Flink (十二) :Table API SQL (一) 概览
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。无论输入是连续的(流式)还是有界的(批处理),在两个接口中指定的查询都具有相同的语义,并指定相同的结果。
Table API 和 SQL 两种 API 是紧密集成的,以及 DataStream API。你可以在这些 API 之间,以及一些基于这些 API 的库之间轻松的切换。例如,您可以使用 MATCH_RECOGNIZE 子句从表中检测模式,然后使用 DataStream API 基于匹配的模式构建警报。
1. Table API 和 SQL 程序的结构
所有用于批处理和流处理的 Table API 和 SQL 程序都遵循相同的模式。下面的代码示例展示了 Table API 和 SQL 程序的通用结构。
import org.apache.flink.table.api.*;
import org.apache.flink.connector.datagen.table.DataGenConnectorOptions;// Create a TableEnvironment for batch or streaming execution.
// See the "Create a TableEnvironment" section for details.
TableEnvironment tableEnv = TableEnvironment.create(/*…*/);// Create a source table
tableEnv.createTemporaryTable("SourceTable", TableDescriptor.forConnector("datagen").schema(Schema.newBuilder().column("f0", DataTypes.STRING()).build()).option(DataGenConnectorOptions.ROWS_PER_SECOND, 100L).build());// Create a sink table (using SQL DDL)
tableEnv.executeSql("CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE SourceTable (EXCLUDING OPTIONS) ");// Create a Table object from a Table API query
Table table1 = tableEnv.from("SourceTable");// Create a Table object from a SQL query
Table table2 = tableEnv.sqlQuery("SELECT * FROM SourceTable");// Emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = table1.insertInto("SinkTable").execute();2. 创建 TableEnvironment
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
- 在内部的 catalog 中注册
Table - 注册外部的 catalog
- 加载可插拔模块
- 执行 SQL 查询
- 注册自定义函数 (scalar、table 或 aggregation)
DataStream和Table之间的转换(面向StreamTableEnvironment)
Table 总是与特定的 TableEnvironment 绑定。 不能在同一条查询中使用不同 TableEnvironment 中的表,例如,对它们进行 join 或 union 操作。 TableEnvironment 可以通过静态方法 TableEnvironment.create() 创建。
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode()//.inBatchMode().build();TableEnvironment tEnv = TableEnvironment.create(settings);或者,用户可以从现有的 StreamExecutionEnvironment 创建一个
StreamTableEnvironment 与 DataStream API 互操作。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);3. 在 Catalog 中创建表
TableEnvironment 维护着一个由标识符(identifier)创建的表 catalog 的映射。标识符由三个部分组成:catalog 名称、数据库名称以及对象名称。如果 catalog 或者数据库没有指明,就会使用当前默认值。
Table 可以是虚拟的(视图 VIEWS)也可以是常规的(表 TABLES)。视图 VIEWS可以从已经存在的Table中创建,一般是 Table API 或者 SQL 的查询结果。 表TABLES描述的是外部数据,例如文件、数据库表或者消息队列。
3.1 临时表(Temporary Table)和永久表(Permanent Table)
表可以是临时的,并与单个 Flink 会话(session)的生命周期相关,也可以是永久的,并且在多个 Flink 会话和群集(cluster)中可见。
永久表需要Catalog(例如 Hive Metastore)以维护表的元数据。一旦永久表被创建,它将对任何连接到 catalog 的 Flink 会话可见且持续存在,直至被明确删除。
另一方面,临时表通常保存于内存中并且仅在创建它们的 Flink 会话持续期间存在。这些表对于其它会话是不可见的。它们不与任何 catalog 或者数据库绑定但可以在一个命名空间(namespace)中创建。即使它们对应的数据库被删除,临时表也不会被删除。
3.1.1 屏蔽(Shadowing)
可以使用与已存在的永久表相同的标识符去注册临时表。临时表会屏蔽永久表,并且只要临时表存在,永久表就无法访问。所有使用该标识符的查询都将作用于临时表。
3.2 创建表
3.2.1 虚拟表
在 SQL 的术语中,Table API 的对象对应于视图(虚拟表)。它封装了一个逻辑查询计划。它可以通过以下方法在 catalog 中创建:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// table is the result of a simple projection query
Table projTable = tableEnv.from("X").select(...);// register the Table projTable as table "projectedTable"
tableEnv.createTemporaryView("projectedTable", projTable);注意: 从传统数据库系统的角度来看,Table 对象与 VIEW 视图非常像。也就是,定义了 Table 的查询是没有被优化的, 而且会被内嵌到另一个引用了这个注册了的 Table的查询中。如果多个查询都引用了同一个注册了的Table,那么它会被内嵌每个查询中并被执行多次, 也就是说注册了的Table的结果不会被共享。
3.2.2 Connector Tables
另外一个方式去创建 TABLE 是通过 connector 声明。Connector 描述了存储表数据的外部系统。存储系统例如 Apache Kafka 或者常规的文件系统都可以通过这种方式来声明。这样的表可以直接使用 Table API 创建,也可以通过切换到 SQL DDL 来创建。
// Using table descriptors
final TableDescriptor sourceDescriptor = TableDescriptor.forConnector("datagen").schema(Schema.newBuilder().column("f0", DataTypes.STRING()).build()).option(DataGenConnectorOptions.ROWS_PER_SECOND, 100L).build();tableEnv.createTable("SourceTableA", sourceDescriptor);
tableEnv.createTemporaryTable("SourceTableB", sourceDescriptor);// Using SQL DDL
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable (...) WITH (...)");3.3 扩展表标识符
表总是通过三元标识符注册,包括 catalog 名、数据库名和表名。用户可以指定一个 catalog 和数据库作为 “当前catalog” 和"当前数据库"。有了这些,那么刚刚提到的三元标识符的前两个部分就可以被省略了。如果前两部分的标识符没有指定, 那么会使用当前的 catalog 和当前数据库。用户也可以通过 Table API 或 SQL 切换当前的 catalog 和当前的数据库。标识符遵循 SQL 标准,因此使用时需要用反引号(`)进行转义。
TableEnvironment tEnv = ...;
tEnv.useCatalog("custom_catalog");
tEnv.useDatabase("custom_database");Table table = ...;// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("exampleView", table);// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_database.exampleView", table);// register the view named 'example.View' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("`example.View`", table);// register the view named 'exampleView' in the catalog named 'other_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_catalog.other_database.exampleView", table);4. 查询表
