AI大模型开发原理篇-2:语言模型雏形之词袋模型
基本概念
词袋模型(Bag of Words,简称 BOW)是自然语言处理和信息检索等领域中一种简单而常用的文本表示方法,它将文本看作是一组单词的集合,并忽略文本中的语法、词序等信息,仅关注每个词的出现频率。

- 文本表示:词袋模型将每篇文本(如句子或文档)转换为一个固定长度的向量,其中每个元素表示词汇表中某个特定词在该文本中出现的次数。
- 忽略顺序:词袋模型不考虑词语出现的顺序,只关注哪些词出现以及每个词的频率。
比如下面这2句话:
- "沐雪喜欢吃葡萄"
- "葡萄是沐雪喜欢的水果"
词袋模型会将这两个句子表示成如下的向量。
{"沐雪": 1, "喜欢": 1, "吃": 1, "葡萄": 1}
{"葡萄": 1, "是": 1, "沐雪": 1, "喜欢": 1, "的": 1, "水果": 1}
通过比较这两个向量之间的相似度,我们就可以判断出它们之间关联性的强弱。
构建词袋模型的步骤
1、文本预处理
- 分词:将文本划分为独立的词(对于英文,通常是按空格和标点符号分词;对于中文,可能需要分词工具如jieba)。
- 去除停用词(可选):如“的”、“是”、“和”等无实际意义的高频词。
- 大小写标准化(可选):统一大小写,如将所有字母转换为小写。
- 去除标点符号(可选):去掉文本中的标点符号,以避免干扰。
2、构建词汇表
例如,假设我们有以下两个句子:
词汇表为:["我", "爱", "自然语言", "学习"]
- 词袋模型会构建一个文本数据集中的所有不同词汇组成的词汇表。这个词汇表的每个词都会成为向量的一个维度。
- “我 爱 自然语言”
- “我 学习 自然语言”
3、构建词频向量
例如,句子“我 爱 自然语言”在词汇表["我", "爱", "自然语言", "学习"]中出现的次数为:
因此,文本“我 爱 自然语言”可以表示为向量:[1, 1, 1, 0]。
对于第二个句子“我 学习 自然语言”,它在同样的词汇表中的表示为:
对应的词袋向量为:[1, 0, 1, 1]。
- 对每篇文本,统计词汇表中每个词在文本中出现的次数。文本中的每个词都会映射到一个数字,表示该词在该文本中的出现次数。
- "我":1次
- "爱":1次
- "自然语言":1次
- "学习":0次
- "我":1次
- "爱":0次
- "自然语言":1次
- "学习":1次
4、构建特征矩阵
假设有两个文档,分别为“我 爱 自然语言”和“我 学习 自然语言”,其特征矩阵为:
| 文档 | 我 | 爱 | 自然语言 | 学习 |
|---|---|---|---|---|
| 文档1 | 1 | 1 | 1 | 0 |
| 文档2 | 1 | 0 | 1 | 1 |
- 如果我们有多个句子或文档,最终的结果就是一个特征矩阵,其中每一行表示一个文档,每一列表示词汇表中的一个词。矩阵的元素表示词汇表中相应词在该文档中出现的次数。
5、计算余弦相似度
计算余弦相似度(Cosine Similarity),衡量两个文本向量的相似性。余弦相似度可用来衡量两个向量的相似程度。它的值在-1到1之间,值越接近1,表示两个向量越相似;值越接近-1,表示两个向量越不相似;当值接近0时,表示两个向量之间没有明显的相似性。在文本处理中,我们通常使用余弦相似度来衡量两个文本在语义上的相似程度。对于词袋表示的文本向量,使用余弦相似度计算文本之间的相似程度可以减少句子长度差异带来的影响。
补充:
余弦相似度和向量距离(Vector Distance)都可以衡量两个向量之间的相似性。余弦相似度关注向量之间的角度,而不是它们之间的距离,其取值范围在-1(完全相反)到1(完全相同)之间。向量距离关注向量之间的实际距离,通常使用欧几里得距离(Euclidean Distance)来计算。两个向量越接近,它们的距离越小。
如果要衡量两个向量的相似性,而不关心它们的大小,那么余弦相似度会更合适。因此,余弦相似度通常用于衡量文本、图像等高维数据的相似性,因为在这些场景下,关注向量的方向关系通常比关注距离更有意义。而在一些需要计算实际距离的应用场景,如聚类分析、推荐系统等,向量距离会更合适。

