17 一个高并发的系统架构如何设计
高并发系统的理解
第一:我们设计高并发系统的前提是该系统要高可用,起码整体上的高可用。
第二:高并发系统需要面对很大的流量冲击,包括瞬时的流量和黑客攻击等
第三:高并发系统常见的需要考虑的问题,如内存不足的问题,服务抖动的问题、磁盘不足的问题、网络带宽的问题、突发流量的问题、面对黑客攻击的问题
高并发的架构设计
-
垂直拆分业务
一个大型的系统业务相对复杂,不同的业务需要面对的流量压力也不同。我们可以根据不同的业务垂直拆分业务(DDD),我们可以根据业务拆也可以根据机器的特性拆服务,这些就要看具体的业务和系统运营方向。
微服务拆分需要把一个单体的应用,按照一定的维度(业务域的维度、机器特性的维度等等)拆分成多个服务模块。
例如:电商系统拆分成用户系统、订单系统、商品系统。 -
数据的垂直和水平拆分+分库分表
网络请求的流量虽然可以通过缓存,mq的削峰等缓解压力,但最终数据部分的压力还是会压到数据库上。数据库的垂直拆分主要是根据我们上面的垂直拆分业务后,根据对应模块的业务做对应的数据库设计。
我们分库还有一个原则就是一个数据库实例操作数据的瓶颈受到数据库引擎程序执行的瓶颈影响,所以在高并发的环境下,做好了垂直拆分的数据库,如果一个数据库实例承载不了并发的情况下,我们也要做水平拆分,一般会根据主键hash求模或数值型主键求模做水平拆分。
分表的场景主要面对单表数据库过大的场景使用。
数据库的分库分表主要使用mycat(由于做的不是很完善,特别是跨库查询的问题用的人越来越少,sharding jdbc(目前主流的用法))。
-
数据库的读写分离、双主等
在高并发的场景中,我们单库能够承载1000左右的tps,如果并发太高对数据库的压力就会很大。不过我们的业务一般都是读多写少的场景,这个时候我们可以考虑数据库的一主多备的部署,读操作从备库中读取。
还有我们的系统后台管理,经常会有慢sql查询,这些可以单独拿出来备库做后管的操作。防止一些复杂查询造成数据库的整体性能的下降。
数据库的主从复制是通过binlog同步的,如果考虑到高可用也可以做双主HA的部署方式。这个要看具体的业务场景。 -
连接池
应用程序从存储中获取数据需要建立连接,我们需要使用连接池。例如:数据库连接池、redis连接池,线程池。
- 缓存
缓存是我们我们设计高并发系统常用的手段。缓存的使用主要是提升系统的整体访问性能。缓存的思想在其他的设计上也大量被使用,比如cpu的设计、操作系统、web应用、浏览器等等都大量使用到缓存。
设计高并发的系统常用的缓存有:redis缓存、JVM本地缓存(堆内存需要程序处理),nginx本地缓存、memcached、CDN静态资源的缓存等。
使用缓存需要注意以下几点的问题:
缓存与数据库数据一致性的问题(延迟双删)
缓存雪崩的问题(缓存大面积的失效,或者redis宕机等):设置redis的缓存有效时间的均匀分布、数据的预热(多应对突发事件,比如热点新闻),redis服务的高可用部署
缓存的击穿问题:一个redis的key失效后,大量请求的涌入到数据库,造成数据库的压力。设置热点数据的过期时间、定时更新策略,锁操作(如果请求拿不到Key先锁住,等数据放入缓存再释放锁)
缓存穿透问题:用户请求的数据缓存和数据库中都没有,但是请求依然不断的涌入,对数据库造成的压力。对于穿透问题,我们可以在业务层先校验,数据库中没有的数据设置在缓存中设置过期时间,该时间内不在请求到数据库
CDN静态资源缓存:将静态的资源放到位于多个物理位置的机房,用户访问静态资源的时候访问到就近的机器,加快了访问速度。
- 异步,mq削峰
我们的系统在做一些活动的时候,会产生一些瞬时的高峰流量,这些请求如果直接和数据库交互处理业务的时候会把数据库压垮。我们把请求发送到mq中通过异步处理的方式,减轻瞬时流量带来的冲击。当然mq还有分布式解耦等其他使用场景,这里不做细说。
- 熔断
熔断是保护系统稳定性的一种手段,在流量比较大的情况下,会出现部分服务的性能瓶颈造成整个服务不可用的情况。例如由于某一个慢sql降低了数据库的性能,其他请求积压过来,数据库的引擎程序处理不了造成数据库的假死。再造成整个服务不可用的情况。这个时候我们就需要采用熔断的手段,比如系统响应时间过慢后来的请求就会转发到错误页面。我们可以使用springcloud 的hystrix组件来做熔断
- 限流
由于我们的系统会有短暂的峰值请求流量进来,我们的CPU,内存,线程数据库在面临短暂的流量高峰无法应对的时候,需要做限流的设置。前面我们讲到一些分布式限流的算法。这里就不再详细叙述。
-
扩容
如果我们的产品随着营运力度的加大,用户不断的增长,原理部署了5台服务器已经满足不了业务的发展。所以在架构设计之初就要考虑到系统支持动态的扩容的功能。比如我们的sharding jdbc支持数据库的动态扩容,还要考虑生成id的策略,是否支持为了增加机器即可的架构方案,我们从单机房部署到多机房部署时是否能平滑扩容。编码能不能支持。特别注意一点就是我们的架构设计中的状态保持和水平扩展库之后原先的数据是否能正常读取的问题 -
海量数据的处理问题
面对大量的数据搜索一般使用elasticsearch,es本身就支持动态的扩容。大数据的存储一般用到hbase、clickhouse等。
相关文章:

17 一个高并发的系统架构如何设计
高并发系统的理解 第一:我们设计高并发系统的前提是该系统要高可用,起码整体上的高可用。 第二:高并发系统需要面对很大的流量冲击,包括瞬时的流量和黑客攻击等 第三:高并发系统常见的需要考虑的问题,如内存不足的问题,服务抖动的…...

Spring Boot 实例解析:配置文件
SpringBoot 的热部署: Spring 为开发者提供了一个名为 spring-boot-devtools 的模块来使用 SpringBoot 应用支持热部署,提高开发者的效率,无需手动重启 SpringBoot 应用引入依赖: <dependency> <groupId>org.springfr…...

pytorch图神经网络处理图结构数据
人工智能例子汇总:AI常见的算法和例子-CSDN博客 图神经网络(Graph Neural Networks,GNNs)是一类能够处理图结构数据的深度学习模型。图结构数据由节点(vertices)和边(edges)组成&a…...
)
计算机网络一点事(23)
传输层 端口作用:标识主机特定进程,TCP,UDP协议 端口号分类:服务器:0-1023,熟知 1024-49151 登记 客户端:49152-65535 功能:实现端到端,进程到进程的通信,…...

(9)下:学习与验证 linux 里的 epoll 对象里的 EPOLLIN、 EPOLLHUP 与 EPOLLRDHUP 的不同。小例子的实验
(4)本实验代码的蓝本,是伊圣雨老师里的课本里的代码,略加改动而来的。 以下是 服务器端的代码: 每当收到客户端的报文时,就测试一下对应的 epoll 事件里的事件标志,不读取报文内容,…...

DeepSeek-R1模型1.5b、7b、8b、14b、32b、70b和671b有啥区别?
deepseek-r1的1.5b、7b、8b、14b、32b、70b和671b有啥区别?码笔记mabiji.com分享:1.5B、7B、8B、14B、32B、70B是蒸馏后的小模型,671B是基础大模型,它们的区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本…...

一、html笔记
(一)前端概述 1、定义 前端是Web应用程序的前台部分,运行在PC端、移动端等浏览器上,展现给用户浏览的网页。通过HTML、CSS、JavaScript等技术实现,是用户能够直接看到和操作的界面部分。上网就是下载html文档,浏览器是一个解释器,运行从服务器下载的html文件,解析html、…...

AI大模型开发原理篇-2:语言模型雏形之词袋模型
基本概念 词袋模型(Bag of Words,简称 BOW)是自然语言处理和信息检索等领域中一种简单而常用的文本表示方法,它将文本看作是一组单词的集合,并忽略文本中的语法、词序等信息,仅关注每个词的出现频率。 文本…...

基于微信小程序的实习记录系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

【LLM】DeepSeek-R1-Distill-Qwen-7B部署和open webui
note DeepSeek-R1-Distill-Qwen-7B 的测试效果很惊艳,CoT 过程可圈可点,25 年应该值得探索更多端侧的硬件机会。 文章目录 note一、下载 Ollama二、下载 Docker三、下载模型四、部署 open webui 一、下载 Ollama 访问 Ollama 的官方网站 https://ollam…...

【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query 返回基于匹配术语的顺序和接近度的文档。 intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。 这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤…...

DeepSeek技术深度解析:从不同技术角度的全面探讨
DeepSeek技术深度解析:从不同技术角度的全面探讨 引言 DeepSeek是一个集成了多种先进技术的平台,旨在通过深度学习和其他前沿技术来解决复杂的问题。本文将从算法、架构、数据处理以及应用等不同技术角度对DeepSeek进行详细分析。 一、算法层面 深度学…...

