hedfs和hive数据迁移后校验脚本
先谈论校验方法,本人腾讯云大数据工程师。
1、hdfs的校验
这个通常就是distcp校验,hdfs通过distcp迁移到另一个集群,怎么校验你的对不对。
有人会说,默认会有校验CRC校验。我们关闭了,为什么关闭?全量迁移,如果当前表再写数据,开自动校验就会失败。数据量大(PB级)迁移流程是先迁移全量,后面在定时补最近几天增量,再找个时间点,进行业务割接
那么怎么知道你迁移的hdfs是否有问题呢?
2个文件,一个是脚本,一个是需要校验的目录
data_checksum.py
# -*- coding: utf-8 -*-
# @Time : 2025/1/16 22:52
# @Author : fly-wlx
# @Email : xxx@163.com
# @File : data_compare.py
# @Software: PyCharmimport subprocess#output_file = 'data_checksum_result.txt'
def load_file_paths_from_conf(conf_file):file_list = []with open(conf_file, 'r') as file:lines = file.readlines()for line in lines:path = line.strip()if path and not path.startswith('#'): # 跳过空行和注释full_path = f"{path}"file_list.append(full_path)return file_list#def write_sizes_to_file(filepath,source_namenode,source_checksum,target_namenode,target_checksum,status, output_file):
# with open(output_file, 'w') as file:
#file.write(f"{source_namenode}/{filepath},{source_checksum},{target_namenode}/{filepath},{target_checksum},{status}\n")def write_sizes_to_file(source_path, src_info, destination_path, target_info, status,output_file):with open(output_file, 'a') as file:file.write(f"{source_path},{src_info},{destination_path}, {target_info}, {status}\n")
def run_hadoop_command(command):"""运行 Hadoop 命令并返回输出"""try:result = subprocess.check_output(command, shell=True, text=True)return result.strip()except subprocess.CalledProcessError as e:print(f"Command failed: {e}")return Nonedef get_hdfs_count(hdfs_filepath):"""获取 HDFS 路径的文件和目录统计信息"""command = f"hadoop fs -count {hdfs_filepath}"output = run_hadoop_command(command)if output:parts = output.split()if len(parts) >= 3:dir_count, file_count, content_size = parts[-3:]return dir_count, file_count, content_sizereturn None, None, Nonedef get_hdfs_size(hdfs_filepath):"""获取 HDFS 路径的总文件大小"""command = f"hadoop fs -du -s {hdfs_filepath}"output = run_hadoop_command(command)if output:parts = output.split()if len(parts) >= 1:return parts[0]return Nonedef validate_hdfs_data(source_namenode, target_namenode,filepath):output_file = 'data_checksum_result.txt'source_path=f"{source_namenode}/{filepath}"destination_path = f"{target_namenode}/{filepath}""""校验 HDFS 源路径和目标路径的数据一致性"""print("Fetching source path statistics...")src_dir_count, src_file_count, src_content_size = get_hdfs_count(source_path)src_total_size = get_hdfs_size(source_path)print("Fetching destination path statistics...")dest_dir_count, dest_file_count, dest_content_size = get_hdfs_count(destination_path)dest_total_size = get_hdfs_size(destination_path)src_info={}src_info["src_dir_count"] = src_dir_countsrc_info["src_file_count"] = src_file_count#src_info["src_content_size"] = src_content_sizesrc_info["src_total_size"] = src_total_sizetarget_info = {}target_info["src_dir_count"] = dest_dir_counttarget_info["src_file_count"] = dest_file_count#target_info["src_content_size"] = dest_content_sizetarget_info["src_total_size"] = dest_total_sizeprint("\nValidation Results:")if (src_dir_count == dest_dir_count andsrc_file_count == dest_file_count and# src_content_size == dest_content_size andsrc_total_size == dest_total_size):print("✅ Source and destination