AI颠覆蛋白质工程:ProMEP零样本预测突变效应
概述
在生命科学的“造物革命”中,蛋白质工程一直面临着“试错成本”与“设计效率”的双重挑战——传统方法依赖繁复的多序列比对(MSA)或耗时的实验室筛选,如同在浩瀚的蛋白质宇宙中盲选星辰。而今日,一项发表于《Cell Research》的突破性研究彻底改写了游戏规则:中国科学家团队开发的ProMEP(Protein Mutational Effect Predictor)通过多模态深度学习,仅凭单条蛋白质序列与预测结构,即可实现零样本突变效应预测,无需MSA辅助,将基因编辑工具TadA的A-to-G转化效率推至77.27%,同时使TnpB核酸酶的编辑效率提升近3倍!这项技术不仅比传统方法快数百倍,更首次证明AI模型通过整合1.6亿蛋白质的序列与结构信息,能精准预测人类从未见过的蛋白质突变效果,为“按需设计生命元件”按下加速键。
这篇论文的题目是《Zero-shot prediction of mutation effects with multimodal deep representation learning guides protein engineering》论文链接
下面我对这篇论文进行结构化介绍,帮助一下读者快速掌握这篇论文核心。
我写了一篇赛博修仙版,搭配食用效果更佳:
《AI修仙实录:ProMEP炼出「零样本蛋白质推背图」,基因编辑直破77%天劫》![]() https://blog.csdn.net/weixin_47520540/article/details/145813189?sharetype=blogdetail&sharerId=145813189&sharerefer=PC&sharesource=weixin_47520540&spm=1011.2480.3001.8118
https://blog.csdn.net/weixin_47520540/article/details/145813189?sharetype=blogdetail&sharerId=145813189&sharerefer=PC&sharesource=weixin_47520540&spm=1011.2480.3001.8118
论文解剖指南:把天书拆成乐高积木
在正式开箱ProMEP这个"蛋白质预言家"之前,请允许我祭出科研江湖生存指南——当年在本科实验室摸鱼时认真学习时,导师传授的论文六脉神剑:
"看东西就关注三点:数据、输入、输出;训练方式、度量方法(loss)、评价体系;网络和特殊设计"
弟子不才,对其进行一下转述:"看AI论文就像做菜:食材(数据)决定上限,菜谱(网络结构)决定下限,火候(训练策略)决定成败,最后还得靠米其林评委(评价指标)盖章认证。"
一、数据部分——蛋白质宇宙的「灵气源泉」
主要让大家看看AI里面的蛋白质数据长啥样,有个基本的把握(可不是一个大分子结构团哦,AI模型可吃不下)
(一)基因编辑酶TnpB和TadA中氨基酸的变异位置的概率

图Source_Data1 AAProbability-score-TnpB.xlsx 和 Source_Data2 AAProbability-score-TadA.xlsx
注:所有图片来自论文开源的数据集
- Position:表示氨基酸在蛋白质序列中的位置(即该氨基酸在序列中的序号)。
- Wild-Type Amino Acid:表示在该位置上的天然氨基酸(即未突变前的氨基酸)。
- Mutated Amino Acid:表示突变后的氨基酸(替换了天然氨基酸的氨基酸)。
- Probability Score:表示模型预测的突变后蛋白质适应性分数,这个分数越高,表明突变后的氨基酸在该位置上更可能维持或增强蛋白质功能。
-
具体介绍:每一行代表蛋白质序列中的一个具体位置及其相应的突变信息,包括该位置上的天然氨基酸、可能的突变氨基酸,以及模型为此突变计算出的适应性概率分数。
这些数据用于评估模型预测的准确性。模型在训练过程中学习如何根据序列和结构信息来预测突变的适应性分数,并通过这些分数来指导蛋白质工程(例如,识别出能够提高酶活性或稳定性的有益突变)。
-
(二)TadA中40个有益突变的编辑效率。
-

