分词器(Tokenizer) | 有了分词器,为什么还需要嵌入模型
文章目录
- 什么是tokenizer
- 有了分词器,为什么还需要嵌入模型
- 分词器为什么在transformers 里
- Hugging Face的Tokenizer
- 大模型不同tokenizer训练效果对比
- 分词器库选择
- 当前顶尖大模型所采用的 Tokenizer 方法与词典大小
- 参考
什么是tokenizer
Tokenizers
huggingface官方文档:https://huggingface.co/docs/tokenizers/main/en/index
tokenizer 是NLP 管道的核心组件之一。它们有一个非常明确的目的:将文本转换为模型可以处理的数据。模型只能处理数字,因此tokenizer 需要将我们的文本输入转换为数字。
你应该知道大模型的输入输出的单位是token,Token是使用Tokenizer(翻译为分词器)分词后的结果。Tokenizer是将文本分割成token的工具。
简单来说,Tokenizer 就是将连续的文本拆分成模型能处理的基本单位——Token 的工具,而 “token” 是模型理解和生成文本的最小单位。对于计算机来说,处理原始文本是非常困难的,因此我们需要一个中间层,把文字转换为一系列的数字序列(即,一个个离散的 token),这些 token 既可以是单个字符、词语,也可以是子词(subword)。而这个转换过程正是由 Tokenizer 完成的。
在传统的自然语言处理中,我们可能直接按照单词或字符来分割文本;而在大模型中,常见的方法则是采用子词级别(subword-level)的分割方式。这种方式既能保证足够细致(能够捕捉到拼写变化、罕见词等信息),又不会使得词表过大,进而影响模型的效率和泛化能力。
在中文中,token 通常是单个汉字(或者在某些情况下是常见词汇)。
在英文中,token 通常是一个词或单词的一部分,平均而言大约 4 个字符或 0.75 个单词,但具体拆分方式依赖于采用的 tokenizer 算法。
有了分词器,为什么还需要嵌入模型
尽管 Tokenizer 能够将文本转换为数值索引,但这些索引本身并不包含语义信息。嵌入模型的作用是为这些索引赋予语义,使得模型能够更好地理解和处理文本。
虽然Tokenizer 将文本转换为数值形式,但这些ID还不能直接用于训练大型语言模型(LLM)。在分词和ID化之后,通常还需要通过**嵌入模型(Embedding Model)**将ID映射为稠密的向量表示,这一步是训练LLM的关键部分。
Tokenizer 和嵌入模型是 NLP 流程中的两个关键组件,它们的关系如下:
- Tokenizer:将原始文本分割为单元,并映射为数值索引。
- 嵌入模型:将数值索引转换为语义丰富的向量表示。
- 下游任务:使用嵌入向量作为输入,完成分类、翻译、问答等任务。
典型流程:
- 输入文本:“I love NLP”。
- Tokenizer:[“I”, “love”, “NLP”] → [1, 2, 3]。
- 嵌入模型:[1, 2, 3] → [[0.1, 0.2, …], [0.3, 0.4, …], [0.5, 0.6, …]]。
- 下游任务:使用嵌入向量完成分类、翻译等任务。
嵌入模型的主要任务是将 Tokenizer 生成的数值索引转换为稠密的向量表示,这些向量能够捕捉单词、子词或句子的语义信息。
Tokenizer 和嵌入模型是 NLP 流程中的两个互补组件,它们共同作用,将原始文本转换为计算机可以理解和处理的格式。
总结:分词器-》embedding-》llm
tokenizer库其实就是接收原始数据集中的语料,然后按照一定的规则分开。分词的目的只有一个,那就是为后来的embeding做准备。
分词器为什么在transformers 里
在 transformers 库中,分词器(Tokenizer)是一个核心组件,因为它是将原始文本转换为模型可处理格式的关键步骤。transformers 库由 Hugging Face 开发,旨在为自然语言处理(NLP)任务提供统一的接口,支持多种预训练模型(如 BERT、GPT、T5 等)。
(1)文本预处理标准化
不同的预训练模型使用不同的分词方法(如 BERT 使用 WordPiece,GPT 使用 Byte Pair Encoding,T5 使用 SentencePiece 等)。
transformers 库通过分词器将这些不同的分词方法统一到一个接口中,用户无需关心底层实现细节。
(2)与预训练模型对齐
预训练模型在训练时使用了特定的分词器和词汇表。为了确保模型在推理或微调时表现一致,必须使用相同的分词器。
