深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。

文章目录
- 文本特征提取的方法
- 1. 基础方法
- 1.1 词袋模型(Bag of Words, BOW)
- 工作原理
- 举例
- 优点
- 缺点
- 1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
- 工作原理
- 举例
- 优点
- 缺点
- 1.3 TF-IDF的改进——BM25
- 优化
- 1.4 N-Gram 模型
- 工作原理
- 举例
- 优点
- 缺点
- 2. 词向量(Word Embeddings)
- 2.1 Word2Vec
- 工作原理
- 举例
- 优点
- 缺点
- 2.2 FastText
- 工作原理
- 优点
- 缺点
- 3. 预训练模型:BERT(Bidirectional Encoder Representations from Transformers)
- 工作原理
- 优点
- 缺点
- 总结
- LSTM(Long Short-Term Memory)
- LSTM 的核心部件
- LSTM 的公式和工作原理
- (1) 遗忘门(Forget Gate)
- (2) 输入门(Input Gate)
- (3) 更新记忆单元状态
- (4) 输出门(Output Gate)
- LSTM 的流程总结
- LSTM 的优点
- LSTM 的局限性
- 热门专栏
- 机器学习
- 深度学习
文本特征提取的方法
1. 基础方法
1.1 词袋模型(Bag of Words, BOW)
词袋模型最简单的方法。它将文本表示为一个词频向量,不考虑词语的顺序或上下文关系,只统计每个词在文本中出现的频率。
工作原理
- 构建词汇表:对整个语料库中的所有词汇建立一个词汇表(也称为词典)。每个文档中的每个词都与词汇表中的一个位置对应。
- 生成词频向量:对于每个文本(文档),生成一个与词汇表长度相同的向量。向量中每个元素表示该词在文档中出现的次数(或者是否出现,用二进制表示)。
举例
假设有两个句子:
- 句子 1:
猫 喜欢 鱼 - 句子 2:
狗 不 喜欢 鱼
词汇表 = [“猫”, “狗”, “喜欢”, “不”, “鱼”]
- 句子 1 的词袋向量表示为:[1, 0, 1, 0, 1]
- 句子 2 的词袋向量表示为:[0, 1, 1, 1, 1]
优点
- 简单直观,易于实现,有效地表示词频信息。
缺点
- 忽略词序:词袋模型无法捕捉词语的顺序,因此在语义表达上有局限。
- 高维稀疏:对于大词汇表,词袋模型会生成非常长的特征向量,大多数元素为 0,容易导致稀疏矩阵,影响计算效率。
- 受到常见词的影响:常见词(如 “the”、“and” 等)可能在各类文档中频繁出现,但对语义贡献较少,词袋模型会受到这些高频词的影响,降低模型的效果。
1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 是对词袋模型的改进,它为词语赋予不同的权重,来衡量每个词在文档中的重要性。与词袋模型相比,TF-IDF 不仅考虑词频,还考虑词的普遍性,以避免常见词(如"the"、“and”)的影响。
工作原理
- TF(词频):计算某个词在文档中出现的频率。
T F ( t , d ) = 词 t 在文档 d 中的出现次数 文档 d 的总词数 TF(t,d)=\frac{词t在文档d中的出现次数}{文档d的总词数} TF(t,d)=文档d的总词数词t在文档d中的出现次数 - IDF(逆文档频率):衡量词在整个语料库中的普遍性,出现频率越低的词权重越高。
I D F ( t ) = log ( N 1 + D F ( t ) ) IDF(t)=\log\left(\frac{N}{1 + DF(t)}\right) IDF(t)=log(1+DF(t)N)- 其中 N N N是文档总数, D F ( t ) DF(t) DF(t)是包含词 t t t的文档数。
- TF - IDF:将 T F TF TF和 I D F IDF IDF相乘,得到词在特定文档中的权重:
T F − I D F ( t , d ) = T F ( t , d ) × I D F ( t ) TF - IDF(t,d)=TF(t,d)\times IDF(t) TF−IDF(t,d)=TF(t,d)×IDF(t)
举例
对于句子“猫 喜欢 鱼”和“狗 不 喜欢 鱼”,假设 “喜欢” 出现在所有文档中,IDF 会给它较低的权重,而像 “猫”、“狗” 这样的词会有较高的 IDF 权重,因为它们只出现在一部分文档中。
优点
- 更准确地反映词的重要性,避免了词袋模型中常见词占主导地位的情况。尤其适用于文本分类任务。
缺点
- 稀疏矩阵:虽然词频的权重经过调整,但词汇表的大小仍然很大,容易产生稀疏矩阵问题。
- 忽略词序:仍然无法捕捉词语之间的顺序和上下文关系。
1.3 TF-IDF的改进——BM25
BM25对TF和IDF进行加权,同时考虑文档长度对相关性的影响,使得对较短和较长文档的评分更加合理。
BM25 的计算公式如下:
B M 25 ( q , d ) = ∑ t ∈ q I D F ( t ) ⋅ T F ( t , d ) ⋅ ( k 1 + 1 ) T F ( t , d ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ d ∣ a v g d l ) BM25(q,d)=\sum_{t\in q}IDF(t)\cdot\frac{TF(t,d)\cdot(k_1 + 1)}{TF(t,d)+k_1\cdot(1 - b + b\cdot\frac{|d|}{avgdl})} BM25(q,d)=t∈q∑IDF(t)⋅TF(t,d)+k1⋅(1−b+b⋅avgdl∣d∣)TF(t,d)⋅(k1+1)
其中:
- q q q 是查询, d d d 是文档, t t t 是查询中的词。
- I D F IDF IDF是与 T F − I D F TF - IDF TF−IDF相似的逆文档频率。
- T F TF TF是词频。
- k 1 k_1 k1 是调节词频饱和度的参数,通常取值范围为 [ 1.2 , 2.0 ] [1.2,2.0] [1.2,2.0]。
- b b b 是调节文档长度的参数,通常取值范围为 [ 0.0 , 1.0 ] [0.0,1.0] [0.0,1.0], b = 0.75 b = 0.75 b=0.75是一个常用的设置。
- ∣ d ∣ |d| ∣d∣是文档的长度(词数), a v g d l avgdl avgdl是语料库中文档的平均长度。
TF-IDF 中的 IDF(逆文档频率)使用 log N d f ( t ) \log\frac{N}{df(t)} logdf(t)N来衡量词的普遍性。然而这种计算方式可能会导致在某些极端情况下(如 df(t) = 0 )出现不合理的结果。
BM25 对 IDF 进行了小改进,以提高在极端情况下的稳定性:
I D F ( t ) = log N − d f ( t ) + 0.5 d f ( t ) + 0.5 IDF(t)=\log\frac{N - df(t)+ 0.5}{df(t)+ 0.5} IDF(t)=logdf(t)+0.5N−df(t)+0.5
这种改进的 IDF 计算在文档数量较少或者某个词的出现频率极高时,能提供更合理的 IDF 值,增加了 BM25 的稳定性。
优化
相比于 TF-IDF,BM25 主要做了以下改进:
- 非线性词频缩放:通过 k 1 k_1 k1 控制词频TF饱和 ,避免 TF 值无限增大导致的偏差。
- 文档长度归一化:使用参数 b b b调整文档长度对评分的影响,防止长文档得分偏高。
- 改进的 IDF 计算:使用平滑后的 IDF 计算,保证在极端情况下的稳定性。
- 查询词频考虑:在评分中更合理地衡量查询中词频的影响,提高了对复杂查询的检索效果。
1.4 N-Gram 模型
N-Gram 模型是一种基于词袋模型的扩展方法,它通过将词组作为特征,来捕捉词语的顺序信息。
