LIMO:少即是多的推理
25年2月来自上海交大、SII 和 GAIR 的论文“LIMO: Less is More for Reasoning”。
一个挑战是在大语言模型(LLM)中的复杂推理。虽然传统观点认为复杂的推理任务需要大量的训练数据(通常超过 100,000 个示例),但本文展示只需很少的示例就可以有效地引发复杂的数学推理能力。这个不仅挑战对海量数据要求的假设,也挑战监督微调(SFT)主要造成记忆而不是泛化的普遍看法。通过全面的实验,提出的模型 LIMO 在数学推理方面表现出前所未有的性能和效率。仅使用 817 个精选的训练样本,LIMO 在极具挑战性的 AIME 基准上实现 57.1% 的准确率,在 MATH 上实现 94.8% 的准确率,将以前基于 SFT 的强大模型在 AIME 上的性能从 6.5% 提高到 57.1%,在 MATH 上的性能从 59.2% 提高到 94.8%,同时仅使用以前方法所需训练数据的 1%。LIMO 表现出分布外(OOD)例外泛化能力,在 10 个不同的基准测试中实现 40.5% 的绝对提升,优于使用 100 倍以上数据训练的模型,直接挑战 SFT 本质上导致记忆而不是泛化的流行观念。
综合这些结果,本文提出少即是多推理假说(LIMO 假说):在预训练期间已全面编码域知识的基础模型中,复杂的推理能力可以通过最少但精确协调的认知过程演示显现出来。该假设认为,复杂推理的引出阈值,本质上不受目标推理任务复杂性的限制,而是由两个关键因素从根本上决定的:(1)预训练期间模型编码知识基础的完整性,以及(2)后训练示例的有效性,它们作为“认知模板”,向模型展示如何有效利用现有知识库来解决复杂的推理任务。
如图所示:LIMO 使用更少的样本实现比 NuminaMath 显著的改进,同时在各种数学和多学科基准测试中表现出色。