矩阵图中每个单元格表示两个句子之间的余弦相似度,颜色越深,句子在语义上越相似。例如,“这部电影真的是很好看的电影”和“电影院句子在语义上越相似。例如,“这部电影真的是很好看的电影”和“电影院的电影都很好看”交叉处的单元格颜色相对较深,说明它们具有较高的余弦相似度,这意味着它们在语义上较为相似。
词袋模型的优缺点
优点:
- 简单易懂:词袋模型非常直观,理解和实现都比较简单。
- 不依赖语法:能够处理没有语法结构的文本,适用于许多实际应用。
- 容易计算:由于不考虑词序列,可以直接进行计算,且非常适合机器学习中的特征提取。
缺点:
- 忽略词序:词袋模型无法捕捉到词语之间的顺序关系,因此不能处理像“我爱自然语言”和“自然语言我爱”这种顺序不同但含义相同的情况。
- 稀疏性:对于大型语料库,词汇表的大小会非常庞大,这可能导致特征矩阵非常稀疏,大量的零值会降低计算效率。
- 语义信息丢失:仅关注词频而忽略了语法和上下文信息,导致词袋模型在处理词义和上下文依赖时的能力较弱。
词袋模型的应用场景
- 文本分类:如垃圾邮件识别、情感分析、主题分类等。
- 信息检索:将文档表示为词袋模型,计算文档与查询的相似度。
- 推荐系统:利用文本特征进行推荐,例如根据用户的评论进行商品推荐。
One-Hot编码
One-Hot编码也可以看作一种特殊的词袋表示。在One-Hot编码中,每个词都对应一个只包含一个1,其他元素全为0的向量,1的位置与该词在词汇表中的索引对应。在单词独立成句的情况下,词袋表示就成了One-Hot编码。比如上面的语料库中,“我”这个单词如果独立成句,则该句子的词袋表示为[1, 0, 0, 0],这完全等价于“我”在当前词汇表中的One-Hot编码。
词袋模型与N-Gram模型的区别
N-Gram和Bag-of-Words是两种非常基础但是仍然十分常用的自然语言处理技术,它们都用于表示文本数据,但具有不同的特点和适用场景。
N-Gram是一种用于语言建模的技术,它用来估计文本中词序列的概率分布。N-Gram模型将文本看作一个由词序列构成的随机过程,根据已有的文本数据,计算出词序列出现的概率。因此,N-Gram主要用于语言建模、文本生成、语音识别等自然语言处理任务中。
(1)N-Gram是一种基于连续词序列的文本表示方法。它将文本分割成由连续的N
个词组成的片段,从而捕捉局部语序信息。
(2)N-Gram可以根据不同的N
值捕捉不同程度的上下文信息。例如,1-Gram(Unigram)仅关注单个词,而2-Gram(Bigram)关注相邻的两个词的组合,以此类推。
(3)随着N的增加,模型可能会遇到数据稀疏性问题,导致模型性能下降。
Bag-of-Words则是一种用于文本表示的技术,它将文本看作由单词构成的无序集合,通过统计单词在文本中出现的频次来表示文本。因此,Bag-of-Words主要用于文本分类、情感分析、信息检索等自然语言处理任务中。
(1)Bag-of-Words是基于词频将文本表示为一个向量,其中每个维度对应词汇表中的一个单词,其值为该单词在文本中出现的次数。
(2)Bag-of-Words忽略了文本中的词序信息,只关注词频。这使得词袋模型在某些任务中表现出色,如主题建模和文本分类,但在需要捕捉词序信息的任务中表现较差,如机器翻译和命名实体识别。
(3)Bag-of-Words可能会导致高维稀疏表示,因为文本向量的长度取决于词汇表的大小。为解决这个问题,可以使用降维技术,如主成分分析(Principal Component Analysis,PCA)或潜在语义分析(LatentSemantic Analysis,LSA)。
相关文章:
AI大模型开发原理篇-2:语言模型雏形之词袋模型
基本概念 词袋模型(Bag of Words,简称 BOW)是自然语言处理和信息检索等领域中一种简单而常用的文本表示方法,它将文本看作是一组单词的集合,并忽略文本中的语法、词序等信息,仅关注每个词的出现频率。 文本…...

