循环神经网络(RNN)+pytorch实现情感分析
目录
一、背景引入
二、网络介绍
2.1 输入层
2.2 循环层
2.3 输出层
2.4 举例
2.5 深层网络
三、网络的训练
3.1 训练过程举例
1)输出层
2)循环层
3.2 BPTT 算法
1)输出层
2)循环层
3)算法流程
四、循环神经网络实现情感分析
4.1 实验介绍
4.2 数据集介绍
4.3 Embedding操作
4.4 pytorch实现
1)数据处理
2)模型设计
3)训练配置
4)训练过程
5)测试模型
一、背景引入
全连接神经网络和卷积神经网络在运行时每次处理的都是独立的输入数据,没有记忆功能。
有些应用需要神经网络具有记忆能力, 典型的是输入数据为时间序列的问题, 时间序列可以抽象地表示为一个向量序列:。
其中, 是向量, 下标 i 为时刻。 各个时刻的向量之间存在相关。 例如, 在说话时当前要说的词和之前已经说出去的词之间存在关系, 依赖于上下文语境。算法需要根据输入序列来产生输出值, 这类问题称为序列预测问题, 需要注意的是输入序列的长度可能不固定。
语音识别和自然语言处理是序列预测问题的典型代表。 语音识别的输入是一个语音信号序列, 自然语言处理的输入是文字序列。 下面用一个实际例子来说明序列预测问题, 假设神经网络要用来完成汉语填空, 考虑下面这个句子:
现在已经下午 2 点了, 我们还没有吃饭, 非常饿, 赶快去餐馆_____ 。
根据上下文的理解, 这个空的最佳答案是“吃饭”, 如果没有上下文, 去参观可以喝咖啡或者歇一会, 但结合前面的饿了, 最佳答案显然是“吃饭”。 为了完成这个预测, 神经网络需要依次输入前面的每一个词, 最后输入“餐馆” 这个词时, 得到预测结果。
神经网络的每次输入为一个词, 最后要预测出这个空的内容, 这需要神经网络能够理解语义, 并记住之前输入的信息, 即语句上下文。 神经网络要根据之前的输入词序列计算出当前使用哪个词的概率最大。
二、网络介绍
循环神经网络(Recurrent Neural Network, 简称 RNN) 是一种能够处理序列数据的神经网络模型。 RNN 具有记忆功能, 它会记住网络在上一时刻运行时产生的状态值, 并将该值用于当前时刻输出值的生成。
RNN 由输入层、 循环层和输出层构成, 也有可能还包含全连接层。 输入层和输出层与前馈型神经网络类似, 唯一不同的是循环层。
2.1 输入层
输入值通常是一个时间序列。每个输入样本由一系列按时间顺序排列的数据点组成,每个数据点可以是向量、标量或其他形式的数据。例如,在自然语言处理中,一个句子可以被视为一个时间序列,其中每个单词或字符代表一个时间步的输入。
2.2 循环层

循环神经网络的输入为向量序列, 每个时刻接收一个输入 , 网络会产生一个输出
, 而这个输出是由之前时刻的输入序列
共同决定的。
假设 t 时刻的状态值为 , 它由上一时刻的状态值
以及当前时刻的输入值
共同决定, 即:
是输入层到隐藏层的权重矩阵
是隐藏层内的权重矩阵,可以看作状态转移权重。其并不会随着时间变化, 在每个时刻进行计算时使用的是同一个矩阵。 这样做的好处是一方面减少了模型参数, 另一方面也记住了之前的信息。
为偏置向量
一个神经元更形象的表示如下:

循环神经网络中循环层可以只有一层, 也可以有多个循环层。
2.3 输出层
输出层以循环层的输出值作为输入并产生循环神经网络最终的输出, 它不具有记忆功能。 输出层实现的变换为:
为权重矩阵
为偏置向量
为激活函数。对于分类任务,
2.4 举例
一个简单的循环神经网络, 这个网络有一个输入层、 一个循环层和一个输出层。其中输入层有 2 个神经元, 循环层有 3 个神经元, 输出层有 2 个神经元。

- 循环层的输出
,其中输入向量是二维的, 输出向量是三维的
- 输出层的输出
,其中输入向量是三维的, 输出向量是二维的
递推:
按照时间轴进行展开, 当输入为 时, 网络的输出为:
当输入为 时, 网络的输出为:
输出值与都有关。 依此类推, 可以得到
时网络的输出值,
时的输出值与
都有关。
可以看出循环神经网络通过递推方式实现了记忆功能。
2.5 深层网络
可以构建含有多个隐藏层的网络,有3种方案
- Deep Input-to-Hidden Function:它在循环层之前加入多个全连接层, 将输入向量进行多层映射之后再送入循环层进行处理。
- Deep Hidden-to-Hidden Transition:它使用多个循环层, 这与前馈型神经网络类似, 唯一不同的是计算隐含层输出的时候需要利用本隐含层上一时刻的值。
- Deep Hidden-to-Output Function:它在循环层到输出层之间加入多个全连接层。
三、网络的训练
循环神经网络(RNN)处理序列数据,每个训练样本是一个时间序列,包含多个相同维度的向量。训练使用BPTT算法(Back Propagation Through Time 算法),先对序列中每个时刻的输入进行正向传播,再通过反向传播计算梯度并更新参数。每个训练样本的序列长度可以不同,前后时刻的输入值有关联。
3.1 训练过程举例
网络结构如下:

有一个训练样本, 其序列值为:。其中,
为输入向量,
为标签向量。 循环层状态的初始值设置为 0。
在 t=1 时刻, 网络的输出为:
在 t=2 时刻, 网络的输出为:
在 t=3 时刻, 网络的输出为:
对单个样本的序列数据, 定义 t 时刻的损失函数为:
样本的总损失函数为各个时刻损失函数之和:
1)输出层
如果输出层使用 softmax 变换, 则损失函数为 softmax 交叉熵:
梯度的计算公式为:
根据之前全连接神经网络中的推论:,
可以得到 t 时刻:
- 损失函数对输出层权重的梯度:
- 损失函数对偏置项的梯度为:
故得到总时刻:
- 总损失函数对权重的梯度为:
- 总损失函数对偏置项的梯度为:
2)循环层
按时间序列展开之后, 各个时刻在循环层的输出值是权重矩阵和偏置项的复合函数。
在 t=1 时刻,
根据全连接神经网络中的推论
可以得到损失函数对 的梯度:

由于 t=1 时循环层的输出值与 无关, 因此:
对偏置项的偏导为:
在 t=2 时刻, 。当前式子中
出现了两次, 因此损失函数对
的梯度为:
又由于:,故有
可以得到损失函数对 的梯度为:

损失函数对 的梯度为:

在 t=3 时刻, 。当前式子中
出现了三次, 因此损失函数对
的梯度为:
类似地, 可以计算出:

由此可以计算出 和
。 在计算出每个时刻的损失函数对各个参数的梯度之后, 把它们加起来得到总损失函数对各个参数的梯度:
接下来用梯度下降法更新参数。
3.2 BPTT 算法
将上面的例子推广到一般情况, 得到通用的 BPTT 算法。
循环神经网络的反向传播是基于时间轴进行的, 我们需要计算所有时刻的总损失函数对所有参数的梯度, 然后用梯度下降法进行更新。 另外循环神经网络在各个时刻的权重、 偏置都是相同的。
设 t 时刻的损失函数为:
总损失函数为:
1)输出层
首先计算输出层偏置项的梯度:
如果选择 softmax 作为输出层的激活函数, 交叉熵作为损失函数, 则上面的梯度为:
对输出层权重矩阵的梯度为:
2)循环层
因此有:
由此建立了 与
之间的递推关系。 定义误差项为:
在总损失函数 中, 比
更早的时刻的损失函数不含有
, 因此与
无关。由于
由
决定, 因此
与
直接相关。 比
晚的时刻的
,
…,
都与
有关, 因此有:
存在

