Redis 集群模式入门
Redis 集群模式入门
一、简介
Redis 有三种集群模式:主从模式、Sentinel 哨兵模式、cluster 分片模式
主从复制(Master-Slave Replication):
- 在这种模式下,数据可以从一个 Redis 实例(主节点 Master)复制到一个或多个其他实例(从节点 Slave)。这可以用来提供冗余,以便在主节点失败时有一个备份,并且可以通过读取从节点来分担负载。
- 主从复制不是真正的集群配置,因为它没有内置的故障转移机制。为了实现自动故障转移,通常会与哨兵(Sentinel)系统结合使用。
哨兵模式(Sentinel):
- Redis Sentinel 系统提供了对 Redis 主从架构的监控、故障检测和自动故障恢复的能力。它由一个或多个 Sentinel 进程组成,这些进程会定期检查主从节点的健康状况。
- 如果主节点不可用,Sentinel 系统会选择一个健康的从节点来接管成为新的主节点,从而保证服务的持续性。
Redis Cluster(集群模式):
- Redis Cluster 是一种原生支持分布式部署的集群解决方案,它将数据分布到多个节点上,并提供了数据的自动分片(sharding)功能。
- 每个键值对都会根据哈希槽(hash slot)分配到集群中的某个节点。集群中至少需要三个主节点才能正确处理故障转移,因为每个主节点都有一个或多个从节点作为冗余。
- Redis Cluster 支持自动的分区(partitioning)、在线重新分片以及故障转移等特性。
二、主从模式
由于单节点的并发能力是有限的,如果要进一步提高Redis的并发能力,就需要新的架构方式,也就是主从模式,通过实现读写分离,将并发能力提升。
主从模式的定义:Redis的主从模式是一种数据备份和读写分离的模式,存在一个主节点,以及多个从节点。只有主节点可以执行写入数据的操作,而从节点只能进行读操作,而新写入的数据,主节点会复制到所有从节点,最终实现数据的同步。

2.1 主从工作原理
主从复制大致分为三个阶段:建立连接、数据同步、命令传播

2.1.1 建立连接、请求同步
-
从节点从
replicaof配置中获取主节点的IP和port建立连接。 -
连接成功之后,从节点会向主节点发送
PSYNC命令,请求同步数据,命令中包含了runID(主节点的实例ID) 和offset(复制进度) 两个参数。- runID:Redis 实例的唯一标识,主从复制进行时,该值为 Redis 主节点实例的ID,首次同步时,从节点不知道主节点的ID,所以为
?。 - offset:从节点数据同步的偏移量,第一次为
-1,表示全量复制。
- runID:Redis 实例的唯一标识,主从复制进行时,该值为 Redis 主节点实例的ID,首次同步时,从节点不知道主节点的ID,所以为
-
主节点收到
PSYNC命令后,会创建一个专门用于复制的后台线程replication thread,并记录从节点的offset参数,回复从节点FULLRESYNC命令,并携带主节点的runID和offset,从节点保存主节点信息,然后开始进行RDB 同步。
2.1.2 数据同步
-
主节点会执行
bgsave命令,fork出一个子进程遍历数据集生成一个RDB文件,将这个文件发送给从节点,这个过程也被称为全量复制。 -
在这个过程中,主节点的进程不会被阻塞,依旧可以对外提供服务,新写入的数据会保存在缓冲区中。
-
从节点接收到主节点
RDB文件后,会清空自身的数据,加载这个文件,替换为主节点的数据。
2.1.3 命令传播
- 在完成第一次全量复制之后,主从节点之间会建立TCP长连接,主节点会将缓冲区中新增的写入数据,发送给从节点,从而保证数据一致,这个过程也被称为命令传播
command propagation。 - 复制数据是异步的,通过记录主节点的写操作,主从节点的数据最终会保持一致。
增量同步
命令传播的过程中,由于网络原因,导致连接 TCP 断开,主节点数据就无法复制到从节点了,需要重新同步。在Redis 2.8 以前只有全量复制,如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大,从Redis 2.8 开始,支持增量同步,只会把网络断开的时候新写入的数据,同步给从节点。

增量同步过程:
- 网络恢复之后,从节点携带主节点的
runId以及从节点复制的offset,发送psync runId offset命令给主节点,请求数据同步。 - 主节点检查
runId和offset是否有效,如果有效则回复continue命令。 - 主节点发送断网期间新写入的命令,从节点接收并执行。
增量同步的关键:
- 主节点在执行写入操作时,会将命令记录在
repl_backlog_buffer(复制积压缓冲区) 中,并使用master_repl_offset记录位置偏移量。 - 从节点执行同步的写命令时,也会用
slave_repl_offset记录写入的位置偏移量,所以正常情况下,主从的位置偏移量会保持一致。 - 当网络断开时,主节点持续写入,从节点没有同步,所以从节点记录的位置偏移量就不会发生变化,两者就会不一致。