长期以来,复杂推理一直被认为是大语言模型 (LLM) 中最难培养的能力之一。尽管最近的研究表明,LLM 可以通过相对较少的指令数据有效地与用户偏好保持一致(Zhou,2024a),但人们普遍认为,教师模型进行推理(尤其是在数学和编程方面)需要更多的训练示例(Paster,2023;Yue,2024)。这种传统观点源于推理任务固有的复杂性,它需要多步骤的逻辑推理、域知识应用和结构化的解决方案路径。由此产生的范式通常涉及对数万或数十万个示例进行训练(Yu,2024;Li,2024b),基于两个基本假设:首先,掌握如此复杂的认知过程需要大量监督演示;其次,监督微调主要造成记忆而不是真正的泛化(Zhang,2024;Xu,2024;Chu,2025)。
虽然这种方法已取得成功,但它带来了巨大的计算成本和数据收集负担。更重要的是,这种数据密集型范式可能不再是必要的。最近的进展从根本上改变 LLM 获取、组织和利用推理知识的方式,表明有可能采用一种更有效的方法。特别是两个关键发展从根本上为重新构想 LLM 中的推理方法创造了条件:
- 知识基础革命:现代基础模型现在在预训练期间纳入前所未有的大量数学内容(Qwen,2025;Yang,2024;Wang,2024)。例如:Llama 2 在所有域的总训练数据为 1.8T 个 token(Touvron,2023 年),而 Llama 3 仅在数学推理中就使用 3.7T 个 token(Grattafiori,2024 年)。这表明当代 LLM 可能已经在其参数空间中拥有丰富的数学知识,将挑战从知识获取转变为知识引出。
- 推理-时间计算规模化革命:规模化更长推理链技术的出现表明,有效的推理在论断过程中需要大量的计算空间。最近的研究(OpenAI,2024;Qin,2024;Huang,2024)表明,允许模型生成规模化推理链,可显著提高其推理能力。本质上,推理-时间计算提供了至关重要的认知工作空间,模型可以在其中系统地解开和应用其预先训练的知识。
LLM 中数学推理的演变。大规模训练数据一直是 LLM 推理能力发展的驱动力。在预训练阶段,相关语料库可以增强 LLM 的推理能力(Wang,2024;Azerbayev,2024;Paster,2023;Shao,2024)。这些精选语料库可以由多种来源组成,例如教科书、科学论文和数学代码,它们捕捉用于解决问题的各种人类认知模式。在后训练阶段,一系列研究专注于策划大规模指令数据以教授 LLM 推理(Yue,2023、2024;Li,2024a)。这包括规模化问题及其相应解决方案的数量。规模化方法很有前景,并且已经取得显着的性能提升。然而,通过这种方法获得的推理能力,因依赖于固定模式的记忆而不是实现真正的泛化而受到批评(Mirzadeh,2024;Zhang,2024)。例如,Mirzadeh(2024)发现,LLM 在回答同一问题的不同实例时表现出明显的差异,并且当仅改变问题中的数值时,其性能会下降。这引发人们对 SFT 方法泛化能力的怀疑(Chu,2025),以及 LLM 是否可以成为真正的推理者而不是单纯的知识检索者(Kambhampati,2024)。
测试-时间规模化和长链推理。最近的研究不再关注规模化模型参数和训练数据(Kaplan,2020),而是转向探索测试-时间规模化(OpenAI,2024;Snell,2024),即增加 token 数量以提高性能。这可以通过使用并行采样(Brown,2024;Wang,2022;Li,2022)或符号树搜索(Hao,2023;Chen,2024;Yao,2023)等方法增强 LLM 来实现,以增强推理能力。此外,OpenAI(2024);Guo(2025) 探索使用强化学习训练 LLM 以生成长 CoT,这通常包括自我反思、验证和回溯——人类在解决复杂问题时常用的过程。这种方法不仅创新 LLM 的训练范式,而且还提供一种新形式的训练数据来增强其推理能力。这种长 CoT 在引出 LLM 固有的推理能力方面表现出高质量的特征。
语言模型中的数据效率。Zhou (2024a) 证明,仅需 1,000 个策划的提示和响应,模型就可以学会遵循特定的格式并很好地推广到未见过的任务。研究结果强调在对齐过程中质量重于数量的重要性。然而,考虑到此类任务的潜在高计算复杂性,这一教训是否可以应用于推理任务仍不确定(Merrill & Sabharwal,2024;Xiang,2025)。虽然一些关于推理的研究强调在整理训练数据时质量的重要性(Zhou,2024b),但此类数据的数量与 LIMA 相比仍然大得多。
下面介绍LIMO的工作。
现象再思考:“少即是多”和强化学习规模化
LIMO 的出现,代表在大语言模型中概念化和激活复杂推理能力的范式转变。首先,将 LIMO 与 LIMA 进行对比,了解“少即是多”原则如何从一般对齐扩展到复杂推理;其次,将 LIMO 与强化学习 (RL) 规模化方法进行比较,以突出开发推理能力的不同哲学观点。通过这些分析,旨在更深入地了解语言模型中复杂认知能力的出现方式以及有效激活的条件。
LIMO 与 LIMA
LLM 中“少即是多”现象的出现,代表对如何用最少的数据引出复杂能力的理解发生了根本性转变。虽然 LIMA(Zhou,2024a)首先在一般对齐的背景下展示了这种现象,但将这一原则扩展到复杂的数学推理提出了独特的挑战和要求。
知识基础革命。过去两年见证语言模型获取和组织数学知识的方式转变。虽然 LIMA 可以依靠一般文本语料库进行对齐,但 LIMO 的成功建立在通过专门的预训练嵌入现代基础模型的丰富数学内容之上(Wang,2024)。这种专门的知识基础是有效激活推理能力的先决条件。
计算能力革命。LIMA 和 LIMO 之间的一个关键区别在于它们的计算要求。虽然 LIMA 的对齐任务可以通过固定长度生成和单次处理来完成,但 LIMO 的推理任务需要大量的计算空间来进行多步审议。推理-时间规模化技术的出现(OpenAI,2024;Qin,2024)提供了必要的“认知工作空间”,模型可以在其中系统地解开并应用其预训练的知识。
协同合流。LIMO 的发现时间,反映了这两场革命的必要合流。 LIMA 和 LIMO 之间两年的差距,不仅代表更好的预训练模型所需时间,还代表等待推理-时间计算突破的必要时间。这种合流促成一种称为“推理抽出阈值”的现象:当模型同时拥有丰富的域知识和足够的计算空间时,可以通过最少但精确的演示激活复杂的推理能力。
对未来研究的启示。这种比较分析表明,“少即是多”不仅仅是一种使用更少数据的提倡,而且是支配模型能力有效抽出的一条基本原则。 LIMO 的成功表明,当满足基本先决条件(知识基础和计算框架)时,复杂的能力可以以显著的数据效率抽出。这一见解表明一个新的研究方向:系统地识别不同能力的先决条件和最佳激活条件。未来的工作应该探索其他高级能力(例如,规划、创造性解决问题)在建立相应的知识和计算基础后是否能达到类似的效率。因此,“少即是多”原则既是理解能力出现的理论框架,也是在各个领域追求数据高效能力发展的实用指南。
如下表比较复杂推理 LIMO 和通用对齐 LIMA:

LIMO 与 RL 规模化
在大语言模型中开发推理能力两种不同方法的出现——RL 规模化和 LIMO——代表了理解和增强模型智能的根本分歧。RL 规模化以 o1(OpenAI,2024)、DeepSeek-R1(Guo,2025)等为例,从工程优化的角度应对挑战。它假设推理能力需要通过大规模强化学习进行广泛的模型训练。虽然这种方法有效,但它本质上将 RL 视为一种广泛的搜索机制,通过大量计算资源发现有效的推理模式。相比之下,LIMO 引入一个更基础的视角:推理能力已经潜伏在预训练模型中,嵌入在预训练阶段。关键挑战从“训练”转向“抽出”——找到能够引出这些天生能力的精确认知模板。
从这个角度来看,像 DeepSeek-R1 这样的 RL 规模化方法可以看作是这一原则的具体实现,使用强化学习作为寻找此类轨迹的机制。虽然这两种方法最终都寻求高质量的推理解决方案,但 LIMO 通过明确的轨迹设计提供一条更有原则、更直接的路径,而 RL 规模化则通过广泛的计算探索发现这些轨迹。这种重新构建表明,包括 RL、专家设计或混合方法在内的各种方法,都可以在 LIMO 的框架内被理解和评估为发现最佳推理轨迹的不同策略。
如下表比较 LIMO 和 RL 规模化:

