深度学习之图像回归(一)
前言
图像回归任务主要是理解一个最简单的深度学习相关项目的结构,整体的思路,数据集的处理,模型的训练过程和优化处理。
因为深度学习的项目思路是差不多的,主要的区别是对于数据集的处理阶段,之后模型训练有一些小的差异。
现在以回归项目进行切入点来理解模型训练的流程。
一 关于整体流程
模型训练的目的是通过训练集进行模型训练 最终得到一个优化后的最佳的模型 帮我们完成对数据的预测 比如根据一个数据的多个描述维度 最终得到标签对应的预测值
整体步骤如下:
-
准备数据(输入 x 和目标 y)。
-
初始化模型参数。
-
用模型预测输出 y^。
-
计算损失值(比如MSE)。
-
用梯度下降更新参数。
-
重复步骤3-5,直到损失值不再下降。
-
用测试数据评估模型性能。
简而言之 就是通过对数据集训练 输入x 然后经过模型训练 得到对应的y 计算loss 梯度回传更新模型 直到算出最好的一项
二 关于数据集处理
代码
class Covid_dataset(Dataset):def __init__(self, file_path, mode): # mode说明数据集是什么类型 训练集还是测试集with open(file_path, "r") as f:csv_data = list(csv.reader(f))data = np.array(csv_data[1:])if mode == "train":indices = [i for i in range(len(data)) if i % 5 != 0]elif mode == "val":indices = [i for i in range(len(data)) if i % 5 == 0]if mode == "test":x = data[:, 1:].astype(float)x = torch.tensor(x)else:x = data[indices, 1:-1].astype(float)x = torch.tensor(x)y = data[indices, -1].astype(float)self.y = torch.tensor(y)self.x = x - x.mean(dim=0, keepdim=True) / x.std(dim=0, keepdim=True)self.mode = modedef __getitem__(self, item):if self.mode == "test":return self.x[item].float() # 测试集没标签。 注意data要转为模型需要的float32型else: # 否则要返回带标签数据return self.x[item].float(), self.y[item].float()def __len__(self):return len(self.x)实现思路

