Spring Boot项目如何使用MyBatis实现分页查询
写在前面:大家好!我是
晴空๓。如果博客中有不足或者的错误的地方欢迎在评论区或者私信我指正,感谢大家的不吝赐教。我的唯一博客更新地址是:https://ac-fun.blog.csdn.net/。非常感谢大家的支持。一起加油,冲鸭!
用知识改变命运,用知识成就未来!加油 (ง •̀o•́)ง (ง •̀o•́)ง
文章目录
- 为什么需要分页查询
- 减少数据库压力
- 减少网络传输数据量
- 提高系统的稳定性
- 提升用户体验
- 原始的实现方式
- 计算偏移量
- 在Mapper接口中定义查询方法
- 编写SQL语句
- 开发流程及完整代码
- Controller层
- Service实现类
- Mapper接口方法
- xml文件SQL
- 使用插件实现
- 引入分页插件依赖
- Service实现类
- xml文件SQL
- 与原始分页的不同
为什么需要分页查询
分页查询是一种常见的数据库查询技术,用于将查询结果分成多个页面展示,而不是一次性返回所有数据。使用分页查询主要是为了减少数据库压力、减少网络传输数据量、提高系统的稳定性、提高客户体验。
减少数据库压力
一次性查询全部数据(例如百万条记录)会占用大量的资源(CPU、内存、I/O),导致响应变慢甚至系统崩溃。分页后,每次仅查询少量数据(如每页100条),可以显著降低负载。