Source_Data3-6.xlsx
- Position:与上面表格类似,表示蛋白质序列中的氨基酸位置。
- Wild-Type Amino Acid:表示在该位置的天然氨基酸。
- Mutated Amino Acid:表示突变后的氨基酸。
- Probability Score:表示模型对每个突变后蛋白质功能的预测分数。
- Additional Columns:可能包含多个额外信息列,如不同突变组合的适应性分数、实验测量值等。
具体:每一行对应一个特定的突变组合及其相关的适应性预测分数。多个突变可能会组合在一起,以显示这些组合对蛋白质功能的影响。
该表格的数据帮助模型学习如何处理复杂的多点突变情景,尤其是涉及多个氨基酸位置同时发生变化的情况。这些数据提供了实际生物实验的参考,以验证模型预测的可靠性和实用性。
二、模型输入
模型的输入是多模态的,主要包括蛋白质的序列信息和结构信息。
1、蛋白质序列
简单来说就是由氨基酸按照特定顺序组成的链,接收一个蛋白质的氨基酸序列,例如"MKVLYNLVNA..."(序列输入首先通过一个嵌入层(embedding layer)进行编码,这个层将每个氨基酸转换成一个向量(矢量),这些向量捕捉了氨基酸的物理化学性质以及它们在蛋白质中的上下文关系。每个氨基酸的嵌入通常是一个高维的向量,比如128维或更高维度的向量,这样可以更全面地表示其性质。)
2、蛋白质结构输入
涉及到蛋白质的三维构象,即蛋白质中各个原子的位置和它们之间的空间关系。
- 蛋白质点云:模型采用了一种名为“蛋白质点云”的表示方法。蛋白质点云是一组三维坐标点,每个点代表一个氨基酸的α碳原子(即该氨基酸的主链中的一个关键原子)。这些点不仅有空间坐标(x, y, z),还附带了该氨基酸的类型(如G, A, V等)和在序列中的位置。
- 输入形式:这些点云数据通过模型的结构嵌入模块进行处理。模型利用这些三维坐标和氨基酸类型来捕捉蛋白质的空间构型和氨基酸之间的相互作用。
3、组合输入
在多模态模型中,序列信息和结构信息并不是独立处理的,而是通过特定的架构(如编码器-解码器架构)结合在一起,以便模型能够同时理解和处理蛋白质的线性序列和三维结构。
- 序列上下文:模型的序列嵌入模块使用Transformer架构,能够捕捉序列中的长程依赖关系和氨基酸之间的复杂相互作用。
- 结构上下文:模型的结构嵌入模块(如SE(3)-Transformer)则能够处理蛋白质的三维信息,确保模型能够识别蛋白质中空间上相互靠近但在序列上可能相隔很远的氨基酸之间的相互作用。
三、模型输出
模型的输出为每个突变体的适应性预测分数,这些分数表示突变后蛋白质功能可能发生的变化(如活性增加或减少)。此外,模型还能够预测多点突变的综合效应,以帮助识别具有潜在有益功能的突变组合。
四、训练方式
训练数据
模型在AlphaFold2数据库中预测的约1.6亿个蛋白质结构上进行自监督训练。训练数据包括从这些蛋白质中提取的序列和结构信息。
训练方法
模型采用了自监督学习的方式进行训练,这意味着模型在训练过程中不需要人工标注的数据,而是通过掩码预测来学习数据的内在结构。(这里补充一下掩码策略)
掩码策略:
- 序列掩码:在输入的蛋白质序列中,随机选择15%的氨基酸进行掩码。被掩码的氨基酸有80%的概率被替换为一个特殊的掩码标记,有10%的概率被替换为随机的另一个氨基酸,剩下的10%保持不变。模型的任务是根据上下文信息预测这些掩码处的真实氨基酸。
- 结构掩码:对于蛋白质的点云结构,模型会掩码掉靠近蛋白质中心的25%的点,然后通过结构信息来重建这些点的三维坐标。
五、度量方法
损失函数
交叉熵损失(Categorical Cross-Entropy, CE):用于评估模型预测的突变氨基酸与实际氨基酸之间的差异,主要用于序列重建。
Chamfer距离损失(Chamfer Distance, CD):用于度量重构后的蛋白质点云与真实结构之间的几何差异,确保模型能够准确捕捉蛋白质的三维结构信息。
六、评价指标
斯皮尔曼等级相关系数(Spearman’s Rank Correlation):用来评估模型预测结果与实验测量之间的相关性,适用于无监督预测任务。(关于这个指标我的这篇博客中有介绍:斯皮尔曼相关系数)
受试者操作特性曲线下面积(Area Under the ROC Curve, AUROC):用于评估模型在区分病原性突变和非病原性突变方面的表现,特别是在病原性预测任务中使用。
平均精确度(Mean Average Precision, MAP):用于多任务预测中的精度评估。
七、模型设计——压轴大戏

