R语言 | 使用 ComplexHeatmap 绘制热图,分区并给对角线分区加黑边框
目的:画热图,分区,给对角线分区添加黑色边框
建议直接看0和4。
0. 准备数据
# 安装并加载必要的包
#install.packages("ComplexHeatmap") # 如果尚未安装
library(ComplexHeatmap)# 使用 iris 数据集 #data(iris)# 选择数值列(去掉物种列)
data0 <- iris
rownames(data0)=paste0(iris$Species, 1:nrow(data0))# data0 <- mtcars 分类效果不好# 随机抽取30个
set.seed(42)
dat=data0[sample(nrow(data0), 30), 1:4]
#dat=data0# 计算余弦距离
#install.packages("proxy") # 如果尚未安装
library("proxy")
distance_matrix <- as.matrix(dist(dat, method = "cosine"))
# 如果不想安装新包,也可以使用默认的欧氏距离:
#distance_matrix <- as.matrix(dist(iris_data, method = "euclidean"))# 使用相似性绘图 simi=1-dist
similarity=1-distance_matrixdim(similarity)
[1] 30 30
1. Heatmap 全部分块加黑框
library(circlize)
col_fun = colorRamp2(c(-2, 0, 2), c("green", "white", "red"))
col_fun(seq(-3, 3))Heatmap(similarity, name = "mat", #col = col_fun,row_km = 3, column_km = 3,)
# 每个分块绘制黑边框
# When the heatmap is split, layer_fun is applied in every slice.
Heatmap(similarity, name = "mat", #col = col_fun,row_km = 3, column_km = 3,layer_fun = function(j, i, x, y, width, height, fill) {# 全部分块都加黑框v = pindex(similarity, i, j)#grid.text(sprintf("%.1f", v), x, y, gp = gpar(fontsize = 10))str(v)grid.rect(gp = gpar(lwd = 2, fill = "transparent"))if(sum(v > 0)/length(v) > 0.75) {}})

2. 为对角线分块添加黑边框
Heatmap(similarity, name = "mat",#col = c("white", "yellow", "red3"),#col = col_fun,col = colorRamp2(c(0.5, 0.75, 1), c("white", "yellow", "red3")),row_km = 3, column_km = 3,layer_fun = function(j, i, x, y, width, height, fill, slice_r, slice_c) {v = pindex(similarity, i, j)#grid.text(sprintf("%.1f", v), x, y, gp = gpar(fontsize = 10))if(slice_r == slice_c) {grid.rect(gp = gpar(lwd = 4, fill = "transparent", col="black"))}})

3. 添加列注释
还有一个与 pheatmap 包同名的函数:
annotation_col = data.frame(type = data0$Species,row.names = rownames(data0)
)[rownames(dat), ,drop=F]
# set colors
ann_colors = list(#type = c('setosa'="#ed553b", 'versicolor'="#99b433", 'virginica'="orange")type = c('setosa'="violetred1", 'versicolor'="turquoise2", 'virginica'="blueviolet")
)
# "#ed553b", "#99b433"
#violetred1,turquoise2,pheatmap(similarity,name = "Cosine\nsimilarity",main="xx", border_color = NA,clustering_method = "ward.D2",annotation_col = annotation_col, #set anno for columnannotation_colors = ann_colors, #set colors#col = c("white", "yellow", "red3"),#col = col_fun,col = colorRamp2(c(0.8, 0.9, 1), c("white", "yellow", "red3")),row_km = 3, column_km = 3,layer_fun = function(j, i, x, y, width, height, fill, slice_r, slice_c) {v = pindex(similarity, i, j)#grid.text(sprintf("%.1f", v), x, y, gp = gpar(fontsize = 10))if(slice_r == slice_c) {grid.rect(gp = gpar(lwd = 4, fill = "transparent", col="black"))}})

Bug:
有一个问题:不同次执行,图竟然是不同的,不仅仅是分类的排列顺序问题,而是分类本身也不同了。搜了一下, 竟然受到随机数种子的影响?!固定的数据,固定的参数,每次聚类为什么还要受到随机数影响?不理解!难道非监督的聚类还要人工判断对不对?
比如,对以上最后一个聚类函数,设置不同的随机数种子,结果分别是:
# set.seed(45) #这个随机数竟然影响分类位置?!比如修改随机数种子,图分别为
pheatmap(similarity,name = "Cosine\nsimilarity",main="xx", border_color = NA,clustering_method = "ward.D2",annotation_col = annotation_col, #set anno for columnannotation_colors = ann_colors, #set colors#col = c("white", "yellow", "red3"),#col = col_fun,col = colorRamp2(c(0.8, 0.9, 1), c("white", "yellow", "red3")),row_km = 3, column_km = 3,layer_fun = function(j, i, x, y, width, height, fill, slice_r, slice_c) {v = pindex(similarity, i, j)#grid.text(sprintf("%.1f", v), x, y, gp = gpar(fontsize = 10))if(slice_r == slice_c) {grid.rect(gp = gpar(lwd = 4, fill = "transparent", col="black"))}})

