【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.10 ndarray内存模型:从指针到缓存优化

2.10 ndarray内存模型:从指针到缓存优化
目录
2.10.1 ndarray结构体解析
NumPy 的 ndarray 是一个高效的多维数组对象,它在内存中的存储方式对性能有重要影响。理解 ndarray 的内部结构有助于更好地优化代码性能。
- C结构体源码解析:NumPy 的 C 源码中
ndarray的结构体定义。 - 内存布局:
ndarray的内存布局。 - ** strides 和 shape**:
strides和shape属性的详细解释。
import numpy as np# 创建一个 3x3 的数组
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(f"数组 a 的形状: {a.shape}") # 输出数组的形状
print(f"数组 a 的步长: {a.strides}") # 输出数组的步长
print(f"数组 a 的数据类型: {a.dtype}") # 输出数组的数据类型
2.10.2 数据指针操作
ndarray 的数据指针(data)是 C 语言中的 void* 指针,指向实际数据在内存中的存储位置。了解数据指针操作可以更好地优化内存访问。
- 数据指针的基本操作:如何访问和操作
ndarray的数据指针。 - 内存视图:创建和使用内存视图。
- 内存连续性:检查和确保内存连续性。
import numpy as np# 创建一个 3x3 的数组
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=np.int32)# 获取数据指针
data_ptr = a.ctypes.data # 获取数组的 C 数据指针
print(f"数组 a 的数据指针: {data_ptr}") # 输出数据指针# 检查内存连续性
print(f"数组 a 是否是 C 内存连续的: {a.flags['C_CONTIGUOUS']}") # 输出 C 内存连续性标志
print(f"数组 a 是否是 Fortran 内存连续的: {a.flags['F_CONTIGUOUS']}") # 输出 Fortran 内存连续性标志
2.10.3 缓存行对齐技巧
缓存行对齐是提高数据访问性能的关键技术之一。在 NumPy 中,通过合理的数组形状和步长设置,可以实现缓存行对齐,从而提高计算效率。
- 缓存行对齐的原理:缓存行对齐的基本原理。
- 缓存行大小:常见的缓存行大小及其影响。
- 实现缓存行对齐:如何在 NumPy 中实现缓存行对齐。
import numpy as np# 创建一个 3x1000 的数组
a = np.random.rand(3, 1000)# 检查步长
print(f"数组 a 的步长: {a.strides}") # 输出步长# 调整数组形状以实现缓存行对齐
aligned_a = np.asfortranarray(a) # 转换为 Fortran 内存顺序
print(f"缓存行对齐后的数组 a 的步长: {aligned_a.strides}") # 输出调整后的步长
2.10.4 指针操作风险
指针操作虽然强大,但也存在潜在的风险,特别是在处理多维数组时。了解这些风险可以帮助避免常见的错误。
- 越界访问:数据指针越界访问的风险。
- 未初始化内存:使用未初始化内存的风险。
- 数据类型不匹配:数据类型不匹配的风险。
import numpy as np# 创建一个 3x3 的数组
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=np.int32)# 获取数据指针
data_ptr = a.ctypes.data# 越界访问
try:value = np.ctypeslib.as_array(np.ctypeslib.c_int32.from_address(data_ptr + 12 * a.itemsize)) # 越界访问print(f"越界访问的值: {value}")
except ValueError as e:print(f"错误: {e}") # 输出错误信息# 未初始化内存
uninitialized_a = np.empty((3, 3), dtype=np.int32)
print(uninitialized_a) # 输出未初始化的数组# 数据类型不匹配
b = np.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]], dtype=np.float64)
try:value = np.ctypeslib.as_array(np.ctypeslib.c_int32.from_address(b.ctypes.data))print(f"数据类型不匹配的值: {value}")
except ValueError as e:print(f"错误: {e}") # 输出错误信息
2.10.5 大数组内存预分配策略
在处理大数组时,合理的内存预分配策略可以显著提高性能,避免频繁的内存分配和释放操作。
- 预分配的好处:内存预分配的好处。
- 使用
np.empty和np.zeros:如何使用np.empty和np.zeros进行内存预分配。 - 动态增长数组:如何动态增长数组。
import numpy as np# 使用 np.empty 进行内存预分配
pre_allocated_array = np.empty((10000, 10000), dtype=np.float32)
print(f"预分配的数组: {pre_allocated_array}") # 输出预分配的数组# 使用 np.zeros 进行内存预分配
zero_array = np.zeros((10000, 10000), dtype=np.float32)
print(f"预分配的零数组: {zero_array}") # 输出预分配的零数组# 动态增长数组
def dynamic_array_growth(size):array = np.empty((0, size), dtype=np.float32)for i in range(10):new_row = np.random.rand(1, size)array = np.vstack((array, new_row))return arraydynamic_array = dynamic_array_growth(10000)
print(f"动态增长的数组: {dynamic_array}") # 输出动态增长的数组
2.10.6 总结
- 关键收获:理解
ndarray的内存模型和缓存行对齐技巧。 - 最佳实践:合理的数据指针操作和内存预分配策略。
- 常见陷阱:指针操作中的常见风险及其解决方法。
通过本文,我们深入探讨了 ndarray 的内存模型,包括其结构体解析、数据指针操作、缓存行对齐技巧、指针操作风险以及大数组内存预分配策略。希望这些内容能帮助你在实际开发中更好地优化代码性能,避免常见的内存陷阱。
2.10.7 参考文献
| 参考资料 | 链接 |
|---|---|
| 《NumPy Beginner’s Guide》 | NumPy Beginner’s Guide |
| 《Python for Data Analysis》 | Python for Data Analysis |
| NumPy 官方文档 | NumPy C API Documentation |
| TensorFlow 官方文档 | TensorFlow Performance Guide |
| 《高性能Python》 | High Performance Python |
| 《Python数据科学手册》 | Python Data Science Handbook |
| Stack Overflow | Understanding NumPy’s C API |
| Medium | Optimizing NumPy Memory Usage |
| SciPy 官方文档 | SciPy Memory Efficiency |
| Wikipedia | Cache Alignment |
| 量子力学教程 | Quantum Mechanics Lecture Notes |
| 《Numerical Linear Algebra》 | Numerical Linear Algebra |
这篇文章包含了详细的原理介绍、代码示例、源码注释以及案例等。希望这对您有帮助。如果有任何问题请随私信或评论告诉我。
相关文章:
【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.10 ndarray内存模型:从指针到缓存优化
2.10 ndarray内存模型:从指针到缓存优化 目录 #mermaid-svg-p0zxLYqAnn59O2Xe {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-p0zxLYqAnn59O2Xe .error-icon{fill:#552222;}#mermaid-svg-p0zxLYqAnn59O…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.6 广播机制核心算法:维度扩展的数学建模
2.6 广播机制核心算法:维度扩展的数学建模 目录/提纲 #mermaid-svg-IfELXmhcsdH1tW69 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-IfELXmhcsdH1tW69 .error-icon{fill:#552222;}#mermaid-svg-IfELXm…...