LIMO 数据集
LIMO 假设
将“少即是多”推理 (LIMO) 假设形式化如下:在基础模型中,域知识在预训练期间已被全面编码,复杂的推理能力可以在最少但精确编排的认知过程演示中出现。这一假设基于两个基本前提:(I)在模型参数空间中,先决条件知识的潜在存在(II)推理链的质量,这些推理链将复杂问题精确分解为详细的逻辑步骤,使认知过程明确且可追溯。为了验证这一假设,本文提出一种系统的方法来构建一个高质量、最小的数据集,可以有效地抽出模型固有的推理能力。
问题定义
本文专注于具有可验证答案的推理任务。给定推理问题空间中的问题 q,目标是生成答案 a 和推理链 r。将推理链 r 定义为一系列中间步骤 {s_1, s_2, …, s_n},其中每个步骤 s_i 代表一个逻辑推理,它弥补问题和最终答案之间的差距。
正式地,可以将推理过程表示为函数 f: Q→R×A。因此,生成数据集 D 的质量,由两个基本但多方面的组成部分决定:(1) 问题 q 的质量,其中包括问题解决方法的多样性、挑战模型能力的适当难度级别、以及涵盖的知识领域广度等因素;(2) 解决方案的质量 (r, a),其中包括教学价值、逻辑连贯性和方法严谨性等方面。问题的设计应鼓励复杂的推理模式和知识整合,而解决方案应展示清晰的逻辑进展并作为有效的学习示例。
高质量数据管理
数据管理过程侧重于构建高质量数据集 D = {(q_i, r_i, a_i)},并且数据量 N 故意保持较小以验证 LIMO 假设。
问题选择。假设高质量问题 q 应该自然地引发扩展的推理过程。选择标准包括以下内容:
• 难度级别。优先考虑那些能够促进复杂推理链、多样化思维过程和知识整合的具有挑战性问题,使 LLM 能够有效地利用预训练的知识进行高质量推理。
• 泛化性。与模型的训练分布偏差更大的问题,可以更好地挑战其固定的思维模式,鼓励探索新的推理方法,从而扩大其推理搜索空间。
• 知识多样性。所选问题应涵盖各种数学领域和概念,要求模型在解决问题时整合和连接远端的知识。
为了有效地实施这些标准,首先从各种既定数据集中收集一个全面的候选问题池:NuminaMath-CoT,包含从高中到高级竞赛水平的标注问题;AIME 历史考试问题,以其极具挑战性和综合性的问题而闻名,涵盖多个数学领域;MATH(Hendrycks,2021),涵盖来自著名竞赛的各种竞争性数学问题;以及其他几个数学问题来源。
从这个丰富的初始集合中,采用系统的多阶段过滤过程。从数千万个问题的初始池开始,首先使用 Qwen2.5-Math-7B-Instruct(Yang,2024)应用基线难度过滤器,消除该模型可以在几次尝试中正确解决的问题。这个过程有助于建立初步的难度阈值。随后,使用最先进的推理模型,包括 R1、DeepSeek-R1-Distill-Qwen-32B(Guo,2025)和 Huang(2024)的模型,对剩余的问题进行更严格的评估,仅保留即使是这些最强大的模型在多次采样迭代后成功率也低于某个阈值的问题。最后,为保持语料库的多样性,采用战略采样技术,在数学领域和复杂度级别之间平衡表示,同时避免概念冗余。这一细致的选择过程,最终从数千万个候选问题的初始池中产生817 个挑选的问题,所选问题共同满足严格的质量标准,同时涵盖丰富的数学推理挑战。
推理链构建。除了高质量的问题之外,解决方案的质量在大语言模型的训练阶段也起着关键作用。为了挑选高质量的解决方案,采用全面的选择策略。首先收集问题的官方解决方案(如果可用),并辅以人类专家和 AI 专家编写的解决方案。此外,利用最先进的推理模型,包括 DeepSeek R1、DeepSeek-R1-Distill-Qwen-32B(Guo,2025)和 Qwen2.5-32b-Instruct,来生成不同的解决方案。此外,按照 O1-Journey-Part2(Huang,2024)中提出的方法,利用基于 Qwen2.5-32b-Instruct 的自我蒸馏技术来创建其他模型变型,然后使用这些变型生成补充问题响应。然后根据答案的正确性筛选这些响应,以建立有效解决方案的基线集合。随后,通过协作检查对这些筛选的解决方案进行全面分析。通过仔细观察和系统审查,确定区分高质量推理链的几个关键特征:
• 最佳结构组织:解决方案表现出清晰且组织良好的结构格式,步骤分解具有自适应粒度。特别是,它在关键的推理节点分配更多token和详细阐述,同时保持简单步骤的简洁表达。这种自适应步骤粒度方法,可确保复杂的转换得到适当的关注,同时避免在较简单的推理中出现不必要的冗长。
• 有效的认知支架:高质量的解决方案,通过精心构建的解释逐步建立理解,从而提供战略教育支持。这包括渐进的概念介绍、在关键点清晰表达关键见解以及深思熟虑地弥合概念差距,使复杂的推理过程更易于理解和学习。
