强化学习 DPO 算法:基于人类偏好,颠覆 PPO 传统策略
目录
- 一、引言
- 二、强化学习基础回顾
- (一)策略
- (二)价值函数
- 三、近端策略优化(PPO)算法
- (一)算法原理
- (二)PPO 目标函数
- (三)代码示例(以 OpenAI Gym 环境 CartPole 为例)
- 四、直接偏好优化(DPO)算法
- (一)算法原理
- (二)DPO 目标函数
- (三)代码示例(简单示意,假设已有偏好数据)
- 五、DPO 与 PPO 对比
- (一)数据利用
- (二)优化目标
- (三)应用场景
- 六、案例分析
- (一)对话系统
- (二)自动驾驶
- 七、结论
一、引言
强化学习在近年来取得了巨大的进展,被广泛应用于机器人控制、游戏、自动驾驶等多个领域。近端策略优化(Proximal Policy Optimization,PPO)算法是强化学习中的经典算法之一,而直接偏好优化(Direct Preference Optimization,DPO)算法则是在其基础上发展而来的一种新算法,它在一些场景下展现出了独特的优势。本文将深入探讨 DPO 算法,通过与 PPO 算法的对比,帮助读者更好地理解这一算法的原理与应用。
二、强化学习基础回顾
在深入了解 DPO 算法之前,我们先来回顾一下强化学习的基本概念。强化学习是智能体(agent)在环境中通过不断试错来学习最优行为策略的过程。智能体根据当前的状态选择一个动作,环境会根据这个动作返回一个奖励和新的状态。智能体的目标是最大化长期累积奖励。
(一)策略
策略(policy)是智能体从状态到动作的映射,通常用 π ( a ∣ s ) \pi(a|s) π(a∣s) 表示在状态 s s s 下选择动作 a a a 的概率。可以把它想象成一个导航仪,根据你当前所处的位置(状态),告诉你应该往哪个方向走(动作)。
(二)价值函数
价值函数(value function)用于评估状态的好坏,分为状态价值函数 V π ( s ) V^{\pi}(s) Vπ(s) 和动作价值函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a) 。
状态价值函数: V π ( s ) = E π [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s ] V^{\pi}(s) = E_{\pi}[\sum_{t=0}^{\infty}\gamma^{t}r_{t}|s_{0}=s] Vπ(s)=Eπ[t=0∑∞γtrt∣s0=s] 其中 γ \gamma γ 是折扣因子, r t r_{t} rt 是在时刻 t t t 获得的奖励。简单来说,它是在当前状态下,按照既定策略行动,未来能获得的所有奖励的总和(考虑了折扣因子,因为越远的奖励对当前决策的影响相对越小)。比如你现在站在一个路口,状态价值函数就代表了你从这个路口出发,按照一定的行走策略,最终能收获的所有 “好处” 的预估。
动作价值函数: Q π ( s , a ) = E π [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s , a 0 = a ] Q^{\pi}(s,a) = E_{\pi}[\sum_{t=0}^{\infty}\gamma^{t}r_{t}|s_{0}=s,a_{0}=a] Qπ(s,a)=Eπ[t=0∑∞γtrt∣s0=s,a0=a] 它评估的是在当前状态下采取某个具体动作后,未来能获得的累积奖励。还是以上述路口为例,动作价值函数就是你在这个路口选择向左转、向右转或者直走等不同动作后,分别能得到的未来奖励总和。
三、近端策略优化(PPO)算法
(一)算法原理
PPO 算法的核心思想是在策略更新时,限制新策略与旧策略之间的差异,以保证策略更新的稳定性。这就好比你在学习骑自行车,你每次尝试的新姿势(新策略)不能和之前已经掌握的姿势(旧策略)相差太大,不然就很容易摔倒(策略不稳定)。它通过重要性采样来估计策略更新的梯度,然后使用截断的目标函数来优化策略。重要性采样可以理解为从旧策略中选取一些有代表性的样本,来指导新策略的更新,就像从过去的骑车经验中挑选一些关键的片段,来帮助你调整当前的骑车姿势。
(二)PPO 目标函数
PPO 使用的目标函数是截断的优势目标函数(clipped surrogate objective): L C L I P ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \mathbb{E}_{t}[\min(r_{t}(\theta)\hat{A}_{t}, \text{clip}(r_{t}(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_{t})] LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中 r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{old}}(a_{t}|s_{t})} rt(θ)=πθold(at∣st)πθ(at∣st) 是重要性采样比, A ^ t \hat{A}_{t} A^t 是估计的优势函数, ϵ \epsilon ϵ 是截断参数。这个公式看起来复杂,但简单来说,就是通过比较新策略和旧策略的采样比,以及优势函数,来确保策略更新在一个合理的范围内(通过截断参数 ϵ \epsilon ϵ 来控制),避免更新幅度过大导致不稳定。