当网络恢复时,只需要将master_repl_offset 和 slave_repl_offset 之间的数据同步给从节点,但是由于repl_backlog_buffer 是一个环形缓冲区,大小为1M,断网时间太长,数据可能会发生覆盖,这样的话,就只能采取全量复制进行同步了,所以可以合理修改repl_backlog_buffer缓冲区的大小。
2.2 优缺点
2.2.1 优点
- 数据冗余与备份
- 从节点复制主节点的数据,提供数据冗余,避免单点故障导致的数据丢失。
- 从节点可以作为主节点的备份,在主节点故障时快速恢复数据。
- 读写分离
- 主节点负责写操作,从节点负责读操作,分担主节点的压力,提升系统整体性能。
- 适合读多写少的场景,显著提高系统的并发处理能力。
- 扩展读性能
- 可以通过增加从节点来扩展系统的读性能,适合需要高并发读取的场景。
- 数据同步简单
- Redis 主从复制的配置简单,只需在从节点配置主节点的地址即可实现数据同步。
2.2.2 缺点
- 主节点单点故障
- 主节点是唯一的写入口,如果主节点故障,写操作将无法进行,直到从节点被提升为主节点。
- 虽然可以通过哨兵模式实现自动故障转移,但在切换过程中仍会有短暂的不可用。
- 数据延迟
- 主从复制是异步的,从节点的数据可能会有一定延迟,不适合对数据一致性要求极高的场景。
- 如果网络延迟较大,数据同步的延迟会更明显。
- 写性能瓶颈
- 所有写操作都集中在主节点,主节点的性能决定了整个系统的写能力。
- 写操作无法通过增加从节点来扩展。
- 资源占用
- 每个从节点都需要存储完整的数据副本,占用额外的内存和磁盘空间。
- 如果从节点数量过多,主节点的网络带宽和资源消耗会显著增加。
- 数据一致性问题
- 由于主从复制是异步的,从节点的数据可能不是最新的,存在短暂的数据不一致问题。
- 如果主节点在数据未完全同步到从节点时崩溃,可能会导致数据丢失。
2.2.3 应用场景
适用场景:
-
读多写少的场景
- 主从模式适合读操作远多于写操作的场景,可以通过增加从节点来扩展读性能。
-
数据备份与容灾
- 主从模式提供数据冗余,适合需要数据备份和容灾的场景。
-
高可用性要求不高的场景
- 如果对高可用性要求不高,主从模式可以满足基本的数据复制需求。
不适用场景:
-
写多读少的场景
- 主从模式无法扩展写性能,写操作集中在主节点,容易成为性能瓶颈。
-
对数据一致性要求极高的场景
- 由于主从复制是异步的,可能存在数据延迟和不一致问题。
-
大规模分布式系统
- 主从模式不适合大规模分布式系统,推荐使用 Redis Cluster 或其他分布式方案。
2.3 主从模式实现
准备三台服务器,也可以通过不同的端口进行模拟三个redis服务
120.xx.xx.139 6379 # 主节点
121.xx.xx.19 6379 # 从节点
8.xx.xx.27 6379 # 从节点
2.3.1 修改 redis.conf 文件
配置主节点
# 1.允许所有ip访问
bind 127.0.0.1 -::1 修改为 bind 0.0.0.0
# 2.启用后台启动
daemonize on 修改为 daemonize yes
# 如果使用后台启动需要指定pid文件
pidfile /var/run/redis_6379.pid #如果以后台方式运行,我们需要指定一个pid文件
# 3.修改日志文件目录
logfile "" 修改为 logfile /usr/local/redis/logs/redis.log
# 4.修改数据目录
dir ./ 修改为 dir /data/redis
# 5.设置redis密码
requirepass redis212365
配置从节点
# 1.允许所有ip访问
bind 127.0.0.1 -::1 修改为 bind 0.0.0.0
# 2.启用后台启动
daemonize on 修改为 daemonize yes
# 如果使用后台启动需要指定pid文件
pidfile /var/run/redis_6379.pid #如果以后台方式运行,我们需要指定一个pid文件
# 3.修改日志文件目录
logfile "" 修改为 logfile /usr/local/redis/logs/redis.log
# 4.修改数据目录
dir ./ 修改为 dir /data/redis
# 5.设置redis密码
requirepass redis212365
# 6.配置主节点ip:port
replicaof 120.xx.xx.139 6379
# 7.配置主节点密码
masterauth redis213465
2.3.2 启动 redis 服务
启动/关闭redis 服务
# 启动服务 redis-sever 指定 redis.conf 启动redis 服务
[root@iZbp16njkri85nae48h9z9Z bin]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf# 停止服务 使用 redis-cli 客户端登录redis服务
[root@iZbp16njkri85nae48h9z9Z bin]# ./redis-cli -p 6379
# 验证密码
127.0.0.1:6379> auth redis213465
OK
# 停止服务
127.0.0.1:6379> shutdown
not connected> exit
客户端连接主节点
# 使用客户端登录redis
[root@linux-1 bin]# ./redis-cli -p 6379
# 输入redis.conf 保存的密码
127.0.0.1:6379> auth redis213465
OK
# 查询当前配置信息(当前无从节点连接)
127.0.0.1:6379> info replication
# Replication
role:master # 当前角色为主服务器
connected_slaves:0 # 连接的从节点数量
master_failover_state:no-failover # 故障转移状态
master_replid:f62d9c02c1a15a3cfc03a4a870de459f64889ceb # 主服务器ID
master_replid2:0000000000000000000000000000000000000000 #
master_repl_offset:0 # 主服务器复制偏移量, 主服务器发送给从服务器的数据量
second_repl_offset:-1 # 主服务器有多个复制流时会用到, -1 表示未使用
repl_backlog_active:0 # 表示复制积压缓冲区是否活跃。0意味着目前没有激活,即没有从服务器连接或所有从服务器都处于完全同步状态。
repl_backlog_size:1048576 # 复制积压缓冲区大小,单位是字节。它用于部分重同步操作,以保持一定量的历史复制数据。
repl_backlog_first_byte_offset:0 # 复制积压缓冲区第一个字节的偏移量
repl_backlog_histlen:0 # 复制积压缓冲区历史长度# 查询当前配置信息(从节点都已经连接)
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=121.xx.xx.19,port=6379,state=online,offset=2086,lag=0
slave1:ip=8.xx.xx.27,port=6379,state=online,offset=2086,lag=1
master_failover_state:no-failover
master_replid:77278f70f4ae7435ed1755b3ad69ede6cc70cb02
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2086
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2086
客户端连接从节点
# 使用客户端登录redis
[root@linux-1 bin]# ./redis-cli -p 6379
# 输入redis.conf 保存的密码
127.0.0.1:6379> auth redis213465
OK
# 查询当前配置
127.0.0.1:6379> info replication
# Replication
role:slave # 当前角色为从节点
master_host:120.xx.xx.139 # 主节点IP
master_port:6379 # 主节点端口
master_link_status:up # 主从连接状态为 up,表示从节点与主节点的连接正常
master_last_io_seconds_ago:5 # 上一次与主节点通信的时间是 5 秒前,表示主从之间的通信是正常的
master_sync_in_progress:0 # 当前没有正在进行的主从同步操作。值为 0 表示同步已完成
slave_read_repl_offset:168 # 从节点当前读取的复制偏移量
slave_repl_offset:168 # 从节点当前的复制偏移量
slave_priority:100 # 从节点的优先级是 100。在哨兵模式中,优先级较低的从节点更容易被提升为主节点
slave_read_only:1 # 从节点处于只读模式(1 表示只读),即从节点只能处理读请求,不能处理写请求
replica_announced:1 # 从节点已向主节点宣告自己的存在
connected_slaves:0 # 当前主节点没有连接其他从节点(因为当前实例是从节点)
master_failover_state:no-failover # 当前没有进行故障转移操作
master_replid:77278f70f4ae7435ed1755b3ad69ede6cc70cb02 # 主节点的复制 ID,用于标识主节点的复制流
master_replid2:0000000000000000000000000000000000000000 # 第二个复制 ID,通常用于故障转移后的旧主节点标识。当前值为空,表示没有发生过故障转移
master_repl_offset:168 # 主节点当前的复制偏移量是 168,表示主节点已经写入了 168 字节的数据
second_repl_offset:-1 # 第二个复制偏移量,通常用于故障转移后的旧主节点标识。当前值为 -1,表示没有发生过故障转移
repl_backlog_active:1 # 复制积压缓冲区已启用(1 表示启用)
repl_backlog_size:1048576 # 复制积压缓冲区的大小是 1048576 字节(即 1MB)
repl_backlog_first_byte_offset:1 # 复制积压缓冲区(Replication Backlog)的第一个字节偏移量是 1
repl_backlog_histlen:168 # 复制积压缓冲区的历史长度是 168 字节
2.3.3 测试
- 主节点写入数据、从节点读取数据
# 主节点写入数据
127.0.0.1:6379> set name jack
OK
127.0.0.1:6379> get name
"jack"# 从节点读取数据
127.0.0.1:6379> get name
"jack"
- 从节点无法写入数据
127.0.0.1:6379> set name marry
(error) READONLY You can't write against a read only replica.
三、哨兵模式
主从模式下,如果主节点发生了故障,会出现写入功能无法使用的问题,需要手动重启服务,或者指定新的主节点,这可能会出现数据不同步等诸多问题,所以便引入了哨兵模式,可以自动实现故障转移,选举出新的主节点,保证高可用。
哨兵模式:哨兵模式下,除了主节点和从节点,还有一个或多个哨兵节点(Sentinel)。哨兵节点的主要任务是监控主节点和从节点的运行状态,并在主节点发生故障时,自动将从节点提升为主节点。

