C++----STL(list)
介绍
list的数据结果是一个带头双向链表。
使用
有了前面string、vector的基础,后续关于list使用的讲解主要提及与string和vector的不同之处。
使用文档:cplusplus.com/reference/list/list/?kw=list
迭代器问题
insert以后迭代器不失效
#include <iostream>
#include <list>
#include <vector>
using namespace std;int main() {list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_front(10);lt.push_front(20);//在元素3的位置上插入30auto it = find(lt.begin(), lt.end(), 3);if (it != lt.end()){lt.insert(it, 30);// insert以后,it不失效*it *= 100;}return 0;
}erase以后迭代器会失效
#define _CRT_SECURE_NO_EARNINGS 1
#include <iostream>
#include <list>
#include <vector>
using namespace std;int main() {list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_front(10);lt.push_front(20);//在元素3的位置上插入30auto it = find(lt.begin(), lt.end(), 3);if (it != lt.end()){lt.insert(it, 30);// insert以后,it不失效*it *= 100;}it = find(lt.begin(), lt.end(), 2);if (it != lt.end()){lt.erase(it);//erase以后,it失效了//*it *= 100;//error}return 0;
}容器和迭代器类型
不同的容器在C++标准模板库(STL)中有不同的底层结构和迭代器类型。这些迭代器类型决定了容器支持哪些算法操作:
- 单向迭代器:forward_list、unordered_map、unordered_set 这些容器仅支持向前遍历(即仅支持++操作)。
- 双向迭代器:list、map、set 这些容器支持向前和向后遍历(即支持++和--操作)。
- 随机访问迭代器:vector、string、deque 这些容器支持高效的随机访问(即支持++,--,+,-,以及比较操作)。
我们再通过vector和list的insert、erase来理解一下上面的讲解:
insert:
#include <iostream>
#include <list>
#include <vector>
using namespace std;int main() {list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_front(10);lt.push_front(20);vector<int> v = { 1,2,3,4,5 };//vector在第5个位置插入数据v.insert(v.begin() + 5, 100);//list在第5个位置插入数据//lt.insert(lt.begin() + 5, 100);//错误做法auto it = lt.begin();for (size_t i = 0; i < 5; i++){++it;}lt.insert(it, 100);return 0;
}erase:
#include <iostream>
#include <list>
#include <vector>
using namespace std;int main() {list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_front(10);lt.push_front(20);vector<int> v = { 1,2,3,4,5 };//vector删除第5个元素v.erase(v.begin() + 5);//list删除第5个元素//lt.erase(begin() + 5);//错误做法it = lt.begin();for (size_t i = 0; i < 5; i++) {++it;}lt.erase(it);return 0;
}排序
sort
如果需要对一组数据sort排序,建议使用vector进行sort排序,而不要使用list,因为在数据量很大的情况下vector排序的效率远高于list。我们通过一个代码来验证一下:
void test_op()
{srand(time(0));const int N = 1000000;vector<int> v;v.reserve(N);list<int> lt1;list<int> lt2;for (int i = 0; i < N; ++i){auto e = rand();lt2.push_back(e);lt1.push_back(e);}// 拷贝到vector排序,排完以后再拷贝回来int begin1 = clock();// 先拷贝到vectorfor (auto e : lt1){v.push_back(e);}// 排序sort(v.begin(), v.end());// 拷贝回去size_t i = 0;for (auto& e : lt1){e = v[i++];}int end1 = clock();int begin2 = clock();lt2.sort();int end2 = clock();printf("vector sort:%d\n", end1 - begin1);printf("list sort:%d\n", end2 - begin2);
}merge:合并排序
#include <iostream>
#include <list>
#include<algorithm>
using namespace std;void print(list<int> lt) {cout << "lt: ";for (auto e : lt) {cout << e << " ";}cout << endl;
}void test_merge(int a1[], int a2[],int len1,int len2) {sort(a1, a1 + len1);sort(a2, a2 + len2);list<int> lt(10);merge(a1, a1 + len1, a2, a2 + len2, lt.begin());print(lt);
}int main() {int first[] = { 5,10,15,20,25 };int second[] = { 50,40,30,20,10 };int len1 = sizeof(first) / sizeof(first[0]);int len2 = sizeof(second) / sizeof(second[0]);test_merge(first, second, len1, len2);return 0;
}其他算法
unique:去重
#include <iostream>
#include <list>
#include<algorithm>
using namespace std;int main() {// 创建一个包含重复元素的 listlist<int> myList = { 1, 7, 2, 3, 4, 4, 4, 5, 6, 6 };// 注意:std::unique 需要已排序的容器myList.sort(); // 先排序auto lastUnique = unique(myList.begin(), myList.end());// 擦除重复的元素myList.erase(lastUnique, myList.end());// 打印去重后的 listfor (auto e : myList) {cout << e << ' ';}cout << endl;return 0;
}remove:删除指定元素
int main() {list<int> mylist = { 9,89,23,67 };mylist.remove(89);for (auto e : mylist){cout << e << " ";}cout << endl;return 0;
}splice:把一个链表的内容转移到另一个链表上
//splice(iterator pos, list& other)
//将整个源列表other的所有元素移动到目标列表的pos位置之前。源列表将变为空。
void test_splice1(list<int> mylist1,list<int> mylist2) {auto it = mylist1.begin();++it; // points to 2//mylist2全部转移到mylist1的第二个位置之前mylist1.splice(it, mylist2);cout << "spliced mulist1: ";for (auto e : mylist1){cout << e << " ";}cout << endl;
}//splice(iterator pos, list& other, iterator first)
//将源列表other中将 first 指向的元素移动到目标列表的pos位置之前。源列表中 first 元素将被移除。
void test_splice2(list<int> mylist1, list<int> mylist2) {auto it = mylist1.begin();++it; // points to 2// 部分转移// mylist2的++mylist2.begin()的元素转移到mylist1的第二个位置之前mylist1.splice(it, mylist2, ++mylist2.begin());cout << "spliced mulist1: ";for (auto e : mylist1){cout << e << " ";}cout << endl;
}//splice(iterator pos, list& other, iterator first, iterator last)
//将源列表other中从 first 到 last(不包括 last)之间的所有元素移动到目标列表的pos位置之前。源列表other中这部分元素将被移除
void test_splice3(list<int> mylist1, list<int> mylist2) {auto it = mylist1.begin();++it; // points to 2// mylist2的++mylist2.begin()之后的元素转移到mylist1的第二个位置之前mylist1.splice(it, mylist2, ++mylist2.begin(), mylist2.end());cout << "spliced mulist1: ";for (auto e : mylist1){cout << e << " ";}cout << endl;
}
int main() {list<int> mylist1, mylist2;list<int>::iterator it;// set some initial values:for (int i = 1; i <= 4; ++i)mylist1.push_back(i); // mylist1: 1 2 3 4for (int i = 1; i <= 3; ++i)mylist2.push_back(i * 10); // mylist2: 10 20 30test_splice1(mylist1,mylist2);test_splice2(mylist1,mylist2);test_splice3(mylist1,mylist2);return 0;
}相关文章:
)
C++----STL(list)
介绍 list的数据结果是一个带头双向链表。 使用 有了前面string、vector的基础,后续关于list使用的讲解主要提及与string和vector的不同之处。 使用文档:cplusplus.com/reference/list/list/?kwlist 迭代器问题 insert以后迭代器不失效 #include…...

