《一文讲透》第4期:KWDB 数据库运维(6)—— 容灾与备份
一、KWDB 容灾
WAL 概述
KWDB 采用预写式日志(Write-Ahead Logging,WAL),记录每个时序表的模式变更和数据变更,以实现时序数据库的数据灾难恢复、时序数据的一致性和原子性。
KWDB 默认会将保存在 WAL 日志缓存中的日志条目实时写入日志文件,每5分钟通过后台线程更新 WAL 文件和数据文件的 CHECKPOINT_LSN (检查点日志序列号),写入 CHECKPOINT WAL 日志,然后同步数据文件到磁盘。
系统正常停机时,KWDB 会主动同步数据文件到磁盘并更新 CHECKPOINT_LSN。系统出现宕机时,KWDB 重启时会从最新的 CHECKPOINT_LSN 回放日志,以保证数据完整性。这种机制确保了即使在系统崩溃的情况下,也能通过重新执行日志中的操作来恢复数据库的一致性。
KWDB 支持对以下操作进行预写式日志记录:
| 参数 | 描述 |
|---|---|
| INSERT | 写入时序数据 |
| UPDATE | 更新时序数据 |
| DELETE | 删除时序数据 |
| CHECKPOINT | 检查点操作 |
| BEGIN | 开始迷你事务,即将多个步骤合并为一个,要么全部成功,要么全部失败的操作 |
| COMMIT | 结束迷你事务 |
| ROLLBACK | 回滚迷你事务 |
| TSBEGIN | 开始时序数据事务 |
| TSCOMMIT | 结束时序数据事务 |
| TSROLLBACK | 回滚时序数据事务 |
| DDL_CREATE | 创建时序表 |
| DDL_DROP | 删除时序表 |
| DDL_ALTER_COLUMN | 修改时序表schema |
WAL 日志文件由多个文件组成,称为 WAL 日志文件组。默认情况下,WAL 日志文件组包含三个大小相同的日志文件,每个文件的大小为 64MB。这些日志文件保存在时序表数据同级目录下的 wal 子目录中,文件以 kwdb_wal 的形式进行命名。系统初始时会使用 kwdb_wal0 作为活动日志文件。当前日志文件写满后,系统会按照顺序创建或使用下一个日志文件,直到日志文件组中的所有文件都被写满,之后系统会重新使用 kwdb_wal0 继续写入。
WAL 设置
KWDB 支持通过set cluster setting <parameter> = <value>SQL 语句来开启或关闭 WAL 日志功能、设置 WAL 日志同步周期、WAL 日志缓存大小、检查点周期,以及调整日志文件组的文件数量和每个日志文件的大小。
1、前提条件
用户为 admin 用户或 admin 用户的成员。
2、步骤
(1)根据需要开启或关闭 WAL日志功能,设置 WAL 日志同步周期。注意:实时写入 WAL 日志可能会显著影响数据写入速度。
SET CLUSTER SETTING ts.wal.flush_interval = <interval>;
默认值为0s,表示开启 WAL 日志功能,并且实时进行日志写入。设置值小于等于0时表示关闭 WAL 日志。设置值在0-200ms区间时,系统会实时写入 WAL 日志,设置值大于200ms时系统将根据实际设置值进行日志同步。
示例
SET CLUSTER SETTING ts.wal.flush_interval = 300 ms;
(2)根据需要设置 WAL 日志缓存大小。
SET CLUSTER SETTING ts.wal.buffer_size = <size>;
默认值为4 MiB,设置值应不小于4 MiB。
示例
SET CLUSTER SETTING ts.wal.buffer_size = 10 MiB;
(3) 根据需要设置 WAL 日志检查点周期。
SET CLUSTER SETTING ts.wal.checkpoint_interval = <interval>;
默认值为1分钟。建议在日常运行中设置大于1分钟的时间间隔。如果宕机恢复速度较慢,可以缩短此间隔,建议最小为1秒。
示例
SET CLUSTER SETTING ts.wal.checkpoint_interval = 10m;
(4)根据需要设置日志文件组的文件数量以及每个WAL日志文件的大小。
SET CLUSTER SETTING ts.wal.files_in_group = <number>;
SET CLUSTER SETTING ts.wal.file_size = <size>;
文件数量默认为3个,文件大小默认值为64MiB,建议将WAL日志文件组的总大小设置为数据库日增大小的1%~3%左右,可根据以下公式计算WAL日志文件使用的磁盘空间上限:
total_wal.file_size = ts.wal.file_size * ts.wal.files_in_group * table_number * replica_number / node_number
示例
SET CLUSTER SETTING ts.wal.files_in_group = 10;
SET CLUSTER SETTING ts.wal.file_size = 256 MiB;
KWDB 备份
KWDB 目前支持通过数据导入导出方式进行数据库库级别和表级别的数据备份
表级别数据导出
KWDB 支持使用 SQL 语句导出以下信息:
- 时序表或关系表的元数据及用户数据。元数据以 meta.sql 文件形式保存,用户数据以.csv 格式保存。
- 系统表数据:具体包括用户信息表、权限信息和集群配置表
导出过程中,如果目标位置不可达,系统会直接报错;如果因其他原因导致导出中断,系统会保留已成功导出的文件。
1、前提条件
- 用户拥有管理员权限。
- 如果要将数据导出到指定服务器,该服务器必须处于运行状态,可访问,且已开放 PUT 权限以支持文件上传。如果导出数据时需要创建文件夹以存放数据,用户还需要拥有在服务器上创建文件夹的权限。
2、SQL 语法
时序表和关系表的导出语法略有不同,时序表支持先筛选表数据范围后再导出,导出表数据时设置包围符、转义符和空值的表示形式,关系表暂不支持上述设置。
- 时序表筛选范围后导出
EXPORT INTO CSV "<expt_path>" FROM SELECT [ * | <column_list> ] FROM <table_name> [<where_clause>];
- 时序表导出
EXPORT INTO CSV "<expt_path>" FROM TABLE <table_name> WITH [ column_name | meta_only | data_only | delimiter = '<char>' | chunk_rows = '<number>' | enclosed = '<char>' | escaped = '<char>' | nullas = '<char>' ];
- 关系表导出
EXPORT INTO CSV "<expt_path>"
FROM TABLE <table_name>
WITH [ meta_only | data_only | delimiter = '<char>' | chunk_rows = '<number>' ];
