MapReduce概述
目录
- 1. MapReduce概述
- 2. MapReduce的功能
- 2.1 数据划分和计算任务调度
- 2.2 数据/代码互定位
- 2.3 系统优化
- 2.4 出错检测和恢复
- 3. MapReduce处理流程
- 4. MapReduce编程基础
- 参考
1. MapReduce概述
MapReduce是面向大数据并行处理的计算模型、框架和平台:
1. 基于集群的高性能并行计算平台:它允许使用市场上普通的商用服务器构成一个包含数十、数百甚至数千个节点的分布式并行计算集群。
2. 并行计算与运行软件框架:它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果。
3. 并行程序设计模型与方法:它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口。
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性,每个节点会周期性地返回它所完成的工作和最新的状态。如果一个节点保持沉默超过一个预设的时间间隔,主节点将标记这个节点状态为死亡,并把分配给这个节点的数据发到别的节点上。
2. MapReduce的功能
2.1 数据划分和计算任务调度
系统自动将一个作业待处理的数据划分成很多个数据块,每个数据块对应于一个计算任务,并自动调度计算节点来处理相应的数据块。作业和任务调度功能主要负责分配和调度计算节点,同时负责监控这些节点的执行状态,并负责Map节点执行的同步控制。
2.2 数据/代码互定位
1. 本地化数据处理:一个计算节点尽可能处理其本地磁盘上所分布存储的数据,实现了代码向数据的迁移。
2. 无法本地化数据处理:寻找其他可用节点并将数据从网络上传送给该节点,但将尽可能从数据所在的本地机架上寻找可用节点以减少通信延迟,实现了数据向代码的迁移。
2.3 系统优化
中间结果数据进入Reduce节点前会进行一定的合并处理;一个Reduce节点所处理的数据可能来自多个Map节点,为了避免Reduce计算阶段发生数据相关性,Map节点输出的中间结果需使用一定的策略进行适当的划分处理,以保证相关性数据发送到同一个Reduce节点。
此外,系统还进行一些计算性能优化处理,如对最慢的计算任务采用多备份执行、选最快完成者作为结果。
2.4 出错检测和恢复
以低端商用服务器构成的大规模MapReduce计算集群中,节点硬件出错和软件出错是常态,因此MapReduce需要能检测并隔离出错节点,调度分配新的节点接管出错节点的计算任务。同时,系统还将维护数据存储的可靠性,用多备份冗余存储机制提高数据存储的可靠性,并能及时检测和恢复出错的数据。
3. MapReduce处理流程
MapReduce处理流程可以分为三个阶段:Map、Shuffle和Reduce。
Map是映射,负责数据的过滤分发,将原始数据转换成键值对;Shuffle将Map的输出进行排序与分割后再交给Reduce;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。MapReduce的处理流程如下图所示。