transformers 库中的分词器与预训练模型一一对应,确保输入格式与模型训练时一致。
(3)支持多种语言和任务
transformers 库支持多种语言和任务(如文本分类、机器翻译、问答等),分词器能够根据任务和语言自动调整分词策略。
(4)高效处理
分词器在 transformers 中经过高度优化,能够快速处理大规模文本数据。
以下是一个使用 transformers 分词器的示例:
from transformers import AutoTokenizer# 加载预训练模型的分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 输入文本
text = "I love NLP!"# 使用分词器处理文本
tokens = tokenizer.tokenize(text) # 分词
input_ids = tokenizer.convert_tokens_to_ids(tokens) # 转换为ID
encoded_input = tokenizer(text) # 直接编码为模型输入格式print("Text:", text)
print("Tokens:", tokens)
print("Input IDs:", input_ids)
print("Encoded Input:", encoded_input)
输出
Text: I love NLP!
Tokens: ['i', 'love', 'nlp', '!']
Input IDs: [1045, 2293, 17953, 999]
Encoded Input: {'input_ids': [101, 1045, 2293, 17953, 999, 102], # 添加了[CLS]和[SEP]'token_type_ids': [0, 0, 0, 0, 0, 0], # 用于区分句子(如BERT)'attention_mask': [1, 1, 1, 1, 1, 1] # 用于标识有效token
}
在 transformers 中,每个预训练模型都有对应的分词器。例如:
- BERT:使用 WordPiece 分词器。
- GPT:使用 Byte Pair Encoding (BPE) 分词器。
- T5:使用 SentencePiece 分词器。
通过 AutoTokenizer,用户可以根据模型名称自动加载对应的分词器,无需手动选择。
Hugging Face的Tokenizer
Hugging Face官方分词器:https://huggingface.co/docs/tokenizers/main/en/index
github:https://github.com/huggingface/tokenizers
Tokenizers 提供了当今最常用的分词器实现,专注于性能和多功能性。这些分词器不仅在研究中使用,还适用于生产环境,具有极快的训练和分词速度,能够在服务器CPU上在20秒内处理1GB的文本。
🤗 Tokenizers provides an implementation of today’s most used tokenizers, with a focus on performance and versatility. These tokenizers are also used in 🤗 Transformers.
huggingface的transform库包含三个核心的类:configuration,models 和tokenizer 。
from transformers import BertTokenizer# 加载预训练的BERT分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 输入文本
text = "I love NLP."# 分词并转换为ID
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)print("Tokens:", tokens)
print("Input IDs:", input_ids)
输出
Tokens: ['i', 'love', 'nlp', '.']
Input IDs: [1045, 2293, 17953, 1012]
大模型不同tokenizer训练效果对比
原文链接:https://zhuanlan.zhihu.com/p/717829515
训练大语言模型之前除了数据收集,还有一个重要的事情是tokenizer的选择,是选择开源的?还是自己根据自己的数据训练一个比较好?
分词器库选择