paths are consistent!")write_sizes_to_file(source_path, src_info, destination_path,target_info, 0,output_file)else:print("❌ Source and destination paths are inconsistent!")write_sizes_to_file(source_path, src_info, destination_path, target_info, 1,output_file)#print(f"Source: DIR_COUNT={src_dir_count}, FILE_COUNT={src_file_count}, CONTENT_SIZE={src_content_size}, TOTAL_SIZE={src_total_size}")#print(f"Destination: DIR_COUNT={dest_dir_count}, FILE_COUNT={dest_file_count}, CONTENT_SIZE={dest_content_size}, TOTAL_SIZE={dest_total_size}")# 设置源路径和目标路径
#source_path = "hdfs://namenode1:8020/"
#destination_path = "hdfs://namenode2:8020/path/to/destination"
# 定义源和目标集群的 namenode 地址
source_namenode = "hdfs://10.xx.xx.6:8020"
target_namenode= "hdfs://10.xx.xx.106:4007"def main():# 配置文件路径和输出文件路径conf_file = 'distcp_paths.conf'# 定义源和目标集群的 namenode 地址# 设置源路径和目标路径#source_namenode = "hdfs://source-namenode:8020"#target_namenode = "hdfs://target-namenode:8020"# 文件列表file_paths = load_file_paths_from_conf(conf_file)# 对每个目录进行校验for filepath in file_paths:validate_hdfs_data(source_namenode, target_namenode, filepath)if __name__ == "__main__":main()# 执行校验
#validate_hdfs_data(source_path, destination_path)distcp_paths.conf
/apps/hive/warehouse/xx.db/dws_ixx_features
/apps/hive/warehouse/xx.db/dwd_xx_df用法
直接python3 data_checksum.py(需要改为自己的)
他会实时打印对比结果,并且将结果生成到一个文件中(data_checksum_result.txt)

2、hive文件内容比对
最终客户要的是任务的数据对得上,而不是管你迁移怎么样,所以验证任务的方式:两边同时跑同多个Hive任务流的任务,查看表数据内容是否一致。(因为跑出来的hdfs的文件大小由于mapreduce原因,肯定是不一致的,校验实际数据一致就行了)
方法是先对比表字段,然后对比count数,然后将每行拼起来对比md5
涉及3个文件,单检测脚本,批量入口脚本,需要批量检测的表文件
check_script.sh
#!/bin/bash
#owner:clark.shi
#date:2025/1/22
#背景:用于hive从源端任务和目标端任务,两边跑完结果表的内容校验(因为mapreduce和小文件不同,所以要用数据内容校验)
# --用trino(presto)会更好,因为可以跨集群使用,目前客户因为资源情况没装,此为使用hive引擎,将数据放到本地进行比对#输入:源端表,目标表,分区名,分区值
#$0是脚本本身,最低从1开始#限制脚本运行内存大小,30gb
#ulimit -v 30485760#---注意,要保证,2个表的字段顺序是一样的(md5是根据顺序拼接的)
echo "================"
echo "注意"
echo "要保证,2个表的字段顺序是一样的(md5是根据顺序拼接的)"
echo "要保证,这2个表是存在的"
echo "要保证,双端是可以互相访问"
echo "要保证,2个hive集群的MD5算法相同"
echo "禁止表,一个分区数据量超过本地磁盘,此脚本会写入本地磁盘(双端数据),对比后删除"
echo "注意,如果分区字段是数字不用加引号,如果是字符串需要加引号,搜partition_value,这里分区是int如20250122是没有引号"
echo "================"a_table=$1
b_table=$2
partition_column=$3
partition_value=$4if [ $# -ne 4 ]; thenecho "错误:必须输入 4 个参数,源端表,目标表,分区名,分区值"exit 1
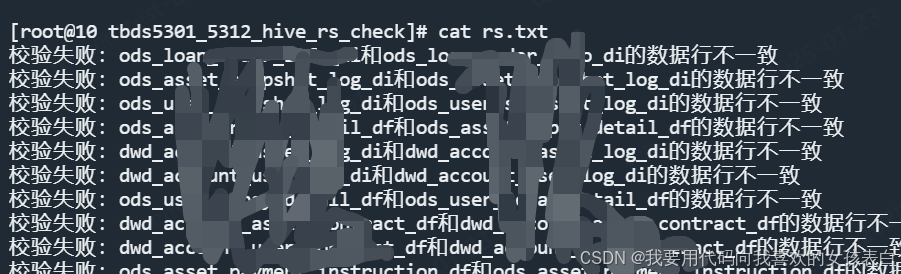
fi#------------函数check_value() {# 第一个参数是布尔值,第二个参数是要 echo 的内容local value=$1local message=$2# 检查第一个参数的值if [ "$value" == "false" ]; thenecho "校验失败:$message" >> rs.txtexit fi
}#-----------函数结束echo "需要对比表的数据内容是$a_table和$b_table--,需要对比分区$partition_column是$partition_value--"sleep 2
echo "===============开始校验============="
#todo改成自己的,kerbers互信认证(也可以用ldap)
`kinit -kt /root/s_xx_tbds.keytab s_xx_tbds@TBDS-V12X10CS`#校验字段类型
echo "1.开始校验字段类型"#todo这里要改成自己的beeline -u "jdbc:hive2://10.xx.xx.4:10001/XXdatabase;principal=hive/tbds-10-xx-xx-4.hadooppdt.xxjin.srv@TBDS-V12X10CS;transportMode=http;httpPath=cliservice" -e "DESCRIBE $b_table" > 1_a_column.txtbeeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" -e "DESCRIBE $a_table" > 1_b_column.txtif diff 1_a_column.txt 1_b_column.txt > /dev/null; thenecho "表结构一致"elseecho "表结构不一致"check_value false "$a_table和$b_table字段类型不一致"fi echo "------------1.表字段,校验完毕,通过-------------"#校验count数
