【PyTorch】4.张量拼接操作

个人主页:Icomi
在深度学习蓬勃发展的当下,PyTorch 是不可或缺的工具。它作为强大的深度学习框架,为构建和训练神经网络提供了高效且灵活的平台。神经网络作为人工智能的核心技术,能够处理复杂的数据模式。通过 PyTorch,我们可以轻松搭建各类神经网络模型,实现从基础到高级的人工智能应用。接下来,就让我们一同走进 PyTorch 的世界,探索神经网络与人工智能的奥秘。本系列为PyTorch入门文章,若各位大佬想持续跟进,欢迎与我交流互关。
前面我们学习了张量和 numpy 数组的相互转换,这是我们在深度学习数据处理中非常实用的技能。
今天,咱们要讲讲张量的拼接操作,这可是在神经网络搭建过程中极为常用的方法,就好比搭建一座宏伟建筑时不可或缺的连接工艺。想象一下,我们构建神经网络就像搭建一座复杂的大厦,张量就是构成大厦的各种预制构件,而拼接操作就像是把这些构件精准连接在一起的关键技术。
比如说,在后面将要学习到的残差网络里,张量的拼接起到了至关重要的作用。残差网络能够有效解决深度神经网络训练过程中的梯度消失和梯度爆炸问题,让网络可以更深层次地学习数据特征。这里面,通过巧妙地拼接不同层的张量,就像是把不同功能的建筑模块合理组合,从而构建出了强大的深层网络结构。
还有注意力机制,这也是深度学习领域的一个重要概念。在注意力机制中,张量的拼接帮助我们对不同的信息进行整合与聚焦,就像在纷繁复杂的信息海洋中,通过拼接操作找到最关键的信息片段并组合起来,让模型能够更加 “聪明” 地处理数据。
所以,掌握张量的拼接操作,对于我们理解和构建先进的神经网络模型至关重要。接下来,咱们就深入学习一下张量的拼接到底是怎么实现的,以及在不同场景下该如何灵活运用它。
1. torch.cat 函数的使用¶
torch.cat 函数可以将两个张量根据指定的维度拼接起来.
import torchdef tensor_concatenation():# 创建第一个三维随机整数张量tensor_1 = torch.randint(0, 10, [3, 5, 4])# 创建第二个三维随机整数张量tensor_2 = torch.randint(0, 10, [3, 5, 4])print(tensor_1)print(tensor_2)print('-' * 50)# 1. 按 0 维度拼接concatenated_tensor_dim0 = torch.cat([tensor_1, tensor_2], dim=0)print(concatenated_tensor_dim0.shape)print('-' * 50)# 2. 按 1 维度拼接concatenated_tensor_dim1 = torch.cat([tensor_1, tensor_2], dim=1)print(concatenated_tensor_dim1.shape)print('-' * 50)# 3. 按 2 维度拼接concatenated_tensor_dim2 = torch.cat([tensor_1, tensor_2], dim=2)print(concatenated_tensor_dim2)if __name__ == '__main__':tensor_concatenation()程序输出结果:
tensor([[[6, 8, 3, 5],[1, 1, 3, 8],[9, 0, 4, 4],[1, 4, 7, 0],[5, 1, 4, 8]],[[0, 1, 4, 4],[4, 1, 8, 7],[5, 2, 6, 6],[2, 6, 1, 6],[0, 7, 8, 9]],[[0, 6, 8, 8],[5, 4, 5, 8],[3, 5, 5, 9],[3, 5, 2, 4],[3, 8, 1, 1]]])