3.1 哨兵模式原理
Redis的哨兵模式,就是在主从模式的基础上,额外部署若干独立的哨兵进程,通过哨兵进程去监视者Redis主从节点的状态,一旦发现主节点宕机,则哨兵可以重新从剩余slave节点中推选一个新的节点并将其升级为master节点,以此保证整个系统功能可以正常使用。
Sentinel主要负责三个方面的任务:
- 监控:通过发送命令,不间断的监控Redis服务器运行状态,包括主服务器和从服务器。
- 故障转移:当哨兵监测到主服务器宕机,会自动在已下线主服务器属下的所有从服务器里面,挑选出一个从服务器将其转换为主服务器(自动切换)。然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
- 通知:哨兵将选出的新主节点连接信息发给其他从节点,从节点和新主节点建立连接,执行
replicaof命令,复制数据。同时,哨兵会把新主节点的连接信息通知给客户端,让它们将操作请求发送给新主节点上。
3.1.1 监控
哨兵使用PING命令检测和主从节点的连接情况,用来判断实例状态。如果哨兵发现主节点或者从节点对PING命令响应超时,那么哨兵就会把它标记为"主观下线"。
- 从节点:哨兵可以将从节点简单标记为"主观下线",因为从库下线影响不大,集群对外服务不会中断。
- 主节点:哨兵不能简单标记为"主观下线",直接开启主从切换。因为可能存在一种情况:哨兵误判,主节点没有故障,可是一旦启动重新选主和通知操作都会带来额外的计算和通信开销。还可能产生脑裂。
确认主节点下线了,主节点才能被标记为客观下线。需要注意的是客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
3.1.1.1 少数服从多数机制
哨兵集群:以多实例组成的集群模式进行部署(至少三台以上),多个哨兵节点进行判断,可以避免单个哨兵因为网络等其他原因,对主节点进行误判,提高判断准确度。
当一个哨兵判断主节点为"主观下线"后就会向其它哨兵发起协商,其它哨兵就会根据自身与主节点的网络状况,做出赞成或拒绝投票的响应。如果大多数哨兵实例判断主节点已经"主观下线",主节点才会被标记"客观下线",即少数服从多数机制,当哨兵的赞同票数达到哨兵配置文件中的 quorum 配置项设定的值后,这时主节点就会被该哨兵标记为客观下线。
客观下线:N个哨兵实例,最好要有N/2+1个实例判断主库为"主观下线",才能判断为"客观下线"。
3.1.1.2 Leader哨兵选举
Redis哨兵(Sentinel)系统中,为了确保主从故障转移的准确性和可靠性,确实采用了一种基于多数表决的机制来决定是否需要进行故障转移,并由一个选举产生的Leader哨兵来执行这个操作。
选举过程:
- 如果大多数(quorum值定义的比例)的哨兵同意主节点处于下线状态,则主节点被标记为“客观下线”。
- 这时候,最初报告主节点下线的那个哨兵成为Leader候选者,尝试获取其他哨兵的支持票来进行领导权的争夺。
- 每个哨兵节点只能投一票,并且可以给自己投票,但只有作为Leader候选者的哨兵才能把票投给自己。
- 成为Leader的条件是获得超过半数的赞成票并且这些票数不低于配置文件中的quorum值。
哨兵集群配置建议:
- 为了确保Leader选举过程顺利并减少脑裂现象的发生,哨兵的数量应设置为奇数个。
- quorum参数应该设定为哨兵总数的一半加1,例如对于三个哨兵来说,quorum应设为2;五个哨兵则设为3。
3.1.2 故障转移
3.1.2.1 筛选条件
过滤网络状态不稳定的从节点
- 在线状态检查:首先排除所有当前处于下线状态的从节点。
- 历史网络连接质量评估:接下来,使用down-after-milliseconds * 10作为阈值来判断一个从节点在过去是否频繁地与主节点断开连接。具体来说,如果某个从节点在过去的尝试中,因为超过down-after-milliseconds毫秒没有收到主节点的消息而被标记为断连,并且这种情况发生了10次或更多,则认为该从节点的网络状况不稳定,不适合晋升为主节点。
3.1.2.2 打分机制
为了公平、合理地选择新主节点,采用多轮评分机制:
第一轮:优先级评分
- 每个从节点可以根据管理员设置的slave-priority配置项获得不同的优先级分数。这个配置允许管理员根据硬件性能、资源可用性等因素自定义每个从节点的重要性。
- 哨兵将优先考虑那些拥有最高优先级分数的从节点作为潜在的新主节点候选人。如果有多个从节点具有相同的最高优先级,则进入下一轮评分。
第二轮:复制进度评分
- 在这一轮中,哨兵会比较各候选从节点的slave_repl_offset(即从节点复制到的数据偏移量)与旧主节点的master_repl_offset。
- 复制进度最接近旧主节点的从节点得分最高,因为它最有可能包含最新的数据副本。如果两个或更多的从节点在这个标准上得分相同,则继续进行第三轮评分。
第三轮:ID号评分
- 当前两轮评分无法区分出最优选时,可以使用每个从节点唯一的ID号作为最后的评判标准。
- ID号较小的从节点将被选为新的主节点。这一步骤提供了一种确定性的方法来打破平局,同时保证了选择过程中的唯一性和一致性。
3.1.3 通知
3.1.3.1 将选举出的从节点升级为主节点
Leader哨兵成功选出一个合适的从节点作为新的主节点后,它会向该从节点发送 REPLICAOF NO ONE 命令。这条命令使得被选中的从节点停止复制任何其他节点,并开始接受客户端的写入请求,正式成为新的主节点。

3.1.3.2 将从节点指向新的主节点
Leader哨兵负责更新所有其他从节点的复制配置。它会向这些从节点发送 REPLICAOF <new-master-ip> <new-master-port> 命令,指示它们开始复制新主节点的数据。这一步确保了整个集群能够继续提供一致的服务。

3.1.3.3 通知客户端主节点已经更换
这主要通过 Redis 的发布者/订阅者机制来实现的。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息。
哨兵提供的消息订阅频道有很多,不同频道包含了主从节点切换过程中的不同关键事件,几个常见的事件如下:
| 事件 | 相关频道 |
|---|---|
| 主库下线事件 | +sdown (实例进入“主观下线”状态), -sdown (实例退出“主观下线”状态), +odown (实例进入“客观下线”状态), -odown (实例退出“客观下线”状态) |
| 从库重新配置事件 | +slave-reconf-sent (哨兵发送REPLICAOF命令重新配置从库), +slave-reconf-inprog (从库配置了新主库,但尚未进行同步), +slave-reconf-done (从库配置了新主库,且和新主库完成同步) |
| 新主库切换 | +switch-master (主库地址发生变化) |
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,Leader哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了。
3.1.3.4 将原主节点变为从节点,指向新的主节点
继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送 REPLICAOF <new-master-ip> <new-master-port> 命令,让它成为新主节点的从节点。

3.2 优缺点
3.2.1 优点
高可用性:
- 哨兵系统可以自动检测主节点的故障,并在必要时执行自动故障转移,选择一个健康的从节点作为新的主节点,从而确保服务的持续可用。
集中管理:
- 哨兵不仅监控主节点,还负责管理和监控所有从节点的状态,使得集群管理更加方便和统一。
灵活性:
- 用户可以通过配置文件自定义哨兵的行为,例如设置判定主节点是否下线的标准(
down-after-milliseconds)、投票所需的法定人数(quorum)等参数,以适应不同的应用场景需求。
客户端透明:
- 当发生故障转移时,哨兵会通过发布/订阅机制通知已订阅的客户端,使它们能够自动更新连接信息,继续与新的主节点交互,尽量减少对应用层的影响。
支持多数据中心部署:
- 可以在多个地理分布的数据中心中部署哨兵实例,提高系统的容灾能力。
3.2.2 缺点
复杂度增加:
- 引入哨兵增加了系统的复杂性,需要额外配置和维护哨兵节点,这对运维人员提出了更高的要求。
潜在的脑裂问题:
- 在某些极端情况下(如网络分区),可能会出现两个或更多的哨兵集群分别选举出不同节点为主节点的情况,导致数据不一致的问题。虽然哨兵设计中有防止这种情况发生的机制,但并非绝对安全。
性能开销:
- 哨兵本身也会消耗一定的资源用于心跳检查、通信以及日志记录等活动,在大规模集群环境中可能带来额外的性能负担。
延迟敏感的应用影响:
- 故障转移过程中的短暂服务中断和重新连接的时间窗口对于一些对延迟非常敏感的应用来说可能是不可接受的。
依赖哨兵健康状况:
- 如果哨兵自身出现问题(如哨兵集群中的多数哨兵节点失效),则无法正常执行其职责,进而影响到整个Redis集群的高可用性保障。
3.2.3 应用场景
适用场景
-
高可用性需求较高的系统
- 哨兵模式适合对服务连续性和数据一致性有严格要求的业务,如金融交易系统、在线支付平台。
- 哨兵的作用:自动监测主节点健康状况,并在故障时迅速切换到健康的从节点,确保服务持续可用。
-
需要自动化运维的环境
- 哨兵模式适用于云服务提供商或托管平台,包含大量独立运行的应用程序实例。
- 哨兵的作用:减少人工干预,通过自动化处理故障恢复,提高运维效率。
-
读多写少且对延迟敏感的系统
- 哨兵模式适合社交网络、电商平台商品详情页加载等以读操作为主但要求低响应时间的应用。
- 哨兵的作用:保持主从架构优点的同时,最小化因故障导致的服务中断风险。
-
跨数据中心部署
- 哨兵模式适用于跨国企业或大型互联网公司在全球范围内的多个数据中心。
- 哨兵的作用:在不同地理位置的数据中心间同步状态,并执行跨数据中心的故障转移,增强鲁棒性和灾难恢复能力。
-
中小规模分布式系统
- 哨兵模式适合希望通过主从复制提升读性能并拥有一定容错能力的应用,但尚未达到使用Redis Cluster复杂度的情况。
- 哨兵的作用:提供简单而有效的高可用性解决方案。
-
对客户端透明的故障恢复
- 哨兵模式适合移动应用后端、API网关等直接面向用户的组件。
- 哨兵的作用:发生故障转移时通知客户端更新连接信息,减少对用户的影响,保持用户体验的一致性。
不适用场景
-
大规模分布式系统
- 原因:管理多个哨兵实例可能变得复杂,推荐使用更复杂的分布式解决方案如Redis Cluster。
-
对延迟极其敏感的应用
- 原因:尽管哨兵减少了故障恢复的时间窗口,但在极端情况下(如网络分区),哨兵可能无法立即反应,影响即时可用性。
-
对数据一致性要求极高的场景
- 原因:哨兵模式下的数据复制是异步的,仍然存在数据延迟和潜在的不一致问题。对于强一致性的需求,哨兵模式可能不是最佳选择。
3.3 哨兵模式实现

