学习路程三 数据加载及向量化
前序
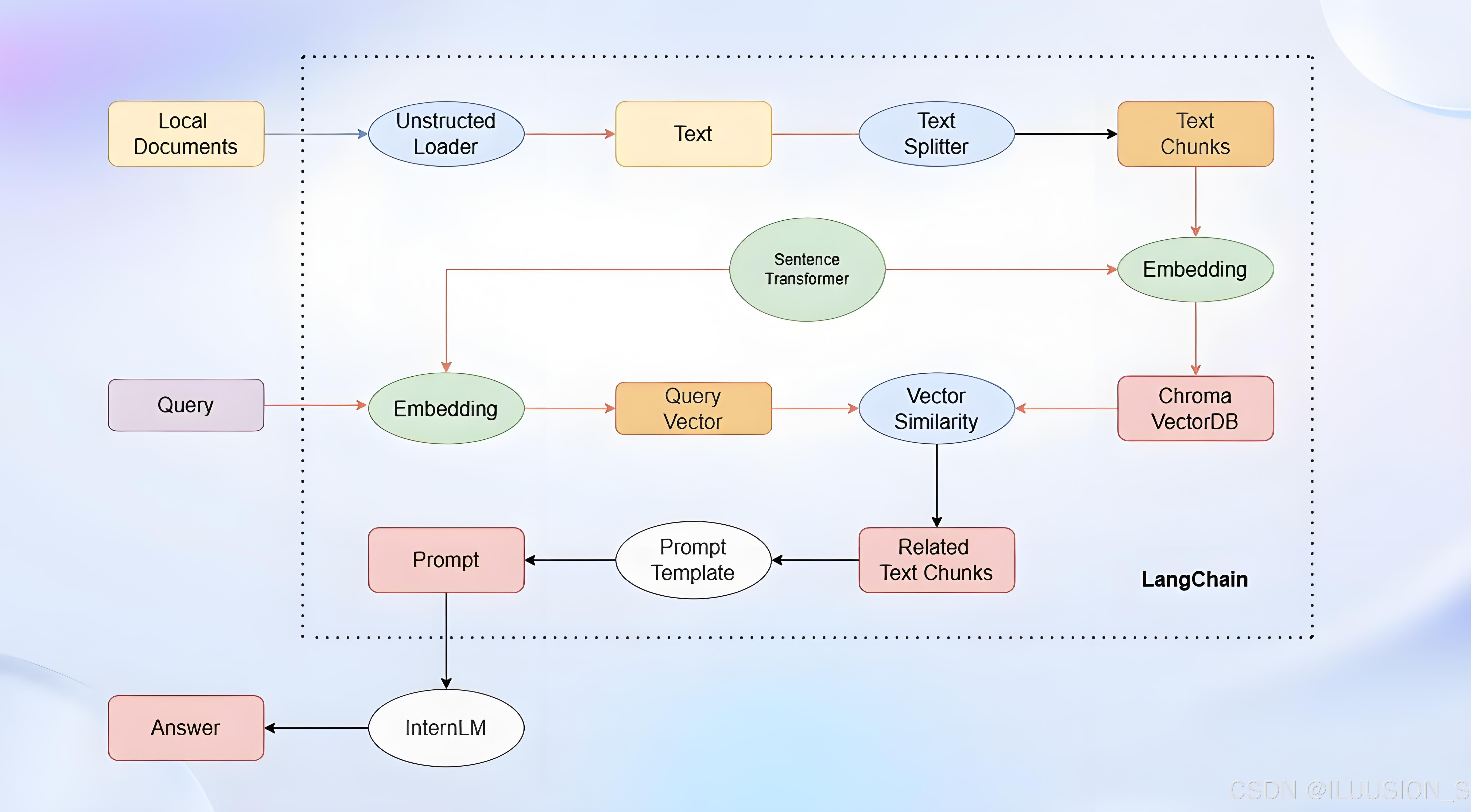 之前简单粗暴将LangChain分了几块,现在就挨着了解学习每块内容。今天主要从文档这条路来看。
之前简单粗暴将LangChain分了几块,现在就挨着了解学习每块内容。今天主要从文档这条路来看。
本地文档这一条链路,通过加载,分割,向量化,再存储数据库
ps:看到这里还想继续实操下去,可以先安装langchain,毕竟还挺费时的,先装着再继续看。
pip install langchain
pip install langchain_community
一、向量及向量化(Embedding)
什么是向量
数学中都学过,向量就是一个点,到另一个点,带有方向的箭头。既有大小,又有方向。
为什么要向量化数据
由于向量可以高度抽象地表示事物的特征和属性,世界上几乎所有类型的数据——视频、图像、声音、文本……统统都可以通过数据处理转换成向量数据。将其他类型的信息转换为向量数据的过程就是向量化。因而,在AI领域流传着一句话,万物皆可Embedding。
举个例子,可以使用词嵌入(word embeddings)来表示文本数据,在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,“Cat” 和 “Dog” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的词性与含义相似;而 “apple” 和 “orange” 也会很接近,因为它们都是水果;而 “Cat” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
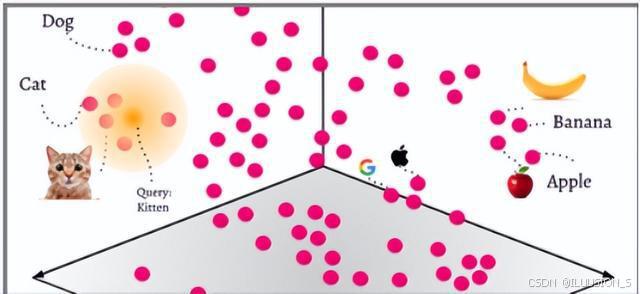
怎么向量化
向量数据,通常指的是将实体(如文本、图像、音频等)转换为数值形式的高维向量。这些向量能够捕捉实体的关键特征,并在向量空间中进行各种计算和比较。向量数据在AI中的应用非常广泛,包括但不限于自然语言处理(NLP)、计算机视觉、语音识别、推荐系统等。通过向量化,AI系统能够更好地理解和处理复杂的数据类型,从而提供更加智能和个性化的服务。
例如我们都是知道代表颜色RGB,如[255,255,255]代表白色。[0,0,0]代表黑色。这就是一种embeding,当然,大模型中,远比这个更复杂,远远不止才3个,而是几百上千,这跟使用的embedding模型
实际上可以通过一些别人训练好的向量化模型,或者说Embedding模型,将输入的内容进行向量化。
二、实操向量化
上面一堆从其他地方CV过来的文字,可以看一下。下面就简单实操。
langchain集成支持的模型列表:https://python.langchain.com/docs/integrations/text_embedding/