tensor([[[4, 6, 8, 1],[0, 1, 8, 2],[4, 9, 9, 8],[5, 1, 5, 9],[9, 4, 3, 0]],[[7, 6, 3, 3],[4, 3, 3, 2],[2, 1, 1, 1],[3, 0, 8, 2],[8, 6, 6, 5]],[[0, 7, 2, 4],[4, 3, 8, 3],[4, 2, 1, 9],[4, 2, 8, 9],[3, 7, 0, 8]]])
--------------------------------------------------
torch.Size([6, 5, 4])
--------------------------------------------------
torch.Size([3, 10, 4])
tensor([[[6, 8, 3, 5, 4, 6, 8, 1],[1, 1, 3, 8, 0, 1, 8, 2],[9, 0, 4, 4, 4, 9, 9, 8],[1, 4, 7, 0, 5, 1, 5, 9],[5, 1, 4, 8, 9, 4, 3, 0]],[[0, 1, 4, 4, 7, 6, 3, 3],[4, 1, 8, 7, 4, 3, 3, 2],[5, 2, 6, 6, 2, 1, 1, 1],[2, 6, 1, 6, 3, 0, 8, 2],[0, 7, 8, 9, 8, 6, 6, 5]],[[0, 6, 8, 8, 0, 7, 2, 4],[5, 4, 5, 8, 4, 3, 8, 3],[3, 5, 5, 9, 4, 2, 1, 9],[3, 5, 2, 4, 4, 2, 8, 9],[3, 8, 1, 1, 3, 7, 0, 8]]])2. torch.stack 函数的使用¶
torch.stack 函数可以将两个张量根据指定的维度叠加起来.
import torchdef test():data1= torch.randint(0, 10, [2, 3])data2= torch.randint(0, 10, [2, 3])print(data1)print(data2)new_data = torch.stack([data1, data2], dim=0)print(new_data.shape)new_data = torch.stack([data1, data2], dim=1)print(new_data.shape)new_data = torch.stack([data1, data2], dim=2)print(new_data)if __name__ == '__main__':test()3. 总结¶
张量的拼接操作也是在后面我们经常使用一种操作。cat 函数可以将张量按照指定的维度拼接起来,stack 函数可以将张量按照指定的维度叠加起来。
相关文章:
【PyTorch】4.张量拼接操作
个人主页:Icomi 在深度学习蓬勃发展的当下,PyTorch 是不可或缺的工具。它作为强大的深度学习框架,为构建和训练神经网络提供了高效且灵活的平台。神经网络作为人工智能的核心技术,能够处理复杂的数据模式。通过 PyTorch࿰…...
MySQL--》深度解析InnoDB引擎的存储与事务机制
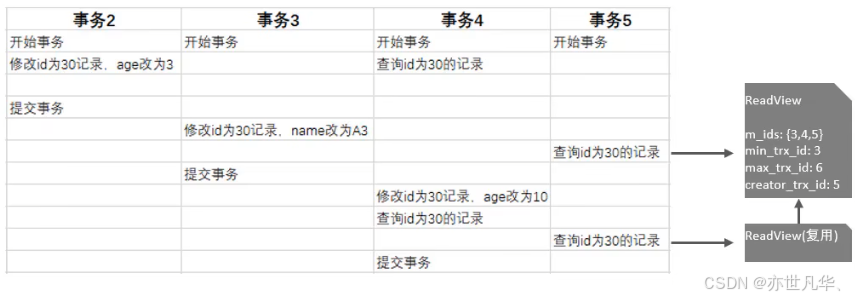
目录 InnoDB架构 事务原理 MVCC InnoDB架构 从MySQL5.5版本开始默认使用InnoDB存储引擎,它擅长进行事务处理,具有崩溃恢复的特性,在日常开发中使用非常广泛,其逻辑存储结构图如下所示, 下面是InnoDB架构图…...
Visio2021下载与安装教程
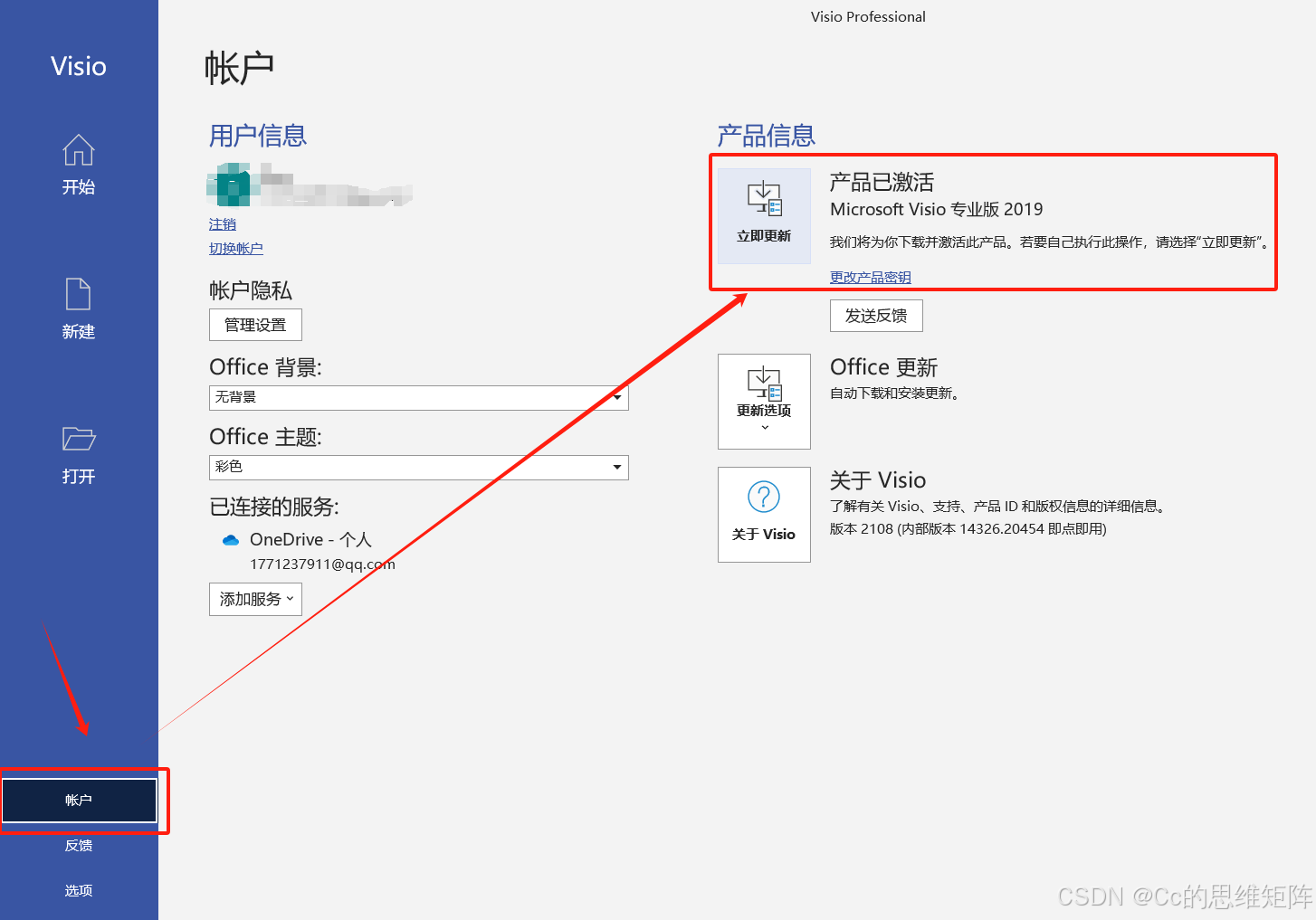
这里写目录标题 软件下载软件介绍安装步骤 软件下载 软件名称:Visio2021软件语言:简体中文软件大小:4.28G系统要求:Windows10或更高,64位操作系统硬件要求:CPU2GHz ,RAM4G或更高下载链接&#…...

