数据密码解锁之DeepSeek 和其他 AI 大模型对比的神秘面纱
本篇将揭露DeepSeek 和其他 AI 大模型差异所在。
目录
编辑
一·本篇背景:
二·性能对比:
2.1训练效率:
2.2推理速度:
三·语言理解与生成能力对比:
3.1语言理解:
3.2语言生成:
四·本篇小结:
一·本篇背景:
在当今人工智能飞速发展的时代,大模型如雨后春笋般不断涌现,它们在自然语言处理、图像识别、智能决策等众多领域发挥着至关重要的作用。
DeepSeek 作为其中一颗耀眼的新星,凭借其独特的技术优势和出色的性能表现吸引了广泛关注。然而,与其他传统的知名 AI 大模型相比,DeepSeek 究竟有何不同?其优势和劣势又体现在哪些方面?本文将通过详细的数据对比和代码示例,为你揭开 DeepSeek 与其他 AI 大模型对比的神秘面纱。
二·性能对比:
2.1训练效率:
训练效率是衡量一个 AI 大模型优劣的重要指标之一。它直接关系到模型的开发成本和迭代速度。我们以训练时间和计算资源消耗作为衡量训练效率的关键数据。
以某一特定规模的数据集和相同的硬件环境为例,传统的 AI 大模型如 GPT - 3 在进行一次完整的训练时,可能需要消耗数千个 GPU 小时的计算资源,训练时间长达数天甚至数周。而 DeepSeek 通过采用创新的训练算法和优化的架构设计,能够在相同数据集和硬件条件下,将训练时间缩短至原来的一半左右,计算资源消耗也大幅降低。下面是一个简单的 C++ 代码示例,模拟训练时间和资源消耗的计算:
#include <iostream>// 定义一个函数来计算训练成本,这里简单用时间和资源消耗的乘积表示
double calculateTrainingCost(double trainingTime, double resourceConsumption) {return trainingTime * resourceConsumption;
}int main() {// GPT - 3的训练时间(小时)和资源消耗(GPU数量)double gpt3TrainingTime = 240; double gpt3ResourceConsumption = 1000;// DeepSeek的训练时间(小时)和资源消耗(GPU数量)double deepSeekTrainingTime = 120; double deepSeekResourceConsumption = 500;double gpt3Cost = calculateTrainingCost(gpt3TrainingTime, gpt3ResourceConsumption);double deepSeekCost = calculateTrainingCost(deepSeekTrainingTime, deepSeekResourceConsumption);std::cout << "GPT - 3的训练成本: " << gpt3Cost << std::endl;std::cout << "DeepSeek的训练成本: " << deepSeekCost << std::endl;return 0;
}
从上述代码的运行结果可以看出,DeepSeek 在训练成本上具有明显的优势,这使得它在大规模数据训练和快速模型迭代方面更具竞争力。
2.2推理速度:
推理速度决定了模型在实际应用中的响应能力。在实时交互场景中,如智能客服、语音助手等,快速的推理速度能够提供更加流畅的用户体验。
我们通过对相同输入数据进行多次推理测试,记录每个模型的平均推理时间。测试结果显示,在处理复杂的自然语言文本时,传统大模型可能需要数百毫秒甚至更长时间才能给出推理结果,而 DeepSeek 凭借其优化的推理算法和高效的内存管理机制,能够将平均推理时间缩短至数十毫秒。下面是一个简单的 C++ 代码示例,模拟推理时间的测试:
#include <iostream>
#include <chrono>
#include <thread>// 模拟一个大模型的推理函数
void modelInference() {// 模拟推理所需的时间std::this_thread::sleep_for(std::chrono::milliseconds(200));
}// 模拟DeepSeek的推理函数,速度更快
void deepSeekInference() {std::this_thread::sleep_for(std::chrono::milliseconds(50));
}int main() {auto start = std::chrono::high_resolution_clock::now();modelInference();auto end = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();std::cout << "传统大模型的推理时间: " << duration << " 毫秒" << std::endl;start = std::chrono::high_resolution_clock::now();deepSeekInference();end = std::chrono::high_resolution_clock::now();duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();std::cout << "DeepSeek的推理时间: " << duration << " 毫秒" << std::endl;return 0;