支持的有许多,没看到deepseek,那就算了。再重新随便选一个就行,这里我选这个智普AI,别问我为什么(因为我点到官网看注册后它免费送我次数-_-)
2.1 注册智普,申请key
智普官网:https://bigmodel.cn/
申请key,找不到可以点链接(https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys)
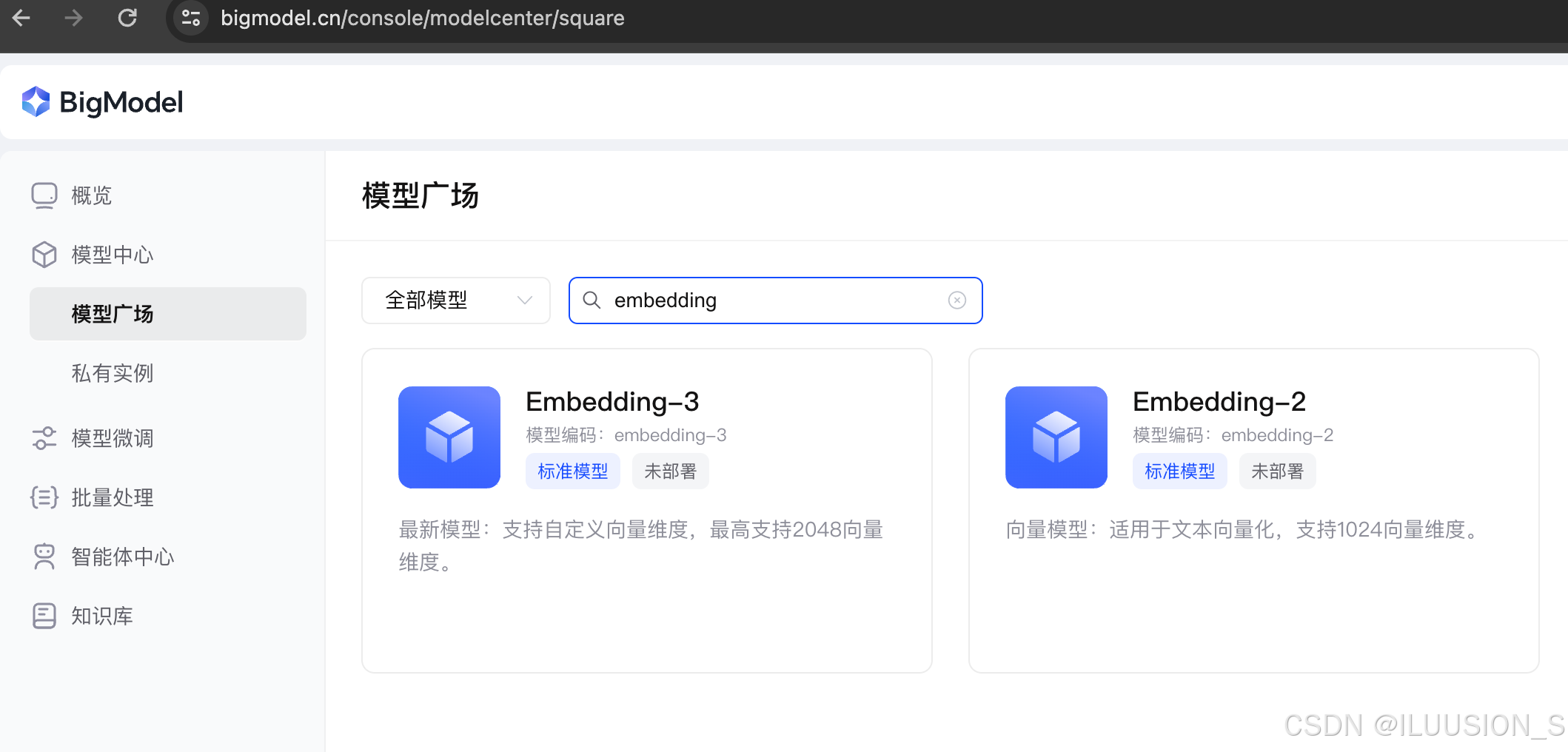
可以去模型广场,搜embedding,可以看到有2个model可供选择
2.2 安装所需要的环境
pip install -U zhipuai
pip install -U langchain_community
import os
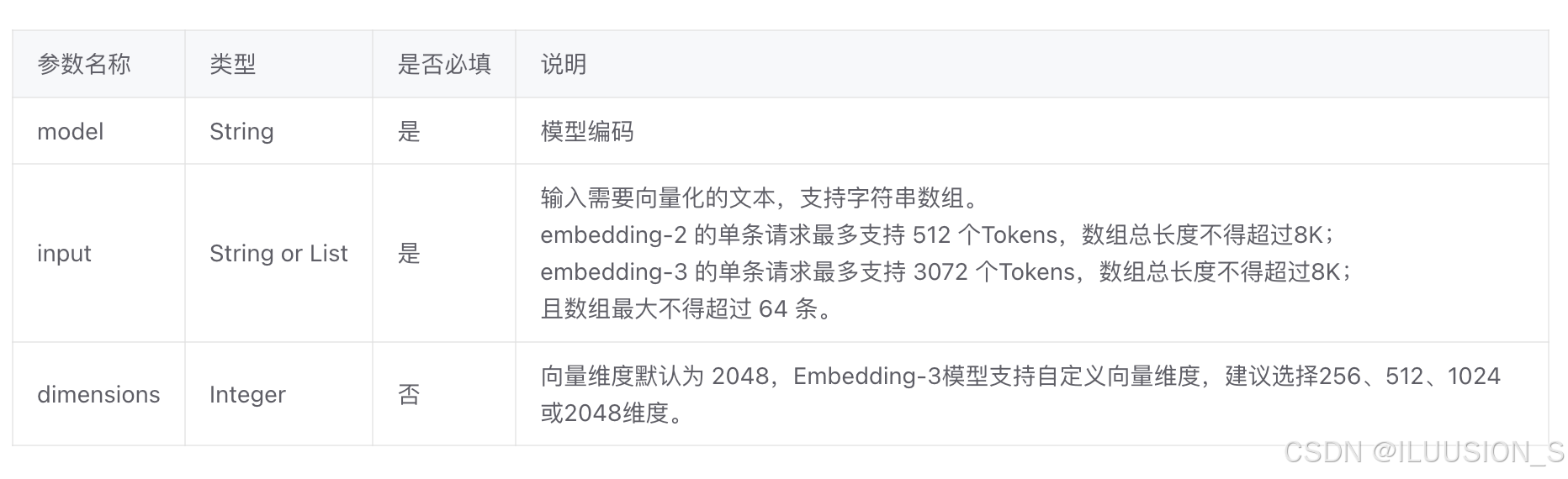
os.environ["ZHIPUAI_API_KEY"] = "a22568xxx"from langchain_community.embeddings import ZhipuAIEmbeddingsembeddings = ZhipuAIEmbeddings(model="embedding-3",
)text = "苹果"
single_vector = embeddings.embed_query(text)
print(single_vector, len(single_vector))