- 用户信息表导出
EXPORT INTO CSV "<expt_path>" FROM TABLE system.users;
- 用户权限信息导出
EXPORT INTO CSV "<expt_path>" FROM SELELCT * FROM system.information_schema.table_privileges;
- 集群配置表导出
EXPORT INTO CSV "<expt_path>" FROM TABLE system.settings;
3、参数说明:
| 参数 | 描述 |
|---|---|
| expt_path | 导出文件的存放路径,支持nodelocal://<node_id>/<dir>和<server_ip>/<dir>两种格式。 一、nodelocal://<node_id>/<dir>:使用节点本地路径。 1、node_id:节点 ID,例如本地只有一个节点时,需要将 node_id 指定为1。 2、 dir:用户自定义的存放数据的文件夹名称。如果文件夹不存在,导出时系统会创建相应的文件夹,路径为用户安装 KWDB 时定义的 KWDB 数据存放路径,默认为/var/lib/kwdb/extern/<folder_name>。 -二、 <server_ip>/<dir>:使用服务器地址。 1、 server_ip:服务器 IP 地址和端口,例如http://172.18.0.1:80902、 dir:用户自定义的存放数据的文件夹名称。如果文件夹不存在,导出时系统会创建相应的文件夹。 |
| column_list | 用于指定需要导出的数据列和标签列,各列之间用逗号隔开。 |
| table_name | 需要导出数据的表名。 |
| where_clause | 可选参数,用于限制待导出的表数据范围,KWDB支持在where子句中使用以下运算符:1、比较运算符:>、 >=、<、<=、=和!= 2、 逻辑运算符:AND、OR和NOT 3、 模糊查询:LIKE,可以使用通配符%表示任意字符(包括空字符)出现任意次数,或者使用_通配符表示任意单个字符。注意:时间戳、数值和布尔类型的数据不支持模糊查询。 4、 NULL值判断:通过IS NULL或IS NOT NULL检查某列的值是否为NULL或不为NULL。 5、IN 运算符:用于匹配一组值中的任意一个 6、BETWEEN运算符:用于匹配某个范围内的值 |
| column_name | 可选参数,表示导出时添加列名,系统默认导出时不导出列名。 |
| meta_only | 可选参数,表示只导出元数据,不导出用户数据。该参数与data_only互斥。 |
| data_only | 可选参数,表示只导出用户数据,不导出元数据。该参数与meta_only互斥。 |
| delimiter | 可选参数,用于指定分隔符。系统将根据指定的分隔符读取表的用户数据或者将数据写入 CSV 文件。 分隔符支持指定单个字符或空字符,不支持双引号。 注意: - 分隔符应尽量避免与现有数据中的字符相同,如果数据中包含指定的分隔符,系统会默认增加包围符来避免导出错误。 - 如果在数据导出时指定了分隔符,在导入数据时需要使用相同的分隔符进行数据导入。导出与导入时定义的分隔符不一致可能会导致数据导入失败。 |
| chunk_rows | 可选参数,用于指定导出时单个 CSV 文件的行数。如果待导出数据的行数大于设定值,系统将根据设定值将待导出的表拆分成多个 CSV 文件,生成的文件按照<节点id>.<文件id>.csv的形式进行命名。 默认值和上限值为 100000 行,设置为0时,表示无行数限制。 |
| enclosed | 可选参数,用于指定导出时序数据时的包围符,默认为双引号,支持指定为单引号,包围符不能与分隔符相同。 注意:将包围符指定为单引号时,格式应为"‘",改回双引号时,格式应为’"'。 |
| escaped | 可选参数,用于指定导出时序数据时的转义符,默认为双引号,支持指定为反斜杠,转义符不能与分隔符相同。 |
| nullas | 可选参数,用于指定导出时序数据时空值的表示形式,默认不显示内容,支持指定为NULL、null、Null或\N。 |
4、示例
示例 1:将表的用户数据和元数据导出到本地节点
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table;result
-----------succeed
(1 row)
示例 2:将表的用户数据和元数据导出到指定服务器
EXPORT INTO CSV "http://172.18.10.1:8090/ts_table" FROM TABLE ts_table;
result
-----------
succeed
(1 row)
示例 3:筛选时序表指定时间段的指定列数据后导出数据
EXPORT INTO CSV "nodelocal://1/a" FROM SELECT ts, value, site_id FROM temperature WHERE ts > '2024-02-01 09:00:00';
result
-----------
succeed
(1 row)
示例 4:导出时序表的非空值数据
EXPORT INTO CSV "nodelocal://1/a" FROM SELECT * from temperature WHERE value IS NOT NULL;
result
-----------
succeed
(1 row)
示例 5:只导出表的用户数据
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH data_only;
result
-----------
succeed
(1 row)
示例 6:只导出表的元数据
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH meta_only;
result
-----------
succeed
(1 row)
示例 7:导出表数据时指定分隔符
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH DELIMITER = '/';
result
-----------
succeed
(1 row)
示例 8:导出表数据时指定分隔符时报错
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH DELIMITER = '"';
ERROR: delimiter can't be "
SQLSTATE: 22023
示例 9:导出表数据时限制单个文件行数
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH chunk_rows = '1000';
result
-----------
succeed
(1 row)
示例 10:导出时序表时指定包围符为单引号
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH enclosed = "'";
result
-----------