a:以任意 WT 蛋白质作为输入,具体而言,对于任意突变,ProMEP 首先从 WT 蛋白质中提取序列嵌入和结构嵌入。然后对这些嵌入进行对齐并输入到预训练的 Transformer 编码器中,以生成残差分辨率的蛋白质表示。使用序列解码器,细粒度蛋白质表示最终分解为序列和结构背景下每个氨基酸的条件概率。任意突变的影响可以解释为突变序列和 WT 序列之间预测对数似然的差异。采用定制的蛋白质点云以原子分辨率引入蛋白质结构背景。
b:输入蛋白质结构的 3D 平移和旋转不会影响蛋白质的结构背景。 ProMEP 应用旋转和平移等变结构嵌入模块来保证这种不变性。
c :ProMEP可用于指导蛋白质工程,而无需标记数据集或对蛋白质结构和分子功能的整体理解。它使用户能够通过有效遍历蛋白质适应度景观来识别有益的(多个)突变体。
模型结构
1、多模态深度学习模型:该模型结合了蛋白质序列和结构的多模态信息,通过编码器-解码器架构学习蛋白质的序列和结构上下文。编码器负责处理输入的掩码序列和点云数据,生成特征表示;解码器则用于重建掩盖的信息。
2、Transformer编码器:由33层堆叠的Transformer组成,每层包括层归一化、20头注意力块和前馈网络,用于捕捉序列信息的上下文。
3、SE(3)-Transformer结构嵌入模块:保证结构上下文在三维变换中的不变性,确保模型对输入结构的旋转和平移具有不变性。
关键设计
- 蛋白质点云:使用蛋白质结构的α碳原子坐标构建点云,保持了蛋白质的几何信息,同时提高了计算效率。
- 多模态训练:同时学习蛋白质序列和结构上下文,确保模型能够整合多种信息来源,从而提供更准确的突变效果预测。
总结展望(科技狂想症犯了)
ProMEP虽强,但科学家的脑洞永远比AI大——这些升级方向正在路上:
🔥 挑战1.0:插入/删除突变
当前模型像精准的「氨基酸狙击枪」,但面对插入或缺失(InDels)这类「霰弹枪式改造」仍力不从心。解法?把训练目标从填空游戏(MLM)切换成接龙预测(Next Token),不过需要更庞大的算力和数据燃料!
🚀 挑战2.0:超长蛋白的「分块处理」
遇到新冠刺突蛋白这类「基因长篇小说」,ProMEP得像读PDF一样拆分成段落分析。未来可能用循环记忆Transformer实现「无限滚动阅读」,彻底告别上下文限制。
🤝 挑战3.0:蛋白质社交网络
现在ProMEP专注「单身蛋白」,若能整合蛋白质相互作用(PPI)数据,就能分析「蛋白复合体派对」——这对药物靶点设计简直是降维打击!
💡 未来科技树点法
-
强化学习(RL):让AI化身「突变策略师」,通过试错奖励机制自动优化设计路线
-
生成对抗网络(GANs):生成海量虚拟突变体,帮模型突破数据局限
-
图神经网络(GNNs):把蛋白质结构变成分子关系网,精准捕捉远程相互作用
终极愿景:当这些技术熔铸一炉,ProMEP将成为生物版的「ChatGPT」——输入目标功能,输出最优突变方案。从癌症治疗到碳中和酶设计,人类终于握住了改写生命蓝图的「代码钢笔」! ✍️🔬
赛博修仙版(科研放松时刻):
《AI修仙实录:ProMEP炼出「零样本蛋白质推背图」,基因编辑直破77%天劫》![]() https://blog.csdn.net/weixin_47520540/article/details/145813189?sharetype=blogdetail&sharerId=145813189&sharerefer=PC&sharesource=weixin_47520540&spm=1011.2480.3001.8118
https://blog.csdn.net/weixin_47520540/article/details/145813189?sharetype=blogdetail&sharerId=145813189&sharerefer=PC&sharesource=weixin_47520540&spm=1011.2480.3001.8118
相关文章:
AI颠覆蛋白质工程:ProMEP零样本预测突变效应
概述 在生命科学的“造物革命”中,蛋白质工程一直面临着“试错成本”与“设计效率”的双重挑战——传统方法依赖繁复的多序列比对(MSA)或耗时的实验室筛选,如同在浩瀚的蛋白质宇宙中盲选星辰。而今日,一项发表于《Cel…...

