PSPNet
文章目录
- 摘要
- Abstract
- 1. 引言
- 2. 框架
- 2.1 金字塔池化模块
- 2.2 特征提取器的监督
- 2.3 训练细节
- 3. 创新点和不足
- 3.1 创新点
- 3.2 不足
- 参考
- 总结
摘要
PSPNet是一个改进了FCN-8s缺点的语义分割模型,它解决了FCN-8s的缺点——分割不够精细以及没有考虑上下文信息。PSPNet的核心创新之一是引入了金字塔池化模块,该模块通过不同尺度的池化操作来捕捉全局和局部的上下文信息。具体来说,金字塔池化模块将特征图划分为不同大小的子区域,对每个子区域进行池化操作,然后将这些不同尺度的特征图上采样并融合,从而生成包含多尺度上下文信息的特征表示。此外,PSPNet提出了基于深度监督损失的优化策略。在训练过程中,除了主分支的分割损失外,还引入了辅助分支的分类损失。辅助分支连接在ResNet的中间层,通过计算分类损失来优化中间层的特征表示。这种策略不仅加速了模型的训练收敛,还提高了模型对全局特征的学习能力。尽管PSPNet在语义分割上效果好,但是它也存在如下的缺点:分割精度的提升是以计算复杂度提升为代价的;它在小目标上分割效果不佳。
Abstract
PSPNet is a semantic segmentation model that improves upon the shortcomings of FCN-8s, addressing its lack of fine segmentation and failure to consider contextual information. One of PSPNet’s core innovations is the introduction of the pyramid pooling module, which captures both global and local contextual information through multi-scale pooling operations. Specifically, the pyramid pooling module divides the feature map into subregions of different sizes, performs pooling operations on each subregion, then upsamples and fuses these multi-scale feature maps to generate a feature representation enriched with multi-scale contextual information.
Additionally, PSPNet proposes an optimization strategy based on deep supervision loss. During training, in addition to the segmentation loss from the main branch, an auxiliary classification loss is introduced. The auxiliary branch is connected to an intermediate layer of ResNet and optimizes the feature representation of this intermediate layer through classification loss. This strategy not only accelerates the convergence of model training but also enhances the model’s ability to learn global features.
Although PSPNet achieves strong performance in semantic segmentation, it also has the following drawbacks: the improvement in segmentation accuracy comes at the cost of increased computational complexity, and its performance on small objects is suboptimal.
1. 引言
在计算机视觉中,场景解析是在语义分割上衍生出来的任务,因此它不仅要预测每个像素的类别标签,而且还要在语义分割的效果图上给出颜色和类别的对应关系。从场景解析的任务要求上,可以看出它对自动驾驶、机器人感知等应用有帮助。
场景解析的难度与场景和标签的多样性密切相关。场景解析的模型大多数都是基于全卷积神经网络的,尽管这些基于卷积神经网络的方法能理解动态对象,但是仍然面临挑战——场景解析需要处理多种多样的场景,并且场景中包含物体的类别标签可能超出预定义的固定词汇表范围。此外,由于不同物体之间外表相似的缘故,场景解析可能会把一个物体误认成另一个物体。但是这个问题可以通过空间金字塔池化利用物体周围的上下文信息来解决。
2. 框架
PSPNet的运行流程:首先输入图片经过一个卷积神经网络(基于残差神经网络的全卷积网络)进行特征提取,提取后的特征图再经过金字塔池化模型得到四个不同大小的特征图,接着对这些特征图进行上采样使得它们的尺寸与输入前的特征图一致,然后将输入前的特征图与这四个上采样后的特征图进行拼接,最后对拼接后的特征图先进行卷积,再进行逐像素的预测。

2.1 金字塔池化模块
尽管全局平均池化也是一个全局上下文先验,但是由于全局平均池化直接把特征图变成了一个在通道维度上的向量会导致空间关系的丢失并引起歧义。全局上下文信息和子区域上下文对于区分不同物体的类别是有帮助的,因此论文提出了金字塔池化模块来利用全局上下文和子区域上下文,同时希望减少不同子区域之间的上下文信息损失。
金字塔池化模块有四个不同的金字塔规格,其中用红色标记的级别使用了全局池化,接下来三个金字塔级别将特征图分成不同的子区域,并形成不同位置的池化表示。金字塔池化模块中不同级别的输出包含不同大小的特征图,接着这些特征图会经过一个卷积核大小为 1 × 1 1\times1 1×1,过滤器个数为1的卷积层,最终得到四个通道数为1的子区域特征图(论文中四个特征图的尺寸分别为 1 × 1 1\times1 1×1, 2 × 2 2\times2 2×2, 3 × 3 3\times3 3×3, 6 × 6 6\times6 6×6)。这一步的目的是为了保证全局特征图在最终输出特征图中所占比重高。金字塔池化模块的最终输出是将输入特征图(全局特征图)和四个经过双线性插值上采样回输入特征图尺寸的子区域特征图进行拼接后得到的特征图。

