YOLOv5训练自己的数据及rknn部署
YOLOv5训练自己的数据及rknn部署
- 一、下载源码
- 二、准备自己的数据集
- 2.1 标注图像
- 2.2 数据集结构
- 三、配置YOLOv5训练
- 3.1 修改配置文件
- 3.2 模型选择
- 四、训练
- 五、测试
- 六、部署
- 6.1 pt转onnx
- 6.2 onnx转rknn
- 七、常见错误
- 7.1 训练过程中的错误
- 7.1.1 cuda: out of memory
- 7.1.2 train: No such file or directory train.cache
- 7.1.3 Expected object of scalar type __int64 but got scalar type float for sequence element 1.
- 7.1.4 __init__() got an unexpected keyword argument 'generator'
- 7.1.5 module 'torch.cuda.amp' has no attribute 'autocast'
- 7.2 部署过程中的错误
- 7.2.1 检测框越界/检测框不准
- 7.2.2 检测框非常多、非常小
一、下载源码
https://github.com/ultralytics/yolov5/releases
二、准备自己的数据集
2.1 标注图像
利用LabelImg标注:
https://github.com/HumanSignal/labelImg
2.2 数据集结构
按照如下结构放置标注好的数据:
/path/to/dataset/images/trainimage1.jpgimage2.jpg.../valimage1.jpgimage2.jpg.../labels/trainimage1.txtimage2.txt.../valimage1.txtimage2.txt...
三、配置YOLOv5训练
3.1 修改配置文件
在data文件夹中创建一个新的.yaml配置文件,例如my_dataset.yaml:
train: /path/to/dataset/images/train
val: /path/to/dataset/images/valnc: 2 # 类别数量
names: ['class1', 'class2'] # 类别名称
3.2 模型选择
在models文件夹中选择一个适合你任务的模型配置文件(例如yolov5s.yaml),可以根据需要进行调整,例如修改nc参数以匹配你的类别数量。
四、训练
一切准备就绪后,可以开始训练模型。运行以下命令:
python train.py --img 640 --batch 16 --epochs 50 --data data/my_dataset.yaml --weights yolov5s.pt --device cuda:0
参数解释:
--img 640指定训练时的图像尺寸为640x640。--batch 16指定每批次处理的图片数量为16。--epochs 50设置训练的轮数为50。--data data/my_dataset.yaml使用我们刚才配置的数据集文件。--cfg models/yolov5s.yaml使用YOLOv5s模型配置。--weights yolov5s.pt使用预训练权重。--device使用cuda还是cpu。
训练过程图:

五、测试
将best.pt和图像拷贝到detect.py同路径下,终端切换到该路径,输入:
python detect.py --weights best.pt --img 640 --source test2.jpg
按照终端显示的保存路径,查看效果。

六、部署
6.1 pt转onnx
将model/yolo.py的 Detect 类下的
def forward(self, x):z = [] # inference outputfor i in range(self.nl):if getattr(self, 'seg_seperate', False):c, s = self.m_replace[i](x[i])if getattr(self, 'export', False):z.append(c)z.append(s)continuebs, _, ny, nx = c.shapec = c.reshape(bs, self.na, -1, ny, nx)s = s.reshape(bs, self.na, -1, ny, nx)x[i] = torch.cat([c, s], 2).permute(0, 1, 3, 4, 2).contiguous()elif getattr(self, 'detect_seperate', False):z.append(torch.sigmoid(self.m[i](x[i])))continueelse:x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)if isinstance(self, Segment): # (boxes + masks)xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xywh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf.sigmoid(), mask), 4)else: # Detect (boxes only)xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, self.na * nx * ny, self.no))if getattr(self, 'export', False):return zreturn x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
修改为:
def forward(self, x):z = []for i in range(self.nl):x[i] = torch.sigmoid(self.m[i](x[i]))return x
将训练好的best.pt放在工程文件夹下,使用yolov5工程中的export.py将其转换为onnx模型。
python export.py --weights best.pt
生成onnx:

将生成的onnx文件导入netron(https://netron.app/)中,查看输出是否为3个分支。
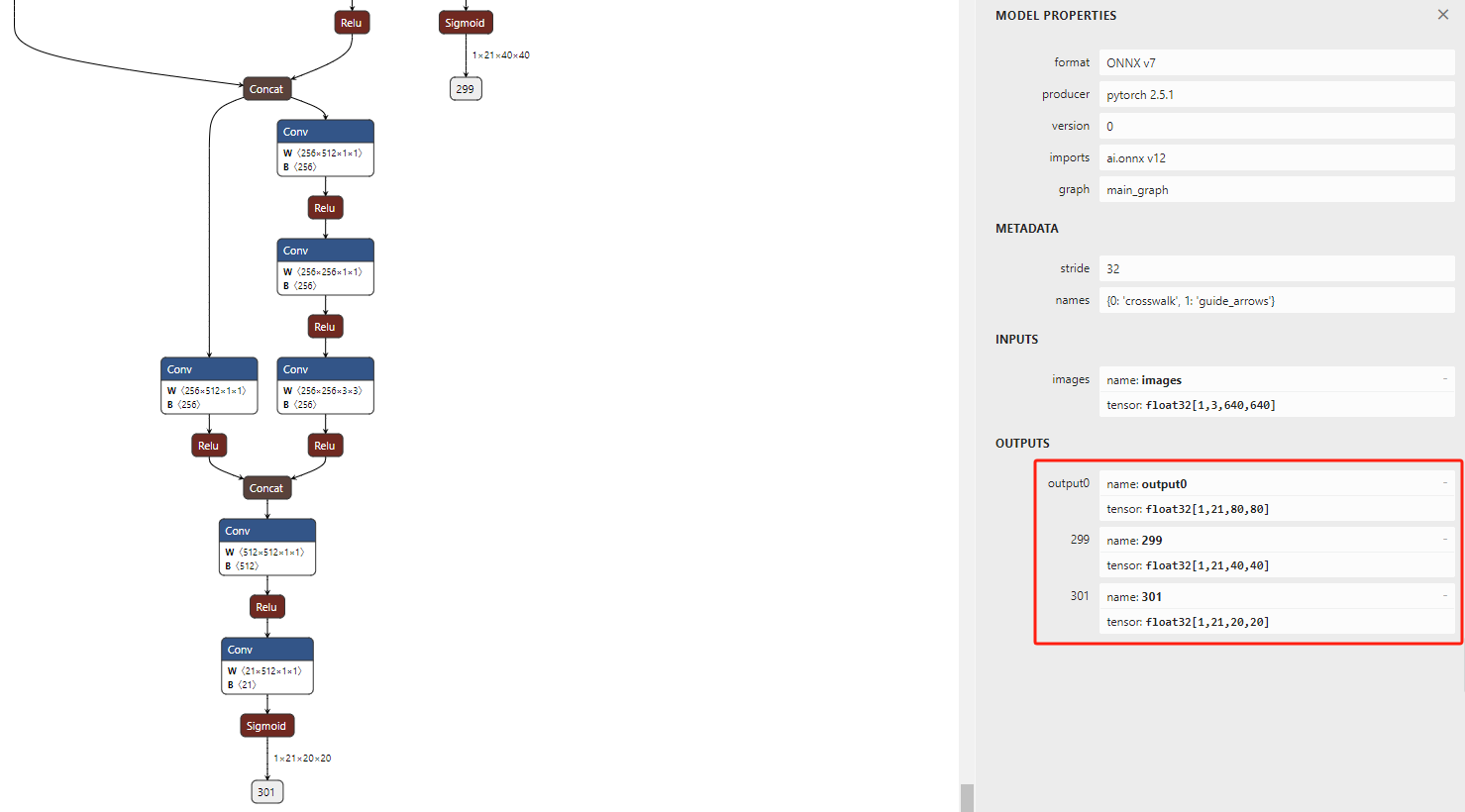
若是3个分支,表示onnx生成成功。
6.2 onnx转rknn
文件结构
/path/bus.jpg/datasets.txt/yolov5_convert.py/best.onnx
datasets的内容:
./bus.jpg
下载转换的程序:
https://github.com/airockchip/rknn-toolkit2/blob/master/rknn-toolkit2/examples/onnx/yolov5/test.py
结合自己的文件路径与类别,修改test.py后运行,便可得到rknn文件。
七、常见错误
7.1 训练过程中的错误
7.1.1 cuda: out of memory
说明内存不足,修改batch的数量,由16改为8或者更小的数。
7.1.2 train: No such file or directory train.cache
方法 1:使用--cache选项强制缓存
python train.py --img 640 --batch 16 --epochs 50 --data data/my_dataset.yaml --weights yolov5s.pt --device cuda:0 --cache
这样,YOLOv5会在数据加载时创建train.cache文件。
方法 2:手动创建缓存
通过运行YOLOv5的dataloaders.py中的create_dataloader函数来创建缓存文件。
python utils/dataloaders.py --data my_dataset.yaml --cache
7.1.3 Expected object of scalar type __int64 but got scalar type float for sequence element 1.
错误位置:
matches = torch.cat((torch.stack(x, 1).long(), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
错误原因:索引应该为整型,而不是浮点型,应该利用.long()转成int_64。
修改:
matches = torch.cat((torch.stack(x, 1).long(), iou[x[0], x[1]].long()[:, None]), 1).cpu().numpy()
