018, InsightFace):
- 提出了 Additive Angular Margin Loss,进一步优化特征的判别性。
- 被广泛用于工业人脸识别系统。
- CosFace、SphereFace:
- 聚焦于特征分布的角度约束,提升类间分离度。
优缺点:
- 优点:特征表示能力强,适用于大规模人脸识别。
- 缺点:需要大量数据和计算资源,可能存在隐私问题。
代表研究:
- 2014年,Facebook 提出 DeepFace。
- 2015年,Google 提出 FaceNet。
- 2018年,ArcFace 成为人脸识别领域的主流算法。
五、人脸比对
获取了人脸特征后,对于不同人脸图像,通过比对其人脸特征之间的距离远近,就可以判断人脸身份。
在 Python 中,OpenCV 提供的 cv2.FaceRecognizerSF 模块可以用于人脸识别任务,match 是其方法之一,用于比较两个特征向量之间的相似度。以下是 facerecognizer.match 方法的详细介绍:
函数原型
cv2.FaceRecognizerSF.match(face1: numpy.ndarray, face2: numpy.ndarray, disType: int = 0) -> float
参数说明
-
face1- 类型:
numpy.ndarray - 描述: 第一个人脸的特征向量。
- 特征向量通常由
cv2.FaceRecognizerSF.feature()方法生成,表示人脸的深度特征。
- 特征向量通常由
- 类型:
-
face2- 类型:
numpy.ndarray - 描述: 第二个人脸的特征向量。
- 同样通过
feature()方法提取,用于与face1比较。
- 同样通过
- 类型:
-
disType- 类型:
int - 描述: 指定距离度量的类型,用于衡量两个特征向量之间的相似性。
- 可选值:
0(cv2.FaceRecognizerSF.FR_COSINE): 使用余弦相似度。1(cv2.FaceRecognizerSF.FR_NORM_L2): 使用 L2 范数(欧几里得距离)。
- 类型:
返回值
- 类型:
float - 描述: 返回两个特征向量的相似度分数。
- 对于余弦相似度,值越大表示越相似(最大值为1)。
- 对于 L2 范数,值越小表示越相似。
六、开源项目盘点
- CompreFace
- Deepface
- InsightFace
- Face Recognition
- FaceNet
- OpenFace
相关文章:

【计算机视觉】人脸识别
一、简介 人脸识别是将图像或者视频帧中的人脸与数据库中的人脸进行对比,判断输入人脸是否与数据库中的某一张人脸匹配,即判断输入人脸是谁或者判断输入人脸是否是数据库中的某个人。 人脸识别属于1:N的比对,输入人脸身份是1&…...

linux环境变量配置文件区别 /etc/profile和~/.bash_profile
在 Linux 系统中,环境变量可以定义用户会话的行为,而这些变量的加载和配置通常涉及多个文件,如 ~/.bash_profile 和 /etc/profile。这些文件的作用和加载时机各有不同。以下是对它们的详细区别和用途的说明: 文章目录 1. 环境变量…...

mac 配置 python 环境变量
最新 mac 电脑,配置原理暂未研究,欢迎答疑 方案一 获取python的安装路径 which python3 配置环境变量 open ~/.bash_profile 末尾添加: PATH"/Library/Frameworks/Python.framework/Versions/3.13/bin:${PATH}" export PATH …...
终极的复杂,是简单
软件仿真拥有最佳的信号可见性和调试灵活性,能够高效捕获很多显而易见的常见错误,被大多数工程师熟练使用。 空间领域应用的一套数据处理系统(Data Handling System),采用抗辐FPGA作为主处理器,片上资源只包含10752个寄存器,软仿也是个挺花时间的事。 Few ms might take …...
)
软件开发中的密码学(国密算法)
1.软件行业中的加解密 在软件行业中,加解密技术广泛应用于数据保护、通信安全、身份验证等多个领域。加密(Encryption)是将明文数据转换为密文的过程,而解密(Decryption)则是将密文恢复为明文的过程。以下…...