echo "2.开始count校验"beeline -u "jdbc:hive2://10.xx.xx.4:10001/XXdatabase;principal=hive/tbds-10-xx-xx-4.hadooppdt.xxjin.srv@TBDS-V12X10CS;transportMode=http;httpPath=cliservice" -e "select count(*) from $b_table where $partition_column=$partition_value" > 2_a_count.txtbeeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" -e "select count(*) from $a_table where $partition_column=$partition_value" > 2_b_count.txtif diff 2_a_count.txt 2_b_count.txt > /dev/null; thenecho "数据行一致"elseecho "数据行不一致"check_value false "$a_table和$b_table的数据行不一致"fiecho "------------2.数据行,校验完毕,通过-------------"#拼接每一行的值,作为唯一值,创建2个临时表
echo "3.生成每条数据唯一标识"#1.获取表列名#使用awk,去除第一行字段名,,删除#字号以及他后面的内容(一般是分区的描述),根据分隔符|取第一列数据,去掉空的行beeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" --outputformat=dsv -e "DESCRIBE $a_table" |awk 'NR > 1' |awk '!/^#/ {print} /^#/ {exit}'|awk 'BEGIN {FS="|"} {print $1}'|awk 'NF > 0' > 3_table_field_name.txt#2.拼接表列名,生成md5的表 (第一步已经检测过双方的表结构了,这里用同一个拼接字段即可)# 使用 while 循环逐行读取文件内容name_fields=""while IFS= read -r line; doif [ -z "$name_fields" ]; thenname_fields="$line"elsename_fields="$name_fields,$line"fidone < "3_table_field_name.txt"echo "$name_fields"#将每行数据进行拼接,并且生成含一个字段的md5表md5_sql="SELECT distinct(MD5(CONCAT($name_fields))) AS md5_value "a_md5_sql="$md5_sql from (select * from dim_user_profile_df where $partition_column=$partition_value limit 100)a;"b_md5_sql="$md5_sql from $a_table where $partition_column=$partition_value;"echo "a表的sql是:$a_md5_sql"echo "b表的sql是:$b_md5_sql"#源端是生产环境,这里做了特殊处理,源端就取100条(没使用order by rand(),客户主要是检测函数,order by 会占用他们集群资源)beeline -u "jdbc:hive2://10.xx.xx.4:10001/XXdatabase;principal=hive/tbds-10-xx-xx-4.hadooppdt.xxjin.srv@TBDS-V12X10CS;transportMode=http;httpPath=cliservice" --outputformat=dsv -e "$a_md5_sql" > 4_a_md5_data.txtbeeline -u "jdbc:hive2://10.xx.xx.104:7001/XXdatabase;principal=hadoop/10.xx.xx.104@TBDS-09T7KXLE" --outputformat=dsv -e "$b_md5_sql" > 4_b_md5_data.txt#3.(由于不是同集群,需要下载到本地,再进行导入--如果耗费资源时长太长,再导入到hive,否则直接shell脚本搞定)# 设置large_file和small_file的路径large_file="4_b_md5_data.txt"small_file="4_a_md5_data.txt"# 遍历small_file中的每一行while IFS= read -r line; do# 检查line是否存在于large_file中if grep -qxF "$line" "$large_file"; then# 如果line存在于large_file中,输出1#echo "1"a=1else# 如果line不存在于large_file中,输出2echo "2"check_value false "$a_table和$b_table抽样存在数据内容不一致"fidone < "$small_file"echo echo "------------3.数据内容,校验完毕,通过-------------"
#抽样核对md5(取数据时已抽样,否则数据太大容易跑挂生产环境)
input_file.txt需要校验的表文件
源端表名,目标端表名,分区字段(写1级分区就可以),分区值
ods_xxnfo_di ods_xxnfo_dii dt 20250106
ods_asxx_log_di ods_asxx_log_dii dt 20250106
ods_xxog_di ods_xxog_di dt 20250106
dwd_xxx dwd_xxx dt 20250106
run.sh
#!/bin/bash# 设置文件路径
input_file="input_file.txt"# 遍历文件中的每一行
while IFS= read -r line; do# 调用另一个脚本并传递当前行的参数echo $line./check_script.sh $line# 在每次执行完后间隔一小段时间,避免系统过载(可选)sleep 1
done < "$input_file"使用方法
sh run.sh(需要把check_scripe和run里的内容改成自己的哈)
他会把不通过的,生成一个rs.txt
相关文章:
hedfs和hive数据迁移后校验脚本
先谈论校验方法,本人腾讯云大数据工程师。 1、hdfs的校验 这个通常就是distcp校验,hdfs通过distcp迁移到另一个集群,怎么校验你的对不对。 有人会说,默认会有校验CRC校验。我们关闭了,为什么关闭?全量迁…...