数据结构——AVL树的实现
Hello,大家好,这一篇博客我们来讲解一下数据结构中的AVL树这一部分的内容,AVL树属于是数据结构的一部分,顾名思义,AVL树是一棵特殊的搜索二叉树,我们接下来要讲的这篇博客是建立在了解搜索二叉树这个知识点…...
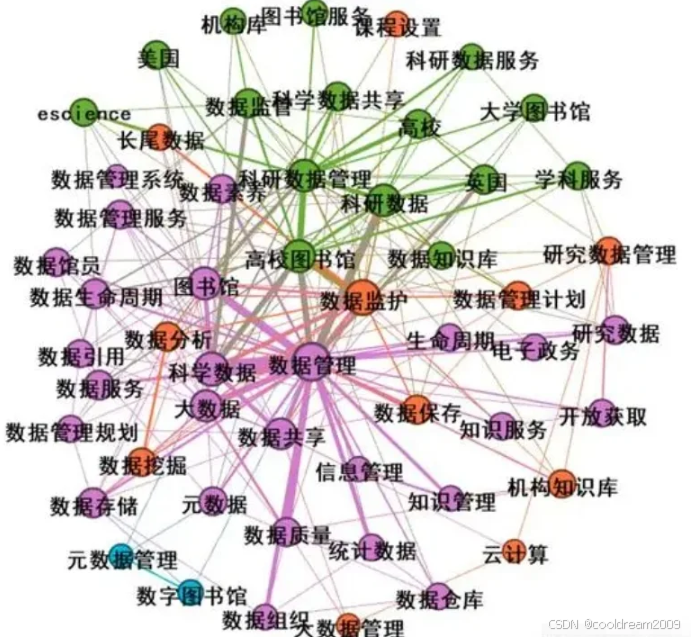
知识图谱在个性化推荐中的应用:赋能智能化未来
目录 前言1. 知识图谱的基本概念2. 个性化推荐的挑战与知识图谱的优势2.1 个性化推荐的主要挑战2.2 知识图谱在个性化推荐中的优势 3. 知识图谱赋能推荐系统的具体实现3.1 数据增强与关系建模3.2 嵌入技术的应用3.3 图神经网络(GNN)的应用3.4 多模态数据…...
C语言自定义数据类型详解(一)——结构体类型(上)
什么是自定义数据类型呢?顾名思义,就是我们用户自己定义和设置的类型。 在C语言中,我们的自定义数据类型一共有三种,它们分别是:结构体(struct),枚举(enum),联合(union)。接下来,我…...

