论文速读|SigLIP:Sigmoid Loss for Language Image Pre-Training.ICCV23
论文地址:https://arxiv.org/abs/2303.15343v4
代码地址:https://github.com/google-research/big_vision
bib引用:
@misc{zhai2023sigmoidlosslanguageimage,title={Sigmoid Loss for Language Image Pre-Training}, author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},year={2023},eprint={2303.15343},archivePrefix={arXiv},primaryClass={cs.CV},url={https://arxiv.org/abs/2303.15343},
}
InShort
提出用于语言 - 图像预训练的Sigmoid损失函数(SigLIP),该函数相比传统Softmax损失函数,在内存效率、训练效率和小批量训练性能上具有优势。研究发现32k的批量大小在对比学习中接近最优,为语言 - 图像预训练研究提供了新方向。
- 研究背景:基于网络图像 - 文本对的对比预训练成为获取通用计算机视觉骨干网络的常用方法,标准做法是使用基于softmax的对比损失。本文提出用sigmoid损失替代,其计算更简单、内存效率更高,还能解耦批量大小与任务定义。
- 相关工作
- 对比学习中的sigmoid损失:此前有工作在无监督降维任务中提出类似sigmoid损失,但在对比图像 - 文本学习中,多数工作依赖基于softmax的InfoNCE损失。在监督分类中,sigmoid损失比softmax损失更有效、更稳健。
- 对比语言 - 图像预训练:CLIP和ALIGN应用softmax对比学习,使对比语言 - 图像预训练受到关注,后续研究将其应用于多种任务。此外,还有生成式语言 - 图像预训练等多种方法。
- 高效语言 - 图像预训练:LiT、FLIP等尝试提高预训练效率,但各有局限,如LiT需预训练骨干网络,FLIP牺牲质量。BASIC和LAION虽扩大批量大小,但也存在不足。
- 方法
- Softmax损失:通过对图像和文本嵌入进行归一化,最小化匹配对和不匹配对之间的差异,公式为 − 1 2 ∣ B ∣ ∑ i = 1 ∣ B ∣ ( l o g e t x i ⋅ y i ∑ j = 1 ∣ B ∣ e t x i ⋅ y j ⏞ i m a g e → t e x t s o t h a t + l o g e t x i ⋅ y i ∑ j = 1 ∣ B ∣ e t x j ⋅ y i ⏞ t e x t → i m a g e s o f t m a x ) -\frac{1}{2|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|}(\overbrace{log \frac{e^{t x_{i} \cdot y_{i}}}{\sum_{j=1}^{|\mathcal{B}|} e^{t x_{i} \cdot y_{j}}}}^{image \to text sothat }+\overbrace{log \frac{e^{t x_{i} \cdot y_{i}}}{\sum_{j=1}^{|\mathcal{B}|} e^{t x_{j} \cdot y_{i}}}}^{text \to image softmax }) −2∣B∣1∑i=1∣B∣(log∑j=1∣B∣etxi⋅yjetxi⋅yi image→textsothat+log∑j=1∣B∣etxj⋅yietxi⋅yi text→imagesoftmax) 。
- Sigmoid损失:将学习问题转化为标准的二元分类,对每个图像 - 文本对独立处理,公式为 − 1 ∣ B ∣ ∑ i = 1 ∣ B ∣ ∑ j = 1 ∣ B ∣ l o g 1 1 + e z i j ( − t x i ⋅ y j + b ) ⏟ L i j -\frac{1}{|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|} \sum_{j=1}^{|\mathcal{B}|} \underbrace{log \frac{1}{1+e^{z_{i j}\left(-t x_{i} \cdot y_{j}+b\right)}}}_{\mathcal{L}_{i j}} −∣B∣1∑i=1∣B∣∑j=1∣B∣Lij log1+ezij(−txi⋅yj+b)1 ,并引入可学习偏差项b缓解正负样本不平衡问题。
- 高效“分块”实现:sigmoid损失采用分块计算方式,降低内存成本,提高计算效率,使大批量训练更可行。
- 实验结果
- SigLiT:在小批量(小于16k)训练时,sigmoid损失显著优于softmax损失;批量增大时,两者差距缩小。SigLiT在4个TPUv4芯片上训练1天,ImageNet零样本准确率可达79.7%;用ViT - g/14模型训练2天,准确率可提升至84.5%。
- SigLIP:在小于32k批量下,SigLIP性能优于CLIP(WebLI)基线。SigLIP在16个TPUv4芯片上训练3天,零样本准确率可达71%;从 scratch训练时,32个TPUv4芯片训练2天,准确率为72.1% ,训练成本显著低于CLIP。
- mSigLIP:多语言预训练中,32k批量已足够,更大批量会降低性能。mSigLIP在XM3600跨模态检索任务上达到新的最先进水平,Base模型的图像检索召回率@1为42.6%,文本检索召回率@1为54.1%。
- 其他实验:研究发现减小Adam和AdaFactor中的β2可稳定大批量训练;sigmoid损失中的正负样本比例不平衡问题影响不大,但有效挖掘负样本可能有益;引入偏差项可提升性能;SigLIP对标签噪声更具鲁棒性。
- 研究结论:sigmoid损失在小批量训练时性能优于softmax损失,内存效率更高,32k批量接近最优。研究为有限资源下的语言 - 图像预训练提供了参考,推动该领域进一步发展。
相关文章:

论文速读|SigLIP:Sigmoid Loss for Language Image Pre-Training.ICCV23
论文地址:https://arxiv.org/abs/2303.15343v4 代码地址:https://github.com/google-research/big_vision bib引用: misc{zhai2023sigmoidlosslanguageimage,title{Sigmoid Loss for Language Image Pre-Training}, author{Xiaohua Zhai and…...
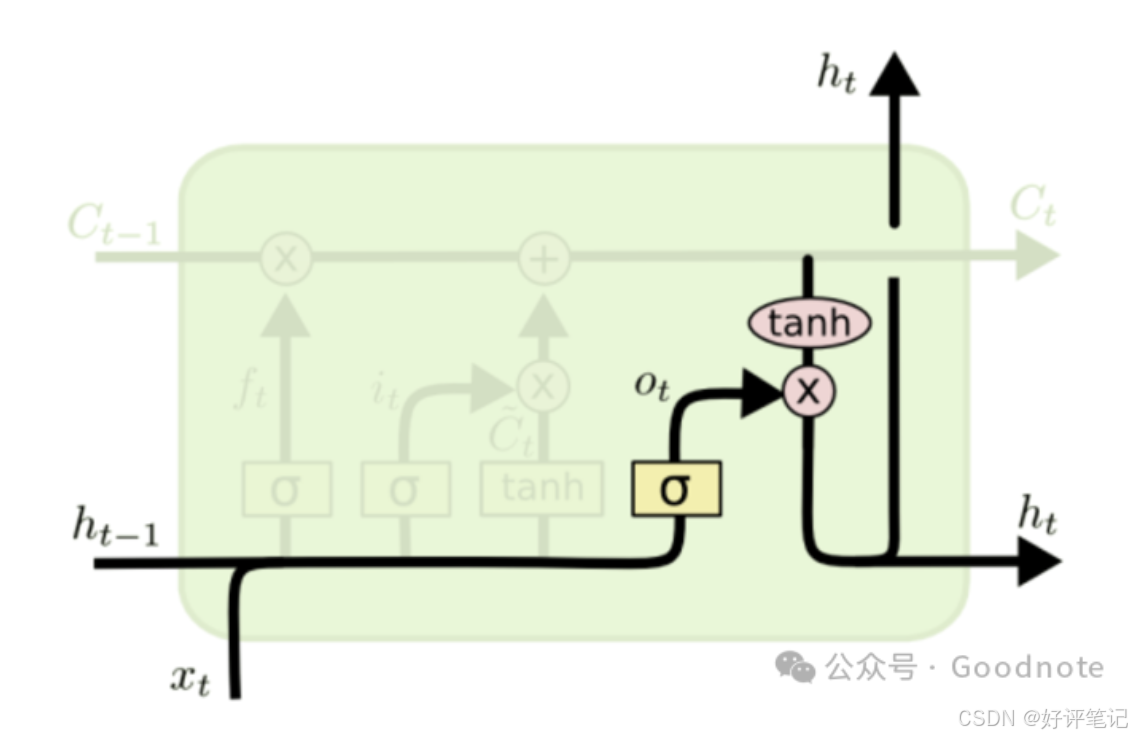
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...
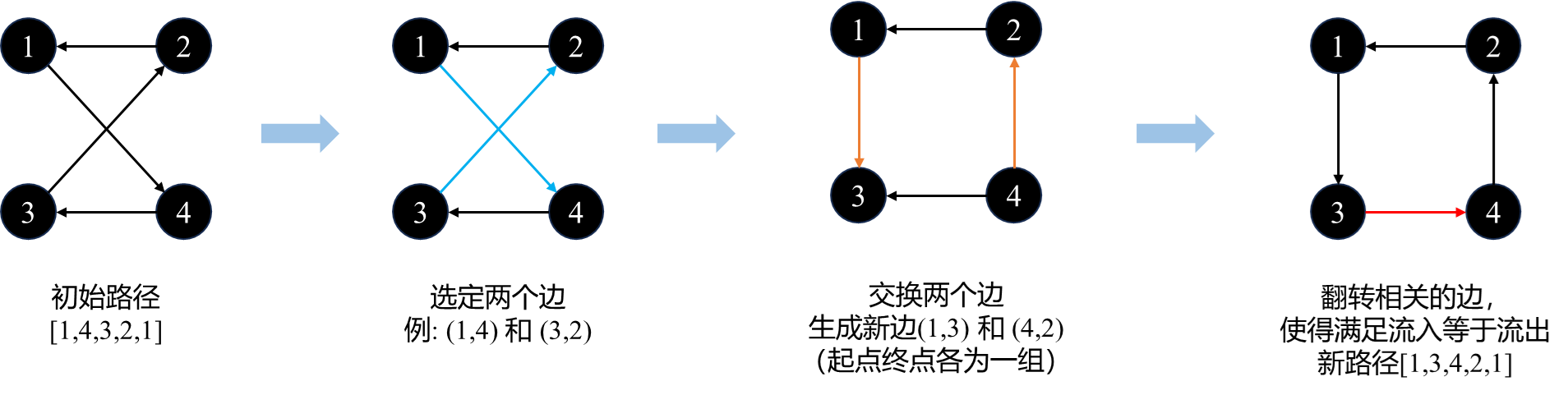
算法整理:2-opt求解旅行商(Python代码)
文章目录 算法思想算法步骤代码1纯函数代码2纯函数数据可视化 算法思想 通过交换边进行寻优。 算法步骤 把初始解作为当前解 通过交换边生成新解 如果新解优于历史最优解,则更新当前解为新解 重复2,3,直到当前解交换了所有的边均不能改…...