2.2 特征提取器的监督
论文利用特征提取器中间层产生的特征图来计算分类损失Loss2,同时利用特征提取器的最终结果经过PSPNet中后续的模块来产生分割损失Loss1。因此PSPNet的最终损失等于分割损失Loss1加上0.4倍的分类损失Loss2,对分类损失Loss2乘上权重的目的旨在使分割损失对模型的训练起主导作用,而分类损失用来辅助模型更好地进行特征提取。在训练阶段,辅助损失和最终损失共同指导网络的训练过程,但在测试阶段,通常只使用经过优化的主分支进行预测。

下面是特征提取器ResNet101的PyTorch实现。
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import model_zoodef load_weights_sequential(target, source_state):new_dict = OrderedDict()for (k1, v1), (k2, v2) in zip(target.state_dict().items(), source_state.items()):new_dict[k1] = v2target.load_state_dict(new_dict)model_urls = {'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
}def conv3x3(in_planes, out_planes, stride=1, dilation=1):return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,padding=dilation, dilation=dilation, bias=False)class Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,padding=dilation, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * 4)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers=(3, 4, 23, 3)):self.inplanes = 64super(ResNet, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2)self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4)for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _make_layer(self, block, planes, blocks, stride=1, dilation=1):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = [block(self.inplanes, planes, stride, downsample)]self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes, dilation=dilation))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x_3 = self.layer3(x)x = self.layer4(x_3)return x, x_3def resnet101(pretrained=True):model = ResNet(Bottleneck, [3, 4, 23, 3])if pretrained:load_weights_sequential(model, model_zoo.load_url(model_urls['resnet101']))return model
2.3 训练细节
下面是PSPNet的PyTorch实现。
class PSPModule(nn.Module):def __init__(self, features, out_features=1024, sizes=(1, 2, 3, 6)):super().__init__()self.stages = []self.stages = nn.ModuleList([self._make_stage(features, size) for size in sizes])self.bottleneck = nn.Conv2d(features * (len(sizes) + 1), out_features, kernel_size=1)self.relu = nn.ReLU()def _make_stage(self, features, size):prior = nn.AdaptiveAvgPool2d(output_size=(size, size))conv = nn.Conv2d(features, features, kernel_size=1, bias=False)return nn.Sequential(prior, conv)def forward(self, feats):h, w = feats.size(2), feats.size(3)priors = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.stages] + [feats]bottle = self.bottleneck(torch.cat(priors, 1))return self.relu(bottle)class PSPUpsample(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1),nn.BatchNorm2d(out_channels),nn.PReLU())def forward(self, x):h, w = 2 * x.size(2), 2 * x.size(3)p = F.upsample(input=x, size=(h, w), mode='bilinear')return self.conv(p)class PSPNet(nn.Module):def __init__(self, n_classes=18, sizes=(1, 2, 3, 6), psp_size=2048, deep_features_size=1024, backend='resnet34',pretrained=True):super().__init__()self.feats = getattr(extractors, backend)(pretrained)self.psp = PSPModule(psp_size, 1024, sizes)self.drop_1 = nn.Dropout2d(p=0.3)self.up_1 = PSPUpsample(1024, 256)self.up_2 = PSPUpsample(256, 64)self.up_3 = PSPUpsample(64, 64)self.drop_2 = nn.Dropout2d(p=0.15)self.final = nn.Sequential(nn.Conv2d(64, n_classes, kernel_size=1),nn.LogSoftmax())self.classifier = nn.Sequential(nn.Linear(deep_features_size, 256),nn.ReLU(),nn.Linear(256, n_classes))def forward(self, x):f, class_f = self.feats(x) p = self.psp(f)p = self.drop_1(p)p = self.up_1(p)p = self.drop_2(p)p = self.up_2(p)p = self.drop_2(p)p = self.up_3(p)p = self.drop_2(p)auxiliary = F.adaptive_max_pool2d(input=class_f, output_size=(1, 1)).view(-1, class_f.size(1))return self.final(p), self.classifier(auxiliary)
下面是训练过程的代码。
from torch import optim
from torch.optim.lr_scheduler import MultiStepLR
from torch.autograd import Variable
from torch.utils.data import DataLoaderfrom tqdm import tqdm
import click
import numpy as npmodels = {'resnet101': lambda: PSPNet(sizes=(1, 2, 3, 6), psp_size=2048, deep_features_size=1024, backend='resnet101')