• 严格的验证:高质量的解决方案,在整个推理过程中包含极其频繁的验证步骤。这包括验证中间结果、交叉检查假设以及确认每个推论的逻辑一致性,从而确保最终答案的可靠性。
基于这些确定的特征,开发一种结合基于规则的过滤和 LLM 辅助策划的混合方法,以针对上述每个问题选择高质量的解决方案。这个系统化的过程,确保每个选定的解决方案都符合既定的质量标准,同时保持整个数据集的一致性。通过专注于一组最小策划的推理链,体现“少即是多”的核心原则:高质量的演示,而不是纯粹的数据量,是解锁复杂推理能力的关键。生成的数据集 D 由精心策划的三元组 (q, r, a) 组成,其中每个推理链 r 都满足质量标准。在限制数据集大小 |D| 的同时保持这些严格的标准,旨在证明高质量的演示,而不是大量的训练数据,对于解锁复杂的推理能力至关重要。
方法论
基于“少即是多”原则,一个模型如果在预训练中积累大量的推理知识,并且在测试-时能够执行长链推理,那么它就可以发展出强大的推理能力。在仅对几百个 SFT 数据实例进行训练后,该模型就会学会将元推理任务整合成一个有凝聚力的推理链。
训练协议
在 LIMO 数据集上使用监督微调对 Qwen2.5-32B-Instruct 进行微调。训练过程采用全参数微调,使用 DeepSpeed ZeRO-3 优化(Rajbhandari,2020)和 FlashAttention- 2(Dao,2023),序列长度限制为 16,384 个 tokens。
评估框架
域内评估。为了全面评估模型在各种推理能力方面的表现,建立了一个涵盖传统和新型基准的多样化评估框架。我们的主要评估套件包括几个成熟的数学竞赛和基准:美国数学邀请赛 (AIME24)、MATH500 (Hendrycks,2021) 和美国数学竞赛 (AMC23)。
分布外(OOD)评估。为了严格评估模型在分布外任务上的表现,选择与训练数据在各个方面不同的一些基准。这些基准可以分为三个不同的类别:
• 多样化的数学竞赛:进一步选择 OlympiadBench(He,2024),它代表数学挑战的独特分布,用于测试模型的 OOD 性能。
• 新的多语言基准:为了最大限度地减少数据污染,用最新的考试问题构建几个基准:2024 年中国高中数学联赛竞赛 CHMath、2024 年中国高考 GAOKAO、中国研究生入学考试 KAOYAN,以及新开发的用于初等数学推理 GradeSchool。值得注意的是,这些基准中的所有问题都是用中文编写的,而训练数据不包含中文问题。这引入一个额外的 OOD 维度,不仅评估模型在问题分布中泛化的能力,还评估其在面对未见过语言时的跨语言推理能力。
• 多学科基准:为了评估数学(训练领域)以外更广泛的泛化能力,结合 Miverva(Lewkowycz,2022)(其中包括本科水平的 STEM 问题)和 GPQA(Rein,2023)。这些基准评估跨多个学科和认知水平的推理能力,深入了解模型将数学推理技能转移到更广泛环境的能力。
性能指标。用 pass@1 指标评估整个基准套件的性能。所有评估均在零样本思维链 (CoT) 设置下进行,以更好地评估模型的推理能力。对于包括 MATH500、OlympiadBench、Gaokao、Kaoyan、GradeSchool、MinervaMath 和 GPQA 在内的基准,采用一种简单的方法,使用贪婪解码和一个单样本来评估正确性。但是,对于每个包含少于 50 个问题的较小基准(特别是 AIME24、AMC23 和 CHMATH),实施更全面的评估协议,生成 16 个样本,温度设置为 0.7,并计算无偏 pass@1 指标,如 Chen (2021) 中所述。对于答案是结构良好的数值问题,直接应用基于规则的评估来检查数学等价性。对于更复杂的答案格式(例如表达式、方程式或结构化解决方案),利用基于 LLM 的评估器,已经验证它的高可靠性。在所有评估过程中,将最大输出长度保持在 32,768 个 tokens,以最大限度地减少输出截断的可能性,确保评估能够捕获完整的问题解决尝试。此外,在评估 LIMO 时,观察到推理-时间规模化偶尔会导致冗长输出末尾出现重复模式。在这种情况下,从模型的响应中提取最可能的最终答案进行评估,以确保准确评估其解决问题的能力。
相关文章:
LIMO:少即是多的推理
25年2月来自上海交大、SII 和 GAIR 的论文“LIMO: Less is More for Reasoning”。 一个挑战是在大语言模型(LLM)中的复杂推理。虽然传统观点认为复杂的推理任务需要大量的训练数据(通常超过 100,000 个示例),但本文展…...