QT闲记-状态栏,模态对话框,非模态对话框
1、创建状态栏 跟菜单栏一样,如果是继承于QMainWindow类,那么可以获取窗口的状态栏,否则就要创建一个状态栏。通过statusBar()获取窗口的状态栏。 2、添加组件 通常添加Label 来显示相关信息,当然也可以添加其他的组件。通过addWidget()添加组件 3、设置状态栏样式 …...

QQ登录测试用例报告
QQ登录测试用例思维导图 一、安全性测试用例 1. 加密传输与存储验证 测试场景:输入账号密码并提交登录请求。预期结果:账号密码通过加密传输(如HTTPS)与存储(如哈希加盐),无明文暴露。 2. 二…...

ipad连接电脑断断续续,不断弹窗的解决办法
因为ipad air 屏幕摔坏,换了一个内外屏,想用爱思检验一下屏幕真伪, 连接电脑时,断断续续,连上几秒钟然后就断开,然后又连上 然后又断开,不断地弹出信任的弹窗。 刚开始以为是数据线问题&#x…...

《FFTformer:基于频域的高效Transformer用于高质量图像去模糊》
paper:2211.12250 GitHub:kkkls/FFTformer: [CVPR 2023] Effcient Frequence Domain-based Transformer for High-Quality Image Deblurring CVPR 2023 目录 摘要 1、介绍 2、相关工作 2.1 基于深度CNN的图像去模糊方法 2.2 Transformer及其在图…...

std::call_once
std::call_once 是 C11 标准库中提供的一个线程安全的一次性调用机制,位于 <mutex> 头文件中。它用于确保在多线程环境中,某个函数(或可调用对象)仅被调用一次,无论有多少线程尝试调用它。这种机制常用于实现线程…...

网络安全研究
1.1 网络安全面临的威胁 网络安全面临的威胁呈现出多样化和复杂化的趋势,给个人、企业和国家的安全带来了严峻挑战。以下是当前网络安全面临的主要威胁: 1.1.1 数据泄露风险 数据泄露是当前网络安全的重大威胁之一。根据国家互联网应急中心发布的《20…...

【软考网工】华为交换机命令
目录 1、华为交换机命令行的三种视图2、修改交换机名称3、关闭和开启信息中心4、vlan附录: 交换机型号:S5700 1、华为交换机命令行的三种视图 <Huaweu> #用户视图。特征:尖括号、用户名。 [Huawei] #系统视图。特…...

【行业解决方案篇十八】【DeepSeek航空航天:故障诊断专家系统 】
引言:为什么说这是“航天故障终结者”? 2025年春节刚过,航天宏图突然官宣"DeepSeek已在天权智能体上线",这个搭载在卫星和空间站上的神秘系统,号称能提前48小时预判99.97%的航天器故障。这不禁让人想起年初NASA禁用DeepSeek引发的轩然大波,更让人好奇:这套系…...

输入菜单关键字,遍历匹配到 menuIds,展开 匹配节点 的所有父节点以及 匹配节点 本身,高亮 匹配节点
菜单检索,名称、地址、权限标志 等 关键字匹配、展开、高亮(全程借助 DeepSeek ) 便捷简洁的企业官网 的后台菜单管理,图示: 改造点: (1)修改 bootstrapTreeTable 的节点class命名方式为:treeg…...

【Blender】二、建模篇--07,置换修改器
0 00:00:03,620 --> 00:00:08,620 大家好 这张课呢 我们来讲建模篇的最后一个重点修改器 置换修改器 1 00:00:08,980 --> 00:00:17,580 把它放在最后 不是因为它最难 而是因为它很常用 尤其大家以后做材质的时候 我们可以用一张贴图把一个平面做出来凹凸的感觉 2 00:00…...

