PyTorch 源码学习:从 Tensor 到 Storage
分享自己在学习 PyTorch 源码时阅读过的资料。本文重点关注 PyTorch 的核心数据结构 Tensor 的设计与实现。因为 PyTorch 不同版本的源码实现有所不同,所以笔者在整理资料时尽可能按版本号升序,版本号见标题前[]。最新版本的源码实现还请查看 PyTorch 仓库。更多内容请参考:
- Ubuntu 22.04 LTS 源码编译安装 PyTorch
- pytorch/CONTRIBUTING.md 机翻
- PyTorch 源码学习
- PyTorch 源码学习:阅读经验 & 代码结构
文章目录
- 通过类图理解 Tensor 的设计
- 更多关于 c10::intrusive_ptr_target、TensorImpl 和 StorageImpl 的分析
- 自顶向下探索 Tensor 的实现及内存分配
- aten/src/ATen/CheckpointTensorImpl.cpp
- aten/src/ATen/CheckpointTensorImpl.h
- aten/src/ATen/templates/TensorBody.h
- c10/core/TensorImpl.h
- c10/core/TensorImpl.cpp
- c10/core/Storage.h
- c10/core/StorageImpl.h
- c10/core/Allocator.h
- c10/util/UniqueVoidPtr.h
- c10/cuda/CUDACachingAllocator.h
- c10/cuda/CUDACachingAllocator.cpp
- void* raw_alloc(size_t nbytes);
- void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream);
- raw_delete(void* ptr);
- void* getBaseAllocation(void *ptr, size_t *size);
- 待更新……
通过类图理解 Tensor 的设计
关于类图:UML之类图关系(继承、实现、依赖、关联、聚合、组合)-CSDN博客
下图来源自:[1.0.0] PyTorch的Tensor(上),当作一个简版的类图。该博客写得较早,但也具有很高的参考价值,同系列的博客还有:
- 2019-01-19:PyTorch的编译系统
- 2019-02-14:PyTorch ATen代码的动态生成
- 2019-02-18:PyTorch Autograd代码的动态生成
- 2019-02-27:PyTorch的初始化
- 2019-03-06:PyTorch的Tensor(上)
- 2019-05-11:PyTorch的Tensor(中)
- 2019-06-23:PyTorch的Tensor(下)
- 2019-03-16:PyTorch的cpp代码生成
- 2019-04-22:再谈PyTorch的初始化(上)
- 2019-04-23:再谈PyTorch的初始化(中)
- 2019-04-24:再谈PyTorch的初始化(下)
- 2019-04-30:PyTorch的动态图(上)
- 2019-05-16:PyTorch的动态图(下)
#垂直表示继承,水平表示被包含,()表示为一个类