K8S极简教程(4小时快速学会)
1. K8S 概览 1.1 K8S 是什么 K8S官网文档:https://kubernetes.io/zh/docs/home/ 1.2 K8S核心特性 服务发现与负载均衡:无需修改你的应用程序即可使用陌生的服务发现机制。存储编排:自动挂载所选存储系统,包括本地存储。Secret和…...
)
系统URL整合系列视频二(界面原型)
视频 系统URL整合系列视频二(界面原型) 视频介绍 (全国)大型分布式系统Web资源URL整合需求界面原型讲解。当今社会各行各业对软件系统的web资源访问权限控制越来越严格,控制粒度也越来越细。安全级别提高的同时也增加…...

虚幻浏览器插件 UE与JS通信
温馨提示:本节内容需要结合插件Content下的2_Communication和Resources下的sample.html 一起阅读。 1. UE调用JS 1.1 JS脚本实现 该部分共两步: 导入jstote.js脚本实现响应函数并保存到 ue.interface 中 jsfunc 通过json对象传递参数,仅支持函数名小…...

OpenAI深夜反击:o3-mini免费上线,能否撼动DeepSeek的地位?
还在为寻找合适的 AI 模型而烦恼吗?chatTools 平台为您精选 o1、GPT4o、Claude、Gemini 等顶尖 AI 模型,满足您不同的 AI 应用需求。立即体验强大的 AI 能力! 深夜反击,OpenAI祭出o3-mini 在DeepSeek异军突起,搅动AI行…...

Golang 应用的 Docker 部署方式介绍及使用详解
本文将介绍如何使用 Docker 部署一个基于 Go 语言的后台服务应用 godco,并介绍如何配置 MongoDB 数据库容器的连接,确保应用能够成功启动并连接到容器方式部署的mongoDB数据库。 前提条件 1.已安装 Docker/Podman 2.已安装 MongoDB 数据库容器ÿ…...
deep seek R1本地化部署及openAI API调用
先说几句题外话。 最近deep seek火遍全球,所以春节假期期间趁着官网优惠充值了deep seek的API,用openAI的接口方式尝试了下对deep seek的调用,并且做了个简单测试,测试内容确实非常简单:通过prompt提示词让大模型对用…...

