R语言学习笔记之高效数据操作
一、概要
数据操作是R语言的一大优势,用户可以利用基本包或者拓展包在R语言中进行复杂的数据操作,包括排序、更新、分组汇总等。R数据操作包:data.table和tidyfst两个扩展包。
data.table是当前R中处理数据最快的工具,可以实现快速的数据汇总、连接、删除、分组计算等操作,具有稳定、速度快、省内存、特性丰富、语法简洁等特点。由于其函数语法结构相对来说较为抽象,对于初学者而言往往需要花更多的时间来掌握。
tidyfst包应运而生,用以提高data.table代码的可读性和可维护性。tidyfst包参考了tidyverse体系的语法结构,让用户能够见名知义;同时,其底层由data.table代码构成,因此实现速度非常快。对于较为复杂的data.table操作,tidyfst包提供了简便的调用函数进行实现。
资料来源:《机器学习全解(R语言版)》 黄天元 2024年7月出版
二、数据读写
在data.table包中可以使用fread和fwrite函数对csv格式的文件进行读写。
如果需要保存规模较大的数据,可以使用tidyfst包的import_fst和export_fst函数来进行数据读写,其数据保存格式为以fst为扩展名的二进制文件。它的特点就是数据高保真、读写速度快和压缩效果好,因此保存下来的fst文件往往要比csv格式占用内存更小。
library(pacman)
p_load(tidyfst,data.table)fwrite(iris,"D:/iris.csv")
ir=fread("D:/iris.csv")export_fst(iris,"D:/iris.fst")
ir=import_fst("D:/iris.fst")
三、筛选列
1、选择需要的列
library(pacman)
p_load(tidyfst,data.table)
ir=as.data.table(iris)
ir# 选取上面构造的数据框ir中的第1、3和4列,以下两种写法等价
ir %>% select_dt(1,3,4) #tidyfst
ir[,c(1,3,4)] # data.table
2、选择连续的列
可以使用“:”符号:
# 选择1到3列
ir %>% select_dt(1:3)
ir[,1:3]
3、根据变量名称选择单列
# 选择Sepal.Length列
ir %>% select_dt(Sepal.Length)
ir[,"Sepal.Length"]
4、根据变量名称选择多列
变量名称之间需要用逗号隔开
# 选择Sepal.Length和Petal.Length两列
ir %>% select_dt(Sepal.Length,Petal.Length)
ir[,c("Sepal.Length","Petal.Length")]
5、根据正则表达式筛选列
# 选择列名称包含“Sepal”的列
ir %>% select_dt("Sepal")
ir[,.SD,.SDcols=patterns("Sepal")] 
6、利用特殊函数选择列
# 选择数据类型为因子的列
ir %>% select_dt(is.factor)
ir[,.SD,.SDcols = is.factor]
7、排除列
排除一些列,则可以在原来基础上加上减号来实现:
# 排除Sepal.Length和Petal.Length这两列
ir %>% select_dt(-Sepal.Length,-Petal.Length)
ir[,-c("Sepal.Length","Petal.Length")]
# 排除因子列
ir %>% select_dt(-is.factor)
ir[,.SD,.SDcols = -is.factor]
四、筛选行
1、根据单个条件筛选行
# 筛选出Sepal.Length大于7的条目
ir %>% filter_dt(Sepal.Length>7)
ir[Sepal.Length>7]
2、多条件筛选行
如果要附加多个条件,那么条件之间可以利用逻辑运算符&(与)、|(或)和!(非)进行修饰和连接。
# 筛选Species列不为versicolor且Sepal.Length大于6的条目
ir %>% filter_dt(Species != "versicolor" & Sepal.Length > 6)
ir[Species != "versicolor" & Sepal.Length > 6]
3、tidyfst包中现成的筛选函数
| slice_max_dt | 获得Sepal.Length最大的10个条目 ir %>% slice_max_dt(Sepal.Length,10) | |
| slice_min_dt | 获得Sepal.Length最小的10个条目 ir %>% slice_min_dt(Sepal.Length,10) | |
| slice_sample_dt | 随机选择10个条目 ir %>% slice_sample_dt(10) | |
| slice_dt | 根据条目的位置来进行筛选。获得ir数据框的第100行 | |
| ir %>% slice_dt(100) | ir[100] | |
| 选择多行,则可以使用数值向量。选出第100行到第105行 | ||
| ir %>% slice_dt(100:105) | ir[100:105] | |
| unique | 去重 ir %>% unique() | |