DataPtr -> StorageImpl -> Storage -> (TensorImpl) -> (Tensor)| |v v(Tensor) -> Variable::Impl Variable -> AutogradMeta -> (TensorImpl)
其中,Storage 和 StorageImpl 之间、TensorImpl 和 Tensor 之间都使用了 Bridge 设计模式。
桥接(Bridge)设计模式是一种结构型设计模式,它旨在将抽象部分与实现部分分离,以便两者可以独立地变化。这样可以使一个类的多个维度变化独立开来,从而减少类之间的耦合度。桥接模式通过使用组合而不是继承的方式来达到这个目的。
Storage和StorageImpl的桥接模式实现:
- 抽象部分(Abstraction):这里是
Storage类。它提供了一个高级别的接口来操作和管理数据存储,但不直接实现存储的细节。- 实现部分(Implementor):这里是
StorageImpl类。它定义了存储的具体实现细节,包括数据类型、数据指针、元素数量等。- 组合关系:
Storage中包含一个指向StorageImpl的智能指针c10::intrusive_ptr<StorageImpl>。这意味着Storage并不直接实现数据存储,而是依赖StorageImpl来实现。storage_impl_是桥接接口(即实现部分)的一个实例,Storage通过它来操作实际的数据存储。使用桥接模式有以下几个好处:
- 分离接口和实现:通过将存储的接口(
Storage)与存储的实现(StorageImpl)分离,允许两者独立变化。例如,可以改变存储实现的细节而不影响存储接口,反之亦然。- 提高灵活性和可扩展性:可以很容易地添加新的存储实现而不改变现有的存储接口。同样,可以扩展存储接口而不改变存储实现。
- 减少耦合度:接口和实现之间的低耦合度提高了代码的可维护性和可测试性。
下图来源自:[1.10.0] [Pytorch 源码阅读] —— Tensor C++相关实现
- 文中有更多关于
c10::intrusive_ptr_target类、TensorImpl类和StorageImpl类源码分析的内容。
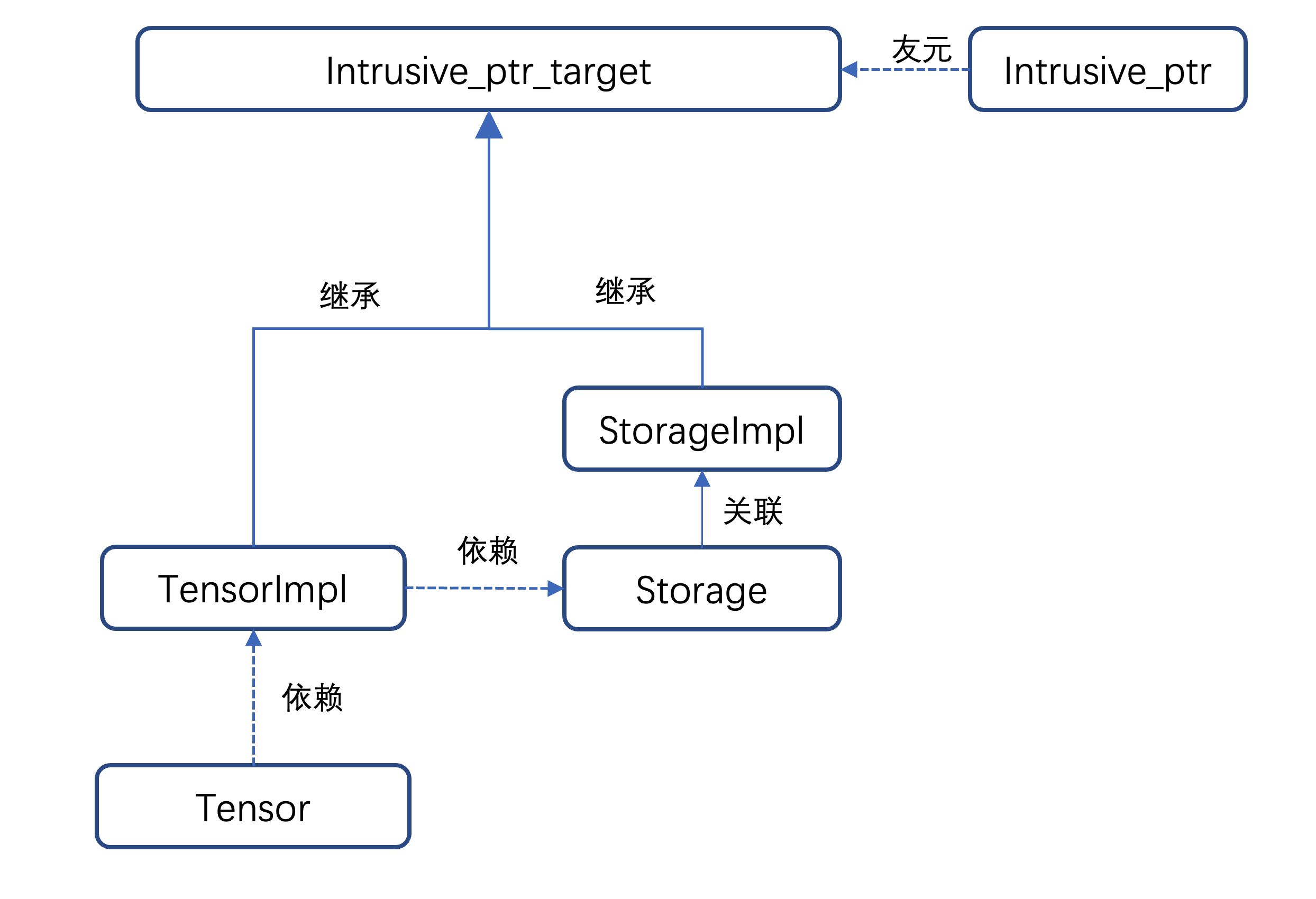
c10::intrusive_ptr的初始化需要intrusive_ptr_target或者其子类。TensorImpl和StorageImpl两个类分别为intrusive_ptr_target的子类,- 然后
StorageImpl主要负责 tensor 的实际物理内存相关的操作,设置空间配置器,获取数据指针,以及占用物理空间大小等; Storage仅仅是对StorageImpl直接包了一下,直接调用的是StorageImpl的相关成员函数。TensorImpl是Tensor类实现的主要依赖类,其初始化就需要依赖Storage类,- 所以上面说:
Tensor=TensorImpl+StorgaeImpl。
下图来源自:[2.0.0] Tensor的组织结构
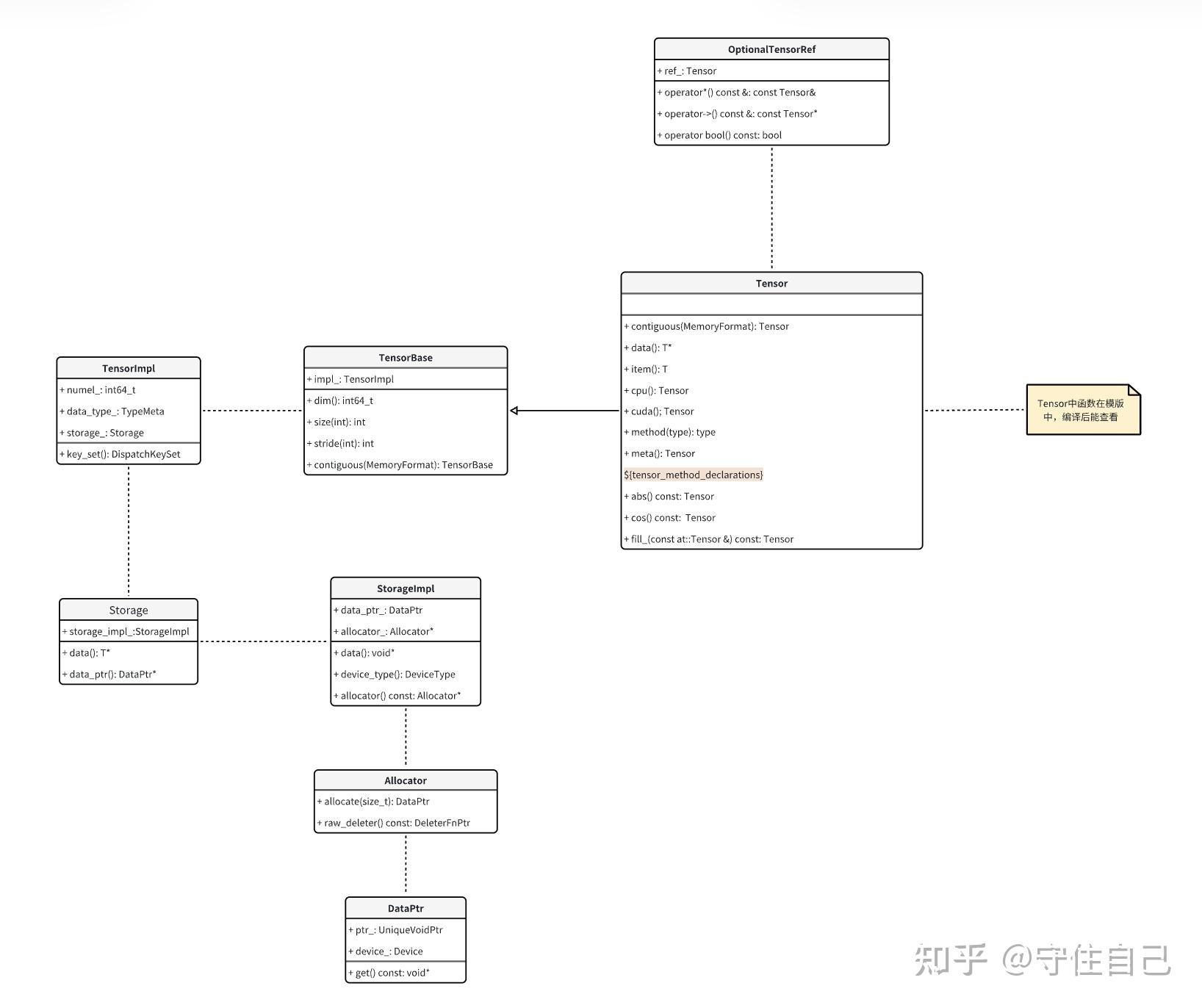
下图来源自:[unknown] pytorch源码学习-Tensor-01
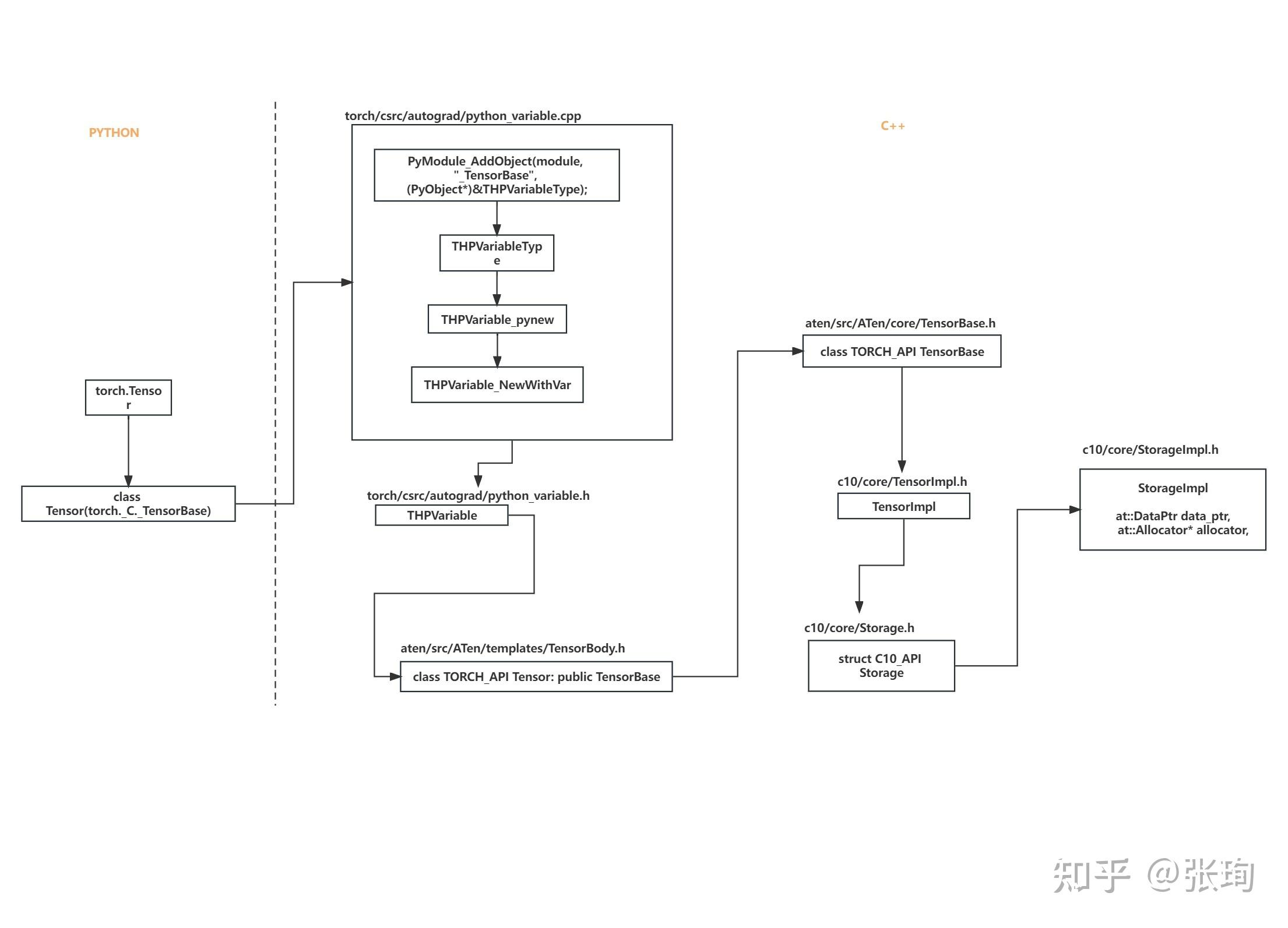
下图来源自:[unknown] Pytorch Tensor/TensorImpl/Storage/StorageImpl,及相关内容:
- pytorch intrusive_ptr
- pytorch Device/DeviceType
- Pytorch TypeMeta

