Redis03 - 高可用
Redis高可用
文章目录
- Redis高可用
- 一:主从复制 & 读写分离
- 1:主从复制的作用
- 2:主从复制原理
- 2.1:全量复制
- 2.2:增量复制(环形缓冲区)
- 3:主从复制实际演示
- 3.1:基本流程
- 准备好两个redis服务器
- 配置修改
- 启动两个服务器
- 查看主从状态
- 主从配置指令
- 测试下
- 3.2:一些说明
- 4:读写分离问题
- 二:哨兵模式
- 1:基本工作流程
- 1.1:哨兵集群组建(消息pub/sub)
- 1.2:下线判断(客观下线)
- 1.3:主哨兵选举(raft半数通过)
- 1.4:新主库的选出(健康,完整的)
- 1.5:故障转移(易主通知复制)
- 2:哨兵模式实际演示
- 2.1:基本流程
- 创建哨兵服务器
- 修改哨兵服务器的配置文件
- 启动哨兵服务器
- 主节点挂掉测试
- 要是哨兵也挂了咋办?
- 2.2:Jedis感知
- 一:集群
- 1:集群的引入
- 2:设计目标
- 3:常用概念
- 3.1:哈希槽 hash_slot
- 3.2:hash_tags
- 分片nodes属性
- 3.3:集群总线
- 4:搭建实例
- 4.1:基本流程
- 创建六个redis服务器
- 配置修改
- 全部启动
- 主从集群分配
- 4.2:其他说明
- 节点信息
- 让某一个主节点挂掉会怎么样?
- 主从都挂了怎么办?
- Jedis
一:主从复制 & 读写分离
主从复制,主从复制是指将一台redis上的服务的数据复制到另外的redis上,前者称为主节点,后者称为从节点【单向性】
1:主从复制的作用
数据冗余
主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式
故障恢复
当主节点出现问题的时候,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务的冗余。
负载均衡
在主从复制的基础上,配合读写分离,可以由主节点提供写服务,从节点提供读服务,分担服务器的负载,尤其是在写少读多的情况下,通过配置多个从节点分担读负载,可以大大的提高redis服务器的并发量。

高可用基石
是哨兵模式和集群可以实现的基础,因此可以说是高可用的基础。
2:主从复制原理
和MongoDB的初始同步和复制很像
2.1:全量复制
当我们启动多个redis实例的时候,就可以使用replicaof(5.0以前是slaveof)形成主库和从库的关系
会按照三个步骤完成数据的第一次同步:
确立主从关系
例如:现在有实例 1(ip:172.16.19.3)和实例 2(ip:172.16.19.5)
我们在实例 2 上执行以下这个命令后,实例 2 就变成了实例 1 的从库,并从实例 1 上复制数据
replicaof 172.16.19.3 6379
全量复制的三个阶段

第一步:建立连接,协商同步
- 主要是为全量复制做准备。
- 在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
- 具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。offset,此时设为 -1,表示第一次复制。主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。
- 注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
第二步:将主库所有同步数据给从库
- 从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件
- 具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
第三步:主库发送新的写命令给从库
- 当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了
2.2:增量复制(环形缓冲区)
如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。
从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。

repl_backlog_buffer
它是为了从库断开之后,如何找到主从差异数据而设计的环形缓冲区,从而避免全量复制带来的性能开销
⚠️ 如果从库断开时间太久,repl_backlog_buffer环形缓冲区被主库的写命令覆盖了,那么从库连上主库后只能乖乖地进行一次全量复制
所以repl_backlog_buffer配置尽量大一些,可以降低主从断开后全量复制的概率
repl_buffer
我们每个client连上Redis后,Redis都会分配一个client buffer,所有数据交互都是通过这个buffer进行的
注意点
一个从库如果和主库断连时间过长,造成它在主库repl_backlog_buffer的slave_repl_offset位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。
每个从库会记录自己的slave_repl_offset,每个从库的复制进度也不一定相同。
在和主库重连进行恢复时,从库会通过psync命令把自己记录的slave_repl_offset发给主库,主库会根据从库各自的复制进度,来决定这个从库可以进行增量复制,还是全量复制
3:主从复制实际演示
3.1:基本流程
准备好两个redis服务器

配置修改
分别将端口号改成6001【redis-master】,6002【redis-slave】 -> 配置文件redis.windows.conf

启动两个服务器

查看主从状态
输入info replication命令来查看当前的主从状态,可以看到默认的角色为:master,也就是说所有的服务器在启动之后都是主节点的状态。

主从配置指令
我们希望让6002作为从节点,通过一个命令即可:输入replicaof 127.0.0.1 6001
🎉 每次都去敲个命令配置主从太麻烦了,我们可以直接在配置文件中配置这个命令
命令后,就会将6001服务器作为主节点,而当前节点作为6001的从节点,并且角色也会变成:slave