状态模式
在软件开发过程中,我们经常会遇到这样的情况:一个对象的行为会随着其内部状态的改变而发生变化。例如,一个手机在不同状态下(开机、关机、静音等)对相同的操作(如来电)会有不同的反应。传统的解…...

RoHS 简介
RoHS(Restriction of Hazardous Substances Directive,限制有害物质指令)是欧盟制定的一项环保法规,旨在限制电气和电子设备中某些有害物质的使用,以减少这些产品对环境和人体健康的危害。 RoHS限制的有害物质及其限量…...

【Vim Masterclass 笔记26】S11L46:Vim 插件的安装、使用与日常管理
文章目录 Section 11:Vim PluginsS11L46 Managing Vim Plugins1 第三方插件管理工具2 安装插件使用的搜索引擎3 Vim 插件的安装方法4 存放 Vim 插件包的路径格式5 示例一:插件 NERDTree 的安装6 示例二:插件 ctrlp.vim 的安装7 示例三&#x…...

深度学习原理与Pytorch实战
深度学习原理与Pytorch实战 第2版 强化学习人工智能神经网络书籍 python动手学深度学习框架书 TransformerBERT图神经网络: 技术讲解 编辑推荐 1.基于PyTorch新版本,涵盖深度学习基础知识和前沿技术,由浅入深,通俗易懂…...

