零基础入门机器学习 -- 第十一章机器学习模型的评估与优化
如何判断你的模型到底行不行?
11.1 为什么需要评估模型?
场景设定:信用卡欺诈检测
想象你是ABC银行的风控经理,你每天的工作就是盯着上百万笔交易,防止客户的信用卡被盗刷。
你们银行新推出了一款机器学习模型,专门用来预测哪些交易是欺诈交易,哪些是正常交易。经过几周的训练,模型终于准备上线了!
这天,老板叫你去汇报:
“我们的新模型怎么样?它能帮我们减少多少欺诈?”
你打开电脑,看了看模型的预测结果,自信满满地说:
“老板,我们的模型准确率高达 98.6%!简直完美!”
老板听了一愣,赶紧叫助手去开香槟庆祝。
但是!你的数据科学家同事突然打断了你:
“等等,你只看准确率,真的代表模型好用吗?”
你皱起眉头,心想:
“准确率高不是好事吗?那还要怎么看模型的好坏?”
于是,你们决定深入分析模型的表现。
11.2 机器学习模型的评估指标
在模型评估时,我们不能只看准确率(Accuracy),因为它可能会掩盖问题。我们需要更多评估指标来全面衡量模型的好坏。
在分类任务中,最常用的指标有:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1 分数(F1 Score)
- 混淆矩阵(Confusion Matrix)
我们来看看这些指标在欺诈交易检测中的意义。
1. 准确率(Accuracy):表面上的好成绩
定义: 预测正确的交易占总交易的比例。
实际数据
你们银行的真实交易数据如下:
| 实际情况 | 模型预测:正常交易 | 模型预测:欺诈交易 |
|---|---|---|
| 实际正常交易(9900 笔) | 9800 | 100 |
| 实际欺诈交易(100 笔) | 40 | 60 |
计算公式:

Python 代码:
from sklearn.metrics import accuracy_score# 真实交易情况(0=正常交易,1=欺诈交易)
y_true = [0]*9900 + [1]*100
# 模型的预测结果
y_pred = [0]*9800 + [1]*100 + [0]*40 + [1]*60 # 计算准确率
accuracy = accuracy_score(y_true, y_pred)
print("准确率:", accuracy)
运行结果:
准确率: 0.986
问题:
- 看起来98.6% 的准确率很高,但模型错过了40 笔欺诈交易!
- 如果这些交易是盗刷,每笔 5000 美元,那银行的损失就是 20 万美元!
结论:
准确率并不能告诉我们模型有没有找到所有欺诈交易,也不能告诉我们它有没有误判正常交易。
所以,我们需要更深入的指标。
2. 精确率(Precision):减少误报
定义: 在所有预测为“欺诈交易”的交易中,真正是欺诈交易的比例。
Python 代码:
from sklearn.metrics import precision_score# 计算精确率
precision = precision_score(y_true, y_pred)
print("精确率:", precision)
运行结果:
精确率: 0.375
解释:
- 精确率 = 37.5%,说明模型预测的欺诈交易中,只有 37.5% 是真的欺诈!
- 也就是说,100 笔交易被误报为欺诈,导致 100 名客户打电话投诉:
“我的信用卡为什么被冻结?我只是买了一杯咖啡啊!”
精确率低的后果
- 客服被大量投诉,银行形象受损
- 用户体验变差,客户可能换银行
- 银行可能错失一些高价值客户
精确率低,说明模型“太紧张”,误伤了很多正常交易。
3. 召回率(Recall):别漏掉坏人
定义: 在所有真正的欺诈交易中,模型成功找到的比例。
计算公式:

Python 代码:
from sklearn.metrics import recall_score# 计算召回率
recall = recall_score(y_true, y_pred)
print("召回率:", recall)
运行结果:
召回率: 0.6
解释:
- 召回率 = 60%,说明模型成功识别了 60% 的欺诈交易,但漏掉了 40%!
- 意味着 40 笔真正的欺诈交易被当成了正常交易,让黑客成功盗刷!
召回率低的后果
- 银行损失惨重,黑客能轻松绕过检测
- 如果召回率太低,系统就变得没有意义
- 黑客甚至会利用模型的漏洞,不断攻击银行
召回率低,说明模型“太松了”,让太多欺诈交易漏网。
4. F1 分数(F1 Score):找到最佳平衡
定义: 平衡精确率和召回率,寻找最佳方案。
Python 代码:
from sklearn.metrics import f1_score# 计算 F1 分数
f1 = f1_score(y_true, y_pred)
print("F1 分数:", f1)
运行结果:
F1 分数: 0.4615
解释:
- F1 分数越高,说明模型的精确率和召回率都比较均衡。
- F1 分数低,意味着模型可能“偏科”:
- 精确率高,召回率低:可能漏掉了很多欺诈交易。
- 召回率高,精确率低:可能误判了太多正常交易。
F1 分数是综合评估模型优劣的关键指标。
5. 混淆矩阵(Confusion Matrix):全面分析
Python 代码:
from sklearn.metrics import confusion_matrix# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
print("混淆矩阵:\n", cm)
输出结果:
[[9800 100][ 40 60]]
解读:
- 9800:模型正确预测了 9800 笔正常交易(真负例 TN)。
- 100:模型误判了 100 笔正常交易为欺诈(假正例 FP)。
- 40:模型漏掉了 40 笔欺诈交易(假负例 FN)。
- 60:模型正确预测了 60 笔欺诈交易(真正例 TP)。
混淆矩阵能清楚地展示模型的错误类型,是优化模型的重要工具。
11.3 结论
| 评估指标 | 作用 | 低值的后果 |
|---|---|---|
| 准确率 | 预测正确率 | 掩盖误报和漏报 |
| 精确率 | 误报率低 | 误伤正常用户 |
| 召回率 | 识别欺诈能力 | 黑客可绕过模型 |
| F1 分数 | 平衡误报和漏报 | 低意味着模型表现不稳定 |
最终:
- 不能只看准确率!
- 银行需要既不能误报太多正常用户,也不能漏掉真正的欺诈。
- F1 分数是最好的综合指标!
你现在知道如何评估模型了吗?😉
相关文章:
零基础入门机器学习 -- 第十一章机器学习模型的评估与优化
如何判断你的模型到底行不行? 11.1 为什么需要评估模型? 场景设定:信用卡欺诈检测 想象你是ABC银行的风控经理,你每天的工作就是盯着上百万笔交易,防止客户的信用卡被盗刷。 你们银行新推出了一款机器学习模型&…...

菜鸟之路Day15一一IO流(一)
菜鸟之路Day15一一IO流(一) 作者:blue 时间:2025.2.8 文章目录 菜鸟之路Day15一一IO流(一)0.概述1.初识IO流1.1.什么是IO流?1.2.IO流的作用1.3.IO流的分类 2.IO流的体系结构3.字节输出流的基本…...

动手学Agent——Day2
文章目录 一、用 Llama-index 创建 Agent1. 测试模型2. 自定义一个接口类3. 使用 ReActAgent & FunctionTool 构建 Agent 二、数据库对话 Agent1. SQLite 数据库1.1 创建数据库 & 连接1.2 创建、插入、查询、更新、删除数据1.3 关闭连接建立数据库 2. ollama3. 配置对话…...

JSONObject,TreeUtil,EagelMap,BeanUtil使用
目录 JSONObject的使用 TreeUtil的使用 EagleMap使用 安装 application.yml配置 springboot导入依赖 配置信息 简单使用 如果想获取这个json字符串里面的distance的值 BeanUtil拷贝注意 JSONObject的使用 假如我现在要处理这样的json数据 可以直接使用JSONUtil.parseObj…...

Unity嵌入到Winform
Unity嵌入到Winform Winform工程🌈...

TCP/UDP协议与OSI七层模型的关系解析| HTTPS与HTTP安全性深度思考》
目录 OSI 7层模型每一层包含的协议: TCP和UDP协议: TCP (Transmission Control Protocol): UDP (User Datagram Protocol): 数据包流程图 TCP与UDP的区别: 传输层与应用层的关联 传输层和应用层的关联…...

《Zookeeper 分布式过程协同技术详解》读书笔记-2
目录 zk的一些内部原理和应用请求,事务和标识读写操作事务标识(zxid) 群首选举Zab协议(ZooKeeper Atomic Broadcast protocol)文件系统和监听通知机制分布式配置中心, 简单Demojava code 集群管理code 分布式锁 zk的一…...

缺陷检测之图片标注工具--labme
一、labelme简介 Labelme是开源的图像标注工具,常用做检测,分割和分类任务的图像标注。 它的功能很多,包括: 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注&a…...

机器学习_13 决策树知识总结
决策树是一种直观且强大的机器学习算法,广泛应用于分类和回归任务。它通过树状结构的决策规则来建模数据,易于理解和解释。今天,我们就来深入探讨决策树的原理、实现和应用。 一、决策树的基本概念 1.1 决策树的工作原理 决策树是一种基于…...