7.1.4 init() got an unexpected keyword argument ‘generator’
该属性是1.6版本新增加的,所以升级pytorch1.6及以上。
7.1.5 module ‘torch.cuda.amp’ has no attribute ‘autocast’
该属性是1.6版本新增加的,所以升级pytorch1.6及以上。
7.2 部署过程中的错误
7.2.1 检测框越界/检测框不准
在train.py中,noaotoanchor的默认为False,如果设定为True,则会使用默认的anchor设定。
所以,如果经过autoanchor,给出了新的anchor设定,那么在推理和转完rknn后的设定,都需要与之相匹配的anchor,而不是用默认的coco数据集的anchor。
默认的coco数据集anchor:
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],[59, 119], [116, 90], [156, 198], [373, 326]]
利用如下代码,查看自己数据集的anchor:
from models.experimental import attempt_loadmodel = attempt_load('best.pt') # 加载权重路径
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1]
print(m.anchor_grid)
在6.2小节的test.py:
yolov5_post_process函数中的anchors参数值,修改为自己数据集的anchors值。
7.2.2 检测框非常多、非常小
由于6.1小节中在修改forward方法时,为了避免置信度大于1,增加了sigmoid函数。所以在6.2小节中test.py的process方法里不应该再有sigmoid函数。不能两个方法都写sigmoid函数,要么forward方法里写sigmoid函数,要么process方法里写sigmoid函数。
相关文章:
YOLOv5训练自己的数据及rknn部署
YOLOv5训练自己的数据及rknn部署 一、下载源码二、准备自己的数据集2.1 标注图像2.2 数据集结构 三、配置YOLOv5训练3.1 修改配置文件3.2 模型选择 四、训练五、测试六、部署6.1 pt转onnx6.2 onnx转rknn 七、常见错误7.1 训练过程中的错误7.1.1 cuda: out of memory7.1.2 train…...