可以看到从节点信息中已经出现了6002服务器,也就是说现在我们的6001和6002就形成了主从关系
- 主服务器和从服务器都会维护一个复制偏移量,主服务器每次向从服务器中传递 N 个字节的时候,会将自己的复制偏移量加上 N。
- 从服务器中收到主服务器的 N 个字节的数据,就会将自己额复制偏移量加上 N
- 通过主从服务器的偏移量对比可以很清楚的知道主从服务器的数据是否处于一致,如果不一致就需要进行增量同步了。
测试下

3.2:一些说明
⚠️ 从节点压根就没办法进行数据插入,节点的模式为只读模式

🎉 那么如果我们现在不想让6002作为6001的从节点了呢?
可以在6002执行replicaof no one【我不是别人的从服务器】即可变回到master

🎉 全量复制和增量复制
接着我们再次让6002变成6001的从节点【或者在创建一个6003作为6001的从节点】
可以看到,在连接之后,也会直接同步主节点的数据,因此无论是已经处于从节点状态还是刚刚启动完成的服务器,都会从主节点同步数据,实际上整个同步流程为:
- 从节点执行replicaof ip port命令后,从节点会保存主节点相关的地址信息。
- 从节点通过每秒运行的定时任务发现配置了新的主节点后,会尝试与该节点建立网络连接,专门用于接收主节点发送的复制命令。
- 连接成功后,第一次会将主节点的数据进行全量复制,之后采用增量复制,持续将新来的写命令同步给从节点。

⚠️ 当我们的主节点关闭后,从节点依然可以读取数据:但是从节点会提示报错信息


再次启动后恢复正常

🎉 除了作为Master节点的从节点外,我们还可以将其作为从节点的从节点

采用这种方式,优点肯定是显而易见的,但是缺点也很明显,整个传播链路一旦中途出现问题,那么就会导致后面的从节点无法及时同步。
4:读写分离问题
延迟与不一致问题
由于主从复制的命令传播是异步的,延迟与数据的不一致不可避免。
如果应用对数据不一致的接受程度程度较低,可能的优化措施包括:
- 优化主从节点之间的网络环境(如在同机房部署);
- 监控主从节点延迟(通过offset)判断,如果从节点延迟过大,通知应用不再通过该从节点读取数据;
- 使用集群同时扩展写负载和读负载等。
数据过期问题
在单机版Redis中,存在两种删除策略:
惰性删除:服务器不会主动删除数据,只有当客户端查询某个数据时,服务器判断该数据是否过期,如果过期则删除。定期删除:服务器执行定时任务删除过期数据,但是考虑到内存和CPU的折中
Redis 3.2中,从节点在读取数据时,增加了对数据是否过期的判断:如果该数据已过期,则不返回给客户端;
将Redis升级到3.2+可以解决数据过期问题。
故障切换问题
在没有使用哨兵的读写分离场景下,应用针对读和写分别连接不同的Redis节点;
当主节点或从节点出现问题而发生更改时,需要及时修改应用程序读写Redis数据的连接;
连接的切换可以手动进行,或者自己写监控程序进行切换,但前者响应慢、容易出错,后者实现复杂,成本都不算低
不持久化的主服务器自动重启非常危险
- 我们设置节点A为主服务器,关闭持久化,节点B和C从节点A复制数据。
- 这时出现了一个崩溃,但Redis具有自动重启系统,重启了进程,因为关闭了持久化,节点重启后只有一个空的数据集。
- 节点B和C从节点A进行复制,现在节点A是空的,所以节点B和C上的复制数据也会被删除。
二:哨兵模式

哨兵作用
-
监控 -> 哨兵会不断地检查主节点和从节点是否运作正常
-
故障自动转移 -> 当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点
-
配置提供者 -> 客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址
-
通知 -> 哨兵可以将故障转移的结果发送给客户端
监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;
而配置提供者和通知功能,则需要在与客户端的交互中才能体现
1:基本工作流程
1.1:哨兵集群组建(消息pub/sub)
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅机制【消息传递】
🌰 举一个简单的栗子
在主从集群中,主库上有一个名为__sentinel__:hello的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
哨兵 1 把自己的 IP(172.16.19.3)和端口(26579)发布到__sentinel__:hello频道上
哨兵 2 和 3 订阅了该频道。
那么此时,哨兵 2 和 3 就可以从这个频道直接获取哨兵 1 的 IP 地址和端口号。
然后,哨兵 2、3 可以和哨兵 1 建立网络连接。

