C++并发编程指南08
以下是经过优化排版后的5.3节内容,详细解释了C++中的同步操作和强制排序机制。每个部分都有详细的注释和结构化展示。
文章目录
- 5.3 同步操作和强制排序
- 假设场景
- 示例代码
- 5.3.1 同步发生 (Synchronizes-with)
- 基本思想
- 5.3.2 先行发生 (Happens-before)
- 单线程环境
- 多线程环境
- 5.3.3 内存顺序 (Memory Order)
- 总结
- 5.3.3 原子操作的内存序
- 顺序一致性 (Sequentially Consistent)
- 示例代码
- 性能影响
- 自由序 (Relaxed Ordering)
- 示例代码
- 获取-释放序 (Acquire-Release Ordering)
- 示例代码
- 性能优势
- 非限制操作示例
- 示例代码
- 结果分析
- 总结
- 5.3.3 原子操作的内存序
- 获取-释放序操作会影响释放操作
- 示例代码
- 结果分析
- 获取-释放序传递同步
- 示例代码
- 结果分析
- 合并同步变量
- 示例代码
- memory_order_consume 数据相关性
- 示例代码
- 结果分析
- 总结
- 5.3.4 释放队列与同步
- 示例代码:使用原子操作从队列中读取数据
- 结果分析
- 5.3.5 栅栏(Fences)
- 示例代码:栅栏可以让自由操作变得有序
- 结果分析
- 5.3.6 原子操作对非原子操作的排序
- 示例代码:使用非原子操作执行序列
- 结果分析
- 5.3.7 非原子操作排序
- 示例代码:非原子操作排序
- 结果分析
- 同步工具总结
- `std::thread`
- `std::mutex`, `std::timed_mutex`, `std::recursive_mutex`, `std::recursibe_timed_mutex`
- `std::shared_mutex`, `std::shared_timed_mutex`
- `std::promise`, `std::future`, `std::shared_future`
- `std::async`, `std::future`, `std::shared_future`
- `std::experimental::latch`, `std::experimental::barrier`, `std::experimental::flex_barrier`
- `std::condition_variable`, `std::condition_variable_any`
5.3 同步操作和强制排序
在多线程环境中,确保数据的一致性和正确性至关重要。通过使用原子操作和适当的内存顺序,可以实现线程间的同步和强制排序。
假设场景
假设我们有两个线程:一个用于写入数据(writer_thread),另一个用于读取数据(reader_thread)。为了避免竞争条件,写入线程需要设置一个标志来表明数据已经准备好,以便读取线程可以在标志设置后安全地访问数据。

示例代码
#include <vector>
#include <atomic>
#include <iostream>
#include <thread>
#include <chrono>std::vector<int> data;
std::atomic<bool> data_ready(false);void reader_thread() {while (!data_ready.load()) { // 1: 等待数据准备就绪std::this_thread::sleep_for(std::chrono::milliseconds(1));}std::cout << "The answer=" << data[0] << "\n"; // 2: 读取数据
}void writer_thread() {data.push_back(42); // 3: 写入数据data_ready.store(true); // 4: 标记数据已准备就绪
}
在这个例子中:
- 等待循环 (
while (!data_ready.load())) 确保读取线程不会在数据未准备好时访问数据。 - 读取操作 (
data[0]) 在data_ready标志被设置为true后进行。 - 写入操作 (
data.push_back(42)) 和 标记操作 (data_ready.store(true)) 确保数据在读取前已经准备好。
尽管每一个数据项都是原子的,但非原子读写操作可能破坏访问顺序,导致未定义行为。为了确保正确的顺序,我们需要理解“先行”和“同步发生”的概念。
5.3.1 同步发生 (Synchronizes-with)
“同步发生”是指两个原子操作之间的关系,其中一个操作必须先于另一个操作完成。这种关系仅存在于原子类型之间。
基本思想
- 原子写操作 W 对变量
x进行标记,并与对x的原子读操作同步。 - 读操作要么读到 W 操作写入的内容,要么读到 W 之后同一线程上的原子写操作写入的值,亦或是任意线程对
x的一系列原子读-改-写操作(如fetch_add()或compare_exchange_weak())。
例如:
std::atomic<int> x(0);
std::atomic<bool> flag(false);// 线程 A
x.store(42, std::memory_order_relaxed);
flag.store(true, std::memory_order_release);// 线程 B
while (!flag.load(std::memory_order_acquire)) {std::this_thread::yield();
}
int value = x.load(std::memory_order_relaxed);
在这个例子中:
- 线程 A 中的
x.store(42)和flag.store(true)是原子写操作。 - 线程 B 中的
flag.load()和x.load()是原子读操作。 - 当
flag被设置为true时,线程 A 的写操作与线程 B 的读操作同步发生。
5.3.2 先行发生 (Happens-before)
“先行发生”是指程序中操作顺序的基本构建块。它规定了某个操作如何影响另一个操作。
单线程环境
在一个单线程环境中,如果操作 A 发生在操作 B 之前,那么 A 就先行于 B。例如:
int get_num() {static int i = 0;return ++i;
}void foo(int a, int b) {std::cout << a << "," << b << std::endl;
}int main() {foo(get_num(), get_num()); // 无序调用 get_num()
}
在这个例子中,get_num() 的调用顺序未指定,输出可能是“1,2”或“2,1”。
多线程环境
在多线程环境中,“先行发生”关系依赖于同步关系:
- 如果操作 A 在一个线程上,并且该线程先行于另一个线程上的操作 B,那么 A 就先行于 B。
- 如果操作 A 与另一个线程上的操作 B 同步,那么 A 就线程间先行于 B。
传递关系:如果 A 先行于 B,并且 B 先行于 C,那么 A 就先行于 C。
示例代码:
std::atomic<bool> ready(false);void thread_a() {data.push_back(42); // 写入数据ready.store(true, std::memory_order_release); // 设置标志
}void thread_b() {while (!ready.load(std::memory_order_acquire)) { // 等待标志std::this_thread::yield();}std::cout << "The answer=" << data[0] << "\n"; // 读取数据
}
在这个例子中:
thread_a中的写操作先行于ready.store(true)。ready.load()先行于thread_b中的读操作。- 因此,写操作先行于读操作。
5.3.3 内存顺序 (Memory Order)