工作原理
-
N-Gram 是指在文本中提取连续的 n 个词组成的词组作为特征。当 n=1 时,即为 unigram(单词级别特征);当 n=2 时,即为 bigram(双词组特征);当 n=3 时,即为 trigram(词三元组特征)。
-
在提取 N-Gram 时,模型不仅关注单个词,还捕捉到词与词之间的顺序和依赖关系。例如,2-Gram 模型会将句子分解为相邻的两词组合。
举例
对于句子“猫 喜欢 吃 鱼”,2-Gram 模型会提取出以下特征:
- [“猫 喜欢”, “喜欢 吃”, “吃 鱼”]
优点
- 能捕捉到顺序和依赖关系,比单词级别的特征表达更丰富。n 越大,模型捕捉的上下文信息越多。
缺点
- 维度膨胀:n 值越大,特征向量的维度会急剧增加,容易导致稀疏矩阵和计算复杂度升高。
- 对长文本,N-Gram 模型可能会生成非常多的组合,计算资源消耗较大。
2. 词向量(Word Embeddings)
词向量是现代 NLP 中的关键特征提取方法,能够捕捉词语的语义信息。常见的词向量方法包括 Word2Vec、GloVe、和 FastText。词向量的核心思想是将每个词表示为一个低维的、密集的向量,词向量之间的相似性能够反映词语的语义相似性。
2.1 Word2Vec
Word2Vec 是一种使用浅层神经网络学习词向量的模型,由 Google 在 2013 年提出。它有两种模型架构:CBOW 和 Skip-gram。
工作原理
- CBOW(Continuous Bag of Words):根据上下文中的词语来预测中心词。模型输入是上下文词语,输出是预测的中心词。
- Skip-gram:与 CBOW 相反,它是根据中心词来预测上下文中的词语。
举例
对于一个句子 “猫 喜欢 吃 鱼”,CBOW 会使用上下文 [“猫”, “吃”, “鱼”] 来预测 “喜欢”,而 Skip-gram 则会使用 “喜欢” 来预测上下文。
优点
- 语义相似性:Word2Vec 生成的词向量能够捕捉词语之间的语义相似性。例如,“king” 和 “queen” 的词向量会非常相近。
- 稠密向量:与词袋模型和 TF-IDF 生成的高维稀疏向量不同,Word2Vec 生成的词向量是低维的密集向量(如 100 维或 300 维),更加高效。
缺点
- 无法处理 OOV(未登录词):如果测试集中出现了训练集中未见过的词,Word2Vec 无法为其生成词向量。
- 上下文无关:Word2Vec 生成的词向量是固定的,无法根据上下文变化来调整词向量。
2.2 FastText
FastText 是 Facebook 提出的词向量方法,它是 Word2Vec 的改进版。FastText 通过将词分解为n-gram字符级别的子词,捕捉词的形态信息。
工作原理
- FastText 将词分解为多个字符 n-gram,然后对每个 n-gram 生成词向量。通过这种方式,FastText 可以捕捉到词语内部的形态信息,尤其对拼写错误或未登录词有较好的处理能力。
优点
- 处理 OOV(未登录词):因为 FastText 基于子词生成词向量,它能够为未见过的词生成向量表示。
- 考虑词形信息:能够捕捉词的形态变化,例如词根、前缀、后缀等。
缺点
- 计算复杂度较高:相比 Word2Vec,FastText 需要对每个词生成多个 n-gram,因此计算量更大。
3. 预训练模型:BERT(Bidirectional Encoder Representations from Transformers)
BERT 是一种基于 Transformer 架构的预训练语言模型,由 Google 于 2018 年提出。与传统的词向量方法不同,BERT 通过双向的 Transformer 网络,能够生成上下文相关的动态词向量。
工作原理
- 双向Transformer:BERT 同时从词语的前后上下文学习词的表示,而不像传统的模型只从前向或后向学习。这样,BERT 能够捕捉到更丰富的语义信息。
- 预训练任务:
- 遮蔽语言模型(Masked Language Model, MLM):在训练时,BERT 会随机遮蔽部分词语,并要求模型预测这些词,从而让模型学到上下文的双向依赖关系。
- 下一句预测(Next Sentence Prediction, NSP):训练时,BERT 要预测两句话是否是连续的句子对,这让模型能够学习句子级别的关系。
优点
- 上下文相关词向量:BERT 生成的词向量是上下文相关的。例如,“bank” 在句子 “I went to the bank” 和 “The river bank” 中会有不同的向量表示。
- 强大的语义理解能力:BERT 在问答、阅读理解、文本分类等任务中表现非常好,能够捕捉到复杂的语义关系。
缺点
- 计算资源需求大:BERT 是一个深层的 Transformer 模型,预训练和微调都需要大量的计算资源,训练时间较长。
- 较慢的推理速度:由于模型较大,在实际应用中推理速度较慢,尤其在实时任务中。
BERT详细参考历史/后续文章:[深度学习笔记——GPT、BERT、T5]
总结
| 方法 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 词袋模型(BOW) | 将文本表示为词频向量,不考虑词序和上下文。 | 简单直观,易实现,能够有效表示词频信息。 | 忽略词序,生成高维稀疏向量。 | 文本分类、信息检索 |
| TF-IDF | 基于词袋模型,考虑词在文档中的频率以及整个语料库中的普遍性,赋予不同词权重。 | 反映词的重要性,避免常见词主导影响,适用于文本分类。 | 生成稀疏矩阵,无法捕捉词序和上下文关系。 | 文本分类、关键词提取 |
| BM25 | 基于 TF-IDF 的改进,考虑词频、文档长度、词重要性等因素,以计算每个词对文档匹配的相关性得分。 非线性词频缩放、 文档长度归一化、 改进的 IDF 计算 | 更好地反映词在文档中的相关性,更适合信息检索,适用于长文档,计算匹配更准确。 | 对参数敏感,适用性依赖于超参数调优,不能捕捉上下文关系。 | 信息检索、文档排名 |
| N-Gram | 捕捉连续 n 个词作为特征,考虑词序信息。 | 能捕捉词语的顺序和依赖关系,n 越大捕捉的上下文信息越多。 | 维度膨胀,计算资源消耗大。 | 语言模型、短文本分类 |
| Word2Vec | 使用浅层神经网络学习词向量,有 CBOW 和 Skip-gram 两种架构。 | 词向量能捕捉语义相似性,生成低维稠密向量,效率高。 | 无法处理未登录词(OOV),词向量上下文无关。 | 词嵌入、相似度计算、文本分类 |
| FastText | 将词分解为字符 n-gram,生成词向量,捕捉词的形态信息。 | 能处理未登录词,捕捉词形信息,适合拼写错误和变形词。 | 计算复杂度高于 Word2Vec。 | 词嵌入、拼写纠错、文本分类 |
| BERT | 基于双向 Transformer,通过预训练生成上下文相关的词向量,支持 Masked Language Model 和 Next Sentence Prediction。 | 生成上下文相关词向量,语义理解强,适用于复杂 NLP 任务。 | 需要大量计算资源,训练和推理时间长。 | 问答系统、文本分类、阅读理解 |
- 传统方法:如词袋模型、TF-IDF 和 N-Gram 易于实现,但无法捕捉语义和上下文信息。
- 词向量方法:如 Word2Vec 和 FastText 通过词嵌入表示词语的语义关系,适合语义相似度计算、文本分类等任务。FastText 能够处理未登录词。
- 预训练模型:如 BERT,能够生成上下文相关的动态词向量,适用于更复杂的自然语言处理任务,但对计算资源的要求更高。
LSTM(Long Short-Term Memory)
LSTM 是 RNN 的一种改进版本,旨在解决 RNN 的长时间依赖问题。LSTM 通过引入记忆单元(cell state) 和门控机制(gates) 来有效地控制信息流动,使得它在长序列建模中表现优异。
LSTM 的核心部件