从而得到:
由此建立了误差项沿时间轴的递推公式, 递推的起点是最后一个时刻的误差:
根据误差项可以计算出损失函数对权重和偏置的梯度:
3)算法流程

四、循环神经网络实现情感分析
4.1 实验介绍
通过 RNN 模型对电影评论进行情感分类,判断评论是正面还是负面。
4.2 数据集介绍
IMDB 数据集包含 50,000 条电影评论, 其中一半用于训练(25,000 条), 另一半用于测试(25,000 条)。 每条评论都附带一个标签, 要么是'pos'表示正面评价, 要么是'neg'表示负面评价。 这些评论通常以文本文件的形式存在, 每个文件中包含一条评论。
4.3 Embedding操作
Embedding 过程:计算机无法直接处理一个单词或者一个汉字, 需要把一个 token 转化成计算机可以识别的向量 。
Embedding 是一种将高维数据(如文本或图像) 转换为较低维度的向量表示的技术。 这种表示捕捉了数据的关键特征, 使得在处理、 分析和机器学习任务中更加高效。 通常用于将离散的、 非连续的数据转换为连续的向量表示, 以便于计算机进行处理。
Embedding 技术通常会捕获数据的语义信息。 在 NLP 中, 这意味着相似的单词或短语在嵌入空间中会更接近, 而不同的单词或短语会远离彼此。 这有助于模型理解语言的含义和语义关系。
Embedding 技术通常是上下文感知的, 它们可以捕获数据点与其周围数据点的关系。 在 NLP 中, 单词的嵌入会考虑其周围的单词, 以更好地表示语法和语义。
简单的说, Embedding 就是把一个东西映射到一个向量 X。 如果这个东西很像, 那么得到的向量 x1 和 x2 的欧式距离就很小。
4.4 pytorch实现
1)数据处理
首先对数据集进行处理, 提取单词表, 单词表的最大尺寸是 10000。
# 加载数据
def load_data(data_dir):texts = [] # 存储文本数据labels = [] # 存储标签数据for label_type in ['neg', 'pos']: # 遍历负面和正面评论目录dir_name = os.path.join(data_dir, label_type) # 构建目录路径 /IMDB/train/neg/0_2.txtfor fname in os.listdir(dir_name): # 遍历目录中的文件if fname.endswith('.txt'): # 只处理文本文件with open(os.path.join(dir_name, fname), encoding="utf-8") as f:texts.append(f.read()) # 读取文本内容labels.append(0 if label_type == 'neg' else 1) # 根据目录确定标签(负面:0,正面:1)return texts, labels # 返回文本和标签# 加载训练和测试数据
train_texts, train_labels = load_data('./IMDB/train')
test_texts, test_labels = load_data('./IMDB/test')# 构建词汇表
max_features = 10000 # 词汇表大小,最多包含10000个单词
maxlen = 150 # 每个文本的最大长度为150tokenizer = Counter(" ".join(train_texts).split()) # 统计词频
# print(tokenizer.most_common(100))
# [('the', 287032), ('a', 155096), ('and', 152664), ('of', 142972),
# ('to', 132568), ('is', 103229), ('in', 85580), ('I', 65973), ('that', 64560), ('this', 57199), ('it', 54439), ('/><br', 50935), ('was', 46698), ('as', 42510), ('with', 41721), ('for', 41070), ('but', 33790), ('The', 33762), ('on', 30767), ('movie', 30506), ('are', 28499), ('his', 27687), ('film', 27402), ('have', 27126), ('not', 26266), ('be', 25512), ('you', 25123), ('he', 21676), ('by', 21426), ('at', 21295), ('one', 20692), ('an', 20626), ('from', 19239), ('who', 18838), ('like', 18133), ('all', 18048), ('they', 17840), ('has', 16472), ('so', 16336), ('just', 16326), ('about', 16286), ('or', 16224), ('her', 15830), ('out', 14368), ('some', 14207), ('very', 13082), ('more', 12950), ('This', 12279), ('would', 11923), ('what', 11685), ('when', 11488), ('good', 11436), ('only', 11106), ('their', 11008), ('It', 10952), ('if', 10899), ('had', 10876), ('really', 10815), ("it's", 10727), ('up', 10658), ('which', 10658), ('even', 10607), ('can', 10560), ('were', 10460), ('my', 10166), ('see', 10155), ('no', 10062), ('she', 9933), ('than', 9772), ('-', 9355), ('been', 9050), ('there', 9036), ('into', 8950), ('get', 8777), ('will', 8558), ('story', 8527), ('much', 8507), ('because', 8357), ('other', 7917), ('most', 7859), ('we', 7808), ('time', 7765), ('me', 7540), ('make', 7485), ('could', 7462), ('also', 7422), ('do', 7408), ('how', 7403), ('first', 7339), ('people', 7335), ('its', 7323), ('/>The', 7243), ('any', 7232), ('great', 7191), ("don't", 7007), ('made', 6962), ('think', 6659), ('bad', 6506), ('him', 6347), ('being', 6202)]
vocab = [word for word, num in tokenizer.most_common(max_features)] # 取出前10000个常用词
# print(vocab)
word_index = {word: idx + 1 for idx, word in enumerate(vocab)} # 为每个词分配一个索引
# print(word_index)# 将文本转换为序列
def texts_to_sequences(texts):return [[word_index.get(word, 0) for word in text.split()] for text in texts]# 转换训练和测试文本为序列
x_train = texts_to_sequences(train_texts)#{}
x_test = texts_to_sequences(test_texts)# 将序列填充到固定长度
x_train_padded = pad_sequence([torch.tensor(seq[:maxlen]) for seq in x_train], batch_first=True, padding_value=0)
x_test_padded = pad_sequence([torch.tensor(seq[:maxlen]) for seq in x_test], batch_first=True, padding_value=0)y_train = torch.tensor(train_labels) # 转换训练标签为张量
y_test = torch.tensor(test_labels) # 转换测试标签为张量# 创建 Dataset 和 DataLoader
class TextDataset(Dataset):def __init__(self, texts, labels):self.texts = texts # 文本数据self.labels = labels # 标签数据def __len__(self):return len(self.labels) # 返回数据集大小def __getitem__(self, idx):return self.texts[idx], self.labels[idx] # 返回指定索引的数据train_dataset = TextDataset(x_train_padded, y_train) # 创建训练数据集
test_dataset = TextDataset(x_test_padded, y_test) # 创建测试数据集train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 创建训练数据加载器
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) # 创建测试数据加载器2)模型设计
实现一个简单的循环神经网络, 第一层是 embedding 层, 词嵌入的大小是 100; 第二层是循环层, 循环层的输入尺寸是 100, 神经元数量是 256; 第三层是全连接层也就是输出层, 输入尺寸是 256, 输出是 1, 因为这是一个二分类问题, 所以输出尺寸是 1 即可。
class SimpleRNN(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):super(SimpleRNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim) # 词嵌入层self.rnn = nn.RNN(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, text):embedded = self.embedding(text)output, hidden = self.rnn(embedded)out = self.fc(output[:, -1, :])return out3)训练配置
设置损失函数和优化器。
model = SimpleRNN(max_features + 1, 100, 256, 1) # 创建模型实例
# 编译模型
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
optimizer = optim.Adam(model.parameters()) # 使用 SGD/Adam 优化器4)训练过程
训练并保存模型
# 训练模型
def train(model, train_loader, optimizer, criterion, epochs):for epoch in range(epochs): # 训练一个周期model.train() # 设置模型为训练for texts, labels in train_loader: # 遍历训练数据optimizer.zero_grad() # 清零梯度outputs = model.forward(texts) # 前向传播loss = criterion(outputs.squeeze(), labels.float()) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 训练并测试模型
train(model, train_loader, optimizer, criterion, epochs=1)
# 模型保存并测试
torch.save(model.state_dict(), 'rnn_state_dict.pth')5)测试模型
评估模型性能
# 测试模型
def predict(model, test_loader):model.eval() # 设置模型为评估模式correct = 0total = 0with torch.no_grad(): # 不计算梯度for texts, labels in test_loader: # 遍历测试数据outputs = model.forward(texts) # 前向传播predicted = (outputs.squeeze() > 0.5).int() # 预测标签total += labels.size(0) # 总样本数correct += (predicted == labels).sum().item() # 正确预测数print(f'测试准确率: {correct / total}')# 模型评估
model = SimpleRNN(max_features + 1, 100, 256, 1)
model.load_state_dict(torch.load('rnn_state_dict.pth'))
predict(model, test_loader)
相关文章:
循环神经网络(RNN)+pytorch实现情感分析
目录 一、背景引入 二、网络介绍 2.1 输入层 2.2 循环层 2.3 输出层 2.4 举例 2.5 深层网络 三、网络的训练 3.1 训练过程举例 1)输出层 2)循环层 3.2 BPTT 算法 1)输出层 2)循环层 3)算法流程 四、循…...
Mac cursor设置jdk、Maven版本
基本配置 – Cursor 使用文档 首先是系统用户级别的设置参数,运行cursor,按下ctrlshiftp,输入Open User Settings(JSON),在弹出的下拉菜单中选中下面这样的: 在打开的json编辑器中追加下面的内容: {"…...
WPS数据分析000005
目录 一、数据录入技巧 二、一维表 三、填充柄 向下自动填充 自动填充选项 日期填充 星期自定义 自定义序列 1-10000序列 四、智能填充 五、数据有效性 出错警告 输入信息 下拉列表 六、记录单 七、导入数据 编辑 八、查找录入 会员功能 Xlookup函数 VL…...