ELK环境搭建
文章目录 1.ElasticSearch安装1.安装的版本选择1.SpringBoot版本:2.4.2 找到依赖的spring-data-elasticsearch的版本2.spring-data-elasticsearch版本:4.1.3 找到依赖的elasticsearch版本3.elasticsearch版本:7.9.3 2.安装1.官方文档2.下载压…...
基于Springboot + vue实现的民俗网
“前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:人工智能学习网站” 💖学习知识需费心, 📕整理归纳更费神。 🎉源码免费人人喜…...
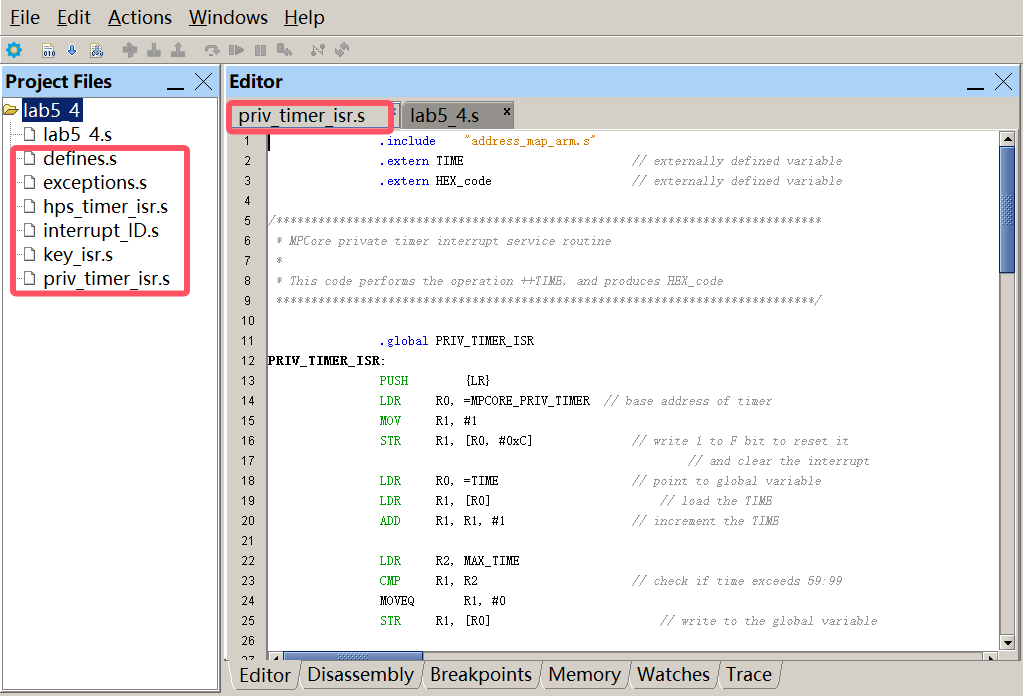
第24篇 基于ARM A9处理器用汇编语言实现中断<六>
Q:怎样设计ARM处理器汇编语言程序使用定时器中断实现实时时钟? A:此前我们曾使用轮询定时器I/O的方式实现实时时钟,而在本实验中将采用定时器中断的方式。新增第三个中断源A9 Private Timer,对该定时器进行配置&#…...
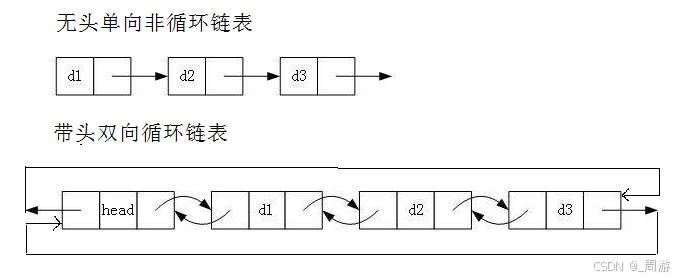
【数据结构】_不带头非循环单向链表
目录 1. 链表的概念及结构 2. 链表的分类 3. 单链表的实现 3.1 SList.h头文件 3.2 SList.c源文件 3.3 Test_SList.c测试文件 关于线性表,已介绍顺序表,详见下文: 【数据结构】_顺序表-CSDN博客 本文介绍链表; 基于顺序表…...

golang 使用双向链表作为container/heap的载体
MyHeap:container/heap的数据载体,需要实现以下方法: Len:堆中数据个数 Less:第i个元素 是否必 第j个元素 值小 Swap:交换第i个元素和 第j个元素 Push:向堆中追加元素 Pop:从堆…...

C#集合操作优化:高效实现批量添加与删除
在C#中,对集合进行批量操作(如批量添加或删除元素)通常涉及使用集合类型提供的方法和特性,以及可能的循环或LINQ查询来高效地处理大量数据。以下是一些常见的方法和技巧: 批量添加元素 使用集合的AddRange方法&#x…...

142.WEB渗透测试-信息收集-小程序、app(13)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:141.WEB渗透测试-信息收集-小程序、app(12) 软件用法,…...

24.日常算法
1. 数组中两元素的最大乘积 题目来源 给你一个整数数组 nums,请你选择数组的两个不同下标 i 和 j,使 (nums[i]-1)*(nums[j]-1) 取得最大值。请你计算并返回该式的最大值。 示例 1: 输入:nums [3,4,5,2] 输出:12 解释…...
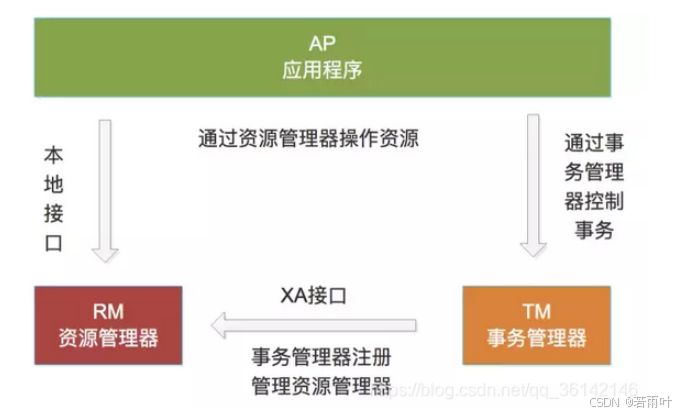
分布式理解
分布式 如何理解分布式 狭义的分布是指,指多台PC在地理位置上分布在不同的地方。 分布式系统 分布式系**统:**多个能独立运行的计算机(称为结点)组成。各个结点利用计算机网络进行信息传递,从而实现共同的“目标或者任…...