可以看到,一个“苹果”就被分成了2048纬度的向量。
官网这里也有单独使用的方法,但是就像最开始说的,每个模型都用他们单独的来使用,那么确实不方便。所以还是尽量选用langcahin提供的跳用方法,到时换模型的话,只需要把参数什么的一换就行

三、文档加载与分割
向量化数据是有长度限制的,所以需要先将文件加载,再进行分割。
langchain提供的文档加载器(Document loaders)主要基于Unstructured 包,Unstructured 是一个python包,可以把各种类型的文件转换成文本。LangChain支持的文档加载器包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的PDF加载引擎)几种常用格式的内容解析,但是在实际的项目中,数据来源一般比较多样,格式也比较复杂
最常用的也就是文本文档 TextLoader
3.1 TextLoader文档加载分割
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./1.txt', encoding='utf-8')
# 适用于小型的txt文档,加载所有
docs = loader.load()# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=512, # 被分割文档的切块大小,500~2000chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)# 开始文档分割
texts = text_splitter.split_documents(docs)
print(texts)"""
[Document(metadata={'source': './1.txt'}, page_content='夜已深,漆黑一片,景物不可见。但山中并不宁静,猛兽咆哮,震动山河,万木摇颤,乱叶簌簌坠落。\n\n群山万壑间,洪荒猛兽横行,太古遗种出没,各种可怕的声音在黑暗中此起彼伏,直欲裂开这天地。\n\n山脉中,远远望去有一团柔和的光隐现,在这黑暗无尽的夜幕下与万山间犹如一点烛火在摇曳,随时会熄灭。\n\n渐渐接近,可以看清那里有半截巨大的枯木,树干直径足有十几米,通体焦黑。除却半截主干外,它只剩下了一条柔弱的枝条,但却在散发着生机,枝叶晶莹如绿玉刻成,点点柔和的光扩散,将一个村子笼罩。\n\n确切的说,这是一株雷击木,在很多年前曾经遭遇过通天的闪电,老柳树巨大的树冠与旺盛的生机被摧毁了。如今地表上只剩下八九米高的一段树桩,粗的惊人,而那仅有的一条柳枝如绿霞神链般,光晕弥漫,笼罩与守护住了整个村子,令这片栖居地朦朦胧胧,犹若一片仙乡,在这大荒中显得很神秘。\n\n村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。'),
Document(metadata={'source': './1.txt'}, page_content='村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。\n\n一声凶戾的禽鸣自高天传来,穿金裂石,竟源自那片乌云,细看它居然是一只庞大到不可思议的巨鸟,遮天蔽月,长也不知多少里。\n\n路过石村,它俯视下方,两只眼睛宛若两轮血月般,凶气滔天,盯着老柳木看了片刻,最终飞向了山脉最深处。\n\n平静了很长一段时间,直到后半夜,大地颤动了起来,一条模糊的身影从远方走来,竟与群山齐高!\n\n莫名气息散发,群山万壑死一般的寂静,凶禽猛兽皆蛰伏,不敢发出一点声音。\n\n近了,这是一个拥有人形的生物,直立行走,庞大的惊人,身高比肩山岳,浑身没有毛发,通体密布着金色的鳞片,熠熠生辉。面部很平,只有一只竖眼,开合间像是一道金色的闪电划过,犀利慑人。整体血气如海,宛如一尊神魔!\n\n它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。'),
Document(metadata={'source': './1.txt'}, page_content='它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。\n\n黎明,一条十米长、水桶粗、银光灿灿的蜈蚣在山中蜿蜒而行,像是白银浇铸而成,每一节都锃亮而狰狞,划过山石时铿锵作响,火星飞溅。但最终它却避过了石村,没有侵入,所过之处黑雾翻腾,万兽避退。\n\n一根散发着莹莹绿霞的柔弱柳条在风中轻轻摇曳……')]
"""
可以看到,将1.txt这个文件分成了3块。
chunk_size=512, # 被分割文档的切块大小,500~2000chunk_overlap=100, # 被分割切块的重叠部分长度,200以内# 重叠是指下一块分割时,包含上一部分的后面100个字符,这样做的目的是避免将重要信息分割时打乱,导致后续处理一些问题。
有点类似断句 “数学王子韩老师”,如果刚好512个字符断到了数学王子, 然后下一个块内容不重叠之前的,韩老师就是人名了。这与最开始的意思不同。所以重叠可以解决一些不必要的歧义问题。
分割完成后,再将每一块分别向量化得到结果
# ...拆分的代码from langchain_community.embeddings import ZhipuAIEmbeddings
embeddings = ZhipuAIEmbeddings(model="embedding-3",
)many_vector = embeddings.embed_documents([text.page_content for text in texts])
for vector in many_vector:print(vector, len(vector))
这就完成了一次完整的文档分割和向量化的过程
from langchain_text_splitters import CharacterTextSplitter