CTF从入门到精通
文章目录 背景知识CTF赛制 背景知识 CTF赛制 1.web安全:通过浏览器访问题目服务器上的网站,寻找网站漏洞(sql注入,xss(钓鱼链接),文件上传,包含漏洞,xxe,ssrf,命令执行,…...
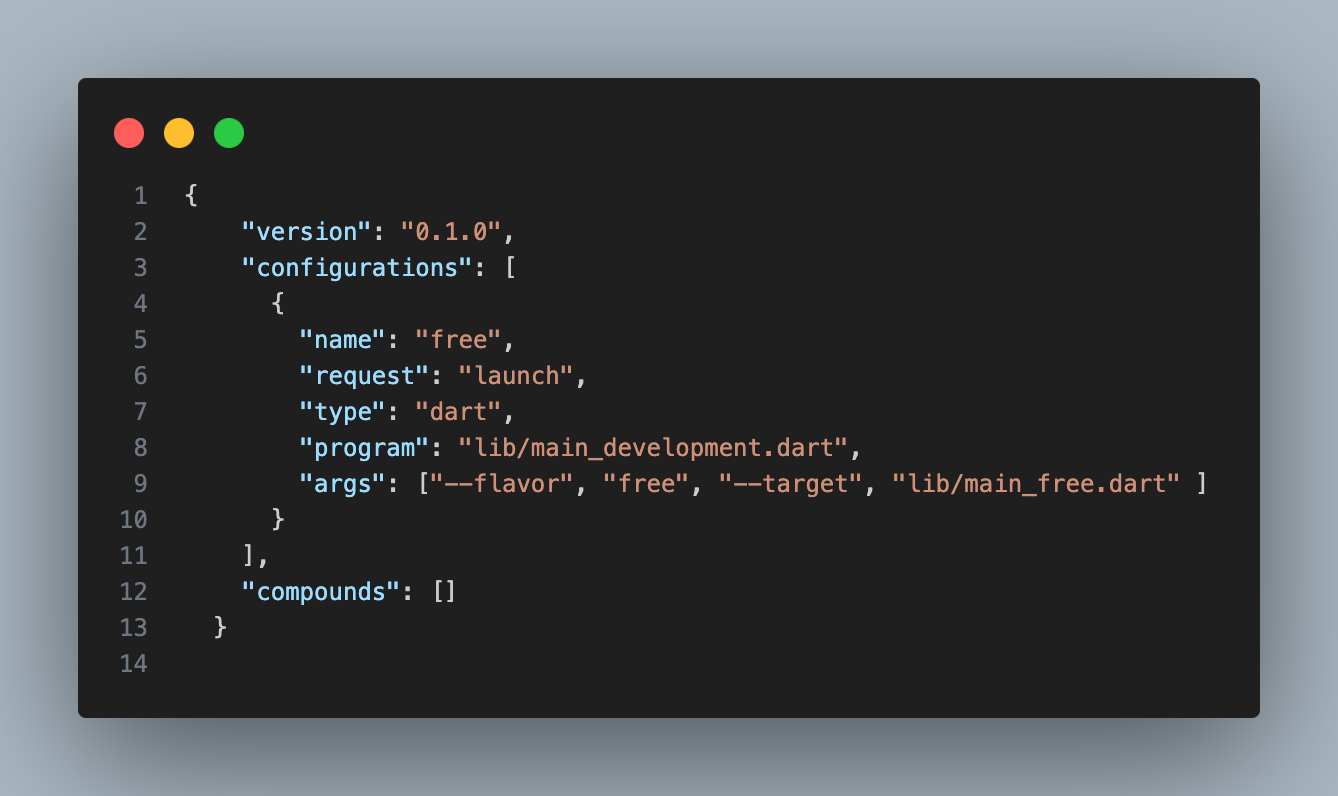
Flutter使用Flavor实现切换环境和多渠道打包
在Android开发中通常我们使用flavor进行多渠道打包,flutter开发中同样有这种方式,不过需要在原生中配置 具体方案其实flutter官网个了相关示例(https://docs.flutter.dev/deployment/flavors),我这里记录一下自己的操作 Android …...