Map和Reduce操作需要开发人员自己定义相应Map类和Reduce类,而Shuffle是系统自动实现的。Shuffle过程发生在Map和Reduce两端,Map端的Shuffle是对单个Map的结果进行分区、排序、分割,然后将属于同一分区的输出合并在一起并写在磁盘上(分区有序的含义是Map输出的键值对按分区进行排列,具有相同分区值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列)。Reduce段的Shuffle是从多个Map上拉取属于自己分区的数据,然后在保持数据排序的情况下将多个Map上的数据按照键值进行合并,同时将多个合并后的数据写入磁盘,最后将多个合并后的数据按照键值进行分组来作为Reduce的输入。
4. MapReduce编程基础
Hadoop内置数据类型如下表所示。
| 类型名 | 含义 |
|---|---|
| BooleanWritable | 标准布尔类型 |
| ByteWritable | 单字节数值 |
| DoubleWritable | 双精度浮点数 |
| FloatWritable | 单精度浮点数 |
| IntWritable | 整型 |
| LongWritable | 长整型 |
| Text | 使用UTF-8格式存储的文本 |
| NullWritable | 当<key, value>中的key或value为空时使用 |
| ArrayWritable | 存储属于Writable类型值的数组 |
下面是maven项目中pom.xml中依赖部分的配置。
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.6</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions></dependency></dependencies>
下面是简单使用Hadoop中内置数据类型的代码。
import org.apache.hadoop.io.ArrayWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
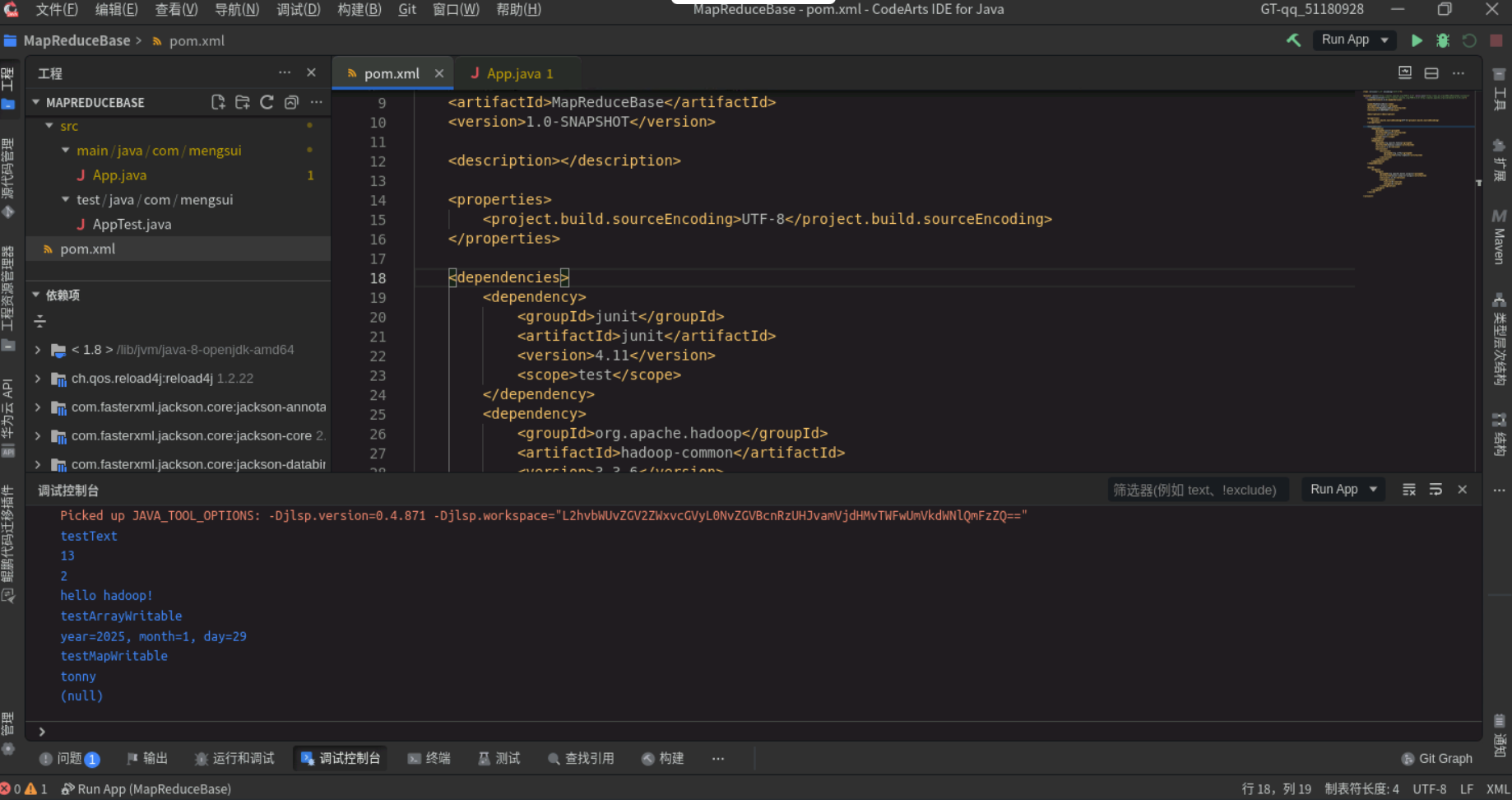
import org.apache.hadoop.io.Writable;public class App {public static void testText() {System.out.println("testText");Text text = new Text("hello hadoop!");System.out.println(text.getLength());System.out.println(text.find("ll"));System.out.println(text.toString());}public static void testArrayWritable() {System.out.println("testArrayWritable");ArrayWritable arr = new ArrayWritable(IntWritable.class);IntWritable year = new IntWritable(2025);IntWritable month = new IntWritable(1);IntWritable day = new IntWritable(29);arr.set(new Writable[] {year, month, day});System.out.printf("year=%s, month=%s, day=%s%n", arr.get()[0], arr.get()[1], arr.get()[2]);}public static void testMapWritable() {System.out.println("testMapWritable");MapWritable map = new MapWritable();Text k1 = new Text("name");Text v1 = new Text("tonny");Text k2 = new Text("password");map.put(k1, v1);map.put(k2, NullWritable.get());System.out.println(map.get(k1).toString());System.out.println(map.get(k2).toString());}public static void main(String[] args) {testText();testArrayWritable();testMapWritable();}
}
运行结果如下。
参考
吴章勇 杨强著 大数据Hadoop3.X分布式处理实战
相关文章:
MapReduce概述
目录 1. MapReduce概述2. MapReduce的功能2.1 数据划分和计算任务调度2.2 数据/代码互定位2.3 系统优化2.4 出错检测和恢复 3. MapReduce处理流程4. MapReduce编程基础参考 1. MapReduce概述 MapReduce是面向大数据并行处理的计算模型、框架和平台: 1. 基于集群的高性能并行…...