【豆包MarsCode 蛇年编程大作战】蛇形烟花
项目体验地址:项目体验地址 官方活动地址:活动地址 目录 【豆包MarsCode 蛇年编程大作战】蛇形烟花演示 引言 豆包 MarsCode介绍 项目准备 第一步:安装插件 第二步:点击豆包图标来进行使用豆包 使用豆包 MarsCodeAI助手实…...
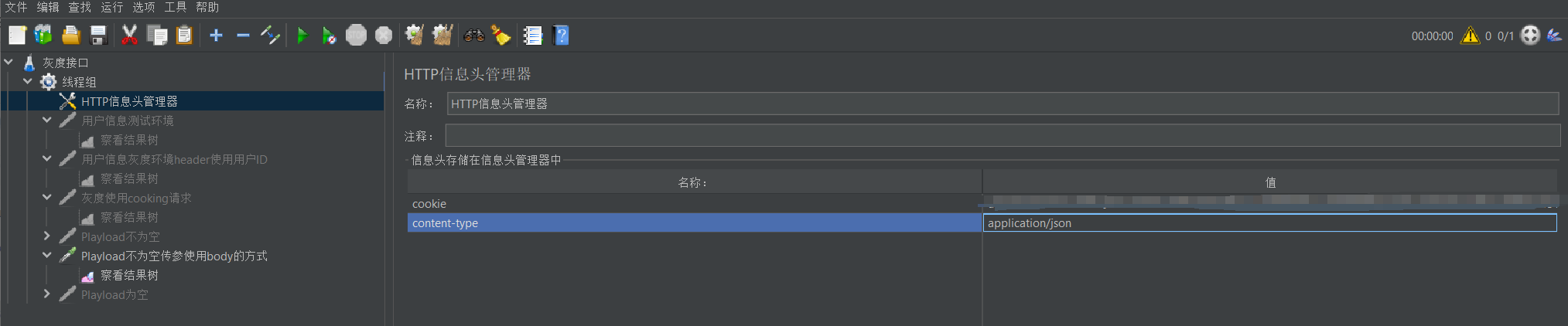
Jmeter使用Request URL请求接口
简介 在Jmeter调试接口时,有时不清楚后端服务接口的具体路径,可以使用Request URL和cookie来实现接口请求。以下内容以使用cookie鉴权的接口举例。 步骤 ① 登录网站后获取具体的Request URL和cookie信息 通过浏览器获取到Request URL和cookie&#…...

使用Pytest Fixtures来提升TestCase的可读性、高效性
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 在编写单元测试时,你是否发现自己有很多重复代码? 数据库设…...
Arduino大师练成手册 -- 读取DHT11
要在 Arduino 上控制 DHT11 温湿度传感器,你可以按照以下步骤进行: 硬件连接: 将 DHT11 的 VCC 引脚连接到 Arduino 的 5V 引脚。 将 DHT11 的 GND 引脚连接到 Arduino 的 GND 引脚。 将 DHT11 的 DATA 引脚连接到 Arduino 的数字引脚&am…...

【Jave全栈】Java与JavaScript比较
文章目录 前言一、Java1、 历史与背景2、语言特点3、应用场景4、生态系统 二、JavaScript1、历史与背景2、语言特点3、应用场景4、 生态系统 三、相同点四、不同点1、语言类型2、用途3、语法和结构4、性能5、生态系统6、开发模式 前言 Java和JavaScript是两种不同的编程语言&a…...

【高项】6.2 定义活动 ITTO
定义活动是识别和记录为完成项目可交付成果而须采取的具体行动的过程。 作用:将工作包分解为进度活动,作为对项目工作进行进度估算、规划、执行、监督和控制的基础 输入 项目管理计划 ① 进度管理计划:定义进度计划方法、滚动式规划的持续…...

openlava/LSF 用户组管理脚本
背景 在openlava运维中经常需要自动化一些常规操作,比如增加用户组以及组成员、删除用户组成员、删除用户组等。而openlava的配置文件需要手动修改,然后再通过badmin reconfig激活配置。因此开发脚本将手工操作自动化就很有必要。 通过将脚本中的User…...
)
数据结构与算法之贪心: LeetCode 649. Dota2 参议院 (Ts版)
Dota2 参议院 https://leetcode.cn/problems/dota2-senate/ 描述 Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇) Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。…...

西藏酥油茶:高原上的醇香温暖
西藏酥油茶:高原上的醇香温暖 在西藏高原,有一种饮品,它不仅滋养了一代又一代的藏民,还承载着丰富的文化与历史,它就是西藏酥油茶。酥油茶,藏语称为“恰苏玛”,意为搅动的茶,是藏族人民日常生活中不可或缺的一部分,更是待客、祭祀等活动中的重要礼仪物品。 历史与文化渊源 酥…...
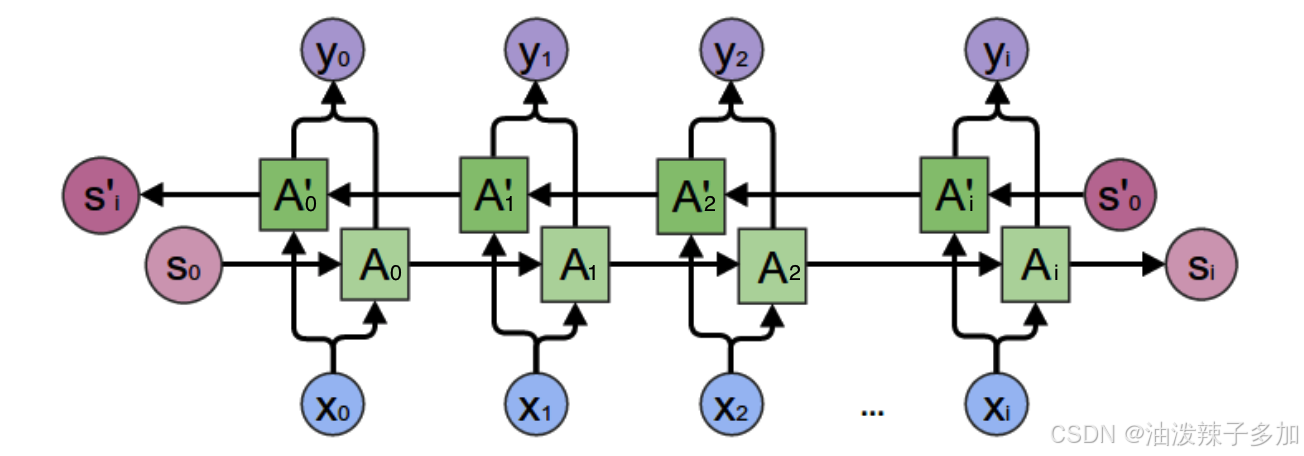
【模型】RNN模型详解
1. 模型架构 RNN(Recurrent Neural Network)是一种具有循环结构的神经网络,它能够处理序列数据。与传统的前馈神经网络不同,RNN通过将当前时刻的输出与前一时刻的状态(或隐藏层)作为输入传递到下一个时刻&…...
)
C++----STL(list)
介绍 list的数据结果是一个带头双向链表。 使用 有了前面string、vector的基础,后续关于list使用的讲解主要提及与string和vector的不同之处。 使用文档:cplusplus.com/reference/list/list/?kwlist 迭代器问题 insert以后迭代器不失效 #include…...