Springboot如何使用面向切面编程AOP?
Springboot如何使用面向切面编程AOP? 在 Spring Boot 中使用面向切面编程(AOP)非常简单,Spring Boot 提供了对 AOP 的自动配置支持。以下是详细的步骤和示例,帮助你快速上手 Spring Boot 中的 AOP。 1. 添加依赖 首先ÿ…...

51单片机(STC89C52)开发:点亮一个小灯
软件安装: 安装开发板CH340驱动。 安装KEILC51开发软件:C51V901.exe。 下载软件:PZ-ISP.exe 创建项目: 新建main.c 将main.c加入至项目中: main.c:点亮一个小灯 #include "reg52.h"sbit LED1P2^0; //P2的…...
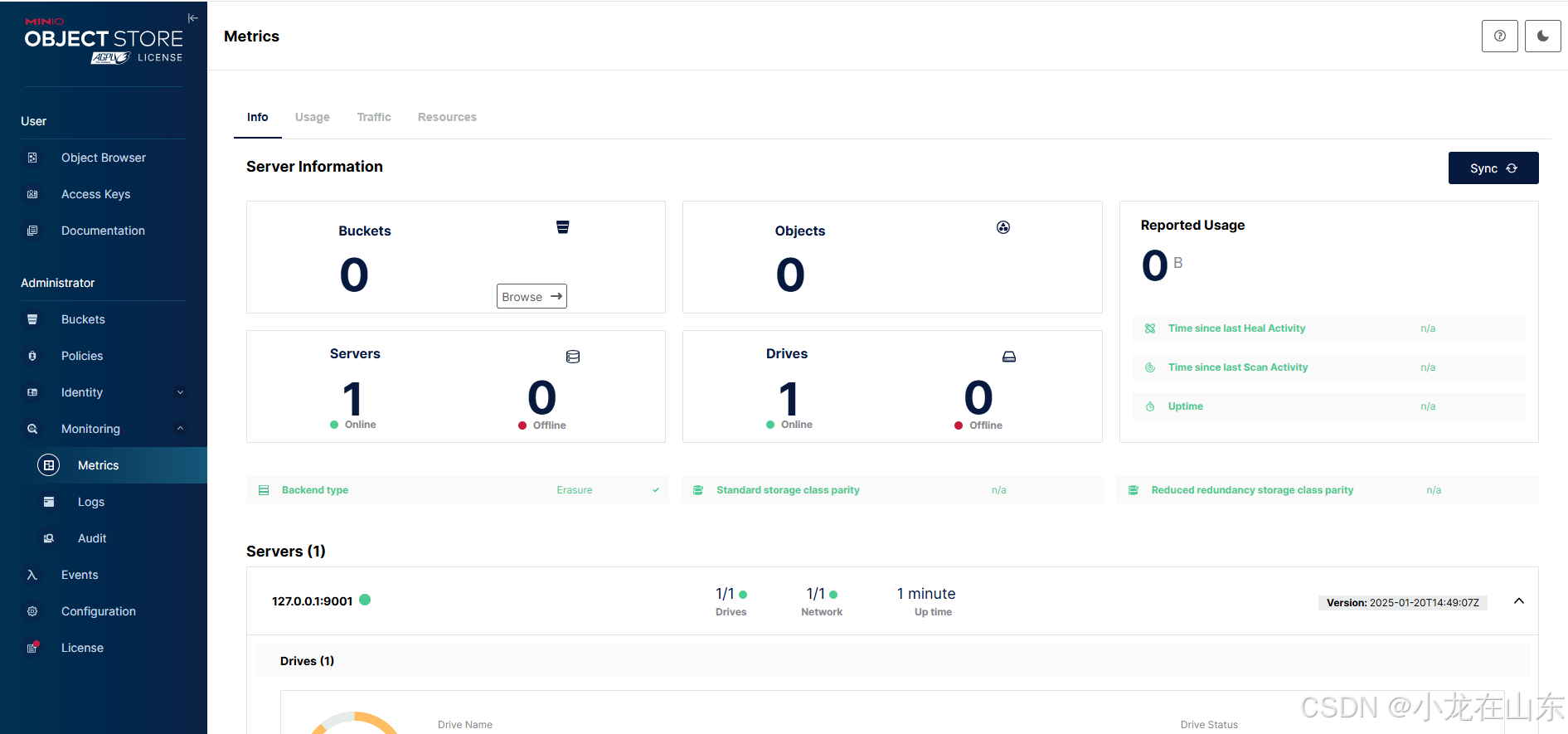
基于MinIO的对象存储增删改查
MinIO是一个高性能的分布式对象存储服务。Python的minio库可操作MinIO,包括创建/列出存储桶、上传/下载/删除文件及列出文件。 查看帮助信息 minio.exe --help minio.exe server --help …...
Ubuntu Server 安装 XFCE4桌面
Ubuntu Server没有桌面环境,一些软件有桌面环境使用起来才更加方便,所以我尝试安装桌面环境。常用的桌面环境有:GNOME、KDE Plasma、XFCE4等。这里我选择安装XFCE4桌面环境,主要因为它是一个极轻量级的桌面环境,适合内…...

