【模型】RNN模型详解
1. 模型架构
RNN(Recurrent Neural Network)是一种具有循环结构的神经网络,它能够处理序列数据。与传统的前馈神经网络不同,RNN通过将当前时刻的输出与前一时刻的状态(或隐藏层)作为输入传递到下一个时刻,使得它能够保留之前的信息并用于当前的决策。

- 输入层:输入数据的每一时刻(如时间序列数据的每个时间步)都会传递到网络。
- 隐藏层:RNN的核心是循环结构,它将先前的隐藏状态与当前的输入结合,生成当前的隐藏状态。通常,RNN的隐藏层包含多个神经元,且它们的状态是由上一时刻的输出状态递归计算得来的。
- 输出层:基于隐藏层的输出,生成预测结果。
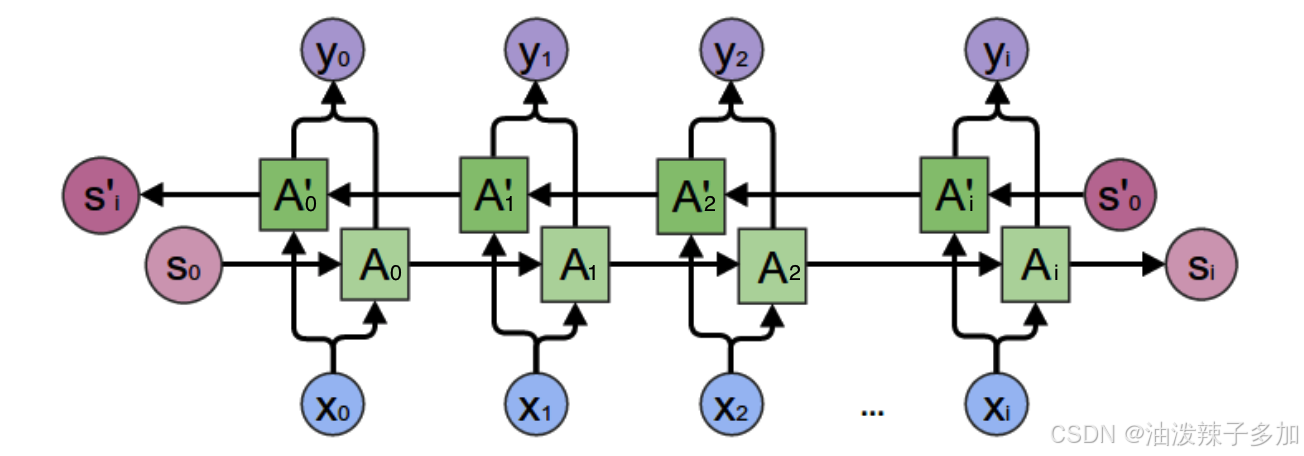
RNN通过共享参数和权重来处理任意长度的序列输入,能够用于语言模型、时间序列预测等任务。
2. 算法实现(PyTorch)
在PyTorch中实现一个简单的RNN模型,通常需要以下几个步骤:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt# 定义RNN模型类
class RNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, forecast_horizon):super(RNN, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.forecast_horizon = forecast_horizon# 定义RNN层self.rnn = nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size,num_layers=self.num_layers, batch_first=True)# 定义全连接层self.fc1 = nn.Linear(self.hidden_size, 64)self.fc2 = nn.Linear(64, self.forecast_horizon) # 输出5步的数据# Dropout层,防止过拟合self.dropout = nn.Dropout(0.2)def forward(self, x):# 初始化隐藏状态h_0 = torch.randn(self.num_layers, x.size(0), self.hidden_size).to(device)# 通过RNN层进行前向传播out, _ = self.rnn(x, h_0)# 只取最后一个时间步的输出out = F.relu(self.fc1(out[:, -1, :])) # 输出通过全连接层1并激活out = self.fc2(out) # 输出通过全连接层2,预测未来5步的数据return out# 准备训练数据
# 假设你已经准备好了数据,X_train, X_test, y_train, y_test等
# 并且 X_train, X_test 是形状为 (samples, time_steps, features) 的三维数组# 设置设备,使用GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')# 将数据转换为torch tensors,并转移到设备(GPU/CPU)
X_train_tensor = torch.Tensor(X_train).to(device)
X_test_tensor = torch.Tensor(X_test).to(device)# 将y_train和y_test调整形状为(batch_size, forecast_horizon),即去掉最后一维
y_train_tensor = torch.Tensor(y_train).squeeze(-1).to(device) # 将 y_train.shape 从 (batch_size, forecast_horizon, 1) -> (batch_size, forecast_horizon)
y_test_tensor = torch.Tensor(y_test).squeeze(-1).to(device) # 将 y_test.shape 从 (batch_size, forecast_horizon, 1) -> (batch_size, forecast_horizon)# 初始化RNN模型
input_size = X_train.shape[2] # 特征数量
hidden_size = 64 # 隐藏层神经元数量
num_layers = 2 # RNN层数