4.1 Table API
Table API 是关于 Scala 和 Java 的集成语言式查询 API。与 SQL 相反,Table API 的查询不是由字符串指定,而是在宿主语言中逐步构建。Table API 是基于 Table 类的,该类表示一个表(流或批处理),并提供使用关系操作的方法。这些方法返回一个新的 Table 对象,该对象表示对输入 Table 进行关系操作的结果。 一些关系操作由多个方法调用组成,例如 table.groupBy(...).select(),其中 groupBy(...) 指定 table 的分组,而 select(...) 在 table 分组上的投影。
以下示例展示了一个简单的 Table API 聚合查询:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// register Orders table// scan registered Orders table
Table orders = tableEnv.from("Orders");
// compute revenue for all customers from France
Table revenue = orders.filter($("cCountry").isEqual("FRANCE")).groupBy($("cID"), $("cName")).select($("cID"), $("cName"), $("revenue").sum().as("revSum"));// emit or convert Table
// execute query4.2 SQL
Flink SQL 是基于实现了SQL标准的 Apache Calcite 的。SQL 查询由常规字符串指定。
下面的示例演示了如何指定查询并将结果作为 Table 对象返回。
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// register Orders table// compute revenue for all customers from France
Table revenue = tableEnv.sqlQuery("SELECT cID, cName, SUM(revenue) AS revSum " +"FROM Orders " +"WHERE cCountry = 'FRANCE' " +"GROUP BY cID, cName");// emit or convert Table
// execute query如下的示例展示了如何指定一个更新查询,将查询的结果插入到已注册的表中。
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// register "Orders" table
// register "RevenueFrance" output table// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.executeSql("INSERT INTO RevenueFrance " +"SELECT cID, cName, SUM(revenue) AS revSum " +"FROM Orders " +"WHERE cCountry = 'FRANCE' " +"GROUP BY cID, cName");4.3 混用 Table API 和 SQL
Table API 和 SQL 查询的混用非常简单因为它们都返回 Table 对象:
- 可以在 SQL 查询返回的
Table对象上定义 Table API 查询。 - 在
TableEnvironment中注册的结果表可以在 SQL 查询的FROM子句中引用,通过这种方法就可以在 Table API 查询的结果上定义 SQL 查询。
5. 输出表
Table 通过写入 TableSink 输出。TableSink 是一个通用接口,用于支持多种文件格式(如 CSV、Apache Parquet、Apache Avro)、存储系统(如 JDBC、Apache HBase、Apache Cassandra、Elasticsearch)或消息队列系统(如 Apache Kafka、RabbitMQ)。
批处理 Table 只能写入 BatchTableSink,而流处理 Table 需要指定写入 AppendStreamTableSink,RetractStreamTableSink 或者 UpsertStreamTableSink。
方法 Table.insertInto(String tableName) 定义了一个完整的端到端管道将源表中的数据传输到一个被注册的输出表中。 该方法通过名称在 catalog 中查找输出表并确认 Table schema 和输出表 schema 一致。 可以通过方法 TablePipeline.explain() 和 TablePipeline.execute() 分别来解释和执行一个数据流管道。
下面的示例演示如何输出 Table:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// create an output Table
final Schema schema = Schema.newBuilder().column("a", DataTypes.INT()).column("b", DataTypes.STRING()).column("c", DataTypes.BIGINT()).build();tableEnv.createTemporaryTable("CsvSinkTable", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/path/to/file").format(FormatDescriptor.forFormat("csv").option("field-delimiter", "|").build()).build());// compute a result Table using Table API operators and/or SQL queries
Table result = ...;// Prepare the insert into pipeline
TablePipeline pipeline = result.insertInto("CsvSinkTable");// Print explain details
pipeline.printExplain();// emit the result Table to the registered TableSink
pipeline.execute();6. 翻译与执行查询
不论输入数据源是流式的还是批式的,Table API 和 SQL 查询都会被转换成 DataStream 程序。 查询在内部表示为逻辑查询计划,并被翻译成两个阶段:
- 优化逻辑执行计划
- 翻译成 DataStream 程序
Table API 或者 SQL 查询在下列情况下会被翻译:
- 当
TableEnvironment.executeSql()被调用时。该方法是用来执行一个 SQL 语句,一旦该方法被调用, SQL 语句立即被翻译。 - 当
TablePipeline.execute()被调用时。该方法是用来执行一个源表到输出表的数据流,一旦该方法被调用, TABLE API 程序立即被翻译。 - 当
Table.execute()被调用时。该方法是用来将一个表的内容收集到本地,一旦该方法被调用, TABLE API 程序立即被翻译。 - 当
StatementSet.execute()被调用时。TablePipeline(通过StatementSet.add()输出给某个Sink)和 INSERT 语句 (通过调用StatementSet.addInsertSql())会先被缓存到StatementSet中,StatementSet.execute()方法被调用时,所有的 sink 会被优化成一张有向无环图。 - 当
Table被转换成DataStream时。转换完成后,它就成为一个普通的 DataStream 程序,并会在调用StreamExecutionEnvironment.execute()时被执行。
7. 查询优化
Apache Flink 使用并扩展了 Apache Calcite 来执行复杂的查询优化。 这包括一系列基于规则和成本的优化,例如:
- 基于 Apache Calcite 的子查询解相关
- 投影剪裁
- 分区剪裁
- 过滤器下推
- 子计划消除重复数据以避免重复计算
- 特殊子查询重写,包括两部分:
- 将 IN 和 EXISTS 转换为 left semi-joins
- 将 NOT IN 和 NOT EXISTS 转换为 left anti-join
- 可选 join 重新排序
- 通过
table.optimizer.join-reorder-enabled启用
- 通过
注意: 当前仅在子查询重写的结合条件下支持 IN / EXISTS / NOT IN / NOT EXISTS。优化器不仅基于计划,而且还基于可从数据源获得的丰富统计信息以及每个算子(例如 io,cpu,网络和内存)的细粒度成本来做出明智的决策。高级用户可以通过 CalciteConfig 对象提供自定义优化,可以通过调用 TableEnvironment#getConfig#setPlannerConfig 将其提供给 TableEnvironment。
8. 解释表
Table API 提供了一种机制来解释计算 Table 的逻辑和优化查询计划。 这是通过 Table.explain() 方法或者 StatementSet.explain() 方法来完成的。Table.explain() 返回一个 Table 的计划。StatementSet.explain() 返回多 sink 计划的结果。它返回一个描述三种计划的字符串:
- 关系查询的抽象语法树(the Abstract Syntax Tree),即未优化的逻辑查询计划,
- 优化的逻辑查询计划
- 物理执行计划。
可以用 TableEnvironment.explainSql() 方法和 TableEnvironment.executeSql() 方法支持执行一个 EXPLAIN 语句获取逻辑和优化查询计划.
以下代码展示了一个示例以及对给定 Table 使用 Table.explain() 方法的相应输出:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);DataStream<Tuple2<Integer, String>> stream1 = env.fromElements(new Tuple2<>(1, "hello"));
DataStream<Tuple2<Integer, String>> stream2 = env.fromElements(new Tuple2<>(1, "hello"));// explain Table API
Table table1 = tEnv.fromDataStream(stream1, $("count"), $("word"));
Table table2 = tEnv.fromDataStream(stream2, $("count"), $("word"));
Table table = table1.where($("word").like("F%")).unionAll(table2);System.out.println(table.explain());上述例子的结果是:
== Abstract Syntax Tree ==
LogicalUnion(all=[true])
:- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])
: +- LogicalTableScan(table=[[Unregistered_DataStream_1]])
+- LogicalTableScan(table=[[Unregistered_DataStream_2]])== Optimized Physical Plan ==
Union(all=[true], union=[count, word])
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
: +- DataStreamScan(table=[[Unregistered_DataStream_1]], fields=[count, word])
+- DataStreamScan(table=[[Unregistered_DataStream_2]], fields=[count, word])== Optimized Execution Plan ==
Union(all=[true], union=[count, word])
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
: +- DataStreamScan(table=[[Unregistered_DataStream_1]], fields=[count, word])
+- DataStreamScan(table=[[Unregistered_DataStream_2]], fields=[count, word])以下代码展示了一个示例以及使用 StatementSet.explain() 的多 sink 计划的相应输出:
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);final Schema schema = Schema.newBuilder().column("count", DataTypes.INT()).column("word", DataTypes.STRING()).build();tEnv.createTemporaryTable("MySource1", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/source/path1").format("csv").build());
tEnv.createTemporaryTable("MySource2", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/source/path2").format("csv").build());
tEnv.createTemporaryTable("MySink1", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/sink/path1").format("csv").build());
tEnv.createTemporaryTable("MySink2", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/sink/path2").format("csv").build());StatementSet stmtSet = tEnv.createStatementSet();Table table1 = tEnv.from("MySource1").where($("word").like("F%"));
stmtSet.add(table1.insertInto("MySink1"));Table table2 = table1.unionAll(tEnv.from("MySource2"));
stmtSet.add(table2.insertInto("MySink2"));String explanation = stmtSet.explain();
System.out.println(explanation);多 sink 计划的结果是:
== Abstract Syntax Tree ==
LogicalLegacySink(name=[`default_catalog`.`default_database`.`MySink1`], fields=[count, word])
+- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])+- LogicalTableScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]])LogicalLegacySink(name=[`default_catalog`.`default_database`.`MySink2`], fields=[count, word])
+- LogicalUnion(all=[true])
:- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])
: +- LogicalTableScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]])
+- LogicalTableScan(table=[[default_catalog, default_database, MySource2, source: [CsvTableSource(read fields: count, word)]]])== Optimized Physical Plan ==
LegacySink(name=[`default_catalog`.`default_database`.`MySink1`], fields=[count, word])
+- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])LegacySink(name=[`default_catalog`.`default_database`.`MySink2`], fields=[count, word])
+- Union(all=[true], union=[count, word])
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
: +- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])
+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource2, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])== Optimized Execution Plan ==
Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])(reuse_id=[1])
+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])LegacySink(name=[`default_catalog`.`default_database`.`MySink1`], fields=[count, word])
+- Reused(reference_id=[1])LegacySink(name=[`default_catalog`.`default_database`.`MySink2`], fields=[count, word])
+- Union(all=[true], union=[count, word])
:- Reused(reference_id=[1])
+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource2, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])相关文章:
 :Table API SQL (一) 概览)
Flink (十二) :Table API SQL (一) 概览
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。无论输入…...