3.3.1 哨兵模式配置
从redis解压的目录中复制一份
sentinel.conf配置文件
#服务监听地址,用于客户端连接,默认本机地址
bind 0.0.0.0
#是否已后台daemon方式启动
daemonize yes
#安全保护模式
protected-mode no
#哨兵端口
port 26379
#日志文件路径
logfile "/usr/local/redis/logs/sentinel.log"
#pid文件路径
pidfile /usr/local/redis/redis-sentinel.pid
#工作目录
dir "/data/redis/sentinel"
#设置要监控的master服务器,quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数。"这里的 mymaster" 是指定需要监听的主节点的自定义名称,但是由于很多默认设置项也是直接使用 "mymaster" 这个名称,所以如果修改的话,配置文件很多地方也需要修改。
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 120.xx.xx.139 6379 2#master设置了密码,连接master服务的密码
sentinel auth-pass mymaster 123456
自定义启动脚本
创建 redis-sentinel-start.sh 启动哨兵的脚本
#!/bin/bash# redis 相关参数
REDIS_BASE_DIR="/usr/local/redis"
REDIS_BIN="${REDIS_BASE_DIR}/bin"
CONF_FILE="${REDIS_BASE_DIR}/conf/sentinel.conf"
LOG_FILE="${REDIS_BASE_DIR}/logs/sentinel.log"
PID_FILE="${REDIS_BASE_DIR}/redis-sentinel.pid"# fun: log
log() {echo -e "\n$(date '+%Y-%m-%d %H:%M:%S') $1" >> ${LOG_FILE}
} # fun: start server
start_server() {echo "Starting Redis sentinel..."if ${REDIS_BIN}/redis-sentinel ${CONF_FILE} >> ${LOG_FILE} 2>&1; thenlog "Redis sentinel started successfully."return 0elselog "Failed to start Redis sentinel"return 1fi
}# fun: get pid
get_pid() {if [ -f "${PID_FILE}" ]; thencat ${PID_FILE}elselog "${PID_FILE} does not exist!"return 1fi
}# fun: main
main() {log "------------------- REDIS SENTINEL START --------------------"# chek redis_pid=$(get_pid)if [ $? -eq 0 ] && ps -p ${redis_pid} > /dev/null; thenlog "Redis sentinel status ===> [running]"log "If you want to stop it, please use the appropriate script to stop it first."elselog "Redis sentinel status ===> [stopped]"if ! start_server; thenlog "Failed to start Redis sentinel. Exiting..."exit 1fifi# 再次检查是否启动成功redis_pid=$(get_pid)if [ $? -eq 0 ]; thenlog "Redis sentinel pid is ${redis_pid}"elselog "Redis sentinel failed to start!"exit 1filog "------------------- REDIS SENTINEL START --------------------"
}main "$@"
自定义关闭脚本
创建 redis-sentinel-stop.sh 关闭哨兵的脚本
#! /bin/bash# redis相关参数
REDIS_BASE_DIR="/usr/local/redis"
REDIS_BIN="${REDIS_BASE_DIR}/bin"
LOG_FILE="${REDIS_BASE_DIR}/logs/sentinel.log"
PID_FILE="${REDIS_BASE_DIR}/redis-sentinel.pid"
PORT=26379# fun: log
log() {echo -e "\n$(date '+%Y-%m-%d %H:%M:%S') $1" >> ${LOG_FILE}
}# fun: stop server
stop_server() {echo "Stopping Redis sentinel..."if ${REDIS_BIN}/redis-cli -p ${PORT} shutdown >> ${LOG_FILE} 2>&1; thensleep 2log "Redis sentinel stopped successfully."return 0elselog "Failed to stop Redis sentinel."return 1fi
}# fun: get pid
get_pid() {if [ -f "${PID_FILE}" ]; thencat ${PID_FILE}elselog "${PID_FILE} does not exist!"return 1fi
}# fun: main
main() {log "------------------- REDIS SENTINEL STOP --------------------" # check redis_pid=$(get_pid)if [ $? -eq 0 ] && ps -p ${redis_pid} > /dev/null; thenlog "Redis sentinel status ===> [running]"stop_server || exit 1elselog "Redis sentinel status ===> [stopped]"log "No need to stop as Redis sentinel is not running."filog "------------------- REDIS SENTINEL STOP --------------------"
}main "$@"
3.3.2 哨兵模式启动
防火墙需要开放哨兵运行的端口,可以在单台服务器复制多个 sentinel.conf 配置文件以多个端口的方式启动多个哨兵,也可以多台服务器分别启动,但是如果多台服务器不在同一网段可能会出现哨兵之间无法通信的情况。
1.先启动三个redis服务,以一主二从的方式(自行查询主从模式的配置)
2.再启动三个哨兵
任意查看一个哨兵的日志文件,可以看到主库和两个从库都已经处于监控中,还有其他两个哨兵也被当前哨兵所监控。

手动下线一个哨兵,其他哨兵和它通信失败,会将它标记为主观下线的状态 +sdown

重新上线哨兵,其他哨兵和它通信成功,就会撤销它主观下线的状态 -sdown

查看哨兵的配置文件,可以看到其自动新增的从库地址,以及其他哨兵的地址

3.3.2 自动选举主库
- 手动下线主库
如果哨兵检测到主库下线了,会将其标记为主观下线,如果标记主观下线的哨兵数量达到了 quorum,那么哨兵Leader就会将主库标记为客观下线,那么就可以开始选举新的主库了。
选举出新的主库之后,就会修改所有节点的配置文件,以及所有哨兵的配置文件,指向新的主库节点,完成主库自动切换。

查看从库的配置文件以及哨兵的配置文件


- 上线旧的主库
旧的主库的配置文件中需要配置 masterauth “redis213465” 统一的主库访问密码,不然无法连接到新的主库。

旧主库作为新的从库上线

四、分片模式
哨兵模式下,虽然实现了自动故障转移,读写分离,但在高并发写操作时,还是存在单点性能瓶颈,写入操作始终是主节点执行的,从节点只能读,并且所有节点的数据都是一样的,数据冗余比较浪费内存空间,所以便引入了分片模式,可以允许多个节点写入数据,节点可以存放不同的数据,提高了写入的效率和内存空间的利用率。
**分片集群:**Redis 分片集群是一种通过将数据分散到多个节点上来提供更高性能、可伸缩性和高可用性的架构设计。它允许 Redis 数据库在多台物理或虚拟服务器之间进行水平扩展,从而显著提升系统的读写吞吐量和存储容量。