循环神经网络(RNN)+pytorch实现情感分析
目录 一、背景引入 二、网络介绍 2.1 输入层 2.2 循环层 2.3 输出层 2.4 举例 2.5 深层网络 三、网络的训练 3.1 训练过程举例 1)输出层 2)循环层 3.2 BPTT 算法 1)输出层 2)循环层 3)算法流程 四、循…...
Mac cursor设置jdk、Maven版本
基本配置 – Cursor 使用文档 首先是系统用户级别的设置参数,运行cursor,按下ctrlshiftp,输入Open User Settings(JSON),在弹出的下拉菜单中选中下面这样的: 在打开的json编辑器中追加下面的内容: {"…...
WPS数据分析000005
目录 一、数据录入技巧 二、一维表 三、填充柄 向下自动填充 自动填充选项 日期填充 星期自定义 自定义序列 1-10000序列 四、智能填充 五、数据有效性 出错警告 输入信息 下拉列表 六、记录单 七、导入数据 编辑 八、查找录入 会员功能 Xlookup函数 VL…...

CTF从入门到精通
文章目录 背景知识CTF赛制 背景知识 CTF赛制 1.web安全:通过浏览器访问题目服务器上的网站,寻找网站漏洞(sql注入,xss(钓鱼链接),文件上传,包含漏洞,xxe,ssrf,命令执行,…...
Flutter使用Flavor实现切换环境和多渠道打包
在Android开发中通常我们使用flavor进行多渠道打包,flutter开发中同样有这种方式,不过需要在原生中配置 具体方案其实flutter官网个了相关示例(https://docs.flutter.dev/deployment/flavors),我这里记录一下自己的操作 Android …...

Springboot如何使用面向切面编程AOP?
Springboot如何使用面向切面编程AOP? 在 Spring Boot 中使用面向切面编程(AOP)非常简单,Spring Boot 提供了对 AOP 的自动配置支持。以下是详细的步骤和示例,帮助你快速上手 Spring Boot 中的 AOP。 1. 添加依赖 首先ÿ…...