succeed
(1 row)
示例 11:导出时序表时指定转义符为反斜杠
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH escaped = '\';
result
-----------
succeed
(1 row)
示例 12:导出时序表时指定空值表现形式为 NULL
EXPORT INTO CSV "nodelocal://1/a" FROM TABLE ts_table WITH NULLAS = 'NULL';
result
-----------
succeed
(1 row)
表级别数据导入
用户可以将从其它 KWDB 数据库导出的时序表或关系表数据及元数据导入到另一个 KWDB 库中。目前不支持导入数据库的系统表数据。
KWDB 支持以下多种导入方式及导入数据选择。
-
同时导入表的用户数据和元数据
-
仅导入表的用户数据
-
仅导入表的元数据
如果目标表中已经存在用户数据时,KWDB 支持对表数据执行增量导入。
数据导入过程中,若出现失败,系统不会回滚导入操作,但会保留已成功导入的数据。时序数据导入报错后,系统通过系统显示写入失败的数据行数,同时将写入失败数据和错误信息记录到 reject 文件中,该文件位于导入数据文件的同级路径下。
提示: -
如果使用
sort -t <separator> -k <primary key column> <file_name>linux 命令提前对数据文件进行数据排序,可提升数据导入效率。 -
如果待导入数据使用 GBK 字符集,则导入前需要使用
SET client_encoding = 'GBK'将客户端字符集编码设置为 GBK。1、前提条件
-
用户拥有管理员权限。
-
待导入表的列数和数据类型与数据库现有表的列数和数据类型一致。
2、SQL 语法
时序表和关系表的导入语法略有不同,时序表支持导入表数据时设置包围符、转义符和空值的表示形式,关系表暂不支持上述设置。
- 时序表导入
- 全量导入用户数据和元数据,并根据指定的文件目录或表结构创建表:
IMPORT TABLE CREATE USING "<sql_path>" CSV DATA ("<file_path>") WITH [delimiter = '<char>' | enclosed = '<char>' | escaped = '<char>' | nullif = '<char>' | thread_concurrency = '<int>'| batch_rows = '<int>'| auto_shrink];
- 仅导入用户数据或增量导入:
IMPORT INTO <table_name> [<column_list>] CSV DATA ("<file_path>") WITH [delimiter = '<char>' | enclosed = '<char>' | escaped = '<char>' | nullif = '<char>' | thread_concurrency = '<int>'| batch_rows = '<int>'| auto_shrink];
- 仅导入元数据:
IMPORT TABLE CREATE USING "<sql_path>";
- 关系表导入
- 同时导入用户数据和元数据
IMPORT TABLE CREATE USING "<sql_path>" CSV DATA ("<file_path>") WITH DELIMITER = '<char>';
- 仅导入用户数据:
IMPORT INTO <table_name> CSV DATA ("<file_path>") WITH DELIMITER = '<char>';
- 仅导入元数据:
IMPORT TABLE CREATE USING "<sql_path>";
3、参数说明
| 参数 | 说明 |
|---|---|
| sql_path | 待导入的元数据文件路径。支持nodelocal://node_id/folder_name/file_name和server_ip/folder_name/file_name两种格式。 一、 nodelocal://node_id/folder_name/file_name:使用节点本地路径。 1)node_id:节点 ID,例如本地只有一个节点时将 node_id 指定为1。 2)folder_name:用户自定义的存放数据的文件夹名称,默认为/var/lib/kwdb/extern/<folder_name>。 3)file_name:待导入的元数据文件名称。二、server_ip/server_ip/folder_name/file_name:使用服务器地址。 1)server_ip:服务器 IP 地址和端口,例如http://172.18.0.1:8090 2)folder_name :用户自定义的存放数据的文件夹名称。 3)file_name:待导入的元数据文件名称。 |
| column_list | 可选参数,用于指定待导入的列。未指定列时,KaiwuDB 将按照源文件中列的顺序导入所有列的数据,指定列名时,可指定源文件的全部或部分数据列或标签列,顺序可与源文件定义的列顺序不同,指定列必须要包括第一列时间戳列和主标签列。 对于未指定列,如果该列支持 NULL 值,系统将自动写入默认值 NULL;如果该列不允许为空值,系统将提示·“Null value in column %s violates not-null constraints.”。 |
| file_path | 待导入的用户数据文件的路径,支持nodelocal://<node_id>/<folder_name>/<file_name>和<server_ip>/<dir>两种格式。一、 nodelocal://<node_id>/<folder_name>/<file_name>:使用节点本地路径。 - node_id:节点名称,只有一个数据库节点时,需要将 node_id 指定为1。 - folder_name:用户自定义的存放数据的文件夹名称,默认为 /var/lib/kwdb/extern/<folder_name>。 - file_name:待导入的文件的名称。 说明: 时序表导入时仅需指定到文件夹,无需指定待导入文件名,关系表导入需指定待导入文件。二、<server_ip>/<dir>:使用服务器地址。 - server_ip:服务器 IP 地址和端口,例如http://172.18.0.1:8090 - dir:用户自定义的存放数据的文件夹名称。 |
| delimiter | 可选参数,用于指定分隔符。系统根据指定的分隔符解析 CSV 文件并将解析后的内容导入到 KaiwuDB 系统。 导入时指定的分隔符需要与 CSV 文件中使用的分隔符一致,否则可能会出现解析后列数不匹配的情况,从而导致数据导入失败。 |
| enclosed | 可选参数,用于导入时序数据时指定包围符,默认为双引号,支持指定为单引号,包围符不能与分隔符相同。 注意: 将包围符指定为单引号时,格式应为"‘",改回双引号时,格式应为’"'。 |