}def build_network(snapshot, backend):epoch = 0backend = backend.lower()net = models[backend]()net = nn.DataParallel(net)if snapshot is not None:_, epoch = os.path.basename(snapshot).split('_')epoch = int(epoch)net.load_state_dict(torch.load(snapshot))logging.info("Snapshot for epoch {} loaded from {}".format(epoch, snapshot))net = net.cuda()return net, epoch@click.command()
@click.option('--data-path', type=str, help='Path to dataset folder')
@click.option('--models-path', type=str, help='Path for storing model snapshots')
@click.option('--backend', type=str, default='resnet34', help='Feature extractor')
@click.option('--snapshot', type=str, default=None, help='Path to pretrained weights')
@click.option('--crop_x', type=int, default=256, help='Horizontal random crop size')
@click.option('--crop_y', type=int, default=256, help='Vertical random crop size')
@click.option('--batch-size', type=int, default=16)
@click.option('--alpha', type=float, default=1.0, help='Coefficient for classification loss term')
@click.option('--epochs', type=int, default=20, help='Number of training epochs to run')
@click.option('--gpu', type=str, default='0', help='List of GPUs for parallel training, e.g. 0,1,2,3')
@click.option('--start-lr', type=float, default=0.001)
@click.option('--milestones', type=str, default='10,20,30', help='Milestones for LR decreasing')
def train(data_path, models_path, backend, snapshot, crop_x, crop_y, batch_size, alpha, epochs, start_lr, milestones, gpu):os.environ["CUDA_VISIBLE_DEVICES"] = gpunet, starting_epoch = build_network(snapshot, backend)data_path = os.path.abspath(os.path.expanduser(data_path))models_path = os.path.abspath(os.path.expanduser(models_path))os.makedirs(models_path, exist_ok=True)train_loader, class_weights, n_images = None, None, Noneoptimizer = optim.Adam(net.parameters(), lr=start_lr)scheduler = MultiStepLR(optimizer, milestones=[int(x) for x in milestones.split(',')])for epoch in range(starting_epoch, starting_epoch + epochs):seg_criterion = nn.NLLLoss2d(weight=class_weights)cls_criterion = nn.BCEWithLogitsLoss(weight=class_weights)epoch_losses = []train_iterator = tqdm(loader, total=max_steps // batch_size + 1)net.train()for x, y, y_cls in train_iterator:steps += batch_sizeoptimizer.zero_grad()x, y, y_cls = Variable(x).cuda(), Variable(y).cuda(), Variable(y_cls).cuda()out, out_cls = net(x)seg_loss, cls_loss = seg_criterion(out, y), cls_criterion(out_cls, y_cls)loss = seg_loss + alpha * cls_lossepoch_losses.append(loss.data[0])status = '[{0}] loss = {1:0.5f} avg = {2:0.5f}, LR = {5:0.7f}'.format(epoch + 1, loss.data[0], np.mean(epoch_losses), scheduler.get_lr()[0])train_iterator.set_description(status)loss.backward()optimizer.step()scheduler.step()torch.save(net.state_dict(), os.path.join(models_path, '_'.join(["PSPNet", str(epoch + 1)])))train_loss = np.mean(epoch_losses)
3. 创新点和不足
3.1 创新点
PSPNet的核心创新之一是引入了金字塔池化模块,该模块通过不同尺度的池化操作来捕捉全局和局部的上下文信息。具体来说,PPM将特征图划分为不同大小的子区域(如 1×1、2×2、3×3、6×6),对每个子区域进行池化操作,然后将这些不同尺度的特征图上采样并融合,从而生成包含多尺度上下文信息的特征表示。此外,PSPNet提出了基于深度监督损失的优化策略。在训练过程中,除了主分支的分割损失外,还引入了辅助分支的分类损失。辅助分支连接在ResNet的中间层,通过计算分类损失来优化中间层的特征表示。这种策略不仅加速了模型的训练收敛,还提高了模型对全局特征的学习能力。
3.2 不足
PSPNet通过金字塔池化模块来捕捉多尺度的上下文信息,虽然提高了分割精度,但同时也显著增加了计算复杂度。这使得PSPNet在处理高分辨率图像时需要更多的计算资源,训练和推理速度相对较慢。此外,尽管PSPNet通过金字塔池化模块能够较好地处理大尺度的上下文信息,但在处理小目标时,其性能可能不如一些专门针对小目标优化的模型。这是因为小目标可能在全局上下文中占比过小,容易被忽略。
参考
Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, and et al. Pyramid Scene Parsing Network.
代码来源:https://github.com/Lextal/pspnet-pytorch
总结
PSPNet解决了全卷积神经网络在语义分割上的缺点——分割不够精细以及没有考虑上下文信息。PSPNet的运行流程:首先输入图片经过一个卷积神经网络(基于残差神经网络的全卷积网络)进行特征提取,提取后的特征图再经过金字塔池化模型得到四个不同大小的特征图,接着对这些特征图进行上采样使得它们的尺寸与输入前的特征图一致,然后将输入前的特征图与这四个上采样后的特征图进行拼接,最后对拼接后的特征图先进行卷积,再进行逐像素的预测。此外,尽管PSPNet在语义分割上效果好,但是它也存在如下的缺点:分割精度的提升是以计算复杂度提升为代价的;它在小目标上分割效果不佳。
相关文章:
PSPNet
文章目录 摘要Abstract1. 引言2. 框架2.1 金字塔池化模块2.2 特征提取器的监督2.3 训练细节 3. 创新点和不足3.1 创新点3.2 不足 参考总结 摘要 PSPNet是一个改进了FCN-8s缺点的语义分割模型,它解决了FCN-8s的缺点——分割不够精细以及没有考虑上下文信息。PSPNet的…...
:Understanding Diffusion Models: A Unified Perspective(二):公式46的推导)
论文阅读的附录(七):Understanding Diffusion Models: A Unified Perspective(二):公式46的推导
Understanding Diffusion Models: A Unified Perspective(二):公式46的推导 文章概括要推导的公式1. 条件概率的定义2. 联合分布的分解2.1 联合分布的定义2.2 为什么可以这样分解?2.3 具体意义 3. 分母的分解:边际化规…...