4.1 分片集群模式原理
分片集群最核心的功能是数据分片,节点通信、cluster meet(节点握手)、cluster addslots(槽分配)
Redis 通过哈希槽(hash slot)的机制实现分片集群,将数据集划分为 2^14(16384)个槽,编号通常是0~16383。分片集群中,存在多个节点(主从节点),每个节点负责存储一部分槽数据,节点之间通过Gossip 协议进行交互和通信。客户端发送命令到任意节点,集群会根据涉及的键的哈希值将命令路由到正确的槽上,由槽所属的节点处理命令,返回处理结果给客户端。
客户端交互流程:
- 客户端发送命令到分片集群的任意节点
- 节点根据键的哈希值计算槽号
- 确定槽号所属节点,路由到指定节点
- 该节点处理命令后,返回结果给客户端
动态调整:
- 加入新节点后,部分槽的数据会自动迁移至新节点,以平衡数据负载。
- 移除节点后,该节点上的槽会重新分配给其他节点,确保服务连续性。
4.1.1 数据分片
数据分片(Sharding)是分布式系统中用于扩展存储和处理能力的关键技术。通过将数据水平分割成多个更小的部分(即“分片”),并分布到不同节点上,可以有效提升系统的性能、可伸缩性和可靠性。哈希分片由于其天然的随机性,在实际应用中非常广泛。
哈希分片的核心思想是对数据的特征值(如键key)进行哈希运算,然后根据哈希值决定数据应该存储在哪个节点上。这种方法能够确保数据分布相对均匀,并且易于实现。衡量数据分片方法好坏的标准有很多,其中比较重要的两个因素是 (1) 数据分布是否均匀 (2)增加或删减节点对数据分布的影响。由于哈希的随机性,哈希分片基本可以保证数据分布均匀;因此在比较哈希分片方案时,重点要看增减节点对数据分布的影响。
(1) 哈希取余分片
计算key的哈希值,然后对节点数量取余,确定数据映射到哪个节点。实现简单,容易理解和部署。但当新增或删减节点时,所有数据都需要重新计算映射关系,导致大规模的数据迁移。对节点数量变化敏感,难以适应动态扩展的需求。
(2) 一致性哈希分片
将整个哈希空间组织成一个虚拟的圆环(通常范围为0至2^32-1)。每个数据项根据其key计算出的哈希值会落在环上的某个位置;从该位置沿环顺时针方向找到的第一个节点即为负责存储该数据项的节点。只有部分数据需要重新定位,减少了节点增减时的数据迁移量。支持动态添加或移除节点,提高了系统的灵活性和可扩展性。但是如果物理节点之间的间隔不均匀,可能会导致某些节点负载过重。

(3) 带虚拟节点的一致性哈希分片
在一致性哈希的基础上,为每个物理节点创建多个“虚拟节点”,这些虚拟节点均匀分布在哈希环上。当有新的键值对需要存储时,它会被分配给最邻近的虚拟节点所对应的物理节点。更加均匀地分布数据,减少因物理节点位置集中而导致的负载不均问题。进一步降低了节点增减时的数据迁移需求。但实现复杂度增加,需要管理更多的虚拟节点。

4.1.2 节点通信
在分布式集群环境中,节点之间的高效通信对于确保系统的稳定性和性能至关重要。每个节点不仅存储数据,还参与维护集群的整体状态。为实现这一目标,每个节点提供了两个TCP端口用于不同的通信目的。
端口定义
- 普通端口:例如7000,主要用于客户端服务以及节点间的数据迁移。
- 集群端口:为普通端口加10000(如7000对应的集群端口是17000),专门用于节点间的通信,如集群管理、故障转移等操作。防火墙配置时需同时开放这两个端口以保证正常工作。
Gossip协议
Gossip协议是一种去中心化的通信方式,适用于大规模网络环境。它通过节点间随机选择伙伴进行信息交换,最终使所有节点的状态达到一致。相比广播模式,Gossip协议减少了CPU和带宽消耗,并提高了系统的容错能力,尽管其收敛速度相对较慢。
消息类型与处理
集群中的节点每秒执行10次定时任务来决定是否发送消息及确定消息类型。根据集群状态的变化,节点之间会传递以下几种类型的消息:
- MEET消息:用于新节点加入集群的握手过程,由现有节点发送给新成员,后者回应PONG确认。
- PING/PONG消息:定期发送以维持节点间的联系并交换状态信息。PING消息采用Gossip协议发送,选择接收者时考虑了最近通信的时间间隔等因素,以平衡收敛速度和资源使用效率。
- FAIL消息:当一个主节点检测到另一个主节点失效时发出,通知其他节点更新其状态记录。
- PUBLISH消息:用于传播特定命令或事件至整个集群,各节点接收到后也会相应执行。
通过上述机制,集群能够快速响应拓扑变化、保持内部状态同步,并且即使在网络分区或其他异常情况下也能维持较高的可用性。
4.1.2 哈希槽
Redis 哈希槽是 Redis 集群中用于分片数据的一种机制。哈希槽的概念可以简单理解为一种数据分片的方式,将所有的数据分散存储在多个节点上,以实现数据的高可用和扩展性。
Redis 集群中共有 16384 个哈希槽,每个槽可以存储一个键值对。当有新的键值对需要存储时,Redis 使用一致性哈希算法将键映射到一个哈希槽中。每个 Redis 节点负责管理一部分哈希槽,节点之间通过 Gossip 协议来进行信息交换,以保证集群的一致性。
在 Redis 集群中,当一个节点宕机或者新增加一个节点时,哈希槽会重新分配。集群会自动将宕机节点上的槽重新分配给其他节点,并且保证每个节点分配的槽数尽量均等。这样可以保证数据的高可用性和负载均衡。