| escaped | 可选参数,用于导入时序数据时指定转义符,默认为双引号,支持指定为反斜杠,转义符不能与分隔符相同。 |
| nullif | 可选参数,用于导入时序数据时指定空值的表示形式,默认不显示内容,支持指定为NULL、null、Null或\N。 |
| thread_concurrency | 导入时序数据CSV文件时,并发读取和写入数据的数量,系统将按照设置值对导入的文件进行平均分割,并进行并发读取和写入。 默认值为1,设置值应大于0,小于等于系统核数的2倍,如果设置值大于核数的2倍,系统将按照核数的2倍执行。 thread_concurrency可与batch_rows、auto_shrink共同使用,中间用逗号隔开。 |
| batch_rows | 并发导入时序数据时,每次读取的行数。 默认为500行,设置值应大于0,并满足以下公式要求:batch_rows * 单行数据的大小 ≤4GB, 如果设置值*单行数据的大小 > 4GB, 系统将按照4GB所支持的最大行数执行。 batch_rows可与thread_concurrency、auto_shrink共同使用,中间用逗号隔开。 |
| auto_shrink | 可选参数,用于指定是否进行集群自适应衰减。 系统默认不进行自适应衰减,如果导入时设置了auto_shrink参数,集群将自动每10秒进行一次衰减。 auto_shrink可与batch_rows、thread_concurrency共同使用,中间用逗号隔开。 |
| table_name | 目标表名,表示将数据导入到数据库中的哪个表中。需要注意导入的数据列数和数据类型与数据库中现有表的列数及数据类型需要一致。 |
4、显示说明
| 参数 | 描述 |
|---|---|
| job_id | 导入任务ID。 |
| status | 任务状态。 |
| fraction_completed | 完成情况,取值范围为[0,1], 1表示已完成。 |
| rows | 导入行数 |
| abandon_row | 因去重未写入的行数 |
| reject_rows | 导入时写入出错的行数,转存到容错文件中。 |
5、示例
示例 1:导入本地节点的表用户数据和元数据
IMPORT TABLE CREATE USING "nodelocal://1/a/meta.sql" CSV DATA ("nodelocal://1/a");job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 2:导入指定服务器的表用户数据和元数据
IMPORT TABLE CREATE USING "http://172.18.0.1:8090/newdb/meta.sql" CSV DATA ("http://172.18.0.1:8090/newdb");job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 3:只导入表的用户数据
IMPORT INTO user_info1 CSV DATA ("nodelocal://1/a");job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 4:只导入表的元数据
IMPORT TABLE CREATE USING "nodelocal://1/a/meta.sql";job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 0 | 0 | 0
(1 row)
示例 5:只导入表用户数据时指定分隔符
IMPORT INTO user_info1 CSV DATA ("nodelocal://1/a") WITH DELIMITER = '/';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 6:只导入时序表用户数据时指定包围符为单引号
IMPORT INTO user_info1 CSV DATA ("nodelocal://1/a") WITH enclosed = "'";job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 7:只导入时序表用户数据时指定转义符为反斜杠
IMPORT INTO user_info1 CSV DATA ("nodelocal://1/a") WITH escaped = '\';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 8:只导入时序表用户数据时指定空值表现形式为 NULL
IMPORT INTO user_info1 CSV DATA ("nodelocal://1/a") WITH NULLIF = 'NULL';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例9:设置导入时序表的写入速率
IMPORT INTO user_info1 CSV DATA ("nodelocal://1/a") WITH thred_concurrency = '20', batch_rows = '200';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
库级别数据导出
支持一次性导出数据库中所有表的元数据及用户数据。导出的每张表是一个单独的目录。
时序数据库导出的表均位于 public 模式下,每张表是一个单独的目录,用于存放该表的用户数据(.csv 文件)。导出的时序数据库数据组织形式:
tsdb
|-- meta.sql
|-- public|-- t1|-- n1.0.csv|-- t2|-- n1.0.csv
关系数据库导出的表按其所在模式进行组织,每张表是一个单独的目录,用于存放该表的元数据信息(meta.sql)和用户数据(.csv 文件)。导出的关系库数据组织形式:
rdb
|-- meta.sql
|-- public|-- table1|-- meta.sql|-- n1.0.csv|-- table2|-- meta.sql|-- n1.0.csv
|-- schema1|-- meta.sql|-- table1|-- meta.sql|-- n1.0.csv
1、前提条件
- 用户拥有管理员权限。
2、SQL 语法
时序数据库和关系数据库的导出语法略有不同,时序数据库支持导出数据时设置包围符、转义符和空值的表示形式,关系数据库暂不支持上述设置。
如果数据使用 GBK 字符集,则导出时需要使用 SET client_encoding = 'GBK'将客户端字符集编码设置为 GBK。
- 时序数据库导出
EXPORT INTO CSV "<expt_path>" FROM DATABASE <db_name> WITH [ column_name | meta_only | data_only | delimiter = '<char>' | chunk_rows = '<number>' | enclosed = '<char>' | escaped = '<char>' | nullas = '<char>'];
- 关系数据库导出