五、更新
更新是指对数据框的一列或多列进行修饰,或根据已有列构造新列。
| mutate_dt | 新增常数列、修改列 |
| mutate_when | 按照一定的条件进行列的更新 |
| mutate_vars | 对多个列同时进行原位修饰 |
ir %>% mutate_dt(one=1)
ir %>% mutate_dt(Sepal.Length=Sepal.Length+1)
ir %>% mutate_when(Sepal.Width=0.2,one=1)
ir %>% mutate_vars("^Petal",function(x) x-1)1、新增一列名为one的常数列,其所有数值均为1

2、让Sepal.Length列的所有数值加1

3、在Petal.Width等于0.2的时候新增名为one的常数列

4、让列名称以Petal开头的列都减去1

六、排序
对数据框进行排序有两种方法,一种是按照行进行排序,另一种是按照列进行排序。
| arrange_dt | 按列排序 |
| relocate_dt | 调整列的位置 |
ir %>% arrange_dt(Sepal.Length)
ir[order(Sepal.Length)]ir %>% arrange_dt(Sepal.Length,Sepal.Width)
ir[order(Sepal.Length,Sepal.Width)]ir %>% arrange_dt(-Sepal.Length)
ir[order(-Sepal.Length)]ir %>% relocate_dt(Species,how="first")
ir %>% relocate_dt(Species,how="last")ir %>% relocate_dt(Petal.Length,how = "after",where = Petal.Width)# 对列的位置进行重新排列
new_order=names(ir)[c(3,2,4,5,1)]
new_order
ir[,.SD,.SDcols = new_order]# 直接写上列名称
ir %>% select_mix(Petal.Length,Sepal.Width,Petal.Width,Species,Sepal.Length)1、按照Sepal.Length列从小到大进行排列

多列:先按照Sepal.Length列进行排列,然后再按照Sepal.Width列进行排列

2、从大到小进行排列,在原来的变量之前加入负号

3、调整列的位置
把Species列放到第一列:

把Sepal.Length列放到最后一列:

七、汇总
汇总的过程是用较少信息表征较多信息的方法。
tidyfst包中使用summarise_dt函数来对数据框中的列进行汇总。
ir %>% summarise_dt(avg=mean(Sepal.Length))
ir %>% summarise_dt(mean=mean(Sepal.Length))
ir %>% summarise_when(Petal.Width==.2,avg=mean(Petal.Length))
ir %>% summarise_vars(2:4,sum)
ir %>% summarise_vars(is.numeric,sum)
八、分组计算
分组计算就是根据分组结果来对每一个组进行相同的操作。
在tidyfst包中,很多函数都具有by参数,by用来指定分组的变量。
如果需要对多个变量进行分组,那么by参数的指定方式有以下几种:
●在by参数中放入字符串,变量之间以逗号分隔(如by="vs,am");
●在by参数中放入字符向量,字符是分组的列名称(如by=c("vs","am"));
●在by参数中放入一个指定分组变量的列表(如by=list(vs,am))。
ir %>% summarise_dt(avg=mean(Sepal.Length),by=Species)
ir %>% summarise_vars(is.numeric,sum,by=Species)mt=as_dt(mtcars)
mt
mt %>% summarise_dt(avg=mean(mpg),by="vs,am")
mt %>% summarise_dt(avg=mean(mpg),by=c("vs","am"))
mt %>% summarise_dt(avg=mean(mpg),by=list(vs,am))
mt %>% summarise_dt(avg=mean(mpg),by=.(vs,am))



九、列的重命名
tidyfst包中使用rename_dt函数来对列进行重命名。对多个列进行重命名,只要用逗号隔开即可。
ir %>% rename_dt(sl=Sepal.Length)
ir %>% rename_dt(sl=Sepal.Length,sw=Sepal.Width)
ir %>% rename_with_dt(toupper)
ir %>% setNames(paste0("V",1:5))