使用 Tailwind CSS + PostCSS 实现响应式和可定制化的前端设计
随着前端开发框架和工具的不断更新,设计和样式的管理已经成为前端开发中的一项核心任务。传统的 CSS 编写方式往往让样式的复用和可维护性变得困难,而 Tailwind CSS 和 PostCSS 作为当下流行的工具,提供了强大的功能来简化开发过程࿰…...

巧用多目标识别能力,帮助应用实现智能化图片解析
为了提升用户体验,各类应用正通过融合人工智能技术,致力于提供更智能、更高效的服务。应用不仅能通过文字和语音的方式与用户互动,还能深入分析图片内容,为用户提供精准的解决方案。 在解析图片之前,应用首先需要准确识…...

算法中的移动窗帘——C++滑动窗口算法详解
1. 滑动窗口简介 滑动窗口是一种在算法中常用的技巧,主要用来处理具有连续性的子数组或子序列问题。通过滑动窗口,可以在一维数组或字符串上维护一个固定或可变长度的窗口,逐步移动窗口,避免重复计算,从而提升效率。常…...
 函数)
AcWing 3585:三角形的边 ← sort() 函数
【题目来源】 给定三个已知长度的边,确定是否能够构成一个三角形,这是一个简单的几何问题。 我们都知道,这要求两边之和大于第三边。 实际上,并不需要检验所有三种可能,只需要计算最短的两个边长之和是否大于最大那个就…...

阿里云-银行核心系统转型之业务建模与技术建模
业务领域建模包括业务建模和技术建模,整体建模流程图如下: 业务建模包括业务流程建模和业务对象建模 业务流程建模:通过对业务流程现状分析,结合目标核心系统建设能力要求,参考行业建 模成果,形成结构化的…...