(三)代码示例(以 OpenAI Gym 环境 CartPole 为例)
import gymimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.distributions import Categorical# 定义策略网络class Policy(nn.Module):def __init__(self, state_size, action_size):super(Policy, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.fc2 = nn.Linear(128, action_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return Categorical(logits=x)# 超参数gamma = 0.99epsilon = 0.2learning_rate = 3e-4num_epochs = 10# 初始化环境和策略网络env = gym.make('CartPole-v1')state_size = env.observation_space.shape[0]action_size = env.action_space.npolicy = Policy(state_size, action_size)optimizer = optim.Adam(policy.parameters(), lr=learning_rate)for epoch in range(num_epochs):states, actions, rewards = [], [], []state = env.reset()state = torch.FloatTensor(state)done = Falsewhile not done:states.append(state)dist = policy(state)action = dist.sample()actions.append(action)state, reward, done, _ = env.step(action.item())state = torch.FloatTensor(state)rewards.append(reward)returns = []R = 0for r in rewards[::-1]:R = r + gamma * Rreturns.insert(0, R)returns = torch.FloatTensor(returns)states = torch.stack(states)actions = torch.tensor(actions)old_log_probs = policy(states).log_prob(actions)for _ in range(3):dist = policy(states)log_probs = dist.log_prob(actions)ratios = torch.exp(log_probs - old_log_probs.detach())advantages = returns - policy(states).valuesurr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1 - epsilon, 1 + epsilon) * advantagesloss = -torch.min(surr1, surr2).mean()optimizer.zero_grad()loss.backward()optimizer.step()env.close()
四、直接偏好优化(DPO)算法
(一)算法原理
DPO 算法直接利用人类偏好数据进行策略优化。想象你在学习画画,PPO 算法就像是你根据自己每次画画后的自我评价(环境奖励)来改进绘画技巧;而 DPO 算法则是直接参考老师或者其他专业人士对你画作的评价(人类偏好)来调整绘画方式。它通过构建一个偏好模型,将人类对不同策略产生的轨迹的偏好信息融入到策略更新中,从而使策略更符合人类的期望。
(二)DPO 目标函数
DPO 的目标函数基于 KL 散度来衡量新策略与参考策略之间的差异,同时考虑偏好奖励: L D P O ( θ ) = − E ( s , a ) ∼ π θ [ r p r e f ( s , a ) − α D K L ( π θ ( a ∣ s ) ∣ ∣ π r e f ( a ∣ s ) ) ] L^{DPO}(\theta) = - \mathbb{E}_{(s,a)\sim \pi_{\theta}}[r_{pref}(s,a) - \alpha D_{KL}(\pi_{\theta}(a|s)||\pi_{ref}(a|s))] LDPO(θ)=−E(s,a)∼πθ[rpref(s,a)−αDKL(πθ(a∣s)∣∣πref(a∣s))]