EXPORT INTO CSV "<expt_path>" FROM DATABASE <db_name> WITH [ meta_only | data_only | delimiter = '<char>' | chunk_rows = '<number>'];
3、参数说明
| 参数 | 描述 |
|---|---|
| expt_path | 导出文件的存放路径,支nodelocal://<node_id>/<dir>和<server_ip>/<dir>两种格式。 一、nodelocal://<node_id>/<dir>:使用节点本地路径。 1)node_id:节点名称,只有一个数据库节点时,需要将 node_id指定为1。 2) dir:用户自定义的存放数据的文件夹名称。如果文件夹不存在,导出时系统会创建相应的文件夹,路径为用户安装KWDB时自定义的KWDB数据存放路径,默认为/var/lib/kwdb/extern/<folder_name>。二、<server_ip>/<dir>:使用服务器地址。 - server_ip:服务器 IP 地址和端口,例如http://172.18.0.1:8090 - dir:用户自定义的存放数据的文件夹名称。如果文件夹不存在,导出时系统会创建相应的文件夹。 |
| db_name | 需要导出数据的数据库名。 |
| column_name | 可选参数,表示导出时添加列名。系统默认导出时不导出列名。 |
| data_only | 可选参数,表示只导出用户数据,不导出元数据。该参数与meta_only互斥。 |
| meta_only | 可选参数,表示只导出元数据,不导出用户数据。该参数与data_only互斥。 |
| delimiter | 可选参数,用于指定分隔符。系统将根据指定的分隔符读取表的用户数据或者将数据写入 CSV 文件。 分隔符支持指定单个字符或空字符,不支持双引号。 注意: -分隔符应尽量避免与现有数据中的字符相同,否则数据导入时可能无法按分隔符正确解析字段而导致数据导入失败。 -如果在数据导出时指定了分隔符,在导入数据时需要使用相同的分隔符进行数据导入。导出与导入时定义的分隔符不一致可能会导致数据导入失败。 |
| chunk_rows | 可选参数,用于指定导出时单个 CSV 文件的行数。如果待导出数据的行数大于设定的行数,系统将根据设定值将文件拆分成多个 CSV 文件,生成的文件按照<分区id>.<文件id>.csv的形式进行命名。 默认值和上限值为 100000 行。设置为0时表示无行数限制。 |
| enclosed | 可选参数,用于导出时序数据时指定包围符,默认为双引号,支持指定为单引号,包围符不能与分隔符相同。 注意: 将包围符指定为单引号时,格式应为"‘",改回双引号时,格式应为’"'。 |
| escaped | 可选参数,用于导出时序数据时指定转义符,默认为双引号,支持指定为反斜杠,转义符不能与分隔符相同。 |
| nullas | 可选参数,用于导出时序数据时指定空值的表示形式,默认不显示内容,支持指定为NULL、null、Null或\N。 |
4、示例
示例 1:将时序数据库的用户数据和元数据导出到本地节点
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db;result
-----------succeed
(1 row)
示例 2:将关系数据库的用户数据和元数据导出到本地节点
EXPORT INTO CSV "nodelocal://1/rdb" FROM DATABASE rdb;
filename |rows|node_id|file_num
-------------------+----+-------+--------
TABLE rdb.public.t1|2 |1 |1
meta.sql |1 |1 |1
TABLE rdb.public.t2|2 |1 |1
meta.sql |1 |1 |1
(4 rows)
示例 3:将时序数据库的用户数据和元数据导出到指定服务器
EXPORT INTO CSV "http://172.18.10.1:8090/ts_db" FROM DATABASE ts_db;result
-----------succeed
(1 row)
示例 4:只导出数据库的用户数据
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH data_only;result
-----------succeed
(1 row)
示例 5:只导出数据库的元数据
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH meta_only;result
-----------succeed
(1 row)
示例 6:导出数据库时使用指定分隔符
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH DELIMITER = '/';result
-----------succeed
(1 row)
示例 7:导出数据库时限制单个 CSV 文件的行数
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH chunk_rows = '1000';result
-----------succeed
(1 row)
示例 8:导出时序数据库时指定包围符为单引号
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH enclosed = "'";result
-----------succeed
(1 row)
示例 9:导出时序数据库时指定转义符为反斜杠
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH escaped = '\';result
-----------succeed
(1 row)
示例 10:导出时序数据库时指定空值表现形式为 NULL
EXPORT INTO CSV "nodelocal://1/ts_db" FROM DATABASE ts_db WITH NULLAS = 'NULL';
result
-----------
succeed
(1 row)
库级别数据导入
用户可以将 KWDB 数据库中导出的所有表数据及元数据完整导入到另一个 KWDB 数据库中。目前支持同时导入元数据和表数据或者只导入元数据,不支持只导入所有表的用户数据。
在数据导入过程中,若出现失败,系统不会回滚导入操作,但会保留已经成功导入的数据。时序数据导入报错后,系统会将写入失败数据和错误信息记录到 reject 文件中,该文件位于导入数据文件的同级路径下。
1、前提条件
- 用户拥有管理员权限。
- 待导入数据的文件夹包含 CSV 和 SQL 文件。
2、SQL 语法
时序数据库和关系数据库的导入语法略有不同,时序数据库支持导入数据时设置包围符、转义符和空值的表示形式,关系数据库暂不支持上述设置。
如果待导入数据使用 GBK 字符集,则导入前需要使用SET client_encoding = 'GBK' 将客户端字符集编码设置为 GBK。