请解释一下Standford Alpaca格式、sharegpt数据格式-------deepseek问答记录
1 Standford Alpaca格式 json格式数据。Stanford Alpaca 格式是一种用于训练和评估自然语言处理(NLP)模型的数据格式,特别是在指令跟随任务中。它由斯坦福大学的研究团队开发,旨在帮助模型理解和执行自然语言指令。以下是该格式的…...

ubuntu 安装管理多版本python3 相关问题解决
背景:使用ubuntu 22.04 默认python 未3.10.编译一些模块的时候发现需要降级到python3.9.于是下载安装 下载: wget https://www.python.org/ftp/python/3.9.16/Python-3.9.16.tgz解压与编译 tar -xf Python-3.9.16.tgz cd Python-3.9.16 ./configure -…...

滑动窗口算法篇:连续子区间与子串问题
1.滑动窗口原理 那么一谈到子区间的问题,我们可能会想到我们可以用我们的前缀和来应用子区间问题,但是这里对于子区间乃至子串问题,我们也可以尝试往滑动窗口的思路方向去进行一个尝试,那么说那么半天,滑动窗口是什么…...

Python爬虫实战:股票分时数据抓取与存储 (1)
在金融数据分析中,股票分时数据是投资者和分析师的重要资源。它能够帮助我们了解股票在交易日内的价格波动情况,从而为交易决策提供依据。然而,获取这些数据往往需要借助专业的金融数据平台,其成本较高。幸运的是,通过…...

【设计模式】【行为型模式】访问者模式(Visitor)
👋hi,我不是一名外包公司的员工,也不会偷吃茶水间的零食,我的梦想是能写高端CRUD 🔥 2025本人正在沉淀中… 博客更新速度 👍 欢迎点赞、收藏、关注,跟上我的更新节奏 🎵 当你的天空突…...

基于实例详解pytest钩子pytest_generate_tests动态生成测试的全过程
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 作为一名软件开发人员,你一定深知有效测试策略的重要性,尤其…...

Copilot基于企业PPT模板生成演示文稿
关于copilot创建PPT,咱们写过较多文章了: Copilot for PowerPoint通过文件创建PPT Copilot如何将word文稿一键转为PPT Copilot一键将PDF转为PPT,治好了我的精神内耗 测评Copilot和ChatGPT-4o从PDF创建PPT功能 Copilot for PPT全新功能&a…...

2025百度快排技术分析:模拟点击与发包算法的背后原理
一晃做SEO已经15年了,2025年还有人问我如何做百度快速排名,我能给出的答案就是:做好内容的前提下,多刷刷吧!百度的SEO排名算法一直是众多SEO从业者研究的重点,模拟算法、点击算法和发包算法是百度快速排名的…...

七星棋牌全开源修复版源码解析:6端兼容,200种玩法全面支持
本篇文章将详细讲解 七星棋牌修复版源码 的 技术架构、功能实现、二次开发思路、搭建教程 等内容,助您快速掌握该棋牌系统的开发技巧。 1. 七星棋牌源码概述 七星棋牌修复版源码是一款高度自由的 开源棋牌项目,该版本修复了原版中的多个 系统漏洞&#…...

解锁原型模式:Java 中的高效对象创建之道
系列文章目录 后续补充~~~ 文章目录 一、引言1.1 软件开发中的对象创建困境1.2 原型模式的登场 二、原型模式的核心概念2.1 定义与概念2.2 工作原理剖析2.3 与其他创建型模式的差异 三、原型模式的结构与角色3.1 抽象原型角色3.2 具体原型角色3.3 客户端角色3.4 原型管理器角色…...
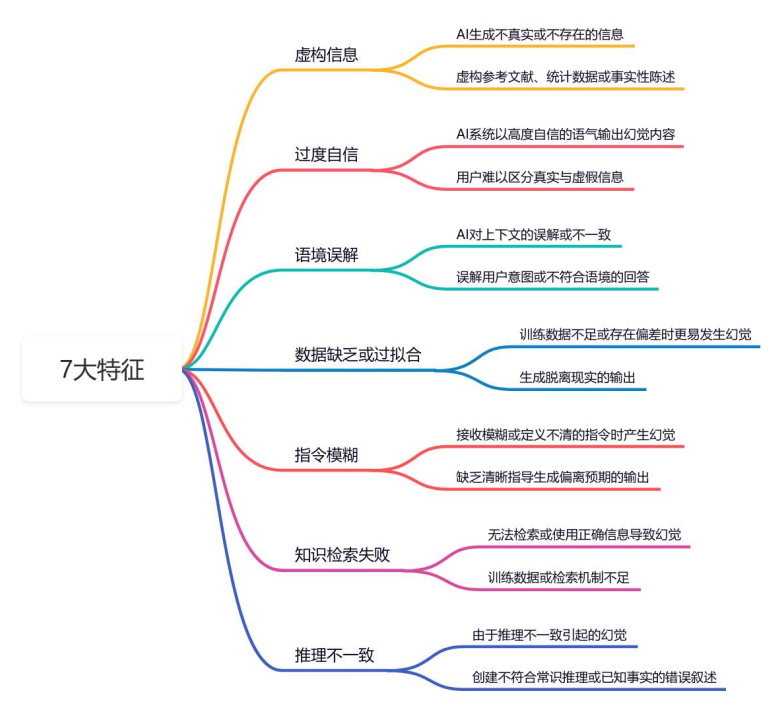
DeepSeek从入门到精通:揭秘 AI 提示语设计误区与 AI 幻觉(新手避坑指南)
文章目录 引言常见陷阱与应对策略:新手必知的提示词设计误区缺乏迭代陷阱:期待一次性完美结果过度指令与模糊指令陷阱:当细节缺乏重点或意图不明确假设偏见陷阱:当前 AI 只听你想听的幻觉生成陷阱:当AI自信地胡说八道忽…...