BGP分解实验·12——配置路由反射器
当一个AS包含多个iBGP对等体时,路由反射器(Route-Reflector)非常有用,因为相对于iBGP路由反射器指定的客户端只需要和路由反射器建立邻居关系,从而降低了iBGP全互连的连接数量。路由反射器(RR)和…...

PCIe 个人理解专栏——【2】LTSSM(Link Training and Status State Machine)
前言: 链路训练和状况状态机LTSSM(Link Training and Status State Machine)是整个链路训练和运行中状态的状态转换逻辑关系图,总共有11个状态。 正文: 包括检测(Detect),轮询&…...

cmake 编译QT之JKQtPlotter-4.0.3
cmake 编译 JKQtPlotter-4.0.3 1.下载源码 源码地址:https://github.com/jkriege2/JKQtPlotter 2.编译 mkdir build cd buildDCMAKE_PREFIX_PATH指编译器目录 D:\ProgramFiles\cmake-3.25.0-rc1-windows-i386\bin\cmake.exe -G "Visual Studio 16 2019&qu…...

【C】memory 详解
<memory.h> 是一个 C 标准库头文件,提供了一组内存管理函数,用于分配、释放和操作动态内存。这些函数主要操作的是未初始化的内存块,是早期 C 编程中常用的内存操作工具。 尽管在现代 C 编程中更推荐使用<cstring>或<memory&…...
Python 爬虫 - Selenium 框架
Python 爬虫 - Selenium 框架 安装安装 Selenium安装 WebDriver 操作浏览器打开浏览器普通方式加载配置方式Headless 方式 设置浏览器窗口最大化显示最小化显示自定义大小 前进后退前进后退 元素定位根据 id 定位根据 name 定位根据 class 定位根据标签名定位使用 CSS 定位使用…...

mysql的having语句
MySQL的HAVING语句用于在GROUP BY子句对数据进行分组后,过滤满足特定条件的组。与WHERE子句不同,HAVING子句可以在过滤条件中使用聚合函数,而WHERE子句则不能。通常,HAVING子句与GROUP BY子句一起使用,以实现对分组数据…...