数据结构——AVL树的实现
Hello,大家好,这一篇博客我们来讲解一下数据结构中的AVL树这一部分的内容,AVL树属于是数据结构的一部分,顾名思义,AVL树是一棵特殊的搜索二叉树,我们接下来要讲的这篇博客是建立在了解搜索二叉树这个知识点…...
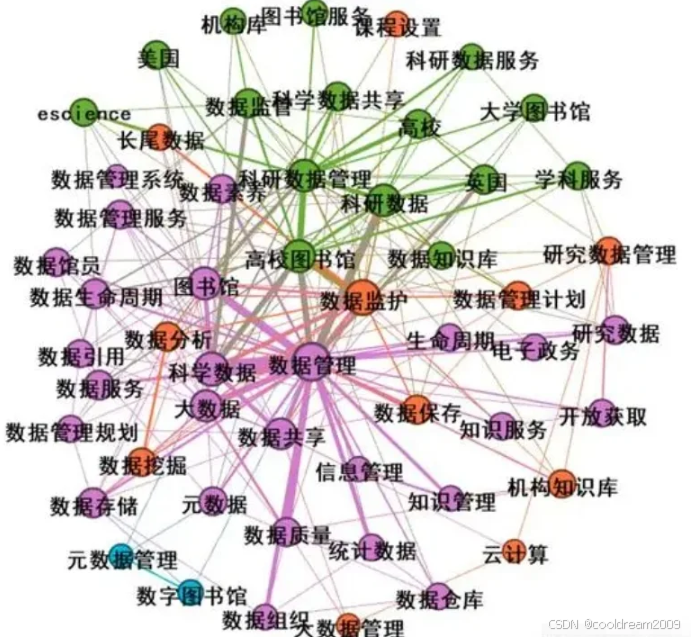
知识图谱在个性化推荐中的应用:赋能智能化未来
目录 前言1. 知识图谱的基本概念2. 个性化推荐的挑战与知识图谱的优势2.1 个性化推荐的主要挑战2.2 知识图谱在个性化推荐中的优势 3. 知识图谱赋能推荐系统的具体实现3.1 数据增强与关系建模3.2 嵌入技术的应用3.3 图神经网络(GNN)的应用3.4 多模态数据…...
C语言自定义数据类型详解(一)——结构体类型(上)
什么是自定义数据类型呢?顾名思义,就是我们用户自己定义和设置的类型。 在C语言中,我们的自定义数据类型一共有三种,它们分别是:结构体(struct),枚举(enum),联合(union)。接下来,我…...

使用 Tailwind CSS + PostCSS 实现响应式和可定制化的前端设计
随着前端开发框架和工具的不断更新,设计和样式的管理已经成为前端开发中的一项核心任务。传统的 CSS 编写方式往往让样式的复用和可维护性变得困难,而 Tailwind CSS 和 PostCSS 作为当下流行的工具,提供了强大的功能来简化开发过程࿰…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

绝了!原来毕业论文还能这样写?2026降AIGC工具推荐合集
还在为查重率爆红、AI痕迹太明显、格式乱成一团而发愁?2026 年的 AI 论文工具早已不只是写文章那么简单,从选题构思到降AIGC率、去AI痕迹、查重优化,全流程智能辅助,帮你把论文写作变得简单高效,告别熬夜改稿的焦虑&am…...

3步终结Windows热键冲突:Hotkey Detective终极排查指南
3步终结Windows热键冲突:Hotkey Detective终极排查指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...

三分钟快速上手:FanControl让你的电脑风扇从此安静又高效
三分钟快速上手:FanControl让你的电脑风扇从此安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...