内存顺序决定了原子操作的行为以及它们与其他操作的关系。常见的内存顺序包括:
- memory_order_relaxed: 不保证任何顺序。
- memory_order_consume: 依赖于当前线程的操作结果。
- memory_order_acquire: 确保后续操作不会被重排序到当前操作之前。
- memory_order_release: 确保之前的操作不会被重排序到当前操作之后。
- memory_order_acq_rel: 结合 acquire 和 release 语义。
- memory_order_seq_cst: 提供全局顺序一致性。
示例代码:
std::atomic<int> x(0);
std::atomic<int> y(0);// 线程 A
x.store(1, std::memory_order_relaxed);
y.store(1, std::memory_order_release);// 线程 B
while (y.load(std::memory_order_acquire) == 0) {std::this_thread::yield();
}
int value = x.load(std::memory_order_relaxed);
在这个例子中:
y.store(1, std::memory_order_release)确保之前的x.store(1)不会被重排序到其后。y.load(std::memory_order_acquire)确保后续的x.load()不会读取到旧值。
总结
通过理解和应用“同步发生”和“先行发生”关系,我们可以确保多线程程序中的数据一致性和正确性。合理选择内存顺序也是至关重要的,它可以帮助我们控制操作的顺序并避免潜在的竞争条件。
这些规则是编写高效、安全的多线程程序的基础,能够帮助我们在复杂的并发环境中管理数据共享和同步。希望这些解释和示例能帮助你更好地理解和应用这些概念。
以下是经过优化排版后的5.3.3节内容,详细解释了C++中的原子操作内存序。每个部分都有详细的注释和结构化展示。
5.3.3 原子操作的内存序
在多线程编程中,内存序(Memory Order)决定了原子操作的行为及其与其他操作的关系。C++提供了六种不同的内存序选项:
- memory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_seq_cst
除非为特定的操作指定一个序列选项,默认内存序是 memory_order_seq_cst(顺序一致性)。尽管有六个选项,但它们代表三种主要的内存模型:顺序一致性、获取-释放序和自由序。
顺序一致性 (Sequentially Consistent)
默认内存序 memory_order_seq_cst 是最简单且最容易理解的内存序。它确保所有线程看到的操作顺序是一致的。
示例代码
#include <atomic>
#include <thread>
#include <cassert>std::atomic<bool> x(false), y(false);
std::atomic<int> z(0);void write_x() {x.store(true, std::memory_order_seq_cst); // 1: 写入x
}void write_y() {y.store(true, std::memory_order_seq_cst); // 2: 写入y
}void read_x_then_y() {while (!x.load(std::memory_order_seq_cst)); // 等待x变为trueif (y.load(std::memory_order_seq_cst)) { // 3: 检查y是否为true++z;}
}void read_y_then_x() {while (!y.load(std::memory_order_seq_cst)); // 等待y变为trueif (x.load(std::memory_order_seq_cst)) { // 4: 检查x是否为true++z;}
}int main() {x = false;y = false;z = 0;std::thread a(write_x);std::thread b(write_y);std::thread c(read_x_then_y);std::thread d(read_y_then_x);a.join();b.join();c.join();d.join();assert(z.load() != 0); // 断言z不为0
}
在这个例子中:
write_x和write_y分别设置x和y为true。read_x_then_y和read_y_then_x分别等待x和y变为true,然后检查另一个变量并增加z的值。
由于使用了 memory_order_seq_cst,所有的操作都保持全局一致的顺序,因此断言不会触发。
性能影响
虽然顺序一致性是最直观的内存序,但在多核系统上会带来较大的性能开销,因为它需要在多个处理器之间进行同步操作。
自由序 (Relaxed Ordering)
memory_order_relaxed 提供最小的同步保证,适用于不需要严格顺序的应用场景。
示例代码
#include <atomic>
#include <thread>
#include <cassert>std::atomic<bool> x(false), y(false);
std::atomic<int> z(0);void write_x_then_y() {x.store(true, std::memory_order_relaxed); // 1: 写入xy.store(true, std::memory_order_relaxed); // 2: 写入y
}void read_y_then_x() {while (!y.load(std::memory_order_relaxed)); // 3: 等待y变为trueif (x.load(std::memory_order_relaxed)) { // 4: 检查x是否为true++z;}
}int main() {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 断言可能会触发
}
在这个例子中:
write_x_then_y先写入x,然后写入y,但没有顺序保证。read_y_then_x等待y变为true,然后检查x是否为true并增加z的值。
由于使用了 memory_order_relaxed,读取操作可能看不到最新的写入值,因此断言可能会触发。
获取-释放序 (Acquire-Release Ordering)
获取-释放序提供了比自由序更强的同步保证,但不像顺序一致性那样严格。
示例代码
#include <atomic>
#include <thread>
#include <cassert>std::atomic<bool> x(false), y(false);
std::atomic<int> z(0);void write_x() {x.store(true, std::memory_order_release); // 1: 写入x
}void write_y() {y.store(true, std::memory_order_release); // 2: 写入y
}void read_x_then_y() {while (!x.load(std::memory_order_acquire)); // 等待x变为trueif (y.load(std::memory_order_acquire)) { // 3: 检查y是否为true++z;}
}void read_y_then_x() {while (!y.load(std::memory_order_acquire)); // 等待y变为trueif (x.load(std::memory_order_acquire)) { // 4: 检查x是否为true++z;}
}int main() {x = false;y = false;z = 0;std::thread a(write_x);std::thread b(write_y);std::thread c(read_x_then_y);std::thread d(read_y_then_x);a.join();b.join();c.join();d.join();assert(z.load() != 0); // 断言可能会触发
}
在这个例子中:
write_x和write_y使用memory_order_release标记写入操作。read_x_then_y和read_y_then_x使用memory_order_acquire进行读取操作。
获取-释放序确保了一个线程的释放操作与另一个线程的获取操作同步,从而提供了一定程度的顺序保证,但仍不如顺序一致性那么严格。
性能优势
获取-释放序通常比顺序一致性更高效,因为它只需要在相关线程之间进行同步,而不是全局同步。
非限制操作示例
为了更好地理解非限制操作,考虑以下多线程示例:
示例代码
#include <thread>
#include <atomic>
#include <iostream>std::atomic<int> x(0), y(0), z(0); // 1: 全局原子变量
std::atomic<bool> go(false); // 2: 同步信号unsigned const loop_count = 10;struct read_values {int x, y, z;
};read_values values1[loop_count], values2[loop_count], values3[loop_count], values4[loop_count], values5[loop_count];void increment(std::atomic<int>* var_to_inc, read_values* values) {while (!go) std::this_thread::yield(); // 3: 等待信号for (unsigned i = 0; i < loop_count; ++i) {values[i].x = x.load(std::memory_order_relaxed);values[i].y = y.load(std::memory_order_relaxed);values[i].z = z.load(std::memory_order_relaxed);var_to_inc->store(i + 1, std::memory_order_relaxed); // 4: 更新变量std::this_thread::yield();}
}void read_vals(read_values* values) {while (!go) std::this_thread::yield(); // 5: 等待信号for (unsigned i = 0; i < loop_count; ++i) {values[i].x = x.load(std::memory_order_relaxed);values[i].y = y.load(std::memory_order_relaxed);values[i].z = z.load(std::memory_order_relaxed);std::this_thread::yield();}
}void print(read_values* v) {for (unsigned i = 0; i < loop_count; ++i) {if (i) std::cout << ",";std::cout << "(" << v[i].x << "," << v[i].y << "," << v[i].z << ")";}std::cout << std::endl;
}int main() {x = 0;y = 0;z = 0;go = false;std::thread t1(increment, &x, values1);std::thread t2(increment, &y, values2);std::thread t3(increment, &z, values3);std::thread t4(read_vals, values4);std::thread t5(read_vals, values5);go = true; // 6: 开始执行主循环的信号t5.join();t4.join();t3.join();t2.join();t1.join();print(values1); // 7: 打印最终结果print(values2);print(values3);print(values4);print(values5);
}
在这个例子中:
- 三个全局原子变量
x,y,z和一个同步信号go。 - 每个线程循环10次,使用