51单片机(STC89C52)开发:点亮一个小灯
软件安装: 安装开发板CH340驱动。 安装KEILC51开发软件:C51V901.exe。 下载软件:PZ-ISP.exe 创建项目: 新建main.c 将main.c加入至项目中: main.c:点亮一个小灯 #include "reg52.h"sbit LED1P2^0; //P2的…...
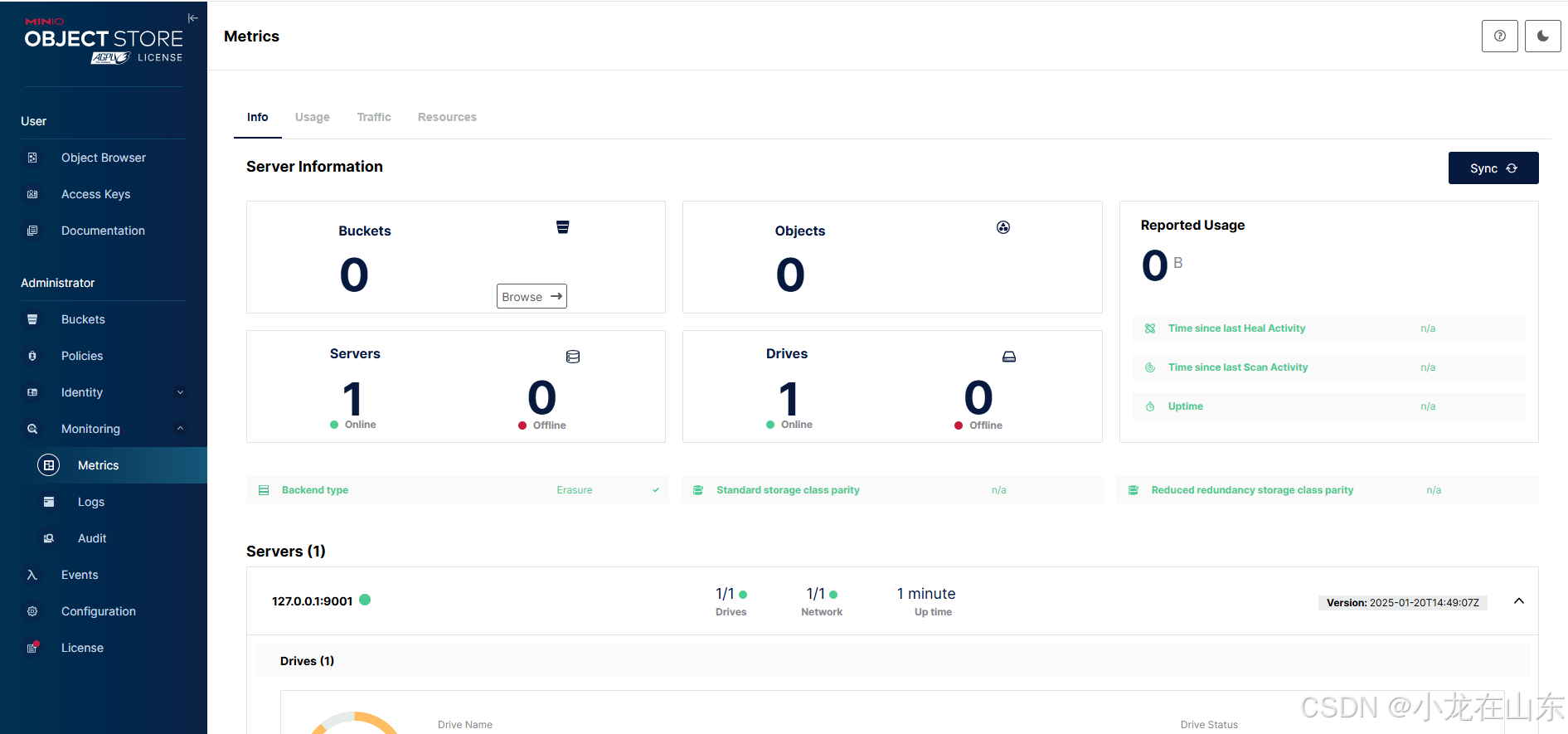
基于MinIO的对象存储增删改查
MinIO是一个高性能的分布式对象存储服务。Python的minio库可操作MinIO,包括创建/列出存储桶、上传/下载/删除文件及列出文件。 查看帮助信息 minio.exe --help minio.exe server --help …...
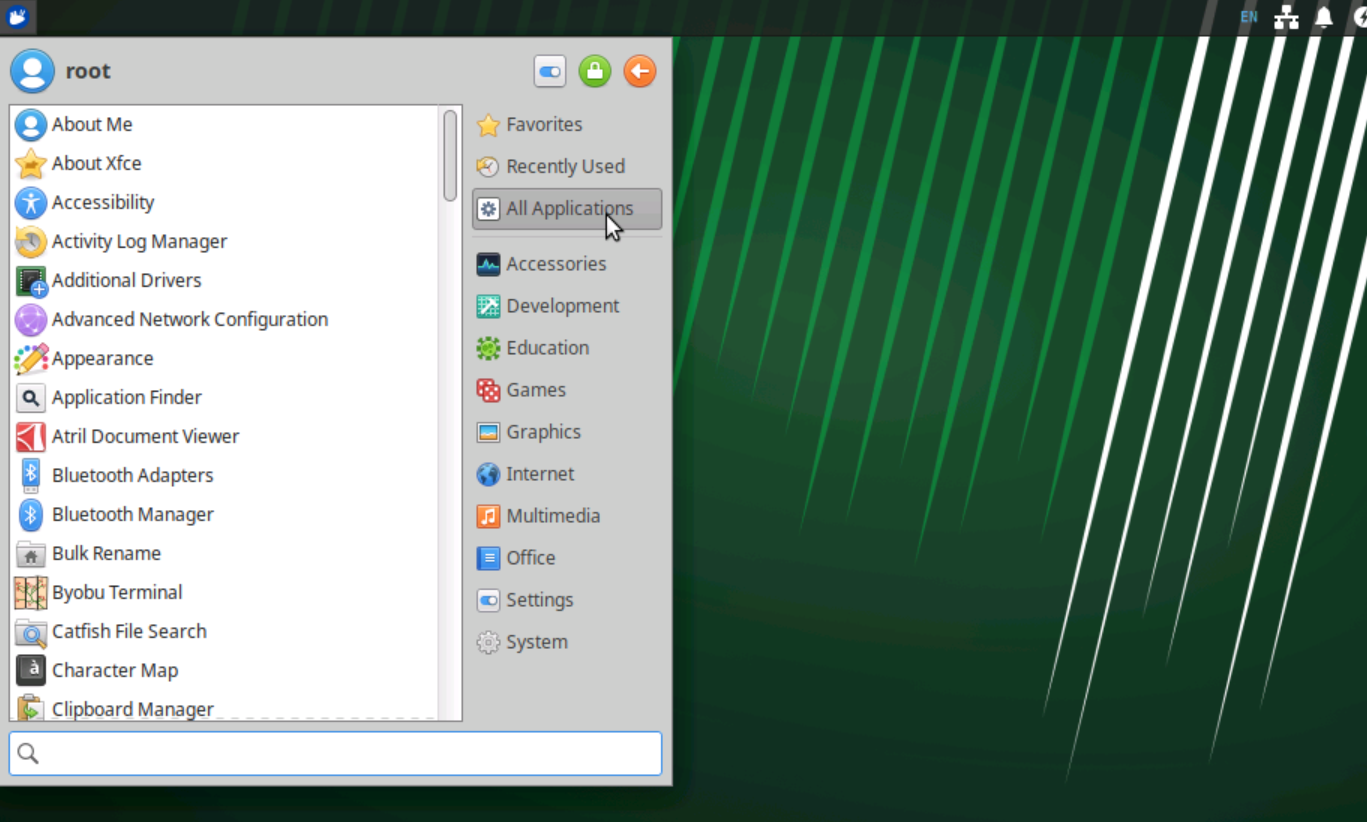
Ubuntu Server 安装 XFCE4桌面
Ubuntu Server没有桌面环境,一些软件有桌面环境使用起来才更加方便,所以我尝试安装桌面环境。常用的桌面环境有:GNOME、KDE Plasma、XFCE4等。这里我选择安装XFCE4桌面环境,主要因为它是一个极轻量级的桌面环境,适合内…...