其中, r p r e f ( s , a ) r_{pref}(s,a) rpref(s,a) 是偏好奖励, α \alpha α 是平衡系数, π r e f \pi_{ref} πref 是参考策略。这个公式的意思是,在优化策略时,既要考虑人类偏好奖励(你画画得到的专业评价分数),又要控制新策略与参考策略(比如一些经典的绘画风格)之间的差异不要太大(通过 KL 散度来衡量)。
(三)代码示例(简单示意,假设已有偏好数据)
import torchimport torch.nn as nnimport torch.optim as optim# 假设已有偏好数据 (states, actions, preferences)states = torch.FloatTensor([[1.0, 2.0], [3.0, 4.0]])actions = torch.tensor([0, 1])preferences = torch.FloatTensor([0.8, 0.6])# 定义策略网络class DPO_Policy(nn.Module):def __init__(self, state_size, action_size):super(DPO_Policy, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.fc2 = nn.Linear(128, action_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return nn.functional.softmax(x, dim=-1)state_size = 2action_size = 2policy = DPO_Policy(state_size, action_size)optimizer = optim.Adam(policy.parameters(), lr=3e-4)alpha = 0.1for _ in range(10):dist = policy(states)log_probs = torch.log(dist.gather(1, actions.unsqueeze(1)))ref_dist = torch.FloatTensor([[0.5, 0.5], [0.5, 0.5]]) # 假设参考策略分布kl_divergence = torch.sum(dist * (torch.log(dist) - torch.log(ref_dist)), dim=1)loss = -torch.mean(preferences * log_probs - alpha * kl_divergence)optimizer.zero_grad()loss.backward()optimizer.step()
五、DPO 与 PPO 对比
(一)数据利用
-
PPO:主要利用环境反馈的奖励数据进行策略优化。就像自己独自摸索学习,通过自己的成功和失败来总结经验。
-
DPO:直接利用人类偏好数据,能更好地捕捉人类的意图和价值观。如同有老师指导,直接获取专业的建议和评价。
(二)优化目标
-
PPO:通过截断目标函数来优化策略,关注策略更新的稳定性。强调在学习过程中稳步前进,避免突然的大幅度改变。
-
DPO:基于 KL 散度和偏好奖励,使策略更符合人类偏好。侧重于让学习结果符合专业标准或大众期望。
(三)应用场景
-
PPO:适用于大多数传统强化学习场景,如机器人控制、游戏等。在这些场景中,通过不断试错来优化策略是可行的。
-
DPO:在需要考虑人类偏好的场景中表现出色,如对话系统、推荐系统等。因为这些场景需要符合人类的交流习惯和兴趣偏好。
六、案例分析
(一)对话系统
在对话系统中,PPO 算法可以通过最大化奖励(如用户满意度评分)来优化对话策略。而 DPO 算法可以直接利用人类标注的对话偏好数据,例如人类标注员对不同对话回复的偏好,使对话策略更符合人类期望的交流方式。比如,对于用户询问 “今天天气如何”,PPO 可能通过不断尝试不同回复并根据用户反馈(奖励)来优化回复方式;而 DPO 则可以参考人类标注员认为更自然、更合适的回复,直接向这个方向优化。
(二)自动驾驶
在自动驾驶中,PPO 可以通过优化车辆行驶的安全性和效率相关的奖励来学习驾驶策略。DPO 则可以利用人类专家对不同驾驶行为的偏好,例如对更平稳驾驶行为的偏好,来优化驾驶策略。例如,在遇到红绿灯时,PPO 可能根据通过路口的速度和时间等奖励来决定驾驶动作;DPO 则可以根据人类专家认为更舒适、更安全的驾驶方式(如提前减速、平稳停车等偏好)来调整驾驶策略。
七、结论
DPO 算法作为强化学习中的一种新方法,通过直接利用人类偏好数据,为策略优化提供了新的思路。与传统的 PPO 算法相比,它在一些需要考虑人类因素的场景中具有独特的优势。然而,DPO 算法也面临着一些挑战,如偏好数据的获取和标注成本较高等。未来,随着技术的不断发展,相信 DPO 算法将在更多领域得到应用和改进。
相关文章:

强化学习 DPO 算法:基于人类偏好,颠覆 PPO 传统策略
目录 一、引言二、强化学习基础回顾(一)策略(二)价值函数 三、近端策略优化(PPO)算法(一)算法原理(二)PPO 目标函数(三)代码示例&…...

长安链支撑全国不动产登记数据可信流通
转自人民日报客户端 不动产登记事关亿万企业、家庭的切身利益。促进不动产登记数据安全流通、业务高效协同,是各方持续努力的目标。记者1月7日从国家区块链技术创新中心获悉,我国自主可控、性能领先的区块链软硬件技术体系长安链,支撑自然资…...

GitCode 助力 Dora SSR:开启游戏开发新征程
项目仓库(点击阅读原文链接可直达) https://gitcode.com/ippclub/Dora-SSR 跨越技术藩篱,构建游戏开发乐园 Dora SSR 是一款致力于打破游戏开发技术壁垒的开源游戏引擎。其诞生源于开发者对简化跨平台游戏开发环境搭建的强烈渴望࿰…...

获取 Windows 视频时长的正确方式——Windows Shell API 深度解析
在 Qt 开发中,有时需要获取视频文件的时长,最直接的方法是在 Windows 上使用 Windows Shell API。然而,这涉及到 IShellItem、IPropertyStore 等 COM 组件,并需要正确处理 PKEY_Media_Duration。本篇文章将详细解析 Windows Shell API 获取视频时长的正确实现方式,并解决常…...
)
Linux系统安装Nginx详解(适用于CentOS 7)
目录 1. 更新系统包 2. 安装EPEL仓库 3. 安装Nginx 4. 启动Nginx服务 5. 设置Nginx开机自启 6. 检查Nginx状态 7. 配置防火墙 8. 访问Nginx默认页面 9. 配置Nginx(可选) 10. 重启Nginx 解决步骤 1. 检查系统版本 2. 移除错误的 Nginx 仓库 …...

深入理解Java对接DeepSeek
其实,整个对接过程很简单,就四步,获取key,找到接口文档,接口测试,代码对接。 1.获取 KEY https://platform.deepseek.com/transactions 直接付款就是了(现在官网暂停充值2025年2月7日…...

flutter isolate到底是啥
在 Flutter 中,Isolate 是一种实现多线程编程的机制,下面从概念、工作原理、使用场景、使用示例几个方面详细介绍: 概念 在 Dart 语言(Flutter 开发使用的编程语言)里,每个 Dart 程序至少运行在一个 Isol…...

深入剖析 Apache Shiro550 反序列化漏洞及复现
目录 前言 一、认识 Apache Shiro 二、反序列化漏洞:隐藏在数据转换中的风险 三、Shiro550 漏洞:会话管理中的致命缺陷 四、漏洞危害:如多米诺骨牌般的连锁反应 五、漏洞复现:揭开攻击的神秘面纱 (一࿰…...

计算机毕业设计——Springboot的简历系统
📘 博主小档案: 花花,一名来自世界500强的资深程序猿,毕业于国内知名985高校。 🔧 技术专长: 花花在深度学习任务中展现出卓越的能力,包括但不限于java、python等技术。近年来,花花更…...

【kubernetes组件合集】深入解析Kubernetes组件之三:client-go
深入解析Kubernetes组件之三:client-go 目录 深入解析Kubernetes组件之三:client-go 引言 1. client-go简介 2. client-go的功能 2.1 资源操作 2.2 资源监听 2.3 认证和授权 2.4 错误处理和重试 2.5 扩展性和定制化 3. 使用client-go与Kubern…...

线程池-抢票系统性能优化
文章目录 引言-购票系统线程池购票系统-线程池优化 池化 vs 未池化 引言-购票系统 public class App implements Runnable {private static int tickets 100;private static int users 10000;private final ReentrantLock lock new ReentrantLock(true);public void run() …...