# 从langchain_text_splitters 点进去,可以看到分割器有很多很多
好像说的是 切分文档的话[RecursiveCharacterTextSplitter递归文档切割器比CharacterTextSplitter字符文本切割器更好用]
更多可以查看其他大神的了解更多,既然更好用,那后面就不用CharacterTextSplitter就行了,我也跟着用RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter分割代码:
# 文档加载器
from langchain_community.document_loaders import TextLoaderloader = TextLoader('./1.txt', encoding='utf-8')
# 适用于小型的txt文档,加载所有
docs = loader.load()# 文档分割器
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=512, # 被分割文档的切块大小,500~2000chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)# 开始文档分割
texts = text_splitter.split_documents(docs)
print(texts)
"""
[Document(metadata={'source': './1.txt'}, page_content='夜已深,漆黑一片,景物不可见。但山中并不宁静,猛兽咆哮,震动山河,万木摇颤,乱叶簌簌坠落。\n\n群山万壑间,洪荒猛兽横行,太古遗种出没,各种可怕的声音在黑暗中此起彼伏,直欲裂开这天地。\n\n山脉中,远远望去有一团柔和的光隐现,在这黑暗无尽的夜幕下与万山间犹如一点烛火在摇曳,随时会熄灭。\n\n渐渐接近,可以看清那里有半截巨大的枯木,树干直径足有十几米,通体焦黑。除却半截主干外,它只剩下了一条柔弱的枝条,但却在散发着生机,枝叶晶莹如绿玉刻成,点点柔和的光扩散,将一个村子笼罩。\n\n确切的说,这是一株雷击木,在很多年前曾经遭遇过通天的闪电,老柳树巨大的树冠与旺盛的生机被摧毁了。如今地表上只剩下八九米高的一段树桩,粗的惊人,而那仅有的一条柳枝如绿霞神链般,光晕弥漫,笼罩与守护住了整个村子,令这片栖居地朦朦胧胧,犹若一片仙乡,在这大荒中显得很神秘。\n\n村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。'),
Document(metadata={'source': './1.txt'}, page_content='村中各户都是石屋,夜深人静,这里祥和而安谧,像是与外界的黑暗还有兽吼隔绝了。\n\n“呜……”\n\n一阵狂风吹过,一片巨大的乌云横空,遮住了整片夜空,挡住了那仅有的一点星华,山脉中更加黑暗了。\n\n一声凶戾的禽鸣自高天传来,穿金裂石,竟源自那片乌云,细看它居然是一只庞大到不可思议的巨鸟,遮天蔽月,长也不知多少里。\n\n路过石村,它俯视下方,两只眼睛宛若两轮血月般,凶气滔天,盯着老柳木看了片刻,最终飞向了山脉最深处。\n\n平静了很长一段时间,直到后半夜,大地颤动了起来,一条模糊的身影从远方走来,竟与群山齐高!\n\n莫名气息散发,群山万壑死一般的寂静,凶禽猛兽皆蛰伏,不敢发出一点声音。\n\n近了,这是一个拥有人形的生物,直立行走,庞大的惊人,身高比肩山岳,浑身没有毛发,通体密布着金色的鳞片,熠熠生辉。面部很平,只有一只竖眼,开合间像是一道金色的闪电划过,犀利慑人。整体血气如海,宛如一尊神魔!\n\n它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。'),
Document(metadata={'source': './1.txt'}, page_content='它路过此地,看了一眼老柳木,稍作停留后,似乎急于赶路,最终快速远去,许多山峰被其脚步震的轰鸣,山地剧烈颤抖。\n\n黎明,一条十米长、水桶粗、银光灿灿的蜈蚣在山中蜿蜒而行,像是白银浇铸而成,每一节都锃亮而狰狞,划过山石时铿锵作响,火星飞溅。但最终它却避过了石村,没有侵入,所过之处黑雾翻腾,万兽避退。\n\n一根散发着莹莹绿霞的柔弱柳条在风中轻轻摇曳……')]
"""
https://blog.csdn.net/m0_62965652/article/details/142999598
3.2 markdownLoder
需要安装一些库,一般是报错什么,缺什么就装什么。
pip install unstructured
pip install unstructured
# coding=utf-8
"""@project: LLM_study@file: md_loader.py@Author:John@date:2025/2/23 18:23
"""
from langchain_community.document_loaders import UnstructuredMarkdownLoader
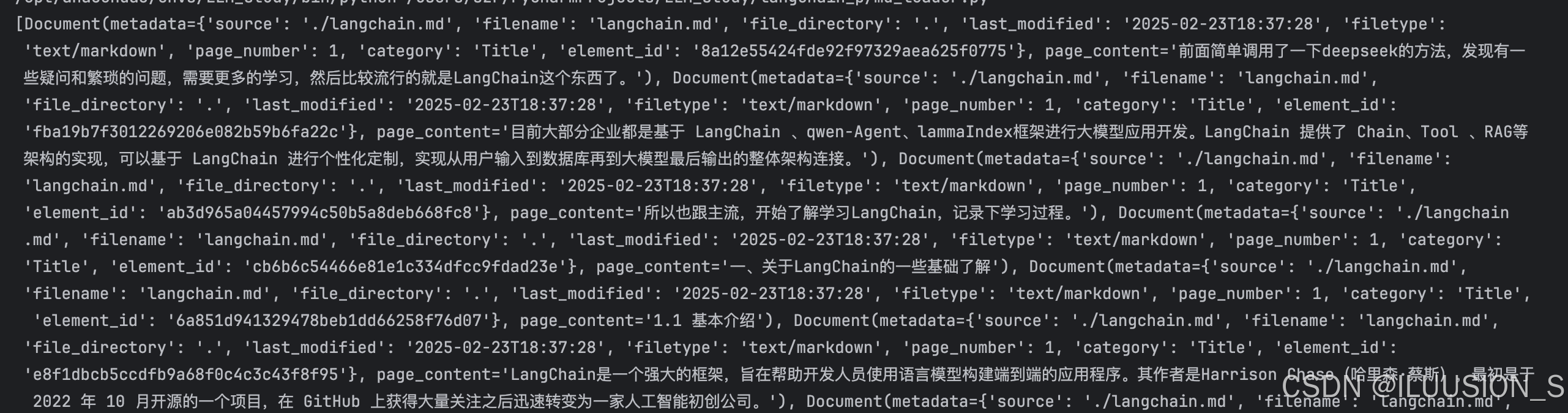
from langchain_text_splitters import RecursiveCharacterTextSplitterloader = UnstructuredMarkdownLoader("langchain.md", mode="elements", autodetect_encoding=True)
docs = loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100))
print(docs)
运行过程中一直报错,各种找问题,发现好像是这个有问题,让手动下载一下,但是下载又失败。
import nltk
nltk.download('punkt')
解决方法