FFmpeg(7.1版本)的基本组成
1. 前言 FFmpeg 是一个非常流行的开源项目,它提供了处理音频、视频以及其他多媒体内容的强大工具。FFmpeg 包含了大量的库,可以用来解码、编码、转码、处理和播放几乎所有类型的多媒体文件。它广泛用于视频和音频的录制、转换、流媒体传输等领域。 2. F…...

基于微信小程序的辅助教学系统的设计与实现
标题:基于微信小程序的辅助教学系统的设计与实现 内容:1.摘要 摘要:随着移动互联网的普及和微信小程序的兴起,基于微信小程序的辅助教学系统成为了教育领域的一个新的研究热点。本文旨在设计和实现一个基于微信小程序的辅助教学系统,以提高教…...

单片机基础模块学习——超声波传感器
一、超声波原理 左边发射超声波信号,右边接收超声波信号 左边的芯片用来处理超声波发射信号,中间的芯片用来处理接收的超声波信号 二、超声波原理图 T——transmit 发送R——Recieve 接收 U18芯片对输入的N_A1信号进行放大,然后输入给超声…...

HTML<hgroup>标签
例子: 使用hgroup元素标记标题和段落是相关的: <hgroup> <h2>Norway</h2> <p>The land with the midnight sun.</p> </hgroup> 定义和用法: 标签<hgroup>用于包围标题和一个或多个<p&g…...