当前顶尖大模型所采用的 Tokenizer 方法与词典大小
原文链接:https://fisherdaddy.com/posts/introduce-llm-tokenizer/


闭源模型的具体分词细节往往属于商业机密,传闻deepseek的分词器也没有开源,有懂的小伙伴可以评论区留言- -~。
参考
分词器(Tokenizer)详解
参考URL: https://zhuanlan.zhihu.com/p/770595538
Huggingface详细教程之Tokenizer库
参考URL: https://zhuanlan.zhihu.com/p/591335566
相关文章:
分词器(Tokenizer) | 有了分词器,为什么还需要嵌入模型
文章目录 什么是tokenizer有了分词器,为什么还需要嵌入模型分词器为什么在transformers 里Hugging Face的Tokenizer大模型不同tokenizer训练效果对比分词器库选择当前顶尖大模型所采用的 Tokenizer 方法与词典大小 参考 什么是tokenizer Tokenizers huggingface官方…...

VisionTransformer(ViT)与CNN卷积神经网络的对比
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

计算机视觉+Numpy和OpenCV入门
Day 1:Python基础Numpy和OpenCV入门 Python基础 变量与数据类型、函数与类的定义、列表与字典操作文件读写操作(读写图像和数据文件) 练习任务:写一个Python脚本,读取一个图像并保存灰度图像。 import cv2 img cv2.im…...
)
Vue 3 工程化打包工具:从理论到实践 (下篇)
引言 在前端开发中,打包工具是工程化的重要组成部分。Vue 3 作为当前流行的前端框架,其工程化离不开高效的打包工具。打包工具不仅能够将代码、样式、图片等资源进行优化和压缩,还能通过模块化、代码分割等功能提升应用的性能。本文将深入探…...
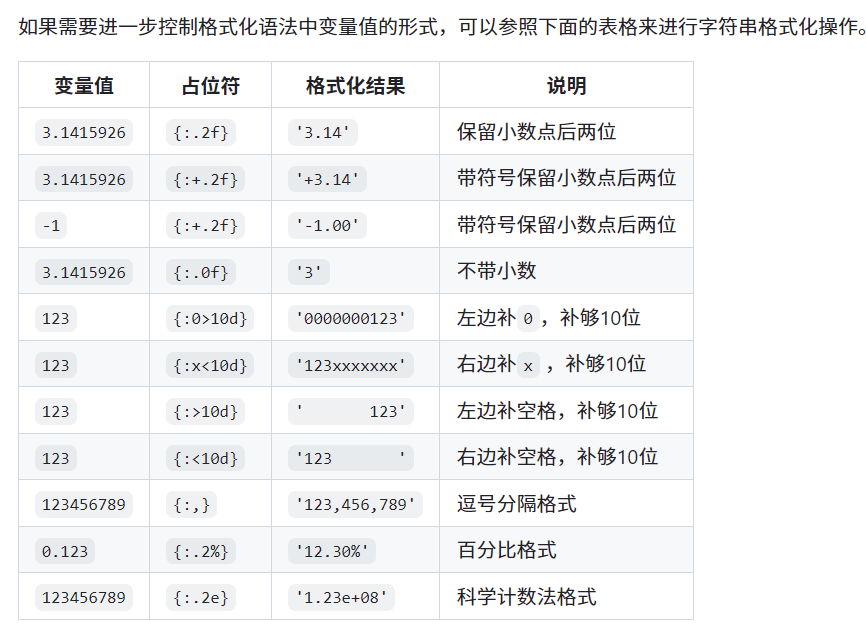
java经验快速学习python!
title: java经验快速学习python! date: 2025-02-19 01:52:05 tags: python学习路线 java经验快速学习python! 本篇文档会一直更新!!!变量、分支结构、循环结构、数据结构【列表、元组、集合字典】python常用内置函数元…...

爬虫破解网页禁止F12
右击页面显示如下 先点击f12再输入网址,回车后没有加载任何数据 目前的一种解决方法: 先 AltD ,再 CtrlShifti...

从零开始构建一个语言模型中vocab_size(词汇表大小)的设定规则
从零开始构建一个语言模型就要设计一个模型框架,其中要配置很多参数。在自然语言处理任务中,vocab_size(词汇表大小) 的设定是模型设计的关键参数之一,它直接影响模型的输入输出结构、计算效率和内存消耗。 本文是在我前文的基础上讲解的:从零开始构建一个小型字符级语言…...

Jenkins插件管理切换国内源地址
安装Jenkins 插件时,由于访问不了国外的插件地址,会导致基本插件都安装失败。 不用着急,等全部安装失败后,进入系统,修改插件源地址,重启后在安装所需插件。 替换国内插件更新地址 选择:系统…...

