25寒假算法刷题 | Day1 | LeetCode 240. 搜索二维矩阵 II,148. 排序链表
目录
- 240. 搜索二维矩阵 II
- 题目描述
- 题解
- 148. 排序链表
- 题目描述
- 题解
240. 搜索二维矩阵 II
点此跳转题目链接
题目描述
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例 1:

输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
示例 2:

输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-109 <= matrix[i][j] <= 109- 每行的所有元素从左到右升序排列
- 每列的所有元素从上到下升序排列
-109 <= target <= 109
题解
暴力算法直接遍历整个矩阵,时间复杂度为 O ( m n ) O(mn) O(mn) , m 、 n m、n m、n 分别为矩阵的行、列数。
由于题中矩阵在行和列上的元素都是升序的,所以想到可以从上到下逐行利用二分查找解决:
class Solution {
public:int binarySearch(const vector<int>& arr, int target) {int left = 0;int right = arr.size() - 1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] < target) {left = mid + 1;} else if (arr[mid] > target) {right = mid - 1;} else {return mid;}}return -1;}bool searchMatrix(vector<vector<int>>& matrix, int target) {if (matrix.empty()) {return false;}// 逐行使用二分法查找targetfor (const vector<int>& line : matrix) {if (binarySearch(line, target) != -1) {return true;}}return false;}
};
行内 n n n 个元素做二分查找的时间复杂度为 O ( l o g n ) O(logn) O(logn) ,共 m m m 行,故时间复杂度为 O ( m l o g n ) O(mlogn) O(mlogn) 。
不过上面两种方法似乎都过于直白简单了,考虑到这个题目带的是“中等”tag,肯定还有更高效的算法:
🔗 以下内容来自 LeetCode官方题解
我们可以从矩阵 matrix 的右上角 (0,n−1) 进行搜索。在每一步的搜索过程中,如果我们位于位置 (x,y) ,那么我们希望在以 matrix 的左下角为左下角、以 (x,y) 为右上角的矩阵中进行搜索,即行的范围为 [x,m−1] ,列的范围为 [0,y] :
- 如果
matrix[x,y]=target,说明搜索完成 - 如果
matrix[x,y]>target,由于每一列的元素都是升序排列的,那么在当前的搜索矩阵中,所有位于第y列的元素都是严格大于target的,因此我们可以将它们全部忽略,即将y减少 1 - 如果
matrix[x,y]<target,由于每一行的元素都是升序排列的,那么在当前的搜索矩阵中,所有位于第x行的元素都是严格小于target的,因此我们可以将它们全部忽略,即将x增加 1。
在搜索的过程中,如果我们超出了矩阵的边界,那么说明矩阵中不存在 target 。代码实现如下:
class Solution {
public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int x = 0;int y = matrix[0].size() - 1;while (x < matrix.size() && y >= 0) {if (matrix[x][y] < target) {x++;} else if (matrix[x][y] > target) {y--;} else {return true;}}return false;}
};
时间复杂度: O ( m + n ) O(m+n) O(m+n) 。在搜索的过程中,如果我们没有找到 target ,那么我们要么将 y 减少 1,要么将 x 增加 1。由于 (x,y) 的初始值分别为 (0,n−1) ,因此 y 最多能被减少 n 次, x 最多能被增加 m 次,总搜索次数为 m+n 。在这之后, x 和 y 就会超出矩阵的边界。
148. 排序链表
点此跳转题目链接
题目描述
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
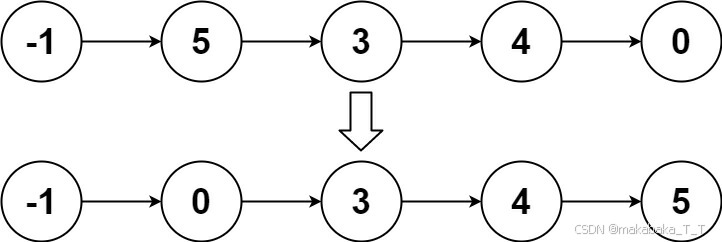
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目在范围
[0, 5 * 104]内 -105 <= Node.val <= 105
进阶: 你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
题解
暴力解法无需多言,遍历一遍链表获取全部元素、排序后重新整一个新链表即可:
struct ListNode
{int val;ListNode *next;ListNode() : val(0), next(nullptr) {}ListNode(int x) : val(x), next(nullptr) {}ListNode(int x, ListNode *next) : val(x), next(next) {}
};class Solution {
public:ListNode* sortList(ListNode* head) {vector<int> elements;while (head){elements.push_back(head->val);head = head->next;}sort(elements.begin(), elements.end());ListNode *dummyHead = new ListNode();ListNode *cur = dummyHead;for (int element : elements) {cur->next = new ListNode(element);cur = cur->next;}return dummyHead->next;}
};
上述算法时间复杂度为 sort() 的 O ( n log n ) O(n\log{n}) O(nlogn) ,空间复杂度为 O ( n ) O(n) O(n) ——因为新建了一个链表。 直接看看进阶要求:时间复杂度为 O ( n log n ) O(n\log{n}) O(nlogn) ,空间复杂度为常数级。