实战纪实 | 真实HW漏洞流量告警分析
视频教程在我主页简介和专栏里 目录: 一、web.xml 文件泄露 二、Fastjson 远程代码执行漏洞 三、hydra工具爆破 四、绕过验证,SQL攻击成功 五、Struts2代码执行 今年七月,我去到了北京某大厂参加HW行动,因为是重点领域—-jr&…...
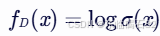
【AI论文】扩散对抗后训练用于一步视频生成总结
摘要:扩散模型被广泛应用于图像和视频生成,但其迭代生成过程缓慢且资源消耗大。尽管现有的蒸馏方法已显示出在图像领域实现一步生成的潜力,但它们仍存在显著的质量退化问题。在本研究中,我们提出了一种在扩散预训练后针对真实数据…...
C语言可变参数)
重回C语言之老兵重装上阵(十六)C语言可变参数
C语言可变参数 在C语言中,标准库提供了一些函数允许接收可变数量的参数。最典型的例子就是 printf 和 scanf,它们能够处理不确定数量的参数。为了实现这一功能,C语言提供了可变参数函数的概念。 1. 可变参数函数的概念 可变参数函数是指函数…...

深拷贝、浅拷贝、移动语义
C 中的拷贝方式 1. 深拷贝(Deep Copy) 定义 深拷贝会复制对象的全部内容,包括对象中动态分配的资源。新对象与原对象完全独立,任何对新对象的修改都不会影响原对象。 实现 通常通过显式的拷贝构造函数或拷贝赋值运算符&#…...