WebSocket 握手过程
文章目录 1. WebSocket 握手过程概述2. 客户端发送握手请求3. 服务器响应握手请求4. 客户端验证握手响应5. 建立 WebSocket 连接6. 安全性与注意事项7. 应用示例 在现代 Web 开发中,WebSocket 协议因其高效的实时通信能力而被广泛应用。WebSocket 允许客户端和服务器…...
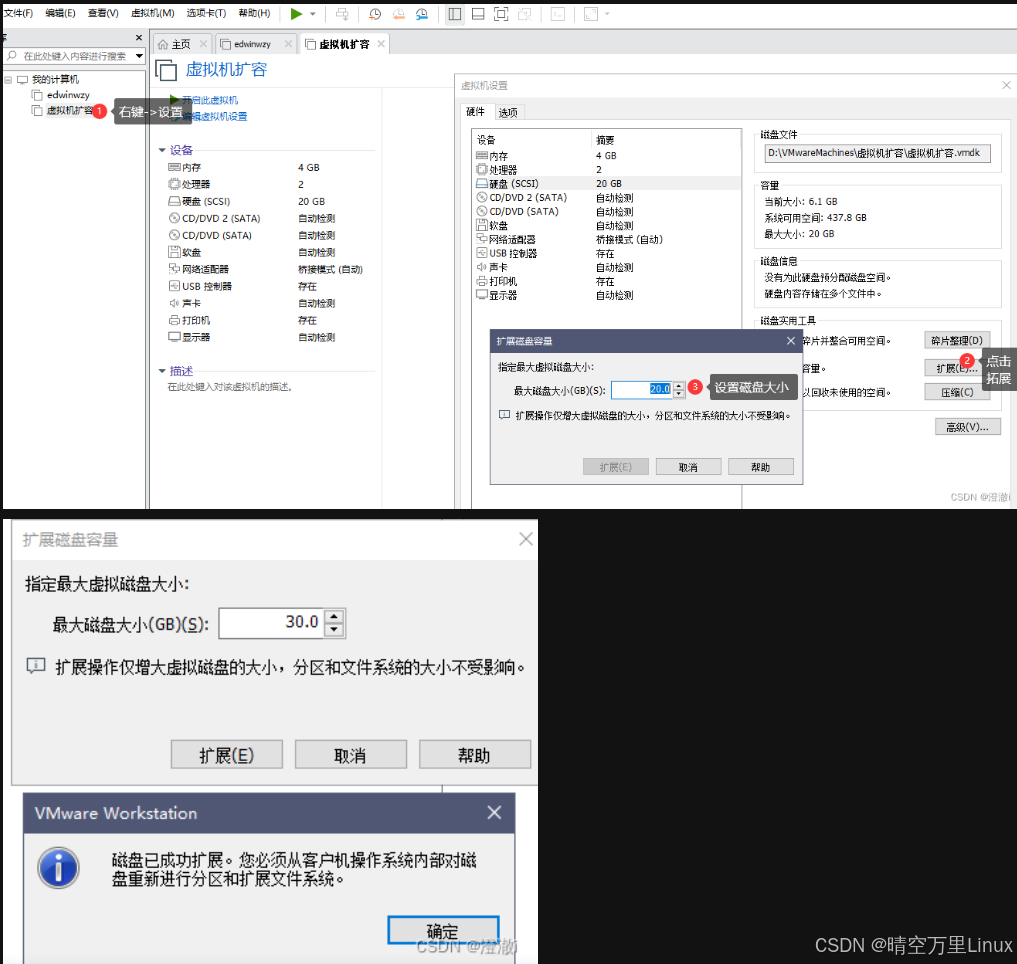
VMware 虚拟机 ubuntu 20.04 扩容工作硬盘
一、关闭虚拟机 关闭虚拟机参考下图,在vmware 调整磁盘容量 二、借助工具fdisk testubuntu ~ $ df -h Filesystem Size Used Avail Use% Mounted on udev 1.9G 0 1.9G 0% /dev tmpfs 388M 3.1M 385M 1% /run /dev/sda5 …...