memory_order_relaxed读取三个原子变量的值,并存储在一个数组中。 - 三个线程每次通过循环更新其中一个原子变量,剩下的两个线程负责读取。
输出示例:
(0,0,0),(1,0,0),(2,0,0),(3,0,0),(4,0,0),(5,7,0),(6,7,8),(7,9,8),(8,9,8),(9,9,10)
(0,0,0),(0,1,0),(0,2,0),(1,3,5),(8,4,5),(8,5,5),(8,6,6),(8,7,9),(10,8,9),(10,9,10)
(0,0,0),(0,0,1),(0,0,2),(0,0,3),(0,0,4),(0,0,5),(0,0,6),(0,0,7),(0,0,8),(0,0,9)
(1,3,0),(2,3,0),(2,4,1),(3,6,4),(3,9,5),(5,10,6),(5,10,8),(5,10,10),(9,10,10),(10,10,10)
(0,0,0),(0,0,0),(0,0,0),(6,3,7),(6,5,7),(7,7,7),(7,8,7),(8,8,7),(8,8,9),(8,8,9)
结果分析
- 第一组值中
x增加1,第二组值中y增加1,第三组中z增加1。 x元素只在给定集中增加,y和z也一样,但不是均匀增加,并且每个线程中的相对顺序不同。- 线程3看不到
x或y的任何更新,但它能看到z的更新。
总结
通过理解和应用不同的内存序选项,可以在多线程编程中实现高效的同步和强制排序。每种内存序都有其适用场景:
- 顺序一致性 (
memory_order_seq_cst):最简单且直观,但性能开销较大。 - 自由序 (
memory_order_relaxed):性能最佳,但缺乏严格的顺序保证。 - 获取-释放序 (
memory_order_acquire和memory_order_release):提供了较强的同步保证,同时保持较高的性能。
选择合适的内存序可以帮助你在保证程序正确性的同时,最大化性能。希望这些解释和示例能帮助你更好地理解和应用这些概念。
以下是经过优化排版后的5.3.3节内容,详细解释了C++中的原子操作内存序,特别是获取-释放序的操作及其传递同步特性。每个部分都有详细的注释和结构化展示。
5.3.3 原子操作的内存序
在多线程编程中,内存序(Memory Order)决定了原子操作的行为及其与其他操作的关系。C++提供了六种不同的内存序选项:
- memory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_seq_cst
除非为特定的操作指定一个序列选项,默认内存序是 memory_order_seq_cst(顺序一致性)。尽管有六个选项,但它们代表三种主要的内存模型:顺序一致性、获取-释放序和自由序。
获取-释放序操作会影响释放操作
示例代码
#include <atomic>
#include <thread>
#include <cassert>std::atomic<bool> x(false), y(false);
std::atomic<int> z(0);void write_x_then_y() {x.store(true, std::memory_order_relaxed); // 1: 写入xy.store(true, std::memory_order_release); // 2: 写入y
}void read_y_then_x() {while (!y.load(std::memory_order_acquire)); // 3: 等待y变为trueif (x.load(std::memory_order_relaxed)) { // 4: 检查x是否为true++z;}
}int main() {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 断言不会触发
}
在这个例子中:
write_x_then_y先写入x,然后写入y。read_y_then_x等待y变为true,然后检查x是否为true并增加z的值。
由于使用了 memory_order_release 和 memory_order_acquire,读取操作会看到最新的写入值,因此断言不会触发。
结果分析
- 存储
x使用的是memory_order_relaxed,没有顺序保证。 - 存储
y使用的是memory_order_release,确保后续的加载操作能看到这个值。 - 加载
y使用的是memory_order_acquire,确保能看到之前的所有释放操作。
因此,存储 x 的操作先行于存储 y 的操作,并且扩展到对 x 的读取操作,使得 z 最终不为零。
获取-释放序传递同步
为了考虑传递顺序,至少需要三个线程。第一个线程用来修改共享变量,第二个线程使用“加载-获取”读取由“存储-释放”操作过的变量,并且再对第二个变量进行“存储-释放”操作。最后,由第三个线程通过“加载-获取”读取第二个共享变量,并提供“加载-获取”操作来读取被“存储-释放”操作写入的值。
示例代码
#include <atomic>
#include <thread>
#include <cassert>std::atomic<int> data[5];
std::atomic<bool> sync1(false), sync2(false);void thread_1() {data[0].store(42, std::memory_order_relaxed);data[1].store(97, std::memory_order_relaxed);data[2].store(17, std::memory_order_relaxed);data[3].store(-141, std::memory_order_relaxed);data[4].store(2003, std::memory_order_relaxed);sync1.store(true, std::memory_order_release); // 1. 设置sync1
}void thread_2() {while (!sync1.load(std::memory_order_acquire)); // 2. 直到sync1设置后,循环结束sync2.store(true, std::memory_order_release); // 3. 设置sync2
}void thread_3() {while (!sync2.load(std::memory_order_acquire)); // 4. 直到sync2设置后,循环结束assert(data[0].load(std::memory_order_relaxed) == 42);assert(data[1].load(std::memory_order_relaxed) == 97);assert(data[2].load(std::memory_order_relaxed) == 17);assert(data[3].load(std::memory_order_relaxed) == -141);assert(data[4].load(std::memory_order_relaxed) == 2003);
}int main() {std::thread t1(thread_1);std::thread t2(thread_2);std::thread t3(thread_3);t1.join();t2.join();t3.join();
}
在这个例子中:
thread_1将数据存储到data中,并设置sync1。thread_2等待sync1被设置后,设置sync2。thread_3等待sync2被设置后,读取data中的数据并进行断言。
由于 thread_2 只接触到 sync1 和 sync2,对于 thread_1 和 thread_3 的同步就足够了,这能保证断言不会触发。
结果分析
thread_1将数据存储到data中先行于存储sync1。- 对
sync1的加载最终会看到thread_1存储的值。 thread_3的加载操作位于存储sync2操作的前面。- 存储
sync2因此先行于thread_3的加载,从而保证断言都不会触发。
合并同步变量
可以将 sync1 和 sync2 通过在 thread_2 中使用“读-改-写”操作 (memory_order_acq_rel) 合并成一个独立的变量。其中会使用 compare_exchange_strong() 来保证 thread_1 对变量只进行一次更新。
示例代码
#include <atomic>
#include <thread>
#include <cassert>std::atomic<int> data[5];
std::atomic<int> sync(0);void thread_1() {data[0].store(42, std::memory_order_relaxed);data[1].store(97, std::memory_order_relaxed);data[2].store(17, std::memory_order_relaxed);data[3].store(-141, std::memory_order_relaxed);data[4].store(2003, std::memory_order_relaxed);sync.store(1, std::memory_order_release);
}void thread_2() {int expected = 1;while (!sync.compare_exchange_strong(expected, 2,std::memory_order_acq_rel))expected = 1;
}void thread_3() {while (sync.load(std::memory_order_acquire) < 2);assert(data[0].load(std::memory_order_relaxed) == 42);assert(data[1].load(std::memory_order_relaxed) == 97);assert(data[2].load(std::memory_order_relaxed) == 17);assert(data[3].load(std::memory_order_relaxed) == -141);assert(data[4].load(std::memory_order_relaxed) == 2003);
}int main() {std::thread t1(thread_1);std::thread t2(thread_2);std::thread t3(thread_3);t1.join();t2.join();t3.join();
}
在这个例子中:
thread_1将数据存储到data中并设置sync为1。thread_2使用compare_exchange_strong将sync从1更新为2。thread_3等待sync大于等于2后,读取data中的数据并进行断言。
使用 memory_order_acq_rel 的“读-改-写”操作,选择语义非常重要。例子中,想要同时进行获取和释放的语义,所以 memory_order_acq_rel 是一个不错的选择。
memory_order_consume 数据相关性
memory_order_consume 是一种特殊的内存序,完全依赖于数据,并展示了与线程间先行关系的不同之处。尽管它在C++17中不推荐使用,但仍有必要了解其概念。
示例代码
#include <atomic>
#include <thread>
#include <cassert>
#include <string>struct X {int i;std::string s;
};std::atomic<X*> p;
std::atomic<int> a;void create_x() {X* x = new X;x->i = 42;x->s = "hello";a.store(99, std::memory_order_relaxed); // 1p.store(x, std::memory_order_release); // 2
}void use_x() {X* x;while (!(x = p.load(std::memory_order_consume))) // 3std::this_thread::sleep_for(std::chrono::microseconds(1));assert(x->i == 42); // 4assert(x->s == "hello"); // 5assert(a.load(std::memory_order_relaxed) == 99); // 6
}int main() {std::thread t1(create_x);std::thread t2(use_x);t1.join();t2.join();
}
在这个例子中:
create_x创建一个X结构体实例,并将其指针存储在p中。use_x等待p被设置为非空值,然后访问X结构体的成员。
由于 memory_order_consume 的使用,X 结构体中的数据成员所在的断言语句不会被触发。然而,加载 a 的断言不能确定是否触发,因为这个操作标记为 memory_order_relaxed,并不依赖于 p 的加载操作。
结果分析
- 存储
a在存储p之前,并且存储p的操作标记为memory_order_release。 - 加载
p的操作标记为memory_order_consume,因此存储p仅先行那些需要加载p的操作。 - 对
x变量操作的表达式对加载p的操作携带有依赖,所以X结构体中数据成员所在的断言语句不会被触发。
总结
通过理解和应用不同的内存序选项,可以在多线程编程中实现高效的同步和强制排序。每种内存序都有其适用场景:
- 顺序一致性 (
memory_order_seq_cst):最简单且直观,但性能开销较大。 - 自由序 (
memory_order_relaxed):性能最佳,但缺乏严格的顺序保证。 - 获取-释放序 (
memory_order_acquire和memory_order_release):提供了较强的同步保证,同时保持较高的性能。 - memory_order_consume:依赖于数据的相关性,但在实际应用中不推荐使用。
选择合适的内存序可以帮助你在保证程序正确性的同时,最大化性能。希望这些解释和示例能帮助你更好地理解和应用这些概念。
以下是经过优化排版后的5.3.4至5.3.7节内容,详细解释了C++中的释放队列、栅栏操作及其对非原子操作的排序。每个部分都有详细的注释和结构化展示。
5.3.4 释放队列与同步
在多线程编程中,释放队列(Release Sequence)是确保不同线程之间正确同步的重要机制。通过使用适当的内存序标记,可以保证存储和加载操作之间的同步关系。
示例代码:使用原子操作从队列中读取数据
#include <atomic>
#include <thread>
#include <vector>std::vector<int> queue_data;
std::atomic<int> count;void populate_queue() {unsigned const number_of_items = 20;queue_data.clear();for (unsigned i = 0; i < number_of_items; ++i) {queue_data.push_back(i);}count.store(number_of_items, std::memory_order_release); // 1 初始化存储
}void consume_queue_items() {while (true) {int item_index;if ((item_index = count.fetch_sub(1, std::memory_order_acquire)) <= 0) { // 2 “读-改-写”操作wait_for_more_items(); // 3 等待更多元素continue;}process(queue_data[item_index - 1]); // 4 安全读取queue_data}
}int main() {std::thread a(populate_queue);std::thread b(consume_queue_items);std::thread c(consume_queue_items);a.join();b.join();c.join();
}
结果分析
populate_queue函数初始化共享队列并设置计数器。consume_queue_items函数从队列中获取元素,并处理它们。- 使用
memory_order_release和memory_order_acquire确保存储和加载操作之间的同步。
当只有一个消费者线程时,一切正常。如果有两个消费者线程,第二个线程会看到第一个线程修改的值,从而避免条件竞争。
5.3.5 栅栏(Fences)
栅栏操作是对内存序列进行约束的全局操作,限制编译器或硬件对指令的重新排序。栅栏操作可以确保特定的操作顺序。
示例代码:栅栏可以让自由操作变得有序
#include <atomic>
#include <thread>
#include <assert.h>std::atomic<bool> x(false), y(false);
std::atomic<int> z(0);void write_x_then_y() {x.store(true, std::memory_order_relaxed); // 1std::atomic_thread_fence(std::memory_order_release); // 2y.store(true, std::memory_order_relaxed); // 3
}void read_y_then_x() {while (!y.load(std::memory_order_relaxed)); // 4std::atomic_thread_fence(std::memory_order_acquire); // 5if (x.load(std::memory_order_relaxed)) // 6++z;
}int main() {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 7
}
结果分析
write_x_then_y函数使用释放栅栏确保x和y的存储顺序。read_y_then_x函数使用获取栅栏确保y和x的加载顺序。- 栅栏操作确保了存储和加载操作之间的同步关系,避免了条件竞争。
如果将存储和加载操作标记为 memory_order_relaxed,则需要栅栏来强制执行顺序。
5.3.6 原子操作对非原子操作的排序
即使使用非原子变量,也可以通过栅栏操作确保操作的顺序性。
示例代码:使用非原子操作执行序列
#include <atomic>
#include <thread>
#include <assert.h>bool x = false; // x现在是一个非原子变量
std::atomic<bool> y(false);
std::atomic<int> z(0);void write_x_then_y() {x = true; // 1 在栅栏前存储xstd::atomic_thread_fence(std::memory_order_release);y.store(true, std::memory_order_relaxed); // 2 在栅栏后存储y
}void read_y_then_x() {while (!y.load(std::memory_order_relaxed)); // 3 在#2写入前,持续等待std::atomic_thread_fence(std::memory_order_acquire);if (x) // 4 这里读取到的值,是#1中写入++z;
}int main() {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 5 断言将不会触发
}
结果分析
write_x_then_y函数使用释放栅栏确保x和y的存储顺序。read_y_then_x函数使用获取栅栏确保y和x的加载顺序。- 尽管
x是一个非原子变量,但栅栏操作仍然确保了操作的顺序性。
5.3.7 非原子操作排序
通过使用栅栏操作,可以对非原子操作进行排序,确保其顺序性和同步性。
示例代码:非原子操作排序
#include <atomic>
#include <thread>
#include <cassert>bool x = false; // 非原子变量
std::atomic<bool> y(false);
std::atomic<int> z(0);void write_x_then_y() {x = true; // 1 在栅栏前存储xstd::atomic_thread_fence(std::memory_order_release);y.store(true, std::memory_order_relaxed); // 2 在栅栏后存储y
}void read_y_then_x() {while (!y.load(std::memory_order_relaxed)); // 3 在#2写入前,持续等待std::atomic_thread_fence(std::memory_order_acquire);if (x) // 4 这里读取到的值,是#1中写入++z;
}int main() {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 5 断言将不会触发
}
结果分析
write_x_then_y函数使用释放栅栏确保x和y的存储顺序。read_y_then_x函数使用获取栅栏确保y和x的加载顺序。- 即使
x是一个非原子变量,栅栏操作仍然确保了操作的顺序性和同步性。
同步工具总结
以下是一些常用的同步工具及其作用:
std::thread
- 构造函数与调用函数或新线程的可调用对象间的同步。
- 对
std::thread对象调用join可以和对应的线程进行同步。
std::mutex, std::timed_mutex, std::recursive_mutex, std::recursibe_timed_mutex
- 对给定互斥量对象调用
lock和unlock,以及对try_lock、try_lock_for或try_lock_until,会形成该互斥量的锁序。 - 对给定的互斥量调用
unlock,需要在调用lock或成功调用try_lock、try_lock_for或try_lock_until之后,这样才符合互斥量的锁序。
std::shared_mutex, std::shared_timed_mutex
- 对给定互斥量对象调用
lock、unlock、lock_shared和unlock_shared,以及对try_lock、try_lock_for、try_lock_until、try_lock_shared、try_lock_shared_for或try_lock_shared_until的成功调用,会形成该互斥量的锁序。
std::promise, std::future, std::shared_future
- 成功调用
std::promise对象的set_value或set_exception与成功的调用wait或get之间同步。 - 成功调用
std::packaged_task对象的函数操作符与成功的调用wait或get之间同步。
std::async, std::future, std::shared_future
- 使用
std::launch::async策略性的通过std::async启动线程执行任务与成功的调用wait和get之间是同步的。 - 使用
std::launch::deferred策略性的通过std::async启动任务与成功的调用wait和get之间是同步的。
std::experimental::latch, std::experimental::barrier, std::experimental::flex_barrier
- 对
std::experimental::latch实例调用count_down或count_down_and_wait与在该对象上成功的调用wait或count_down_and_wait之间是同步的。 - 对
std::experimental::barrier实例调用arrive_and_wait或arrive_and_drop与在该对象上随后成功完成的arrive_and_wait之间是同步的。
std::condition_variable, std::condition_variable_any
- 条件变量不提供任何同步关系,所有同步都由互斥量提供。
这些同步工具提供了丰富的功能,帮助开发者在多线程环境中实现正确的同步和顺序控制。希望这些解释和示例能帮助你更好地理解和应用这些概念。
相关文章:
C++并发编程指南08
以下是经过优化排版后的5.3节内容,详细解释了C中的同步操作和强制排序机制。每个部分都有详细的注释和结构化展示。 文章目录 5.3 同步操作和强制排序假设场景示例代码 5.3.1 同步发生 (Synchronizes-with)基本思想 5.3.2 先行发生 (Happens-before)单线程环境多线程…...
Spring Boot - 数据库集成03 - 集成Mybatis
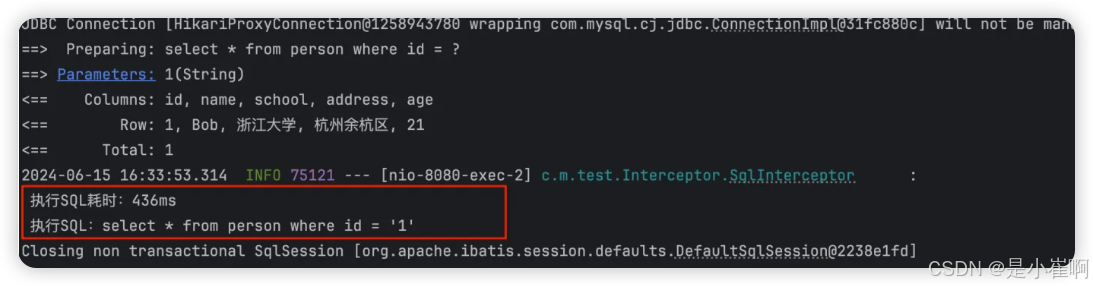
Spring boot集成Mybatis 文章目录 Spring boot集成Mybatis一:基础知识1:什么是MyBatis2:为什么说MyBatis是半自动ORM3:MyBatis栈技术演进3.1:JDBC,自行封装JDBCUtil3.2:IBatis3.3:My…...