考虑算法题中常用的高效排序算法——归并排序,有:
class Solution {
public:ListNode *merge(ListNode *L, ListNode *R) {ListNode dummyHead;ListNode *cur = &dummyHead;while (L && R) {if (L->val < R->val) {cur->next = L;L = L->next;} else {cur->next = R;R = R->next;}cur = cur->next;}cur->next = L ? L : R;return dummyHead.next;}ListNode *sortList(ListNode *head, ListNode *tail) {if (!head || head == tail) return head;// 快慢指针找到链表中点ListNode *slow = head, *fast = head;while (fast != tail && fast->next != tail) {slow = slow->next;fast = fast->next->next;}ListNode *mid = slow->next;slow->next = nullptr; // 断开链表return merge(sortList(head, slow), sortList(mid, tail));}ListNode *sortList(ListNode *head) { return sortList(head, nullptr); }
};
上述算法时间复杂度为 O ( n log n ) O(n\log{n}) O(nlogn) ,即归并排序的时间复杂度。空间复杂度取决于递归调用的栈空间,为 O ( log n ) O(\log{n}) O(logn) ,还是没到最佳的常数级别。为此,需要采用“自底向上”的归并排序实现 O ( 1 ) O(1) O(1) 的空间复杂度:
🔗 以下内容参考 LeetCode官方题解
首先求得链表的长度 length ,然后将链表拆分成子链表进行合并。具体做法如下:
- 用
subLength表示每次需要排序的子链表的长度,初始时subLength=1。 - 每次将链表拆分成若干个长度为
subLength的子链表(最后一个子链表的长度可以小于subLength),按照每两个子链表一组进行合并,合并后即可得到若干个长度为subLength×2的有序子链表(最后一个子链表的长度可以小于subLength×2)。合并两个子链表仍然使用之前用过的归并算法。 - 将
subLength的值加倍,重复第 2 步,对更长的有序子链表进行合并操作,直到有序子链表的长度大于或等于length,整个链表排序完毕。
通过数学归纳法易证最后得到的链表是有序的(每次合并用到的子链表是有序的,合并后的也是有序的)。
class Solution {
public:ListNode *merge(ListNode *L, ListNode *R) {ListNode dummyHead;ListNode *cur = &dummyHead;while (L && R) {if (L->val < R->val) {cur->next = L;L = L->next;} else {cur->next = R;R = R->next;}cur = cur->next;}cur->next = L ? L : R;return dummyHead.next;}ListNode *sortList(ListNode *head) {if (!head) {return nullptr;}// 获取链表长度int length = 0;ListNode *cur = head;while (cur != nullptr) {length++;cur = cur->next;}// 自底向上,两两合并长度为subLength的子链表ListNode *dummyHead = new ListNode(0, head);for (int subLength = 1; subLength < length; subLength <<= 1) {ListNode *prev = dummyHead;cur = prev->next;while (cur != nullptr) {// 获取第一个子链表ListNode *head1 = cur;for (int i = 1; i < subLength && cur->next != nullptr; ++i) {cur = cur->next;}// 获取第二个子链表ListNode *head2 = cur->next;cur->next = nullptr; // 断开第一个子链表结尾cur = head2;for (int i = 1; i < subLength && cur && cur->next; ++i) {cur = cur->next;}// 预存第三个子链表(即下一轮的第一个子链表)的头节点// 即第二个子链表结尾节点的next节点ListNode *nextHead = nullptr;if (cur != nullptr) {nextHead = cur->next;cur->next = nullptr; // 断开第二个子链表结尾}// 合并第一、二个子链表ListNode *merged = merge(head1, head2);// 更新prev、cur指针prev->next = merged;while (prev->next != nullptr) {prev = prev->next;}cur = nextHead;}}return dummyHead->next;}
};
该算法时间复杂度为 O ( n log n ) O(n \log{n}) O(nlogn) ,空间复杂度为 O ( 1 ) O(1) O(1) 。
相关文章:
25寒假算法刷题 | Day1 | LeetCode 240. 搜索二维矩阵 II,148. 排序链表
目录 240. 搜索二维矩阵 II题目描述题解 148. 排序链表题目描述题解 240. 搜索二维矩阵 II 点此跳转题目链接 题目描述 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到…...
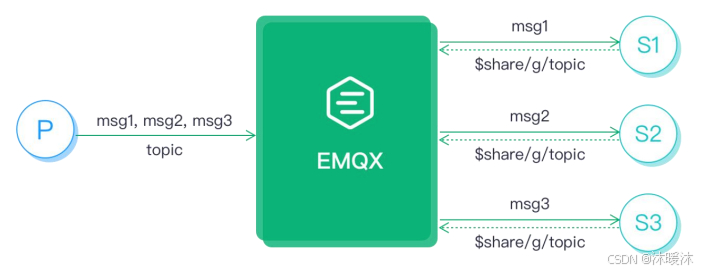
MQTT知识
MQTT协议 MQTT 是一种基于发布/订阅模式的轻量级消息传输协议,专门针对低带宽和不稳定网络环境的物联网应用而设计,可以用极少的代码为联网设备提供实时可靠的消息服务。MQTT 协议广泛应用于物联网、移动互联网、智能硬件、车联网、智慧城市、远程医疗、…...