备战蓝桥杯:二分算法之牛可乐和魔法封印问题
这道题就是一道简单的模板题,我们分析一下!,首先我们要找大于等于x的起始位置 我们还是用两个指针,left指向1,right指向n,如果a[mid]<x left mid1 如果a[mid]>x 就让right mid 如果数组全是小于x…...

普通用户授权docker使用权限
1、检查docker用户组 sudo cat /etc/group |grep docker 若显示:docker:x:999: # 表示存在否则创建docker用户组: sudo groupadd docker2、查看 /var/run/docker.sock 的属性 ll /var/run/docker.sock 显示: srw-rw---- 1 root root 0 1月…...

【实战篇】DeepSeek + ElevenLabs:让人工智能“开口说话”,打造你的专属语音助手!
最近,AI语音合成技术真是火得不行,各种“开口脆”的AI声音层出不穷,听得我直呼“这也太像真人了吧!” 作为一个科技爱好者,我当然不能错过这股潮流,这不,最近就沉迷于用 DeepSeek 和 ElevenLabs 这两款神器,捣鼓各种人声音频,简直停不下来! 先来科普一下这两位“主角…...

Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式
目录 引言 一、ViT模型的起源和历史 二、什么是ViT? 图像处理流程 图像切分 展平与线性映射 位置编码 Transformer编码器 分类头(Classification Head) 自注意力机制 注意力图 三、Coovally AI模型训练与应用平台 四、ViT与图像…...

LabVIEW国内外开发的区别
LabVIEW作为全球领先的图形化编程平台,在国内外工业测控领域均占据重要地位。本文从开发理念、技术生态、应用深度及自主可控性四个维度,对比分析国内外LabVIEW开发的差异,并结合国内实际应用场景,探讨其未来发展趋势。 一、开…...

【并发控制、更新、版本控制】.NET开源ORM框架 SqlSugar 系列
系列文章目录 🎀🎀🎀 .NET开源 ORM 框架 SqlSugar 系列 🎀🎀🎀 文章目录 系列文章目录一、并发累计(累加)1.1 单条批量累计1.2 批量更新并且字段11.3 批量更新并且字段list中对应的…...

淘宝App交易链路终端混合场景体验探索
如何应对产品形态与产品节奏相对确定情况下转变为『在业务需求与产品形态高度不确定性的情况下,如何实现业务交付时间与交付质量的确定性』。我们希望通过混合架构(Native 业务容器 Weex 2.0)作为未来交易终端架构的重要演进方向,…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...
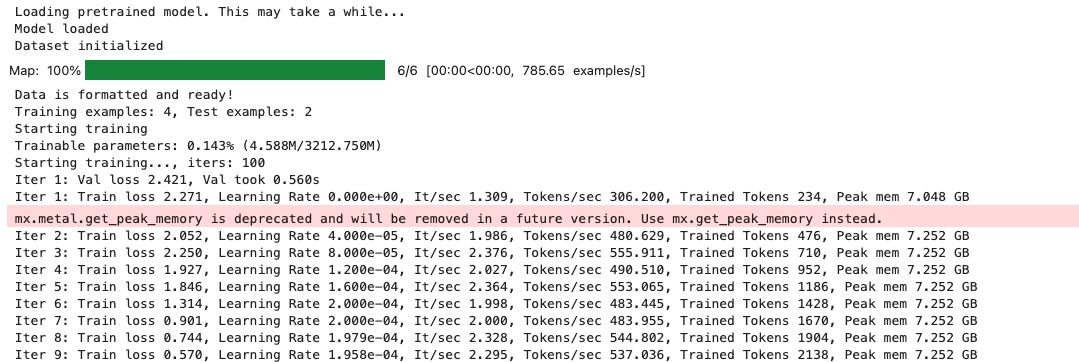
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...