蓝桥杯单片机(八)定时器的基本原理与应用
模块训练: 当有长定时情况时,也就是定时长度超过65.5ms时,采用多次定时累加 一、定时器介绍 1.单片机的定时/计数器 2.定时器工作原理 3.定时器相关寄存器 二、定时器使用程序设计 1.程序设计思路 与写中断函数一样,先写一个初…...
刷题总结 回溯算法
为了方便复习并且在把算法忘掉的时候能尽量快速的捡起来 刷完回溯算法这里需要做个总结 回溯算法的适用范围 回溯算法是深度优先搜索(DFS)的一种特定应用,在DFS的基础上引入了约束检查和回退机制。 相比于普通的DFS,回溯法的优…...

C++ 静态变量static的使用方法
static概述: static关键字有三种使用方式,其中前两种只指在C语言中使用,第三种在C中使用。 静态局部变量(C) 静态全局变量/函数(C) 静态数据成员/成员函数(C) 静态局部变量 静态局部变量&…...
Langchain+文心一言调用
import osfrom langchain_community.llms import QianfanLLMEndpointos.environ["QIANFAN_AK"] "" os.environ["QIANFAN_SK"] ""llm_wenxin QianfanLLMEndpoint()res llm_wenxin.invoke("中国国庆日是哪一天?") print(…...

20250124 Flink中 窗口开始时间和結束時間
增量聚合的 ProcessWindowFunction # ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 搭配使用, 使其能够在数据到达窗口的时候进行增量聚合。当窗口关闭时,ProcessWindowFunction 将会得到聚合的结果。 这样它就可以增量聚合窗口的…...
Android Studio安装配置
一、注意事项 想做安卓app和开发板通信,踩了大坑,Android 开发不是下载了就能直接开发的,对于新手需要注意的如下: 1、Android Studio版本,根据自己的Android Studio版本对应决定了你所兼容的AGP(Android…...
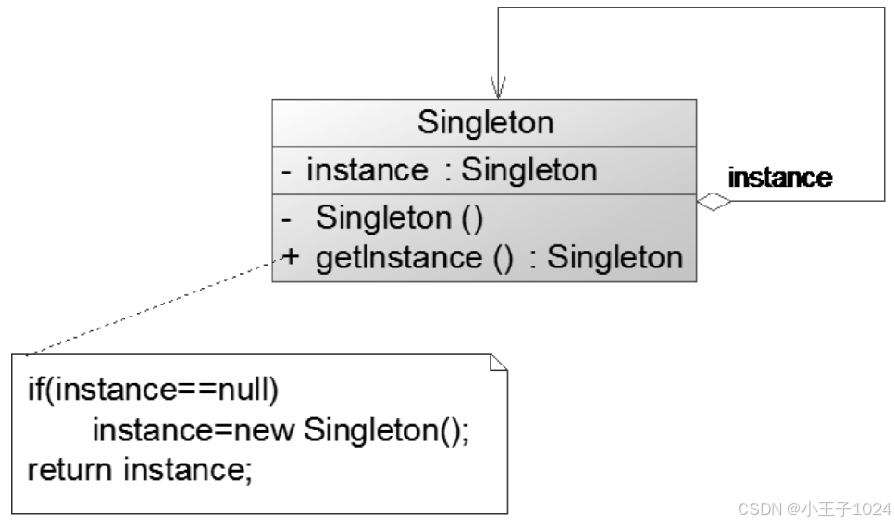
设计模式Python版 单例模式
文章目录 前言一、单例模式二、单例模式实现方式三、单例模式示例四、单例模式在Django框架的应用 前言 GOF设计模式分三大类: 创建型模式:关注对象的创建过程,包括单例模式、简单工厂模式、工厂方法模式、抽象工厂模式、原型模式和建造者模…...