【机器学习与数据挖掘实战】案例11:基于灰色预测和SVR的企业所得税预测分析
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈机器学习与数据挖掘实战 ⌋ ⌋ ⌋ 机器学习是人工智能的一个分支,专注于让计算机系统通过数据学习和改进。它利用统计和计算方法,使模型能够从数据中自动提取特征并做出预测或决策。数据挖掘则是从大型数据集中发现模式、关联…...

新一代搜索引擎,是 ES 的15倍?
Manticore Search介绍 Manticore Search 是一个使用 C 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码…...

使用 Context API 管理临时状态,避免 Redux/Zustand 的持久化陷阱
在开发 React Native 应用时,我们经常需要管理全局状态,比如用户信息、主题设置、网络状态等。而对于某些临时状态,例如 数据同步进行中的状态 (isSyncing),我们应该选择什么方式来管理它? 在项目开发过程中ÿ…...
PyTorch框架——基于深度学习YOLOv8神经网络学生课堂行为检测识别系统
基于YOLOv8深度学习的学生课堂行为检测识别系统,其能识别三种学生课堂行为:names: [举手, 读书, 写字] 具体图片见如下: 第一步:YOLOv8介绍 YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本…...

word2vec 实战应用介绍
Word2Vec 是一种由 Google 在 2013 年推出的重要词嵌入模型,通过将单词映射为低维向量,实现了对自然语言处理任务的高效支持。其核心思想是利用深度学习技术,通过训练大量文本数据,将单词表示为稠密的向量形式,从而捕捉单词之间的语义和语法关系。以下是关于 Word2Vec 实战…...