Docker 部署 Starrocks 教程
Docker 部署 Starrocks 教程 StarRocks 是一款高性能的分布式分析型数据库,主要用于 OLAP(在线分析处理)场景。它最初是由百度的开源团队开发的,旨在为大数据分析提供一个高效、低延迟的解决方案。StarRocks 支持实时数据分析&am…...

【LLM-agent】(task6)构建教程编写智能体
note 构建教程编写智能体 文章目录 note一、功能需求二、相关代码(1)定义生成教程的目录 Action 类(2)定义生成教程内容的 Action 类(3)定义教程编写智能体(4)交互式操作调用教程编…...

29.Word:公司本财年的年度报告【13】
目录 NO1.2.3.4 NO5.6.7 NO8.9.10 NO1.2.3.4 另存为F12:考生文件夹:Word.docx选中绿色标记的标题文本→样式对话框→单击右键→点击样式对话框→单击右键→修改→所有脚本→颜色/字体/名称→边框:0.5磅、黑色、单线条:点…...
)
14 2D矩形模块( rect.rs)
一、 rect.rs源码 // Copyright 2013 The Servo Project Developers. See the COPYRIGHT // file at the top-level directory of this distribution. // // Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or // http://www.apache.org/licenses/LICENS…...
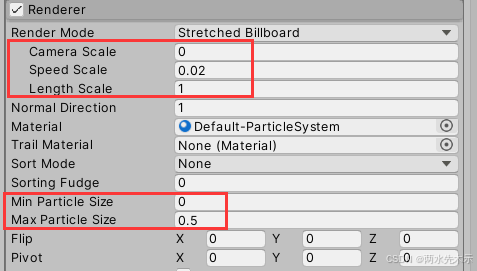
【Unity3D】实现2D角色/怪物死亡消散粒子效果
核心:这是一个Unity粒子系统自带的一种功能,可将粒子生成控制在一个Texture图片网格范围内,并且粒子颜色会自动采样图片的像素点颜色,之后则是粒子编辑出消散效果。 Particle System1物体(爆发式随机速度扩散10000个粒…...
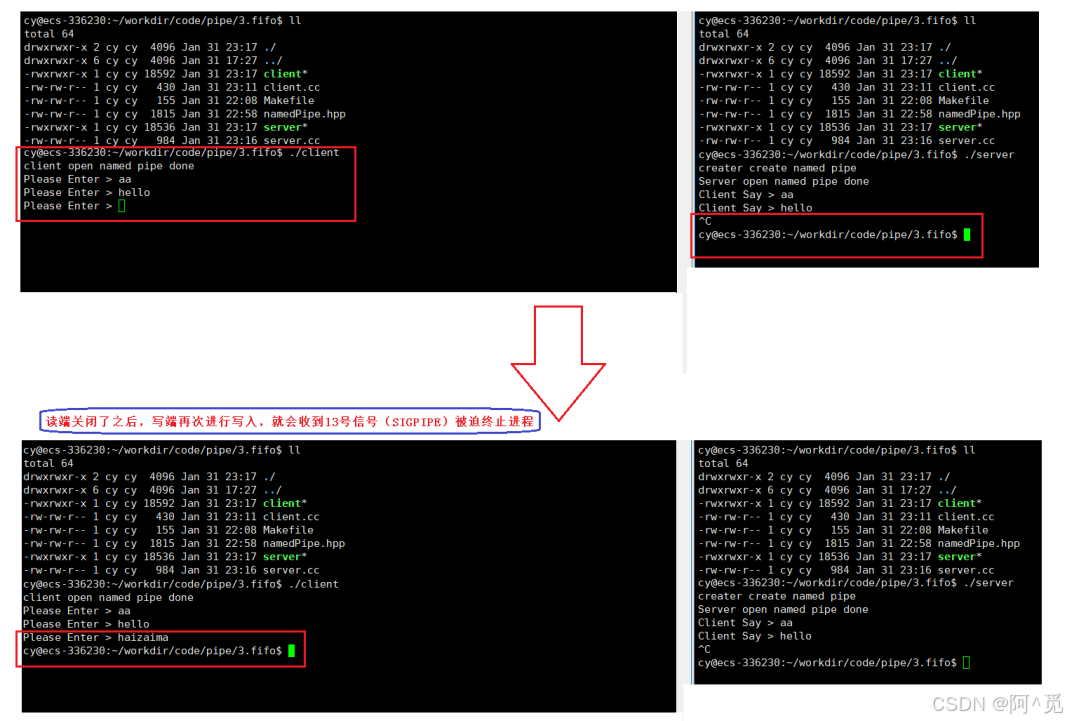
Linux - 进程间通信(3)
目录 3、解决遗留BUG -- 边关闭信道边回收进程 1)解决方案 2)两种方法相比较 4、命名管道 1)理解命名管道 2)创建命名管道 a. 命令行指令 b. 系统调用方法 3)代码实现命名管道 构建类进行封装命名管道&#…...
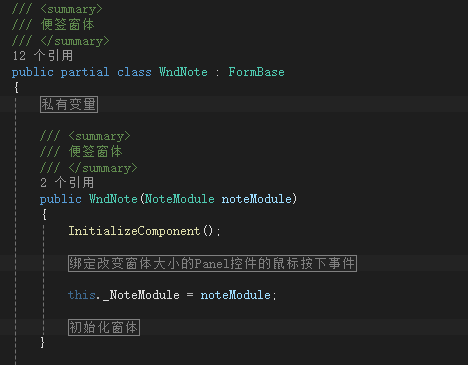
3、C#基于.net framework的应用开发实战编程 - 实现(三、三) - 编程手把手系列文章...
三、 实现; 三.三、编写应用程序; 此文主要是实现应用的主要编码工作。 1、 分层; 此例子主要分为UI、Helper、DAL等层。UI负责便签的界面显示;Helper主要是链接UI和数据库操作的中间层;DAL为对数据库的操…...
)
C++编程语言:抽象机制:泛型编程(Bjarne Stroustrup)
泛型编程(Generic Programming) 目录 24.1 引言(Introduction) 24.2 算法和(通用性的)提升(Algorithms and Lifting) 24.3 概念(此指模板参数的插件)(Concepts) 24.3.1 发现插件集(Discovering a Concept) 24.3.2 概念与约束(Concepts and Constraints) 24.4 具体化…...