- Tensor, WeakTensor ->
aten/src/ATen/core/Tensor.h - TensorImpl ->
c10/core/TensorImpl.h - Storage ->
c10/core/Storage.h - StorageImpl ->
c10/core/StorageImpl.h - DataPtr, Allocator,AllocatorRegisterer ->
c10/core/Allocator.h - UniqueVoidPtr ->
c10/util/UniqueVoidPtr.h
更多关于 c10::intrusive_ptr_target、TensorImpl 和 StorageImpl 的分析
- Tensor源码分析与复现(1)& Tensor源码分析与复现(2)★★★
- 【翻译】PyTorch中的intrusive_ptr
- pytorch基于intrusive_ptr_target实现的核心数据结构介绍
自顶向下探索 Tensor 的实现及内存分配
下面的内容源于笔者读研期间的课题研究。代码可以参考 DTR 版本的 PyTorch 1.7.0。
从 CheckpointTensorImpl.cpp 里的 memory 函数开始探索
aten/src/ATen/CheckpointTensorImpl.cpp
具体见:aten/src/ATen/CheckpointTensorImpl.cpp
#include <ATen/CheckpointTensorImpl.h> -> aten/src/ATen/CheckpointTensorImpl.h
#include <ATen/Logger.h>
#include <c10/cuda/CUDACachingAllocator.h> -> c10/cuda/CUDACachingAllocator.hinline size_t memory(const Tensor& t) {if (! t.has_storage()) {return 0;}auto& storage = t.storage();size_t res = storage.nbytes();memory_sum += res;memory_max = std::max(memory_max, res);memory_count += 1;return res;
}long current_memory() {auto device_stat = c10::cuda::CUDACachingAllocator::getDeviceStats(0);return device_stat.allocated_bytes[0].current;
}
aten/src/ATen/CheckpointTensorImpl.h
具体见:aten/src/ATen/CheckpointTensorImpl.h
#include <c10/core/Backend.h>
#include <c10/core/MemoryFormat.h>
#include <c10/core/Storage.h> -> c10/core/Storage.h
#include <c10/core/TensorOptions.h>
#include <c10/core/DispatchKeySet.h>
#include <c10/core/impl/LocalDispatchKeySet.h>
#include <c10/core/CopyBytes.h>#include <c10/util/Exception.h>
#include <c10/util/Optional.h>
#include <c10/util/Flags.h>
#include <c10/util/Logging.h>
#include <c10/util/python_stub.h>
#include <c10/core/TensorImpl.h> -> c10/core/TensorImpl.h
#include <ATen/Tensor.h> -> aten/src/ATen/Tensor.h -> aten/src/ATen/templates/TensorBody.h
#include <ATen/ATen.h> -> aten/src/ATen/ATen.h
aten/src/ATen/templates/TensorBody.h
具体见:aten/src/ATen/templates/TensorBody.h
#include <c10/core/Device.h>
#include <c10/core/Layout.h>
#include <c10/core/MemoryFormat.h>
#include <c10/core/QScheme.h>
#include <c10/core/Scalar.h>
#include <c10/core/ScalarType.h>
#include <c10/core/Storage.h> -> c10/core/Storage.h
#include <ATen/core/TensorAccessor.h>
#include <c10/core/TensorImpl.h> -> c10/core/TensorImpl.h
#include <c10/core/UndefinedTensorImpl.h>
#include <c10/util/Exception.h>
#include <c10/util/Deprecated.h>
#include <c10/util/Optional.h>
#include <c10/util/intrusive_ptr.h>
#include <ATen/core/DeprecatedTypePropertiesRegistry.h>
#include <ATen/core/DeprecatedTypeProperties.h>
#include <ATen/core/NamedTensor.h>
#include <ATen/core/QuantizerBase.h>
#include <torch/csrc/WindowsTorchApiMacro.h>class CAFFE2_API Tensor {public:bool defined() const {return impl_;}bool has_storage() const {return defined() && impl_->has_storage();}const Storage& storage() const {return impl_->storage();}void* data_ptr() const {return this->unsafeGetTensorImpl()->data();}template <typename T>T * data_ptr() const;protected:c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl> impl_;
};
c10/core/TensorImpl.h
具体见:c10/core/TensorImpl.h
#include <c10/core/Backend.h>
#include <c10/core/MemoryFormat.h>
#include <c10/core/Storage.h> -> c10/core/Storage.h
#include <c10/core/TensorOptions.h>
#include <c10/core/DispatchKeySet.h>
#include <c10/core/impl/LocalDispatchKeySet.h>
#include <c10/core/CopyBytes.h>#include <c10/util/Exception.h>
#include <c10/util/Optional.h>
#include <c10/util/Flags.h>
#include <c10/util/Logging.h>
#include <c10/util/python_stub.h>struct C10_API TensorImpl : public c10::intrusive_ptr_target {public:/*** Return a reference to the sizes of this tensor. This reference remains* valid as long as the tensor is live and not resized.*/virtual IntArrayRef sizes() const;/*** True if this tensor has storage. See storage() for details.*/virtual bool has_storage() const;/*** Return the underlying storage of a Tensor. Multiple tensors may share* a single storage. A Storage is an impoverished, Tensor-like class* which supports far less operations than Tensor.** Avoid using this method if possible; try to use only Tensor APIs to perform* operations.*/virtual const Storage& storage() const;/*** Return the size of a single element of this tensor in bytes.*/size_t itemsize() const {TORCH_CHECK(dtype_initialized(),"Cannot report itemsize of Tensor that doesn't have initialized dtype ""(e.g., caffe2::Tensor x(CPU), prior to calling mutable_data<T>() on x)");return data_type_.itemsize();}protected:Storage storage_;
};
c10/core/TensorImpl.cpp
具体见:c10/core/TensorImpl.cpp
#include <c10/core/TensorImpl.h> -> c10/core/TensorImpl.hIntArrayRef TensorImpl::sizes() const {return sizes_;
}bool TensorImpl::has_storage() const {return storage_;
}const Storage& TensorImpl::storage() const {return storage_;
}
c10/core/Storage.h
具体见:c10/core/Storage.h
#include <c10/core/StorageImpl.h> -> c10/core/StorageImpl.hstruct C10_API Storage {public:size_t nbytes() const {return storage_impl_->nbytes();}// get() use here is to get const-correctnessvoid* data() const {return storage_impl_.get()->data();}at::DataPtr& data_ptr() {return storage_impl_->data_ptr();}const at::DataPtr& data_ptr() const {return storage_impl_->data_ptr();}at::Allocator* allocator() const {return storage_impl_.get()->allocator();}protected:c10::intrusive_ptr<StorageImpl> storage_impl_;
};
c10/core/StorageImpl.h
具体见:c10/core/StorageImpl.h
#include <c10/core/Allocator.h> -> c10/core/Allocator.h
#include <c10/core/ScalarType.h>#include <c10/util/intrusive_ptr.h>struct C10_API StorageImpl final : public c10::intrusive_ptr_target {public:size_t nbytes() const {return size_bytes_;}at::DataPtr& data_ptr() {return data_ptr_;};const at::DataPtr& data_ptr() const {return data_ptr_;};// TODO: Return const ptr eventually if possiblevoid* data() {return data_ptr_.get();}void* data() const {return data_ptr_.get();}at::Allocator* allocator() {return allocator_;}const at::Allocator* allocator() const {return allocator_;};private:DataPtr data_ptr_;size_t size_bytes_;Allocator* allocator_;
};
c10/core/Allocator.h
具体见:c10/core/Allocator.h
#include <c10/core/Device.h>
#include <c10/util/Exception.h>
#include <c10/util/ThreadLocalDebugInfo.h>
#include <c10/util/UniqueVoidPtr.h> -> c10/util/UniqueVoidPtr.hclass C10_API DataPtr {private:c10::detail::UniqueVoidPtr ptr_;Device device_;public:void* get() const {return ptr_.get();}};struct C10_API Allocator {virtual ~Allocator() = default;virtual DataPtr allocate(size_t n) const = 0;};
