【机器学习】数据预处理之数据归一化
数据预处理之数据归一化
- 一、摘要
- 二、数据归一化概念
- 三、数据归一化实现方法
- 3.1 最值归一化方法
- 3.2 均值方差归一化方法
一、摘要
本文主要讲述了数据归一化(Feature Scaling)的重要性及其方法。首先通过肿瘤大小和发现时间的例子,说明了不同量纲特征在距离计算中可能导致偏差,从而引出数据归一化的必要性。接着,介绍了最值归一化(Normalization)的概念和方法,即将数据映射到0-1之间的尺度,并指出其适用于分布有明显边界的情况。最后,还指出了最值归一化的一个缺点,即受异常值影响较大。
二、数据归一化概念
- 归一化是指一种简化计算的方式,将数据经过处理之后限定到一定的范围之内,一般都会将数据限定在[0,1]。数据归一化可以加快算法的收敛速度,而且在后续的数据处理上也会比较方便。
- 数据归一化的重要性:
- 数据归一化是机器学习中非常重要的一步,也称为特征缩放。
- 归一化的目的是使数据在不同特征之间具有相同的尺度,以便更好地进行分类或其他机器学习任务。
- 另外,归一化算法是一种
去量纲的行为,关于量纲对于计算的影响可以举这样一个例子:使用肿瘤大小(厘米)和发现时间(天)作为特征进行分类。

未归一化时,距离计算主要受发现时间影响,因为时间单位的差异导致数据尺度不同。通过调整时间单位为年,可以使得距离计算更准确地反映肿瘤大小的重要性。归一化的作用就是去除这样的量纲给计算带来的影响。
三、数据归一化实现方法
3.1 最值归一化方法
- 最值归一化将数据映射到0到1之间。
- 方法:对每个特征求最大值和最小值,然后使用公式(x - xmin) / (xmax - xmin)进行转换。

- 适用于数据分布有明确边界的情况,如
考试成绩或像素值。 - 缺点:对异常值敏感,可能影响归一化结果。
- 注意事项:
在执行归一化的算法时有一个地方需要注意,因为公式 y=(x-MinValue)/(MaxValueMinValue)的分母是 MaxValue-MinValue,如果某一个字段的最大值和最小值是相同的,会出现分母为零的情况。所以对于字段数据全部相同的情况要加以判断,通常来讲如果当前字段全部相等且为非零数值,就转换为 1 来处理。如果当前字段全部数值都是 0,那就直接保留 0。 - 最值归一化的实现
-
整型向量数据的归一化代码
import numpy as np # 随机生成向量,其中每个向量的数值是0-100,生成100个 x = np.random.randint(0,100,size=100) # 根据最值归一化公式,实现Int类型数据的归一化 # 实现最值归一化公式,返回结果是一个向量,其中每一个元素的值就处于[0,1]之间 (x - np.min(x)) / (np.max(x) - np.min(x))在jupyter中执行结果:

-
浮点型矩阵数据的归一化代码
# 生成50x2的矩阵,其中数值都在0-100之间 X = np.random.randint(0,100,(50,2)) # 将整型的矩阵转成浮点型矩阵 X = np.array(X,dtype=float) # 将X矩阵数据进行最值归一化,由于矩阵的列数是2列,因此分别需要对矩阵的每一列进行最值归一化处理,如有多列,则使用循环即可 for col in range(0,2):# 对X中每列进行最值归一化X[:,col] = (X[:,col] - np.min(X[:,col])) / (np.max(X[:,col]) - np.min(X[:,col])) # 可以将X矩阵归一化之后的数据绘制出来,验证其中每列数值是否处于[0,1]之间 import matplotlib.pyplot as plt plt.scatter(X[:,0],X[:,1]) plt.show()执行结果:

此时,可以看出图中横纵坐标的数值处于[0,1]之间,说明X矩阵的数据已经完成了最值归一化。 -
查看X矩阵中的均值和方差
# 查看X矩阵方差 [(np.std(X[:,col])) for col in range(0,2)] # 查看X矩阵方差 [(np.std(X[:,col])) for col in range(0,2)]执行结果:

-
3.2 均值方差归一化方法
-
均值方差归一化将数据转换为均值为0,方差为1的分布。
-
方法:用每个特征减去均值,再除以方差。

S为方差,Xmean为均值。 -
适用于数据分布没有明确边界的情况,如收入分布。
-
优点:不受异常值影响,使数据分布更加合理。
-
代码实现过:
-
实现步骤及效果:
- 生成随机矩阵并进行均值方差归一化。
- 步骤:求均值和方差,减去均值,再除以方差。
- 结果:
矩阵中的元素不保证在0到1之间,但均值为0,方差为1。
-
编写代码
X = np.random.randint(0,100,(50,2)) X = np.array(X,dtype=float) # 根据均值方差归一化公式,实现X矩阵的均值方差归一化实现代码 for col in range(0,2):X[:,col] = (X[:,col] - np.mean(X[:,col])) / np.std(X[:,col]) # 绘制图像查看效果 plt.scatter(X[:,0],X[:,1]) plt.show()执行效果:

-
查看X矩阵中的均值和方差是否接近或等于0和1:
-
查看X矩阵的每列数据的均值是否接近或等于0
# 通过图像查看并不是很直观,因此,我们查看X矩阵的每列数据的均值是否接近或等于0 [(np.mean(X[:,col])) for col in range(0,2)]执行结果:

浮点数精度限制:计算机在存储和处理浮点数时存在精度限制。不同编程语言和系统对于浮点数的表示遵循 IEEE 754 标准,常见的单精度浮点数(float)通常有大约 7 位十进制有效数字,双精度浮点数(double)大约有 15 - 16 位十进制有效数字。当一个数的绝对值小于计算机所能表示的最小非零浮点数时,就可能会出现下溢情况,计算机可能会将其当作 0 处理。不过, -1.3322676295501878e - 17 一般不会出现这种情况,大多数计算机环境能正常表示它。
实际应用场景的误差容忍度:在许多实际的计算和应用中,我们会设定一个误差范围(也称为容差)。如果一个数的绝对值小于这个容差,就可以将其当作 0 处理。例如,在数值计算、物理模拟等领域,为了简化计算或者忽略极小的误差,常常会这么做。以下是 Python 示例代码,演示了如何根据容差判断一个数是否近似为 0:num = -1.3322676295501878e-17 tolerance = 1e-15 if abs(num) < tolerance:print("在给定容差范围内,该数近似为 0") else:print("该数不等于 0")
-
查看X矩阵的每列数据的方差是否接近或等于1
# 通过图像查看并不是很直观,因此,我们查看X矩阵的每列数据的方差是否接近或等于1 [(np.std(X[:,col])) for col in range(0,2)]执行结果:

-
-
相关文章:
【机器学习】数据预处理之数据归一化
数据预处理之数据归一化 一、摘要二、数据归一化概念三、数据归一化实现方法3.1 最值归一化方法3.2 均值方差归一化方法 一、摘要 本文主要讲述了数据归一化(Feature Scaling)的重要性及其方法。首先通过肿瘤大小和发现时间的例子,说明了不同…...

【专题】2024-2025人工智能代理深度剖析:GenAI 前沿、LangChain 现状及演进影响与发展趋势报告汇总PDF洞察(附原数据表)
原文链接:https://tecdat.cn/?p39630 在科技飞速发展的当下,人工智能代理正经历着深刻的变革,其能力演变已然成为重塑各行业格局的关键力量。从早期简单的规则执行,到如今复杂的自主决策与多智能体协作,人工智能代理…...
)
非递减子序列(力扣491)
这道题的难点依旧是去重,但是与之前做过的子集类问题的区别就是,这里是求子序列,意味着我们不能先给数组中的元素排序。因为子序列中的元素的相对位置跟原数组中的相对位置是一样的,如果我们改变数组中元素的顺序,子序…...

网站快速收录策略:提升爬虫抓取效率
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/102.html 要实现网站快速收录并提升爬虫抓取效率,可以从以下几个方面入手: 一、优化网站结构与内容 清晰的网站结构 设计简洁明了的网站导航,确保爬虫…...

系统思考—自我超越
“人们往往认为是个人的能力限制了他们,但事实上,是组织的结构和惯性思维限制了他们的潜力。”—彼得圣吉 最近和一家行业隐形冠军交流,他们已经是领域第一,老板却依然要求:核心团队都要自我超越,攻坚克难…...

苍穹外卖-菜品分页查询
3. 菜品分页查询 3.1 需求分析和设计 3.1.1 产品原型 系统中的菜品数据很多的时候,如果在一个页面中全部展示出来会显得比较乱,不便于查看,所以一般的系统中都会以分页的方式来展示列表数据。 菜品分页原型: 在菜品列表展示时…...
)
子集II(力扣90)
这道题与子集(力扣78)-CSDN博客 的区别就在于集合中的元素会重复,那么还按照之前的代码来操作就会得到重复的子集,因此这道题的重点就在于去重。需要注意的是,这里的去重指的是在同一层递归中,而在往下递归的子集中可以取重复的元…...
)
user、assistant、system三大角色在大语言模型中的作用(通俗解释)
1 概述 在大语言模型中,通常涉及到三种角色:用户(user)、助手(assistant)和系统(system)。简单来说,和大模型对话其实是三个人的电影。 2 角色定义 2.1 系统…...