- 时序数据库导入:
IMPORT DATABASE CSV DATA ("<db_path>") WITH [ delimiter = '<char>' | enclosed = '<char>' | escaped = '<char>' | nullif = '<char>' | thread_concurrency = '<int>'| batch_rows = '<int>'| auto_shrink];
- 关系数据库导入:
IMPORT DATABASE CSV DATA ("<db_path>") [WITH DELIMITER = '<char>'];
3、参数说明:
| 参数 | 描述 |
|---|---|
| db_path | 待导入数据库的存放路径。支持 nodelocal://<node_id>/<dir>和<server_ip>/<dir>两种格式。 一、nodelocal://node_id/<folder_name>:使用节点本地路径。 1)node_id:节点名称,只有一个数据库节点时,需要将 node_id 指定为1。 2) dir:用户自定义的存放数据的文件夹名称,默认为/var/lib/kwdb/extern/<folder_name>。 二、 <server_ip>/<dir>:使用服务器地址。 1) server_ip:服务器 IP 地址和端口,例如 http://172.18.0.1:8090 2) dir:用户自定义的存放数据的文件夹名称。 |
| delimiter | 可选参数,用于指定分隔符。系统根据指定的分隔符解析 CSV 文件并将解析后的内容导入到 KWDB 系统。导入时指定的分隔符需要与 CSV 文件中使用的分隔符一致,否则可能会出现解析后列数不匹配的情况,从而导致数据导入失败。 |
| enclosed | 可选参数,用于导入时序数据时指定包围符,默认为双引号,支持指定为单引号,包围符不能与分隔符相同。 注意: 将包围符指定为单引号时,格式应为"‘",改回双引号时,格式应为’"'。 |
| escaped | 可选参数,用于导入时序数据时指定转义符,默认为双引号,支持指定为反斜杠,转义符不能与分隔符相同。 |
| nullif | 可选参数,用于导入时序数据时指定空值的表示形式,默认不显示内容,支持指定为 NULL、null、Null或\N。 |
| thread_concurrency | 导入时序数据 CSV 文件时,并发读取和写入数据的数量,系统将按照设置值对导入的文件进行平均分割,并进行并发读取和写入。 默认值为1,设置值应大于0,小于等于系统核数的2倍,如果设置值大于核数的2倍,系统将按照核数的2倍执行。 thread_concurrency 可与 batch_rows、auto_shrink 共同使用,中间用逗号隔开。 |
| batch_rows | 并发导入时序数据时,每次读取的行数。 默认为500行,设置值应大于0,并满足以下公式要求:batch_rows * 单行数据的大小 ≤4GB, 如果设置值*单行数据的大小 > 4GB, 系统将按照4GB所支持的最大行数执行。 batch_rows 可与 thread_concurrency、auto_shrink 共同使用,中间用逗号隔开。 |
| auto_shrink | 可选参数,用于指定是否需要进行集群自适应衰减。 系统默认不进行自适应衰减,如果导入时设置了auto_shrink参数,集群将自动每10秒进行一次衰减。 auto_shrink 可与 batch_rows、thread_concurrency 共同使用,中间用逗号隔开。 |
4、示例
示例 1:导入本地数据库
IMPORT DATABASE CSV DATA ("nodelocal://1/db");job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 2:导入指定服务器的数据库
IMPORT DATABASE CSV DATA ("http://172.18.0.1:8090/newdb");job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 3:导入数据库时指定分隔符
IMPORT DATABASE CSV DATA ("nodelocal://1/db") WITH DELIMITER = '/';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 4:导入时序数据库时指定包围符为单引号
IMPORT DATABASE CSV DATA ("nodelocal://1/db") WITH enclosed = "'";job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 5:导入时序数据库时指定转义符为反斜杠
IMPORT DATABASE CSV DATA ("nodelocal://1/db") WITH escaped ='\';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
示例 6:导入时序数据库时指定空值表现形式为 NULL
IMPORT DATABASE CSV DATA ("nodelocal://1/db") WITH NULLIF = 'NULL';job_id | status | fraction_completed | rows | abandon_rows | reject_rows
---------------------+-----------+--------------------+------+--------------+--------------/ | succeeded | 1 | 1 | / | /
(1 row)
相关文章:
—— 容灾与备份)
《一文讲透》第4期:KWDB 数据库运维(6)—— 容灾与备份
一、KWDB 容灾 WAL 概述 KWDB 采用预写式日志(Write-Ahead Logging,WAL),记录每个时序表的模式变更和数据变更,以实现时序数据库的数据灾难恢复、时序数据的一致性和原子性。 KWDB 默认会将保存在 WAL 日志缓存中的…...
ArcGIS10.2 许可License点击始终启动无响应的解决办法及正常启动的前提
1、问题描述 在ArcGIS License Administrator中,手动点击“启动”无响应;且在计算机管理-服务中,无ArcGIS License 或者License的启动、停止、禁止等均为灰色,无法操作。 2、解决方法 ①通过cmd对service.txt进行手动服务的启动…...

Level2逐笔成交逐笔委托毫秒记录:今日分享优质股票数据20250124
逐笔成交逐笔委托下载 链接: https://pan.baidu.com/s/1UWVY11Q1IOfME9itDN5aZA?pwdhgeg 提取码: hgeg Level2逐笔成交逐笔委托数据分享下载 通过Level2逐笔成交与逐笔委托的详细数据,这种以毫秒为单位的信息能揭示许多关键点,如庄家意图、误导性行为…...