LSTM 的核心结构由以下几部分组成:
- 记忆单元(Cell State):贯穿整个序列的数据流【图中的C】,能够存储序列中的重要信息,允许网络长时间保留重要的信息。
- 隐藏状态(Hidden State):每个时间步的输出,LSTM 通过它来决定当前的输出和对下一时间步的传递信息。【RNN中就有】
- 三个门控机制(Forget Gate、Input Gate、Output Gate):通过这些门控机制,LSTM 可以选择性地遗忘、存储、或者输出信息(具体在图中的结构参考下面具体介绍)。
LSTM 中最重要的概念是记忆单元状态和门控机制,它们帮助网络在长时间序列中保留重要的历史信息。
在 LSTM 中,隐藏状态是对当前时间步的即时记忆(短期记忆),而记忆单元是对整个序列中长期信息的存储(长期记忆)。
- 遗忘门(Forget Gate):根据当前输入和前一个时间步的隐藏状态,决定记忆单元哪些信息需要被遗忘;
- 输入门(Input Gate):根据当前输入和前一时间步的隐藏状态,决定当前时间步输入对记忆单元的影响;
- 输出门(Output Gate):根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前时间步隐藏状态的输出/影响;(输出内容是从记忆单元中提取的信息);
LSTM 的公式和工作原理
在 LSTM 中,每个时间步 ( t ) 的计算分为以下几步:
图像参考:LSTM(长短期记忆网络)
(1) 遗忘门(Forget Gate)