这个类有三个功能函数 分别对应初始化 取出特定的一个元素 计算数据集长度
需要注意的是,数据的处理需要根据训练集 测试集 测试集三个不同的部分进行对应处理
| Index | Feature1 | Feature2 | ... | FeatureN | Label |
|---|---|---|---|---|---|
| 1 | 0.1 | 0.2 | ... | 0.3 | 10 |
| 2 | 0.4 | 0.5 | ... | 0.6 | 20 |
| ... | ... | ... | ... | ... | ... |
-
特征部分:从第二列到倒数第二列(
Feature1到FeatureN)。 -
标签部分:最后一列(
Label)。
如图是一个csv格式的数据
注意事项
1 测试集 训练集 验证集如何划分
对于训练集和验证集 按照4:1的比例进行划分
训练集需要的数据体量比较大 主要是为了保证训练的准确性 验证集比较小
2 测试集 训练集 验证集的特征值和标签
对于测试集
由于测试集主要是在模型训练完成之后评估模型性能的 因此特征值需要提取第二列到最后一列,此时最后一列也作为特征被提取
不需要带标签 因为测试集用来测试模型对未知数据的预测能力 标签是未知的
对于验证集和训练集
需要提取第二列到倒数第二列作为特征值
同时需要提取对应的标签
是否需要标签可以类比成做练习题 训练集是平时训练的题目 验证集是自己做的小测试 都是有答案的 这样可以方便调整 而测试集不带标签可以理解成最后的大考是没有答案的
3 数据的处理
为什么特征值和标签需要处理成张量的形式还需要转换成浮点数
-
转换为张量:是为了与 PyTorch 模型兼容,支持 GPU 加速和自动求导。
-
转换为浮点数:是为了确保数据在数学运算中的精度,支持梯度下降和数据标准化。
4 归一化的原因和方式
归一化(Normalization)是数据预处理中非常重要的一步,尤其是在机器学习和深度学习中。它的目的是将特征值调整到一个统一的范围内,例如 [0, 1] 或 [-1, 1],或者使其符合某种分布(如均值为 0、标准差为 1 的正态分布)。归一化的处理可以显著提高模型的训练效率和性能。
以下是归一化处理的几个主要原因:
1. 加速模型收敛
-
原因:不同的特征可能有不同的量纲和数值范围。例如,一个特征的范围可能是 [0, 1],而另一个特征的范围可能是 [0, 1000]。如果不对这些特征进行归一化,模型在训练时可能会因为特征的数值差异而难以收敛。
-
解释:在梯度下降过程中,数值范围大的特征可能会主导梯度的方向,导致模型的更新方向不准确。通过归一化,所有特征的数值范围被统一,梯度下降的方向更加均衡,从而加速模型的收敛。
2. 提高模型性能
-
原因:归一化可以减少特征之间的数值差异,使模型更容易学习到数据中的模式。
-
解释:对于许多机器学习算法(如线性回归、支持向量机、神经网络等),特征的数值范围会影响模型的权重更新。如果特征的数值范围差异过大,模型可能会对某些特征过于敏感,而忽略其他特征。归一化可以避免这种情况,从而提高模型的性能。
3. 防止数值计算问题
-
原因:在深度学习中,模型的训练过程涉及大量的矩阵运算和梯度计算。如果特征的数值范围过大,可能会导致数值计算问题,如梯度爆炸(Gradient Explosion)或梯度消失(Gradient Vanishing)。
-
解释:
-
梯度爆炸:当数值范围过大时,梯度可能会变得非常大,导致模型的权重更新过大,从而使模型的训练不稳定。
-
梯度消失:当数值范围过小时,梯度可能会变得非常小,导致模型的权重更新过慢,从而使模型难以收敛。
-
通过归一化,可以将特征值调整到一个合理的范围内,避免这些数值计算问题。
4. 提高模型的泛化能力
-
原因:归一化可以减少模型对数据的依赖,使模型更加鲁棒。
-
解释:如果特征的数值范围差异过大,模型可能会过度拟合训练数据中的数值差异,而无法泛化到新的数据。通过归一化,模型可以更好地学习数据中的模式,而不是数值差异,从而提高模型的泛化能力。
5. 常见的归一化方法
-
(1) Min-Max 归一化:
-
将特征值调整到 [0, 1] 范围内:
x_normalized = (x - x_min) / (x_max - x_min) -
优点:简单直观,适用于特征值范围已知的情况。
-
缺点:对异常值敏感,如果数据中存在极端值,可能会导致归一化后的数据范围不均匀。
-
-
(2) Z-Score 标准化:
-
将特征值调整到均值为 0、标准差为 1 的分布:
x_normalized = (x - x_mean) / x_std -
优点:对异常值不敏感,适用于特征值呈正态分布的情况。
-
缺点:如果数据不符合正态分布,归一化后的数据可能仍然存在数值范围差异。
-
-
(3) MaxAbs 归一化:
-
将特征值调整到 [-1, 1] 范围内:
x_normalized = x / max(abs(x)) -
优点:适用于稀疏数据,能够保留数据的稀疏性。
-
缺点:对异常值敏感。
-
6. 总结
归一化处理是机器学习和深度学习中非常重要的一步,它可以帮助:
-
加速模型的收敛。
-
提高模型的性能。
-
防止数值计算问题。
-
提高模型的泛化能力。
归一化的方法选择取决于数据的特性和任务的需求。常见的归一化方法包括 Min-Max 归一化、Z-Score 标准化和 MaxAbs 归一化。
三 关于自定义的神经网络模型

class myModel(nn.Module):def __init__(self, dim):super(myModel, self).__init__()self.fc1 = nn.Linear(dim, 100)self.relu = nn.ReLU()self.fc2 = nn.Linear(100, 1)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)if len(x.size()) > 1:return x.squeeze(1)else:return x关注的问题:
1 模型结构
输入层、隐藏层(带 ReLU 激活函数)、输出层。