力扣第435场周赛讲解
文章目录 题目总览题目详解3442.奇偶频次间的最大差值I3443.K次修改后的最大曼哈顿距离3444. 使数组包含目标值倍数的最少增量3445.奇偶频次间的最大差值 题目总览 奇偶频次间的最大差值I K次修改后的最大曼哈顿距离 使数组包含目标值倍数的最少增量 奇偶频次间的最大差值II …...

初入机器学习
写在前面 本专栏专门撰写深度学习相关的内容,防止自己遗忘,也为大家提供一些个人的思考 一切仅供参考 概念辨析 深度学习: 本质是建模,将训练得到的模型作为系统的一部分使用侧重于发现样本集中隐含的规律难点是认识并了解模型&…...

Signature
Signature 题目是: import ecdsaimport randomdef ecdsa_test(dA,k):sk ecdsa.SigningKey.from_secret_exponent(secexpdA,curveecdsa.SECP256k1)sig1 sk.sign(databHi., kk).hex()sig2 sk.sign(databhello., kk).hex()#不同的kr1 int(sig1[:64], 16)s1 i…...

93,【1】buuctf web [网鼎杯 2020 朱雀组]phpweb
进入靶场 页面一直在刷新 在 PHP 中,date() 函数是一个非常常用的处理日期和时间的函数,所以应该用到了 再看看警告的那句话 Warning: date(): It is not safe to rely on the systems timezone settings. You are *required* to use the date.timez…...
笔灵ai写作技术浅析(四):知识图谱
知识图谱(Knowledge Graph)是一种结构化的知识表示方式,通过将知识以图的形式进行组织,帮助AI系统更好地理解和利用信息。在笔灵AI写作中,知识图谱技术被广泛应用于结构化组织各种领域的知识,使AI能够根据写作主题快速获取相关的背景知识、概念关系等,从而为生成内容提供…...
Chromium132 编译指南 - Android 篇(四):配置 depot_tools
1. 引言 在前面的章节中,我们详细介绍了编译 Chromium 132 for Android 所需的系统和硬件要求,以及如何安装和配置基础开发环境和常用工具。完成这些步骤后,接下来需要配置 depot_tools,这是编译 Chromium 的关键工具集。depot_t…...

使用真实 Elasticsearch 进行高级集成测试
作者:来自 Elastic Piotr Przybyl 掌握高级 Elasticsearch 集成测试:更快、更智能、更优化。 在上一篇关于集成测试的文章中,我们介绍了如何通过改变数据初始化策略来缩短依赖于真实 Elasticsearch 的集成测试的执行时间。在本期中࿰…...

SQL进阶实战技巧:如何分析浏览到下单各步骤转化率及流失用户数?
目录 0 问题描述 1 数据准备 2 问题分析 3 问题拓展 3.1 跳出率计算...
机器学习--概览
一、机器学习基础概念 1. 定义 机器学习(Machine Learning, ML):通过算法让计算机从数据中自动学习规律,并利用学习到的模型进行预测或决策,而无需显式编程。 2. 与编程的区别 传统编程机器学习输入:规…...