通过这个方式,哨兵 2 和 3 也可以建立网络连接,这样一来,哨兵集群就形成了。
它们相互间可以通过网络连接进行通信,比如说对主库有没有下线这件事儿进行判断和协商。
1.2:下线判断(客观下线)
首先要理解两个概念:主观下线和客观下线
- 主观下线:任何一个哨兵都是可以监控探测,并作出Redis节点下线的判断;
- 客观下线:有哨兵集群共同决定Redis节点是否下线;
当某个哨兵(如下图中的哨兵2)判断主库“主观下线”后,就会给其他哨兵发送 is-master-down-by-addr 命令。
接着,其他哨兵会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票

如果赞成票数是大于等于哨兵配置文件中的 quorum 配置项(比如这里如果是quorum=2), 则可以判定主库客观下线了
1.3:主哨兵选举(raft半数通过)
判断完主库下线后,由哪个哨兵节点来执行主从切换呢?
为什么需要哨兵的选举
为了避免单节点哨兵的存在,就需要哨兵集群,而集群的出现表示必然要面临共识问题【选举问题】
故障转移和通知都由主哨兵节点进行负责即可。
哨兵的选举是怎样的
哨兵的选举,遵循的是著名的raft算法:
当投票数 r >= num / 2 + 1 就进行当选
如何成为leader哨兵节点
- 第一,拿到半数以上的赞成票
- 第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值
以 3 个哨兵为例,假设此时的 quorum 设置为 2,那么,任何一个想成为 Leader 的哨兵只要拿到 2 张赞成票,就可以了。
1.4:新主库的选出(健康,完整的)
- 过滤掉不健康的(下线或断线),没有回复过哨兵ping响应的从节点
- 选择
salve-priority从节点优先级最高(redis.conf)的 - 选择复制偏移量最大,指复制最完整的从节点

1.5:故障转移(易主通知复制)
假设现在有这样的情况:主库节点已经客观下线了,哨兵节点3被选为了哨兵leader,并且决定新的主库为从节点slave_1

故障转移的流程
- 将slave-1脱离原从节点(5.0 中应该是
replicaof no one),升级主节点, - 将从节点slave-2指向新的主节点
- 通知客户端主节点已更换
- 将原主节点(oldMaster)变成从节点,指向新的主节点

转移之后

2:哨兵模式实际演示
2.1:基本流程

创建哨兵服务器

修改哨兵服务器的配置文件
# 其他的全部都删除掉,只写这一行
# 其中第一个和第二个参数是固定的
# 第三个参数是为监控对象名称,随意
# 第四个,第五个参数就是主节点的相关信息,包括IP地址和端口
# 最后一个参数是哨兵支持数大于等于多少sentinel monitor cuihaida-sentinel 127.0.0.1 6001 1
启动哨兵服务器

可以看到以哨兵模式启动后,会自动监控主节点,然后还会显示那些节点是作为从节点存在的。
主节点挂掉测试
一开始从节点还在常规报错,因为会认为主节点只是网络卡顿了,没必要急着切换主节点

但是一段时间之后,哨兵发现还是连接不上主节点,便开始重新选主

6003已经成为新的主节点

再次启动6001之后,发现他已经变成了6003的从节点

那么,这个选举规则是怎样的呢?是在所有的从节点中随机选取还是遵循某种规则呢?
- 首先会根据优先级进行选择,可以在配置文件中进行配置,添加
replica-priority配置项(默认是100),越小表示优先级越高。 - 如果优先级一样,那就选择偏移量最大的
- 要是还选不出来,那就选择runid(启动时随机生成的)最小的。
要是哨兵也挂了咋办?
咱们可以多安排几个哨兵,只需要把哨兵的配置复制一下,然后修改端口,这样就可以同时启动多个哨兵了,我们启动3个哨兵(一主二从三哨兵),这里我们吧最后一个值改为2:
sentinel monitor cuihaida 192.168.0.8 6001 2
这个值实际上代表的是当有几个哨兵认为主节点挂掉时,就判断主节点真的挂掉了
2.2:Jedis感知
在哨兵重新选举新的主节点之后,我们Java中的Redis的客户端怎么感知到呢?
<dependencies><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>4.2.1</version></dependency>
</dependencies>
public class Main {public static void main(String[] args) {try {//这里我们直接使用JedisSentinelPool来获取Master节点//需要把三个哨兵的地址都填入JedisSentinelPool pool = new JedisSentinelPool("cuihaida", new HashSet<>(Arrays.asList("192.168.0.8:26741", "192.168.0.8:26740", "192.168.0.8:26739")))) {Jedis jedis = pool.getResource(); //直接询问并得到Jedis对象,这就是连接的Master节点jedis.set("test", "114514"); //直接写入即可,实际上就是向Master节点写入Jedis jedis2 = pool.getResource(); //再次获取System.out.println(jedis2.get("test")); //读取操作} catch (Exception e) {e.printStackTrace();}}
}
一:集群
1:集群的引入
如果我们服务器的内存不够用了,但是现在我们的Redis又需要继续存储内容,那么这个时候就可以利用集群来实现扩容。
因为单机的内存容量最大就那么多,已经没办法再继续扩展了,但是现在又需要存储更多的内容
这时我们就可以让N台机器上的Redis来分别存储各个部分的数据(每个Redis可以存储1/N的数据量),这样就实现了容量的横向扩展。
同时每台Redis还可以配一个从节点,这样就可以更好地保证数据的安全性。