参数的计算 以便于帮我们更好地理解模型
维度变化
| 层级 | 维度变化 | 参数计算式 | 参数量 |
|---|---|---|---|
| fc1 | dim → 100 | (dim × 100) + 100 | 10100 |
| fc2 | 100 → 1 | (100 × 1) + 1 | 101 |
| 总计 | 10201 |
本质上是y=wx+b的线性计算
dim对应的是对应的特征值 需要先进行线性运算 映射到一个隐藏层 隐藏层经过ReLU的激活 改变数值的分布 最后ReLU到fc2 继续线性变换后输出 由于是回归任务 因此是预测一个连续值 需要注意的是输出的维度需要统一成一维的
2 激活函数
引入激活函数的原因
-
引入非线性
- 使神经网络能够拟合任意复杂函数
- 无激活函数时多层网络等价于单层线性变换
-
特征空间映射
- 将输入分布映射到特定输出范围(如(0,1)、(-1,1)等)在这个范围内 模型表现比较好
-
梯度调控
- 通过导数控制反向传播的梯度流动
选择ReLU的核心原因
| 优势维度 | 具体表现 | 对比其他激活函数 |
|---|---|---|
| 梯度传导 | 正区间梯度恒为1,避免梯度消失 | Sigmoid最大梯度仅0.25 |
| 计算效率 | 无需指数运算,速度提升约6倍 | Tanh需计算双曲函数 |
| 稀疏激活 | 约50%神经元被抑制,提升特征选择性 | Leaky ReLU保持全激活 |
| 生物学合理 | 近似神经元"全或无"的放电特性 | 更符合生物神经元工作机制 |
3 为什么要这样设计输出层?
-
统一输出形状:
-
在回归任务中,我们希望模型的输出是一个一维张量
[batch_size],而不是二维张量[batch_size, 1]。这样可以方便后续的计算,例如计算损失函数时,损失函数通常期望输入是一维张量。
-
-
兼容不同批量大小:
-
当批量大小为 1 时,模型的输出可能是
[1]而不是[1, 1]。通过这段代码,可以确保无论批量大小是多少,输出的形状始终是一致的。
-
四 关于模型训练