python:洛伦兹变换
洛伦兹变换(Lorentz transformations)是相对论中的一个重要概念,特别是在讨论时空的变换时非常重要。在四维时空的背景下,洛伦兹变换描述了在不同惯性参考系之间如何变换时间和空间坐标。在狭义相对论中,洛伦兹变换通常…...

“星门计划对AI未来的意义——以及谁将掌控它”
“星门计划对AI未来的意义——以及谁将掌控它” 图片由DALL-E 3生成 就在几天前,唐纳德特朗普宣布了“星门计划”,OpenAI随即跟进,分享了更多细节。他们明确表示,计划在未来四年内投资5000亿美元,在美国为OpenAI构建一…...

为什么“记住密码”适合持久化?
✅ 特性 1:应用重启后仍需生效 记住密码的本质是长期存储用户的登录凭证(如用户名、密码、JWT Token),即使用户关闭应用、重启设备,仍然可以自动登录。持久化存储方案: React Native 推荐使用 AsyncStorag…...

国产SiC碳化硅功率器件技术成为服务器电源升级的核心引擎
在服务器电源应用中,国产650V碳化硅(SiC)MOSFET逐步取代传统超结(Super Junction, SJ)MOSFET,其核心驱动力源于SiC材料在效率、功率密度、可靠性和长期经济性上的显著优势,叠加产业链成熟与政策…...
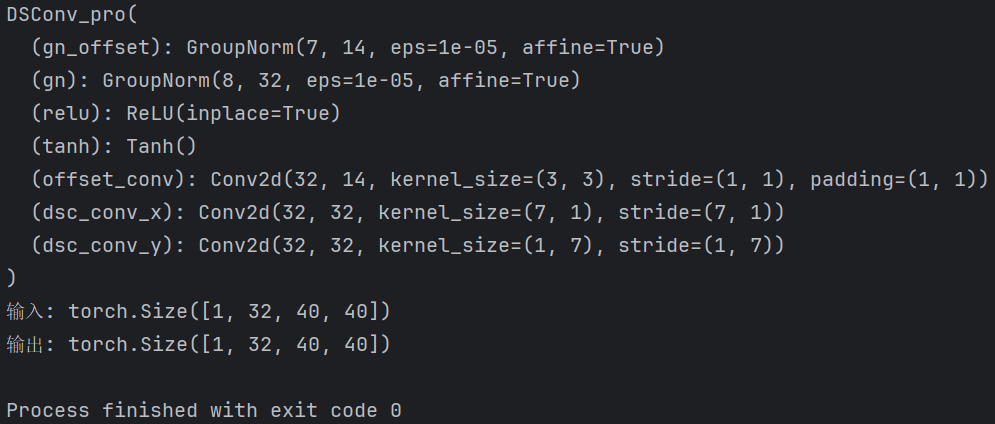
【Block总结】动态蛇形卷积,专注于细长和弯曲的局部结构|即插即用
论文信息 标题: Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation 作者: 戚耀磊、何宇霆、戚晓明、张媛、杨冠羽 会议: 2023 IEEE/CVF International Conference on Computer Vision (ICCV) 发表时间: 2023年10月…...