基于微信小程序的实习记录系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

【LLM】DeepSeek-R1-Distill-Qwen-7B部署和open webui
note DeepSeek-R1-Distill-Qwen-7B 的测试效果很惊艳,CoT 过程可圈可点,25 年应该值得探索更多端侧的硬件机会。 文章目录 note一、下载 Ollama二、下载 Docker三、下载模型四、部署 open webui 一、下载 Ollama 访问 Ollama 的官方网站 https://ollam…...

【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query 返回基于匹配术语的顺序和接近度的文档。 intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。 这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤…...

DeepSeek技术深度解析:从不同技术角度的全面探讨
DeepSeek技术深度解析:从不同技术角度的全面探讨 引言 DeepSeek是一个集成了多种先进技术的平台,旨在通过深度学习和其他前沿技术来解决复杂的问题。本文将从算法、架构、数据处理以及应用等不同技术角度对DeepSeek进行详细分析。 一、算法层面 深度学…...

Docker 部署 Starrocks 教程
Docker 部署 Starrocks 教程 StarRocks 是一款高性能的分布式分析型数据库,主要用于 OLAP(在线分析处理)场景。它最初是由百度的开源团队开发的,旨在为大数据分析提供一个高效、低延迟的解决方案。StarRocks 支持实时数据分析&am…...

【LLM-agent】(task6)构建教程编写智能体
note 构建教程编写智能体 文章目录 note一、功能需求二、相关代码(1)定义生成教程的目录 Action 类(2)定义生成教程内容的 Action 类(3)定义教程编写智能体(4)交互式操作调用教程编…...