原因:使用kmeans聚类,确实是随机数确定初始中心的。不使用kmeans聚类,就不会受到随机数的影响。
4. 层次聚类,对结果分群
- 原来:row_km = 3, column_km = 3, #kmeans确实是种子确定初始中心,结果会随随机数而变化
- 现在:cutree_row=3, cutree_cols=3, #层次聚类是稳定的
pheatmap(similarity,name = "Cosine\nsimilarity",main="Hierarchical cluster", border_color = NA,clustering_method = "ward.D2",annotation_col = annotation_col, #set anno for columnannotation_colors = ann_colors, #set colors#col = c("white", "yellow", "red3"),#col = col_fun,col = colorRamp2(c(0.8, 0.9, 1), c("white", "yellow", "red3")),#row_km = 3, column_km = 3, #kmeans确实是种子确定初始中心cutree_row=3, cutree_cols=3, #层次聚类是稳定的layer_fun = function(j, i, x, y, width, height, fill, slice_r, slice_c) {v = pindex(similarity, i, j)#grid.text(sprintf("%.1f", v), x, y, gp = gpar(fontsize = 10))if(slice_r == slice_c) {grid.rect(gp = gpar(lwd = 4, fill = "transparent", col="black"))}})

Ref
相关文章:
R语言 | 使用 ComplexHeatmap 绘制热图,分区并给对角线分区加黑边框
目的:画热图,分区,给对角线分区添加黑色边框 建议直接看0和4。 0. 准备数据 # 安装并加载必要的包 #install.packages("ComplexHeatmap") # 如果尚未安装 library(ComplexHeatmap)# 使用 iris 数据集 #data(iris)# 选择数值列&a…...

React图标库: 使用React Icons实现定制化图标效果
React图标库: 使用React Icons实现定制化图标效果 图标库介绍 是一个专门为React应用设计的图标库,它包含了丰富的图标集合,覆盖了常用的图标类型,如FontAwesome、Material Design等。React Icons可以让开发者在React应用中轻松地添加、定制各…...

Python sider-ai-api库 — 访问Claude、llama、ChatGPT、gemini、o1等大模型API
目前国内少有调用ChatGPT、Claude、Gemini等国外大模型API的库。 Python库sider_ai_api 提供了调用这些大模型的一个完整解决方案, 使得开发者能调用 sider.ai 的API,实现大模型的访问。 Sider是谷歌浏览器和Edge的插件,能调用ChatGPT、Clau…...

DeepSeek、哪吒和数据库:厚积薄发的力量
以下有部分来源于AI,毕竟我认为AI还不能替代,他只能是辅助 快速迭代是应用程序不是工程 在这个追求快速迭代、小步快跑的时代,我们似乎总是被 “快” 的节奏裹挟着前进。但当我们静下心来,审视 DeepSeek 的发展、饺子导演创作哪吒…...

DDD - 微服务架构模型_领域驱动设计(DDD)分层架构 vs 整洁架构(洋葱架构) vs 六边形架构(端口-适配器架构)
文章目录 引言1. 概述2. 领域驱动设计(DDD)分层架构模型2.1 DDD的核心概念2.2 DDD架构分层解析 3. 整洁架构:洋葱架构与依赖倒置3.1 整洁架构的核心思想3.2 整洁架构的层次结构 4. 六边形架构:解耦核心业务与外部系统4.1 六边形架…...

第 1 天:UE5 C++ 开发环境搭建,全流程指南
🎯 目标:搭建 Unreal Engine 5(UE5)C 开发环境,配置 Visual Studio 并成功运行 C 代码! 1️⃣ Unreal Engine 5 安装 🔹 下载与安装 Unreal Engine 5 步骤: 注册并安装 Epic Game…...
】)
【华为OD-E卷 - 109 磁盘容量排序 100分(python、java、c++、js、c)】
【华为OD-E卷 - 磁盘容量排序 100分(python、java、c、js、c)】 题目 磁盘的容量单位常用的有M,G,T这三个等级, 它们之间的换算关系为1T 1024G,1G 1024M, 现在给定n块磁盘的容量,…...
)
【大数据技术】编写Python代码实现词频统计(python+hadoop+mapreduce+yarn)
编写Python代码实现词频统计(python+hadoop+mapreduce+yarn) 搭建完全分布式高可用大数据集群(VMware+CentOS+FinalShell) 搭建完全分布式高可用大数据集群(Hadoop+MapReduce+Yarn) 本机PyCharm连接CentOS虚拟机 在阅读本文前,请确保已经阅读过以上三篇文章,成功搭建了…...