Spring MVC 框架:构建高效 Java Web 应用的利器
Java学习资料 Java学习资料 Java学习资料 一、引言 在 Java Web 开发领域,Spring MVC 框架是一颗耀眼的明星。它作为 Spring 框架家族的重要成员,为开发者提供了一套强大而灵活的解决方案,用于构建 Web 应用程序。Spring MVC 遵循模型 - 视…...
新鲜速递:DeepSeek-R1开源大模型本地部署实战—Ollama + MaxKB 搭建RAG检索增强生成应用
在AI技术快速发展的今天,开源大模型的本地化部署正在成为开发者们的热门实践方向。最火的莫过于吊打OpenAI过亿成本的纯国产DeepSeek开源大模型,就在刚刚,凭一己之力让英伟达大跌18%,纳斯达克大跌3.7%,足足是给中国AI产…...
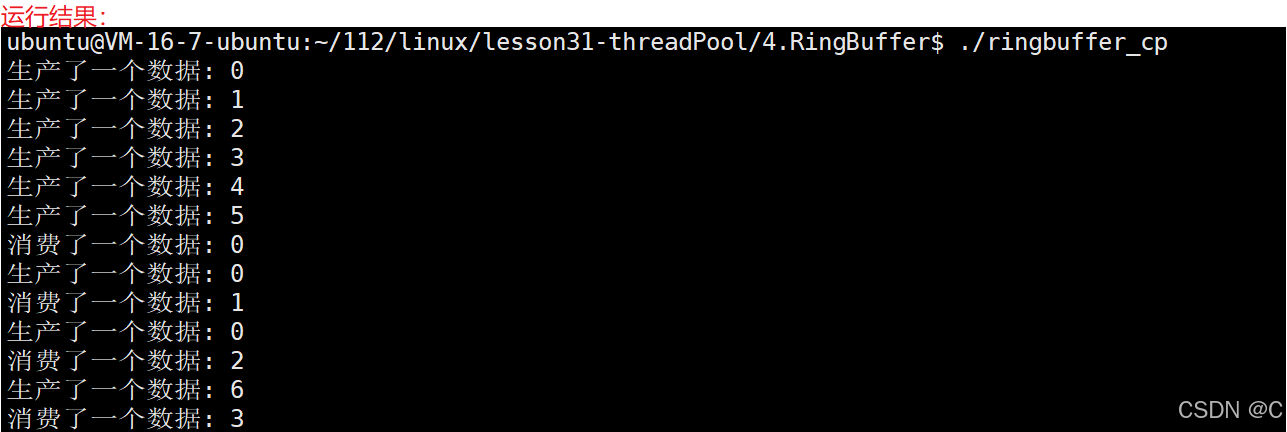
Linux_线程同步生产者消费者模型
同步的相关概念 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。 同步的…...
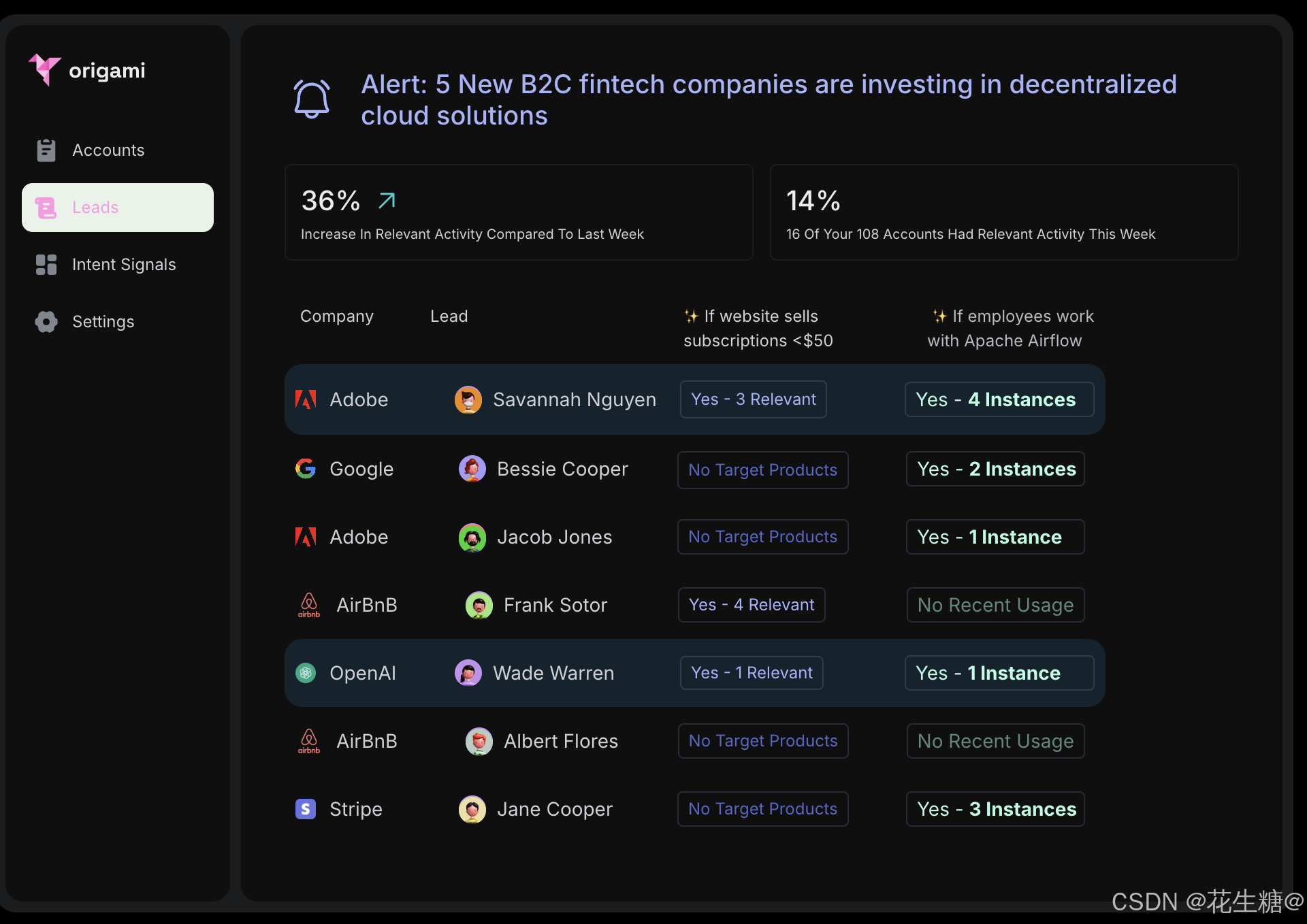
Origami Agents:通过AI驱动的研究工具提升B2B销售效率
在当今竞争激烈的商业环境中,B2B销售团队面临着巨大的挑战,如何高效地发现潜在客户并进行精准的外展活动成为关键。Origami Agents通过其创新的AI驱动研究工具,正在彻底改变这一过程。本文将深入探讨Origami Agents的产品特性、技术架构以及其快速增长背后的成功因素。 一、…...

linux的/proc 和 /sys目录差异
/proc 和 /sys 都是Linux系统中用于提供系统信息和进行系统配置的虚拟文件系统,但它们的原理并不完全一样,以下是具体分析: 目的与功能 /proc :主要用于提供系统进程相关信息以及内核运行时的一些参数等,可让用户和程…...

AIGC时代的Vue或React前端开发
在AIGC(人工智能生成内容)时代,Vue开发正经历着深刻的变革。以下是对AIGC时代Vue开发的详细分析: 一、AIGC技术对Vue开发的影响 代码生成与自动化 AIGC技术使得开发者能够借助智能工具快速生成和优化Vue代码。例如,通…...