通过curl命令直接测试Taotoken聊天补全接口的配置与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的配置与调用 在对接大模型服务时,有时我们希望在引入完整SDK之前ÿ…...

跨平台包管理新思路:paks项目如何统一软件安装体验
1. 项目概述:一个轻量级、跨平台的包管理新思路如果你和我一样,常年混迹在开发运维一线,肯定对“包管理”这件事又爱又恨。爱的是,它能让我们一键安装、更新、卸载软件,省去了手动编译、配置依赖的繁琐;恨的…...

监控与日志:Prometheus+Grafana实时追踪GPU、显存、推理延迟与错误率
系列导读 你现在看到的是《本地大模型私有化部署与优化:从入门到生产级实战》的第 8/10 篇,当前这篇会重点解决:让你的本地大模型服务像云服务一样可观测,提前发现并解决性能问题。 上一篇回顾:第 7 篇《量化部署终极指南:从GPTQ到AWQ,精度损失与显存节省的平衡艺术》…...

好用的昆明线上经营推广哪家好选
在数字化浪潮席卷的当下,昆明的企业和商家们越来越意识到线上经营推广的重要性。选择一家靠谱的线上经营推广公司,能够让企业在激烈的市场竞争中脱颖而出。那么,在昆明众多的推广公司中,哪家才是比较好的选择呢?今天&a…...

Taotoken用量看板如何帮助团队管理大模型API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队管理大模型API成本 作为团队的技术负责人,在引入大模型能力支持多个项目时,一…...

如何用Python自动化工具解放你的电商评价时间:3分钟完成30分钟任务
如何用Python自动化工具解放你的电商评价时间:3分钟完成30分钟任务 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 你知道吗?每次网购后写评价平均要花30分钟ÿ…...

RK3576开发板AIoT实战:从模型转换到边缘部署全流程解析
1. 项目概述:从一块开发板到AI应用落地的完整旅程 最近几年,AIoT(人工智能物联网)的概念越来越火,但很多开发者朋友拿到一块功能强大的开发板后,往往卡在“如何把AI模型真正跑起来”这一步。我手头这块RK35…...

QT新手避坑:一个QWidget只能有一个QLayout,别再重复setLayout了
QT布局管理核心机制:从QLayout父子关系到内存安全实践 在QT的GUI开发中,布局管理是最基础也最容易踩坑的领域之一。许多刚接触QT的开发者,往往会被看似简单的布局系统所迷惑,直到控制台不断输出"QLayout: Attempting to add …...

游戏后台记录器开发:从低开销捕获到硬件编码的工程实践
1. 项目概述:一个为游戏玩家设计的“后台记录器”如果你是一名资深游戏玩家,或者正在从事游戏相关的开发、测试、数据分析工作,那么你很可能遇到过这样的场景:在《艾尔登法环》里被某个Boss虐了上百次,却记不清每次失败…...

巧用邮件合并批量生成带条形码的证件标签
1. 为什么需要批量生成带条形码的证件标签? 在日常办公中,我们经常会遇到需要批量制作证件标签的情况。比如学校图书馆要给新生办理借书证,公司要给新员工制作工牌,或者社区要给居民发放会员卡。传统的手工制作方式不仅效率低下&…...