就是缺什么去装什么。运行报错时会告诉缺什么,装好就行了。

最后成功 运行结果:
其它
其他loader用法都大差不差的。这里也不一一展示了,几乎一样的用法,不同的文档类型,选择不同的loader就行。
也许后面用到了什么再回来补这里。暂时还没用到其他的。附上官网下提供的loader,需要的可以自己选择查看。
https://python.langchain.com/docs/how_to/
相关文章:
学习路程三 数据加载及向量化
前序 之前简单粗暴将LangChain分了几块,现在就挨着了解学习每块内容。今天主要从文档这条路来看。 本地文档这一条链路,通过加载,分割,向量化,再存储数据库 ps:看到这里还想继续实操下去,可以…...

基于GWO灰狼优化的WSN网络最优节点部署算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 无线传感器网络(Wireless Sensor Network, WSN)由大量分布式传感器节点组成,用于监测物理或环境状况。节点部署是 WSN 的关键问…...

保姆级! 本地部署DeepSeek-R1大模型 安装Ollama Api 后,Postman本地调用 deepseek
要在Postman中访问Ollama API并调用DeepSeek模型,你需要遵循以下步骤。首先,确保你有一个有效的Ollama服务器实例运行中,并且DeepSeek模型已经被加载。 可以参考我的这篇博客 保姆级!使用Ollama本地部署DeepSeek-R1大模型 并java…...

架构对比分析
您提到的两种架构描述本质上遵循相同的分层设计理念,但存在差异的原因在于 视角不同 和 硬件平台特性。以下是详细解析: 一、架构对比分析 1. 逻辑分层(通用软件设计视角) 应用层(UI/用户交互)↓ 业务逻辑…...