概率密度函数(PDF)分布函数(CDF)——直方图累积直方图——直方图规定化的数学基础
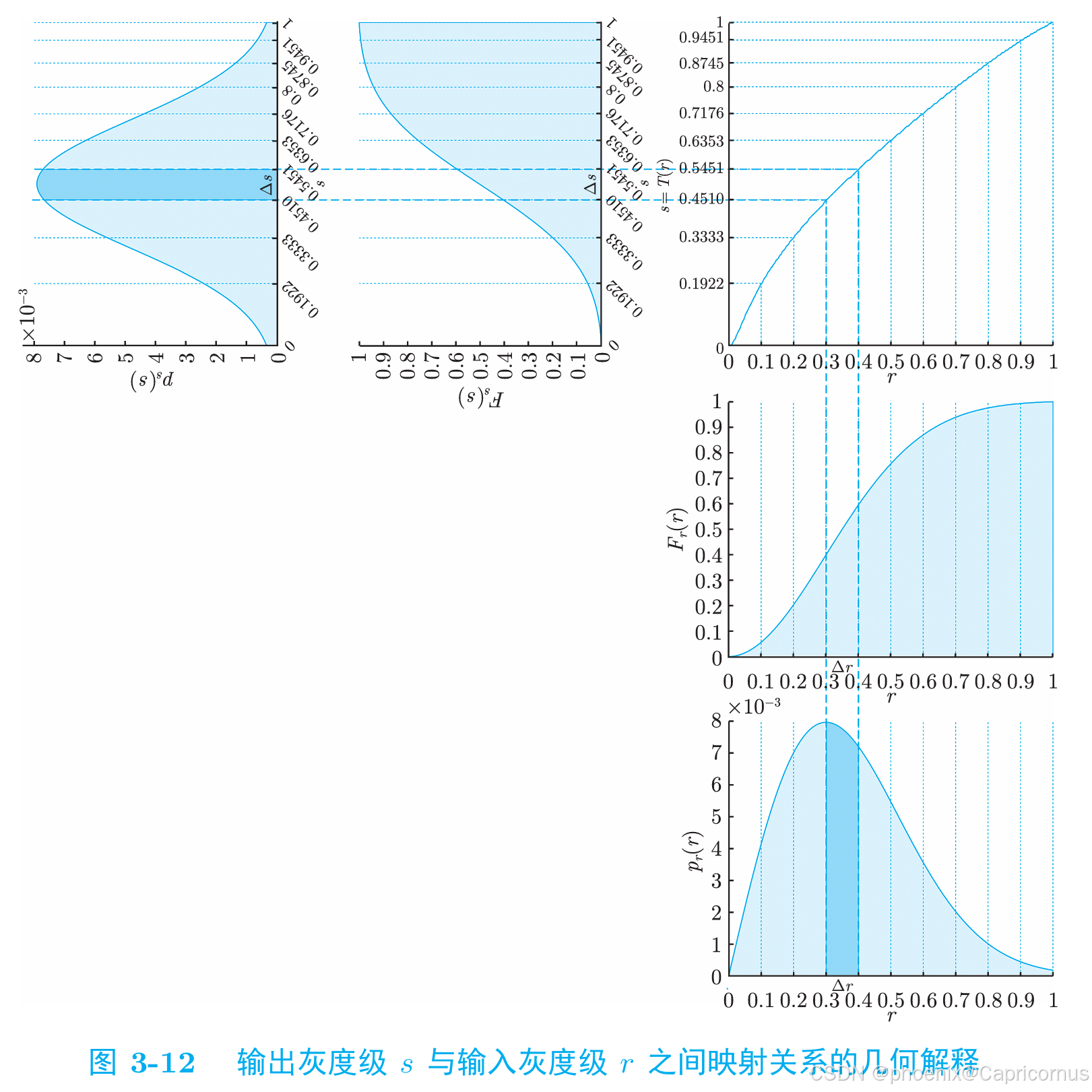
对于连续型随机变量,分布函数(Cumulative Distribution Function, CDF)是概率密度函数(Probability Density Function, PDF)的变上限积分,概率密度函数是分布函数的导函数。 如果我们有一个连续型随机变量…...
YOLOv5训练自己的数据及rknn部署
YOLOv5训练自己的数据及rknn部署 一、下载源码二、准备自己的数据集2.1 标注图像2.2 数据集结构 三、配置YOLOv5训练3.1 修改配置文件3.2 模型选择 四、训练五、测试六、部署6.1 pt转onnx6.2 onnx转rknn 七、常见错误7.1 训练过程中的错误7.1.1 cuda: out of memory7.1.2 train…...

计算机图形学:实验四 带纹理的OBJ文件读取和显示
一、程序功能设计 在程序中读取带纹理的obj文件,载入相应的纹理图片文件,将带纹理的模型显示在程序窗口中。实现带纹理的OBJ文件读取与显示功能,具体设计如下: OBJ文件解析与数据存储 通过实现TriMesh类中的readObj函数&#x…...

SQL Server 使用SELECT INTO实现表备份
在数据库管理过程中,有时我们需要对表进行备份,以防数据丢失或修改错误。在 SQL Server 中,可以使用 SELECT INTO 语句将数据从一个表备份到另一个表。 备份表的 SQL 语法: SELECT * INTO 【备份表名】 FROM 【要备份的表】 SEL…...
【线性代数】基础版本的高斯消元法
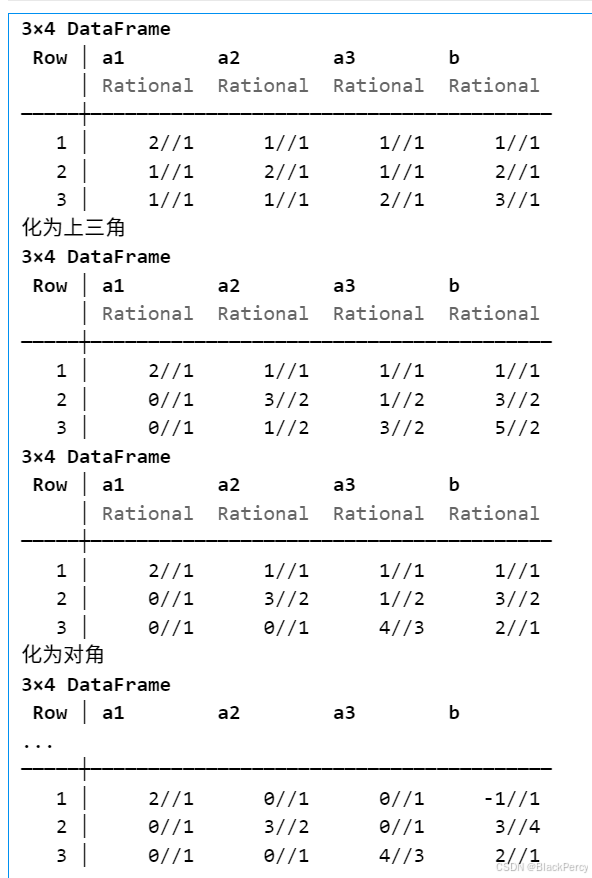
[精确算法] 高斯消元法求线性方程组 线性方程组 考虑线性方程组, 已知 A ∈ R n , n , b ∈ R n A\in \mathbb{R}^{n,n},b\in \mathbb{R}^n A∈Rn,n,b∈Rn, 求未知 x ∈ R n x\in \mathbb{R}^n x∈Rn A 1 , 1 x 1 A 1 , 2 x 2 ⋯ A 1 , n x n b 1…...