5-Scene层级关系
Fiber里有个scene是只读属性,能从fiber中获取它属于哪个场景,scene实体中又声明了fiber,fiber与scene是互相引用的关系。 scene层级关系 举例 在unity.core中的EntityHelper中,可以通过entity获取对应的scene root fiber等属性…...

JVM执行流程与架构(对应不同版本JDK)
直接上图(对应JDK8以及以后的HotSpot) 这里主要区分说明一下 方法区于 字符串常量池 的位置更迭: 方法区 JDK7 以及之前的版本将方法区存放在堆区域中的 永久代空间,堆的大小由虚拟机参数来控制。 JDK8 以及之后的版本将方法…...
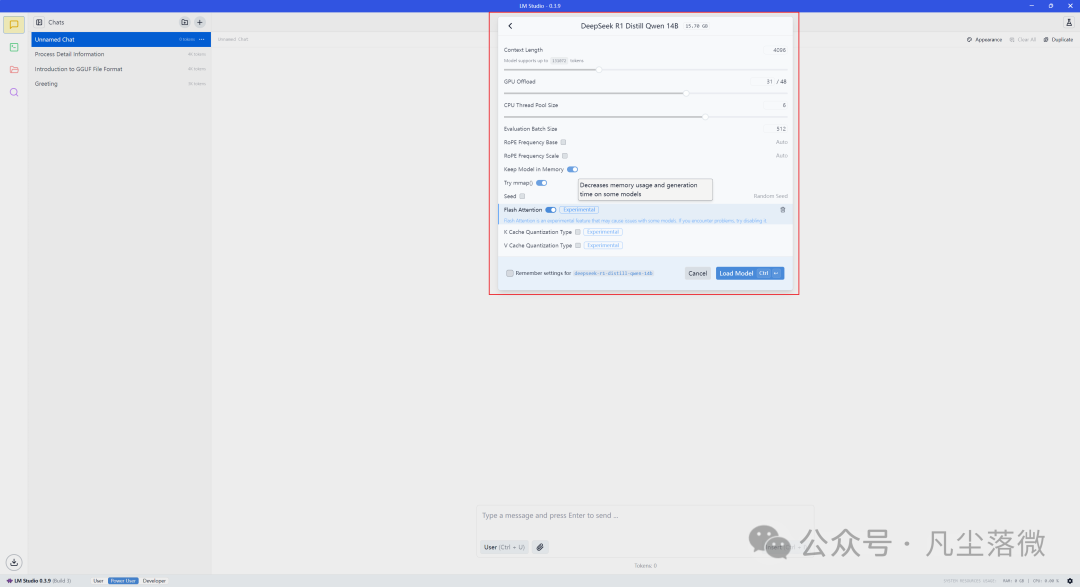
本地部署 DeepSeek-R1:简单易上手,AI 随时可用!
🎯 先看看本地部署的运行效果 为了测试本地部署的 DeepSeek-R1 是否真的够强,我们随便问了一道经典的“鸡兔同笼”问题,考察它的推理能力。 📌 问题示例: 笼子里有鸡和兔,总共有 35 只头,94 只…...

请求响应(接上篇)
请求 日期参数 需要在前面加上一个注解DateTimeFormat来接收传入的参数的值 Json参数 JSON参数:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数,需要使用 RequestBody 标识 通过RequestBody将JSON格式的数据封装到实体类…...

数组排序算法
数组排序算法 用C语言实现的数组排序算法。 排序算法平均时间复杂度最坏时间复杂度最好时间复杂度空间复杂度是否稳定适用场景QuickO(n log n)O(n)O(n log n)O(log n)不稳定大规模数据,通用排序BubbleO(n)O(n)O(n)O(1)稳定小规模数据,教学用途InsertO(n)…...

防火墙的安全策略
1.VLAN 2属于办公区;VLAN 3属于生产区,创建时间段 [FW]ip address-set BG type object [FW-object-address-set-BG]address 192.168.1.0 mask 25 [FW]ip address-set SC type object [FW-object-address-set-SC]address 192.168.1.129 mask 25 [FW]ip address-se…...