计算机图形学:实验四 带纹理的OBJ文件读取和显示
一、程序功能设计 在程序中读取带纹理的obj文件,载入相应的纹理图片文件,将带纹理的模型显示在程序窗口中。实现带纹理的OBJ文件读取与显示功能,具体设计如下: OBJ文件解析与数据存储 通过实现TriMesh类中的readObj函数&#x…...

SQL Server 使用SELECT INTO实现表备份
在数据库管理过程中,有时我们需要对表进行备份,以防数据丢失或修改错误。在 SQL Server 中,可以使用 SELECT INTO 语句将数据从一个表备份到另一个表。 备份表的 SQL 语法: SELECT * INTO 【备份表名】 FROM 【要备份的表】 SEL…...
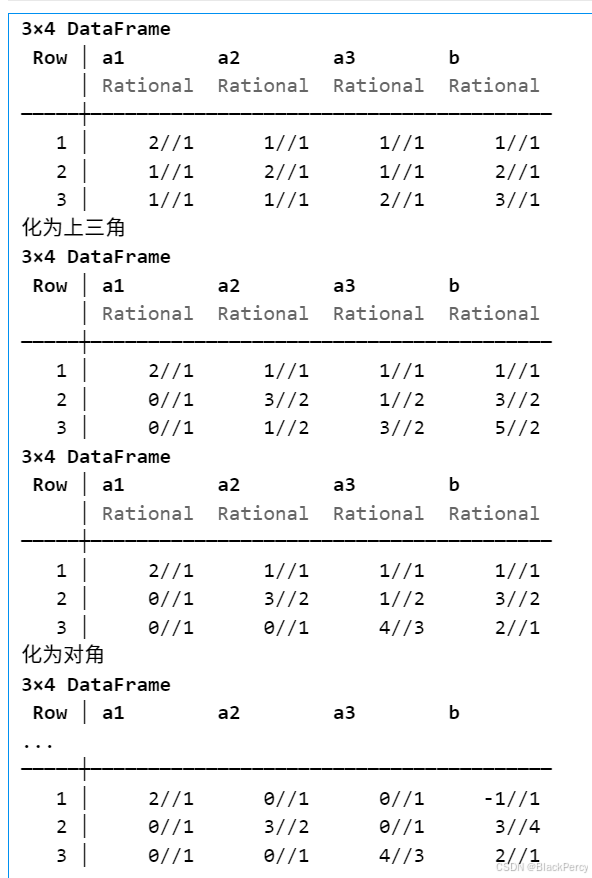
【线性代数】基础版本的高斯消元法
[精确算法] 高斯消元法求线性方程组 线性方程组 考虑线性方程组, 已知 A ∈ R n , n , b ∈ R n A\in \mathbb{R}^{n,n},b\in \mathbb{R}^n A∈Rn,n,b∈Rn, 求未知 x ∈ R n x\in \mathbb{R}^n x∈Rn A 1 , 1 x 1 A 1 , 2 x 2 ⋯ A 1 , n x n b 1…...

Python标准库 threading 的 start 和 join 的使用
python 的多线程机制可以的适用场景不适合与计算密集型的,因为 GIL 的存在,多线程在处理计算密集型时,实际上也是串行的,因为每个时刻只有一个线程可以获得 GIL,但是对于 IO 处理来说,不管是网络IO还是文件…...
无公网IP 外网访问媒体服务器 Emby
Emby 是一款多媒体服务器软件,用户可以在 Emby 创建自己的个人多媒体娱乐中心,并且可以跨多个设备访问自己的媒体库。它允许用户管理传输自己的媒体内容,比如电影、电视节目、音乐和照片等。 本文将详细的介绍如何利用 Docker 在本地部署 Emb…...
【数据结构】_顺序表
目录 1. 概念与结构 1.1 静态顺序表 1.2 动态顺序表 2. 动态顺序表实现 2.1 SeqList.h 2.2 SeqList.c 2.3 Test_SeqList.c 3. 顺序表性能分析 线性表是n个具有相同特性的数据元素的有限序列。 常见的线性表有:顺序表、链表、栈、队列、字符串等;…...

[MySQL]数据库表内容的增删查改操作大全
目录 一、增加表数据 1.全列插入与指定列插入 2.多行数据插入 3.更新与替换插入 二、查看表数据 1.全列查询与指定列查询 2.查询表达式字段 3.为查询结果起别名 4.结果去重 5.WHERE条件 6.结果排序 7.筛选分页结果 8.插入查询的结果 9.group by子句 三、修改表数…...

解决双系统引导问题:Ubuntu 启动时不显示 Windows 选项的处理方法
方法 1:检查 GRUB 引导菜单是否隐藏 启动进入 Ubuntu 系统。打开终端,输入以下命令编辑 GRUB 配置文件:sudo nano /etc/default/grub检查以下配置项: GRUB_TIMEOUT0:如果是 0,将其改为一个较大的值&#x…...
Java面试题2025-Spring
讲师:邓澎波 Spring面试专题 1.Spring应该很熟悉吧?来介绍下你的Spring的理解 1.1 Spring的发展历程 先介绍Spring是怎么来的,发展中有哪些核心的节点,当前的最新版本是什么等 通过上图可以比较清晰的看到Spring的各个时间版本对…...