29.Word:公司本财年的年度报告【13】
目录 NO1.2.3.4 NO5.6.7 NO8.9.10 NO1.2.3.4 另存为F12:考生文件夹:Word.docx选中绿色标记的标题文本→样式对话框→单击右键→点击样式对话框→单击右键→修改→所有脚本→颜色/字体/名称→边框:0.5磅、黑色、单线条:点…...
)
14 2D矩形模块( rect.rs)
一、 rect.rs源码 // Copyright 2013 The Servo Project Developers. See the COPYRIGHT // file at the top-level directory of this distribution. // // Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or // http://www.apache.org/licenses/LICENS…...
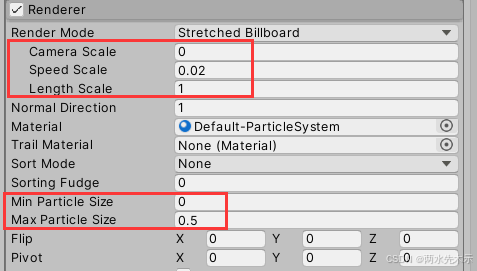
【Unity3D】实现2D角色/怪物死亡消散粒子效果
核心:这是一个Unity粒子系统自带的一种功能,可将粒子生成控制在一个Texture图片网格范围内,并且粒子颜色会自动采样图片的像素点颜色,之后则是粒子编辑出消散效果。 Particle System1物体(爆发式随机速度扩散10000个粒…...
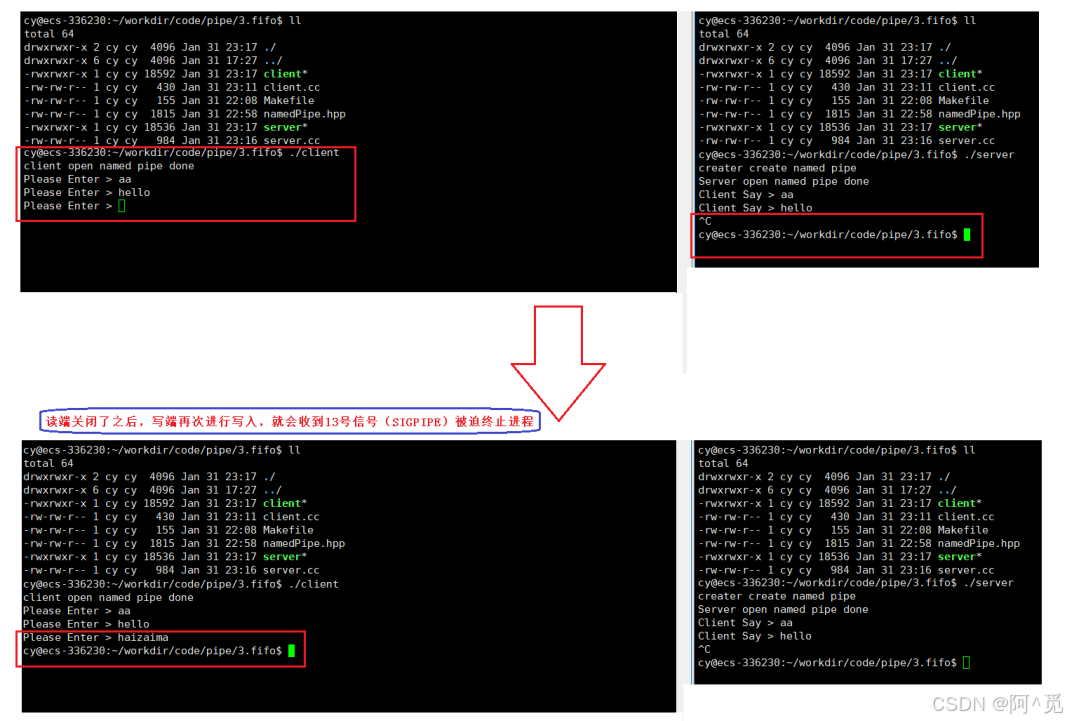
Linux - 进程间通信(3)
目录 3、解决遗留BUG -- 边关闭信道边回收进程 1)解决方案 2)两种方法相比较 4、命名管道 1)理解命名管道 2)创建命名管道 a. 命令行指令 b. 系统调用方法 3)代码实现命名管道 构建类进行封装命名管道&#…...
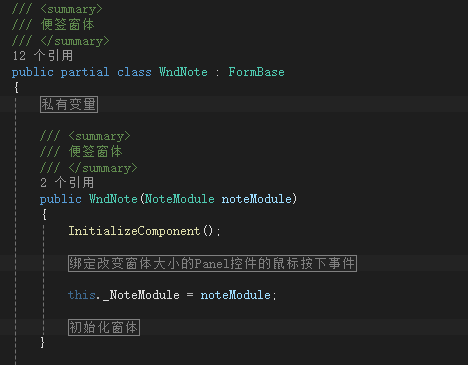
3、C#基于.net framework的应用开发实战编程 - 实现(三、三) - 编程手把手系列文章...
三、 实现; 三.三、编写应用程序; 此文主要是实现应用的主要编码工作。 1、 分层; 此例子主要分为UI、Helper、DAL等层。UI负责便签的界面显示;Helper主要是链接UI和数据库操作的中间层;DAL为对数据库的操…...
)
C++编程语言:抽象机制:泛型编程(Bjarne Stroustrup)
泛型编程(Generic Programming) 目录 24.1 引言(Introduction) 24.2 算法和(通用性的)提升(Algorithms and Lifting) 24.3 概念(此指模板参数的插件)(Concepts) 24.3.1 发现插件集(Discovering a Concept) 24.3.2 概念与约束(Concepts and Constraints) 24.4 具体化…...

Python面试宝典13 | Python 变量作用域,从入门到精通
今天,我们来深入探讨一下 Python 中一个非常重要的概念——变量作用域。理解变量作用域对于编写清晰、可维护、无 bug 的代码至关重要。 什么是变量作用域? 简单来说,变量作用域就是指一个变量在程序中可以被访问的范围。Python 中有四种作…...

基于最近邻数据进行分类
人工智能例子汇总:AI常见的算法和例子-CSDN博客 完整代码: import torch import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt# 生成一个简单的数据…...

DeepSeek V3 vs R1:大模型技术路径的“瑞士军刀“与“手术刀“进化
DeepSeek V3 vs R1:——大模型技术路径的"瑞士军刀"与"手术刀"进化 大模型分水岭:从通用智能到垂直突破 2023年,GPT-4 Turbo的发布标志着通用大模型进入性能瓶颈期。当模型参数量突破万亿级门槛后,研究者们开…...
一、TensorFlow的建模流程
1. 数据准备与预处理: 加载数据:使用内置数据集或自定义数据。 预处理:归一化、调整维度、数据增强。 划分数据集:训练集、验证集、测试集。 转换为Dataset对象:利用tf.data优化数据流水线。 import tensorflow a…...