MySQL 存储函数:数据库的自定义函数
在数据库开发中,存储函数(Stored Function)是一种非常有用的工具。它允许我们创建自定义的函数,这些函数可以在 SQL 查询中像内置函数一样使用,用于实现特定的逻辑和计算。本文将深入探讨 MySQL 存储函数的概念、与存储…...
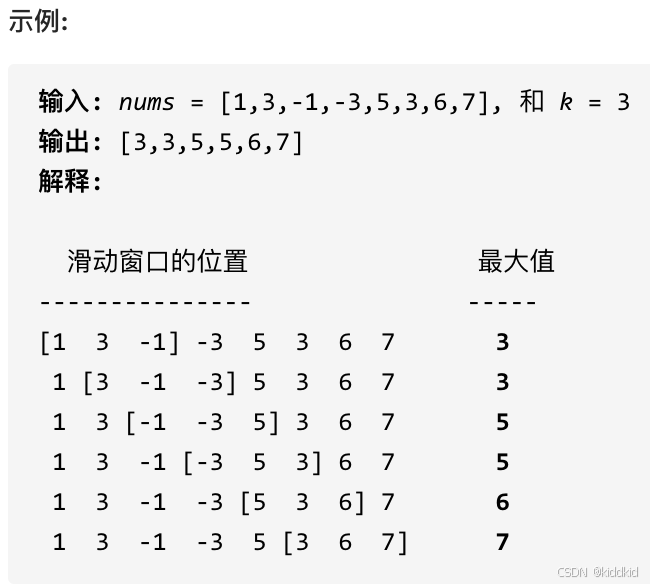
代码随想录_栈与队列
栈与队列 232.用栈实现队列 232. 用栈实现队列 使用栈实现队列的下列操作: push(x) – 将一个元素放入队列的尾部。 pop() – 从队列首部移除元素。 peek() – 返回队列首部的元素。 empty() – 返回队列是否为空。 思路: 定义两个栈: 入队栈, 出队栈, 控制出入…...