十、多表连接
连接是指根据表格所包含的共同信息来对多个表格进行合并的过程。基本的连接可以分为内连接、全连接、左连接和右连接。
内连接又称为自然连接,该操作会从结果表中删除与其他被连接表中没有匹配行的所有行,只保留两个表格中都包含的数据条目。
全连接会保留所有表格的所有信息。
左连接则仅会保证左边(即第一个出现的)表格的信息会被完全保留,右边(第二个)表格的信息只有与第一个表格的信息匹配的才能够保留。
右连接是左连接的逆运算,即完全保留第二个表格的信息,而第一个表格中只有与第二个表格的信息匹配的内容才能保留。
还有一种特殊的连接方式叫作过滤型连接,它包括反连接和半连接。
半连接与左连接相似,但是它只保留了左表格的所有列,而右表格的列则不会放入结果。这相当于只提取了右表格的匹配列,然后与左表格进行连接。
反连接则与半连接相反,它会保留左表和右表对应列相异的部分。
workers=fread("name companyNick AcmeJohn AjaxDaniela Ajax")positions=fread("name positionJohn designerDaniela engineerCathie manager")workers
positionsworkers %>% inner_join_dt(positions)
workers %>% merge(positions)workers %>% full_join_dt(positions)
workers %>% merge(positions,all = T)workers %>% left_join_dt(positions)
workers %>% merge(positions,all.x = T)workers %>% right_join_dt(positions)
workers %>% merge(positions,all.y = T)workers %>% left_join_dt(positions,by="name")
workers %>% merge(positions,all.x = T,by="name")positions2=setNames(positions,c("worker","position"))
workers
positions2
workers %>% inner_join_dt(positions2,by=c("name"="worker"))
workers %>% inner_join_dt(positions2,on="name==worker")
workers %>% merge(positions2,by.x="name",by.y = "worker")workers %>% semi_join_dt(positions)
workers %>% anti_join_dt(positions) 



十一、长宽转换
tidyfst包中的longer_dt函数实现将“宽数据”转换成“长数据”。
tidyfst包中的wider_dt函数实现“长数据”转成“宽数据”。
stocks=data.frame(time=as.Date('2009-01-01')+0:9,X=rnorm(10,0,1),Y=rnorm(10,0,2),Z=rnorm(10,0,4)
)
stocks# 转成长数据
stocks %>% longer_dt(time) -> long_stocks
long_stocksstocks %>% longer_dt(time,name="NAME",value="VALUE")# 转成宽数据
wide_stockes=long_stocks %>% wider_dt(name="name",value="value")
wide_stockes

十二、集合运算

| tidyfst包函数 | data.table包函数 | |
|---|---|---|
| 交集 | intersect_dt | fintersect |
| 并集 | union_dt | funion |
| 差集 | setdiff_dt | fsetdiff |
注意:tidyfst包会自动地把任意数据框转化为data.table格式。
十三、缺失值处理
1、删除缺失记录
na.omit函数可以删掉任意包含缺失值的行。
tidyfst包的drop_na_dt函数可以实现删除某一列中存在缺失值的条目。
2、缺失值填充
tidyfst包中的replace_na_dt函数实现填充指定的值。
tidyfst包的fill_na_dt函数实现将上一个观测值作为下面缺失的填充值。
tidyfst包中的impute_dt函数实现使用非缺失数值的均值、中位数或众数来对缺失值进行填充。
十四、列表列的应用
列表列(list column)是R语言中相对较新的一个概念,它能够根据分组把一整块数据集成在一起成为一列,而这个列的数据类型为列表(list)。在tidyfst包中可以使用nest_dt函数进行实现。
相关文章:
R语言学习笔记之高效数据操作
一、概要 数据操作是R语言的一大优势,用户可以利用基本包或者拓展包在R语言中进行复杂的数据操作,包括排序、更新、分组汇总等。R数据操作包:data.table和tidyfst两个扩展包。 data.table是当前R中处理数据最快的工具,可以实现快…...
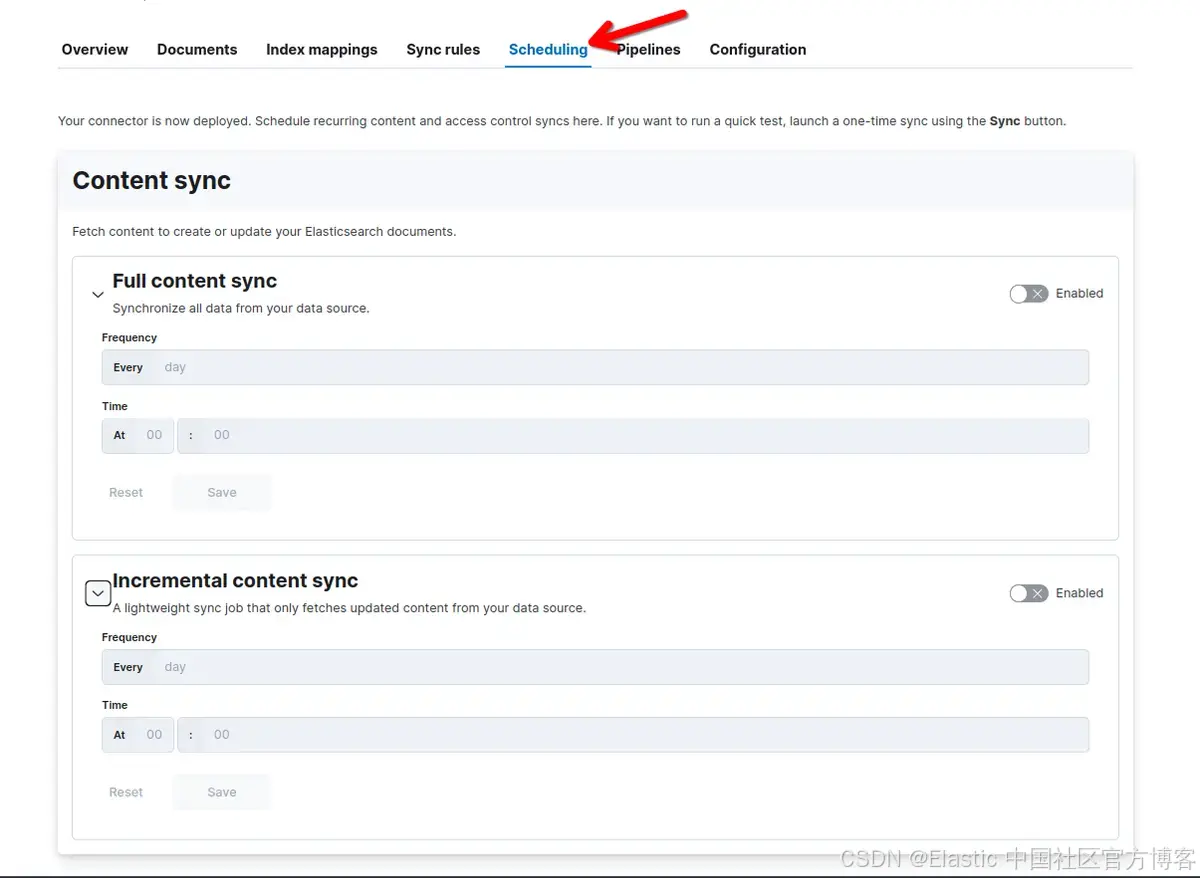
将 OneLake 数据索引到 Elasticsearch - 第二部分
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo 本文分为两部分,第二部分介绍如何使用自定义连接器将 OneLake 数据索引并搜索到 Elastic 中。 在本文中,我们将利用第 1 部分中学到的知识来创建 OneLake 自定义 Elasticsearch 连接器…...