CentOS7安装使用containerd
一,安装 1.1、安装containerd 下载 https://github.com/containerd/containerd/releases/download/v1.7.24/cri-containerd-cni-1.7.24-linux-amd64.tar.gz wget https://github.com/containerd/containerd/releases/download/v1.7.24/cri-containerd-cni-1.7.24-…...

Redis 集群模式入门
Redis 集群模式入门 一、简介 Redis 有三种集群模式:主从模式、Sentinel 哨兵模式、cluster 分片模式 主从复制(Master-Slave Replication): 在这种模式下,数据可以从一个 Redis 实例(主节点 Master)复…...

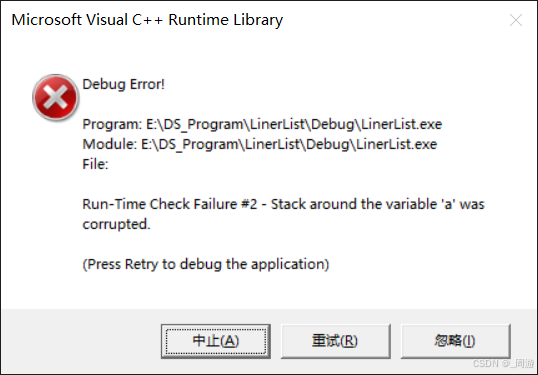
WinDBG查找C++句柄泄露
C代码(频繁点击About按钮导致Mutex句柄泄露) HANDLE _mutexHandle;LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam) {switch (message){case WM_COMMAND:{int wmId LOWORD(wParam);// 分析菜单选择:switch (wmId){c…...

Linux查看服务器的内外网地址
目录: 1、内网地址2、外网地址3、ping时显示地址与真实不一致 1、内网地址 ifconfig2、外网地址 curl ifconfig.me3、ping时显示地址与真实不一致 原因是dns缓存导致的,ping这种方法也是不准确的,有弊端不建议使用,只适用于测试…...

深入MapReduce——引入
引入 前面我们已经深入了HDFS的设计与实现,对于分布式系统也有了不错的理解。 但HDFS仅仅解决了海量数据存储和读写的问题。要想让数据产生价值,一定是需要从数据中挖掘出价值才行,这就需要我们拥有海量数据的计算处理能力。 下面我们还是…...

Oracle之开窗函数使用
Oracle中的开窗函数(Window Functions)是一种强大的工具,用于在SQL查询中对数据进行复杂的分析和聚合操作,而无需改变原始查询结果的行数或顺序。以下是关于Oracle开窗函数的使用方法和常见示例: 1. 开窗函数的基本语法…...
)
航空客户价值的数据挖掘与分析(numpy+pandas+matplotlib+scikit-learn)
文章目录 航空客户价值的数据挖掘与分析(numpy+pandas+matplotlib+scikit-learn)写在前面背景与挖掘目标1.1 需求背景1.2 挖掘目标1.3 项目概述项目分析方法规划2.1 RFM模型2.2 LRFMC模型指标2.3 分析总体流程图数据抽取探索及预处理3.1 数据抽取3.2 数据探索分析3.3 数据预处…...

云原生时代,如何构建高效分布式监控系统
文章目录 一.监控现状二.Thanos原理分析SidecarQuerierStoreCompactor 三.Sidecar or ReceiverThanos Receiver工作原理 四.分布式运维架构 一.监控现状 Prometheus是CNCF基金会管理的一个开源监控项目,由于其良好的架构设计和完善的生态,迅速成为了监控…...

什么是CIDR技术? 它是如何解决路由缩放问题的
什么是CIDR技术? 它是如何解决路由缩放问题的 一. 什么是 CIDR?二. CIDR 是如何工作的?1. 高效地址分配2. 路由聚合(Route Aggregation)3. 精确满足需求 三. CIDR 的计算详解1. 子网掩码计算2. 地址范围计算3. 可用 IP…...

Unity URP 获取/设置 Light-Indirect Multiplier
Unity URP 获取/设置 Light-Indirect Multiplier 他喵的代码的字段名称叫:bounceIntensity ~~~~~~...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...