【微服务与分布式实践】探索 Sentinel
参数设置 熔断时长 、最小请求数、最大RT ms、比例阈值、异常数 熔断策略 慢调⽤⽐例 当单位统计时⻓内请求数⽬⼤于设置的最⼩请求数⽬,并且慢调⽤的⽐例⼤于阈值,则接下来的熔断时⻓内请求会⾃动被熔断 异常⽐例 当单位统计时⻓内请求数⽬⼤于设置…...
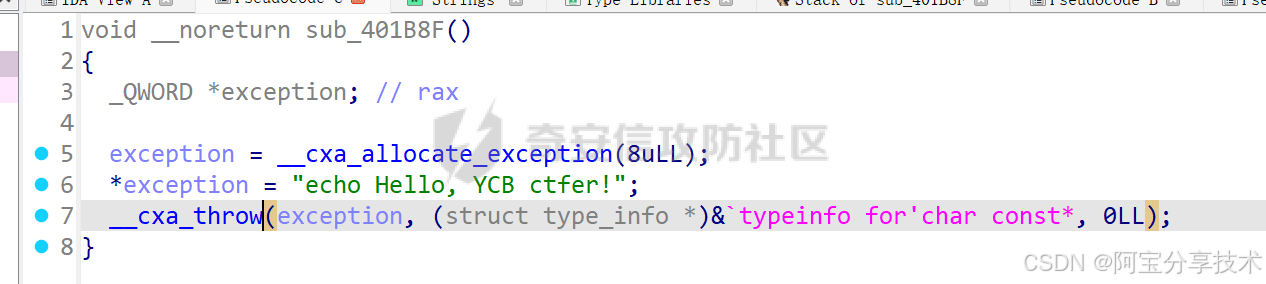
深入研究异常处理机制
一、原理探究 C异常处理 本节内容针对 Linux 下的 C 异常处理机制,重点在于研究如何在异常处理流程中利用溢出漏洞,所以不对异常处理及 unwind 的过程做详细分析,只做简单介绍 异常机制中主要的三个关键字:throw 抛出异常&#x…...

【memgpt】letta 课程4:基于latta框架构建MemGpt代理并与之交互
Lab 3: Building Agents with memory 基于latta框架构建MemGpt代理并与之交互理解代理状态,例如作为系统提示符、工具和agent的内存查看和编辑代理存档内存MemGPT 代理是有状态的 agents的设计思路 每个步骤都要定义代理行为 Letta agents persist information over time and…...

讯飞智作 AI 配音技术浅析(二):深度学习与神经网络
讯飞智作 AI 配音技术依赖于深度学习与神经网络,特别是 Tacotron、WaveNet 和 Transformer-TTS 模型。这些模型通过复杂的神经网络架构和数学公式,实现了从文本到自然语音的高效转换。 一、Tacotron 模型 Tacotron 是一种端到端的语音合成模型ÿ…...
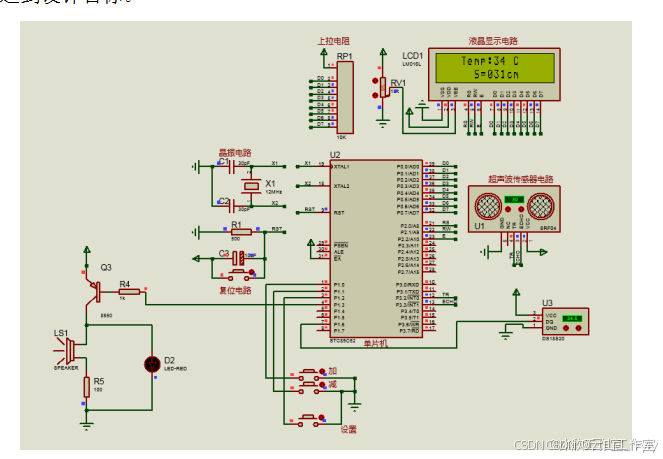
基于单片机的超声波液位检测系统(论文+源码)
1总体设计 本课题为基于单片机的超声波液位检测系统的设计,系统的结构框图如图2.1所示。其中包括了按键模块,温度检测模块,超声波液位检测模块,显示模块,蜂鸣器等器件设备。其中,采用STC89C52单片机作为主控…...