# 训练函数
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):model = model.to(device)# 记录每一轮的损失函数plt_train_loss = []plt_val_loss = []min_val_loss = 9999999999999# 训练for epoch in range(epochs):train_loss = 0.0val_loss = 0.0start_time = time.time()model.train() # 模型调整为训练模式for batch_x, batch_y in train_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x) # 得到预测值train_bat_loss = loss(pred, target)train_bat_loss.backward() # 梯度回传 更新模型optimizer.step()optimizer.zero_grad() # 清零 训练完一轮了train_loss += train_bat_loss.cpu().item()plt_train_loss.append(train_loss / train_loader.dataset.__len__())# 验证 model.eval()with torch.no_grad():for batch_x, batch_y in val_loader:x, target = batch_x.to(device), batch_y.to(device)pred = model(x) # 得到预测值val_bat_loss = loss(pred, target)val_loss += val_bat_loss.cpu().item()plt_val_loss.append(val_loss/val_loader.__len__())# 保存结果if val_loss < min_val_loss:torch.save(model, save_path)min_val_loss = val_lossprint('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f' % \(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1])) # 打印训练结果。 注意python语法, %2.2f 表示小数位为2的浮点数, 后面可以对应。# 画图plt.plot(plt_train_loss)plt.plot(plt_val_loss)plt.title("loss图")plt.legend(["train", "val"])plt.show()关于反向传播
因为模型不可能一次训练就得到最优秀的结果 因此需要根据训练结果动态更新 最后得到的一个观测值 计算与标签的loss之后 可以通过反向求导计算梯度 之后利用梯度下降算法进行更新 直到表现最优秀
关于验证集
验证集不需要进行梯度更新 只有训练的时候需要
(1) 验证集的作用是评估模型
-
验证集用于评估模型在未见过的数据上的表现,而不是用于训练模型。如果在验证集上更新梯度,模型会逐渐适应验证集的数据,这违背了验证集的初衷。
-
验证集的核心目标:评估模型的泛化能力,确保模型在新的、未见过的数据上仍然表现良好。
(2) 防止过拟合
-
如果在验证集上更新梯度,模型可能会逐渐过拟合验证集的数据,导致模型在训练集和验证集上表现良好,但在真实数据上表现不佳。
-
过拟合:模型对训练数据(包括验证集)拟合得过于完美,但在新数据上表现差。
(3) 保持模型的独立性
-
验证集应该保持独立性,即模型在验证集上的表现应该反映其在真实数据上的表现。
-
如果在验证集上更新梯度,模型会逐渐依赖验证集的数据,失去独立性。
五 关于模型测试
这段代码实现了一个完整的测试流程,包括:
-
加载模型:从指定路径加载训练好的模型。
-
测试阶段:对测试数据进行预测,并将预测结果存储到列表中。
-
保存结果:将预测结果保存到一个 CSV 文件中,格式为
[id, 预测值]。
def evaluate(save_path, device, test_loader, rel_path):model = torch.load(save_path).to(device)rel = []with torch.no_grad():for x in test_loader:pred = model(x.to(device))rel.append(pred.cpu().item())print(rel)with open(rel_path, "w", newline='') as f:csvWtiter = csv.writer(f)csvWtiter.writerow(["id", "test_positive"])for i, value in enumerate(rel):csvWtiter.writerow([str(i), str(rel[i])])print("文件已经保存到{}".format(rel_path))
六 关于超参数的设置
device = "cuda" if torch.cuda.is_available() else "cpu"train_file = "covid.train.csv"
test_file = "covid.test.csv"train_data = Covid_dataset(train_file, "train")
val_data = Covid_dataset(train_file, "val")
test_data = Covid_dataset(train_file, "test")train_loader = DataLoader(train_data, batch_size=16, shuffle=True)
val_loader = DataLoader(val_data, batch_size=16, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1, shuffle=False) # 测试集的batchsize一般为1 且不可以打乱dim = 93config = {"lr": 0.001,"momentum": 0.9,"epochs": 20,"save_path": "model_save/model.pth","rel_path": "pred.csv"
}model = myModel(dim)loss = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"]) # 优化器train_val(model, train_loader, val_loader, device, config["epochs"], optimizer, loss, config["save_path"])evaluate(config["save_path"], device, test_loader, config["rel_path"])在这段代码中,超参数(Hyperparameters)是用于控制模型训练过程和行为的关键参数。它们在训练开始之前需要手动设置,并对模型的性能和训练效率有重要影响。以下是对代码中涉及的超参数的详细解释:
1. 设备选择(Device)
device = "cuda" if torch.cuda.is_available() else "cpu"-
超参数:
device -
作用:指定模型和数据运行的设备。
-
解释:
-
如果 GPU(CUDA)可用,则使用
"cuda",否则使用"cpu"。 -
使用 GPU 可以显著加速模型的训练和推理过程。
-
2. 数据加载器(DataLoader)
train_loader = DataLoader(train_data, batch_size=16, shuffle=True)
val_loader = DataLoader(val_data, batch_size=16, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1, shuffle=False)-
超参数:
-
batch_size:每个批次的样本数量。 -
shuffle:是否在每个 epoch 开始时随机打乱数据。
-
-
作用:
-
batch_size:-
控制每次传递给模型的数据量。
-
较大的
batch_size可以提高训练效率,但会增加内存消耗。 -
较小的
batch_size可以减少内存消耗,但可能需要更多的迭代次数。
-
-
shuffle:-
在训练和验证阶段,通常将数据打乱以防止模型学习到数据的顺序。
-
在测试阶段,通常不打乱数据,以保持预测结果的顺序。
-
-
3. 模型参数
dim = 93
model = myModel(dim)-
超参数:
dim -
作用:输入特征的维度。
-
解释:
-
dim是输入数据的特征数量,用于初始化模型的输入层。 -
在这个例子中,输入特征的维度是 93。
-
4. 训练配置(Config)
Python复制
config = {"lr": 0.001,"momentum": 0.9,"epochs": 20,"save_path": "model_save/model.pth","rel_path": "pred.csv"
}-
超参数:
-
lr(Learning Rate):学习率,控制参数更新的步长。-
较大的学习率可能导致模型训练不稳定,较小的学习率可能导致训练速度过慢。
-
-
momentum:动量因子,用于加速梯度下降过程,防止震荡。-
动量可以帮助优化器跳出局部最小值,加速收敛。
-
-
epochs:训练的总轮数。-
较多的轮数可以提高模型性能,但可能导致过拟合。
-
-
save_path:保存最佳模型的路径。 -
rel_path:保存预测结果的路径。
-
5. 损失函数和优化器
loss = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])-
超参数:
-
损失函数(Loss Function):
-
nn.MSELoss():均方误差损失函数,适用于回归任务。
-
-
优化器(Optimizer):
-
optim.SGD:随机梯度下降优化器。 -
lr:学习率。 -
momentum:动量因子。
-
-
6. 测试阶段
evaluate(config["save_path"], device, test_loader, config["rel_path"])-
超参数:
-
test_loader的batch_size设为 1,因为测试集通常逐个样本进行预测。 -
shuffle=False,以保持预测结果的顺序。
-
总结
在这段代码中,涉及的超参数包括:
-
设备选择:
device。 -
数据加载器:
-
batch_size:控制每个批次的样本数量。 -
shuffle:是否随机打乱数据。
-
-
模型参数:
-
dim:输入特征的维度。
-
-
训练配置:
-
lr:学习率。 -
momentum:动量因子。 -
epochs:训练的总轮数。 -
save_path:保存模型的路径。 -
rel_path:保存预测结果的路径。
-
-
损失函数和优化器:
-
损失函数:
nn.MSELoss()。 -
优化器:
optim.SGD。
-
七 最后的结果展示