华为数据之道-读书笔记
内容简介 关键字 数字化生产 已经成为普遍的商业模式,其本质是以数据为处理对象,以ICT平台为生产工具,以软件为载体,以服务为目的的生产过程。 信息与通信技术平台(Information and Communication Technology Platf…...
CDN、源站与边缘网络
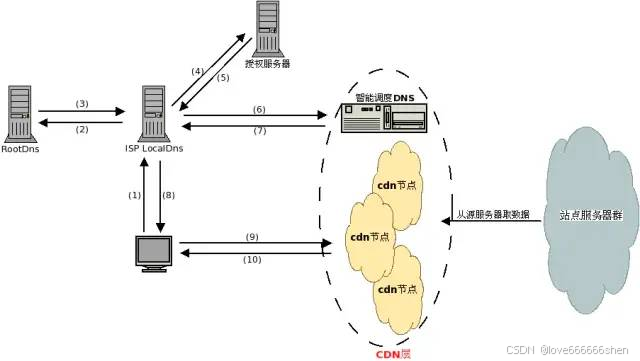
什么是“源站” 源服务器 源服务器的目的是处理和响应来自互联网客户端的传入请求。源服务器的概念通常与边缘服务器或缓存服务器的概念结合使用。源服务器的核心是一台运行一个或多个程序的计算机,这些程序旨在侦听和处理传入的客户端请求。源服务器可以承担为网…...
工业相机 SDK 二次开发-Sherlock插件
本文介绍了 sherlock 连接相机时的插件使用。通过本套插件可连接海康的工业相机。 一.环境配置 1. 拷贝动态库 在用户安装 MVS 目录下按照如下路径 Development\ThirdPartyPlatformAdapter 找到目 录为 DalsaSherlock 的文件夹,根据 Sherlock 版本找到…...
FlinkSql使用中rank/dense_rank函数报错空指针
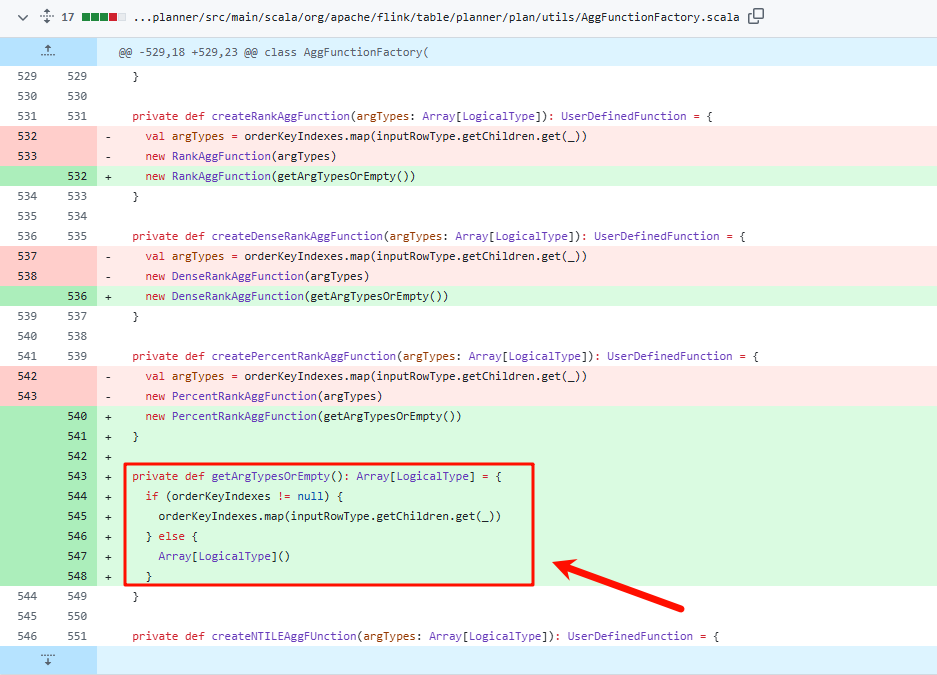
问题描述 在flink1.16(甚至以前的版本)中,使用rank()或者dense_rank()进行排序时,某些场景会导致报错空指针NPE(NullPointerError) 报错内容如下 该报错没有行号/错误位置,无法排查 现状 目前已经确认为bug,根据github上的PR日…...