Q - learning 算法是什么
Q - learning 算法是什么 Q - learning 算法是一种经典的无模型强化学习算法,由克里斯沃特金斯(Chris Watkins)在 1989 年提出。它被广泛应用于解决各种决策问题,尤其适用于智能体在环境中通过与环境交互来学习最优策略的场景。下面从基本概念、核心公式、算法流程和特点几…...

nasm - console 32bits
文章目录 nasm - console 32bits概述笔记my_build.batnasm_main.asm用VS2019写个程序,按照win32方式编译,比较一下。备注END nasm - console 32bits 概述 看到一个nasm的例子(用nasm实现一个32bits控制台的程序架子) 学习一下 笔记 my_build.bat ec…...

11.编写前端内容|vscode链接Linux|html|css|js(C++)
vscode链接服务器 安装VScode插件 Chinese (Simplified) (简体中⽂) Language Pack for Visual Studio CodeOpen in BrowserRemote SSH 在命令行输入 remote-ssh接着输入 打开配置文件,已经配置好主机 点击远程资源管理器可以找到 右键链接 输入密码 …...

【deepseek-r1模型】linux部署deepseek
1、快速安装 Ollama 下载:Download Ollama on macOS Ollama 官方主页:https://ollama.com Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/ 官网提供了一条命令行快速安装的方法。 (1)下载Olla…...

【Github每日推荐】-- 2024 年项目汇总
1、AI 技术 项目简述OmniParser一款基于纯视觉的 GUI 智能体,能够准确识别界面上可交互图标以及理解截图中各元素语义,实现自动化界面交互场景,如自动化测试、自动化操作等。ChatTTS一款专门为对话场景设计的语音生成模型,主要用…...

C++中的.*运算符
看运算符重载的时候,看到这一句 .* :: sizeof ?: . 注意以上5个运算符不能重载。 :: sizeof ?: . 这四个好理解,毕竟都学过,但.*是什么? 于是自己整理了一下 .* 是一种 C 中的运算符,称为指针到成…...
深度学习笔记——LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的LSTM知识点。 文章目录 LSTM(Long Short-Term Memory)LSTM 的核心部件LSTM 的公式和工作原理(1) 遗忘门&a…...

spring boot知识点2
1.spring boot 要开启一些特性,可通过什么方式开启 a.通过Enable注解,可启动定时服务 b.通过application.properties可设置端口号等地址信息 2.什么是热部署,以及spring boot通过什么方式进行热部署 热部署这个概念,我知道。就…...
【机器学习】CNN与Transformer的表面区别与本质区别
仅供参考 表面区别 1. 结构和原理: CNN:主要通过卷积层来提取特征,这些层通过滑动窗口(卷积核)捕捉局部特征,并通过池化层(如最大池化)来降低特征的空间维度。CNN非常适合处理具有网格状拓扑结构的数据,如图像。Transformer:基于自注意力(Self-Attention)机制,能…...
框架篇 - Hearth ArcGIS 框架扩展(DryIoC、Options、Nlog...)
框架篇 - Hearth ArcGISPro Addin 框架扩展(DryIoC、Options、Nlog…) 文章目录 框架篇 - Hearth ArcGISPro Addin 框架扩展(DryIoC、Options、Nlog...)1 使用IoC、DI1.1 服务注册1.1.1 `ServiceAttribute`服务特性1.2 依赖注入1.2.1 SDK底层创建实例类型依赖注入1.2.2 `In…...

JUC并发—7.AQS源码分析三
大纲 1.等待多线程完成的CountDownLatch介绍 2.CountDownLatch.await()方法源码 3.CountDownLatch.coutDown()方法源码 4.CountDownLatch总结 5.控制并发线程数的Semaphore介绍 6.Semaphore的令牌获取过程 7.Semaphore的令牌释放过程 8.同步屏障CyclicBarrier介绍 9.C…...
windows系统本地部署DeepSeek-R1全流程指南:Ollama+Docker+OpenWebUI
本文将手把手教您使用OllamaDockerOpenWebUI三件套在本地部署DeepSeek-R1大语言模型,实现私有化AI服务搭建。 一、环境准备 1.1 硬件要求 CPU:推荐Intel i7及以上(需支持AVX2指令集) 内存:最低16GB,推荐…...