7-Zip高危漏洞CVE-2025-0411:解析与修复
7-Zip高危漏洞CVE-2025-0411:解析与修复 免责声明 本系列工具仅供安全专业人员进行已授权环境使用,此工具所提供的功能只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利…...
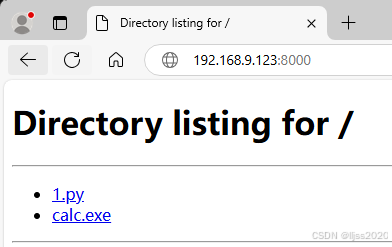
python实现http文件服务器访问下载
//1.py import http.server import socketserver import os import threading import sys# 获取当前脚本所在的目录 DIRECTORY os.path.dirname(os.path.abspath(__file__))# 设置服务器的端口 PORT 8000# 自定义Handler,将根目录设置为脚本所在目录 class MyHTT…...
—— 容灾与备份)
《一文讲透》第4期:KWDB 数据库运维(6)—— 容灾与备份
一、KWDB 容灾 WAL 概述 KWDB 采用预写式日志(Write-Ahead Logging,WAL),记录每个时序表的模式变更和数据变更,以实现时序数据库的数据灾难恢复、时序数据的一致性和原子性。 KWDB 默认会将保存在 WAL 日志缓存中的…...
ArcGIS10.2 许可License点击始终启动无响应的解决办法及正常启动的前提