那么问题来,现在用户来了一个写入的请求,数据该写到哪个节点上呢?
首先,一个Redis集群包含16384个插槽,集群中的每个Redis 实例负责维护一部分插槽以及插槽所映射的键值数据,那么这个插槽是什么意思呢?
实际上,插槽就是键的Hash计算后的一个结果,这里采用CRC16,能得到16个bit位的数据,也就是说算出来之后结果是0-65535之间,再进行取模,得到最终结果:
Redis key的路由计算公式:slot = CRC16(key) % 16384
结果的值是多少,就应该存放到对应维护的Redis下
比如Redis节点1负责0-25565的插槽,而这时客户端插入了一个新的数据
a=10,a在Hash计算后结果为666,那么a就应该存放到1号Redis节点中。简而言之,本质上就是通过哈希算法将插入的数据分摊到各个节点的,所以说哈希算法真的是处处都有用啊。
主从复制和哨兵机制保障了高可用,就读写分离而言虽然slave节点扩展了主从的读并发能力,但是写能力和存储能力是无法进行扩展,就只能是master节点能够承载的上限。
如果面对海量数据那么必然需要构建master(主节点分片)之间的集群,同时必然需要吸收高可用(主从复制和哨兵机制)能力,即每个master分片节点还需要有slave节点,这是分布式系统中典型的纵向扩展(集群的分片技术)的体现
所以在Redis 3.0版本中对应的设计就是Redis Cluster

2:设计目标
高性能可线性扩展至最多1000节点。集群中没有代理,(集群节点间)使用异步复制,没有归并操作
3:常用概念
3.1:哈希槽 hash_slot
redis分片没有使用一致性hash,而是采用了hash槽的概念,redis分片中有16284(214)个hash槽
每一个key通过校验之后对16284 mod决定放到那个槽里。分片中的每一个节点负责一部分槽。
比如集群中存在三个节点,则可能存在的一种分配如下:
- 节点A包含0到5500号哈希槽;
- 节点B包含5501到11000号哈希槽;
- 节点C包含11001到16384号哈希槽。
3.2:hash_tags
hash_tags提供了一种策略,用来将多个(相关的)key分配到相同的hash槽中,这是实现muitl_key的基础。
hash_tags规则如下,如果满足如下规则,{和}之间的字符将用来计算hash槽,以保证这样的key保存在同一个slot中
- key包含一个{字符
- 并且 如果在这个{的右面有一个}字符
- 并且 如果在{和}之间存在至少一个字符
--------- 举几个例子 ----------
{user1000}.following和{user1000}.followers这两个key会被hash到相同的hash slot中,因为只有user1000会被用来计算hash slot值。 foo{}{bar}这个key不会启用hash tag因为第一个{和}之间没有字符。 foozap这个key中的{bar部分会被用来计算hash slot foo{bar}{zap}这个key中的bar会被用来计算计算hash slot,而zap不会
分片nodes属性
每一个节点在分片中有唯一的名字
节点在配置文件中保存它的id,并且永久的使用这个id,直到被管理员使用CLUSTER RESET HARD命令重置节点。
节点id被用来在整个分集群中标识每个节点。一个节点可以修改自己的IP地址而不需要修改自己的id
节点ID不是唯一与节点绑定的信息,但是他是唯一的一个总是保持全局一致的字段。
3.3:集群总线
每个集群节点有一个额外的TCP端口用来接受其他节点的连接。
这个端口与用来接收client命令的普通TCP端口有一个固定的offset。该端口等于普通命令端口加上10000。
例如,一个Redis在端口6379和客户端连接,那么它的集群总线端口16379也会被打开。
节点到节点的通讯只使用集群总线,同时使用集群总线协议:有不同的类型和大小的帧组成的二进制协议。