代码随想录算法训练营第三十九天-动态规划-337. 打家劫舍 III
老师讲这是树形dp的入门题目解题思路是以二叉树的遍历(递归三部曲)再结合动规五部曲dp数组如何定义:只需要定义一个二个元素的数组,dp[0]与dp[1] dp[0]表示不偷当前节点的最大价值dp[1]表示偷当前节点后的最大价值这样可以把每个节…...
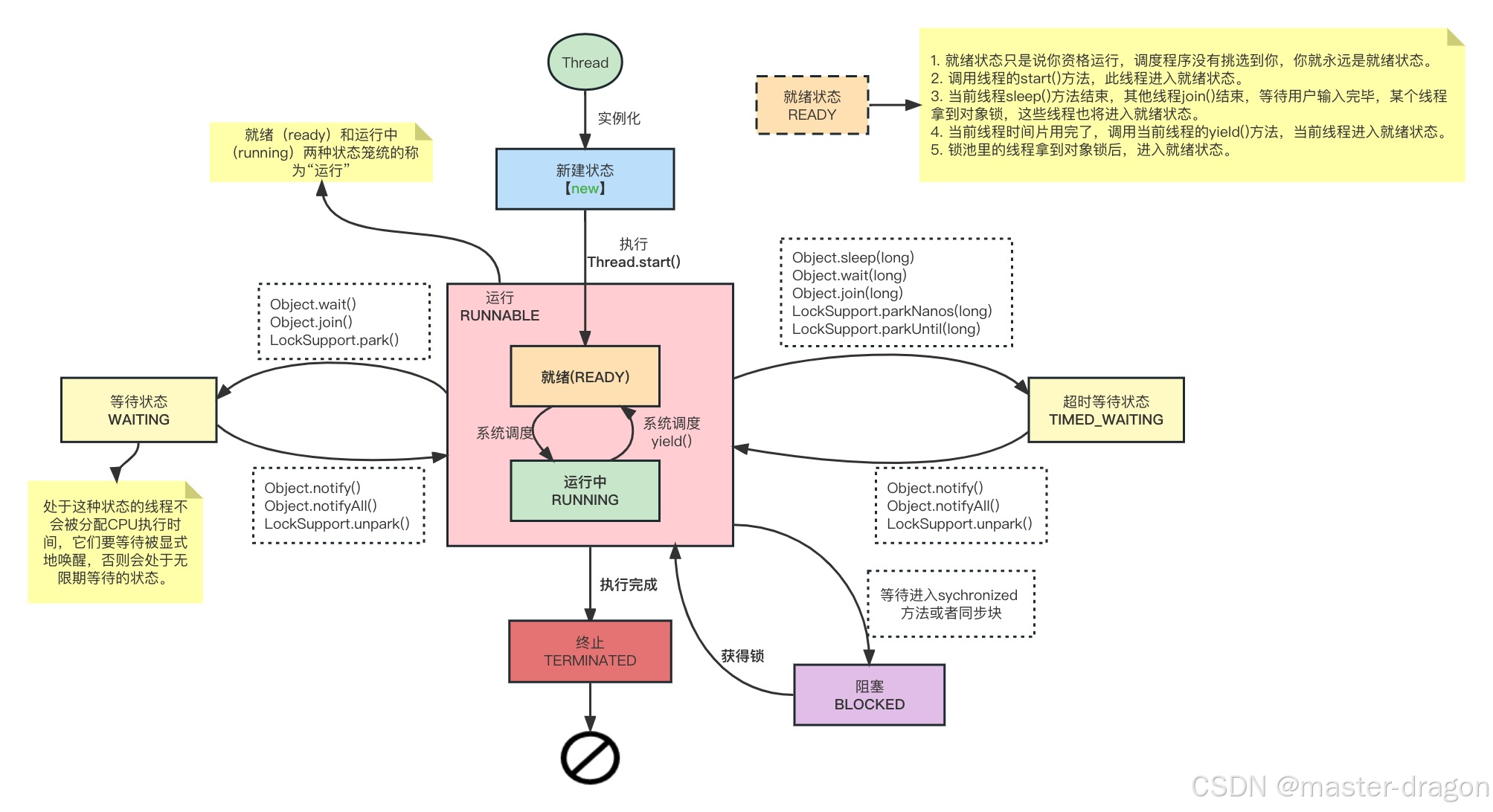
Java线程认识和Object的一些方法
专栏系列文章地址:https://blog.csdn.net/qq_26437925/article/details/145290162 本文目标: 要对Java线程有整体了解,深入认识到里面的一些方法和Object对象方法的区别。认识到Java对象的ObjectMonitor,这有助于后面的Synchron…...
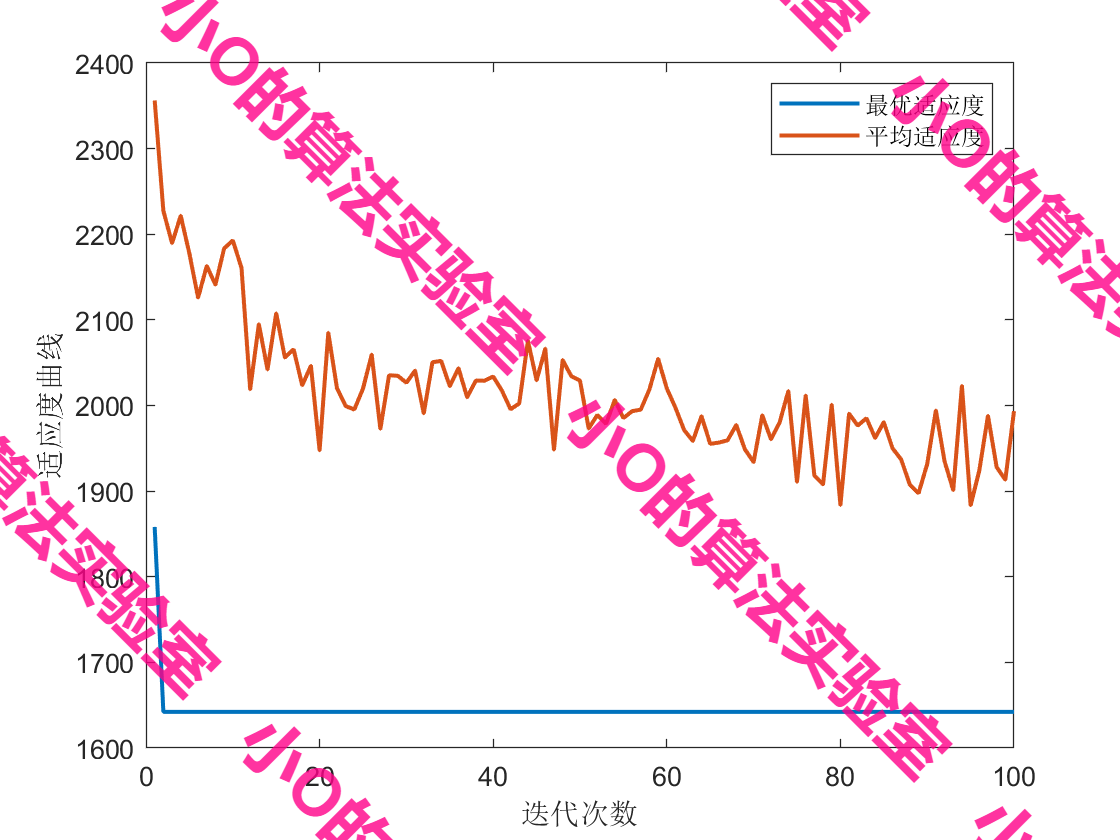
【算法应用】基于A*-蚁群算法求解无人机城市多任务点配送路径问题
目录 1.A星算法原理2.蚁群算法原理3.结果展示4.代码获取 1.A星算法原理 A*算法是一种基于图搜索的智能启发式算法,它具有高稳定性和高节点搜索效率。主要原理为:以起点作为初始节点,将其加入开放列表。从开放列表中选择具有最小总代价值 f (…...