Linux——冯 • 诺依曼体系结构
目录 一、冯•诺依曼体系结构原理二、内存提高冯•诺依曼体系结构效率的方法三、当用QQ和朋友聊天时数据的流动过程四、关于冯诺依曼五、总结 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系 流程&#…...

Java进阶(一)
目录 一.Java注解 什么是注解? 内置注解 元注解 二.对象克隆 什么是对象克隆? 为什么用到对象克隆 三.浅克隆深克隆 一.Java注解 什么是注解? java中注解(Annotation)又称java标注,是一种特殊的注释。 可以添加在包,类&…...

appium自动化环境搭建
一、appium介绍 appium介绍 appium是一个开源工具、支持跨平台、用于自动化ios、安卓手机和windows桌面平台上面的原生、移动web和混合应用,支持多种编程语言(python,java,Ruby,Javascript、PHP等) 原生应用和混合应用…...

Qt 5.14.2 学习记录 —— 이십 QFile和多线程
文章目录 1、QFile1、打开2、读写3、关闭4、程序5、其它功能 2、多线程1、演示2、锁 3、条件变量和信号量 1、QFile Qt有自己的一套文件体系,不过Qt也可以使用C,C,Linux的文件操作。使用Qt的文件体系和Qt自己的一些类型更好配合。 管理写入读…...
積分方程與簡單的泛函分析7.希爾伯特-施密特定理
1)def函數叫作"由核生成的(有源的)" 定义: 设 是定义在区域上的核函数。 对于函数,若存在函数使得, 则称函数是“由核生成的(有源的)”。 这里的直观理解是: 函数的“来源”可以通过核函数 与另一个函数的积分运算得到。 在积分方程理论中,这种表述常…...

使用vitepress搭建自己的博客项目
一、介绍can-vitepress-blog 什么是CAN BLOG CAN BLOG是基于vitepress二开的个人博客系统,他能够方便使用者快速构建自己的博客文章,无需繁琐的配置和复杂的代码编写。 CAN BLOG以antdv为UI设计基础,简洁大方,界面友好…...