集群拓扑
redis集群是一张全网拓扑,节点与其他每个节点之间都保持着TCP连接。
在一个拥有N个节点的集群中,每个节点由N-1个TCP传出连接,和N-1个TCP传入连接。 这些TCP连接总是保持活性。
当一个节点在集群总线上发送了ping请求并期待对方回复pong,(如果没有得到回复)在等待足够成时间以便将对方标记为不可达之前,它将先尝试重新连接对方以刷新与对方的连接。
而在全网拓扑中的redis集群节点,节点使用gossip协议和配置更新机制来避免在正常情况下节点之间交换过多的消息,因此集群内交换的消息数目(相对节点数目)不是指数级的。
节点握手
节点总是接受集群总线端口的链接,并且总是会回复ping请求,即使ping来自一个不可信节点。
然而,如果发送节点被认为不是当前集群的一部分,所有其他包将被抛弃
节点认定其他节点是当前集群的一部分有两种方式:
- 如果一个节点出现在了一条MEET消息中。一条MEET消息非常像一个ping消息,但是它会强制接收者接受一个节点作为集群的一部分。节点只有在接收到系统管理员的如下命令后,才会向其他节点发送MEET消息
cluster meet ip port
- 如果一个被信任的节点gossip了某个节点,那么接收到gossip消息的节点也会那个节点标记为集群的一部分。也就是说,如果在集群中,A知道B,而B知道C,最终B会发送gossip消息到A,告诉A节点C是集群的一部分。这时,A会把C注册未网络的一部分,并尝试与C建立连接。
🔉一旦我们把某个节点加入了连接图,它们最终会自动形成一张全连接图。这意味着只要系统管理员强制加入了一条信任关系(在某个节点上通过meet命令加入了一个新节点),集群可以自动发现其他节点
4:搭建实例
4.1:基本流程
创建六个redis服务器

配置修改
修改三个节点的配置【主节点端口:6001, 6002, 6003】【从节点端口:7001,7002,7003】
bind 127.0.0.1注释掉【56行】- 保护模式关闭
protected-mode no【75行】 - 设置端口【79行】
cluster-enabled yes解开注释 【707行】
🎉 改好一份复制redis.windows.conf到其他的服务器,然后其他的服务器只需要改端口就可以了
全部启动
⚠️ 要是起不来了,把所有的持久化文件全部删除,所有的节点内容必须是空的。

主从集群分配
然后输入redis-cli.exe --cluster create --cluster-replicas 1 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003
这里的--cluster-replicas 1指的是每个节点配一个从节点:

输入之后,会为你展示客户端默认分配的方案,并且会询问你当前的方案是否合理。可以看到6001/6002/6003都被选为主节点,其他的为从节点,我们直接输入yes即可:

分配成功,可以看到插槽的分配情况

5:测试
随便连接一个节点,尝试插入一个值:

在插入时,出现了一个错误,实际上这就是因为a计算出来的哈希值(插槽),不归当前节点管,我们得去管这个插槽的节点执行
通过上面的分配情况,我们可以得到15495号插槽属于节点6003管理:

6:集群方式连接
以使用集群方式连接,这样我们无论在哪个节点都可以插入,只需要添加-c表示以集群模式访问:

可以看到,在6001节点成功对a的值进行了更新,只不过还是被重定向到了6003节点进行插入
4.2:其他说明
节点信息
我们可以输入cluster nodes命令来查看当前所有节点的信息

让某一个主节点挂掉会怎么样?
现在我们把6001挂掉,可以看到原本的6001从节点7001,晋升为了新的主节点,而之前的6001已经挂了

现在我们将6001重启,可以看到6001变成了7001的从节点

主从都挂了怎么办?
要是6001和7001都挂了

我们尝试插入新的数据,可以看到,当存在节点不可用时,会无法插入新的数据
Jedis
// 我们需要用到JedisCluster对象:
public class Main {public static void main(String[] args) {//和客户端一样,随便连一个就行,也可以多写几个,构造方法有很多种可以选择try(JedisCluster cluster = new JedisCluster(new HostAndPort("192.168.0.8", 6003))){System.out.println("集群实例数量:"+cluster.getClusterNodes().size());cluster.set("a", "yyds");System.out.println(cluster.get("a"));}}
}
相关文章:
Redis03 - 高可用
Redis高可用 文章目录 Redis高可用一:主从复制 & 读写分离1:主从复制的作用2:主从复制原理2.1:全量复制2.2:增量复制(环形缓冲区) 3:主从复制实际演示3.1:基本流程准…...
)
系统URL整合系列视频四(需求介绍补充)
视频 系统URL整合系列视频四(需求补充说明) 视频介绍 (全国)大型分布式系统Web资源URL整合需求(补充)讲解。当今社会各行各业对软件系统的web资源访问权限控制越来越严格,控制粒度也越来越细。…...