forecast_horizon = 5 # 预测的目标步数model = RNN(input_size, hidden_size, num_layers, forecast_horizon).to(device)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
def train_model(model, X_train, y_train, X_test, y_test, epochs=2000, batch_size=1024):train_loss = []val_loss = []for epoch in range(epochs):model.train()optimizer.zero_grad()# 前向传播output_train = model(X_train)# 计算损失loss = criterion(output_train, y_train)loss.backward()optimizer.step()train_loss.append(loss.item())# 计算验证集损失model.eval()with torch.no_grad():output_val = model(X_test)val_loss_value = criterion(output_val, y_test)val_loss.append(val_loss_value.item())if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{epochs}], Train Loss: {loss.item():.4f}, Validation Loss: {val_loss_value.item():.4f}')# 绘制训练损失和验证损失曲线plt.plot(train_loss, label='Train Loss')plt.plot(val_loss, label='Validation Loss')plt.title('Loss vs Epochs')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()plt.show()# 训练模型
train_model(model, X_train_tensor, y_train_tensor, X_test_tensor, y_test_tensor, epochs=2000)# 评估模型
def evaluate_model(model, X_test, y_test):model.eval()with torch.no_grad():y_pred = model(X_test)y_pred_rescaled = y_pred.cpu().numpy()y_test_rescaled = y_test.cpu().numpy()# 计算均方误差mse = mean_squared_error(y_test_rescaled, y_pred_rescaled)print(f'Mean Squared Error: {mse:.4f}')return y_pred_rescaled, y_test_rescaled# 评估模型性能
y_pred_rescaled, y_test_rescaled = evaluate_model(model, X_test_tensor, y_test_tensor)# 保存模型
def save_model(model, path='./model_files/multisteos_rnn_model.pth'):torch.save(model.state_dict(), path)print(f'Model saved to {path}')# 保存训练好的模型
save_model(model)1.代码解析
(1)反向传播
def forward(self, x):# 初始化隐藏状态h_0 = torch.randn(self.num_layers, x.size(0), self.hidden_size).to(device)# 通过RNN层进行前向传播out, _ = self.rnn(x, h_0)# 只取最后一个时间步的输出out = F.relu(self.fc1(out[:, -1, :])) # 输出通过全连接层1并激活out = self.fc2(out) # 输出通过全连接层2,预测未来5步的数据return out
- 此处