Python标准库 threading 的 start 和 join 的使用
python 的多线程机制可以的适用场景不适合与计算密集型的,因为 GIL 的存在,多线程在处理计算密集型时,实际上也是串行的,因为每个时刻只有一个线程可以获得 GIL,但是对于 IO 处理来说,不管是网络IO还是文件…...
无公网IP 外网访问媒体服务器 Emby
Emby 是一款多媒体服务器软件,用户可以在 Emby 创建自己的个人多媒体娱乐中心,并且可以跨多个设备访问自己的媒体库。它允许用户管理传输自己的媒体内容,比如电影、电视节目、音乐和照片等。 本文将详细的介绍如何利用 Docker 在本地部署 Emb…...
【数据结构】_顺序表
目录 1. 概念与结构 1.1 静态顺序表 1.2 动态顺序表 2. 动态顺序表实现 2.1 SeqList.h 2.2 SeqList.c 2.3 Test_SeqList.c 3. 顺序表性能分析 线性表是n个具有相同特性的数据元素的有限序列。 常见的线性表有:顺序表、链表、栈、队列、字符串等;…...

[MySQL]数据库表内容的增删查改操作大全
目录 一、增加表数据 1.全列插入与指定列插入 2.多行数据插入 3.更新与替换插入 二、查看表数据 1.全列查询与指定列查询 2.查询表达式字段 3.为查询结果起别名 4.结果去重 5.WHERE条件 6.结果排序 7.筛选分页结果 8.插入查询的结果 9.group by子句 三、修改表数…...

解决双系统引导问题:Ubuntu 启动时不显示 Windows 选项的处理方法
方法 1:检查 GRUB 引导菜单是否隐藏 启动进入 Ubuntu 系统。打开终端,输入以下命令编辑 GRUB 配置文件:sudo nano /etc/default/grub检查以下配置项: GRUB_TIMEOUT0:如果是 0,将其改为一个较大的值&#x…...
Java面试题2025-Spring
讲师:邓澎波 Spring面试专题 1.Spring应该很熟悉吧?来介绍下你的Spring的理解 1.1 Spring的发展历程 先介绍Spring是怎么来的,发展中有哪些核心的节点,当前的最新版本是什么等 通过上图可以比较清晰的看到Spring的各个时间版本对…...

CentOS7安装使用containerd
一,安装 1.1、安装containerd 下载 https://github.com/containerd/containerd/releases/download/v1.7.24/cri-containerd-cni-1.7.24-linux-amd64.tar.gz wget https://github.com/containerd/containerd/releases/download/v1.7.24/cri-containerd-cni-1.7.24-…...

Redis 集群模式入门
Redis 集群模式入门 一、简介 Redis 有三种集群模式:主从模式、Sentinel 哨兵模式、cluster 分片模式 主从复制(Master-Slave Replication): 在这种模式下,数据可以从一个 Redis 实例(主节点 Master)复…...

WinDBG查找C++句柄泄露
C代码(频繁点击About按钮导致Mutex句柄泄露) HANDLE _mutexHandle;LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam) {switch (message){case WM_COMMAND:{int wmId LOWORD(wParam);// 分析菜单选择:switch (wmId){c…...

Linux查看服务器的内外网地址
目录: 1、内网地址2、外网地址3、ping时显示地址与真实不一致 1、内网地址 ifconfig2、外网地址 curl ifconfig.me3、ping时显示地址与真实不一致 原因是dns缓存导致的,ping这种方法也是不准确的,有弊端不建议使用,只适用于测试…...

深入MapReduce——引入
引入 前面我们已经深入了HDFS的设计与实现,对于分布式系统也有了不错的理解。 但HDFS仅仅解决了海量数据存储和读写的问题。要想让数据产生价值,一定是需要从数据中挖掘出价值才行,这就需要我们拥有海量数据的计算处理能力。 下面我们还是…...

Oracle之开窗函数使用
Oracle中的开窗函数(Window Functions)是一种强大的工具,用于在SQL查询中对数据进行复杂的分析和聚合操作,而无需改变原始查询结果的行数或顺序。以下是关于Oracle开窗函数的使用方法和常见示例: 1. 开窗函数的基本语法…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

Unity中MMD初音资源导入与动画落地全流程指南
1. 这不是普通模型包:初音跳舞资源在Unity中的真实价值定位“Unity初音跳舞精品模型动画资源分享”——看到这个标题,很多刚接触Unity的美术向开发者第一反应是:“哇,能直接放进项目里做Demo了!”但我在带三个独立游戏…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

[特殊字符] 高效统计排序数组中目标元素的出现次数
给定一个已排序的数组和一个目标值,如何快速统计该目标值在数组中出现的次数?这是面试中非常经典的一道题,今天就来聊聊两种解法:线性搜索和二分搜索。 问题描述 假设有一个已排序的数组 arr[] 和一个整数 target,需…...