- 计算公式:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t - 1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf)- f t f_t ft:遗忘门的输出,值介于0到1之间,表示记忆单元中的每个值需要被保留的比例。
- h t − 1 h_{t - 1} ht−1:上一时间步的隐藏状态(短期记忆)。
- x t x_t xt:当前时间步的输入。
- W f W_f Wf、 b f b_f bf:遗忘门的权重和偏置。
- σ \sigma σ:sigmoid函数,将值限制在0到1之间。
遗忘门的作用:它根据当前输入和前一个时间步的隐藏状态,选择哪些来自过去的记忆单元信息需要被遗忘。
(2) 输入门(Input Gate)

- 计算公式:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h_{t - 1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)- i t i_t it:输入门的输出,值介于0到1之间,表示是否更新记忆单元。
- W i W_i Wi、 b i b_i bi:输入门的权重和偏置。
- 候选记忆生成:
C ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde{C}_t=\tanh(W_c\cdot[h_{t - 1},x_t]+b_c) C~t=tanh(Wc⋅[ht−1,xt]+bc)- C ~ t \tilde{C}_t C~t:候选记忆,是根据当前输入生成的新的记忆内容,值在 [ − 1 , 1 ] [- 1,1] [−1,1]之间。
- W c W_c Wc、 b c b_c bc:生成候选记忆的权重和偏置。
输入门的作用:输入门通过 sigmoid 激活函数决定当前输入 ( x t x_t xt ) 和前一时间步的隐藏状态 ( h t − 1 h_{t-1} ht−1 ) 对记忆单元的影响。结合候选记忆 ( C ~ t \tilde{C}_t C~t),输入门决定是否将当前输入的信息入到记忆单元中。
(3) 更新记忆单元状态