激活函数篇 03 —— ReLU、LeakyReLU、ELU
本篇文章收录于专栏【机器学习】 以下是激活函数系列的相关的所有内容: 一文搞懂激活函数在神经网络中的关键作用 逻辑回归:Sigmoid函数在分类问题中的应用 整流线性单位函数(Rectified Linear Unit, ReLU),又称修正线性单元&a…...

山东大学软件学院人机交互期末复习笔记
文章目录 2022-2023 数媒方向2023-2024 软工方向重点题目绪论发展阶段 感知和认知基础视觉听觉肤觉知觉认知过程和交互设计原则感知和识别注意记忆问题解决语言处理影响认知的因素 立体显示技术及其应用红蓝眼镜偏振式眼镜主动式(快门时)立体眼镜 交互设…...

python 语音识别方案对比
目录 一、语音识别 二、代码实践 2.1 使用vosk三方库 2.2 使用SpeechRecognition 2.3 使用Whisper 一、语音识别 今天识别了别人做的这个app,觉得虽然是个日记app 但是用来学英语也挺好的,能进行语音识别,然后矫正语法,自己说的时候 ,实在不知道怎么说可以先乱说,然…...

docker常用命令及案例
以下是 Docker 的所有常用命令及其案例说明,按功能分类整理: 1. 镜像管理 1.1 拉取镜像 命令: docker pull <镜像名>:<标签>案例: 拉取官方的 nginx 镜像docker pull nginx:latest1.2 列出本地镜像 命令: docker images案例: 查看本地所有…...

DeepSeek-R1 云环境搭建部署流程
DeepSeek横空出世,在国际AI圈备受关注,作为个人开发者,AI的应用可以有效地提高个人开发效率。除此之外,DeepSeek的思考过程、思考能力是开放的,这对我们对结果调优有很好的帮助效果。 DeepSeek是一个基于人工智能技术…...

Java_双列集合
双列集合特点 存放的是键值对对象(Entry) Map 因为都是继承Map,所以要学会这些API,后面的类就都知道了 put 有两个操作,添加(并返回null)或者覆盖(返回被覆盖的值)…...

.net的一些知识点6
1.写个Lazy<T>的单例模式 public class SingleInstance{private static readonly Lazy<SingleInstance> instance new Lazy<SingleInstance>(() > new SingleInstance());private SingleInstance(){}public static SingleInstance Instace > instance…...

无须付费,安装即是完全版!
不知道大家有没有遇到过不小心删掉了电脑上超重要的文件,然后急得像热锅上的蚂蚁? 别担心,今天给大家带来一款超给力的数据恢复软件,简直就是拯救文件的“救星”! 数据恢复 专业的恢复数据软件 这款软件的界面设计得特…...