2025Java面试题超详细整理《微服务篇》
什么是微服务架构? 微服务框架是将某个应用程序开发划分为许多独立小型服务,实现敏捷开发和部署,这些服务一般围绕业务规则进行构建,可以用不同的语言开发,使用不同的数据存储,最终使得每个服务运行在自己…...

中位数定理:小试牛刀> _ <2025牛客寒假1
给定数轴上的n个点,找出一个到它们的距离之和尽量小的点(即使我们可以选择不是这些点里的点,我们还是选择中位数的那个点最优) 结论:这些点的中位数就是目标点。可以自己枚举推导(很好想) (对于 点的数量为…...

(2025,LLM,下一 token 预测,扩散微调,L2D,推理增强,可扩展计算)从大语言模型到扩散微调
Large Language Models to Diffusion Finetuning 目录 1. 概述 2. 研究背景 3. 方法 3.1 用于 LM 微调的高斯扩散 3.2 架构 4. 主要实验结果 5. 结论 1. 概述 本文提出了一种新的微调方法——LM to Diffusion (L2D),旨在赋予预训练的大语言模型(…...

如何开发一个大语言模型,开发流程及需要的专业知识
开发大型语言模型(LLM)是一个复杂且资源密集的过程,涉及多个阶段和跨学科知识。以下是详细的开发流程和所需专业知识指南: 一、开发流程 1. 需求分析与规划 目标定义:明确模型用途(如对话、翻译、代码生成…...

【数据采集】基于Selenium采集豆瓣电影Top250的详细数据
基于Selenium采集豆瓣电影Top250的详细数据 Selenium官网:https://www.selenium.dev/blog/ 豆瓣电影Top250官网:https://movie.douban.com/top250 写在前面 实验目标:基于Selenium框架采集豆瓣电影Top250的详细数据。 电脑系统:Windows 使用软件:PyCharm、Navicat 技术需求…...

neo4j-在Linux中安装neo4j
目录 切换jdk 安装neo4j 配置neo4j以便其他电脑可以访问 切换jdk 因为我安装的jdk是1.8版本的,而我安装的neo4j版本为5.15,Neo4j Community 5.15.0 不支持 Java 1.8,它要求 Java 17 或更高版本。 所以我需要升级Java到17 安装 OpenJDK 17 sudo yu…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

从SD卡初始化到读写文件:一个完整嵌入式项目中的SDIO驱动避坑实践
从SD卡初始化到读写文件:嵌入式SDIO驱动实战全解析 在嵌入式系统开发中,SD卡因其高容量、低成本和便携性成为数据存储的首选方案。然而,看似简单的SD卡接口背后隐藏着复杂的初始化协议和时序要求。许多工程师在项目初期都会遇到SD卡无法识别、…...

等压雨幕原理在铝合金窗的应用
等压雨幕原理在铝合金窗的应用 摘要: 针对常见的样窗水密气密不达标,首先概述等压雨幕的作用原理,然后介绍其在铝合金门窗应用中的代表性细节。可以看出,控制框扇搭接处的间隙很重要,以及密封胶条合理设计选用的重要性。而且日系推拉采用等压设计的方式很值得借鉴。 关键…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

3D打印乐高手机支架:低成本打造高清视频会议摄像头方案
1. 项目概述与核心思路如果你和我一样,对视频会议、直播时笔记本自带摄像头那“感人”的画质感到无奈,同时又觉得单独购买一个高品质的网络摄像头是一笔不小的开销,那么这个项目绝对值得你花上一个周末的时间来折腾。它的核心思路非常巧妙&am…...

开源机械爪OpenClaw:从设计到力控抓取的完整实现指南
1. 项目概述:从“OpenClaw”看开源机械爪的无限可能最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“MeyerZhou/openclaw”。光看名字,你大概能猜到这是个关于机械爪的开源项目。没错,这是一个旨在提供低成本、模块…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

多维子集和问题:NP难问题的算法与应用解析
1. 多维子集和问题概述多维子集和问题(Multi-dimensional Subset Sum Problem)是计算复杂度理论中的经典NP难问题。简单来说,它要求在给定的n维向量集合中,找出一个子集,使得该子集中所有向量在每一维上的和恰好等于目标向量对应的分量。这个…...

Arm CoreLink PCK-600电源管理架构与寄存器编程详解
1. Arm CoreLink PCK-600电源控制架构解析在嵌入式系统设计中,电源管理单元(PMU)是实现高效能耗控制的核心组件。Arm CoreLink PCK-600作为业界领先的电源控制解决方案,其架构设计体现了现代SoC电源管理的先进理念。PCK-600系列采…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...