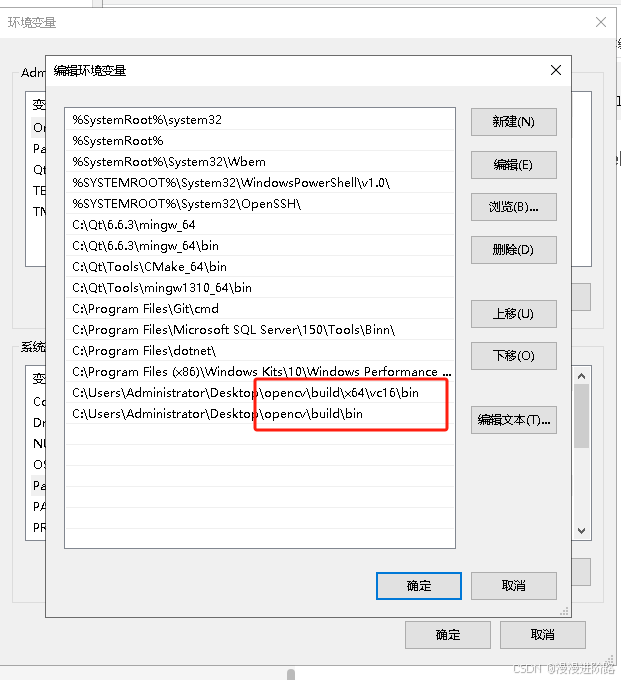
VS C++ 配置OPENCV环境
VS C 配置OPENCV环境 1.下载opencv2.安装环境3.opencv环境4.VS配置opencv环境5.EXE执行文件路径的环境lib和dll需要根据是debug还是release环境来区分使用哪个 6.Windows环境 1.下载opencv 链接: link 2.安装环境 双击运行即可 3.opencv环境 include文件路径:opencv\build\…...
【SpringSecurity】基本开发流程
文章目录 概要整体架构流程实现流程1、编写各种Handler2 、AccessToken处理器3、定义AuthenticationFilter 继承 OncePerRequestFilter (OncePerRequestFilter是Spring提供的一个过滤器基类,它确保了在一次完整的HTTP请求中,无论请求经过多少…...
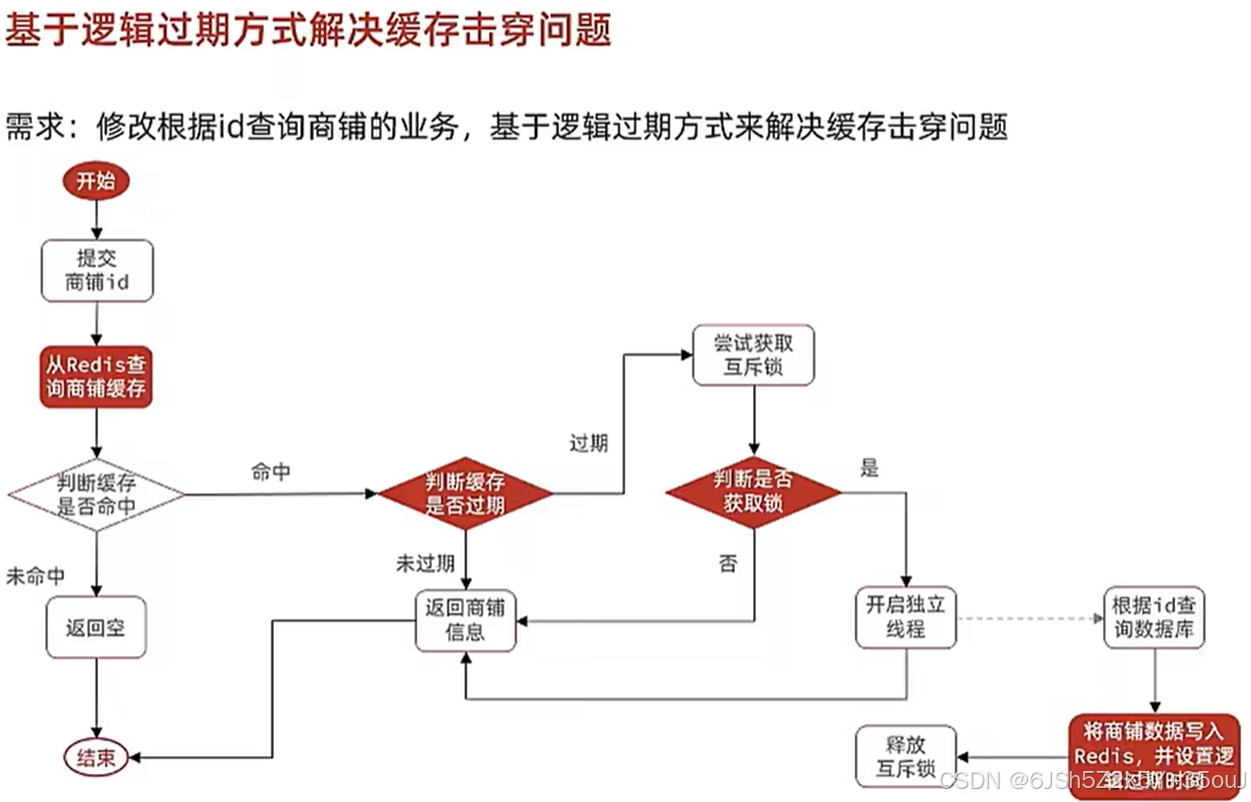
Redis实战(黑马点评)——关于缓存(缓存更新策略、缓存穿透、缓存雪崩、缓存击穿、Redis工具)
redis实现查询缓存的业务逻辑 service层实现 Overridepublic Result queryById(Long id) {String key CACHE_SHOP_KEY id;// 现查询redis内有没有数据String shopJson (String) redisTemplate.opsForValue().get(key);if(StrUtil.isNotBlank(shopJson)){ // 如果redis的数…...