LeetCode 3444.使数组包含目标值倍数的最小增量
给你两个数组 nums 和 target 。 在一次操作中,你可以将 nums 中的任意一个元素递增 1 。 返回要使 target 中的每个元素在 nums 中 至少 存在一个倍数所需的 最少操作次数 。 示例 1: 输入:nums [1,2,3], target [4] 输出:…...

2月9日星期日今日早报简报微语报早读
2月9日星期日,农历正月十二,早报#微语早读。 1、2025WTT新加坡大满贯:王楚钦林诗栋获得男双冠军; 2、海南万宁快查快处一起缺斤短两案件:拟罚款5万元,责令停业3个月; 3、四川宜宾市筠连县山体…...

MOSSE目标跟踪算法详解
1. 引言 MOSSE算法(Multi-Object Spectral Tracking with Energy Regularization)是多目标跟踪领域的一座里程碑式成果,被认为是开创性的工作,为后续研究奠定了重要基础。该算法通过创新性地结合频域特征分析与能量正则化方法&am…...

生成式聊天机器人 -- 基于Pytorch + Global Attention + 双向 GRU 实现的SeqToSeq模型 -- 下
生成式聊天机器人 -- 基于Pytorch Global Attention 双向 GRU 实现的SeqToSeq模型 -- 下 训练Masked 损失单次训练过程迭代训练过程 测试贪心解码(Greedy decoding)算法实现对话函数 训练和测试模型完整代码 生成式聊天机器人 – 基于Pytorch Global Attention 双向 GRU 实…...
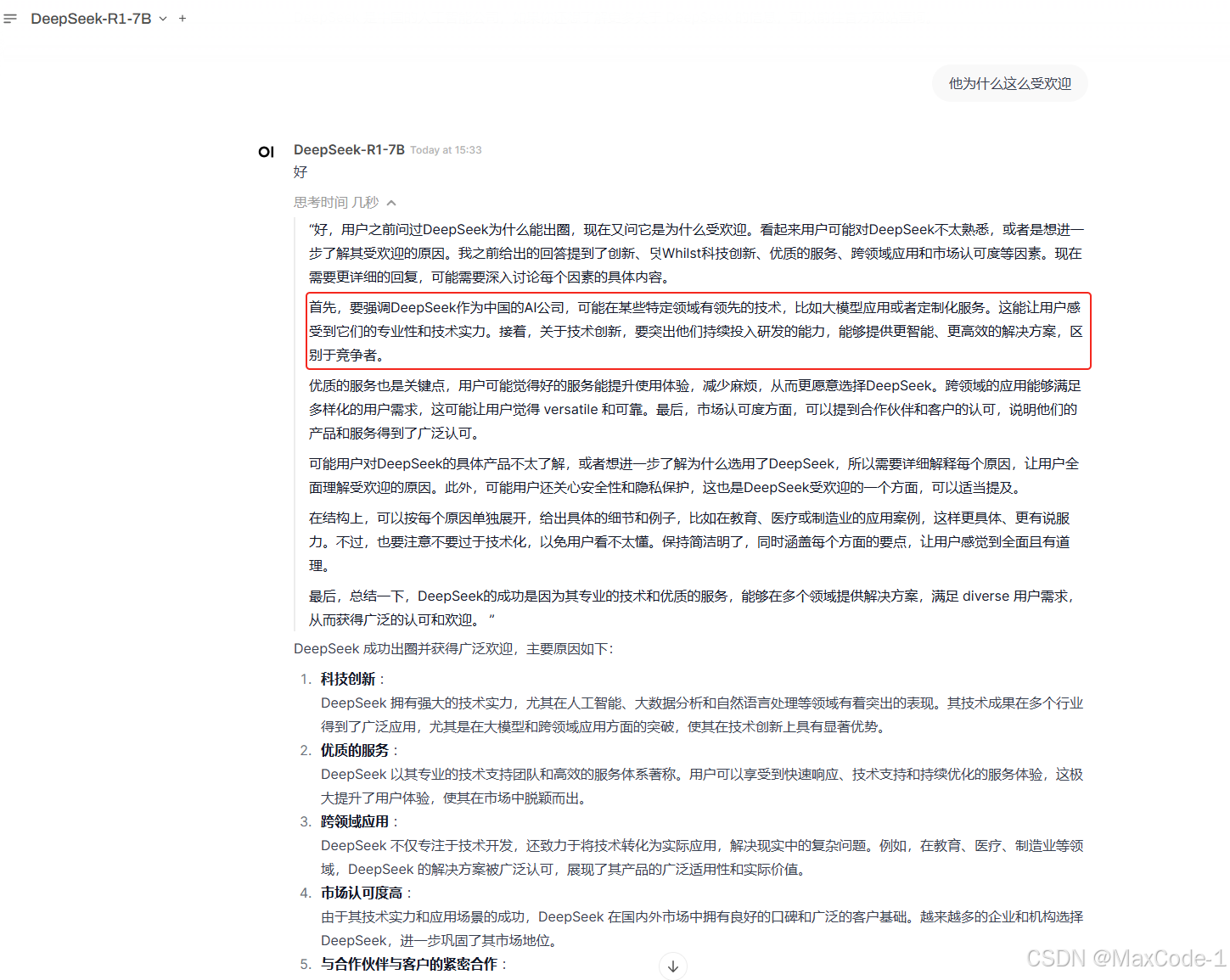
本地部署的DeepSeek-R1-32B与DeepSeek-R1-7B模型效果对比
本地部署的DeepSeek-R1-32B与DeepSeek-R1-7B模型效果对比 在当今人工智能快速发展的时代,大语言模型(Large Language Model, LLM)的应用场景日益广泛。无论是企业级应用还是个人开发,本地部署大语言模型已经成为一种趋势。DeepSeek-R1-32B和DeepSeek-R1-7B作为DeepSeek系列…...