常见数据库对象与视图VIEW
常见的数据库对象 表 TABLE 数据字典 约束 CONSTRAINT 视图 VIEW 索引 INDEX 存储过程 PROCESS 存储函数 FUNCTION 触发器 TRIGGER 视图VIEW 1、引入 为什么使用视图? 视图可以帮助我们使用表的一部分,针对不同的用户制定不同的查询视图。 …...
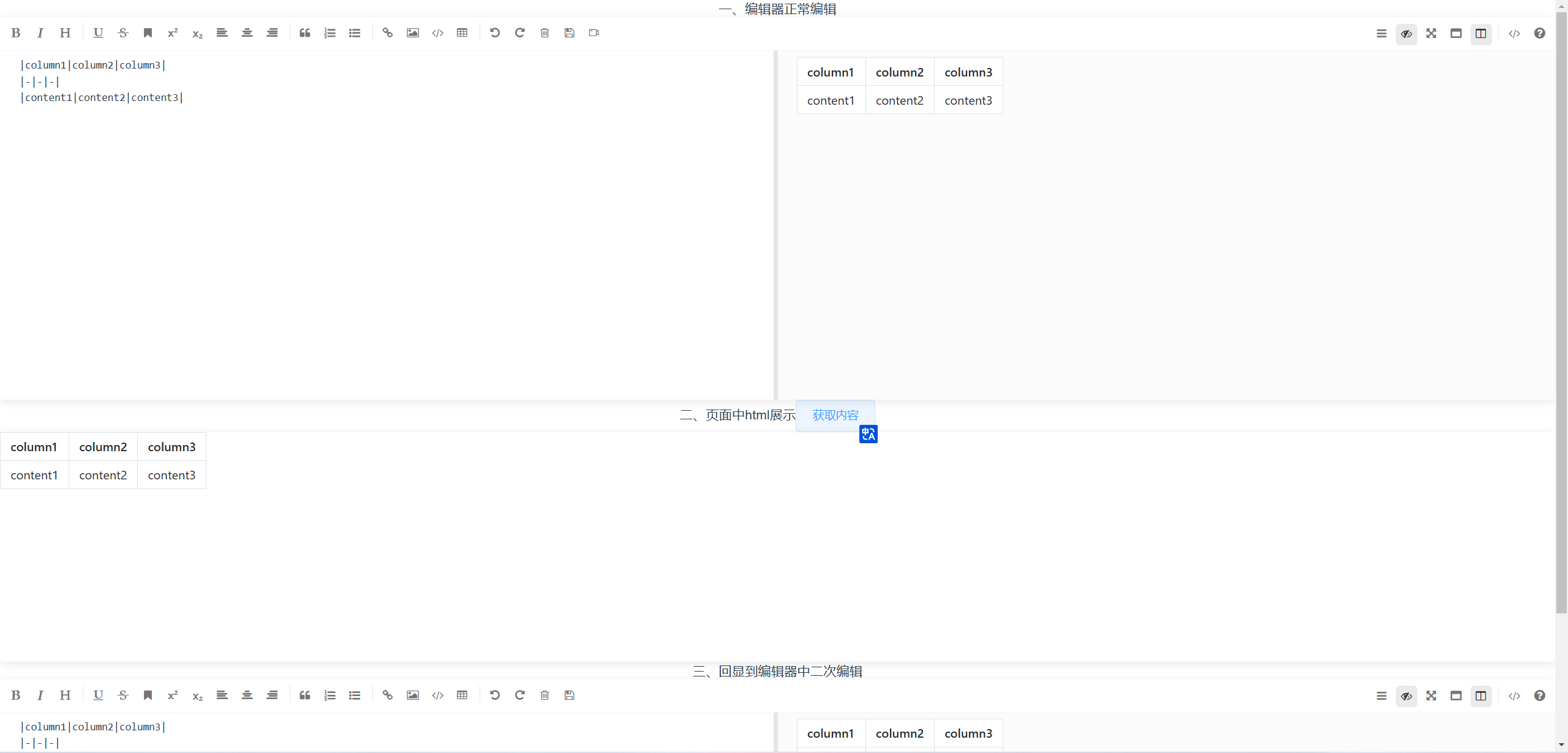
【Vue2】vue2项目中如何使用mavon-editor编辑器,数据如何回显到网页,如何回显到编辑器二次编辑
参考网站: 安装使用参考:vue2-常用富文本编辑器使用介绍 html网页展示、编辑器回显二次编辑参考:快速搞懂前端项目如何集成Markdown插件mavon-editor,并回显数据到网页 安装命令 npm install mavon-editor2.9.1 --save全局配置 …...

2、Python面试题解析:如何进行字符串插值?
Python字符串插值详解 字符串插值是将变量或表达式嵌入字符串中的一种技术,Python提供了多种方式实现字符串插值。以下是常见的几种方法及其详细解析和代码示例。 1. 百分号(%)格式化 这是Python早期版本中的字符串插值方法,类似…...

计算机网络-SSH基本原理
最近年底都在忙,然后这两天好点抽空更新一下。前面基本把常见的VPN都学习了一遍,后面的内容应该又继续深入一点。 一、SSH简介 SSH(Secure Shell,安全外壳协议)是一种用于在不安全网络上进行安全远程登录和实现其他安…...

doris:MySQL 兼容性
Doris 高度兼容 MySQL 语法,支持标准 SQL。但是 Doris 与 MySQL 还是有很多不同的地方,下面给出了它们的差异点介绍。 数据类型 数字类型 类型MySQLDorisBoolean- 支持 - 范围:0 代表 false,1 代表 true- 支持 - 关键字&am…...

mysql 存储过程和自定义函数 详解
首先创建存储过程或者自定义函数时,都要使用use database 切换到目标数据库,因为存储过程和自定义函数都是属于某个数据库的。 存储过程是一种预编译的 SQL 代码集合,封装在数据库对象中。以下是一些常见的存储过程的关键字: 存…...

C++ 中的 cJSON 解析库:用法、实现及递归解析算法与内存高效管理
在现代软件开发中,JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式,因其易于阅读和编写、易于机器解析和生成的特性,被广泛应用于各种场景。C 作为一种强大的编程语言,自然也需要一个高效的…...

websocket自动重连封装
websocket自动重连封装 前端代码封装 import { ref, onUnmounted } from vue;interface WebSocketOptions {url: string;protocols?: string | string[];reconnectTimeout?: number; }class WebSocketService {private ws: WebSocket | null null;private callbacks: { [k…...