c10/util/UniqueVoidPtr.h
具体见:c10/util/UniqueVoidPtr.h
class UniqueVoidPtr {private:// Lifetime tied to ctx_void* data_;std::unique_ptr<void, DeleterFnPtr> ctx_;public:void clear() {ctx_ = nullptr;data_ = nullptr;}void* get() const {return data_;}};
c10/cuda/CUDACachingAllocator.h
具体见:c10/cuda/CUDACachingAllocator.h
#include <c10/cuda/CUDAStream.h>
#include <c10/core/Allocator.h> -> c10/core/Allocator.h
#include <c10/cuda/CUDAMacros.h>
#include <c10/util/Registry.h>namespace CUDACachingAllocator {struct Stat {int64_t current = 0;int64_t peak = 0;int64_t allocated = 0;int64_t freed = 0;
};enum struct StatType : uint64_t {AGGREGATE = 0,SMALL_POOL = 1,LARGE_POOL = 2,NUM_TYPES = 3 // remember to update this whenever a new stat type is added
};typedef std::array<Stat, static_cast<size_t>(StatType::NUM_TYPES)> StatArray;// Struct containing memory allocator summary statistics for a device.
struct DeviceStats {// COUNT: allocations requested by client codeStatArray allocation;// COUNT: number of allocated segments from cudaMalloc().StatArray segment;// COUNT: number of active memory blocks (allocated or used by stream)StatArray active;// COUNT: number of inactive, split memory blocks (unallocated but can't be released via cudaFree)StatArray inactive_split;// SUM: bytes requested by client codeStatArray allocated_bytes;// SUM: bytes reserved by this memory allocator (both free and used)StatArray reserved_bytes;// SUM: bytes within active memory blocksStatArray active_bytes;// SUM: bytes within inactive, split memory blocksStatArray inactive_split_bytes;// COUNT: total number of failed calls to CUDA malloc necessitating cache flushes.int64_t num_alloc_retries = 0;// COUNT: total number of OOMs (i.e. failed calls to CUDA after cache flush)int64_t num_ooms = 0;
};// Struct containing info of an allocation block (i.e. a fractional part of a cudaMalloc)..
struct BlockInfo {int64_t size = 0;bool allocated = false;bool active = false;
};// Struct containing info of a memory segment (i.e. one contiguous cudaMalloc).
struct SegmentInfo {int64_t device = 0;int64_t address = 0;int64_t total_size = 0;int64_t allocated_size = 0;int64_t active_size = 0;bool is_large = false;std::vector<BlockInfo> blocks;
};C10_CUDA_API void* raw_alloc(size_t nbytes);
C10_CUDA_API void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream);
C10_CUDA_API void raw_delete(void* ptr);C10_CUDA_API Allocator* get();
C10_CUDA_API void init(int device_count);
C10_CUDA_API void emptyCache();
C10_CUDA_API void cacheInfo(int dev_id, size_t* cachedAndFree, size_t* largestBlock);
C10_CUDA_API void* getBaseAllocation(void *ptr, size_t *size);
C10_CUDA_API void recordStream(const DataPtr&, CUDAStream stream);
C10_CUDA_API DeviceStats getDeviceStats(int device);
C10_CUDA_API void resetAccumulatedStats(int device);
C10_CUDA_API void resetPeakStats(int device);
C10_CUDA_API std::vector<SegmentInfo> snapshot();C10_CUDA_API std::mutex* getFreeMutex();C10_CUDA_API std::shared_ptr<void> getIpcDevPtr(std::string handle);
} // namespace CUDACachingAllocator
c10/cuda/CUDACachingAllocator.cpp
具体见:c10/cuda/CUDACachingAllocator.cpp
#include <c10/cuda/CUDACachingAllocator.h> -> c10/cuda/CUDACachingAllocator.h#include <c10/cuda/CUDAGuard.h>
#include <c10/cuda/CUDAException.h>
#include <c10/cuda/CUDAFunctions.h>
#include <c10/util/UniqueVoidPtr.h> -> c10/util/UniqueVoidPtr.h
void* raw_alloc(size_t nbytes);
// 实现
void* raw_alloc(size_t nbytes) {if (nbytes == 0) {return nullptr;}int device;C10_CUDA_CHECK(cudaGetDevice(&device));void* r = nullptr;caching_allocator.malloc(&r, device, nbytes, cuda::getCurrentCUDAStream(device));return r;
}---/** allocates a block which is safe to use from the provided stream 从提供的流中分配一个可以安全使用的块* THCCachingAllocator 类的成员函数* 被 void* raw_alloc 调用
*/
void malloc(void** devPtr, int device, size_t size, cudaStream_t stream) {TORCH_INTERNAL_ASSERT(0 <= device && device < device_allocator.size(),"Allocator not initialized for device ",device,": did you call init?");// 调用device_allocator的分配函数,并且把新建的block加入到add_allocated_block中。Block* block = device_allocator[device]->malloc(device, size, stream);add_allocated_block(block);*devPtr = (void*)block->ptr;
}---/*** 被 THCCachingAllocator 类的成员函数 void malloc 调用* DeviceCachingAllocator 类的成员函数
*/
Block* malloc(int device, size_t size, cudaStream_t stream)
{std::unique_lock<std::recursive_mutex> lock(mutex);// process outstanding cudaEventsprocess_events();// 分配512 byte倍数的数据size = round_size(size);// 寻找合适的内存池进行分配auto& pool = get_pool(size);// 根据分配segment分配分配空间const size_t alloc_size = get_allocation_size(size);// 把需要的数据放入params中,尤其是size、alloc_sizeAllocParams params(device, size, stream, &pool, alloc_size, stats);// 设置标志,其中stat_types包括三个标志,分别针对AGGREGATE、SMALL_POOL以及LARGE_POOL,分别有bitset进行赋值(true of false)params.stat_types[static_cast<size_t>(StatType::AGGREGATE)] = true;params.stat_types[static_cast<size_t>(get_stat_type_for_pool(pool))] = true;// 最为核心的部分,包括了四个小部分。bool block_found =// Search pool// 从对应大小的Pool中搜索出>=所需size的数据,并分配。get_free_block(params)// Trigger callbacks and retry search 手动进行一波垃圾回收,回收掉没人用的 Block,再调用 get_free_block|| (trigger_free_memory_callbacks(params) && get_free_block(params))// Attempt allocate// Allocator 在已有的 Block 中找不出可分配的了,就调用 cudaMalloc 创建新的 Block。|| alloc_block(params, false)// Free all non-split cached blocks and retry alloc. 释放所有非分割缓存块并重试分配。// 如果无法分配合理的空间,那么系统会调用free_cached_blocks()函数先将cache释放掉,然后再重新分配。|| (free_cached_blocks() && alloc_block(params, true));// 如果无法重复使用指针,也没有额外的资源分配空间。// 该部分处理分配未成功的部分。如果走到了这里,那程序就意味着没救了,剩下的就只有崩溃。TORCH_INTERNAL_ASSERT((!block_found && params.err != cudaSuccess) || params.block);if (!block_found) {if (params.err == cudaErrorMemoryAllocation) {size_t device_free;size_t device_total;C10_CUDA_CHECK(cudaMemGetInfo(&device_free, &device_total));stats.num_ooms += 1;// "total capacity": total global memory on GPU// "already allocated": memory allocated by the program using the// caching allocator// "free": free memory as reported by the CUDA API// "cached": memory held by the allocator but not used by the program//// The "allocated" amount does not include memory allocated outside// of the caching allocator, such as memory allocated by other programs// or memory held by the driver.