wordpress调用指定ID页面的链接
在WordPress中,如果你想调用一个指定ID的页面链接,可以使用以下几种方法: 方法一:使用页面ID 你可以直接使用页面的ID来生成链接。例如,如果你想链接到ID为123的页面,可以使用以下代码: <…...
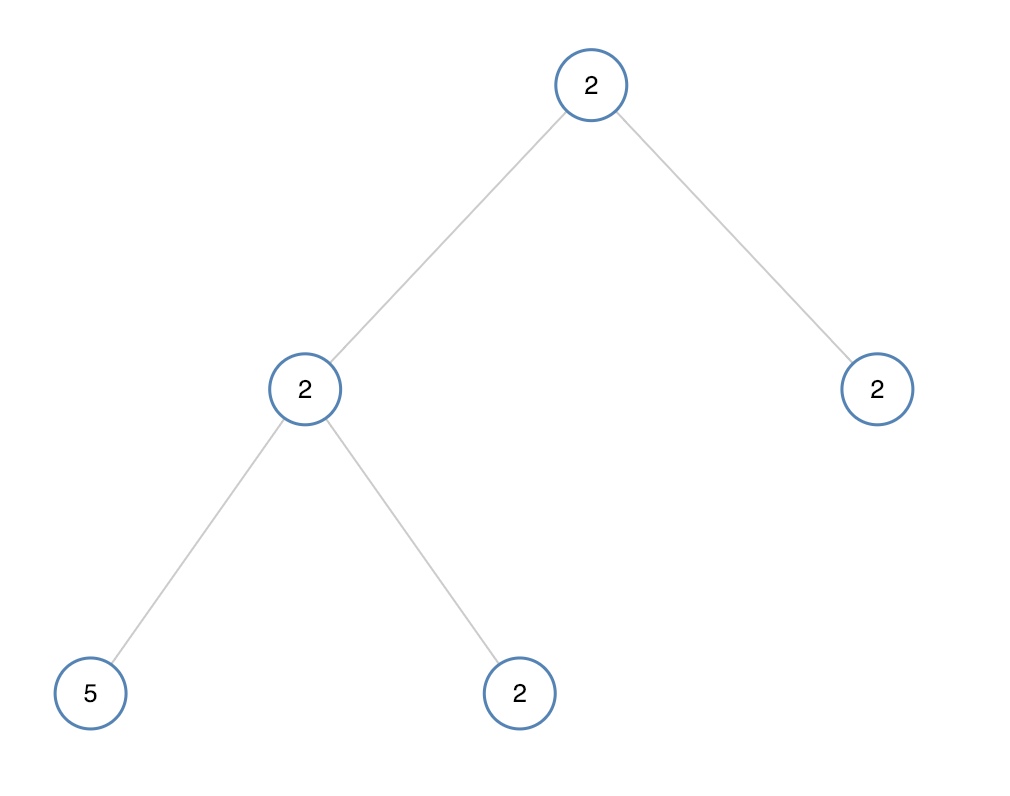
单值二叉树(C语言详解版)
一、摘要 今天要讲的是leetcode单值二叉树,这里用到的C语言,主要提供的是思路,大家看了我的思路之后可以点击链接自己试一下。 二、题目简介 如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。 只有给定的树是单…...
python学opencv|读取图像(四十二)使用cv2.add()函数实现多图像叠加
【1】引言 前序学习过程中,掌握了灰度图像和彩色图像的掩模操作: python学opencv|读取图像(九)用numpy创建黑白相间灰度图_numpy生成全黑图片-CSDN博客 python学opencv|读取图像(四十)掩模:三…...

速通Docker === Docker Compose
目录 Docker Compose 简介 Docker Compose 常用命令 使用 Docker Compose 启动 WordPress 普通启动方式(使用 Docker 命令) 使用 Docker Compose 启动 Docker Compose 的特性 Docker Compose 简介 Docker Compose 是一个用于定义和运行多容器 Dock…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...