4.2 优缺点
Redis分片(Sharding)模式是将数据分散到多个Redis实例上的一种策略,以达到水平扩展的目的。每个Redis实例负责存储数据的一部分,这样可以有效地提升性能和增加可容纳的数据量。以下是Redis分片模式的优缺点:
4.2.1 优点
水平扩展:
- 分片模式可以将数据分布到多个 Redis 实例上,从而实现水平扩展,突破单机 Redis 的性能和存储限制。。
提高性能:
- 通过将数据分散到多个实例,分片模式可以显著提高 Redis 的并发处理能力和吞吐量。
资源隔离:
- 每个分片实例独立运行,资源(如 CPU、内存、网络带宽)相互隔离,避免单点资源竞争。
灵活性:
- 可以根据业务需求动态调整分片数量,灵活扩展或缩减集群规模。
4.2.2 缺点
复杂度增加:
- 实现和管理分片架构比单实例或主从复制更加复杂,包括配置分片逻辑、维护一致性以及处理故障恢复等。
数据迁移困难:
- 当需要调整分片数量时,如增加或减少分片,涉及到的数据迁移操作会变得复杂且耗时。
不一致性和部分失败的风险:
- 如果一个分片出现故障,可能会影响整个系统的可用性;而且,在跨分片操作中,如果其中一个分片失败,则可能导致事务的部分完成,造成数据不一致。
查询复杂性增加:
- 对于某些涉及多个分片的查询,应用程序必须知道如何组合来自不同分片的结果,这增加了开发难度。
缺乏内置的高可用性机制:
- Redis本身没有提供针对分片模式的自动故障转移功能,因此需要额外的组件(如哨兵或者集群模式)来保证高可用性。
4.2.3 应用场景
适用场景
-
大规模分布式系统
- 对于拥有海量数据和高并发访问要求的系统,分片模式能够有效缓解单个Redis实例的压力,提高整体性能。
-
对延迟敏感的应用
- 在确保合理分布负载的情况下,分片模式可以帮助降低响应时间,适合对延迟敏感的应用程序。
-
需水平扩展的场景
- 当预计未来会有大量增长并且希望避免垂直扩展带来的成本和复杂性时,分片是一个好的选择。
不适用场景
-
小规模应用
- 如果应用程序的数据量不大,并且预期不会有显著的增长,那么采用分片可能会引入不必要的复杂性。
-
对数据一致性有极高要求的场景
- 因为分片模式下的数据分布在多个节点上,所以在跨分片进行事务处理时,很难保证强一致性。
4.3 分片模式实现
| IP | 端口 | 节点 |
|---|---|---|
| 8.x.x.27 | 9001,9002,9003 | node1 |
| 121.x.x.19 | 9001,9002,9003 | node2 |
| 120.x.x.139 | 9001,9002,9003 | node3 |
4.3.1 分片配置
复制redis.conf 文件
# 复制redis.conf 文件
[root@iZbp1dfulgjy4kd3ev4y7bZ conf]# cp /usr/local/redis-6.2.12/redis.conf /usr/local/redis/conf/cluster/redis_cluster_9001.conf
[root@iZbp1dfulgjy4kd3ev4y7bZ conf]# cp /usr/local/redis-6.2.12/redis.conf /usr/local/redis/conf/cluster/redis_cluster_9002.conf
[root@iZbp1dfulgjy4kd3ev4y7bZ conf]# cp /usr/local/redis-6.2.12/redis.conf /usr/local/redis/conf/cluster/redis_cluster_9003.conf
修改 redis_cluster.conf 文件
每个节点的配置文件都需要修改
redis_cluster_9001.conf。
[root@iZbp1dfulgjy4kd3ev4y7bZ cluster]# vim redis_cluster_9001.conf
bind 0.0.0.0
port 9001
daemonize yes
pidfile "/usr/local/redis/pid/cluster_9001.pid"
logfile "/usr/local/redis/logs/cluster/cluster_9001.log"
dir "/data/redis/cluster_9001"
masterauth "redis213465"
requirepass "redis213465"
# 开启AOF
appendonly yes
# 开启集群模式
cluster-enabled yes
# 集群持久化配置文件,内容包含其它节点的状态信息等,会自动生成在上面配置的dir目录下
cluster-config-file nodes_9001.conf
cluster-node-timeout 15000
复制配置文件到另一台服务器下
# scp [源文件路径] [用户名]@[远程主机]:[目标路径]
[root@iZbp1dfulgjy4kd3ev4y7bZ cluster]# scp redis_cluster_*.conf root@121.x.x.19:/usr/local/redis/conf/cluster/
root@121.x.x.19's password:
redis_cluster_9001.conf 100% 92KB 47.4MB/s 00:00
redis_cluster_9002.conf 100% 92KB 56.8MB/s 00:00
redis_cluster_9003.conf 100% 92KB 63.8MB/s 00:00
4.3.2 启动服务
启动脚本
#!/bin/bash# redis 相关参数
REDIS_BASE_DIR="/usr/local/redis"
REDIS_BIN="${REDIS_BASE_DIR}/bin"
CONF_FILE="${REDIS_BASE_DIR}/conf/cluster/redis_cluster_9001.conf"
LOG_FILE="${REDIS_BASE_DIR}/logs/cluster/cluster_9001.log"
PID_FILE="${REDIS_BASE_DIR}/pid/cluster_9001.pid"# fun: log
log() {echo -e "\n$(date '+%Y-%m-%d %H:%M:%S') $1" >> ${LOG_FILE}
}# fun: start server
start_server() {echo "Starting Redis server..."if ${REDIS_BIN}/redis-server ${CONF_FILE} >> ${LOG_FILE} 2>&1; thenlog "Redis server started successfully."return 0elselog "Failed to start Redis server"return 1fi
}# fun: get pid
get_pid() {if [ -f "${PID_FILE}" ]; thencat ${PID_FILE}elselog "${PID_FILE} does not exist!"return 1fi
}# fun: main
main() {log "-------------------- REDIS SERVER START --------------------"# check redis_pid=$(get_pid)if [ $? -eq 0 ] && ps -p ${redis_pid} > /dev/null; thenlog "Redis server status ===> [running]"log "If you want to stop it, please use the appropriate script to stop it first."elselog "Redis server status ===> [stopped]"if ! start_server; thenlog "Failed to start Redis server. Exiting..."exit 1fifi# 再次检查是否启动成功redis_pid=$(get_pid)if [ $? -eq 0 ]; thenlog "Redis server pid is ${redis_pid}"elselog "Redis server failed to start!"exit 1filog "-------------------- REDIS SERVER START --------------------"
}main "$@"关闭脚本
#! /bin/bash# redis相关参数
REDIS_BASE_DIR="/usr/local/redis"
REDIS_BIN="${REDIS_BASE_DIR}/bin"
LOG_FILE="${REDIS_BASE_DIR}/logs/cluster/cluster_9001.log"
PID_FILE="${REDIS_BASE_DIR}/pid/cluster_9001.pid"
PASSWORD="redis213465"
PORT=9001# fun: log
log() {echo -e "\n$(date '+%Y-%m-%d %H:%M:%S') $1" >> ${LOG_FILE}
}# fun: stop server
stop_server() {echo "Stopping Redis ..."if ${REDIS_BIN}/redis-cli -p ${PORT} -a ${PASSWORD} shutdown >> ${LOG_FILE} 2>&1; thensleep 2log "Redis server stopped successfully."return 0elselog "Failed to stop Redis server"return 1fi
}# fun: get pid
get_pid() {if [ -f "${PID_FILE}" ]; thencat ${PID_FILE}elselog "${PID_FILE} does not exist!"return 1fi
}# fun: main
main() {log "------------------- REDIS SERVER STOP --------------------"# check redis_pid=$(get_pid)if [ $? -eq 0 ] && ps -p ${redis_pid} > /dev/null; thenlog "Redis server status ===> [running]"stop_server || exit 1elselog "Redis server status ===> [stopped]"log "No need to stop as Redis server is not running."filog "------------------- REDIS SERVER STOP --------------------"
}main "$@"
启动多个服务
[root@iZbp1dfulgjy4kd3ev4y7bZ redis-cluster]# ls
cluster-9001-start.sh cluster-9002-start.sh cluster-9003-start.sh
cluster-9001-stop.sh cluster-9002-stop.sh cluster-9003-stop.sh
[root@iZbp1dfulgjy4kd3ev4y7bZ redis-cluster]# ./cluster-9001-start.sh;./cluster-9002-start.sh;./cluster-9003-start.sh
Starting Redis server...
Starting Redis server...
Starting Redis server...
查看服务启动详情
[root@iZbp1dfulgjy4kd3ev4y7bZ redis-cluster]# netstat -tnlp | grep 'redis-server'

4.3.3 创建集群
创建3个主节点
[root@iZbp1dfulgjy4kd3ev4y7bZ bin]# ./redis-cli -a redis213465 --cluster create \
8.xx.xx.27:9001 8.xx.xx.27:9002 8.xx.xx.27:9003 \
121.xx.xx.19:9001 121.xx.xx.19:9002 121.xx.xx.19:9003 \
--cluster-replicas 1# –cluster-replicas 1 : 表示集群的一个主节点有1个从节点,就是一主一从模式