训练效果良好 损失快速下降并趋于平稳 没有明显的过拟合现象 模型在训练集和验证集上的表现都较为理想
相关文章:
深度学习之图像回归(一)
前言 图像回归任务主要是理解一个最简单的深度学习相关项目的结构,整体的思路,数据集的处理,模型的训练过程和优化处理。 因为深度学习的项目思路是差不多的,主要的区别是对于数据集的处理阶段,之后模型训练有一些小…...
)
Docker 替换到 Containerd (nerdctl相关指令)
因为docker不给用了,所以使用Containerd来代替 前置准备 安装 Containerd # 安装 containerd yum install -y yum-utils yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo yum install -y containerd.io # 生成默认配置文件 mkdir -p…...

Ollama API 参考文档
文档来源:API 参考文档 -- Ollama 中文文档|Ollama官方文档 端点 生成完成生成聊天完成创建模型列出本地模型显示模型信息复制模型删除模型拉取模型推送模型生成嵌入列出正在运行的模型版本...

PHP房屋出租出售高效预约系统小程序源码
🏠 房屋出租出售高效预约系统 —— 您的智能找房新选择 💡 这是一款集智慧与匠心于一体的房屋出租出售预约系统,它巧妙地融合了ThinkPHP与Uniapp两大先进框架,精心打造而成。无论是小程序、H5网页,还是APP端ÿ…...

学习threejs,使用MeshBasicMaterial基本网格材质
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.MeshBasicMaterial 二…...

Kafka Connect 功能介绍
Kafka Connect 是一款用于在 Apache Kafka 和其他系统之间进行数据传输的工具,它提供了以下功能: 1. 通用框架 标准化集成:Kafka Connect 提供了一个通用框架,用于将其他数据系统与 Kafka 集成,简化了连接器的开发、部署和管理。支持多种数据系统:可以快速定义连接器,将…...