h_0是RNN的初始隐藏状态,形状为(num_layers, batch_size, hidden_size),它存储了每一层在时间步t=0的初始隐藏状态; out中存储的是 最后一层的所有时间步的隐藏状态,PyTorch 的nn.RNN系列实现中,out始终返回的是 最后一层 的隐藏状态;例如,3层的 RNN,out中的数据是第3层的隐藏状态,前两层的状态不会在out中;out[:, -1, :]取的是最后一层并且最后一个时间步的隐藏状态,这是因为在许多任务中(如预测未来值),最后时间步的隐藏状态通常包含了整个序列的信息,因此可以作为最终的特征表示;_是 所有层 的最后一个时间步的隐藏状态,通常会有多个层(即num_layers > 1时),其形状为(num_layers, batch_size, hidden_size);
3. 训练使用方式
- 数据准备:通常RNN处理时间序列数据。数据需要转换成合适的格式,即将每个数据点按时间顺序组织成序列样本。
- 损失函数:对于回归任务,通常使用均方误差(MSE),而分类任务则使用交叉熵损失。
- 优化器:使用Adam或SGD等优化器来更新网络权重。
- 批处理和梯度裁剪:RNN的训练可能遇到梯度爆炸或梯度消失的问题,可以使用梯度裁剪(gradient clipping)来缓解。
4. 模型优缺点
优点:
- 时间序列建模:RNN可以处理具有时序依赖的数据(如语音、文本、股市等)。
- 共享权重:RNN通过在时间步之间共享权重,减少了模型的参数数量。
- 灵活性:RNN可以处理不同长度的输入序列。
缺点:
- 梯度消失/爆炸:在长序列中,RNN容易出现梯度消失或梯度爆炸的问题,导致训练困难。
- 训练效率低:传统的RNN难以捕捉长时间跨度的依赖关系,训练速度较慢。
- 局部依赖:RNN在捕获远程依赖时表现较差,容易受到短期记忆的影响。
5. 模型变种
-
LSTM (Long Short-Term Memory)
- LSTM 是RNN的一种变种,通过引入“记忆单元”来解决标准RNN中的梯度消失问题。它使用了三个门控机制——输入门、遗忘门和输出门,来控制信息的存储与更新,从而能够捕捉长时间跨度的依赖。
-
GRU (Gated Recurrent Unit)
- GRU是LSTM的一个简化版本,具有类似的性能但较少的参数。它合并了LSTM中的遗忘门和输入门为一个“更新门”,使得模型更为简洁。
-
Bidirectional RNN
- 双向RNN在处理序列数据时,通过同时考虑从前向和反向两个方向的信息,能够提高模型的表达能力,尤其在文本处理任务中有较好表现。
-
Attention机制
- Attention机制不仅在NLP任务中广泛使用,还被引入到RNN中,帮助模型关注输入序列中最重要的部分,从而有效处理长时间序列和远程依赖问题。
-
Transformer
- Transformer模型去除了传统RNN中的循环结构,完全基于自注意力机制(self-attention)来建模序列的依赖关系,避免了RNN的梯度消失问题,并能够并行处理序列。
6. 模型特点
- 时序数据建模:RNN特别适用于处理时序数据,可以理解序列中前后时间步之间的依赖关系。
- 状态更新:RNN通过隐藏层的状态传递,实现了对历史信息的持续更新和记忆。
- 参数共享:与传统的前馈神经网络不同,RNN在每个时间步使用相同的权重,因此模型在处理长序列时参数效率较高。
7. 应用场景
- 自然语言处理:
- 语言模型:RNN可以用于生成语言模型,如生成文本或对句子进行语言建模。
- 机器翻译:通过编码器-解码器结构,RNN(尤其是LSTM和GRU)在序列到序列(seq2seq)任务中非常有效。
- 语音识别:将语音信号转化为文字的过程中,RNN用于捕捉语音的时序特性。
- 时间序列预测:
- 股市预测:RNN可以用于基于历史股市数据预测未来价格。
- 天气预测:使用RNN模型预测未来几天的气候变化。
- 销售预测:基于历史销售数据预测未来销售量。
- 生成模型:
- 文本生成:基于RNN的文本生成模型(如char-level语言模型)可以生成与输入数据风格相似的文本。
- 音乐生成:RNN可以用来生成音乐序列,模仿人类作曲的风格。
- 视频分析:
- 视频分类:利用RNN在视频帧序列中的时序特性进行分类。
- 动作识别:RNN可以捕捉视频序列中的动作模式,用于人类行为分析。
相关文章:
【模型】RNN模型详解
1. 模型架构 RNN(Recurrent Neural Network)是一种具有循环结构的神经网络,它能够处理序列数据。与传统的前馈神经网络不同,RNN通过将当前时刻的输出与前一时刻的状态(或隐藏层)作为输入传递到下一个时刻&…...
)
C++----STL(list)
介绍 list的数据结果是一个带头双向链表。 使用 有了前面string、vector的基础,后续关于list使用的讲解主要提及与string和vector的不同之处。 使用文档:cplusplus.com/reference/list/list/?kwlist 迭代器问题 insert以后迭代器不失效 #include…...