从账单明细看Taotoken按token计费如何助力项目成本核算
从账单明细看Taotoken按token计费如何助力项目成本核算 1. 项目成本核算的传统痛点 在AI技术深度融入业务系统的今天,模型调用成本往往成为项目财务管理的盲区。传统模式下,团队通常只能获取按月汇总的API支出账单,缺乏细粒度数据支撑成本归…...

终极指南:如何用XInputTest精准测量Xbox控制器轮询性能
终极指南:如何用XInputTest精准测量Xbox控制器轮询性能 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest XInputTest是一款专业的Xbox 360控制器轮询率检测工具&am…...
)
告别龟速推理:手把手教你用TensorRT 8.x加速PyTorch模型(附完整代码)
告别龟速推理:手把手教你用TensorRT 8.x加速PyTorch模型(附完整代码) 当你的PyTorch模型在测试集上表现优异,却在生产环境中遭遇推理延迟时,这种落差感就像赛车手开着F1却跑出了自行车的速度。本文将带你深入TensorRT …...

Fomu FPGA开发板入门:从Verilog到RISC-V软核的渐进式学习指南
1. 从零开始:认识你的Fomu硬件开发板如果你对FPGA(现场可编程门阵列)感兴趣,但又觉得它高深莫测、入门门槛太高,那么Fomu这个小玩意儿可能会彻底改变你的看法。它是一块可以塞进USB接口的FPGA开发板,把整个…...

告别IP飘忽不定!用这个批处理脚本,一键搞定Windows与WSL2 Ubuntu 20.04的固定IP互访
告别IP飘忽不定!用这个批处理脚本,一键搞定Windows与WSL2 Ubuntu 20.04的固定IP互访 每次重启WSL2都要重新配置IP?开发环境总是因为IP变动而中断?这个问题困扰着许多使用WSL2进行开发的程序员。本文将提供一个开箱即用的自动化解…...

Ultimate SD Upscale终极指南:三步掌握AI图像高清放大技术
Ultimate SD Upscale终极指南:三步掌握AI图像高清放大技术 【免费下载链接】ultimate-upscale-for-automatic1111 项目地址: https://gitcode.com/gh_mirrors/ul/ultimate-upscale-for-automatic1111 Ultimate SD Upscale是AUTOMATIC1111 Stable Diffusion …...

One-Token Rollout:LLM监督微调的高效策略梯度方法
1. 项目背景与核心价值在大型语言模型(LLM)的监督微调(SFT)领域,传统方法通常需要完整生成整个序列后才能计算损失函数并进行梯度更新。这种"全序列回传"机制存在两个显著痛点:首先,生…...

如何用BCUninstaller实现Windows批量卸载:新手快速上手指南
如何用BCUninstaller实现Windows批量卸载:新手快速上手指南 【免费下载链接】Bulk-Crap-Uninstaller Remove large amounts of unwanted applications quickly. 项目地址: https://gitcode.com/gh_mirrors/bu/Bulk-Crap-Uninstaller 在Windows系统长期使用过…...

惠普OMEN游戏本性能解锁全攻略:OmenSuperHub深度解析与实战指南
惠普OMEN游戏本性能解锁全攻略:OmenSuperHub深度解析与实战指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方OMEN Gaming …...

如何用layerdivider在3分钟内完成智能图像分层:设计师的终极效率工具
如何用layerdivider在3分钟内完成智能图像分层:设计师的终极效率工具 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾为复杂的插画分…...