MySQL 存储函数:数据库的自定义函数
在数据库开发中,存储函数(Stored Function)是一种非常有用的工具。它允许我们创建自定义的函数,这些函数可以在 SQL 查询中像内置函数一样使用,用于实现特定的逻辑和计算。本文将深入探讨 MySQL 存储函数的概念、与存储…...
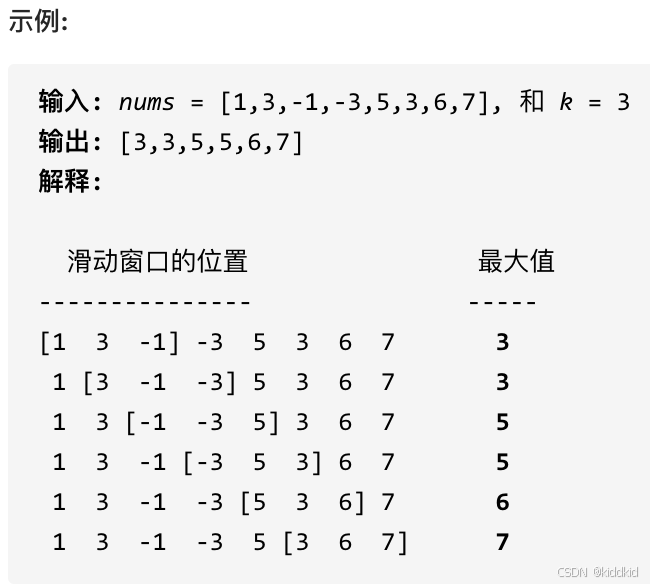
代码随想录_栈与队列
栈与队列 232.用栈实现队列 232. 用栈实现队列 使用栈实现队列的下列操作: push(x) – 将一个元素放入队列的尾部。 pop() – 从队列首部移除元素。 peek() – 返回队列首部的元素。 empty() – 返回队列是否为空。 思路: 定义两个栈: 入队栈, 出队栈, 控制出入…...

【微服务与分布式实践】探索 Sentinel
参数设置 熔断时长 、最小请求数、最大RT ms、比例阈值、异常数 熔断策略 慢调⽤⽐例 当单位统计时⻓内请求数⽬⼤于设置的最⼩请求数⽬,并且慢调⽤的⽐例⼤于阈值,则接下来的熔断时⻓内请求会⾃动被熔断 异常⽐例 当单位统计时⻓内请求数⽬⼤于设置…...
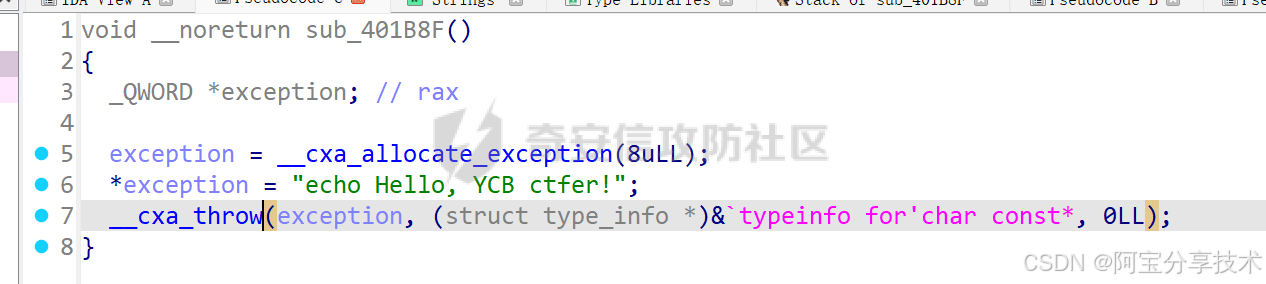
深入研究异常处理机制
一、原理探究 C异常处理 本节内容针对 Linux 下的 C 异常处理机制,重点在于研究如何在异常处理流程中利用溢出漏洞,所以不对异常处理及 unwind 的过程做详细分析,只做简单介绍 异常机制中主要的三个关键字:throw 抛出异常&#x…...