【玩转 Postman 接口测试与开发2_018】第14章:利用 Postman 初探 API 安全测试
《API Testing and Development with Postman》最新第二版封面 文章目录 第十四章 API 安全测试1 OWASP API 安全清单1.1 相关背景1.2 OWASP API 安全清单1.3 认证与授权1.4 破防的对象级授权(Broken object-level authorization)1.5 破防的属性级授权&a…...
如何编写测试用例
代码质量管理是软件开发过程中的关键组成部分,比如我们常说的代码规范、代码可读性、单元测试和测试覆盖率等,对于研发人员来说单元测试和测试覆盖率是保障自己所编写代码的质量的重要手段;好的用例可以帮助研发人员确保代码质量和稳定性、减…...
)
复原IP地址(力扣93)
有了上一道题分割字符串的基础,这道题理解起来就会容易很多。相同的思想我就不再赘述,在这里我就说明一下此题额外需要注意的点。首先是终止条件如何确定,上一题我们递归到超过字符串长度时,则说明字符串已经分割完毕,…...

zzcms接口index.php id参数存在SQL注入漏洞
zzcms接口index.php id参数存在SQL注入漏洞 漏洞描述 ZZCMS 2023中发现了一个严重漏洞。该漏洞影响了文件/index.php中的某些未知功能,操纵参数id会导致SQL注入,攻击可能是远程发起的,该漏洞已被公开披露并可被利用。攻击者可通过sql盲注等手段,获取数据库信息。 威胁等级:…...

Redis03 - 高可用
Redis高可用 文章目录 Redis高可用一:主从复制 & 读写分离1:主从复制的作用2:主从复制原理2.1:全量复制2.2:增量复制(环形缓冲区) 3:主从复制实际演示3.1:基本流程准…...
)
系统URL整合系列视频四(需求介绍补充)
视频 系统URL整合系列视频四(需求补充说明) 视频介绍 (全国)大型分布式系统Web资源URL整合需求(补充)讲解。当今社会各行各业对软件系统的web资源访问权限控制越来越严格,控制粒度也越来越细。…...

激活函数篇 03 —— ReLU、LeakyReLU、ELU
本篇文章收录于专栏【机器学习】 以下是激活函数系列的相关的所有内容: 一文搞懂激活函数在神经网络中的关键作用 逻辑回归:Sigmoid函数在分类问题中的应用 整流线性单位函数(Rectified Linear Unit, ReLU),又称修正线性单元&a…...

山东大学软件学院人机交互期末复习笔记
文章目录 2022-2023 数媒方向2023-2024 软工方向重点题目绪论发展阶段 感知和认知基础视觉听觉肤觉知觉认知过程和交互设计原则感知和识别注意记忆问题解决语言处理影响认知的因素 立体显示技术及其应用红蓝眼镜偏振式眼镜主动式(快门时)立体眼镜 交互设…...

python 语音识别方案对比
目录 一、语音识别 二、代码实践 2.1 使用vosk三方库 2.2 使用SpeechRecognition 2.3 使用Whisper 一、语音识别 今天识别了别人做的这个app,觉得虽然是个日记app 但是用来学英语也挺好的,能进行语音识别,然后矫正语法,自己说的时候 ,实在不知道怎么说可以先乱说,然…...

docker常用命令及案例
以下是 Docker 的所有常用命令及其案例说明,按功能分类整理: 1. 镜像管理 1.1 拉取镜像 命令: docker pull <镜像名>:<标签>案例: 拉取官方的 nginx 镜像docker pull nginx:latest1.2 列出本地镜像 命令: docker images案例: 查看本地所有…...

DeepSeek-R1 云环境搭建部署流程
DeepSeek横空出世,在国际AI圈备受关注,作为个人开发者,AI的应用可以有效地提高个人开发效率。除此之外,DeepSeek的思考过程、思考能力是开放的,这对我们对结果调优有很好的帮助效果。 DeepSeek是一个基于人工智能技术…...

Java_双列集合
双列集合特点 存放的是键值对对象(Entry) Map 因为都是继承Map,所以要学会这些API,后面的类就都知道了 put 有两个操作,添加(并返回null)或者覆盖(返回被覆盖的值)…...

.net的一些知识点6
1.写个Lazy<T>的单例模式 public class SingleInstance{private static readonly Lazy<SingleInstance> instance new Lazy<SingleInstance>(() > new SingleInstance());private SingleInstance(){}public static SingleInstance Instace > instance…...

无须付费,安装即是完全版!
不知道大家有没有遇到过不小心删掉了电脑上超重要的文件,然后急得像热锅上的蚂蚁? 别担心,今天给大家带来一款超给力的数据恢复软件,简直就是拯救文件的“救星”! 数据恢复 专业的恢复数据软件 这款软件的界面设计得特…...