- 记忆单元状态更新公式:
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t*C_{t - 1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t- f t ∗ C t − 1 f_t*C_{t - 1} ft∗Ct−1:遗忘门决定了哪些来自前一时间步的记忆单元信息被保留。
- i t ∗ C ~ t i_t*\tilde{C}_t it∗C~t:输入门决定了新的候选记忆 C ~ t \tilde{C}_t C~t需要被加入到记忆单元中的比例。
记忆单元的作用:记忆单元 ( C t C_t Ct ) 根据遗忘门和输入门的输出,保留了来自过去的长期信息,使得重要的历史信息能够长时间存储。
(4) 输出门(Output Gate)
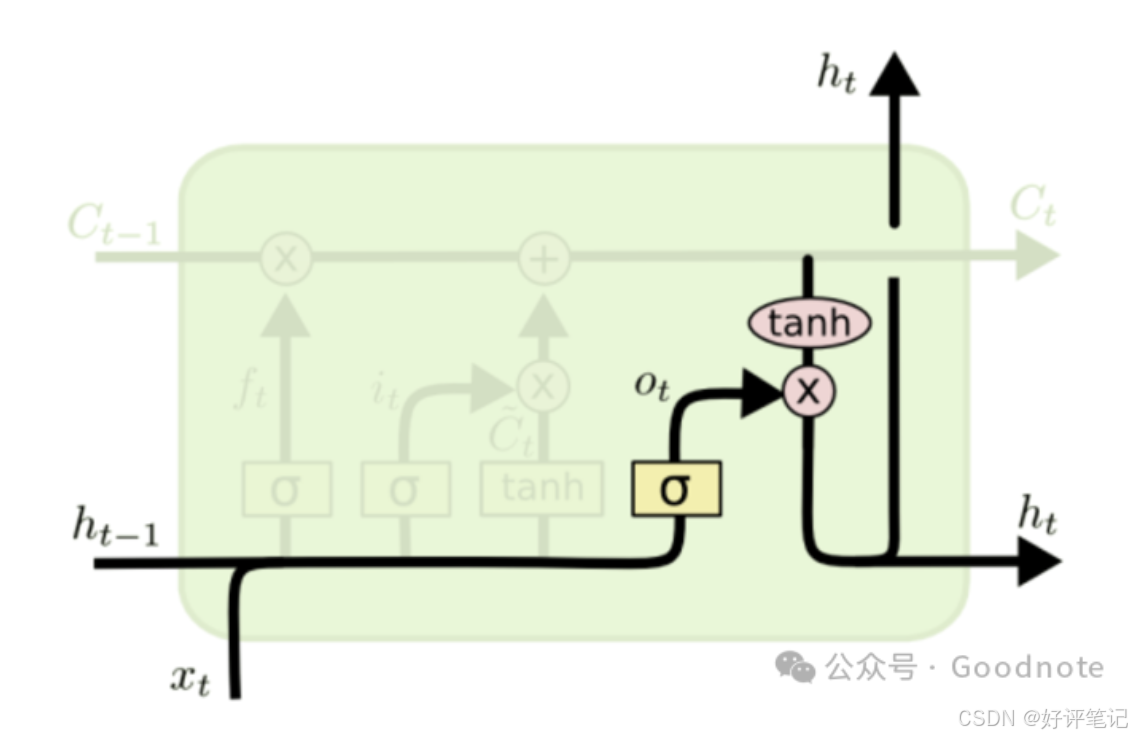
输出门控制从记忆单元中提取多少信息作为当前时间步的隐藏状态 h t h_t ht 并输出。
- 计算公式:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t - 1},x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo)- o t o_t ot:输出门的输出,决定隐藏状态的输出比例。
- W o W_o Wo、 b o b_o bo:输出门的权重和偏置。
- 生成当前隐藏状态:
h t = o t ∗ tanh ( C t ) h_t=o_t*\tanh(C_t) ht=ot∗tanh(Ct)- tanh ( C t ) \tanh(C_t) tanh(Ct):对当前的记忆单元状态 C t C_t Ct进行非线性变换,生成当前时间步的隐藏状态。
- 输出门 o t o_t ot决定了多少信息从记忆单元状态 C t C_t Ct中提取,并输出为当前时间步的隐藏状态。
输出门的作用:输出门根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前的隐藏状态 ( h t h_t ht ) 的值,它不仅作为当前时间步的输出,还会传递到下一时间步。
LSTM 的流程总结
在每个时间步 ( t t t ),LSTM 会执行以下步骤:
- 遗忘门:根据当前输入和前一个时间步的隐藏状态,控制哪些来自上一个时间步的记忆单元信息需要被保留或遗忘。
- 输入门:根据当前输入和前一时间步的隐藏状态,决定当前输入信息是否更新到记忆单元中,通过候选记忆生成新的信息。
- 记忆单元状态更新:根据遗忘门和输入门的输出,更新当前时间步的记忆单元状态 ( C t C_t Ct )。
- 输出门:根据当前的输入和记忆单元状态,控制当前时间步的隐藏状态 ( h t h_t ht ) 的输出,隐藏状态会传递到下一时间步,作为当前的输出结果。
LSTM 的优点
LSTM 通过引入门控机制,可以选择性地控制信息的流动;记忆单元可以有效地保留长期信息,避免了传统 RNN 中的梯度消失问题。因此,LSTM 能够同时处理短期和长期的依赖关系,尤其在需要保留较长时间跨度信息的任务中表现优异。
LSTM 的局限性
LSTM 的门控机制使得它的结构复杂,训练时间较长,需要更多的计算资源,尤其是在处理大规模数据时。依赖于序列数据的时间步信息,必须按顺序处理每个时间步,难以并行化处理序列数据。
热门专栏
机器学习
机器学习笔记合集
深度学习
深度学习笔记合集
相关文章:
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...
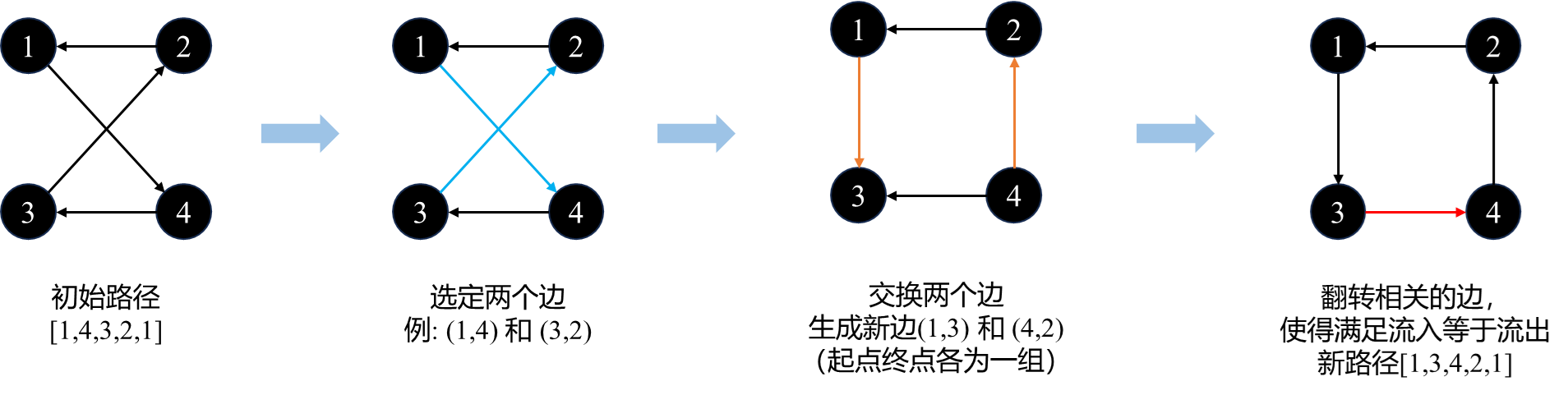
算法整理:2-opt求解旅行商(Python代码)
文章目录 算法思想算法步骤代码1纯函数代码2纯函数数据可视化 算法思想 通过交换边进行寻优。 算法步骤 把初始解作为当前解 通过交换边生成新解 如果新解优于历史最优解,则更新当前解为新解 重复2,3,直到当前解交换了所有的边均不能改…...