【memgpt】letta 课程4:基于latta框架构建MemGpt代理并与之交互
Lab 3: Building Agents with memory 基于latta框架构建MemGpt代理并与之交互理解代理状态,例如作为系统提示符、工具和agent的内存查看和编辑代理存档内存MemGPT 代理是有状态的 agents的设计思路 每个步骤都要定义代理行为 Letta agents persist information over time and…...

讯飞智作 AI 配音技术浅析(二):深度学习与神经网络
讯飞智作 AI 配音技术依赖于深度学习与神经网络,特别是 Tacotron、WaveNet 和 Transformer-TTS 模型。这些模型通过复杂的神经网络架构和数学公式,实现了从文本到自然语音的高效转换。 一、Tacotron 模型 Tacotron 是一种端到端的语音合成模型ÿ…...
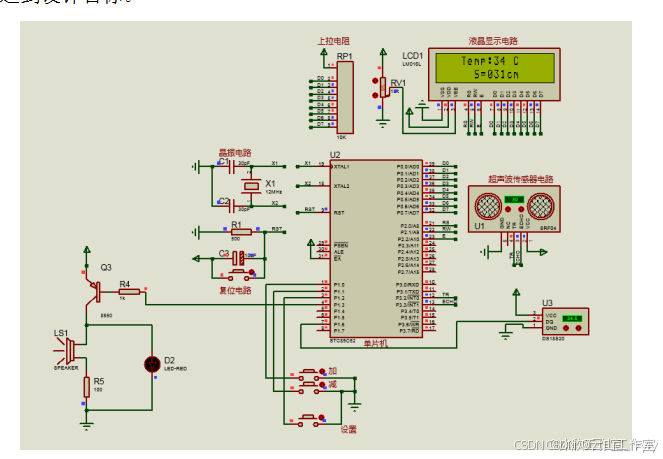
基于单片机的超声波液位检测系统(论文+源码)
1总体设计 本课题为基于单片机的超声波液位检测系统的设计,系统的结构框图如图2.1所示。其中包括了按键模块,温度检测模块,超声波液位检测模块,显示模块,蜂鸣器等器件设备。其中,采用STC89C52单片机作为主控…...

Autogen_core: test_code_executor.py
目录 代码代码解释 代码 import textwrapimport pytest from autogen_core.code_executor import (Alias,FunctionWithRequirements,FunctionWithRequirementsStr,ImportFromModule, ) from autogen_core.code_executor._func_with_reqs import build_python_functions_file f…...

从0开始使用面对对象C语言搭建一个基于OLED的图形显示框架
目录 前言 环境介绍 代码与动机 架构设计,优缺点 博客系列指引 前言 笔者前段时间花费了一周,整理了一下自从TM1637开始打算的,使用OLED来搭建一个通用的显示库的一个工程。笔者的OLED库已经开源到Github上了,地址在…...
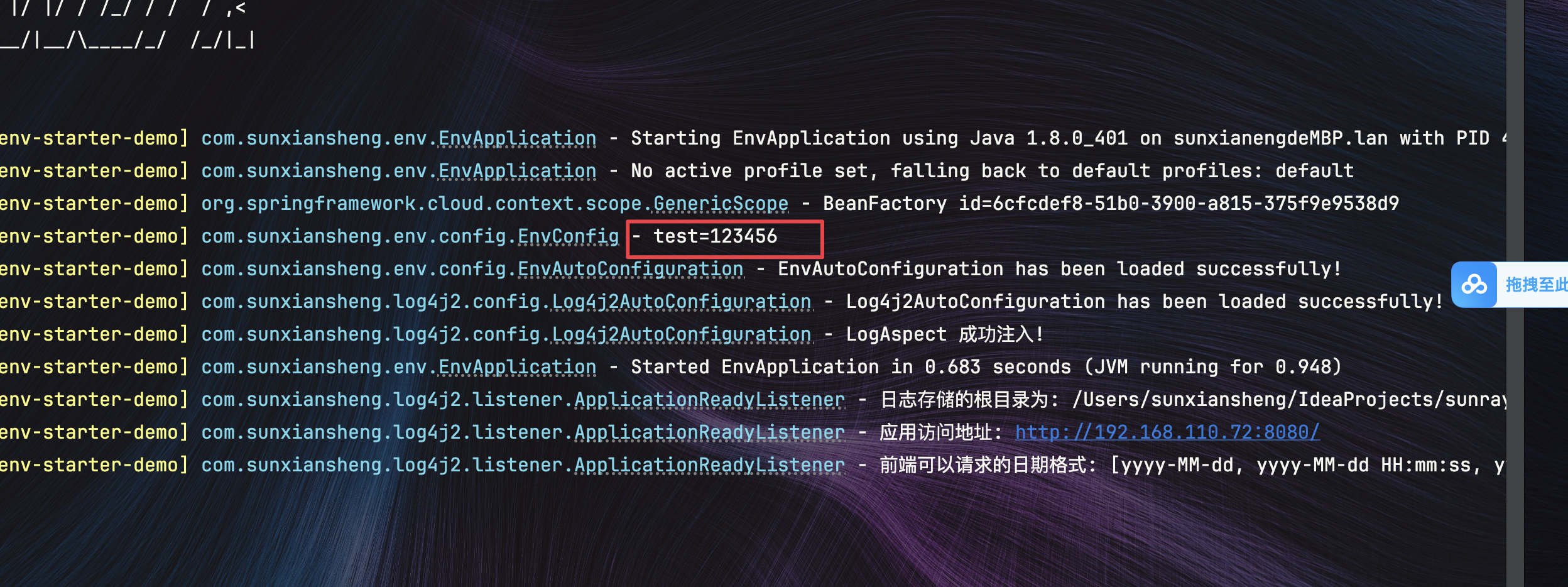
Java实现.env文件读取敏感数据
文章目录 1.common-env-starter模块1.目录结构2.DotenvEnvironmentPostProcessor.java 在${xxx}解析之前执行,提前读取配置3.EnvProperties.java 这里的path只是为了代码提示4.EnvAutoConfiguration.java Env模块自动配置类5.spring.factories 自动配置和注册Enviro…...