C# 操作符重载对象详解
.NET学习资料 .NET学习资料 .NET学习资料 一、操作符重载的概念 在 C# 中,操作符重载允许我们为自定义的类或结构体定义操作符的行为。通常,我们熟悉的操作符,如加法()、减法(-)、乘法&#…...

python学opencv|读取图像(五十四)使用cv2.blur()函数实现图像像素均值处理
【1】引言 前序学习进程中,对图像的操作均基于各个像素点上的BGR值不同而展开。 对于彩色图像,每个像素点上的BGR值为三个整数,因为是三通道图像;对于灰度图像,各个像素上的BGR值是一个整数,因为这是单通…...
: 非极大值抑制(Non-Maximum Suppression, NMS))
CNN的各种知识点(四): 非极大值抑制(Non-Maximum Suppression, NMS)
非极大值抑制(Non-Maximum Suppression, NMS) 1. 非极大值抑制(Non-Maximum Suppression, NMS)概念:算法步骤:具体例子:PyTorch实现: 总结: 1. 非极大值抑制(…...

虚幻基础16:locomotion direction
locomotion locomotion:角色运动系统的总称:包含移动、奔跑、跳跃、转向等。 locomotion direction 玩家输入 玩家输入:通常代表玩家想要的移动方向。 direction 可以计算当前朝向与移动方向的Δ。从而实现朝向与移动(玩家输入)方向的分…...

C++游戏开发实战:从引擎架构到物理碰撞
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 C 是游戏开发中最受欢迎的编程语言之一,因其高性能、低延迟和强大的底层控制能力,被广泛用于游戏…...

代理模式——C++实现
目录 1. 代理模式简介 2. 代码示例 1. 代理模式简介 代理模式是一种行为型模式。 代理模式的定义:由于某些原因需要给某对象提供一个代理以控制该对象的访问。这时,访问对象不适合或者不能直接访问引用目标对象,代理对象作为访问对象和目标…...

什么情况下,C#需要手动进行资源分配和释放?什么又是非托管资源?
扩展:如何使用C#的using语句释放资源?什么是IDisposable接口?与垃圾回收有什么关系?-CSDN博客 托管资源的回收有GC自动触发,而非托管资源需要手动释放。 在 C# 中,非托管资源是指那些不由 CLR(…...

LeetCode 2909. 元素和最小的山形三元组 II
**### LeetCode 2909. 元素和最小的山形三元组 II 问题描述 给定一个下标从 0 开始的整数数组 nums,我们需要找到一个“山形三元组”(i, j, k)满足以下条件: i < j < knums[i] < nums[j] 且 nums[k] < nums[j] 并…...

搬迁至bilibili声明
我将搬迁到bilibili ,用户名:北苏清风 在这个用户名上的文章部分将出自csdn的这个账号,均属于本人原创...

【周易哲学】生辰八字入门讲解(八)
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文讲解【周易哲学】生辰八字入门讲解,期待与你一同探索、学习、进步,一起卷起来叭! 目录 一、六亲女命六亲星六亲宫位相互关系 男命六亲星…...

复制粘贴小工具——Ditto
在日常工作中,复制粘贴是常见的操作,但Windows系统自带的剪贴板功能较为有限,只能保存最近一次的复制记录,这对于需要频繁复制粘贴的用户来说不太方便。今天,我们介绍一款开源、免费且功能强大的剪贴板增强工具——Dit…...

3、从langchain到rag
文章目录 本文介绍向量和向量数据库向量向量数据库 索引开始动手实现rag加载文档数据并建立索引将向量存放到向量数据库中检索生成构成一条链 本文介绍 从本节开始,有了上一节的langchain基础学习,接下来使用langchain实现一个rag应用,并稍微…...