AWS Fargate
AWS Fargate 是一个由 Amazon Web Services (AWS) 提供的无服务器容器计算引擎。它使开发者能够运行容器化应用程序,而无需管理底层的服务器或虚拟机。简而言之,AWS Fargate 让你只需关注应用的容器本身,而不需要管理运行容器的基础设施&…...
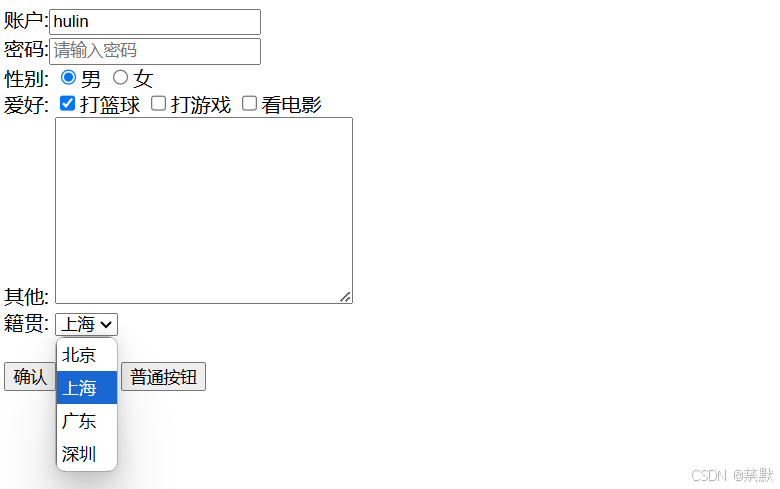
表单与交互:HTML表单标签全面解析
目录 前言 一.HTML表单的基本结构 基本结构 示例 二.常用表单控件 文本输入框 选择控件 文件上传 按钮 综合案例 三.标签的作用 四.注意事项 前言 HTML(超文本标记语言)是构建网页的基础,其中表单(<form>&…...

【电机控制器】STC8H1K芯片——低功耗
【电机控制器】STC8H1K芯片——低功耗 文章目录 [TOC](文章目录) 前言一、芯片手册说明二、IDLE模式三、PD模式四、PD模式唤醒五、实验验证1.接线2.视频(待填) 六、参考资料总结 前言 使用工具: 1.STC仿真器烧录器 提示:以下是本…...

win10 llamafactory模型微调相关① || Ollama运行微调模型
目录 微调相关 1.微调结果评估 2.模型下载到本地 导出转换,Ollama运行 1.模型转换(非常好的教程!) 2.Ollama 加载GGUF模型文件 微调相关 1.微调结果评估 【06】LLaMA-Factory微调大模型——微调模型评估_llamafactory评估-C…...

SMU寒假训练周报
训练情况 本周是第一周,训练情况不是很好,因为从期末周到现在一直没训练,不是在复习就是在忙其他的事情,导致状态下滑很严重,没有什么代码的感觉,而且回家之后的事情也挺多,社会实践的时间有时…...

高并发读多写少场景下的高效键查询与顺序统计的方案思路
之前在某平台看到一篇有意思的场景——对于高并发读多写少场景下,如何进行高效键查询与统计早于其创建时间且没有被删除的数量(只需要先入先出,不需要从中间删元素) 在高并发、读多写少的场景下,业务需求通常聚焦在以…...

Android Studio 配置 Gerrit Code Review
很多大厂(华为、荣耀)的大型项目都有gerrit代码审查流程,那么我们如何实现不手动敲命令行,就在Android Studio中像平常开发一样,只需要用鼠标点点点,就能将代码推送到gerrit审查仓呢,现在就来跟…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...