//// The sum of "allocated" + "free" + "cached" may be less than the// total capacity due to memory held by the driver and usage by other// programs.//// Note that at this point free_cached_blocks has already returned all// possible "cached" memory to the driver. The only remaining "cached"// memory is split from a larger block that is partially in-use.TORCH_CHECK_WITH(CUDAOutOfMemoryError, false,"CUDA out of memory. Tried to allocate ", format_size(alloc_size), // 使内存分配不足的最后一颗稻草。" (GPU ", device, "; ",format_size(device_total), " total capacity; ", // GPU设备的总显存大小,该值来源于cudaMemGetInfo(&device_free, &device_total),而该函数能返回gpu中的free与total显存的量。format_size(stats.allocated_bytes[static_cast<size_t>(StatType::AGGREGATE)].current)," already allocated; ", // 表示使用cache分配器已经分配的数据的量,对应malloc中的update_stat_array(stats.allocated_bytes, block->size, params.stat_types);format_size(device_free), " free; ", // 为free显存的量format_size(stats.reserved_bytes[static_cast<size_t>(StatType::AGGREGATE)].current)," reserved in total by PyTorch)"); // 表示PyTorch中真正分配与cache后的数据,就是该值减去“已经分配的值(stats.allocated_bytes)”就是暂存在pool中的物理上已经分配但是逻辑上没有被使用的总显存大小。} else {C10_CUDA_CHECK(params.err);}}Block* block = params.block;Block* remaining = nullptr;TORCH_INTERNAL_ASSERT(block);const bool already_split = block->is_split();// block分裂,针对get_free_block以及alloc_block情况(复用cache的指针以及重新分配)if (should_split(block, size)) {remaining = block;// 新建一个block,其大小为size,而不是alloc_size(因为alloc_size实际大小过大,需要分裂)block = new Block(device, stream, size, &pool, block->ptr);// 在原来的block链中间插入新的block,而把原来的block转化为remaining,添加到新block的后面block->prev = remaining->prev;if (block->prev) {block->prev->next = block;}block->next = remaining;remaining->prev = block;remaining->ptr = static_cast<char*>(remaining->ptr) + size;// 将remaining块缩小remaining->size -= size;pool.insert(remaining);if (already_split) {// An already-split inactive block is being shrunk by size bytes.update_stat_array(stats.inactive_split_bytes, -block->size, params.stat_types);} else {// A new split inactive block is being created from a previously unsplit block,// size remaining->size bytes.update_stat_array(stats.inactive_split_bytes, remaining->size, params.stat_types);update_stat_array(stats.inactive_split, 1, params.stat_types);}} else if (already_split) {// An already-split block is becoming activeupdate_stat_array(stats.inactive_split_bytes, -block->size, params.stat_types);update_stat_array(stats.inactive_split, -1, params.stat_types);}block->allocated = true;// active_blocks中存储的是正在使用的block,insert表示将新建立的block插入到这个集合中active_blocks.insert(block);c10::reportMemoryUsageToProfiler(block, block->size, c10::Device(c10::DeviceType::CUDA, device));// 以此保存内存分配次数、内存分配byte大小、正在使用的数据个数、正在使用的数据大小update_stat_array(stats.allocation, 1, params.stat_types);update_stat_array(stats.allocated_bytes, block->size, params.stat_types);update_stat_array(stats.active, 1, params.stat_types);update_stat_array(stats.active_bytes, block->size, params.stat_types);return block;
}---std::mutex mutex;// allocated blocks by device pointer 通过设备指针分配块
// 在缓存分配器中跟踪分配的内存块。
/**
这行代码声明了一个名为 allocated_blocks 的 std::unordered_map 容器。
这个哈希表将 void* 类型的键(在本例中是设备指针,指向分配的内存)映射到 Block* 类型的值
(Block 结构体代表分配的内存块的信息)。
std::unordered_map 基于哈希表实现,提供了平均常数时间复杂度的查找、插入和删除操作。
*/
std::unordered_map<void*, Block*> allocated_blocks;/*** THCCachingAllocator 类的成员函数* 将新分配的内存块添加到 allocated_blocks 哈希表中。** 被 THCCachingAllocator 类的成员函数 void malloc 调用
*/
void add_allocated_block(Block* block) {std::lock_guard<std::mutex> lock(mutex);allocated_blocks[block->ptr] = block;
}
void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream);
// 实现
void* raw_alloc_with_stream(size_t nbytes, cudaStream_t stream) {if (nbytes == 0) {return nullptr;}int device;C10_CUDA_CHECK(cudaGetDevice(&device));void* r = nullptr;// 和 id* raw_alloc(size_t nbytes) 的实现区别在指定 streamcaching_allocator.malloc(&r, device, nbytes, stream); return r;
}
raw_delete(void* ptr);
// void raw_delete(void* ptr); 的实现
void raw_delete(void* ptr) {caching_allocator.free(ptr);
}---/*** THCCachingAllocator 类的成员函数* 被 void raw_delete 调用
*/
void free(void* ptr) {if (!ptr) {return;}Block* block = get_allocated_block(ptr, true /* remove */);if (!block) {AT_ERROR("invalid device pointer: ", ptr);}device_allocator[block->device]->free(block);
}---/*** THCCachingAllocator 的成员函数* 被 void free 调用
*/
Block* get_allocated_block(void *ptr, bool remove=false) {std::lock_guard<std::mutex> lock(mutex);auto it = allocated_blocks.find(ptr);if (it == allocated_blocks.end()) {return nullptr;}Block* block = it->second;if (remove) {allocated_blocks.erase(it);}return block;
}---/*** 被 THCCachingAllocator 的成员函数 void free 调用
*/
void free(Block* block)
{std::lock_guard<std::recursive_mutex> lock(mutex);block->allocated = false;c10::reportMemoryUsageToProfiler(block, -block->size, c10::Device(c10::DeviceType::CUDA, block->device));// 更新全局的记录StatTypes stat_types;stat_types[static_cast<size_t>(StatType::AGGREGATE)] = true;stat_types[static_cast<size_t>(get_stat_type_for_pool(*(block->pool)))] = true;update_stat_array(stats.allocation, -1, {stat_types});update_stat_array(stats.allocated_bytes, -block->size, {stat_types});// 判断stream是不是空的if (!block->stream_uses.empty()) {// stream_uses不是空,则进入insert_events(block);} else {// 是空的进入free_block(block);}
}
void* getBaseAllocation(void *ptr, size_t *size);
// void* getBaseAllocation(void *ptr, size_t *size); 的实现
void* getBaseAllocation(void *ptr, size_t *size)
{return caching_allocator.getBaseAllocation(ptr, size);
}---// THCCachingAllocator 类的成员函数,被 void* getBaseAllocation 调用
void* getBaseAllocation(void* ptr, size_t* outSize)
{Block* block = get_allocated_block(ptr);if (!block) {AT_ERROR("invalid device pointer: ", ptr);}return device_allocator[block->device]->getBaseAllocation(block, outSize);
}---/*** 被 THCCachingAllocator 类的成员函数 void* getBaseAllocation 调用
*/
void* getBaseAllocation(Block* block, size_t* outSize) {std::lock_guard<std::recursive_mutex> lock(mutex);while (block->prev) { // 找到一个 segment 的头指针block = block->prev;}void *basePtr = block->ptr; // 找到了,暂存给 basePtrif (outSize) {size_t size = 0;while (block) {size += block->size;block = block->next;}*outSize = size; // 求的应该是这个 segment 的长度}return basePtr;
}
待更新……
相关文章:
PyTorch 源码学习:从 Tensor 到 Storage
分享自己在学习 PyTorch 源码时阅读过的资料。本文重点关注 PyTorch 的核心数据结构 Tensor 的设计与实现。因为 PyTorch 不同版本的源码实现有所不同,所以笔者在整理资料时尽可能按版本号升序,版本号见标题前[]。最新版本的源码实现还请查看 PyTorch 仓…...