Tip
分片模式至少需要分配3个主节点

查看任意的集群配置文件 node_9001.conf
[root@iZbp1dfulgjy4kd3ev4y7bZ cluster_9001]# cat nodes_9001.conf
a43fec7e661d330e391fd1e9e4c5c3c1ecc69d88 8.xx.xx.27:9002@19002 master - 0 1737077951000 2 connected 10923-16383
42b21836567e2cc2e2ee9ccecb45b5633f267975 121.xx.xx.19:9001@19001 master - 0 1737077951221 4 connected 5461-10922
0cb940b84791c08f8263f7fc72ec00ac5c58e865 8.xx.xx.27:9003@19003 slave 42b21836567e2cc2e2ee9ccecb45b5633f267975 0 1737077952224 4 connected
226462840492a5ade58a03851ad371bb502aedfa 121.xx.xx.19:9003@19003 slave 799f56ec974684bdb035193db2505ee7b6af661f 0 1737077950216 1 connected
5bc57f420f41ddb41e80400d22b935be985cd4e0 121.xx.xx.19:9002@19002 slave a43fec7e661d330e391fd1e9e4c5c3c1ecc69d88 0 1737077949316 2 connected
799f56ec974684bdb035193db2505ee7b6af661f 172.xx.xx.91:9001@19001 myself,master - 0 1737077950000 1 connected 0-5460

以下是对每个参数的解释:
a43fec7e661d330e391fd1e9e4c5c3c1ecc69d88:这是节点的唯一标识符(ID),每个Redis集群中的节点都有一个唯一的ID。
8.xx.xx.27:9002@19001:这表示该节点的地址和端口。8.xx.xx.27是IP地址,9002是客户端连接的端口,而@19001后面的数字通常是集群总线端口号,用于节点间通信。
master 或 slave:这指明了节点的角色。master是主节点,可以接受写操作;slave是从节点,通常用于读取操作和数据冗余。
-:这个位置通常会显示其他信息,如故障标志等,此处为空意味着没有异常。
0:这是最后一次成功同步的时间戳(以毫秒为单位)。
1737077951000:这是最后的心跳时间(以毫秒为单位)。
2:这是配置纪元(configuration epoch),用来解决脑裂问题。
connected:表示节点之间的连接状态,这里显示的是“已连接”。
10923-16383:这表示该主节点负责的槽范围。Redis集群将键空间划分成16384个槽,每个主节点负责一部分槽。
最后一行中包含myself,表示这是当前节点自己在集群中的状态描述。
配置纪元(Configuration Epoch)是Redis集群中用于解决网络分区(也称为脑裂,split-brain)问题的一个机制。当集群经历网络分区时,可能会出现一部分节点无法与另一部分通信的情况。在这种情况下,每组节点可能会独立选举新的主节点,这可能导致数据不一致。
配置纪元的作用在于为每次配置更改分配一个唯一的递增数字。这个数字被用来确定哪个配置是最新的,从而帮助解决网络分区后重新合并时可能出现的数据一致性问题。
具体来说:
- 每个主节点都有自己的配置纪元。
- 当发生故障转移时,从节点会增加其配置纪元并尝试成为新的主节点。
- 如果多个从节点在同一时间试图晋升为主节点,它们的配置纪元将用来决定哪一个应该成功:具有较高配置纪元的节点通常会被选为新的主节点。
- 在网络分区恢复后,节点间交换信息以确定最新的配置纪元,并据此调整自己的角色和状态。
不同数量的配置纪元意味着不同的配置版本。如果一个节点有更高的配置纪元,那么它的配置就被认为是比较新的,其他节点应当根据这一情况更新自己持有的槽映射等信息。这种机制有助于确保在集群拓扑变化(如主从切换)之后,所有节点都能达成一致,维持集群的一致性和可用性。
4.3.4 登录集群
登录集群
[root@iZbp1dfulgjy4kd3ev4y7bZ bin]# ./redis-cli -p 9001
127.0.0.1:9001> auth redis213465
OK
127.0.0.1:9001> cluster info
cluster_state:ok # 表示集群的状态是正常的,所有槽都被正确分配,并且没有检测到任何问题。
cluster_slots_assigned:16384 # 总共16384个槽都已经分配给了集群中的主节点。
cluster_slots_ok:16384 # 所有已分配的槽都处于正常工作状态,没有报告任何问题
cluster_slots_pfail:0 # 部分故障(pfail)槽的数量
cluster_slots_fail:0 # 明确故障(fail)槽的数量
cluster_known_nodes:6 # 集群中已知的节点总数
cluster_size:3 # 集群中有多少个主节点
cluster_current_epoch:6 # 当前集群的配置纪元
cluster_my_epoch:1 # 当前节点自身的配置纪元
cluster_stats_messages_ping_sent:2322 # 发送的PING请求
cluster_stats_messages_pong_sent:2457 # 发送的PONG响应
cluster_stats_messages_sent:4779 # 总的发送
cluster_stats_messages_ping_received:2452 # 接收到的PING请求
cluster_stats_messages_pong_received:2322 # 接收到的PONG响应
cluster_stats_messages_meet_received:5 # 接收到的MEET消息,这是一种介绍新节点给现有节点的消息
cluster_stats_messages_received:4779 # 总的接收

查询集群节点信息
127.0.0.1:9001> cluster nodes
a43fec7e661d330e391fd1e9e4c5c3c1ecc69d88 8.xx.xx.27:9002@19002 master - 0 1737081206000 2 connected 10923-16383
42b21836567e2cc2e2ee9ccecb45b5633f267975 121.xx.xx.19:9001@19001 master - 0 1737081207263 4 connected 5461-10922
0cb940b84791c08f8263f7fc72ec00ac5c58e865 8.xx.xx.27:9003@19003 slave 42b21836567e2cc2e2ee9ccecb45b5633f267975 0 1737081206259 4 connected
226462840492a5ade58a03851ad371bb502aedfa 121.xx.xx.19:9003@19003 slave 799f56ec974684bdb035193db2505ee7b6af661f 0 1737081208267 1 connected
5bc57f420f41ddb41e80400d22b935be985cd4e0 121.xx.xx.19:9002@19002 slave a43fec7e661d330e391fd1e9e4c5c3c1ecc69d88 0 1737081207000 2 connected
799f56ec974684bdb035193db2505ee7b6af661f 172.16.69.91:9001@19001 myself,master - 0 1737081204000 1 connected 0-5460

4.3.5 增删节点
增加节点
# 添加节点
127.0.0.1:9001> cluster meet 120.xx.xx.139 9001
OK
# c
127.0.0.1:9001> cluster nodes

新加入的节点是以master 身份加入集群的,也可以将它的身份改为 slave
# 登录 120.xx.xx.139 9001 节点# 将 a43..d88 作为它的主节点
127.0.0.1:9001> cluster replicate a43fec7e661d330e391fd1e9e4c5c3c1ecc69d88
OK
127.0.0.1:9001> cluster nodes

节点身份变成了 slave,这里用的是内网IP
删除节点
127.0.0.1:9001> cluster forget d0f587497b5cd9fe2611cfefef7db7828a1b52c9
OK
127.0.0.1:9001> cluster nodes

Redis Cluster 使用 Gossip 协议来传播集群状态信息。当你在一个节点上执行 CLUSTER FORGET 命令时,该节点会忘记指定的节点。但是,其他节点仍然会通过 Gossip 协议将已删除的节点信息传播回来,导致节点重新加入集群。为了彻底删除节点,需要在 所有节点 上执行 cluster forget 命令,这样非常麻烦。
使用 redis-cli --cluster 命令可以更方便的删除节点
[root@iZbp1dfulgjy4kd3ev4y7bZ bin]# ./redis-cli -a redis213465 --cluster del-node 8.xx.xx.27:9001 d0f587497b5cd9fe2611cfefef7db7828a1b52c9
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node d0f587497b5cd9fe2611cfefef7db7828a1b52c9 from cluster 8.xx.x.27:9001
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
4.3.6 master 下线
模拟 master 下线,关闭 8.x.x.27:9003 这个主节点,过一会儿查看节点状态,可以看出,原来的slave 节点变成了 master 节点。

查看任意节点的日志

重新上线 原 master 节点,查看节点信息,发现它已经变成了 slave 节点

相关文章:
Redis 集群模式入门
Redis 集群模式入门 一、简介 Redis 有三种集群模式:主从模式、Sentinel 哨兵模式、cluster 分片模式 主从复制(Master-Slave Replication): 在这种模式下,数据可以从一个 Redis 实例(主节点 Master)复…...