1、问题描述 在ArcGIS License Administrator中,手动点击“启动”无响应;且在计算机管理-服务中,无ArcGIS License 或者License的启动、停止、禁止等均为灰色,无法操作。 2、解决方法 ①通过cmd对service.txt进行手动服务的启动…...

Level2逐笔成交逐笔委托毫秒记录:今日分享优质股票数据20250124
逐笔成交逐笔委托下载 链接: https://pan.baidu.com/s/1UWVY11Q1IOfME9itDN5aZA?pwdhgeg 提取码: hgeg Level2逐笔成交逐笔委托数据分享下载 通过Level2逐笔成交与逐笔委托的详细数据,这种以毫秒为单位的信息能揭示许多关键点,如庄家意图、误导性行为…...
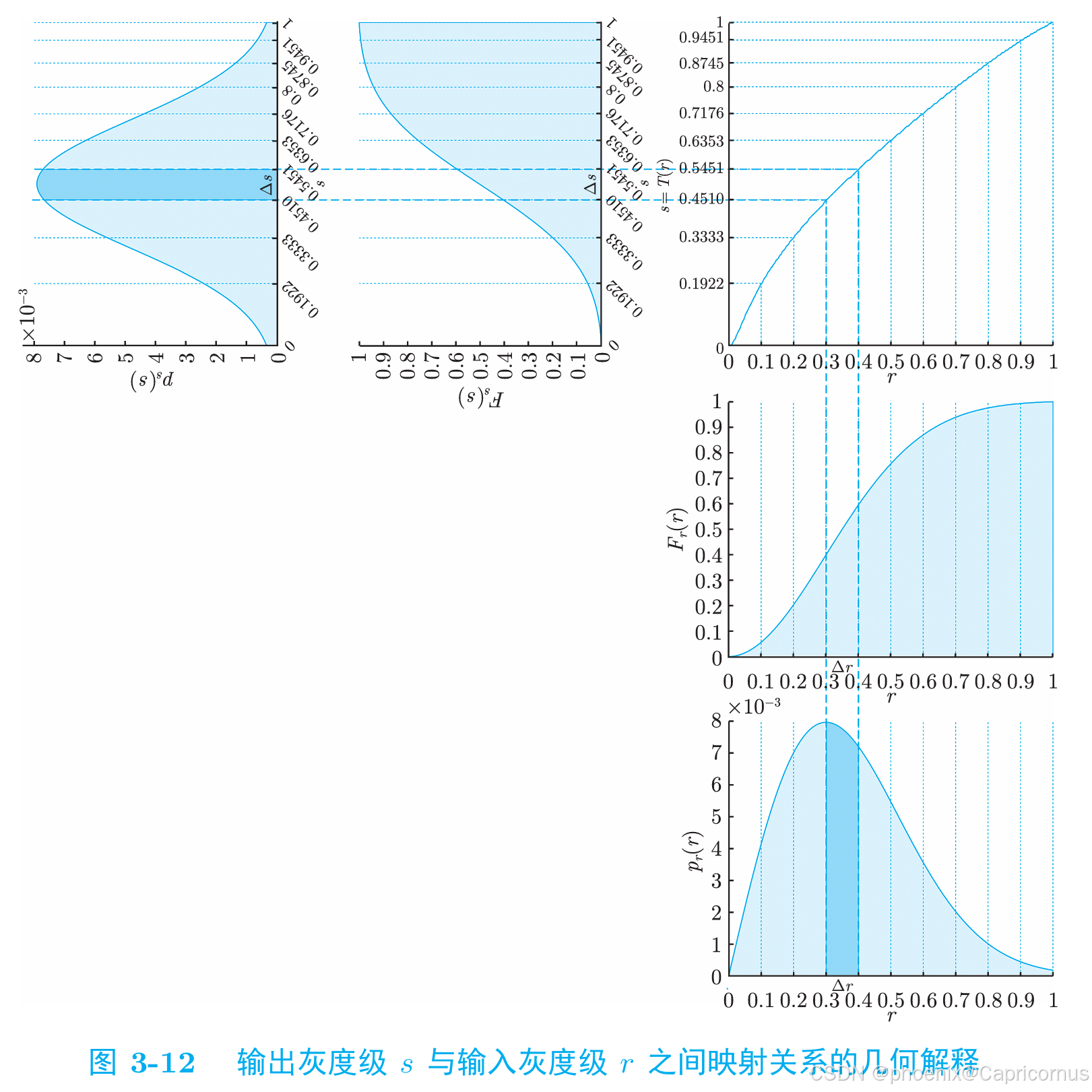
概率密度函数(PDF)分布函数(CDF)——直方图累积直方图——直方图规定化的数学基础
对于连续型随机变量,分布函数(Cumulative Distribution Function, CDF)是概率密度函数(Probability Density Function, PDF)的变上限积分,概率密度函数是分布函数的导函数。 如果我们有一个连续型随机变量…...
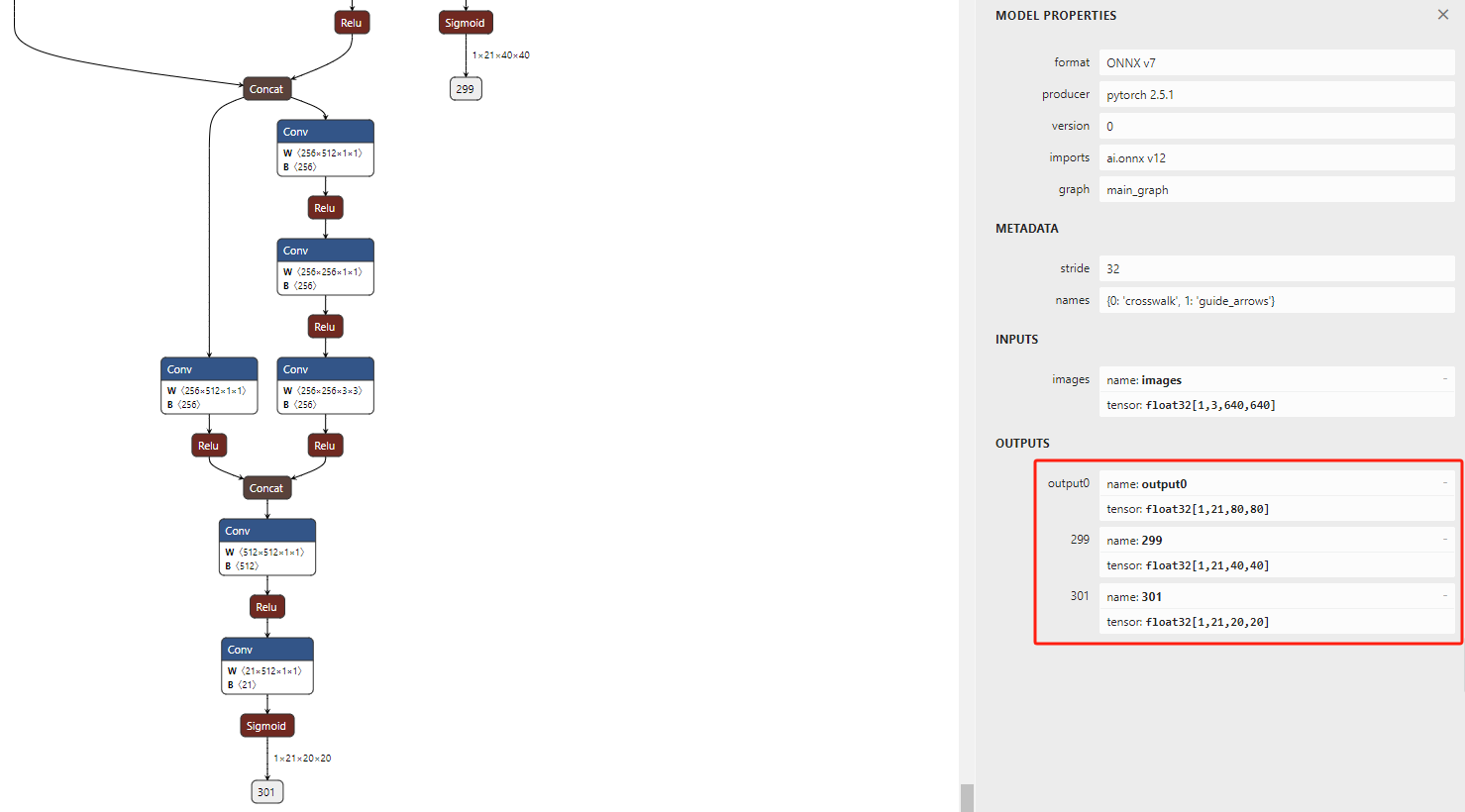
YOLOv5训练自己的数据及rknn部署