从卡顿到丝滑:火山引擎DeepSeek-R1引领AI工具新体验
方舟大模型体验中心全新上线,免登录体验满血联网版Deep Seek R1 模型及豆包最新版模型:https://www.volcengine.com/experience/ark?utm_term202502dsinvite&acDSASUQY5&rcGO9H7M38 告别DeepSeek卡顿,探索火山引擎DeepSeek-R1的丝滑之旅 在A…...
Vulnhub-node靶机教学
本篇文章旨在为网络安全渗透测试靶机教学。通过阅读本文,读者将能够对渗透Vulnhub系列node靶机有一定的了解 一、信息收集阶段 靶机下载地址:https://www.vulnhub.com/entry/node-1,252 因为靶机为本地部署虚拟机网段,查看dhcp地址池设置。得…...

php处理图片出现内存溢出(Allowed memory size of 134217728 bytes exhausted)
错误: 最近做图片上传功能时发现上传某些图片时报内存溢出错误。如下所示: {"code": 0,"msg": "Allowed memory size of 134217728 bytes exhausted (tried to allocate 24576 bytes)","data": {"code&q…...

网络IP跳动问题解决详
一、问题原因分析 DHCP服务器配置问题: DHCP服务器租期设置过短。 DHCP地址池范围过小,导致地址耗尽。 网络中可能存在多个DHCP服务器,导致IP分配冲突。 网络中存在IP地址冲突: 手动配置的IP地址与DHCP分配的地址冲突。 网络中存在未经授权的DHCP服…...

Linux firewalld 常用命令
本文参考RedHat官网文章How to configure a firewall on Linux with firewalld。 Firewalld 是守护进程名,对应命令为firewall-cmd。帮助详见以下命令: $ firewall-cmd --helpUsage: firewall-cmd [OPTIONS...]General Options-h, --help Pr…...

LeetCode 热题 100 49. 字母异位词分组
LeetCode 热题 100 | 49. 字母异位词分组 大家好,今天我们来解决一道经典的算法题——字母异位词分组。这道题在LeetCode上被标记为中等难度,要求我们将字母异位词组合在一起。下面我将详细讲解解题思路,并附上Python代码实现。 问题描述 给…...
从 DeepSeek 到飞算 JavaAI:AI 开发工具如何重塑技术生态?
在科技飞速发展的当下,AI 开发工具正以前所未有的态势重塑技术生态。从备受瞩目的 DeepSeek 到崭露头角的飞算 JavaAI,它们在不同维度上推动着软件开发领域的变革,深刻影响着开发者的工作方式与行业发展走向。 DeepSeek:AI 开发领…...

OceanBase 初探学习历程之二——操作系统参数最佳实践
本文章分享OB操作系统参数最佳实践值,相关参数部分来自PK项目得知,仅供参考,实际参数设置仍需结合现有设备条件及业务系统特点是否有必要如此设置,但我任务大部分场景均可用(仅本人个人观点)。 1、磁盘配置…...
)
全面指南:使用JMeter进行性能压测与性能优化(中间件压测、数据库压测、分布式集群压测、调优)
目录 一、性能测试的指标 1、并发量 2、响应时间 3、错误率 4、吞吐量 5、资源使用率 二、压测全流程 三、其他注意点 1、并发和吞吐量的关系 2、并发和线程的关系 四、调优及分布式集群压测(待仔细学习) 1.线程数量超过单机承载能力时的解决…...

《机器学习实战》专栏 No12:项目实战—端到端的机器学习项目Kaggle糖尿病预测
《机器学习实战》专栏 第12集:项目实战——端到端的机器学习项目Kaggle糖尿病预测 本集为专栏最后一集,本专栏的特点是短平快,聚焦重点,不长篇大论纠缠于理论,而是在介绍基础理论框架基础上,快速切入实战项…...