【每日八股】Redis篇(二):数据结构
Redis 数据类型? 主要有 STRING、LIST、ZSET、SET 和 HASH。 STRING String 类型底层的数据结构实现主要是 SDS(简单动态字符串),其主要应用场景包括: 缓存对象:可以用 STRING 缓存整个对象的 JSON&…...

windows使用命令解压jar包,替换里面的文件。并重新打包成jar包,解决Failed to get nested archive for entry
有一个jar包,需要替换里面的文件,使用解压工具打开项目,然后找到对应的子包,再次打开,然后进行手工替换重新压缩成jar包后,发现启动服务报错Failed to get nested archive for entry。 使用下面的命令可实…...
)
2025电商与跨境贸易实战全解析:DeepSeek赋能细分领域深度指南(附全流程案例)
🚀 2025电商与跨境贸易实战全解析:DeepSeek赋能细分领域深度指南(附全流程案例)🚀 📚 目录 DeepSeek在电商与跨境贸易中的核心价值选品与市场分析:AI驱动的精准决策Listing优化与多语言营销:提升转化率的秘密物流与供应链管理:AI赋能的效率革命客户服务与私域运营:…...

驱动开发系列39 - Linux Graphics 3D 绘制流程(二)- 设置渲染管线
一:概述 Intel 的 Iris 驱动是 Mesa 中的 Gallium 驱动,主要用于 Intel Gen8+ GPU(Broadwell 及更新架构)。它负责与 i915 内核 DRM 驱动交互,并通过 Vulkan(ANV)、OpenGL(Iris Gallium)、或 OpenCL(Clover)来提供 3D 加速。在 Iris 驱动中,GPU Pipeline 设置 涉及…...

自动驾驶中planning为什么要把横纵向分开优化?
在自动驾驶系统中,将 横向(Lateral)规划 和 纵向(Longitudinal)规划 分开优化是一种常见的设计范式,其核心原理在于 解耦车辆运动控制的多维复杂性,同时兼顾 计算效率 和 安全性约束。以下从原理…...
)
Linux 命令大全完整版(06)
2. 系统设置命令 pwunconv 功能说明:关闭用户的投影密码。语法:pwunconv补充说明:执行 pwunconv 指令可以关闭用户投影密码,它会把密码从 shadow 文件内,重回存到 passwd 文件里。 rdate(receive date) 功能说明&a…...
)
第9章:LangChain结构化输出-示例2(数字提取服务)
如何使用LangChain4j框架创建和使用多种AI服务。它通过定义接口和注解,将自然语言处理任务(如情感分析、数字提取、日期提取、POJO提取等)封装为服务,并通过LangChain4j的AiServices动态生成这些服务的实现。 本章主要讲述基于Lan…...

每天五分钟深度学习pytorch:使用Inception模块搭建GoogLeNet模型
本文重点 前面我们学习了Incetption模块,它的作用类似于vgg块对于VGG网络模型一样,本文我们使用Inception搭建GoogLeNet网络,如果使用卷积层开始从头开始搭建GoogleNet,那么这样看起来会很不清晰,我们使用已经封装好的Inception来搭建GoogLeNet网络 关键点 关键点在于I…...

Ubuntu - Redis 安装、远程访问
参考教程: https://blog.csdn.net/houor/article/details/126672577 https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/install-redis-on-linux/ 查看是否安装 redis-cli --versionUbuntu 上安装 更新: sudo apt update …...

SpringBoot+Vue+微信小程序的猫咖小程序平台(程序+论文+讲解+安装+调试+售后)
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,我会一一回复,希望帮助更多的人。 系统介绍 在当下这个高速发展的时代,网络科技正以令人惊叹的速度不断迭代更新。从 5G …...

二分查找算法的全面解析C++
一、核心原理与特性 二分查找是一种**对数时间复杂度(O(log n))**的高效搜索算法46,需满足两个前提条件: 数据存储在连续内存空间(如数组)数据按升序/降序有序排列35 算法通过折半比较缩小搜索范围: 初始化左右边界…...

深度学习(5)-卷积神经网络
我们将深入理解卷积神经网络的原理,以及它为什么在计算机视觉任务上如此成功。我们先来看一个简单的卷积神经网络示例,它用干对 MNIST数字进行分类。这个任务在第2章用密集连接网络做过,当时的测试精度约为 97.8%。虽然这个卷积神经网络很简单…...
)
第9章:LangChain结构化输出-示例3(日期和时间提取服务)
如何使用LangChain4j框架创建和使用多种AI服务。它通过定义接口和注解,将自然语言处理任务(如情感分析、数字提取、日期提取、POJO提取等)封装为服务,并通过LangChain4j的AiServices动态生成这些服务的实现。 本章主要讲述基于LangChain调用大模型如何进行结构化输出的真实…...