YOLOv5训练自己的数据及rknn部署 一、下载源码二、准备自己的数据集2.1 标注图像2.2 数据集结构 三、配置YOLOv5训练3.1 修改配置文件3.2 模型选择 四、训练五、测试六、部署6.1 pt转onnx6.2 onnx转rknn 七、常见错误7.1 训练过程中的错误7.1.1 cuda: out of memory7.1.2 train…...

计算机图形学:实验四 带纹理的OBJ文件读取和显示
一、程序功能设计 在程序中读取带纹理的obj文件,载入相应的纹理图片文件,将带纹理的模型显示在程序窗口中。实现带纹理的OBJ文件读取与显示功能,具体设计如下: OBJ文件解析与数据存储 通过实现TriMesh类中的readObj函数&#x…...

SQL Server 使用SELECT INTO实现表备份
在数据库管理过程中,有时我们需要对表进行备份,以防数据丢失或修改错误。在 SQL Server 中,可以使用 SELECT INTO 语句将数据从一个表备份到另一个表。 备份表的 SQL 语法: SELECT * INTO 【备份表名】 FROM 【要备份的表】 SEL…...
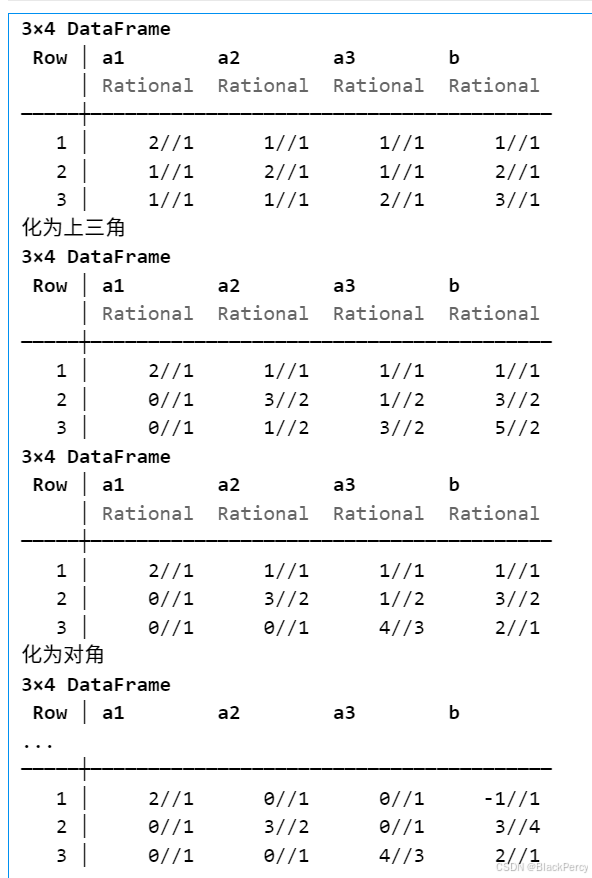
【线性代数】基础版本的高斯消元法
[精确算法] 高斯消元法求线性方程组 线性方程组 考虑线性方程组, 已知 A ∈ R n , n , b ∈ R n A\in \mathbb{R}^{n,n},b\in \mathbb{R}^n A∈Rn,n,b∈Rn, 求未知 x ∈ R n x\in \mathbb{R}^n x∈Rn A 1 , 1 x 1 A 1 , 2 x 2 ⋯ A 1 , n x n b 1…...