}
从代码模拟的结果可以直观地看到,DeepSeek 在推理速度上远远超过传统大模型,这使得它在实时性要求较高的应用场景中具有更大的优势。
三·语言理解与生成能力对比:
3.1语言理解:
语言理解能力是衡量 AI 大模型的核心指标之一,它体现在对自然语言文本的准确理解和分析上。
我们通过一系列的语言理解测试任务,如文本分类、情感分析、语义理解等,对 DeepSeek 和其他 AI 大模型进行评估。
在文本分类任务中,我们使用一个包含多种主题的文本数据集进行测试。传统大模型在分类准确率上可能达到 80% 左右,而 DeepSeek 通过引入更多的领域知识和改进的语义表示方法,能够将分类准确率提高到 85% 以上。下面是一个简单的 C++ 代码示例,模拟文本分类的过程:
#include <iostream>
#include <vector>// 模拟文本分类函数
int textClassification(const std::string& text, const std::vector<std::string>& categories) {// 这里简单随机返回一个分类结果,实际应用中需要更复杂的算法return rand() % categories.size();
}// 模拟DeepSeek的文本分类函数,准确率更高
int deepSeekTextClassification(const std::string& text, const std::vector<std::string>& categories) {// 假设DeepSeek有更高的准确率,这里简单调整返回结果if (rand() % 10 < 8) { return 0; }return rand() % categories.size();
}int main() {std::vector<std::string> categories = {"科技", "娱乐", "体育"};std::string testText = "这是一篇关于科技的文章";int traditionalResult = textClassification(testText, categories);int deepSeekResult = deepSeekTextClassification(testText, categories);std::cout << "传统大模型的分类结果: " << categories[traditionalResult] << std::endl;std::cout << "DeepSeek的分类结果: " << categories[deepSeekResult] << std::endl;return 0;
}
3.2语言生成:
语言生成能力体现在模型生成自然、连贯、有逻辑的文本能力上。
我们通过生成故事、诗歌、新闻报道等不同类型的文本,对模型进行评估。
传统大模型生成的文本可能存在逻辑不连贯、语言表达生硬等问题,而 DeepSeek 通过优化的生成算法和大量的高质量训练数据,能够生成更加自然流畅、富有创意的文本。下面是一个简单的 C++ 代码示例,模拟文本生成的过程:
#include <iostream>
#include <string>// 模拟传统大模型的文本生成函数
std::string traditionalTextGeneration() {return "这是一段传统大模型生成的文本,可能不够流畅。";
}// 模拟DeepSeek的文本生成函数
std::string deepSeekTextGeneration() {return "DeepSeek生成了一段自然流畅且富有逻辑的文本,仿佛是人类创作的一般。";
}int main() {std::string traditionalText = traditionalTextGeneration();std::string deepSeekText = deepSeekTextGeneration();std::cout << "传统大模型生成的文本: " << traditionalText << std::endl;std::cout << "DeepSeek生成的文本: " << deepSeekText << std::endl;return 0;
}
四·本篇小结:
通过以上多方面的数据对比和代码示例可以看出,DeepSeek 在训练效率、推理速度、语言理解与生成能力等方面都展现出了明显的优势。然而,我们也应该认识到,每个模型都有其适用的场景和局限性。在实际应用中,我们需要根据具体的需求和场景,综合考虑各种因素,选择最适合的 AI 大模型。随着技术的不断发展和创新,相信 DeepSeek 和其他 AI 大模型都将不断进化和完善,为人工智能领域带来更多的惊喜和突破。
相关文章:

数据密码解锁之DeepSeek 和其他 AI 大模型对比的神秘面纱
本篇将揭露DeepSeek 和其他 AI 大模型差异所在。 目录 编辑 一本篇背景: 二性能对比: 2.1训练效率: 2.2推理速度: 三语言理解与生成能力对比: 3.1语言理解: 3.2语言生成: 四本篇小结…...

python算法和数据结构刷题[5]:动态规划
动态规划(Dynamic Programming, DP)是一种算法思想,用于解决具有最优子结构的问题。它通过将大问题分解为小问题,并找到这些小问题的最优解,从而得到整个问题的最优解。动态规划与分治法相似,但区别在于动态…...

Ollama+OpenWebUI部署本地大模型
OllamaOpenWebUI部署本地大模型 前言 Ollama是一个强大且易于使用的本地大模型推理框架,它专注于简化和优化大型语言模型(LLMs)在本地环境中的部署、管理和推理工作流。可以将Ollama理解为一个大模型推理框架的后端服务。 Ollama Ollama安…...
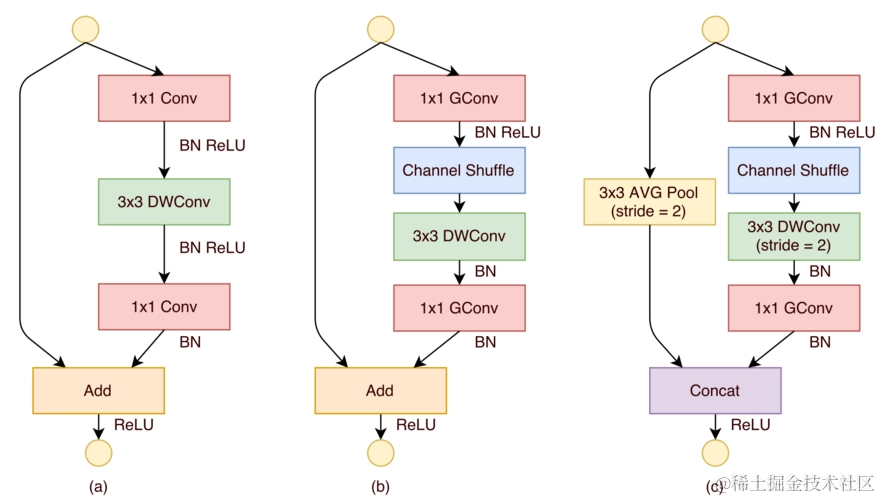
Python从0到100(八十六):神经网络-ShuffleNet通道混合轻量级网络的深入介绍
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Pyth…...

【网络】传输层协议TCP(重点)
文章目录 1. TCP协议段格式2. 详解TCP2.1 4位首部长度2.2 32位序号与32位确认序号(确认应答机制)2.3 超时重传机制2.4 连接管理机制(3次握手、4次挥手 3个标志位)2.5 16位窗口大小(流量控制)2.6 滑动窗口2.7 3个标志位 16位紧急…...

海思ISP开发说明
1、概述 ISP(Image Signal Processor)图像信号处理器是专门用于处理图像信号的硬件或处理单元,广泛应用于图像传感器(如 CMOS 或 CCD 传感器)与显示设备之间的信号转换过程中。ISP通过一系列数字图像处理算法完成对数字…...

实验十 Servlet(一)
实验十 Servlet(一) 【实验目的】 1.了解Servlet运行原理 2.掌握Servlet实现方式 【实验内容】 1、参考课堂例子,客户端通过login.jsp发出登录请求,请求提交到loginServlet处理。如果用户名和密码相同则视为登录成功,…...

doris:聚合模型的导入更新
这篇文档主要介绍 Doris 聚合模型上基于导入的更新。 整行更新 使用 Doris 支持的 Stream Load,Broker Load,Routine Load,Insert Into 等导入方式,往聚合模型(Agg 模型)中进行数据导入时,都…...

Java NIO_非阻塞I/O的实现与优化
1. 引言 1.1 背景介绍 随着互联网应用的快速发展,传统的阻塞I/O模型已经无法满足高并发、高性能的需求。Java NIO(Non-blocking I/O)提供了高效的非阻塞I/O操作,使得开发者能够构建高性能的网络应用和文件处理系统。 1.2 Java NIO的重要性 Java NIO通过非阻塞I/O和多路…...