数据结构——AVL树的实现
Hello,大家好,这一篇博客我们来讲解一下数据结构中的AVL树这一部分的内容,AVL树属于是数据结构的一部分,顾名思义,AVL树是一棵特殊的搜索二叉树,我们接下来要讲的这篇博客是建立在了解搜索二叉树这个知识点…...
知识图谱在个性化推荐中的应用:赋能智能化未来
目录 前言1. 知识图谱的基本概念2. 个性化推荐的挑战与知识图谱的优势2.1 个性化推荐的主要挑战2.2 知识图谱在个性化推荐中的优势 3. 知识图谱赋能推荐系统的具体实现3.1 数据增强与关系建模3.2 嵌入技术的应用3.3 图神经网络(GNN)的应用3.4 多模态数据…...
C语言自定义数据类型详解(一)——结构体类型(上)
什么是自定义数据类型呢?顾名思义,就是我们用户自己定义和设置的类型。 在C语言中,我们的自定义数据类型一共有三种,它们分别是:结构体(struct),枚举(enum),联合(union)。接下来,我…...

使用 Tailwind CSS + PostCSS 实现响应式和可定制化的前端设计
随着前端开发框架和工具的不断更新,设计和样式的管理已经成为前端开发中的一项核心任务。传统的 CSS 编写方式往往让样式的复用和可维护性变得困难,而 Tailwind CSS 和 PostCSS 作为当下流行的工具,提供了强大的功能来简化开发过程࿰…...

巧用多目标识别能力,帮助应用实现智能化图片解析
为了提升用户体验,各类应用正通过融合人工智能技术,致力于提供更智能、更高效的服务。应用不仅能通过文字和语音的方式与用户互动,还能深入分析图片内容,为用户提供精准的解决方案。 在解析图片之前,应用首先需要准确识…...

算法中的移动窗帘——C++滑动窗口算法详解
1. 滑动窗口简介 滑动窗口是一种在算法中常用的技巧,主要用来处理具有连续性的子数组或子序列问题。通过滑动窗口,可以在一维数组或字符串上维护一个固定或可变长度的窗口,逐步移动窗口,避免重复计算,从而提升效率。常…...
 函数)
AcWing 3585:三角形的边 ← sort() 函数
【题目来源】 给定三个已知长度的边,确定是否能够构成一个三角形,这是一个简单的几何问题。 我们都知道,这要求两边之和大于第三边。 实际上,并不需要检验所有三种可能,只需要计算最短的两个边长之和是否大于最大那个就…...

阿里云-银行核心系统转型之业务建模与技术建模
业务领域建模包括业务建模和技术建模,整体建模流程图如下: 业务建模包括业务流程建模和业务对象建模 业务流程建模:通过对业务流程现状分析,结合目标核心系统建设能力要求,参考行业建 模成果,形成结构化的…...

MySQL核心知识:春招面试数据库要点
在前文中,我们深入剖析了MyBatis这一优秀的持久层框架,了解了它如何实现SQL语句与Java对象的映射,以及其缓存机制等重要内容。而作为数据持久化的核心支撑,数据库的相关知识在Java开发中同样至关重要。MySQL作为最流行的开源关系型…...