uniapp 使用 鸿蒙开源字体
uniapp vue3 使用 鸿蒙开源字体 我的需求是全局使用鸿蒙字体。 所以: 0. 首先下载鸿蒙字体: 鸿蒙资源 下载后解压,发现里面有几个文件夹: 字体名称说明Sans默认的鸿蒙字体,支持基本的多语言字符(包括字…...

LabVIEW多电机CANopen同步
核心问题与解决方案 通信层配置 节点ID与波特率冲突问题:在多电机系统中,节点ID重复或波特率不匹配常导致通信中断或数据丢失。案例:某3轴贴片机因步科驱动器的默认节点ID均为1,触发了总线仲裁错误。解决方案:通过配置…...

每日定投40刀BTC(2)20250209 - 20250212
行路吟 青山叠叠水迢迢, 步履虽艰志未消。 莫问前程几多苦, 长风破浪自逍遥。...

【LeetCode Hot100 子串】和为 k 的子数组、滑动窗口最大值、最小覆盖子串
子串 1. 和为 k 的子数组题目描述解题思路主要思路步骤 时间复杂度与空间复杂度代码实现 2. 滑动窗口最大值题目描述解题思路双端队列的原理:优化步骤: Java实现 3. 最小覆盖子串题目描述解题思路滑动窗口的基本思路:具体步骤:算法…...