Autogen_core: test_code_executor.py
目录 代码代码解释 代码 import textwrapimport pytest from autogen_core.code_executor import (Alias,FunctionWithRequirements,FunctionWithRequirementsStr,ImportFromModule, ) from autogen_core.code_executor._func_with_reqs import build_python_functions_file f…...

从0开始使用面对对象C语言搭建一个基于OLED的图形显示框架
目录 前言 环境介绍 代码与动机 架构设计,优缺点 博客系列指引 前言 笔者前段时间花费了一周,整理了一下自从TM1637开始打算的,使用OLED来搭建一个通用的显示库的一个工程。笔者的OLED库已经开源到Github上了,地址在…...
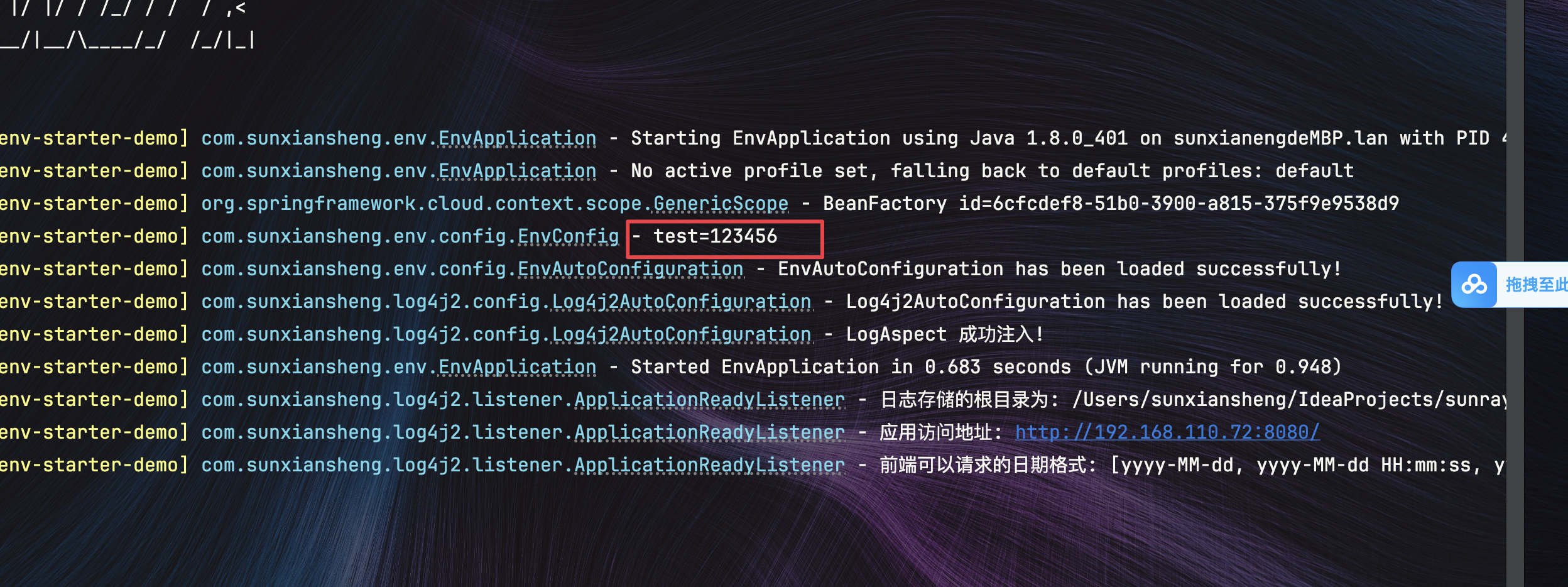
Java实现.env文件读取敏感数据
文章目录 1.common-env-starter模块1.目录结构2.DotenvEnvironmentPostProcessor.java 在${xxx}解析之前执行,提前读取配置3.EnvProperties.java 这里的path只是为了代码提示4.EnvAutoConfiguration.java Env模块自动配置类5.spring.factories 自动配置和注册Enviro…...
Uncertainty-Aware Pixel-Level Contrastive Learning for Enhanced Semi-Supervised Medical Image Segmen
1. 医学图像分割的挑战与半监督学习机遇 医学图像分割一直是计算机视觉领域的重要研究方向,它能够帮助医生快速定位病灶区域,提高诊断效率。但在实际应用中,我们常常面临标注数据稀缺的问题——专业医生标注一张CT或MRI图像可能需要数小时&am…...