MySQL核心知识:春招面试数据库要点
在前文中,我们深入剖析了MyBatis这一优秀的持久层框架,了解了它如何实现SQL语句与Java对象的映射,以及其缓存机制等重要内容。而作为数据持久化的核心支撑,数据库的相关知识在Java开发中同样至关重要。MySQL作为最流行的开源关系型…...

Hive之加载csv格式数据到hive
场景: 今天接了一个需求,将测试环境的hive数据导入到正式环境中。但是不需要整个流程的迁移,只需要迁移ads表 解决方案: 拿到这个需求首先想到两个方案: 1、将数据通过insert into语句导出,然后运行脚本 …...

Java web与Java中的Servlet
一。前言 Java语言大多用于开发web系统的后端,也就是我们是的B/S架构。通过浏览器一个URL去访问系统的后端资源和逻辑。 当我在代码里看到这个类HttpServletRequest 时 让我想到了Servlet,Servlet看上去多么像是Java的一个普通类,但是它确实…...

kafka常用目录文件解析
文章目录 1、消息日志文件(.log)2、消费者偏移量文件(__consumer_offsets)3、偏移量索引文件(.index)4、时间索引文件( .timeindex)5、检查点引文件( .checkpoint&#x…...
RV1126+FFMPEG推流项目源码
源码在我的gitee上面,感兴趣的可以自行了解 nullhttps://gitee.com/x-lan/rv126-ffmpeg-streaming-projecthttps://gitee.com/x-lan/rv126-ffmpeg-streaming-project...

ANSYS SimAI
ANSYS SimAI 是 ANSYS 公司推出的一款基于人工智能(AI)的仿真解决方案,旨在通过机器学习技术加速仿真流程,降低计算资源需求,并为用户提供更高效的工程决策支持。其核心目标是简化复杂仿真过程,帮助工程师快…...
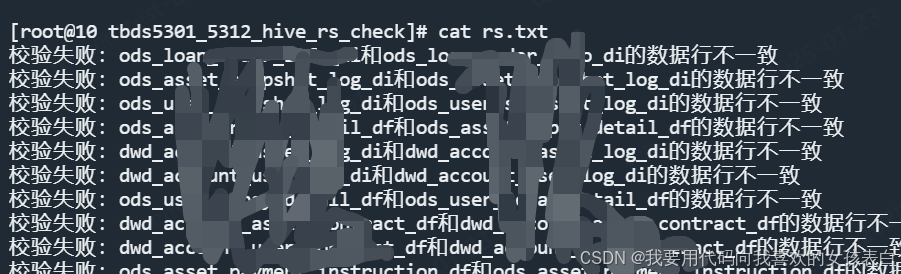
hedfs和hive数据迁移后校验脚本
先谈论校验方法,本人腾讯云大数据工程师。 1、hdfs的校验 这个通常就是distcp校验,hdfs通过distcp迁移到另一个集群,怎么校验你的对不对。 有人会说,默认会有校验CRC校验。我们关闭了,为什么关闭?全量迁…...