C++并发编程指南08
以下是经过优化排版后的5.3节内容,详细解释了C中的同步操作和强制排序机制。每个部分都有详细的注释和结构化展示。 文章目录 5.3 同步操作和强制排序假设场景示例代码 5.3.1 同步发生 (Synchronizes-with)基本思想 5.3.2 先行发生 (Happens-before)单线程环境多线程…...
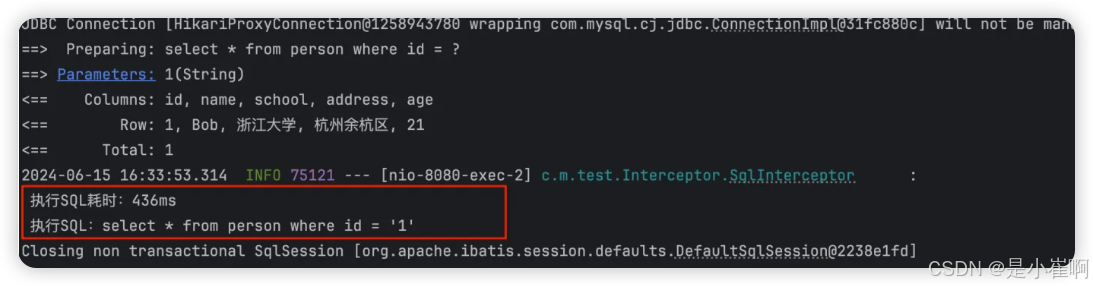
Spring Boot - 数据库集成03 - 集成Mybatis
Spring boot集成Mybatis 文章目录 Spring boot集成Mybatis一:基础知识1:什么是MyBatis2:为什么说MyBatis是半自动ORM3:MyBatis栈技术演进3.1:JDBC,自行封装JDBCUtil3.2:IBatis3.3:My…...

python:洛伦兹变换
洛伦兹变换(Lorentz transformations)是相对论中的一个重要概念,特别是在讨论时空的变换时非常重要。在四维时空的背景下,洛伦兹变换描述了在不同惯性参考系之间如何变换时间和空间坐标。在狭义相对论中,洛伦兹变换通常…...

“星门计划对AI未来的意义——以及谁将掌控它”
“星门计划对AI未来的意义——以及谁将掌控它” 图片由DALL-E 3生成 就在几天前,唐纳德特朗普宣布了“星门计划”,OpenAI随即跟进,分享了更多细节。他们明确表示,计划在未来四年内投资5000亿美元,在美国为OpenAI构建一…...

为什么“记住密码”适合持久化?
✅ 特性 1:应用重启后仍需生效 记住密码的本质是长期存储用户的登录凭证(如用户名、密码、JWT Token),即使用户关闭应用、重启设备,仍然可以自动登录。持久化存储方案: React Native 推荐使用 AsyncStorag…...

国产SiC碳化硅功率器件技术成为服务器电源升级的核心引擎
在服务器电源应用中,国产650V碳化硅(SiC)MOSFET逐步取代传统超结(Super Junction, SJ)MOSFET,其核心驱动力源于SiC材料在效率、功率密度、可靠性和长期经济性上的显著优势,叠加产业链成熟与政策…...
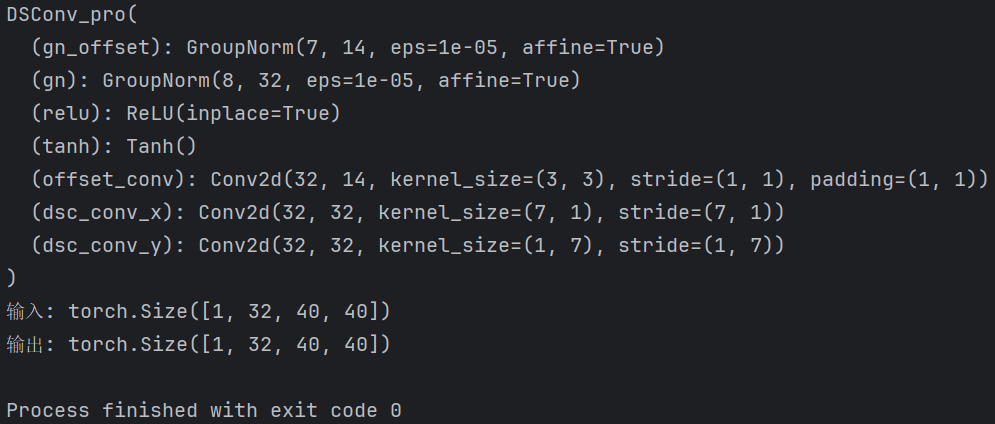
【Block总结】动态蛇形卷积,专注于细长和弯曲的局部结构|即插即用
论文信息 标题: Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation 作者: 戚耀磊、何宇霆、戚晓明、张媛、杨冠羽 会议: 2023 IEEE/CVF International Conference on Computer Vision (ICCV) 发表时间: 2023年10月…...