指导初学者使用Anaconda运行GitHub上One - DM项目的步骤
以下是指导初学者使用Anaconda运行GitHub上One - DM项目的步骤: 1. 安装Anaconda 下载Anaconda: 让初学者访问Anaconda官网(https://www.anaconda.com/products/distribution),根据其操作系统(Windows、M…...

7层还是4层?网络模型又为什么要分层?
~犬📰余~ “我欲贱而贵,愚而智,贫而富,可乎? 曰:其唯学乎” 一、为什么要分层 \quad 网络通信的复杂性促使我们需要一种分层的方法来理解和管理网络。就像建筑一样,我们不会把所有功能都混在一起…...

C++:抽象类习题
题目内容: 求正方体、球、圆柱的表面积,抽象出一个公共的基类Container为抽象类,在其中定义一个公共的数据成员radius(此数据可以作为正方形的边长、球的半径、圆柱体底面圆半径),以及求表面积的纯虚函数area()。由此抽象类派生出…...

从YOLOv1到v5:一个算法工程师的实战避坑与版本选择指南
从YOLOv1到v5:算法工程师的版本选择与实战避坑指南 在计算机视觉领域,目标检测一直是工业界和学术界关注的焦点。作为实时检测领域的标杆算法,YOLO系列从2015年诞生至今已经迭代了五个主要版本。不同于学术论文中的理论比较,本文…...
:IPCF核间通信机制深度解析与应用)
S32G2汽车网关实战(四):IPCF核间通信机制深度解析与应用
1. IPCF核间通信机制基础解析 在S32G2这样的多核异构SoC中,不同处理器核心之间的高效通信是系统设计的关键。IPCF(Inter-Processor Communication Framework)作为恩智浦提供的核间通信解决方案,其核心思想是通过共享内存中断触发的…...

基于ARM核心板的工业无线示教器开发全流程解析
1. 项目概述:当工业机器人遇上“掌上大脑”在工业自动化领域,示教器是人与机器人交互的核心枢纽。传统的示教器,往往体积庞大、线缆缠绕、成本高昂,并且高度依赖特定的控制器硬件。作为一名长期混迹于工控和嵌入式开发一线的工程师…...

Fast-GitHub终极指南:如何将GitHub下载速度从KB/s提升到MB/s
Fast-GitHub终极指南:如何将GitHub下载速度从KB/s提升到MB/s 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾因…...
内核是如何发送事件到用户空间)
RK3568平台开发系列讲解(热拔插篇)内核是如何发送事件到用户空间
🚀返回专栏总目录 文章目录 一、相关接口函数 二、udevadm 命令 三、实验程序 四、运行效果 沉淀、分享、成长,让自己和他人都能有所收获!😄 一、相关接口函数 kobject_uevent 是 Linux 内核中的一个函数, 用于生成和发送 uevent 事件。 它是 udev 和其他设备管理工具与…...

百度网盘Mac版SVIP破解终极指南:解锁70倍下载速度的完整方案
百度网盘Mac版SVIP破解终极指南:解锁70倍下载速度的完整方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 百度网盘Mac版SVIP破解插件是一…...
那点事儿)
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿 激光技术正悄然渗透进我们生活的每个角落——从自动驾驶汽车的"眼睛"到智能门锁的指纹识别,从工业切割到医疗美容,这些看似毫不相关…...

从零到一:手把手带你完成DevEco Studio环境搭建与项目启动
1. 环境准备:从下载到安装的完整指南 第一次接触HarmonyOS开发的朋友们,你们好!我是老张,在智能硬件行业摸爬滚打十多年,今天要带大家搞定DevEco Studio这个开发利器。很多人刚开始都会被环境搭建劝退,其实…...

如何在Windows 11上完美运行经典游戏:DDrawCompat终极兼容性解决方案
如何在Windows 11上完美运行经典游戏:DDrawCompat终极兼容性解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mir…...

Redis分布式锁进阶第一二十五篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...