双向链表在系统调度、游戏、文本编辑及组态方面的应用
在编程的奇妙世界里,数据结构就像是一把把神奇的钥匙(前面我们介绍过单向链表的基础了,这里我们更进一步),能帮我们打开解决各种问题的大门。今天,咱们就来聊聊其中一把特别的钥匙——双向链表。双向链表和…...

实践网络安全:常见威胁与应对策略详解
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言 在数字化转型的浪潮中,网络安全的重要性已达到前所未有的高度。无论是个人用户、企业,还是政府机构…...

关于2024年
关于2024年 十分钟前我从床上爬起来,坐在电脑面前先后听了《黄金时代》——声音碎片和《Song F》——达达两首歌,我觉得躺着有些无聊,又或者除夕夜的晚上躺着让我觉得有些不适,我觉得自己应该爬起来,爬起来记录一下我…...
Hive:Hive Shell技巧
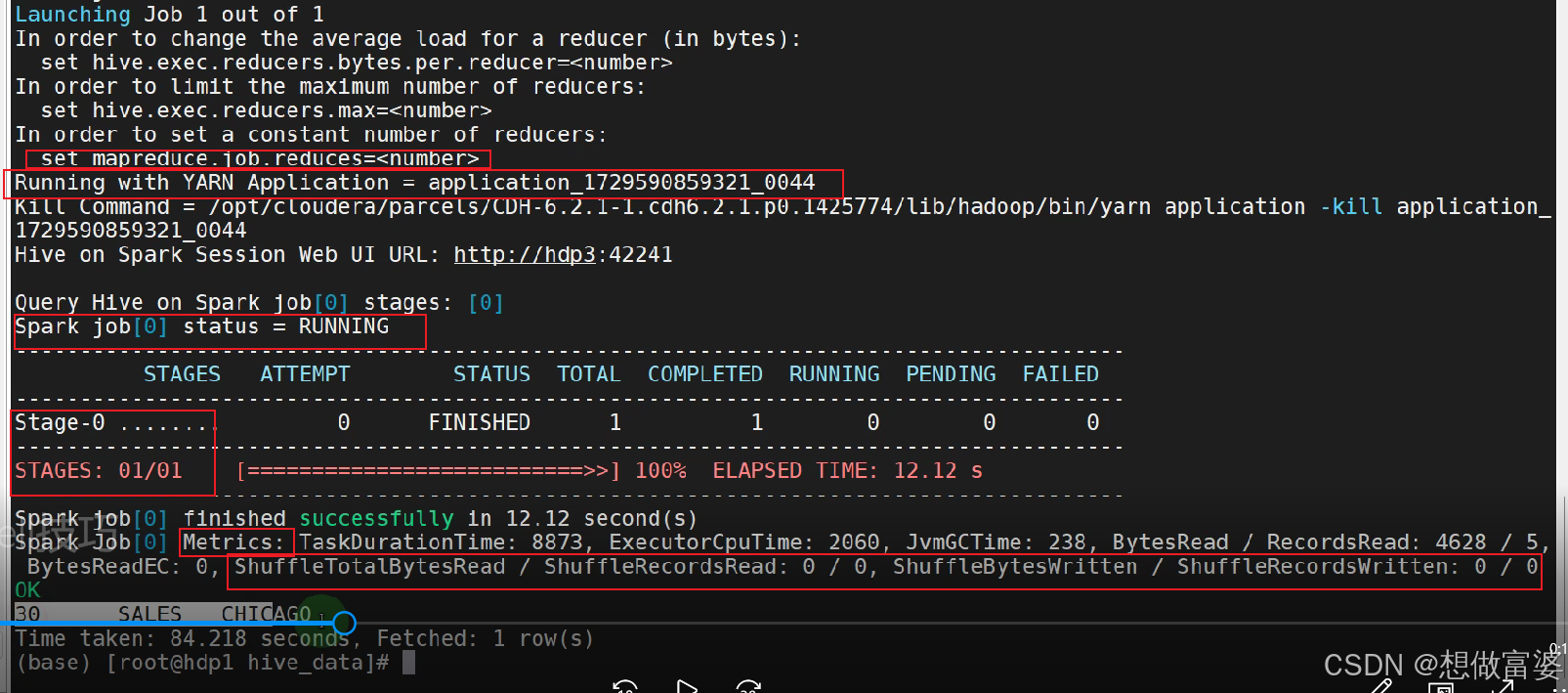
在终端命令窗口不能直接执行select,creat等HQL命令,需要先进入hive之后才能执行,比较麻烦,但是如果使用Hive Shell就可以直接执行 在终端只执行一次Hive命令 -e 参数, "execute"(执行),使用-e参数后会在执行完Hive的命令后退出Hive 使用场景:…...
Markdown Viewer 浏览器, vscode
使用VS Code插件打造完美的MarkDown编辑器(插件安装、插件配置、markdown语法)_vscode markdown-CSDN博客 右键 .md 文件,选择打开 方式 (安装一些markdown的插件) vscode如何预览markdown文件 | Fromidea GitCode - 全球开发者…...
快速分析LabVIEW主要特征进行判断
在LabVIEW中,快速分析程序特征进行判断是提升开发效率和减少调试时间的重要技巧。本文将介绍如何高效地识别和分析程序的关键特征,从而帮助开发者在编写和优化程序时做出及时的判断,避免不必要的错误。 数据流和并行性分析 LabVIEW的图形…...
【Super Tilemap Editor使用详解】(十五):从 TMX 文件导入地图(Importing from TMX files)
Super Tilemap Editor 支持从 TMX 文件(Tiled Map Editor 的文件格式)导入图块地图。通过导入 TMX 文件,你可以将 Tiled 中设计的地图快速转换为 Unity 中的图块地图,并自动创建图块地图组(Tilemap Group)。以下是详细的导入步骤和准备工作。 一、导入前的准备工作 在导…...
--响应式编程实现详解)
JavaScript系列(45)--响应式编程实现详解
JavaScript响应式编程实现详解 🔄 今天,让我们深入探讨JavaScript的响应式编程实现。响应式编程是一种基于数据流和变化传播的编程范式,它使我们能够以声明式的方式处理异步数据流。 响应式编程基础概念 🌟 💡 小知识…...