Spring MVC 框架:构建高效 Java Web 应用的利器
Java学习资料 Java学习资料 Java学习资料 一、引言 在 Java Web 开发领域,Spring MVC 框架是一颗耀眼的明星。它作为 Spring 框架家族的重要成员,为开发者提供了一套强大而灵活的解决方案,用于构建 Web 应用程序。Spring MVC 遵循模型 - 视…...
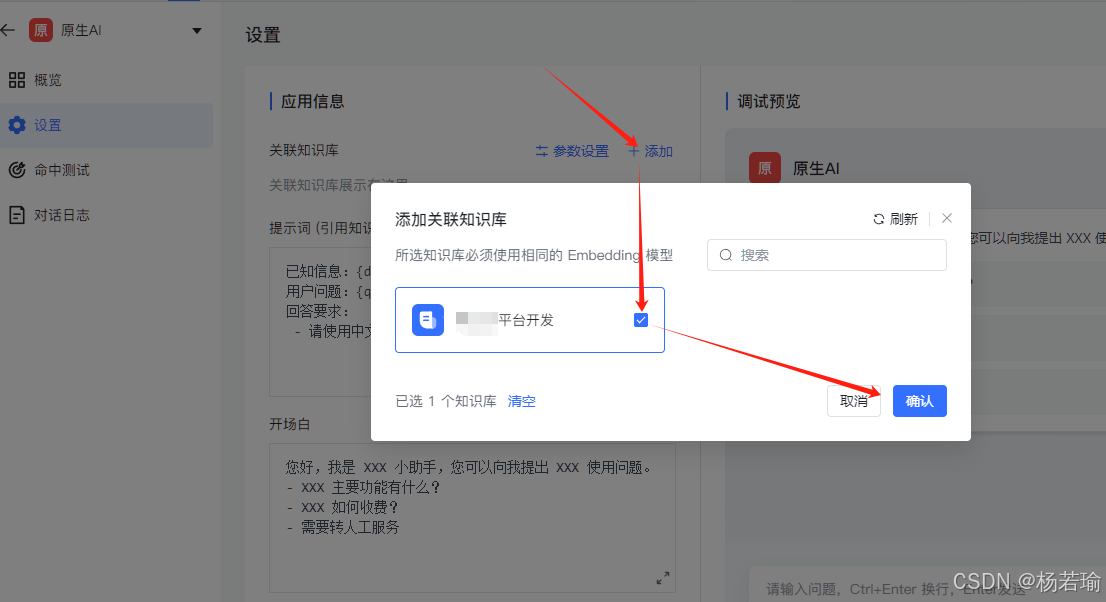
新鲜速递:DeepSeek-R1开源大模型本地部署实战—Ollama + MaxKB 搭建RAG检索增强生成应用
在AI技术快速发展的今天,开源大模型的本地化部署正在成为开发者们的热门实践方向。最火的莫过于吊打OpenAI过亿成本的纯国产DeepSeek开源大模型,就在刚刚,凭一己之力让英伟达大跌18%,纳斯达克大跌3.7%,足足是给中国AI产…...
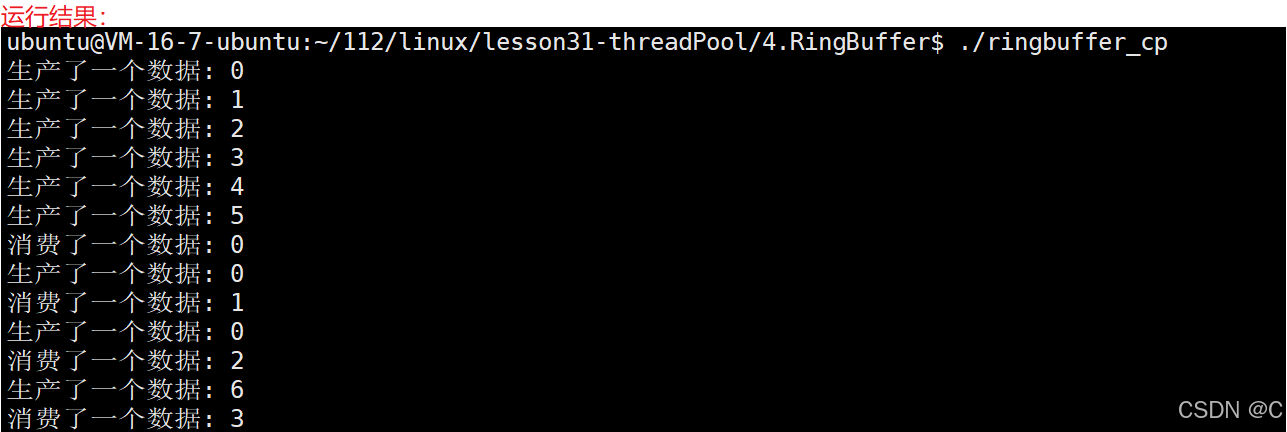
Linux_线程同步生产者消费者模型
同步的相关概念 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。 同步的…...
Origami Agents:通过AI驱动的研究工具提升B2B销售效率
在当今竞争激烈的商业环境中,B2B销售团队面临着巨大的挑战,如何高效地发现潜在客户并进行精准的外展活动成为关键。Origami Agents通过其创新的AI驱动研究工具,正在彻底改变这一过程。本文将深入探讨Origami Agents的产品特性、技术架构以及其快速增长背后的成功因素。 一、…...