终极指南:iView模态框与下拉菜单的完美焦点控制技巧
终极指南:iView模态框与下拉菜单的完美焦点控制技巧 【免费下载链接】iview A high quality UI Toolkit built on Vue.js 2.0 项目地址: https://gitcode.com/gh_mirrors/iv/iview iView是一个基于Vue.js 2.0构建的高质量UI工具包,提供了丰富的组…...

Manus被禁止外资收购,全球化资本路径在中美科技脱钩下成“钢丝绳”
1. Manus事件迎来最终结论在创始团队沉默了几个月后,Manus事件迎来了最终结论。据国家发改委网站,4月27日,外商投资安全审查工作机制办公室(国家发展改革委)依法依规对外资收购Manus项目作出禁止投资决定,要…...

GLM Coding Plan 的三个版本——Lite、Pro、Max的区别
1. 最核心的区别:你能不能用上最强的 GLM-5 模型? 这是选择 Pro/Max 的首要理由。 Lite 用户:主要使用 GLM-4.7 等模型。这个模型能力已经不错,但相比最新版本有差距。 Pro/Max 用户:可以调用最新的 GLM-5 和 GLM-5.1 …...
)
Instruct-IPT:多任务图像恢复(去雨/去雾/去模糊)
文章目录 Instruct-IPT:多任务图像恢复(去雨/去雾/去模糊) 一、任务 二、环境 三、模型 3.1 权重调制层 3.2 完整 IPT Backbone 四、训练 五、推理 六、结果 All-in-One vs Single-Task 七、消融 八、调试 九、总结 代码链接与详细流程 购买即可解锁1000+YOLO优化文章,并且…...

别光看理论!用LTSPICE亲手仿真一次MOS管的米勒效应,看完波形就懂了
从波形到本质:LTSPICE实战解析MOS管米勒效应的三重境界 当你在示波器上第一次看到那个诡异的栅极电压"小台阶"时,是否曾困惑于这个看似简单的波形背后隐藏的物理奥秘?米勒效应作为电力电子设计中最经典的"幽灵现象"&…...

告别僵硬动画!用UE5.1的IK重定向器,5分钟让你的自定义角色“活”起来
告别僵硬动画!用UE5.1的IK重定向器,5分钟让你的自定义角色“活”起来 在游戏开发或影视动画制作中,一个精心设计的角色模型如果只能僵硬地站立,就像一尊没有灵魂的雕塑。传统动画制作流程往往需要美术师逐帧调整,耗时耗…...

Llama-3.1-Nemotron-8B模型4位量化技术与部署实践
1. 项目概述 "Llama-3.1-Nemotron-Nano-8B-v1-bnb-4bit"这个看似复杂的名称实际上揭示了一个在AI模型量化领域的前沿实践。这个项目名称包含了模型架构、版本迭代、量化方案等关键信息,我们可以将其拆解为以下几个核心部分: Llama-3.1 &…...

Golin:如何用一体化安全工具解决企业等保合规与风险评估双重挑战
Golin:如何用一体化安全工具解决企业等保合规与风险评估双重挑战 【免费下载链接】Golin 弱口令检测、 漏洞扫描、端口扫描(协议识别,组件识别)、web目录扫描、等保工具(网络安全等级保护现场测评工具)内置…...

底层算法逆向揭秘:哪些降重软件可以同时降低查重率和AIGC疑似率?2026高效论文降重方案全解析
【CSDN独家硬核长文 / 年度置顶专栏】 博主身份:CSDN百大实力榜博主 / AI安全与大语言模型(LLM)风控研究员 / 硕博避坑指南星推官 版权声明:本文系2026年毕业压测季的最真实黑盒施压数据,未经授权严禁搬运。这是一场为了保住各位毕业双证的“…...

咖啡烘焙数据可视化平台Artisan:构建专业级烘焙过程控制的革命性方案
咖啡烘焙数据可视化平台Artisan:构建专业级烘焙过程控制的革命性方案 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan Artisan作为全球最受信赖的开源咖啡烘焙软件&…...