蓝桥杯单片机(八)定时器的基本原理与应用
模块训练: 当有长定时情况时,也就是定时长度超过65.5ms时,采用多次定时累加 一、定时器介绍 1.单片机的定时/计数器 2.定时器工作原理 3.定时器相关寄存器 二、定时器使用程序设计 1.程序设计思路 与写中断函数一样,先写一个初…...
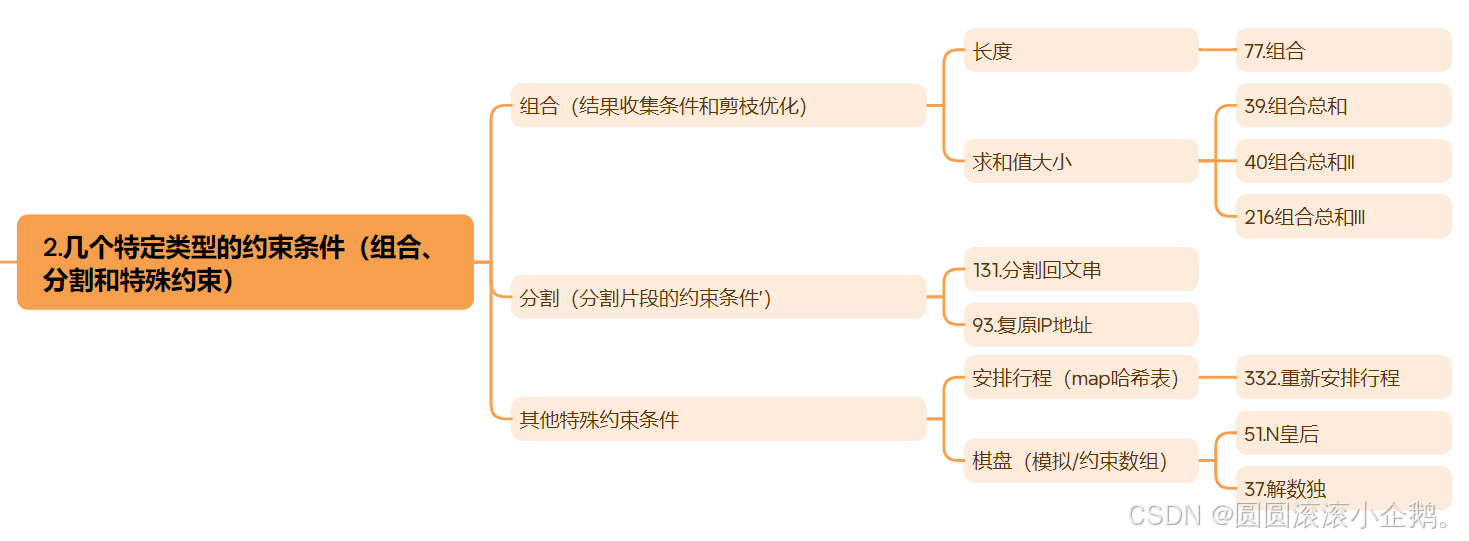
刷题总结 回溯算法
为了方便复习并且在把算法忘掉的时候能尽量快速的捡起来 刷完回溯算法这里需要做个总结 回溯算法的适用范围 回溯算法是深度优先搜索(DFS)的一种特定应用,在DFS的基础上引入了约束检查和回退机制。 相比于普通的DFS,回溯法的优…...

C++ 静态变量static的使用方法
static概述: static关键字有三种使用方式,其中前两种只指在C语言中使用,第三种在C中使用。 静态局部变量(C) 静态全局变量/函数(C) 静态数据成员/成员函数(C) 静态局部变量 静态局部变量&…...
Langchain+文心一言调用
import osfrom langchain_community.llms import QianfanLLMEndpointos.environ["QIANFAN_AK"] "" os.environ["QIANFAN_SK"] ""llm_wenxin QianfanLLMEndpoint()res llm_wenxin.invoke("中国国庆日是哪一天?") print(…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...
提升你的图表专业度?)
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度?
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度? 在数据驱动的决策时代,图表不仅是科研论文中的证据载体,更是商业汇报中的说服工具。我曾见证一位生物统计学家将同一组临床试验数据呈现给三种不同受众&…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...

OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS
OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重获新…...

OpenTK 3.3.3实现3D旋转立方体:C# OpenGL入门实战
1. 为什么一个旋转立方体是3D图形编程真正的“Hello World” 很多人第一次接触OpenGL或现代图形API时,总想直接上手做粒子系统、PBR渲染或者实时阴影——结果卡在顶点缓冲对象(VBO)绑定失败、着色器编译报错、甚至窗口根本没显示出来。我带过…...