某虚拟页式存储管理系统中有一个程序占8个页面,运行时访问页面的顺序是1,2,3,4,5,3,4,1,6,7,8,7,8,5。假设刚开始内存没有预装入任何页面。
某虚拟页式存储管理系统中有一个程序占8个页面,运行时访问页面的顺序是1,2,3,4,5,3,4,1,6,7,8,7,8,5。假设刚开始内存没有预装入任何页面。 (1) 如果采用LRU调度算法,该程序在得到4块内存空间时,会产生多少次缺页中断?请给出详细…...
)
傅里叶公式推导(三)
文章目录 周期 2L周期T 周期 2L 周期 T 2 L T2L T2L 的傅里叶变换 即 f ( t ) f ( t 2 L ) f(t) f(t2L) f(t)f(t2L) xt2 π \pi π 2 L 2L 2L 原公式 f ( x ) a 0 2 ∑ n 1 ∞ [ a n cos n x b n sin n x ] a 0 1 π ∫ − π π f ( x ) d x a n 1 π ∫…...

Ubuntu 下 nginx-1.24.0 源码分析 - ngx_time_update函数
定义在 src\core\ngx_times.c 中 ngx_time_init 函数后面 void ngx_time_update(void) {u_char *p0, *p1, *p2, *p3, *p4;ngx_tm_t tm, gmt;time_t sec;ngx_uint_t msec;ngx_time_t *tp;struct timeval tv;if (!ngx_trylock(&ngx…...

老牌系统工具箱,现在还能打!
今天给大家分享一款超实用的电脑软硬件检测工具,虽然它是一款比较“资深”的软件,但依然非常好用,完全能满足我们的日常需求。 电脑软硬件维护检测工具 功能强大易用 这款软件非常贴心,完全不需要安装,直接打开就能用…...

mysql error1449解决方法
MySQL Error 1449 错误信息为 “The user specified as a definer (userhost) does not exist”,意思是定义者(创建存储过程、函数、触发器等数据库对象时指定的用户)在当前系统中不存在,从而导致无法正常使用这些对象。以下是针对…...

Notepad++ 中删除所有以 “pdf“ 结尾的行
Notepad 中删除所有以 “pdf” 结尾的行 操作步骤 1.打开文件: 在 Notepad 中打开你需要处理的文本文件。 2.打开查找和替换对话框: 按快捷键 Ctrl F,打开“查找和替换”对话框。 3.启用正则表达式模式: 在对话框的底部…...

归并排序 和 七大算法的总结图
目录 什么是递归排序: 图解: 递归方法: 代码实现: 思路分析: 非递归方法: 思路: 代码实现: 思路分析: 什么是递归排序: 先将数据分解成诺干个序列࿰…...

嵌入式硬件篇---原码、补码、反码
文章目录 前言简介八进制原码、反码、补码1. 原码规则示例问题 2. 反码规则示例问题 3. 补码规则示例优点 4. 补码的运算5. 总结 十六进制原码、反码、补码1. 十六进制的基本概念2. 十六进制的原码规则示例 3. 十六进制的反码规则示例 4. 十六进制的补码规则示例 5. 十六进制补…...