状态模式
在软件开发过程中,我们经常会遇到这样的情况:一个对象的行为会随着其内部状态的改变而发生变化。例如,一个手机在不同状态下(开机、关机、静音等)对相同的操作(如来电)会有不同的反应。传统的解…...

RoHS 简介
RoHS(Restriction of Hazardous Substances Directive,限制有害物质指令)是欧盟制定的一项环保法规,旨在限制电气和电子设备中某些有害物质的使用,以减少这些产品对环境和人体健康的危害。 RoHS限制的有害物质及其限量…...

【Vim Masterclass 笔记26】S11L46:Vim 插件的安装、使用与日常管理
文章目录 Section 11:Vim PluginsS11L46 Managing Vim Plugins1 第三方插件管理工具2 安装插件使用的搜索引擎3 Vim 插件的安装方法4 存放 Vim 插件包的路径格式5 示例一:插件 NERDTree 的安装6 示例二:插件 ctrlp.vim 的安装7 示例三&#x…...

深度学习原理与Pytorch实战
深度学习原理与Pytorch实战 第2版 强化学习人工智能神经网络书籍 python动手学深度学习框架书 TransformerBERT图神经网络: 技术讲解 编辑推荐 1.基于PyTorch新版本,涵盖深度学习基础知识和前沿技术,由浅入深,通俗易懂…...

ELK环境搭建
文章目录 1.ElasticSearch安装1.安装的版本选择1.SpringBoot版本:2.4.2 找到依赖的spring-data-elasticsearch的版本2.spring-data-elasticsearch版本:4.1.3 找到依赖的elasticsearch版本3.elasticsearch版本:7.9.3 2.安装1.官方文档2.下载压…...
基于Springboot + vue实现的民俗网
“前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:人工智能学习网站” 💖学习知识需费心, 📕整理归纳更费神。 🎉源码免费人人喜…...
第24篇 基于ARM A9处理器用汇编语言实现中断<六>
Q:怎样设计ARM处理器汇编语言程序使用定时器中断实现实时时钟? A:此前我们曾使用轮询定时器I/O的方式实现实时时钟,而在本实验中将采用定时器中断的方式。新增第三个中断源A9 Private Timer,对该定时器进行配置&#…...
【数据结构】_不带头非循环单向链表
目录 1. 链表的概念及结构 2. 链表的分类 3. 单链表的实现 3.1 SList.h头文件 3.2 SList.c源文件 3.3 Test_SList.c测试文件 关于线性表,已介绍顺序表,详见下文: 【数据结构】_顺序表-CSDN博客 本文介绍链表; 基于顺序表…...

golang 使用双向链表作为container/heap的载体
MyHeap:container/heap的数据载体,需要实现以下方法: Len:堆中数据个数 Less:第i个元素 是否必 第j个元素 值小 Swap:交换第i个元素和 第j个元素 Push:向堆中追加元素 Pop:从堆…...