Hive之加载csv格式数据到hive
场景: 今天接了一个需求,将测试环境的hive数据导入到正式环境中。但是不需要整个流程的迁移,只需要迁移ads表 解决方案: 拿到这个需求首先想到两个方案: 1、将数据通过insert into语句导出,然后运行脚本 …...

Java web与Java中的Servlet
一。前言 Java语言大多用于开发web系统的后端,也就是我们是的B/S架构。通过浏览器一个URL去访问系统的后端资源和逻辑。 当我在代码里看到这个类HttpServletRequest 时 让我想到了Servlet,Servlet看上去多么像是Java的一个普通类,但是它确实…...

kafka常用目录文件解析
文章目录 1、消息日志文件(.log)2、消费者偏移量文件(__consumer_offsets)3、偏移量索引文件(.index)4、时间索引文件( .timeindex)5、检查点引文件( .checkpoint&#x…...
RV1126+FFMPEG推流项目源码
源码在我的gitee上面,感兴趣的可以自行了解 nullhttps://gitee.com/x-lan/rv126-ffmpeg-streaming-projecthttps://gitee.com/x-lan/rv126-ffmpeg-streaming-project...

ANSYS SimAI
ANSYS SimAI 是 ANSYS 公司推出的一款基于人工智能(AI)的仿真解决方案,旨在通过机器学习技术加速仿真流程,降低计算资源需求,并为用户提供更高效的工程决策支持。其核心目标是简化复杂仿真过程,帮助工程师快…...
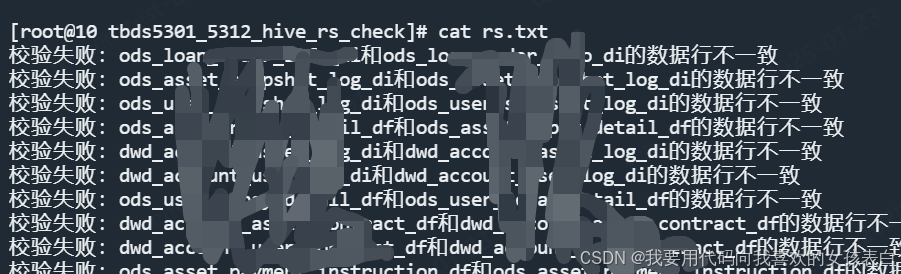
hedfs和hive数据迁移后校验脚本
先谈论校验方法,本人腾讯云大数据工程师。 1、hdfs的校验 这个通常就是distcp校验,hdfs通过distcp迁移到另一个集群,怎么校验你的对不对。 有人会说,默认会有校验CRC校验。我们关闭了,为什么关闭?全量迁…...

蓝桥杯单片机(八)定时器的基本原理与应用
模块训练: 当有长定时情况时,也就是定时长度超过65.5ms时,采用多次定时累加 一、定时器介绍 1.单片机的定时/计数器 2.定时器工作原理 3.定时器相关寄存器 二、定时器使用程序设计 1.程序设计思路 与写中断函数一样,先写一个初…...
刷题总结 回溯算法
为了方便复习并且在把算法忘掉的时候能尽量快速的捡起来 刷完回溯算法这里需要做个总结 回溯算法的适用范围 回溯算法是深度优先搜索(DFS)的一种特定应用,在DFS的基础上引入了约束检查和回退机制。 相比于普通的DFS,回溯法的优…...

C++ 静态变量static的使用方法
static概述: static关键字有三种使用方式,其中前两种只指在C语言中使用,第三种在C中使用。 静态局部变量(C) 静态全局变量/函数(C) 静态数据成员/成员函数(C) 静态局部变量 静态局部变量&…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析
LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 功能模块架构与核心技…...

别只盯着主控芯片!拆解STM32最小系统板:电源、时钟、复位三大支柱电路深度解析
STM32最小系统板设计进阶:电源、时钟与复位电路的工程实践 在嵌入式系统开发中,我们常常将注意力集中在主控芯片的功能实现上,却忽略了支撑系统稳定运行的三大基础电路——电源、时钟和复位。这些看似简单的电路模块,实则是整个系…...