评估多智能体协作网络(MACNET)的性能:COT和AUTOGPT基线方法
评估多智能体协作网络(MACNET)的性能 方法选择:选择COT(思维链,Chain of Thought)、AUTOGPT等作为基线方法。 COT是一种通过在推理过程中生成中间推理步骤,来增强语言模型推理能力的方法,能让模型更好地处理复杂问题,比如在数学问题求解中,展示解题步骤。 AUTOGPT则是…...
洛谷题目: P2398 GCD SUM 题解 (本题较难,省选-难度)
题目传送门: P2398 GCD SUM - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 前言: 本题涉及到 欧拉函数,素数判断,质数,筛法 ,三大知识点,相对来说还是比较难的。 本题要求我们计算 …...

kubernetes-cni 框架源码分析
深入探索 Kubernetes 网络模型和网络通信 Kubernetes 定义了一种简单、一致的网络模型,基于扁平网络结构的设计,无需将主机端口与网络端口进行映射便可以进行高效地通讯,也无需其他组件进行转发。该模型也使应用程序很容易从虚拟机或者主机物…...

AI Agent有哪些痛点问题
AI Agent有哪些痛点问题 目录 AI Agent有哪些痛点问题AI Agent领域有哪些知名的论文缺乏一个将智能多智能体技术和在真实环境中学习的两个适用流程结合起来的统一框架LLM的代理在量化和客观评估方面存在挑战自主代理在动态环境中学习、推理和驾驭不确定性存在挑战AI Agent领域有…...

使用Java爬虫获取京东JD.item_sku API接口数据
在电商领域,商品的SKU(Stock Keeping Unit)信息是运营和管理的关键数据。SKU信息包括商品的规格、价格、库存等,对于商家的库存管理、定价策略和市场分析至关重要。京东作为国内领先的电商平台,提供了丰富的API接口&am…...

华为云+硅基流动使用Chatbox接入DeepSeek-R1满血版671B
华为云硅基流动使用Chatbox接入DeepSeek-R1满血版671B 硅基流动 1.1 注册登录 1.2 实名认证 1.3 创建API密钥 1.4 客户端工具 OllamaChatboxCherry StudioAnythingLLM 资源包下载: AI聊天本地客户端 接入Chatbox客户端 点击设置 选择SiliconFloW API 粘贴1.3创…...

平方数列与立方数列求和的数学推导
先上结论: 平方数列求和公式为: S 2 ( n ) n ( n 1 ) ( 2 n 1 ) 6 S_2(n) \frac{n(n1)(2n1)}{6} S2(n)6n(n1)(2n1) 立方数列求和公式为: S 3 ( n ) ( n ( n 1 ) 2 ) 2 S_3(n) \left( \frac{n(n1)}{2} \right)^2 S3(n)(2n(n1)…...

Codex:不只是程序员的代码助手,更是办公人士的高效伙伴
Codex:不只是程序员的代码助手,更是办公人士的高效伙伴 面向团队协作、文档处理、数据分析和日常执行的智能工作台 当人们谈到 Codex,第一反应往往是“写代码”。这当然是它的强项,但如果只把 Codex 看成程序员的专属工具&#…...

无人机雷达与LiDAR协同监测土壤湿度技术解析
1. 无人机雷达与LiDAR协同监测土壤湿度的技术原理在精准农业领域,土壤湿度监测一直面临着植被遮挡带来的技术挑战。传统的地面传感器网络虽然精度较高,但存在部署成本高、维护困难等问题;而光学遥感又难以穿透茂密的作物冠层。无人机载雷达与…...

【Midjourney 2026审美趋势白皮书】:基于127万组V6–V7生成样本的AI视觉演化模型预测
更多请点击: https://intelliparadigm.com 第一章:Midjourney 2026审美趋势白皮书导论 人工智能图像生成正从“可用”迈向“可策展”阶段。Midjourney v6.5 及其预发布的 Beta-2026 引擎已展现出对文化语境、跨媒介质感与时间性美学的深层建模能力——这…...

汽车产业变革:从颠覆到协作的生态模式与SDV实践
1. 从“颠覆”到“协作”:汽车产业权力格局的深层变革在科技行业浸淫超过二十五年,我经历过三次真正意义上的“颠覆时刻”。第一次是2006年,Luminary Micro推出首款Arm Cortex-M3微控制器,它彻底改变了嵌入式系统的游戏规则。第二…...

3分钟掌握百度网盘秒传技术:彻底解决文件分享失效难题
3分钟掌握百度网盘秒传技术:彻底解决文件分享失效难题 【免费下载链接】rapid-upload-userscript-doc 秒传链接提取脚本 - 文档&教程 项目地址: https://gitcode.com/gh_mirrors/ra/rapid-upload-userscript-doc 在数字化协作时代,百度网盘秒…...

NVIDIA aicr:AI容器运行时核心原理与生产部署指南
1. 项目概述:当AI遇见容器运行时如果你在AI开发或者高性能计算领域摸爬滚打过一段时间,大概率会遇到一个让人头疼的问题:如何高效、稳定地管理那些“胃口”巨大、依赖复杂的AI工作负载?从训练一个大型语言模型到运行一个实时的计算…...

基于Vue 3与Express的私有化ChatGPT Web客户端部署指南
1. 项目概述与核心价值最近在折腾一个自用的AI对话工具,核心需求很简单:想在一个自己完全掌控的界面上,方便地使用大语言模型,比如ChatGPT的API。市面上虽然有很多现成的网页应用,但要么功能太臃肿,要么部署…...

Cloudflare + PlanetScale:在边缘运行全栈应用,数据库也不例外
全栈开发者面对的一道老难题 Cloudflare Workers 解决了计算层的全球分发问题——你的代码跑在 Cloudflare 遍布全球的 300 多个数据中心里,离用户近,启动快,不需要管理任何服务器。 但数据不一样。 数据库天然是"有状态的"&#x…...

QAbstractTableModel进阶实战:构建可编辑数据表格的完整指南
1. 从零理解QAbstractTableModel的核心机制 第一次接触Qt模型视图框架时,很多人会被QAbstractTableModel这个抽象类吓到。但当我真正用它完成第一个可编辑表格后,发现它的设计其实非常优雅。想象你正在开发一个学生管理系统,需要展示包含姓名…...

41《CAN总线报文周期、抖动与实时性分析》
CAN总线基础:从物理层到数据链路层的核心概念 一、一个让我熬夜的CAN问题 去年调试某款车载ECU时遇到个诡异现象:同一批次的控制器,有的在-20℃低温下CAN通信完全正常,有的却频繁丢帧。示波器挂上去一看,显性电平的下降沿斜率明显变缓,从正常的15ns拖到了40ns。查了三天…...