linux的/proc 和 /sys目录差异
/proc 和 /sys 都是Linux系统中用于提供系统信息和进行系统配置的虚拟文件系统,但它们的原理并不完全一样,以下是具体分析: 目的与功能 /proc :主要用于提供系统进程相关信息以及内核运行时的一些参数等,可让用户和程…...

AIGC时代的Vue或React前端开发
在AIGC(人工智能生成内容)时代,Vue开发正经历着深刻的变革。以下是对AIGC时代Vue开发的详细分析: 一、AIGC技术对Vue开发的影响 代码生成与自动化 AIGC技术使得开发者能够借助智能工具快速生成和优化Vue代码。例如,通…...

代码随想录算法训练营第三十九天-动态规划-337. 打家劫舍 III
老师讲这是树形dp的入门题目解题思路是以二叉树的遍历(递归三部曲)再结合动规五部曲dp数组如何定义:只需要定义一个二个元素的数组,dp[0]与dp[1] dp[0]表示不偷当前节点的最大价值dp[1]表示偷当前节点后的最大价值这样可以把每个节…...
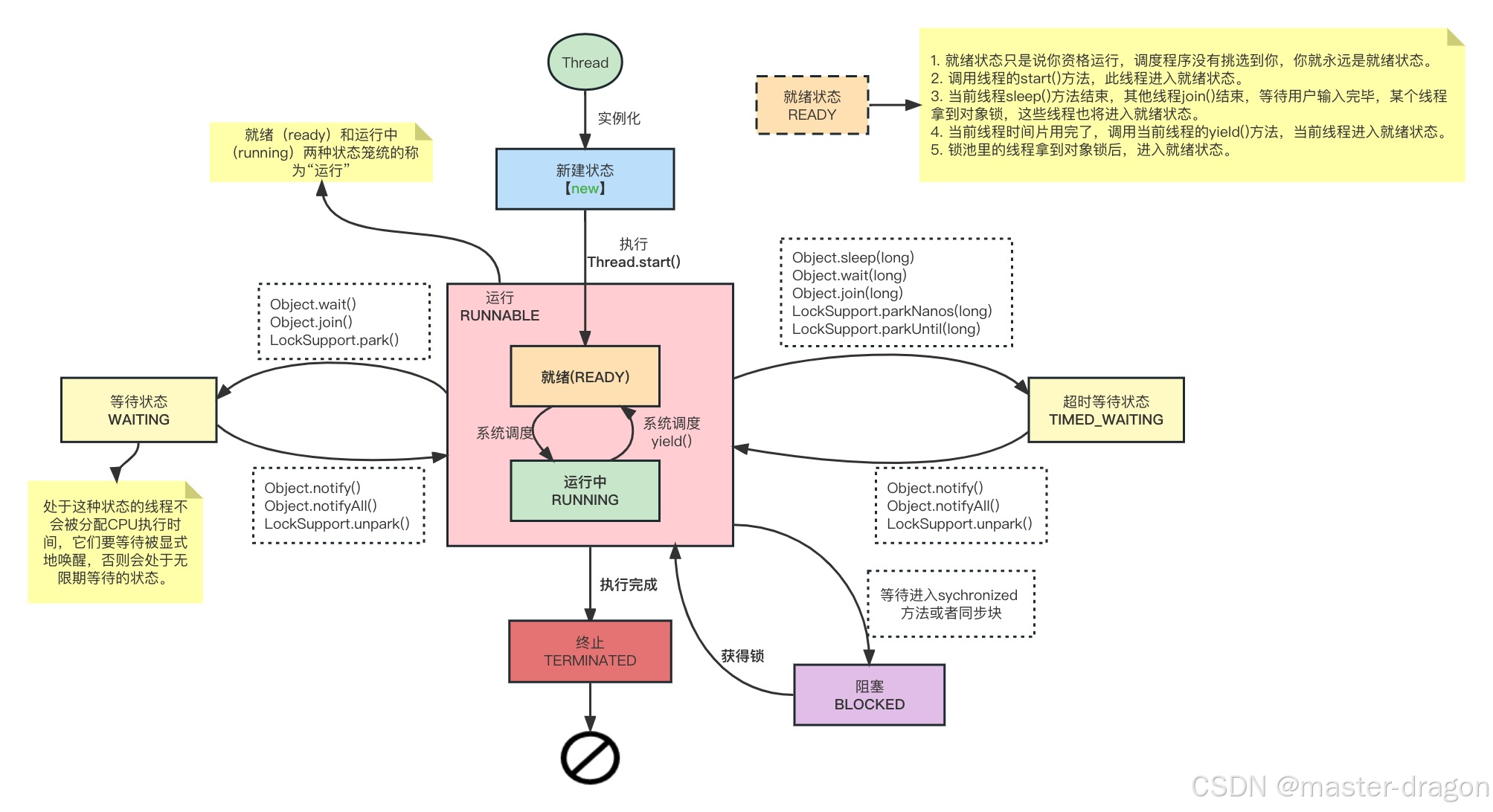
Java线程认识和Object的一些方法
专栏系列文章地址:https://blog.csdn.net/qq_26437925/article/details/145290162 本文目标: 要对Java线程有整体了解,深入认识到里面的一些方法和Object对象方法的区别。认识到Java对象的ObjectMonitor,这有助于后面的Synchron…...