Go反射指南
概念: 官方对此有个非常简明的介绍,两句话耐人寻味: 反射提供一种让程序检查自身结构的能力反射是困惑的源泉 第1条,再精确点的描述是“反射是一种检查interface变量的底层类型和值的机制”。 第2条,很有喜感的自嘲…...

FastAPI API版本控制:URI前缀的终极实现指南
FastAPI API版本控制:URI前缀的终极实现指南 【免费下载链接】fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 项目地址: https://gitcode.com/GitHub_Trending/fa/fastapi FastAPI是一个高性能、易于学习…...

Intel Broadwell处理器选型指南:IBRS、noTSX这些后缀到底该怎么选?
Intel Broadwell处理器选型实战:从安全特性到性能优化的深度解析 在2014年问世的Intel Broadwell架构,作为第五代酷睿处理器的重要里程碑,至今仍在特定应用场景中保持着独特的价值。不同于简单的参数对比,本文将带您深入理解不同…...

倩女幽魂易语言源码|支持编译运行,适合易语言开发者学习研究
温馨提示:文末有联系方式【标一】可编译倩女幽魂易语言源码开放 本套源码基于易语言开发,已完成基础环境配置与编译测试,生成的程序可正常启动并执行核心逻辑。 适用于熟悉易语言语法、掌握API调用与内存读写技术的开发者。【标二】仅面向具备…...

新手零踩坑!微信搜一搜排名优化8大干货,14天轻松冲进前10
很多新手运营者都有一个共同的困惑:明明做了公众号、小程序,也发了不少内容,可在微信搜一搜里搜相关关键词,却始终找不到自己的账号和内容,排名一直徘徊在百名之外,精准流量根本引不进来,更别提…...
结合:多模态理解新思路)
vLLM-v0.17.1与卷积神经网络(CNN)结合:多模态理解新思路
vLLM-v0.17.1与卷积神经网络(CNN)结合:多模态理解新思路 1. 多模态AI的行业痛点与解决方案 计算机视觉和自然语言处理长期作为AI两大独立分支发展,但在实际业务场景中,图像与文本的协同理解需求日益凸显。传统方案通…...

工业自动化场景信捷 PLC EtherNet/IP 转 TCP/IP 通信方案
EtherNet/IP转TCP/IP网关应用:信捷PLC工业自动化数据采集实战案例一、项目背景本次项目落地于国内某大型3C电子精密组装工厂,聚焦智能手机中框自动化组装产线,属于当前工业自动化领域高增速、高前景的主流场景,也是工业物联网落地…...

AIGlasses_for_navigation商业应用:社区养老中心盲道安全监测解决方案
AIGlasses_for_navigation商业应用:社区养老中心盲道安全监测解决方案 1. 项目背景与价值 社区养老中心作为老年人日常活动的重要场所,无障碍设施的安全性直接关系到老年人的出行安全。传统的盲道巡检主要依靠人工目视检查,存在效率低、覆盖…...

UnrealPakViewer实战指南:解决Pak文件解析难题的5个创新方法
UnrealPakViewer实战指南:解决Pak文件解析难题的5个创新方法 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer 当你面对10GB加密Pak包&…...
)
FPGA开发实战——常见错误排查与优化技巧(持续更新)
1. Vivado仿真与PR Flow冲突问题实战解析 第一次用Vivado做PR(Partial Reconfiguration)项目时,我兴冲冲地点开仿真按钮,结果弹出一个让人崩溃的报错:"ERROR [Common 17-69] Command failed. Simulation for PR F…...

如何通过开源看板工具Kanboard实现团队高效协作
如何通过开源看板工具Kanboard实现团队高效协作 【免费下载链接】kanboard Kanban project management software 项目地址: https://gitcode.com/gh_mirrors/ka/kanboard 在当今快节奏的工作环境中,团队协作效率是项目成功的关键因素。Kanboard作为一款免费开…...