稀疏进化训练:机器学习优化算法中的高效解决方案
稀疏进化训练:机器学习优化算法中的高效解决方案 稀疏进化训练:机器学习优化算法中的高效解决方案引言第一部分:背景与动机1.1 传统优化算法的局限性1.2 进化策略的优势1.3 稀疏性的重要性 第二部分:稀疏进化训练的核心思想2.1 稀…...

书成紫微动,律定凤凰驯:海棠山铁哥的道,从来不是嘴上说的,是写在作品里的
文坛从不缺大道理,也不缺高谈阔论的传道者,历来最缺的,是知行合一、落地成真的真大道。一、乱象:言道者多,行道者少口头标榜实际行径文脉传承随波逐流初心坚守妥协功利拒绝流量收割热度敬畏真诚唯数据论 语言可以伪装人…...

避坑指南:QGraphicsView自适应缩放时,为什么你的Item总对不齐或留白?
避坑指南:QGraphicsView自适应缩放时Item对齐与留白问题深度解析 在Qt图形界面开发中,QGraphicsView框架因其强大的2D显示能力被广泛应用。但当开发者尝试实现视图内容的自适应缩放时,经常会遇到一个令人头疼的问题——调用fitInView后&#…...

Taotoken Token Plan套餐在实际开发中的成本控制体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan套餐在实际开发中的成本控制体感 1. 套餐选择与预算锚定 在项目开发初期,团队或个人开发者面临的…...

WinUtil:Windows系统优化与软件管理的终极免费解决方案
WinUtil:Windows系统优化与软件管理的终极免费解决方案 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系统优化和软…...

告别卡顿!Flowframes让普通视频秒变丝滑的AI插帧神器
告别卡顿!Flowframes让普通视频秒变丝滑的AI插帧神器 【免费下载链接】flowframes Flowframes Windows GUI for video interpolation using DAIN (NCNN) or RIFE (CUDA/NCNN) 项目地址: https://gitcode.com/gh_mirrors/fl/flowframes 你是否曾为观看动作电影…...

本地RAG系统实战:基于开源模型构建私有知识库问答应用
1. 项目概述与核心价值最近在折腾本地大模型应用的时候,发现了一个挺有意思的项目,叫Awareness-Local。这名字听起来有点玄乎,但说白了,它就是一个帮你把本地文件(比如PDF、Word、TXT,甚至图片里的文字&…...
)
SAP ECC6 2027年停服倒计时:手把手教你评估四大迁移路径与成本(含第三方支持避坑指南)
SAP ECC6 2027年停服倒计时:企业迁移决策全景指南 当2027年的钟声敲响时,全球仍在运行SAP ECC6系统的企业将面临一个关键转折点。这不是简单的技术升级,而是一次关乎企业数字化未来的战略抉择。作为经历过三次SAP重大版本迁移的顾问ÿ…...
)
仅限首批200位开发者获取:ElevenLabs未公开的僧伽罗文Fine-tuning API沙箱权限+定制音色训练模板(含Kandy方言语料集)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs僧伽罗文语音合成的技术突破与本地化意义 ElevenLabs 在 2024 年首次将僧伽罗文(Sinhala)纳入其多语言语音合成支持矩阵,标志着南亚高复杂度音节文字系统在…...

骨传导耳机品牌Mojawa完成数千万元A+轮融资,发力AI运动智能平台
硬氪获悉,苏州索迩电子技术有限公司近日完成数千万元人民币的A轮融资,由正海资本领投。资金将用于拓展海外线下渠道和推进产品AI智能化研发。骨传导耳机市场增长显著在音频产品市场,骨传导耳机因无线和开耳式聆听技术需求增加而显著增长。202…...

矩阵中的“对角线强迫症”:如何优雅地判断Toeplitz矩阵?
举个栗子 🌰 例子1: 矩阵: [6, 7, 8] [4, 6, 7] [1, 4, 6]它的对角线分别是:[6,6,6], [7,7], [8], [4,4], [1],每条对角线上的数字都相同,所以它是Toeplitz矩阵 ✅ 例子2: 矩阵: …...