低代码系统-产品架构案例介绍、炎黄盈动-易鲸云(十二)
易鲸云作为炎黄盈动新推出的产品,在定位上为低零代码产品。 开发层 表单引擎 表单设计器,包括设计和渲染 流程引擎 流程设计,包括设计和渲染,需要说明的是:采用国际标准BPMN2.0,可以全球通用 视图引擎 视图…...
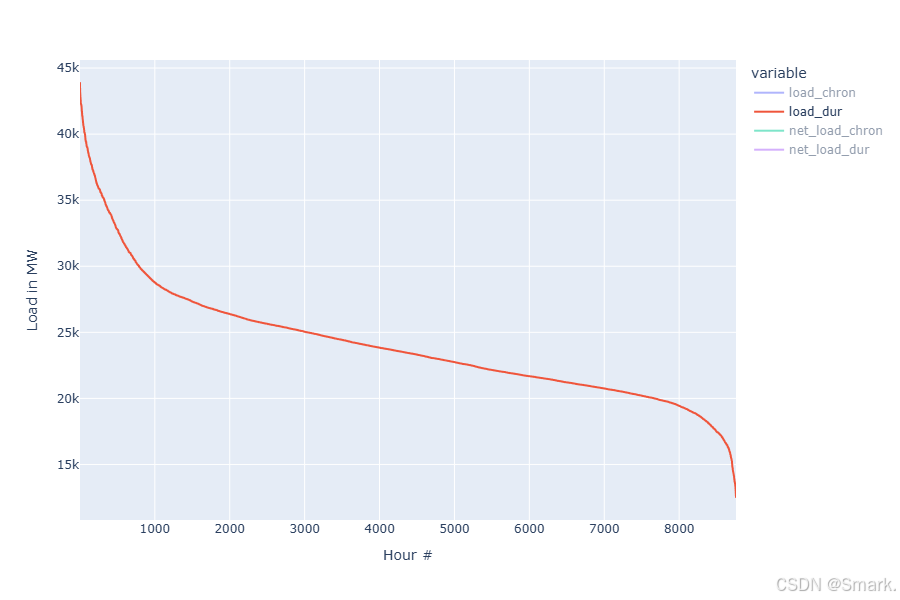
Electricity Market Optimization 探索系列(二)
本文参考链接link 负荷持续时间曲线 (Load Duration Curve),是根据实际的符合数据进行降序排序之后得到的一个曲线 这个曲线能够发现负荷在某个区间时,将会持续多长时间,有助于发电容量的规划 净负荷(net load) 是指预期负荷和预期可再生…...

OpenAI 实战进阶教程 - 第一节:OpenAI API 架构与基础调用
目标 掌握 OpenAI API 的基础调用方法。理解如何通过 API 进行内容生成。使用实际应用场景帮助零基础读者理解 API 的基本用法。 一、什么是 OpenAI API? OpenAI API 是一种工具,允许开发者通过编程方式与 OpenAI 的强大语言模型(例如 gpt-…...
)
紧急更新!Midjourney刚推送的--stylize 1000级调优补丁,已实测提升立体主义结构清晰度达4.8倍(附对比数据集下载)
更多请点击: https://intelliparadigm.com 第一章:Midjourney立体主义风格的本质解构 立体主义并非简单地将物体“打碎再拼合”,而是一种对多维时空感知的视觉转译——Midjourney 通过其隐式扩散先验,以概率化方式重构了布拉克与…...
NeoPixel电源设计全攻略:从电流估算到多电源分配
1. 项目概述:为什么NeoPixel电源设计是成败关键如果你玩过NeoPixel或者类似的WS2812B可编程LED,大概率经历过这样的场景:精心设计的动画点亮了十几个灯珠,效果惊艳;但当你兴冲冲地把灯珠数量加到一百个,准备…...

基于Blazor与LLamaSharp构建本地大模型ChatGPT式Web应用
1. 项目概述与核心价值最近在折腾一个内部工具,想把本地大模型的能力和类似ChatGPT的对话体验结合起来,部署成一个Web应用。找了一圈,发现一个挺有意思的项目叫“BLlamaSharp.ChatGpt.Blazor”。光看这个名字,信息量就很大了&…...

FontForge:从零到一的免费字体设计全攻略
FontForge:从零到一的免费字体设计全攻略 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾经想过亲手设计一款属于自己的字体?也许你为…...

如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南
如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款强大的Unity游戏插件框架,为游戏模组…...

Windows终极优化神器:三分钟让Windows焕然一新
Windows终极优化神器:三分钟让Windows焕然一新 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否厌倦了每次重装系统后繁琐的…...

ADC选型新思路:从抗混叠架构革新到极致集成设计
1. 从“采样”到“混叠”:一个老问题的现代解法做信号链设计,ADC选型永远是绕不开的核心。这些年,从工业物联网的传感器节点到汽车雷达的信号处理板,我经手过不少项目,一个深刻的体会是:系统性能的瓶颈&…...

2026届学术党必备的五大降AI率工具解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 每位学者以及学生,在学术研究的这条道路之上,都必然要跨越论文写作这…...
)
ssm基于Java的试题库管理系统(10030)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...
)
QT6.5项目实战:用HidApi库搞定USB HID设备读写(附完整配置流程)
QT6.5实战:HidApi库深度集成与USB HID设备高效通信指南 USB HID设备作为人机交互的基础协议,在工业控制、医疗设备、游戏外设等领域广泛应用。当开发者需要在QT6.5环境中实现与这类设备的稳定通信时,HidApi库因其轻量级和跨平台特性成为理想选…...