【Java边缘运行时部署终极指南】:20年专家亲授5大避坑法则与3步极速上线实战
第一章:Java边缘运行时部署全景认知与演进脉络Java在边缘计算场景中的运行时部署正经历从传统云中心化架构向轻量、自治、低延迟方向的深刻演进。早期Java应用依赖完整JDK和重量级容器(如Tomcat)部署于虚拟机或Kubernetes集群,难以…...

别只改.prettierrc了!从Git配置到CI/CD,一劳永逸解决团队换行符冲突
从Git配置到CI/CD:彻底解决团队协作中的换行符冲突 跨平台协作开发时,换行符问题就像鞋里的一粒沙子——看似微不足道,却能让整个团队步履维艰。当Windows的CRLF遇上Unix的LF,不仅会导致Prettier报出恼人的Delete ␍错误ÿ…...

向量化计算失效的7大隐性陷阱,深度解析HotSpot向量编译器决策逻辑
第一章:向量化计算失效的7大隐性陷阱,深度解析HotSpot向量编译器决策逻辑HotSpot JVM 的向量化编译(Vector API 编译支持与循环自动向量化)并非在所有场景下都能生效。其背后由C2编译器的向量化决策引擎驱动,该引擎基于…...

避开高光谱求导的坑:你的平滑做对了吗?附MATLAB代码与数据示例
高光谱微分预处理实战指南:如何避免噪声放大陷阱 第一次处理高光谱数据时,我兴奋地直接对原始光谱曲线求导,结果得到了一堆杂乱无章的噪声信号。这个教训让我明白了一个关键原则:未经平滑的微分操作就像在放大镜下观察指纹——细节…...

Sambert多情感语音合成镜像:在虚拟主播场景下的应用实践
Sambert多情感语音合成镜像:在虚拟主播场景下的应用实践 1. 引言:虚拟主播的“声音”难题 你有没有想过,那些在直播间里和你互动、讲段子、带货的虚拟主播,为什么有的声音听起来特别“假”,而有的却能让你感觉像在和…...

万物识别镜像在内容安全场景的应用:SpringBoot集成与效果展示
万物识别镜像在内容安全场景的应用:SpringBoot集成与效果展示 1. 万物识别镜像技术解析 万物识别-中文-通用领域镜像基于cv_resnest101_general_recognition算法构建,是一个强大的视觉识别工具。这个镜像最突出的特点是能够识别超过5万类日常物体&…...

RevokeMsgPatcher:微信QQ防撤回终极指南,轻松保留重要消息
RevokeMsgPatcher:微信QQ防撤回终极指南,轻松保留重要消息 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: htt…...

2023B卷,IPv4地址转换成整数
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,IPv4地址转换成整数。 1.1 ☘️题目详情 题目: 存…...

10个企业级Windows自动化场景:pywinauto终极应用指南
10个企业级Windows自动化场景:pywinauto终极应用指南 【免费下载链接】pywinauto pywinauto/pywinauto: 一个 Python 库,用于自动化 Windows 应用程序。特点是提供了丰富的函数和类库,可以用于控制鼠标、键盘和菜单等元素,实现自动…...

函数信号发生器电路仿真、原理图及PCB设计
函数信号发生器电路仿真,原理图,PCB拆开手头的旧音响翻出几颗运放,突然想搞个函数信号发生器玩玩。这玩意儿说难不难,关键得让方波、三角波、正弦波乖乖听话。咱们今天直接从电路仿真干起,免得焊板子时炸电容。先上LTs…...