【vue项目中如何实现一段文字跑马灯效果】
在Vue项目中实现一段文字跑马灯效果,可以通过多种方式实现,以下是几种常见的方法: 方法一:使用CSS动画和Vue数据绑定 这种方法通过CSS动画实现文字的滚动效果,并结合Vue的数据绑定动态更新文本内容。 步骤ÿ…...
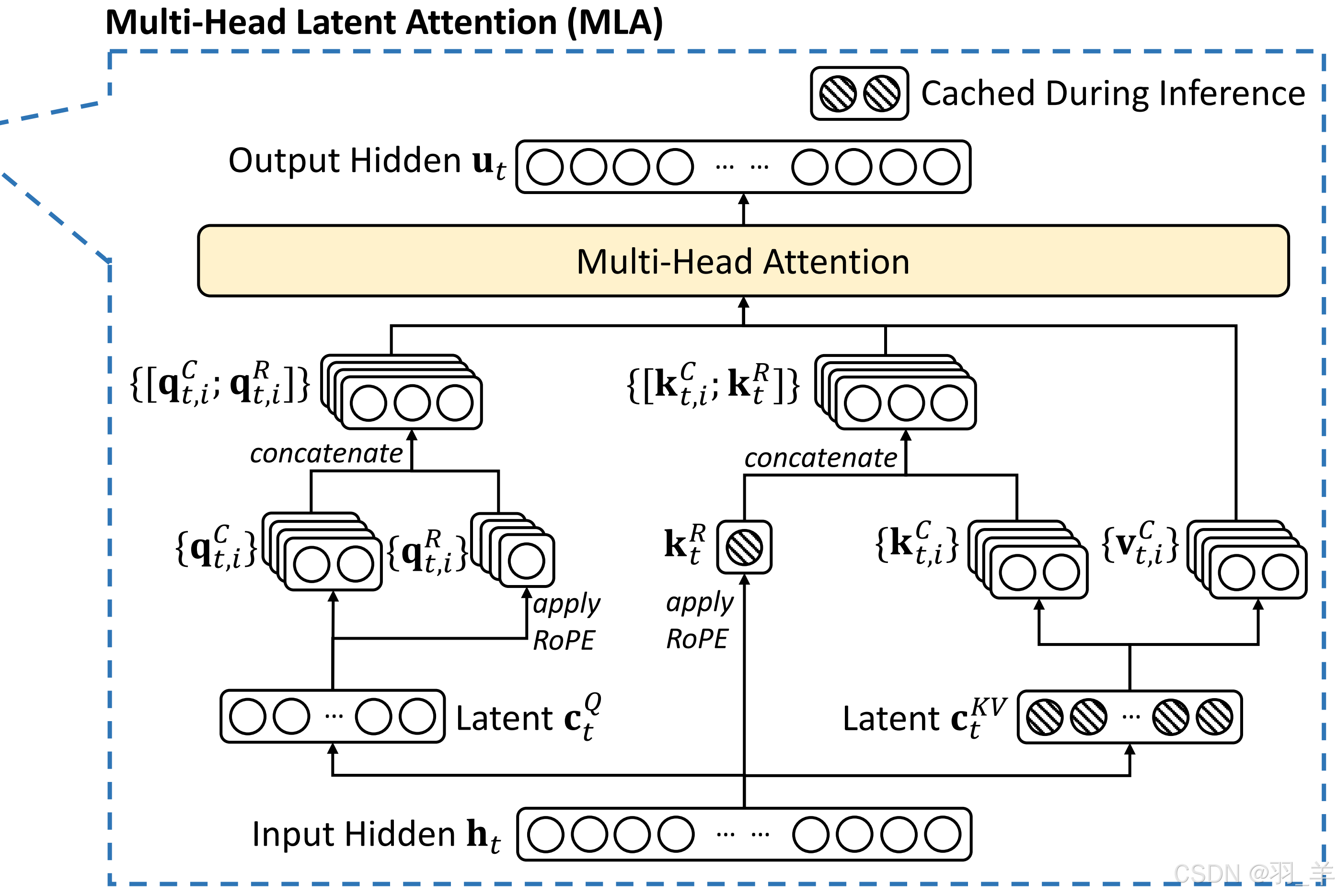
DeepSeek 细节之 MLA (Multi-head Latent Attention)
DeepSeek 系统模型的基本架构仍然基于Transformer框架,为了实现高效推理和经济高效的训练,DeepSeek 还采用了MLA(多头潜在注意力)。 MHA(多头注意力)通过多个注意力头并行工作捕捉序列特征,但面临高计算成本…...