玩转 Java 与 Python 交互,JEP 库来助力
文章目录 玩转 Java 与 Python 交互,JEP 库来助力一、背景介绍二、JEP 库是什么?三、如何安装 JEP 库?四、JEP 库的简单使用方法五、JEP 库的实际应用场景场景 1:数据处理场景 2:机器学习场景 3:科学计算场…...

鸿蒙学习-
鸿蒙数据传值 //* 传值 //* State /**State创建一个响应式的数据,但不是所有的更改都会引起刷新,只有被框架观察到的修改才会被刷新UI* 1. 基本数据类型如 number string boolean等值的变化修改* 2. Object类型,只会观察到第一层的数据变化或…...

list结构刨析与模拟实现
目录 1.引言 2.C模拟实现 2.1模拟实现结点 2.2模拟实现list前序 1)构造函数 2)push_back函数 2.3模拟实现迭代器 1)iterator 构造函数和析构函数: *操作符重载函数: 前置/后置/--: /!操作符重载…...

机器人部分专业课
华东理工 人工智能与机器人导论 Introduction of Artificial Intelligence and Robots 必修 考查 0.5 8 8 0 1 16477012 程序设计基础 The Fundamentals of Programming 必修 考试 3 64 32 32 1 47450012 算法与数据结构 Algorithm and Data Structure 必修 考试 3 56 40 …...

流行粗野主义几何风现代曲线标题logo设计psai无衬线英文字体安装包 Mortend – Extended Family
介绍我们名为 Mortend 的新探索,这是一个强大的扩展字体系列。Mortend 的设计具有几何形状、大胆、强烈的曲线和现代感。灵感来自当今流行的粗野主义海报和极简主义设计,让您有更多机会表达您的创造力。这个字体系列带来了强烈的感觉而优雅的外观&#x…...

前端常见面试题-2025
vue4.0 Vue.js 4.0 是在 2021 年 9 月发布。Vue.js 4.0 是 Vue.js 的一个重要版本,引入了许多新特性和改进,旨在提升开发者的体验和性能。以下是一些关键的更新和新特性: Composition API 重构:Vue 3 引入了 Composition API 作为…...
高通Camera点亮3——Camera Module
Camera点亮除了Sensor之外还需要配置module、EEPROM等,multicamera;配置好编译设置。 Module <?xml version"1.0" encoding"utf-8" ?> <cameraModuleData<!--Module group can contain either 1 module or 2 modules…...
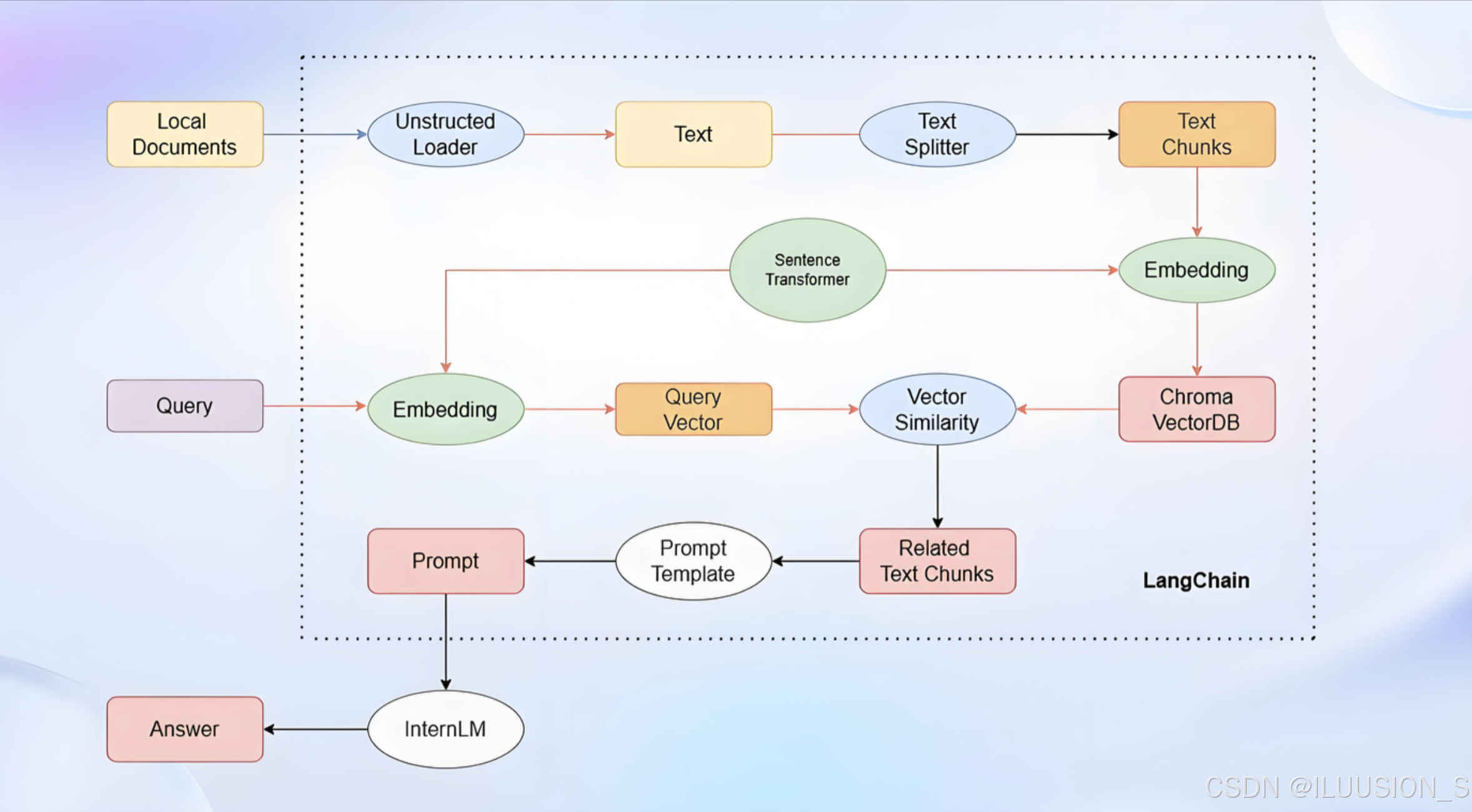
学习路程二 LangChain基本介绍
前面简单调用了一下deepseek的方法,发现有一些疑问和繁琐的问题,需要更多的学习,然后比较流行的就是LangChain这个东西了。 目前大部分企业都是基于 LangChain 、qwen-Agent、lammaIndex框架进行大模型应用开发。LangChain 提供了 Chain、To…...