CTC语音唤醒模型在医疗语音录入系统中的应用案例
CTC语音唤醒模型在医疗语音录入系统中的应用案例 1. 引言 在医疗场景中,医生每天需要处理大量的病历记录工作。传统的手写或键盘输入方式不仅效率低下,还容易分散医生对患者的注意力。现在,通过CTC语音唤醒技术,医疗语音录入系统…...

3个技巧快速解锁百度网盘SVIP下载特权
3个技巧快速解锁百度网盘SVIP下载特权 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾因百度网盘Mac版的下载速度而苦恼?普通用户下…...

AI-AGENT概念解析 - LLM任务训练
**问题:LLM大模型是否针对写作,做PPT,编写程序,拆解任务这些输入参数,用同一个大模型需要训练为不同的模型结构或参数化的权重矩阵去适应那些不同的提示词输入参数? 对于不同的任务类型(写作、做…...

从零到一:超外差收音机DIY全流程解析与调试心法
1. 超外差收音机原理精要 第一次接触超外差收音机时,我被这个拗口的专业名词吓到了。但拆解开来理解其实很简单——"超"指的是本振频率超过信号频率,"外差"则是混频产生差频的过程。这种设计巧妙地把不同电台信号都转换成固定的465k…...

Gradio界面定制化:为DAMO-YOLO WebUI添加导出检测结果CSV功能
Gradio界面定制化:为DAMO-YOLO WebUI添加导出检测结果CSV功能 1. 项目背景与需求 如果你用过那个基于DAMO-YOLO的手机检测WebUI,可能会发现一个问题:检测结果只能看,不能存。 每次上传图片,系统会告诉你检测到了几个…...
)
【2026年阿里巴巴春招- 3月28日-算法岗-第二题- 隐式素数计算】(题目+思路+JavaC++Python解析+在线测试)
题目内容 我们称一个正整数为隐式素数,如果它不同的正因子的个数是一个素数。给定一个闭区间$ [l,r]$,请计算该区间内隐式素数的个数 输入描述 每个测试文件均包含多组测试数据。第一行输入一个整数$ T (1 ≤ T ≤ 10^4)$,代表数据组数,每组测试数据描述如下: 在一行上…...

使用Yolo 11进行定制化图像识别全流程
全流程预览 Label Studio标注 → 导出YOLO格式 → 编写data.yaml → 拆分数据集 → 模型训练 → 预测部署步骤工具/技术产出物数据标注Label Studio标注好的图片数据导出YOLO with imagesimages/ labels/配置文件data.yaml数据集配置数据拆分Python脚本train/val/test模型训练…...

安路PH1A180 FPGA实战:用米联客FDMA IP搞定DDR视频缓存,附源码调试心得
安路PH1A180 FPGA实战:FDMA IP与DDR视频缓存深度优化指南 在视频处理系统中,FPGADDR架构已成为实时高清视频流处理的标准方案。安路PH1A180凭借其高性能特性,配合米联客FDMA IP核,能够构建稳定高效的视频缓存系统。但在实际工程落…...

Bongo-Cat-Mver:实时键盘动画工具的创新应用与实践指南
Bongo-Cat-Mver:实时键盘动画工具的创新应用与实践指南 【免费下载链接】Bongo-Cat-Mver An Bongo Cat overlay written in C 项目地址: https://gitcode.com/gh_mirrors/bo/Bongo-Cat-Mver 在直播、教学和演示场景中,如何让观众清晰感知键盘操作…...