【C语言】球球大作战游戏
目录 1. 前期准备 2. 玩家操作 3. 生成地图 4. 敌人移动 5. 吃掉小球 6. 完整代码 1. 前期准备 游戏设定:小球的位置、小球的半径、以及小球的颜色 这里我们可以用一个结构体数组来存放这些要素,以方便初始化小球的信息。 struct Ball {int x;int y;float r;DWORD c…...

人工智能D* Lite 算法-动态障碍物处理、多步预测和启发式函数优化
在智能驾驶领域,D* Lite 算法是一种高效的动态路径规划算法,适用于处理环境变化时的路径重规划问题。以下将为你展示 D* Lite 算法的高级用法,包含动态障碍物处理、多步预测和启发式函数优化等方面的代码实现。 代码实现 import heapq impo…...

FastDFS整合Nginx踩坑记:升级1.22.0修复CVE-2021-23017,如何平滑保留模块不报错?
FastDFS整合Nginx安全升级实战:从漏洞修复到模块兼容的全流程指南 最近在维护一个使用FastDFS作为分布式存储的生产环境时,遇到了Nginx的CVE-2021-23017安全漏洞问题。这个漏洞可能允许攻击者通过特制的DNS响应导致工作进程崩溃,对于线上业务…...

如何用开源Lenovo Legion Toolkit彻底掌控你的拯救者笔记本:技术深度解析与实战指南
如何用开源Lenovo Legion Toolkit彻底掌控你的拯救者笔记本:技术深度解析与实战指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo…...
)
玩转OurBMC第二十六期:OpenBMC固件远程更新原理与实践(下)
栏目介绍:“玩转OurBMC” 是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过 “玩转OurBMC” 栏目,帮助开发者们深入了解到社区文…...

芯片设计公司ISO 9001认证:从质量管理体系到流片成功的工程实践
1. 从一则旧闻聊起:ISO 9001认证对一家芯片设计公司意味着什么?前几天在整理资料时,偶然翻到一篇2011年的行业旧闻,说的是当时一家名为SiliconBlue Technologies的公司,获得了ISO 9001:2008质量管理体系认证。新闻稿写…...
)
从‘古董’到统一:聊聊Linux内核中buffer与cache合并背后的那些事儿(附free命令实战)
从‘古董’到统一:Linux内核中buffer与cache合并背后的设计哲学 在Linux系统的性能优化领域,free命令的输出一直是开发者关注的焦点。当你键入free -h时,那行看似简单的"buff/cache"统计背后,隐藏着一段跨越二十年的内…...

避开这些坑!在Colab上运行AlphaFold2时,参数、路径和依赖库的常见错误排查指南
避开这些坑!在Colab上运行AlphaFold2时,参数、路径和依赖库的常见错误排查指南 在Google Colab上运行AlphaFold2看似简单,但实际操作中90%的用户都会遇到各种"诡异"报错。上周一位结构生物学博士向我吐槽:"明明按照…...

收藏!普通人零基础转行AI,3-5个月实现高薪就业的进阶指南
本文指出AI行业对非计算机专业人才的需求激增,半路转行者因具备行业经验而更具竞争力。文章澄清了转行AI的常见误区,强调“技术懂业务”是关键,并提供了普通人转行AI的3步走策略:选择AI算法、自然语言或应用工程师等低门槛岗位&am…...

化工仿真神器 Aspen 15.0:AI 赋能 + 绿氢专项,附下载安装教程
Aspen 15.0 是 工业流程模拟与数字化平台,核心为化工、石化、炼油、能源等行业提供全生命周期解决方案,从工艺设计、模拟优化到生产运维、绿色转型全覆盖,15.0 版本重点强化工业 AI、生成式 AI 能力,适配绿色能源与可持续发展需求…...

Beyond Compare 5完全激活指南:3种简单方法告别30天试用限制
Beyond Compare 5完全激活指南:3种简单方法告别30天试用限制 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否正在使用Beyond Compare 5这款强大的文件对比工具,却因…...

MCP Analytics Suite:用自然语言驱动AI数据分析,零代码生成专业报告
1. 项目概述:当AI助手遇上专业数据分析如果你和我一样,日常工作中需要处理大量的业务数据——可能是Shopify的订单报表、Stripe的支付流水,或者是一堆从各个渠道导出的CSV文件——那你一定体会过那种“数据在手,却无从下手”的焦虑…...