代码随想录算法训练营Day51 | 101.孤岛的总面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
文章目录 101.孤岛的总面积思路与重点 102.沉没孤岛思路与重点 103.水流问题思路与重点 104.建造最大岛屿思路与重点 101.孤岛的总面积 题目链接:101.孤岛的总面积讲解链接:代码随想录状态:直接看题解了。 思路与重点 nextx或者nexty越界了…...
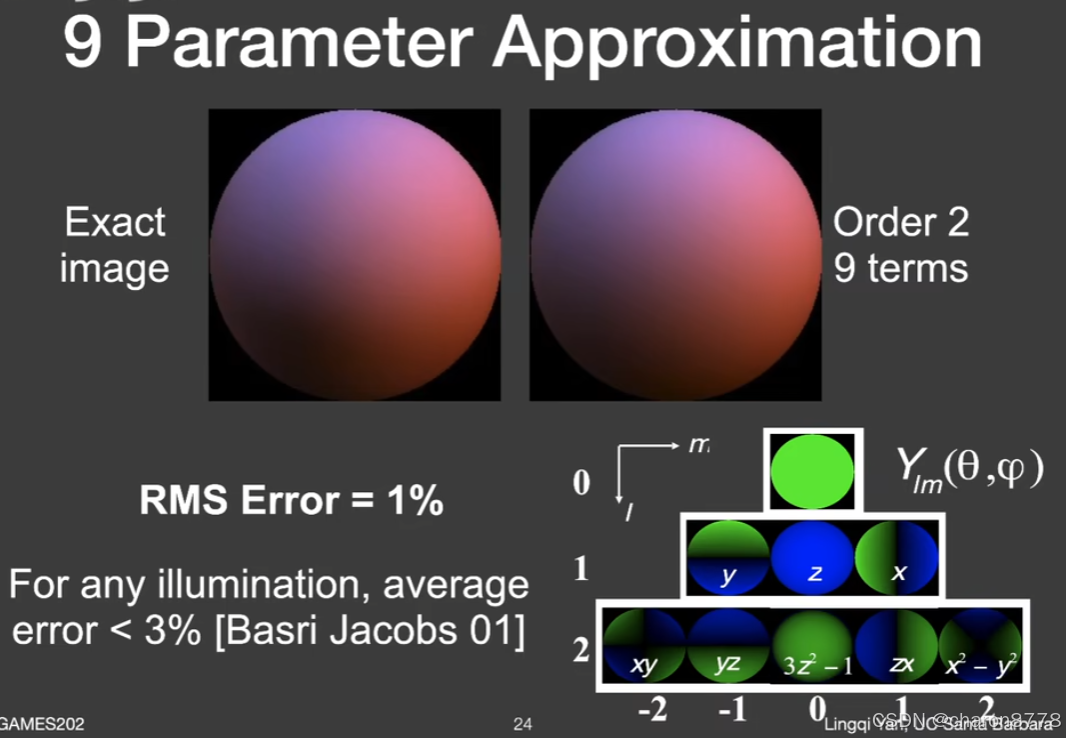
Games202Lecture 6 Real-time Environment Mapping
RTRT RTRT(real time ray tracing): path tracingdenoising PRT PRT (Precomputed radiance transfer):离线预计算,运行时快速内积。 预计算(Offline Precomputation): 传输函数(Transfer Function&…...

在 Zemax 中使用布尔对象创建光学光圈
在 Zemax 中,布尔对象用于通过组合或减去较简单的几何形状来创建复杂形状。布尔运算涉及使用集合运算(如并集、交集和减集)来组合或修改对象的几何形状。这允许用户在其设计中为光学元件或机械部件创建更复杂和定制的形状。 本视频中…...
)
MySQL知识点总结(十八)
说明你对InnoDB集群的整体认知。 MySQL组复制技术是InnoDB集群实现的基础,组复制安装在集群中的每个服务器实例上。组复制能够创建弹性复制拓扑,在集群中的服务器脱机时可以自动重新配置自己。必须至少有三台服务器才能组成一个可以提供高可用性的组。组…...

[论文总结] 深度学习在农业领域应用论文笔记14
当下,深度学习在农业领域的研究热度持续攀升,相关论文发表量呈现出迅猛增长的态势。但繁荣背后,质量却不尽人意。相当一部分论文内容空洞无物,缺乏能够落地转化的实际价值,“凑数” 的痕迹十分明显。在农业信息化领域的…...

MySQL和Redis的区别
MySQL和Redis都是流行的数据存储解决方案,但它们在设计、用途和特性上有显著区别。理解这些区别有助于选择合适的数据库来满足不同的应用需求。本文将详细介绍MySQL和Redis的区别,包括它们的架构、使用场景、性能和其他关键特性。 一、基本概述 MySQL&…...

Rust 中的注释使用指南
Rust 中的注释使用指南 注释是代码中不可或缺的一部分,它帮助开发者理解代码的逻辑和意图。Rust 提供了多种注释方式,包括行注释、块注释和文档注释。本文将详细介绍这些注释的使用方法,并通过一个示例展示如何在实际代码中应用注释。 1. 行…...
)
2025年2月2日(tcp3次握手4次挥手)
TCP(三次握手和四次挥手)是建立和关闭网络连接的标准过程,确保数据在传输过程中可靠无误。下面是详细解释: 1. 三次握手(TCP连接建立过程) 三次握手是为了在客户端和服务器之间建立一个可靠的连接&#x…...

一文了解制造业中的QC是什么
制造业中的QC QC :Quality Control,品质控制,产品的质量检验,发现质量问题后的分析、改善和不合格品控制相关人员的总称。中文意思是品质控制、质量检验。为达到品质要求所采取的作业技术和活动。有些推行ISO9000的组织会设置这样…...