电梯系统的UML文档14
对于 HallButtonControl,我们有二个状态: "门厅灯开 " 和 " 门厅灯关"。 从给出的初始信息,初始的状态应该是"门厅灯关"。行为定义: " 当 HallCall[f,d]是真,则指令 HallLight[f&…...
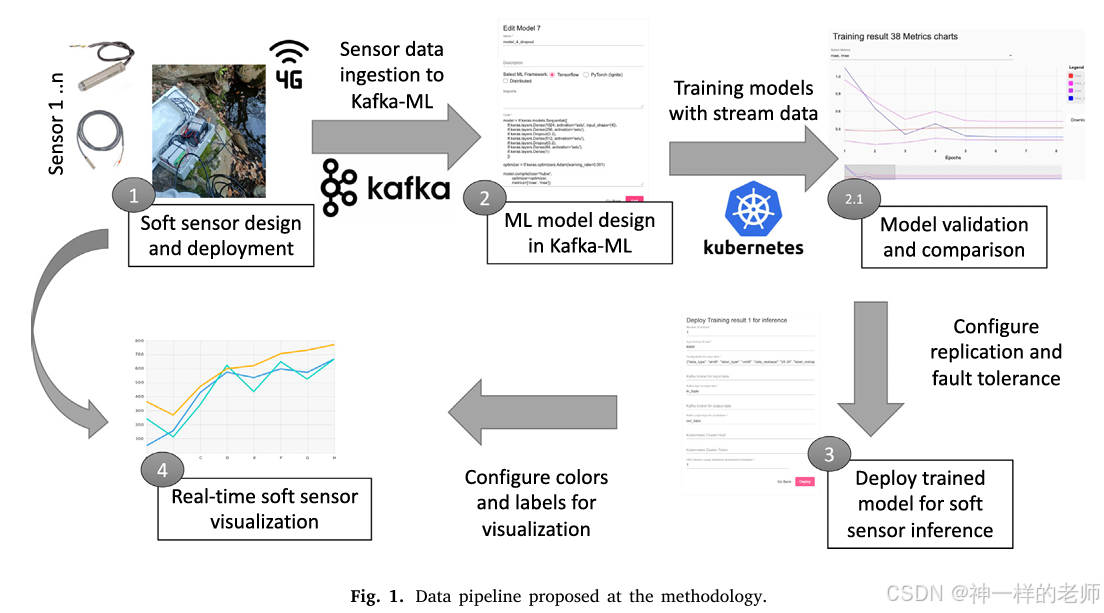
一种用于低成本水质监测的软传感器开源方法:以硝酸盐(NO3⁻)浓度为例
论文标题 A Soft Sensor Open-Source Methodology for Inexpensive Monitoring of Water Quality: A Case Study of NO3− Concentrations 作者信息 Antonio Jess Chaves, ITIS Software, University of Mlaga, 29071 Mlaga, Spain Cristian Martn, ITIS Software, Universi…...

[250130] VirtualBox 7.1.6 维护版本发布 | Anthropic API 推出全新引用功能
目录 VirtualBox 7.1.6 维护版本发布⚙️ 功能改进🛠️ Bug 修复 Anthropic API 推出全新引用功能,让 Claude 的回答更可信 VirtualBox 7.1.6 维护版本发布 VirtualBox 7.1.6 现已发布,这是一个维护版本,主要修复了一些错误并进行…...

JVM_类的加载、链接、初始化、卸载、主动使用、被动使用
①. 说说类加载分几步? ①. 按照Java虚拟机规范,从class文件到加载到内存中的类,到类卸载出内存为止,它的整个生命周期包括如下7个阶段: 第一过程的加载(loading)也称为装载验证、准备、解析3个部分统称为链接(Linking)在Java中数据类型分为基本数据类型和引用数据…...

Graphormer部署教程:/etc/supervisor/conf.d/graphormer.conf配置解析
Graphormer部署教程:/etc/supervisor/conf.d/graphormer.conf配置解析 1. 项目介绍 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等…...
中的技术路径拆解、时间节点校验与政策匹配度评分)
GLM-4-9B-Chat-1M惊艳效果:碳中和白皮书(120页)中的技术路径拆解、时间节点校验与政策匹配度评分
GLM-4-9B-Chat-1M惊艳效果:碳中和白皮书(120页)中的技术路径拆解、时间节点校验与政策匹配度评分 1. 项目背景与核心能力 今天要给大家展示一个让人眼前一亮的技术应用场景——用GLM-4-9B-Chat-1M这个本地部署的大模型,来深度分…...

Arduino_ConnectionHandler库:嵌入式网络连接状态管理与自适应重连
1. Arduino_ConnectionHandler 库深度解析:嵌入式网络连接管理的工程实践指南1.1 库定位与核心价值Arduino_ConnectionHandler是 Arduino 官方生态中面向物联网终端设备的网络连接抽象管理层,其设计目标并非替代底层通信协议栈(如 WiFiClient…...

【AI知识点】交叉注意力机制:连接不同世界的“信息桥梁”
1. 从"信息桥梁"理解交叉注意力机制 想象你正在同时阅读一本英文书和它的中文翻译版。当你遇到一个不太理解的英文句子时,会自然地在中文版本中寻找对应的段落来帮助理解——这个过程就像交叉注意力机制在神经网络中的工作方式。它就像是架设在两个不同世…...

usearch的内存泄漏自动化测试:在CI中集成泄漏检测
usearch的内存泄漏自动化测试:在CI中集成泄漏检测 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolf…...

AI应用架构师讲解AI在金融市场应用案例的模型构建
AI应用架构师讲解:AI在金融市场应用案例的模型构建 一、引入与连接:当AI成为金融市场的“智能分析师” 2023年,某头部量化基金的AI策略实现了35%的年化收益率,远超市场平均水平;同年,某国有银行用AI风险模型…...

从 Seata 1.x 升级到 2.0.0:Docker 环境下的平滑迁移与配置变更指南
从 Seata 1.x 升级到 2.0.0:Docker 环境下的平滑迁移与配置变更指南 分布式事务框架 Seata 2.0.0 版本带来了多项架构优化与功能增强,包括对 Raft 共识算法的原生支持、安全模块的全面升级以及配置管理机制的改进。对于已在生产环境部署 Seata 1.x 版本的…...

聊聊 Comsol 仿真方形锂离子电池那些事儿
comsol仿真 锂离子电池 电化学 仿真 comsol 方形锂离子电池的三维模型:三维模型有助于准确的评估电芯中的集流体和极耳等对电流、电位以及产热分布的影响。 模型基于三维 Newman 模型,其中包括了在颗粒尺度描述锂粒子插层和扩散的额外维度。 此外&#…...

Hi3559平台ISP调试实战:从参数配置到画质优化
1. Hi3559平台ISP基础概念与工作原理 第一次接触Hi3559平台的ISP模块时,我完全被各种专业术语搞晕了。后来在调试车载摄像头项目时才发现,理解ISP的工作原理对画质优化有多重要。简单来说,ISP就像是我们手机里的美颜功能,只不过它…...

Qwen3.5-2B图文理解评测:在TextVQA、ChartQA等基准测试中的轻量级SOTA表现
Qwen3.5-2B图文理解评测:在TextVQA、ChartQA等基准测试中的轻量级SOTA表现 1. 模型概览 Qwen3.5-2B是Qwen3.5系列中的轻量化多模态基础模型,仅有20亿参数规模,却展现出超越参数量的强大图文理解能力。该模型专为低功耗、低门槛部署场景设计…...