减少网络传输数据量
分页查询每次只传输当前页的数据,相比于全表查询会极大的减少网络传输的数据量,降低网络带宽的占用。
提高系统的稳定性
后端服务处理分页查询时,单次处理的数据量可控,避免因一次性加载大数据导致内存耗尽出现 OOM 问题。对于前端也由于无需一次性渲染大量的数据而减少了内存崩溃的风险。
提升用户体验
分页查询由于单次查询的数据量少,后端与前端可以快速的处理相关的数据。用户无需进行长时间的等待,极大的提高了客户的体验。
原始的实现方式
如果不使用分页查询相关的插件需要我们自己计算分页查询的偏移量offset,还需要手动查询结果集以及数据总条数,并且在相关的 Mapper.xml 中定义分页查询的 SQL 语句。主要实现步骤如下:
计算偏移量
手动分页查询需要我们通过在 SQL 语句中添加分页相关的语法来实现,例如在 MySQL 中的语法:
SELECT * FROM users LIMIT #{pageSize} offset #{offset};
其中,#{offset} 表示偏移量,但是前端的分页查询请求中一般只有查询第几页 page 和每页的大小 pageSize。需要我们先计算一下偏移量是多少。
需要注意前端传的 page 是从 0 开始的还是从 1 开始的。
- 从 0 开始则 offset = page * pageSize
- 从 1 开始则 offset = (page - 1) * pageSize
在Mapper接口中定义查询方法
/*** 分页查询结果集* @param page* @param offset* @param name* @param categoryId* @param status* @return*/
List<DishVO> pageQuery(int page, int offset, String name, Integer categoryId, Integer status);/*** 查询总条数* @return*/
int getTotalSize();
编写SQL语句
<mapper namespace="com.sky.mapper.DishMapper"><insert id="insert" useGeneratedKeys="true" keyProperty="id">insert into dish (name, category_id, price, image, description, status, create_time, update_time, create_user, update_user)values (#{name}, #{categoryId}, #{price}, #{image}, #{description},#{status}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser})</insert><select id="pageQuery" resultType="com.sky.vo.DishVO">select d.*, c.name as categoryName from dish d left outer join category c on d.category_id = c.id<where><if test="name != null">and d.name like concat('%', #{name}, '%')</if><if test="categoryId != null">and d.category_id = #{categoryId}</if><if test="status != null">and d.status = #{status}</if></where>order by d.create_time desclimit #{page}offset #{offset}</select><select id="getTotalSize" resultType="java.lang.Integer">select count(*) from dish;</select>
</mapper>
开发流程及完整代码
在开发过程中 由外而内 进行开发效率会更高一些,我们一般不需要先写 Mapper.xml 中的 SQL语句,再定义Mapper接口中的方法,然后再通过 Service类 中进行调用。
一般会从 Service类 开始写起,然后再通过编辑器的快捷方式帮助我们生成相关的代码,再一层一层的实现。
Controller层
@GetMapping("/page")
@ApiOperation("菜品分页查询")
public Result<PageResult> pageQuery(DishPageQueryDTO dishPageQueryDTO) {log.info("菜品分页查询开始[{}]", dishPageQueryDTO);return dishService.pageQuery(dishPageQueryDTO);
}
Service实现类
@Override
public Result<PageResult> pageQuery(DishPageQueryDTO dishPageQueryDTO) {// 计算偏移量int offset = (dishPageQueryDTO.getPage() - 1) * dishPageQueryDTO.getPageSize();// 查询当前页的数据List<DishVO> dishVOList = dishMapper.pageQuery(dishPageQueryDTO.getPageSize(), offset, dishPageQueryDTO.getName(),dishPageQueryDTO.getCategoryId(), dishPageQueryDTO.getStatus());// 查询数据库中的总条数int total = dishMapper.getTotalSize();PageResult pageResult = new PageResult();pageResult.setTotal(total);pageResult.setRecords(dishVOList);log.info("分页查询结果为[{}]", pageResult);return Result.success(pageResult);
}
Mapper接口方法
/*** 分页查询结果集* @param page* @param offset* @param name* @param categoryId* @param status* @return*/
List<DishVO> pageQuery(int page, int offset, String name, Integer categoryId, Integer status);/*** 查询总条数* @return*/
int getTotalSize();
xml文件SQL
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.DishMapper"><insert id="insert" useGeneratedKeys="true" keyProperty="id">insert into dish (name, category_id, price, image, description, status, create_time, update_time, create_user, update_user)values (#{name}, #{categoryId}, #{price}, #{image}, #{description},#{status}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser})</insert><select id="pageQuery" resultType="com.sky.vo.DishVO">select d.*, c.name as categoryName from dish d left outer join category c on d.category_id = c.id<where><if test="name != null">and d.name like concat('%', #{name}, '%')</if><if test="categoryId != null">and d.category_id = #{categoryId}</if><if test="status != null">and d.status = #{status}</if></where>order by d.create_time desclimit #{page}offset #{offset}</select><select id="getTotalSize" resultType="java.lang.Integer">select count(*) from dish;</select>
</mapper>使用插件实现
使用分页插件可以极大的简化分页查询实现。虽然实现的主要原理还是通过原始实现方式中提到的逻辑,但是通过分页插件我们就可以少写很多代码而且一般分页插件(例如 PageHelper) 会通过动态 SQL 的构建和优化,能够有效避免传统分页方法的性能问题。
使用插件进行分页查询只需要修改一下上述原始实现方式的Service类 及 xml 文件中的 SQL 语句即可。
引入分页插件依赖
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>
Service实现类
@Override
public Result<PageResult> pageQuery(DishPageQueryDTO dishPageQueryDTO) {PageHelper.startPage(dishPageQueryDTO.getPage(), dishPageQueryDTO.getPageSize());Page<DishVO> page = dishMapper.pageHelperQuery(dishPageQueryDTO);PageResult pageResult = new PageResult();pageResult.setTotal(page.getTotal());pageResult.setRecords(page.getResult());log.info("分页查询结果为[{}]", pageResult);return Result.success(pageResult);}
xml文件SQL
<select id="pageHelperQuery" resultType="com.sky.vo.DishVO">select d.*, c.name as categoryName from dish d left outer join category c on d.category_id = c.id<where><if test="name != null">and d.name like concat('%', #{name}, '%')</if><if test="categoryId != null">and d.category_id = #{categoryId}</if><if test="status != null">and d.status = #{status}</if></where>order by d.create_time desc
</select>
与原始分页的不同
使用分页插件进行分页不需要手动计算分页查询的偏移量,在写SQL语句时也不需要显式地使用 LIMIT 和 OFFSET 来实现分页。而且分页插件也会直接将查询的结果集和总条数封装到 Page对象 中,不需要我们手动的查询结果集和总条数。
- mysql开启缓存、设置缓存大小、缓存过期机制
- PageHelper分页插件最新源码解读及使用
- 苍穹外卖
相关文章:
Spring Boot项目如何使用MyBatis实现分页查询
写在前面:大家好!我是晴空๓。如果博客中有不足或者的错误的地方欢迎在评论区或者私信我指正,感谢大家的不吝赐教。我的唯一博客更新地址是:https://ac-fun.blog.csdn.net/。非常感谢大家的支持。一起加油,冲鸭&#x…...