Python爬虫具体是如何解析商品信息的?
在使用Python爬虫解析亚马逊商品信息时,通常会结合requests库和BeautifulSoup库来实现。requests用于发送HTTP请求并获取网页内容,而BeautifulSoup则用于解析HTML页面并提取所需数据。以下是具体的解析过程,以按关键字搜索亚马逊商品为例。 …...

lerobot调试记录
这里写自定义目录标题 libtiff.so undefined symbol libtiff.so undefined symbol anaconda3/envs/lerobot3/lib/python3.10/site-packages/../.././libtiff.so.6: undefined symbol: jpeg12_write_raw_data, version LIBJPEG_8.01.安装库 conda install -c conda-forge jpeg …...

像素剧本圣殿实操手册:Qwen2.5-14B-Instruct输出剧本导入Final Draft兼容性测试
像素剧本圣殿实操手册:Qwen2.5-14B-Instruct输出剧本导入Final Draft兼容性测试 1. 工具介绍与核心功能 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct大模型深度优化的专业剧本创作工具。这个工具将AI强大的文本生成能…...
)
告别Root后迷茫:手把手教你用Magisk模块激活LSPosed(Riru/Zygisk双版本保姆级教程)
从Root到模块实战:Magisk与LSPosed的终极配置指南 当你成功解锁Bootloader并完成Root后,真正的Android定制之旅才刚刚开始。面对琳琅满目的Magisk模块,特别是功能强大的LSPosed框架,许多用户会陷入选择困难——Riru还是Zygisk&am…...

QueryExcel技术解密:多Excel文件并行检索工具深度解析与实战指南
QueryExcel技术解密:多Excel文件并行检索工具深度解析与实战指南 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 在现代企业数据管理中,Excel文件作为最常见的数据存储格式之一…...

预约软件测评2026
2026 中国市场预约软件全景测评:自由职业者与本地商家如何选?预约管理正成为越来越多自由职业者、一人企业(OPC)和本地生活商家的刚需。从咨询师到美甲店,谁都需要一套让客户自助预约、自动确认的工具——但市面上产品…...

清雪车远程监控运维管理系统方案
在北方某高速路段冬季除雪保畅作业中,现场配置了配备滚刷、雪铲、破冰装置及融雪剂撒布系统的多功能清雪车车队。管理层面临着车辆位置分布不清、作业状态无法实时感知的双重痛点。因此,车队打造信息化车辆管理平台的核心需求是:不仅要实时掌…...

PDA5927四象限光电管:从基础测试到光电流线性化应用
1. PDA5927四象限光电管基础特性解析 第一次拿到PDA5927这颗四象限光电管时,我就像拆开一个新玩具的工程师,迫不及待想了解它的"脾气"。实测下来,这颗器件确实有些有趣的特性值得分享。 用万用表二极管档测量四个象限,正…...

ESP8266 I2C通信避坑指南:从SHT30读取失败到BH1750数据不准的常见问题排查
ESP8266 I2C通信实战避坑指南:从硬件连接到协议调试的完整解决方案 当你第一次尝试用ESP8266通过I2C总线连接传感器时,可能会遇到各种令人困惑的问题——传感器无响应、数据读取为0、数值异常波动,甚至I2C地址扫描不到。这些问题往往让开发者…...

meshio性能优化技巧:如何提升大规模网格文件处理效率
meshio性能优化技巧:如何提升大规模网格文件处理效率 【免费下载链接】meshio :spider_web: input/output for many mesh formats 项目地址: https://gitcode.com/gh_mirrors/me/meshio meshio是一款功能强大的网格文件输入输出工具,支持多种网格…...

基于前缀树的 Harness 快速指令匹配
万亿级指令毫秒级命中:基于前缀树的Harness自动化测试指令匹配系统从原理到落地全指南 关键词 前缀树(Trie)、Harness自动化平台、指令模糊匹配、DevOps性能优化、参数自动提取、多租户规则隔离、毫秒级响应 摘要 在云原生DevOps普及的今天,Harness作为主流的自动化交付…...

面试官:聊聊RocketMQ事务消息?
知识回顾 本文不讲什么是 RocketMQ ,不讲它的实现原理,只想和大家探讨下它的事务消息的正确使用方式 再探讨之前,先带大家回顾下知识点 事务消息的设计原理 RocketMQ 在 4.3.0 版中已经支持分布式事务消息,采用 2PC 的思想实现事务…...