常见数据库对象与视图VIEW
常见的数据库对象 表 TABLE 数据字典 约束 CONSTRAINT 视图 VIEW 索引 INDEX 存储过程 PROCESS 存储函数 FUNCTION 触发器 TRIGGER 视图VIEW 1、引入 为什么使用视图? 视图可以帮助我们使用表的一部分,针对不同的用户制定不同的查询视图。 …...
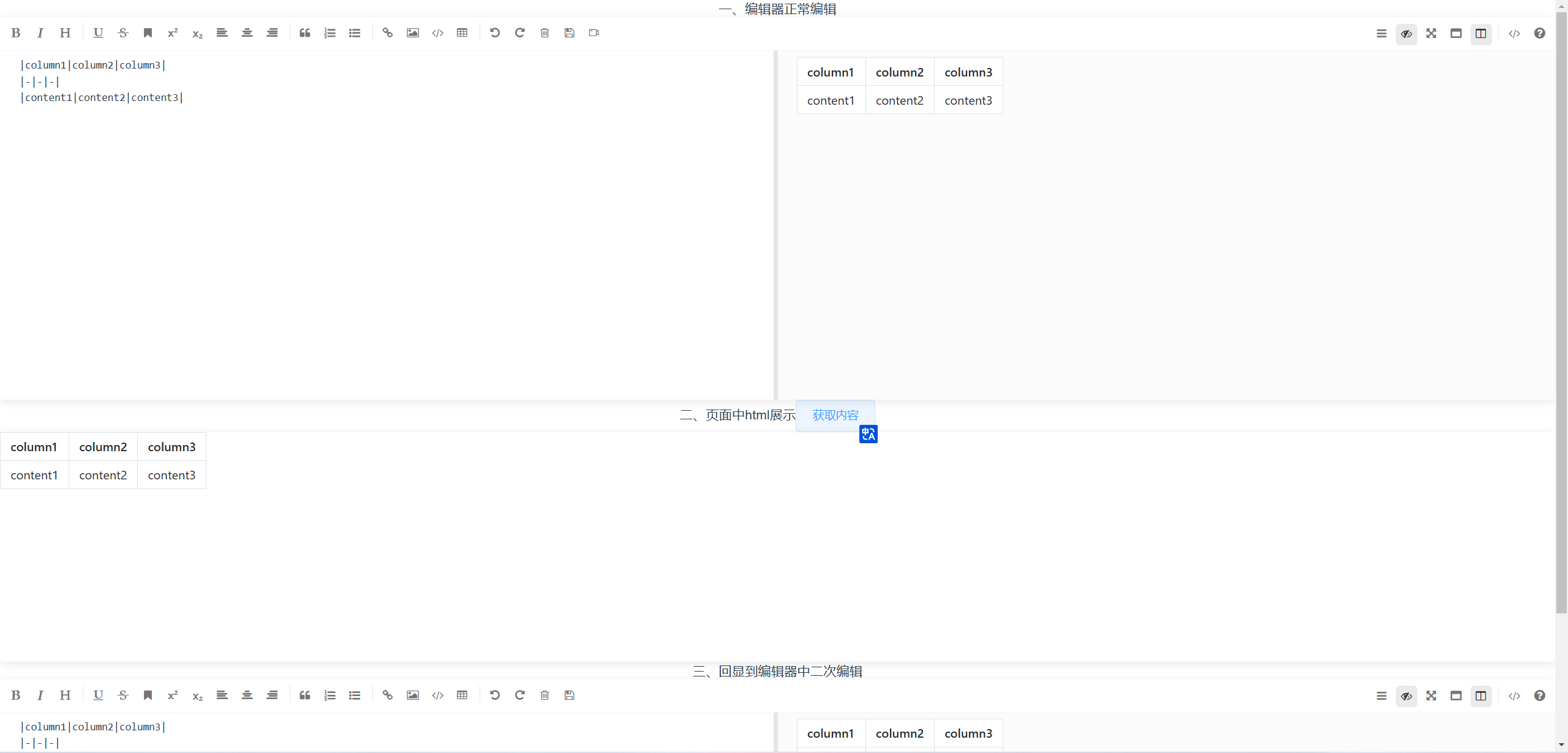
【Vue2】vue2项目中如何使用mavon-editor编辑器,数据如何回显到网页,如何回显到编辑器二次编辑
参考网站: 安装使用参考:vue2-常用富文本编辑器使用介绍 html网页展示、编辑器回显二次编辑参考:快速搞懂前端项目如何集成Markdown插件mavon-editor,并回显数据到网页 安装命令 npm install mavon-editor2.9.1 --save全局配置 …...