WinDBG查找C++句柄泄露
C代码(频繁点击About按钮导致Mutex句柄泄露) HANDLE _mutexHandle;LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam) {switch (message){case WM_COMMAND:{int wmId LOWORD(wParam);// 分析菜单选择:switch (wmId){c…...

Linux查看服务器的内外网地址
目录: 1、内网地址2、外网地址3、ping时显示地址与真实不一致 1、内网地址 ifconfig2、外网地址 curl ifconfig.me3、ping时显示地址与真实不一致 原因是dns缓存导致的,ping这种方法也是不准确的,有弊端不建议使用,只适用于测试…...

深入MapReduce——引入
引入 前面我们已经深入了HDFS的设计与实现,对于分布式系统也有了不错的理解。 但HDFS仅仅解决了海量数据存储和读写的问题。要想让数据产生价值,一定是需要从数据中挖掘出价值才行,这就需要我们拥有海量数据的计算处理能力。 下面我们还是…...

Oracle之开窗函数使用
Oracle中的开窗函数(Window Functions)是一种强大的工具,用于在SQL查询中对数据进行复杂的分析和聚合操作,而无需改变原始查询结果的行数或顺序。以下是关于Oracle开窗函数的使用方法和常见示例: 1. 开窗函数的基本语法…...
)
航空客户价值的数据挖掘与分析(numpy+pandas+matplotlib+scikit-learn)
文章目录 航空客户价值的数据挖掘与分析(numpy+pandas+matplotlib+scikit-learn)写在前面背景与挖掘目标1.1 需求背景1.2 挖掘目标1.3 项目概述项目分析方法规划2.1 RFM模型2.2 LRFMC模型指标2.3 分析总体流程图数据抽取探索及预处理3.1 数据抽取3.2 数据探索分析3.3 数据预处…...

云原生时代,如何构建高效分布式监控系统
文章目录 一.监控现状二.Thanos原理分析SidecarQuerierStoreCompactor 三.Sidecar or ReceiverThanos Receiver工作原理 四.分布式运维架构 一.监控现状 Prometheus是CNCF基金会管理的一个开源监控项目,由于其良好的架构设计和完善的生态,迅速成为了监控…...

什么是CIDR技术? 它是如何解决路由缩放问题的
什么是CIDR技术? 它是如何解决路由缩放问题的 一. 什么是 CIDR?二. CIDR 是如何工作的?1. 高效地址分配2. 路由聚合(Route Aggregation)3. 精确满足需求 三. CIDR 的计算详解1. 子网掩码计算2. 地址范围计算3. 可用 IP…...

Unity URP 获取/设置 Light-Indirect Multiplier
Unity URP 获取/设置 Light-Indirect Multiplier 他喵的代码的字段名称叫:bounceIntensity ~~~~~~...

用Python和Tkinter标准模块建立密码管理器
用Python和Tkinter标准模块建立密码管理器 创建一个简单的密码管理器应用程序,帮助用户存储和管理他们的密码。使用Python的tkinter模块来创建一个图形用户界面(GUI)。 本程序支持 添加、查看、搜索、复制、修改、删除 功能。 本程序使用 …...

PyQt5菜单加多页签实现
pyqt tabs标签_哔哩哔哩_bilibili 代码实现 # coding:utf-8 import sys from PyQt5.QtCore import Qt from PyQt5 import QtCore,QtWidgets from PyQt5.QtWidgets import QApplication,QWidget from QhTabs01 import Ui_Form from PyQt5.Qt import *class QhLiangHuaGUI(QWidg…...

关注搜索引擎蜘蛛压力
以前在建站的时候,他们说蜘蛛来抓取的频率越多越好,因为蜘蛛来抓取说明了网站更新速度快,受搜索引擎的欢迎,但是在最近的网站统计中,发现很多蜘蛛爬取的频次非常的高,比如有的蜘蛛一天能来网站几万次&#…...

Python3 OS模块中的文件/目录方法说明三
一. 简介 前面文章简单学习了Python3中 OS模块中的文件/目录的部分函数。 本文继续来学习 OS模块中文件、目录的操作方法:os.fdopen()方法、os.fpathconf() 方法、os.fstat() 方法、os.fstatvfs() 方法。 二. Python3 OS模块中的文件/目录方法说明三 1. os.fdop…...

2024年终总结:技术成长与突破之路
文章目录 前言一、技术成长:菜鸟成长之路1. 学习与实践的结合2. 技术分享与社区交流 二、生活与事业的平衡:技术之外的思考1. 时间管理与效率提升2. 技术对生活的积极影响 三、突破与展望:未来之路1. 技术领域的突破2. 未来规划与目标 四、结…...

mysql-06.JDBC
目录 什么是JDBC: 为啥存在JDBC: JDBC工作原理: JDBC的优势: 下载mysql驱动包: 用java程序操作数据库 1.创建dataSource: 2.与服务端建立连接 3.构造sql语句 4.执行sql 5.关闭连接,释放资源 参考代码: 插…...

使用python调用JIRA6 进行OAuth1认证获取AccessToken
Jira配置应用程序链接 1) 创建应用程序链接 登录 JIRA 管理后台。转到 Administration > Applications > Application Links。在输入框中输入外部应用程序的 URL(例如 GitLab 或自定义应用),然后点击 Create new link。 2) 配置 Con…...

HTML5使用favicon.ico图标
目录 1. 使用favicon.ico图标 1. 使用favicon.ico图标 favicon.ico一般用于作为网站标志,它显示在浏览器的地址栏或者标签上 制作favicon图标 选择一个png转ico的在线网站,这里以https://www.bitbug.net/为例。上传图片,目标尺寸选择48x48&a…...

黑龙江锅包肉:酸甜香酥的东北经典
黑龙江锅包肉:酸甜香酥的东北经典 黑龙江锅包肉,作为东北菜的代表之一,尤其在黑龙江省哈尔滨市享有极高的声誉。这道美食不仅承载着丰富的历史文化内涵,更以其鲜明的地域特色,成为了黑龙江省乃至整个东北地区的标志性菜肴。 历史渊源 锅包肉的历史可以追溯到清朝光绪年间,其…...

Unity阿里云OpenAPI 获取 Token的C#【记录】
获取Token using UnityEngine; using System; using System.Text; using System.Linq; using Newtonsoft.Json.Linq; using System.Security.Cryptography; using UnityEngine.Networking; using System.Collections.Generic; using System.Globalization; using Cysharp.Thr…...
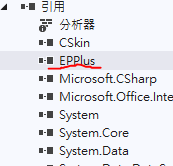
winfrom项目,引用EPPlus.dll实现将DataTable 中的数据保存到Excel文件
最近研究不安装office也可以保存Excel文件,在网上查询资料找到这个方法。 第一步:下载EPPlus.dll文件(自行去网上搜索下载) 第二步:引用到需要用的项目中,如图所示: 第三步:写代码…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

ZYNQ中断避坑指南:PL端信号线如何正确‘连线’到PS端处理函数?
ZYNQ中断系统深度解析:从硬件信号到软件响应的全链路实践 在嵌入式系统开发中,中断处理是实时响应的核心机制。对于ZYNQ这种集成了ARM处理器(PS)和可编程逻辑(PL)的异构计算平台,其中断系统既有传统处理器的特性,又具备FPGA灵活定…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...

PrediPrune:机器学习驱动的编译器超级优化候选剪枝策略
1. 项目概述与核心挑战在编译器优化的世界里,我们总在追求极致的性能。传统的编译器优化器,比如LLVM的Pass,依赖于一系列预定义的、经过验证的转换规则。它们很高效,但想象力也受限于这些规则。超级优化器(Superoptimi…...