ChatGPT从数据分析到内容写作建议相关的46个提示词分享!
在当今快节奏的学术环境中,研究人员面临着海量的信息和复杂的研究任务。幸运的是,随着人工智能技术的发展,像ChatGPT这样的先进工具为科研人员提供了强大的支持。今天就让我们一起探索如何利用ChatGPT提升研究效率进一步优化研究流程。 ChatG…...

在 Windows 11 中设置 WSL2 Ubuntu 的 `networkingMode=mirrored` 详细教程
在 Windows 11 中设置 WSL2 Ubuntu 的 networkingModemirrored 详细教程 引言环境要求配置 .wslconfig 文件重启 WSL2验证镜像网络模式解决常见问题其他注意事项结论 引言 在 Windows 11 中使用 WSL2(Windows Subsystem for Linux 2)时,默认…...
万字长文总结前端开发知识---JavaScriptVue3Axios
JavaScript学习目录 一、JavaScript1. 引入方式1.1 内部脚本 (Inline Script)1.2 外部脚本 (External Script) 2. 基础语法2.1 声明变量2.2 声明常量2.3 输出信息 3. 数据类型3.1 基本数据类型3.2 模板字符串 4. 函数4.1 具名函数 (Named Function)4.2 匿名函数 (Anonymous Fun…...

怎么样把pdf转成图片模式(不能复制文字)
贵但好用的wps, 转换——转为图片型pdf —————————————————————————————————————————— 转换前: 转换后: 肉眼可见,模糊了,且不能复制。 其他免费办法,参考&…...
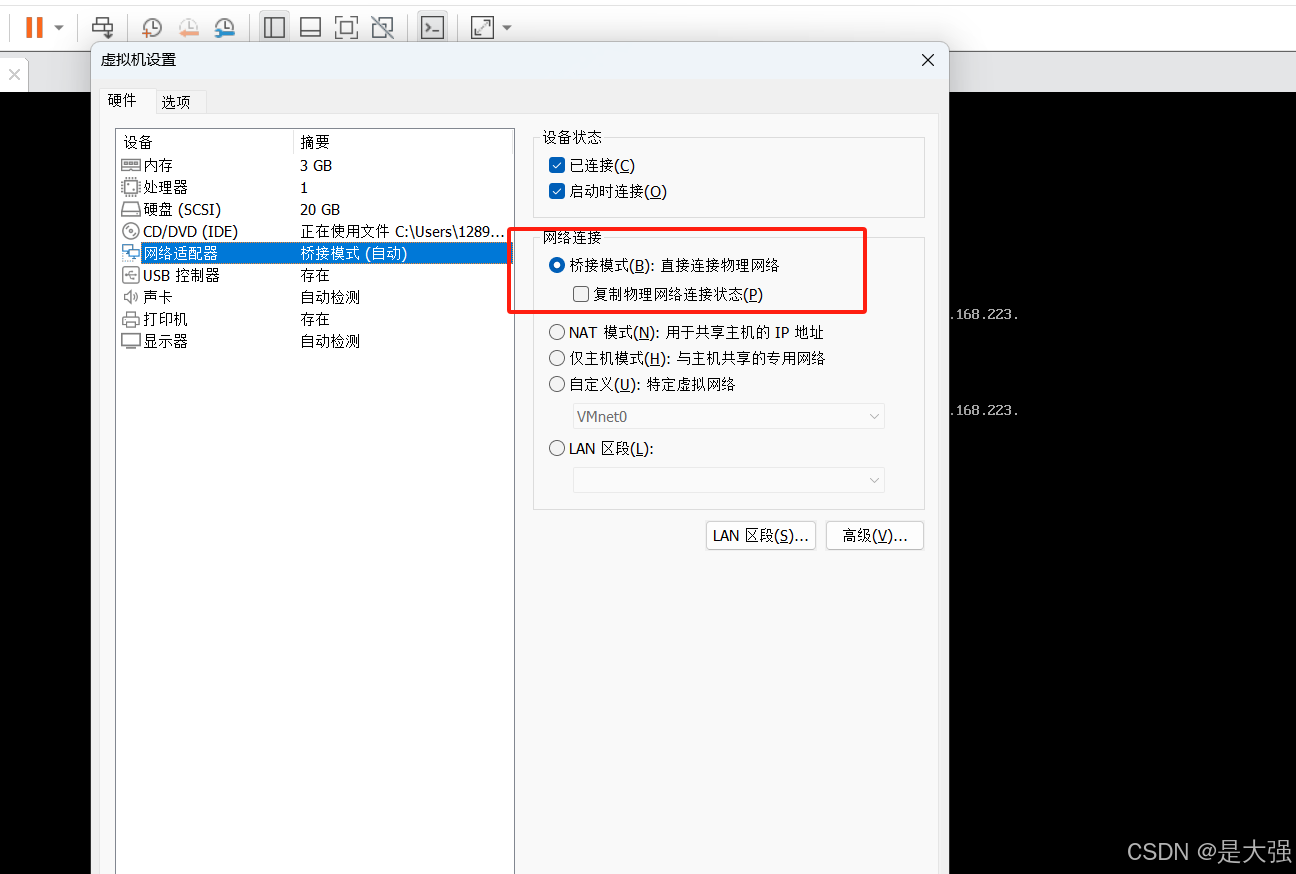
本地centos网络配置
1、路径 2、配置 另外还需要...