飞行汽车中的无刷外转子电机、人形机器人中的无框力矩电机技术解析与应用
重点:无刷外转子电机与无框力矩电机:技术解析与应用对比 在现代工业自动化和精密机械领域,无刷电机因其高效、低噪音和高可靠性而备受青睐。其中,无刷外转子电机和无框力矩电机更是以其独特的结构和性能特点,成为众多应用场景中的…...

FreeRTOS学习 --- 队列集
队列集简介 一个队列只允许任务间传递的消息为同一种数据类型,如果需要在任务间传递不同数据类型的消息时,那么就可以使用队列集 ! 作用:用于对多个队列或信号量进行“监听”,其中不管哪一个消息到来,都可让…...

【R语言】R语言安装包的相关操作
一、管理R语言安装包 1、安装R包 install.packages() 2、查看已安装的R包 installed.packages() 3、更新R包 update.packages() 4、卸载R包 remove.packages() 二、加载R语言安装包 打开R语言时,基础包(base包)会自动被加载到内存中…...

15.[前端开发]Day15-HTML+CSS阶段练习(网易云音乐四)
完整代码 01_网易云-header <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"wid…...

【基于SprintBoot+Mybatis+Mysql】电脑商城项目之用户登录
🧸安清h:个人主页 🎥个人专栏:【Spring篇】【计算机网络】【Mybatis篇】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 目录 🎯1.登录-持久层 &…...

测试方案和测试计划相同点和不同点
在软件测试领域,测试方案与测试计划皆为举足轻重的关键文档,尽管它们有着紧密的关联,但在目的与内容层面存在着显著的差异。相同点: 1.共同目标:测试方案和测试计划的核心目标高度一致,均致力于保障软件的…...

c++提取矩形区域图像的梯度并拟合直线
c提取旋转矩形区域的边缘最强梯度点,并拟合直线 #include <opencv2/opencv.hpp> #include <iostream> #include <vector>using namespace cv; using namespace std;int main() {// 加载图像Mat img imread("image.jpg", IMREAD_GRAYS…...

Unity Shader Graph 2D - 角色身体电流覆盖效果
在游戏中,通常会有游戏角色受到“电击”的效果,此时游戏角色身体上会覆盖有电流,该效果能表明游戏角色的当前状态,让玩家能够获得更直观更好的体验。 那么如何实现呢 首先创建一个ShaderGraph文件,命名为Current,再创建对应的材质球M_Current。 基础的资源显示 老规矩,…...
搜索引擎Agent)
【LLM-agent】(task4)搜索引擎Agent
note 新增工具:搜索引擎Agent 文章目录 note一、搜索引擎AgentReference 一、搜索引擎Agent import os from dotenv import load_dotenv# 加载环境变量 load_dotenv() # 初始化变量 base_url None chat_model None api_key None# 使用with语句打开文件…...
)
携程Java开发面试题及参考答案 (200道-下)
insert 一行数据的时候加的是什么锁?为什么? 在 MySQL 中,当执行 INSERT 操作插入一行数据时,加锁的情况会因存储引擎和具体的事务隔离级别而有所不同。一般来说,在 InnoDB 存储引擎下,INSERT 操作加的是行级排他锁(Row Exclusive Lock),以下详细说明原因。 行级排他…...

GWO优化SVM回归预测matlab
灰狼优化算法(Grey Wolf Optimizer,简称 GWO),是由澳大利亚格里菲斯大学的 Mirjalii 等人于 2014 年提出的群智能优化算法。该算法的设计灵感源自灰狼群体的捕食行为,核心思想是对灰狼社会的结构与行为模式进行模仿。 …...