C#集合操作优化:高效实现批量添加与删除
在C#中,对集合进行批量操作(如批量添加或删除元素)通常涉及使用集合类型提供的方法和特性,以及可能的循环或LINQ查询来高效地处理大量数据。以下是一些常见的方法和技巧: 批量添加元素 使用集合的AddRange方法&#x…...

142.WEB渗透测试-信息收集-小程序、app(13)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:141.WEB渗透测试-信息收集-小程序、app(12) 软件用法,…...

24.日常算法
1. 数组中两元素的最大乘积 题目来源 给你一个整数数组 nums,请你选择数组的两个不同下标 i 和 j,使 (nums[i]-1)*(nums[j]-1) 取得最大值。请你计算并返回该式的最大值。 示例 1: 输入:nums [3,4,5,2] 输出:12 解释…...
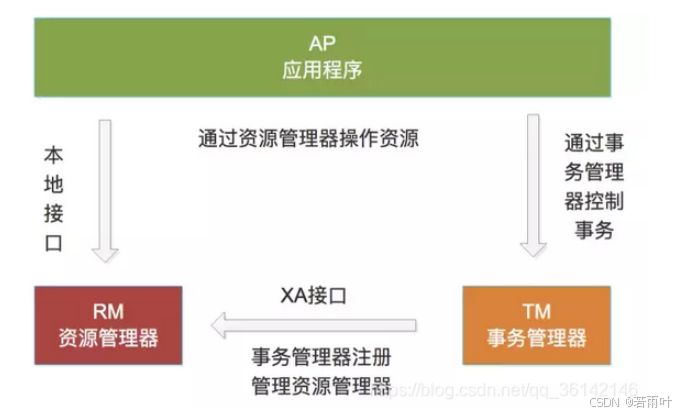
分布式理解
分布式 如何理解分布式 狭义的分布是指,指多台PC在地理位置上分布在不同的地方。 分布式系统 分布式系**统:**多个能独立运行的计算机(称为结点)组成。各个结点利用计算机网络进行信息传递,从而实现共同的“目标或者任…...

wordpress调用指定ID页面的链接
在WordPress中,如果你想调用一个指定ID的页面链接,可以使用以下几种方法: 方法一:使用页面ID 你可以直接使用页面的ID来生成链接。例如,如果你想链接到ID为123的页面,可以使用以下代码: <…...
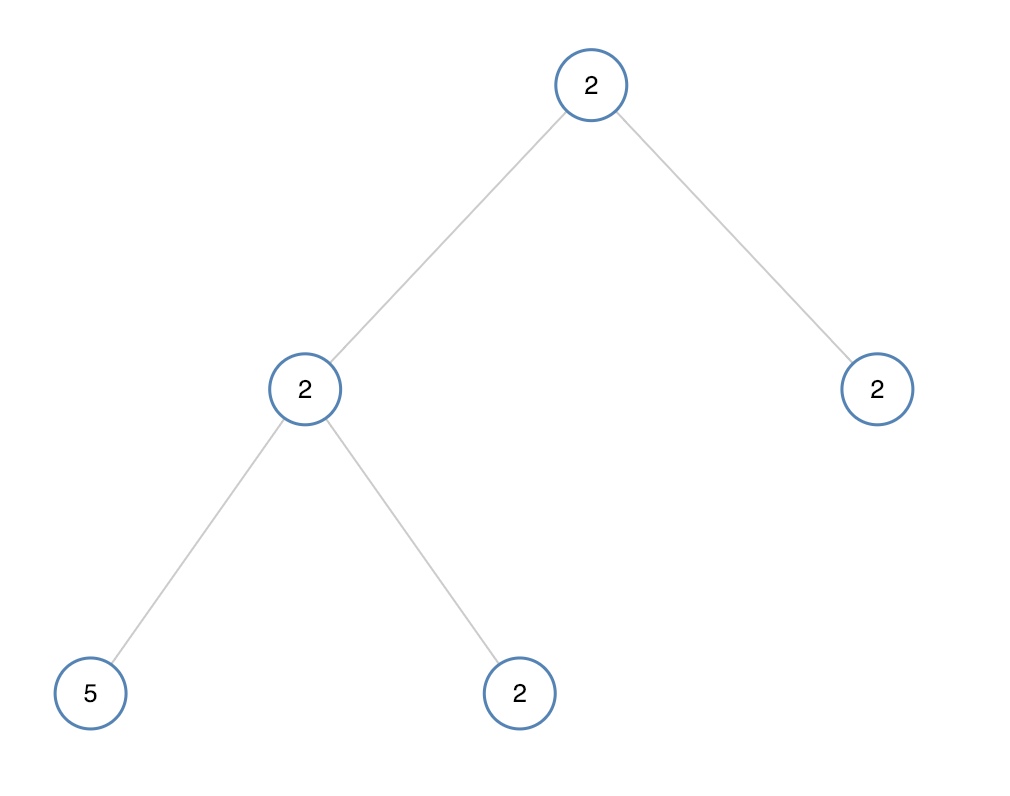
单值二叉树(C语言详解版)
一、摘要 今天要讲的是leetcode单值二叉树,这里用到的C语言,主要提供的是思路,大家看了我的思路之后可以点击链接自己试一下。 二、题目简介 如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。 只有给定的树是单…...
python学opencv|读取图像(四十二)使用cv2.add()函数实现多图像叠加
【1】引言 前序学习过程中,掌握了灰度图像和彩色图像的掩模操作: python学opencv|读取图像(九)用numpy创建黑白相间灰度图_numpy生成全黑图片-CSDN博客 python学opencv|读取图像(四十)掩模:三…...