扩散浓度曲线计算:从实例看 Pandat 代算与自行操作
扩散浓度曲线计算(Pandat代算或自己操作) 实例33: Al-4.06at%Mg/Al扩散偶在781K下退火36960s,Mg元素浓度随距离的变化曲线及实验数据对比如图a所示;Al-11at%Mg/Al扩散偶在773K下退火86400s,Mg元素浓度随距离的变化曲线及实验对比如图b所示&am…...

Ubuntu 24.04 时间同步踩坑记:从 hwclock 到 timedatectl 的演进与实战
Ubuntu 24.04 时间同步踩坑记:从 hwclock 到 timedatectl 的演进与实战 记得第一次在 Ubuntu 24.04 上看到系统时间与 Windows 11 相差整整 8 小时时,我下意识地敲下了熟悉的 hwclock 命令——这个陪伴我多年的老伙计。然而终端冰冷的报错提示让我意识到…...
)
气象防灾实战:如何用QGIS快速生成暴雨等值面预警图?(含历史数据对比)
气象防灾实战:如何用QGIS快速生成暴雨等值面预警图?(含历史数据对比) 暴雨灾害的预警与防控一直是应急管理和市政规划领域的核心挑战。传统的气象数据分析往往依赖专业软件和复杂代码,让非技术背景的从业者望而却步。本…...
LumiPixel Canvas Quest超现实主义创作:生成融合自然与机械的赛博格人像
LumiPixel Canvas Quest超现实主义创作:生成融合自然与机械的赛博格人像 1. 当AI画笔遇见赛博格幻想 打开LumiPixel Canvas Quest的第一感觉,就像拿到了通往异世界的钥匙。这个擅长超现实题材的AI艺术工具,最近在我们团队内部掀起了一阵&qu…...

实时手机检测-通用效果对比:YOLOv5s/v8n/DAMOYOLO-S三模型同图评测
实时手机检测-通用效果对比:YOLOv5s/v8n/DAMOYOLO-S三模型同图评测 1. 引言:为什么需要更好的手机检测模型? 想象一下,你正在开发一个智能会议室管理系统,需要自动检测参会者是否在会议期间违规使用手机。或者&#…...

Nuka Carousel与TypeScript完美集成:类型安全和开发体验提升
Nuka Carousel与TypeScript完美集成:类型安全和开发体验提升 【免费下载链接】nuka-carousel Small, fast, and accessibility-first React carousel library with an easily customizable UI and behavior to fit your brand and site. 项目地址: https://gitcod…...

CDN 报错 403/502/504 怎么解决?源站与防护策略排查
网站接入CDN后,原本访问流畅,突然出现403、502、504报错,用户反馈无法访问,自己排查半天找不到头绪——其实这类报错大多和「源站状态」「防护策略」「CDN配置」三个环节相关,今天就结合实操经验,把这三种常…...

【并发心法】别用 volatile 骗自己了!撕碎裸机并发的伪安全,用 C++ Atomics 与内存屏障镇压“乱序执行”的底层叛乱
摘要:在嵌入式 C/C 开发中,99% 的工程师误以为 volatile 是解决中断与主循环并发冲突的万能解药。本文将无情揭露这一长达数十年的认知毒瘤。我们将带你深入现代编译器(GCC/Clang)的优化黑盒与 ARM Cortex 高级内核的流水线深处&a…...

导师严选!盘点2026年冠绝行业的的AI智能降重工具
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的AI智能降重工具,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你高效搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...

Claudia:提升开发效率的智能代码助手桌面应用
Claudia:提升开发效率的智能代码助手桌面应用 【免费下载链接】opcode A powerful GUI app and Toolkit for Claude Code - Create custom agents, manage interactive Claude Code sessions, run secure background agents, and more. 项目地址: https://gitcode…...