2、Python面试题解析:如何进行字符串插值?
Python字符串插值详解 字符串插值是将变量或表达式嵌入字符串中的一种技术,Python提供了多种方式实现字符串插值。以下是常见的几种方法及其详细解析和代码示例。 1. 百分号(%)格式化 这是Python早期版本中的字符串插值方法,类似…...

计算机网络-SSH基本原理
最近年底都在忙,然后这两天好点抽空更新一下。前面基本把常见的VPN都学习了一遍,后面的内容应该又继续深入一点。 一、SSH简介 SSH(Secure Shell,安全外壳协议)是一种用于在不安全网络上进行安全远程登录和实现其他安…...

doris:MySQL 兼容性
Doris 高度兼容 MySQL 语法,支持标准 SQL。但是 Doris 与 MySQL 还是有很多不同的地方,下面给出了它们的差异点介绍。 数据类型 数字类型 类型MySQLDorisBoolean- 支持 - 范围:0 代表 false,1 代表 true- 支持 - 关键字&am…...

借助PD协议分析仪洞悉Type-C充电握手全流程
1. 为什么需要PD协议分析仪? Type-C接口如今已经成为手机、笔记本等设备的标配,但很多用户都遇到过这样的尴尬:买了个第三方充电器,插上设备后要么完全没反应,要么只能以5V慢充。这背后往往是因为PD(Power …...

Postman实战:自动化管理API访问令牌的两种高效策略
1. 为什么需要自动化管理API访问令牌 在如今的API开发中,身份验证和授权已经成为必不可少的安全机制。大多数现代API都采用基于令牌(Token)的认证方式,其中Bearer Token是最常见的标准之一。想象一下,每次调用API都需要手动复制粘贴一长串Tok…...

告别重复图片困扰:AntiDupl.NET 智能图片去重工具完全指南
告别重复图片困扰:AntiDupl.NET 智能图片去重工具完全指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑中堆积如山的重复图片而感到困扰&…...

保姆级教程:手把手拆解Android相机启动流程,从点击图标到预览画面发生了什么?
从点击到成像:Android相机启动全链路技术解析 当你在旅行中突然发现值得记录的瞬间,手指本能地点击相机图标的那一刻,手机内部其实已经触发了一场精密协作的"交响乐演出"。作为Android开发者,理解这套从用户界面直达硬件…...
)
保姆级教程:用Sigrity PowerSI提取5GHz内单端S参数(附DDR4仿真实例)
从零掌握Sigrity PowerSI:5GHz单端S参数提取与DDR4实战解析 在高速PCB设计中,信号完整性问题往往成为工程师的"隐形杀手"。当DDR4内存接口速率突破2400MHz时,传统时域分析方法已难以捕捉信号在传输过程中的微妙变化。散射参数&…...

3步构建个人知识库:微信读书笔记智能同步终极方案
3步构建个人知识库:微信读书笔记智能同步终极方案 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com/gh_mirrors/ob…...

NsEmuTools:5分钟搞定NS模拟器自动化管理的终极方案
NsEmuTools:5分钟搞定NS模拟器自动化管理的终极方案 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 你是否厌倦了手动安装和更新NS模拟器的繁琐过程?NsEmuTools作为…...
)
别再被防火墙挡在门外!FileZilla Server在Windows下的完整端口放行指南(含被动模式配置)
FileZilla Server在Windows环境下的防火墙配置与端口管理实战 "为什么我的FTP客户端能连接却无法列出目录?"——这是许多初次配置FileZilla Server的用户常遇到的困惑。Windows防火墙就像一位严格的保安,如果不清楚FTP协议的特殊性,…...

DroidCam OBS插件终极指南:零成本将手机变身高清直播摄像头
DroidCam OBS插件终极指南:零成本将手机变身高清直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 还在为专业直播设备价格昂贵而烦恼?想用手机摄像头获得…...

Java 100 天进阶之路 | 从入门到上岗就业 · 完整目录导航
📚 Java 100 天进阶之路 | 从入门到上岗就业 完整目录导航 不背八股文,不堆概念。44篇基础56篇进阶,100天助你达到Java就业水平,从容面对技术面试。 零差评Java教程,从入门到微服务,每篇都有代码、避坑和面…...