解决Open WebU无法显示基于OpenAI API接口的推理内容的问题
解决方案 把reasoning content的东西移到content中来 并在reasoning时,手动加上标签。具体做法是截获第三方api返回的stream,并修改其中的内容,再移交给open webUI处理。 在backend\open_webui\routers\openai.py中 找到 generate_chat_com…...
AI颠覆蛋白质工程:ProMEP零样本预测突变效应
概述 在生命科学的“造物革命”中,蛋白质工程一直面临着“试错成本”与“设计效率”的双重挑战——传统方法依赖繁复的多序列比对(MSA)或耗时的实验室筛选,如同在浩瀚的蛋白质宇宙中盲选星辰。而今日,一项发表于《Cel…...

QT闲记-状态栏,模态对话框,非模态对话框
1、创建状态栏 跟菜单栏一样,如果是继承于QMainWindow类,那么可以获取窗口的状态栏,否则就要创建一个状态栏。通过statusBar()获取窗口的状态栏。 2、添加组件 通常添加Label 来显示相关信息,当然也可以添加其他的组件。通过addWidget()添加组件 3、设置状态栏样式 …...

终极科研生产力革命:如何用Obsidian模板30天构建你的个人学术知识库
终极科研生产力革命:如何用Obsidian模板30天构建你的个人学术知识库 【免费下载链接】obsidian_vault_template_for_researcher This is an vault template for researchers using obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian_vault_templat…...

Docker 27在农田边缘节点落地难?揭秘高湿尘环境下的容器自愈机制与离线OTA升级全流程
第一章:Docker 27在农田边缘节点落地难?揭秘高湿尘环境下的容器自愈机制与离线OTA升级全流程农田边缘计算节点常年暴露于高湿度(>90% RH)、粉尘浓度超 5 mg/m 的严苛环境中,传统 Docker 27 守护进程易因 systemd 单…...

如何快速使用RPGMakerDecrypter:解密RPG Maker加密资源的完整指南
如何快速使用RPGMakerDecrypter:解密RPG Maker加密资源的完整指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_m…...

终极指南:使用115proxy-for-kodi高效实现115云盘视频电视播放
终极指南:使用115proxy-for-kodi高效实现115云盘视频电视播放 【免费下载链接】115proxy-for-kodi 115原码播放服务Kodi插件 项目地址: https://gitcode.com/gh_mirrors/11/115proxy-for-kodi 想要在电视上直接流畅播放115云盘中的视频内容?115pr…...
)
为什么你的GraalVM镜像总在容器OOMKilled?深度解析Native Image内存布局、C heap分配与mmap区域争用(附perf flame graph诊断流程)
第一章:为什么你的GraalVM镜像总在容器OOMKilled?GraalVM 原生镜像(Native Image)虽能显著降低启动延迟与内存常驻开销,但在容器化部署中频繁遭遇 OOMKilled,根源常被误判为“Java 内存泄漏”或“JVM 参数配…...
)
别再踩坑了!微信小程序this.setData修改对象属性的两种正确姿势(附数组场景)
微信小程序this.setData操作对象属性的深度避坑指南 刚接触微信小程序开发时,我曾在this.setData修改对象属性上栽过不少跟头。记得有一次深夜调试,明明逻辑看起来没问题,页面却始终不更新,最后发现是对象属性修改方式不当导致的。…...
)
别再傻傻分不清了!嵌入式开发中EEPROM和FLASH选型实战指南(含W25Q64/AT24C02案例)
嵌入式存储选型实战:EEPROM与FLASH的黄金分割法则 当你在设计一个智能家居控制器时,用户偏好的灯光场景该如何保存?开发工业传感器节点时,设备运行日志又该存储在何处?这些看似简单的选择背后,藏着嵌入式开…...

MySQL存储过程如何实现循环打印日志_调试信息输出技巧
MySQL存储过程调试首选建临时日志表INSERT记录,或用SELECT CONCAT输出(仅开发环境手动调用有效);禁用SIGNAL抛异常打日志,因其中断执行且低版本不支持;循环内应批量拼接日志再插入以提升性能。MySQL存储过程…...
)
Windows 11 24H2 系统下,保姆级安装华为 eNSP 模拟器(含依赖软件下载与避坑指南)
Windows 11 24H2 系统下华为 eNSP 模拟器全流程安装指南 最近升级到 Windows 11 24H2 系统的网络工程师们可能发现,原本流畅运行的华为 eNSP 模拟器突然无法正常工作了。这并非个例,而是由于新版操作系统引入的安全机制与模拟器底层依赖产生了兼容性冲突…...

别再羡慕别人的UI了!用Python tkinter的TinUI库,5分钟给你的按钮加上圆角和悬停效果
用Python tkinter的TinUI库打造现代感UI:5分钟实现圆角按钮与悬停效果 每次看到那些设计精美的软件界面,你是否也暗自羡慕?作为Python开发者,我们常常被tkinter默认控件的"复古"风格困扰。别担心,今天我要分…...