Lustre Core 语法 - 布尔表达式
Lustre v6 中的 Lustre Core 部分支持的表达式种类中,支持布尔表达式。相关的表达式包括and, or, xor, not, #, nor。 相应的文法定义为 Expression :: not Expression| Expression and Expression| Expression or Expression | Expression xor Expression | # (…...
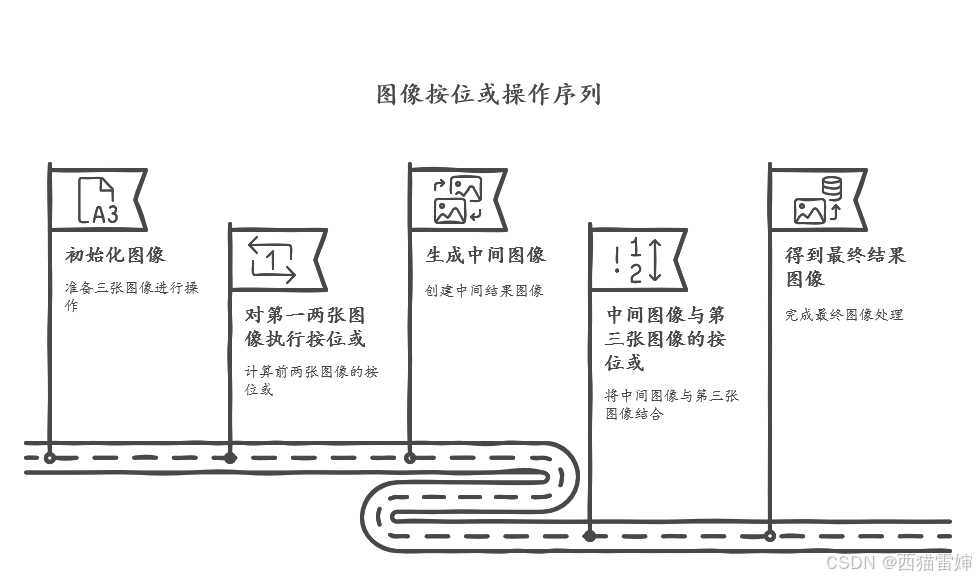
python学opencv|读取图像(四十六)使用cv2.bitwise_or()函数实现图像按位或运算
【0】基础定义 按位与运算:全1取1,其余取0。按位或运算:全0取0,其余取1。 【1】引言 前序学习进程中,已经对图像按位与计算进行了详细探究,相关文章链接如下: python学opencv|读取图像&…...
C# 添加、替换、提取、或删除Excel中的图片
在Excel中插入与数据相关的图片,能将关键数据或信息以更直观的方式呈现出来,使文档更加美观。此外,对于已有图片,你有事可能需要更新图片以确保信息的准确性,或者将Excel 中的图片单独保存,用于资料归档、备…...