QMK启用摇杆和鼠标按键功能
虽然选择了触摸屏,我仍选择为机械键盘嵌入摇杆模块,这本质上是对"操作连续性"的执着。 值得深思的是,本次开发过程中借助DeepSeek的代码生成与逻辑推理,其展现的能力已然颠覆传统编程范式,需求描述可自动…...

Unity实现按键设置功能代码
一、前言 最近在学习unity2D,想做一个横版过关游戏,需要按键设置功能,让用户可以自定义方向键与攻击键等。 自己写了一个,总结如下。 二、界面效果图 这个是一个csv文件,准备第一列是中文按键说明,第二列…...

基于物联网技术的实时数据流可视化研究(论文+源码)
1系统方案设计 根据系统功能的设计要求,展开基于物联网技术的实时数据流可视化研究设计。如图2.1所示为系统总体设计框图,系统以STM32单片机做为主控制器,通过DHT11、MQ-2、光照传感器实现环境中温湿度、烟雾、光照强度数据的实时检测&#x…...

list容器(详解)
1. list的介绍及使用 1.1 list的介绍(双向循环链表) https://cplusplus.com/reference/list/list/?kwlist(list文档介绍) 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭…...

Elasticsearch基本使用详解
文章目录 Elasticsearch基本使用详解一、引言二、环境搭建1、安装 Elasticsearch2、安装 Kibana(可选) 三、索引操作1、创建索引2、查看索引3、删除索引 四、数据操作1、插入数据2、查询数据(1)简单查询(2)…...

17.3.4 颜色矩阵
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 17.3.4.1 矩阵基本概念 矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合,类似于数组。 由…...

FPGA 时钟多路复用
时钟多路复用 您可以使用并行和级联 BUFGCTRL 的组合构建时钟多路复用器。布局器基于时钟缓存 site 位置可用性查找最佳布局。 如果可能,布局器将 BUFGCTRL 布局在相邻 site 位置中以利用专用级联路径。如无法实现,则布局器将尝试将 BUFGCTRL 从…...
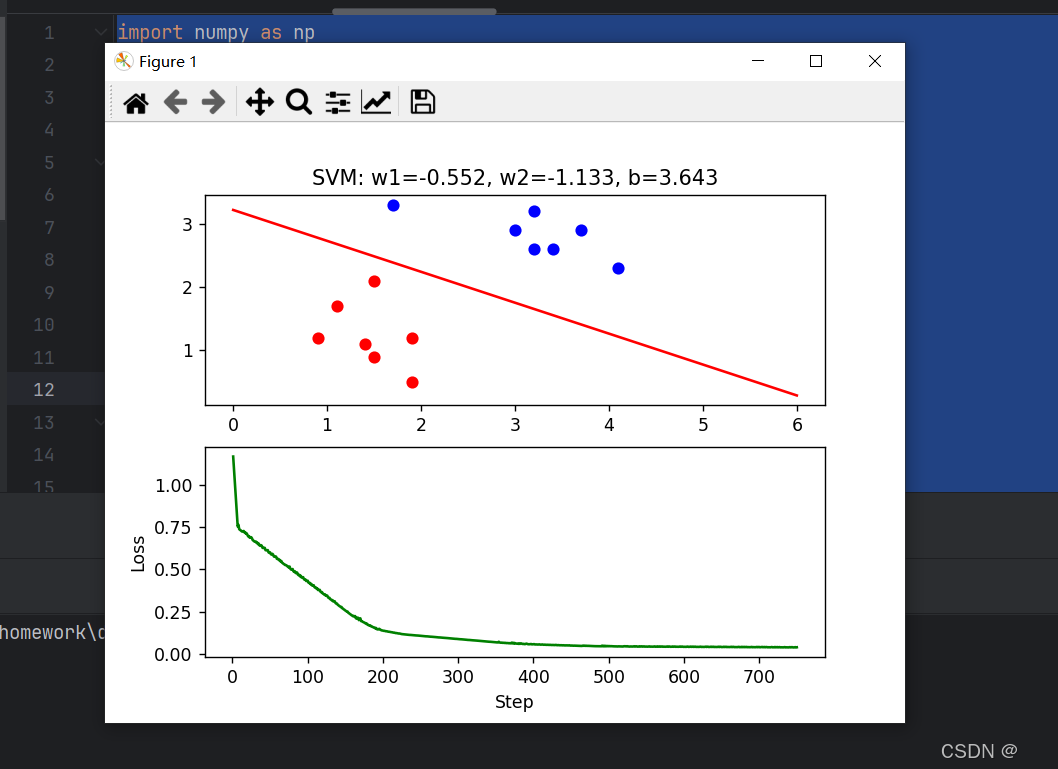
机器学习10
自定义数据集 使用scikit-learn中svm的包实现svm分类 代码 import numpy as np import matplotlib.pyplot as pltclass1_points np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])class2_points np.array([[3.2, 3.2],[3.7, 2.9],…...