Python标准库 threading 的 start 和 join 的使用
python 的多线程机制可以的适用场景不适合与计算密集型的,因为 GIL 的存在,多线程在处理计算密集型时,实际上也是串行的,因为每个时刻只有一个线程可以获得 GIL,但是对于 IO 处理来说,不管是网络IO还是文件…...
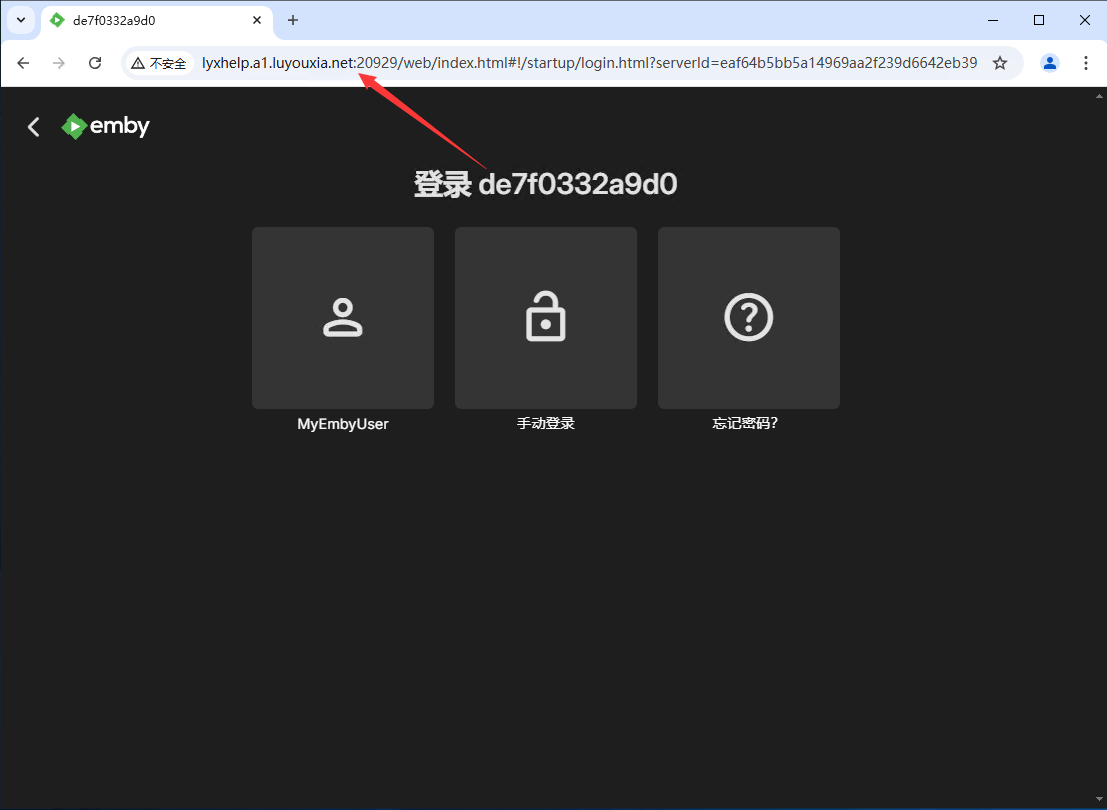
无公网IP 外网访问媒体服务器 Emby
Emby 是一款多媒体服务器软件,用户可以在 Emby 创建自己的个人多媒体娱乐中心,并且可以跨多个设备访问自己的媒体库。它允许用户管理传输自己的媒体内容,比如电影、电视节目、音乐和照片等。 本文将详细的介绍如何利用 Docker 在本地部署 Emb…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...

DeepSeek-R1代码补全实测报告:37个真实项目、8类编程语言、48小时压测后,我删掉了Copilot
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全实测报告总览 DeepSeek-R1 是深度求索(DeepSeek)推出的开源大语言模型,专为代码理解与生成任务优化。本章聚焦其在主流 IDE 环境中代码补全能力的…...