工作总结:压测篇
前言 压测是测试需要会的一项技能,作为开发,有点时候也要会一点压测。也是被逼着现学现卖的。 一、压测是什么,以及压测工具的选择 压测,即压力测试,是一种性能测试手段,通过模拟大量用户同时访问系统&am…...

11JavaWeb——SpringBootWeb案例02
前面我们已经实现了员工信息的条件分页查询以及删除操作。 关于员工管理的功能,还有两个需要实现: 新增员工 修改员工 首先我们先完成"新增员工"的功能开发,再完成"修改员工"的功能开发。而在"新增员工"中…...

OpenClaw 落地企业微信:AI 驱动办公,效率提升看得见
前言 在企业数字化办公场景下,将智能对话功能与企业微信集成可有效提升内部沟通效率和业务响应速度。本文系统阐述了OpenClaw与企业微信的对接方案,该方案采用可视化操作界面实现智能机器人的快速部署,助力企业便捷构建专属AI助手࿰…...
)
从V1到V3:手把手教你用PyTorch复现MobileNet进化史(附完整代码)
从V1到V3:手把手教你用PyTorch复现MobileNet进化史(附完整代码) 在移动端和嵌入式设备上部署深度学习模型一直是计算机视觉领域的核心挑战之一。2017年,Google推出的MobileNet系列彻底改变了轻量级卷积神经网络的设计范式…...

30天试用期重置神器:JetBrains IDE免费使用终极解决方案
30天试用期重置神器:JetBrains IDE免费使用终极解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?每次30天试用结束后,那些强大的…...

深入解析 magic-cli:基于模板的自动化代码生成工具设计与实践
1. 项目概述:一个能“变魔术”的命令行工具最近在折腾一些自动化脚本和项目脚手架时,发现了一个挺有意思的开源项目,叫magic-cli。乍一看这个名字,你可能会觉得有点玄乎,命令行工具还能玩出什么“魔法”来?…...

微软MOS认证-Word专家级|超全报考指南
不管是大学生还是职场人,Word 都是绕不开的工具。但多数人只会基础打字排版,面对长文档、规范报告时常常手忙脚乱。MOSWord 专家级认证,正是帮你把 “普通 Word” 变成 “高-效办公武器” 的实用路径。#微软mos认证 #大学生考证 #mos认证考试…...

FreeRTOS任务通知:轻量级任务通信机制的原理与应用实践
1. 项目概述:从“消息队列”到“任务通知”的思维跃迁在嵌入式实时操作系统(RTOS)的开发中,任务间的通信与同步是核心议题。我们习惯了使用队列(Queue)、信号量(Semaphore)、事件组&…...
)
KNN算法调参实战:如何为你的数据选择合适的距离度量(从闵可夫斯基距离说起)
KNN算法调参实战:如何为你的数据选择合适的距离度量(从闵可夫斯基距离说起) 在机器学习项目中,K近邻(KNN)算法因其简单直观而广受欢迎。但许多实践者往往忽略了一个关键环节——距离度量的选择。当你在Scik…...
)
LangGraph Agent 开发指南(9~工具 Tools)
一、什么是工具? 1.1 通俗解释 想象你有一个智能助手: 没有工具:你: 帮我查一下北京明天的天气助手: 抱歉,我没有联网功能,无法查询实时天气有工具:你: 帮我查一下北京明天的天气助手: 好的,…...

告别‘不是内部或外部命令’:手把手配置MsBuild.exe环境变量与命令行编译实战
1. 为什么命令行找不到MsBuild.exe? 刚装完系统或者新配置开发环境时,很多朋友都会遇到这个经典错误:在命令行输入msbuild后,系统提示"不是内部或外部命令"。这就像你拿着钥匙却找不到锁孔一样让人抓狂。其实这个问题90…...

保姆级教程:将LabelImg标注的VOC数据一键转为Ultralytics RT-DETR训练格式
从VOC到RT-DETR:零基础完成目标检测数据格式转换实战 当你第一次尝试用Ultralytics框架训练RT-DETR模型时,最令人头疼的往往不是模型调参,而是数据准备阶段——特别是当你的标注数据还停留在LabelImg生成的VOC格式(XML文件&#x…...