航空航天装备行业技术岗结构设计工程师晋升CTO
下面我直接给你:航空航天装备行业「结构设计工程师 → CTO」的完整岗位链 每级年限 薪资(军工院所 vs 商业航天 2026 实价) 关键跃迁点,全部按结构岗真实晋升路线写死,不掺虚的。一、总路线(结构工程师 →…...

告别付费困扰:Linux与Windows双平台免费获取Typora全攻略
1. Typora收费后的免费替代方案 Typora作为一款广受欢迎的Markdown编辑器,突然宣布收费让很多用户措手不及。作为一名长期使用Typora的技术写作者,我完全理解大家的心情。好消息是,我们完全可以在不违反软件许可协议的前提下,继续…...

086、Python数据压缩与归档:zipfile与tarfile实战笔记
086、Python数据压缩与归档:zipfile与tarfile实战笔记 一、从线上故障说起 上周排查一个生产环境问题:某服务每天生成的日志文件把磁盘撑满了。 查看代码发现,开发同事用 open().write() 直接写文本,一年下来积累了上千个文件。 其实这类场景最适合用压缩归档——既节省空…...

AntiDupl.NET:高效智能的重复图片检测与清理解决方案
AntiDupl.NET:高效智能的重复图片检测与清理解决方案 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑中堆积如山的重复图片而感到困扰&#…...

运放数据手册没明说的秘密:5种ESD保护电路全解析与避坑指南
运放数据手册没明说的秘密:5种ESD保护电路全解析与避坑指南 在工业现场、医疗设备或精密测量系统中,运算放大器往往需要直面静电放电(ESD)的威胁。许多工程师在选型时只关注增益带宽积和噪声指标,却忽略了数据手册中那…...

基于MCP协议构建智能Telegram助手:连接AI与外部服务的实践指南
1. 项目概述:一个连接AI与Telegram的智能桥梁如果你正在寻找一种方法,让你在Telegram上使用的AI助手(比如ChatGPT、Claude等)能够“活”起来,不仅能聊天,还能帮你查天气、看新闻、管理待办事项,…...

PvZ Toolkit终极指南:5分钟掌握植物大战僵尸PC版最强修改器
PvZ Toolkit终极指南:5分钟掌握植物大战僵尸PC版最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 植物大战僵尸PC版玩家们,你是否想过拥有无限阳光、免费种植、自定…...

AI融合物理知识:无线信道建模精度与可解释性双重突破
1. 项目概述:当无线信号遇见AI与传播知识无线信道建模,这个听起来有点学术的词,其实就是搞清楚无线电波从发射端到接收端这一路上都经历了什么。无论是你用手机刷视频、家里的Wi-Fi联网,还是未来自动驾驶汽车之间的通信࿰…...
)
限时开放:ChatGPT Slogan生成专业版Prompt集(含金融/快消/科技三大垂直领域加密模板)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Slogan生成的核心原理与边界认知 ChatGPT 生成 slogan 的本质并非“创意发明”,而是基于大规模语料统计规律的条件概率采样。其输出受限于训练数据分布、指令微调策略(如…...

博彩业税收支持STEM教育的风险与可持续筹资方案探讨
1. 项目概述:当教育经费与博彩业挂钩作为一名长期关注科技教育领域发展的从业者,我时常需要追踪全球范围内STEM(科学、技术、工程和数学)教育的政策与资金动向。最近在梳理历史资料时,一篇2012年的旧文再次引起了我的注…...