开始步入达梦中级dba
分析内存使用需要的方法之一 disql /nolog conn sysdba/sysdbaselect value from v$parameter where nameMEMORY_LEAK_CHECK; SP_SET_PARA_VALUE(0,MEMORY_LEAK_CHECK,1); select * from V$MEM_REGINFO; select * from V$MEM_HEAP;...

如何在docker中的mysql容器内执行命令与执行SQL文件
通过 docker ps -a 查询当前运行的容器,找到想执行命令的容器名称。 docker ps -a若想执行sql文件,则将sql文件放入当前文件夹下后将项目内的 SQL 文件拷贝到 mysql 容器内部的 root下。 sudo docker cp /root/enterprise.sql mysql:/root/然后进入 my…...

S4 HANA更改Tax base Amount的字段控制
本文主要介绍在S4 HANA OP中Tax base Amount的字段控制相关设置。具体请参照如下内容: 1. 更改Tax base Amount的字段控制 以上配置用于控制FB60/FB65/FB70/FB75/MIRO的页签“Tax”界面是否可以修改“Tax base Amount”, 如果勾选Change 表示可以修改T…...

Linux权限有关
文章目录 一、添加普通用户二、Xshell下命令行的知识三、 Linux和Windows操作系统四、再探指令和Linux权限五、用户相关用户切换: 今天我们学习与Linux有关的权限等内容,以及一些零碎知识帮助我们理解Linux的系统和Xshell的原理。 本篇是在Xshell环境下执行的。 一…...

【github 使用相关】提交pr和commit message Conventional Commits 规范 代码提交的描述该写什么?
目录 Git 提交信息格式格式描述Subject(标题)Body(正文) 规范的标签(Tag)示例 CG Git 提交信息格式 格式描述 一般开源项目代码库根目录都会有一个 CONTRIBUTING.md 或者其他类似名字的文档来介绍如何开始…...

Docker—搭建Harbor和阿里云私有仓库
Harbor概述 Harbor是一个开源的企业级Docker Registry管理项目,由VMware公司开发。它的主要用途是帮助用户迅速搭建一个企业级的Docker Registry服务,提供比Docker官方公共镜像仓库更为丰富和安全的功能,特别适合企业环境使用。12 Harb…...

Maven的下载安装配置
maven的下载安装配置 maven是什么 Maven 是一个用于 Java 平台的 自动化构建工具,由 Apache 组织提供。它不仅可以用作包管理,还支持项目的开发、打包、测试及部署等一系列行为 Maven的核心功能 项目构建生命周期管理:Maven定义了项目构建…...

Rust:高性能与安全并行的编程语言
引言 在现代编程世界里,开发者面临的最大挑战之一就是如何平衡性能与安全性。在许多情况下,C/C这样的系统级编程语言虽然性能强大,但其内存管理的复杂性导致了各种安全漏洞。为了解决这些问题,Rust 作为一种新的系统级编程语言进入…...
函数详解(OK))
matlab的cat()函数详解(OK)
cat函数的功能是 连接数组 功能: 按指定的维度连接多个向量 结构: C cat(dim, A, B) 按dim指定的维度连接向量A和BC cat(dim, A1, A2, A3,A4, …) 按dim指定的维度连接多个向量A1, A2,A3,A4…C cat(dim, A{:}) 将包含向量的cell或结构数组联合为一…...

将个人微信中的时间改成标准的日期时间格式
list1["10:05","上午 10:07","下午 2:07","晚上 8:07","昨天 16:07","星期天 19:27","星期二 19:27","星期四 14:27","2025年1月10日 17:43"]from datetime import datetime, time…...

centos9编译安装opensips 二【进阶篇-定制目录+模块】推荐
环境:centos9 last opensips -V version: opensips 3.6.0-dev (x86_64/linux) flags: STATS: On, DISABLE_NAGLE, USE_MCAST, SHM_MMAP, PKG_MALLOC, Q_MALLOC, F_MALLOC, HP_MALLOC, DBG_MALLOC, CC_O0, FAST_LOCK-ADAPTIVE_WAIT ADAPTIVE_WAIT_LOOPS1024, MAX_RE…...

初步搭建并使用Scrapy框架
目录 目标 版本 实战 搭建框架 获取图片链接、书名、价格 通过管道下载数据 通过多条管道下载数据 下载多页数据 目标 掌握Scrapy框架的搭建及使用,本文以爬取当当网魔幻小说为案例做演示。 版本 Scrapy 2.12.0 实战 搭建框架 第一步:在D:\pyt…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...