速通Docker === Docker Compose
目录 Docker Compose 简介 Docker Compose 常用命令 使用 Docker Compose 启动 WordPress 普通启动方式(使用 Docker 命令) 使用 Docker Compose 启动 Docker Compose 的特性 Docker Compose 简介 Docker Compose 是一个用于定义和运行多容器 Dock…...
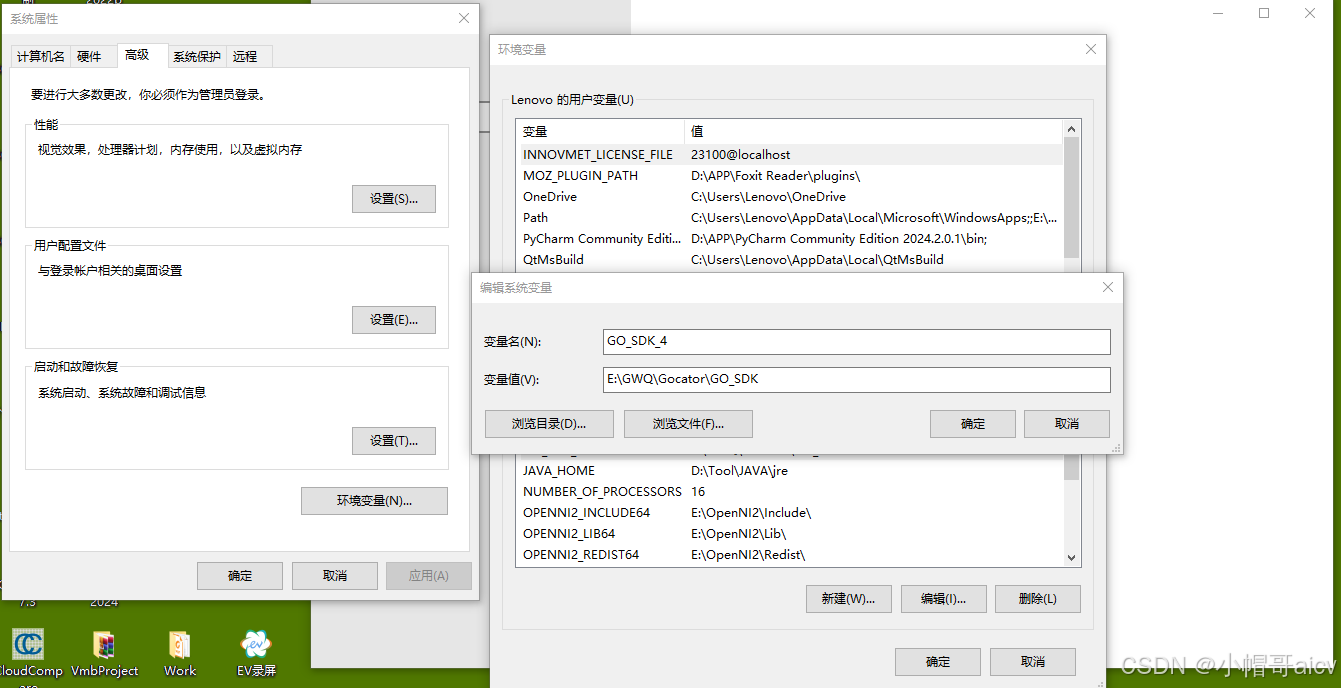
LMI Gocator GO_SDK VS2019引用配置
LMI SDK在VS2019中的引用是真的坑爹,总结一下经验,希望后来的人能少走弯路.大致内容如下: (1) 环境变量 (2)C/C 附加包含目录 E:\GWQ\Gocator\GO_SDK\Gocator\GoSdk E:\GWQ\Gocator\GO_SDK\Platform\kApi (3&#…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...