【NEXT】网络编程——上传文件(不限于jpg/png/pdf/txt/doc等),或请求参数值是file类型时,调用在线服务接口
最近在使用华为AI平台ModelArts训练自己的图像识别模型,并部署了在线服务接口。供给客户端(如:鸿蒙APP/元服务)调用。 import核心能力: import { http } from kit.NetworkKit; import { fileIo } from kit.CoreFileK…...

在CentOS服务器上部署DeepSeek R1
在CentOS服务器上部署DeepSeek R1,并通过公网IP与其进行对话,可以按照以下步骤操作: 一、环境准备 系统要求: CentOS 8+(需支持AVX512指令集)。 硬件配置: GPU版本:NVIDIA驱动520+,CUDA 11.8+。 CPU版本:至少16核处理器,64GB内存。 存储空间:原始模型需要30GB,量…...

【AI知识点】交叉注意力机制:连接不同世界的“信息桥梁”
1. 从"信息桥梁"理解交叉注意力机制 想象你正在同时阅读一本英文书和它的中文翻译版。当你遇到一个不太理解的英文句子时,会自然地在中文版本中寻找对应的段落来帮助理解——这个过程就像交叉注意力机制在神经网络中的工作方式。它就像是架设在两个不同世…...

Windows右键菜单效率革命:ContextMenuManager极简操作与深度定制指南
Windows右键菜单效率革命:ContextMenuManager极简操作与深度定制指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 每天面对电脑上杂乱的右键菜单&…...

DanKoe 视频笔记:每日60分钟改变生活:引言与概述
在本教程中,我们将学习如何通过每天投入60分钟来系统地改变生活。我们将探讨常规的重要性,并介绍三个核心习惯,帮助你重新掌控精力、提升财务状况、改善健康以及获得内心的清晰。 每日60分钟改变生活:2:常规的必要性 …...

别再死记硬背了!用这5个真实运维脚本,搞定90%的Shell面试题
5个实战Shell脚本:从面试题到真实运维场景的蜕变 在技术面试中,Shell脚本能力往往是区分普通候选人和优秀候选人的关键指标。但死记硬背面试题答案的时代已经过去,现代企业更看重候选人解决实际问题的能力。本文将带你通过5个真实运维场景中的…...

Windows 11系统优化新方案:Win11Debloat工具全方位性能提升指南
Windows 11系统优化新方案:Win11Debloat工具全方位性能提升指南 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改…...

韦东山T113工业板+7寸RGB屏保姆级调试笔记:从设备树修改到触摸背光全搞定
T113工业板7寸RGB屏实战调试指南:从设备树到触摸背光的全链路避坑 拿到韦东山T113工业板和配套7寸RGB电容屏的那一刻,很多开发者会迫不及待地开始调试,但很快就会发现事情没那么简单——屏幕不亮、触摸失灵、背光异常等问题接踵而至。本文将带…...

@rc-component/slider拖拽轨道功能解析:提升用户体验的5个技巧
rc-component/slider拖拽轨道功能解析:提升用户体验的5个技巧 【免费下载链接】slider React Slider 项目地址: https://gitcode.com/gh_mirrors/sl/slider rc-component/slider是一款功能强大的React滑块组件,其拖拽轨道功能为用户提供了直观便捷…...
)
逆向思维:用VSCode Remote+X11转发打造无缝远程Python开发环境(避坑指南)
逆向工程:VSCode Remote与X11转发的深度整合实践 远程开发环境中GUI应用的调试一直是工程师们的痛点。想象一下这样的场景:你在本地用VSCode愉快地编写着Python数据分析脚本,所有代码都在云端服务器运行,突然需要可视化一个Matpl…...

2026年3月房产中介房源管理系统使用体验评测
在房产中介行业数字化转型的浪潮中,一款合适的房产中介房源管理系统能帮助经纪人高效处理房客源、规范业务流程、降低运营成本,甚至直接提升成交率。本文基于一线实操体验,对4款主流房产中介房源管理软件进行客观评测,包括全房源系…...

check-dev-env - 开发环境依赖检测技能
check-dev-env - 开发环境依赖检测技能 技能概述 check-dev-env 是一个用于自动检查开发环境中常见依赖项是否已安装的 AI Agent 技能。该技能能够快速验证 Java、Maven、Node.js、NPM、Go、Python、Git 等主流开发工具的安装状态和版本号。 📋 元信息 项目说明技…...