Docker-技术架构演进之路
目录 一、概述 常见概念 二、架构演进 1.单机架构 2.应用数据分离架构 3.应用服务集群架构 4.读写分离 / 主从分离架构 5.引入缓存 —— 冷热分离架构 6.垂直分库 7.业务拆分 —— 微服务 8.容器化引入——容器编排架构 三、尾声 一、概述 在进行技术学习过程中&am…...

即将盲审的研究生,怕学术论文被拒,有什么方法能顺利过审?
马上又到一年一度的盲审季,不少研究生正怀着忐忑的心情,既担心自己的论文能否顺利通过,也焦虑着deadline一天天逼近。盲审,是决定能否顺利参加答辩、最终毕业的关键一关。在这个最后的冲刺阶段,怎样才能稳稳通过盲审&a…...

物联网物模型原理与2026年行业现状
对于物联网架构,一般分为云、管、端三部分,“端”可以简单的指设备、传感器,“云”一般指应用平台,而“管”就是指物联网平台,物联网平台的作用就是承上启下,向下接入各种不同类型的设备,向上提…...

让歌词动起来:给你的音乐播放器注入灵魂
让歌词动起来:给你的音乐播放器注入灵魂 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource 你是否曾经觉得,那些在屏幕上缓缓滚动的歌…...

实战解析:从通达信本地数据文件高效提取全市场股票代码与名称
1. 为什么需要本地解析股票数据 作为量化交易开发者,我经常遇到这样的尴尬场景:网络突然中断,但策略急需最新的股票代码表;或者高频请求交易所接口时被限制访问。这时候才意识到,过度依赖网络API是多么脆弱。其实像通达…...

CLIP-GmP-ViT-L-14效果展示:手绘草图-产品需求文档语义映射实例
CLIP-GmP-ViT-L-14效果展示:手绘草图-产品需求文档语义映射实例 1. 模型能力概览 CLIP-GmP-ViT-L-14是一个经过几何参数化(GmP)微调的视觉语言模型,在ImageNet和ObjectNet数据集上达到了约90%的准确率。这个模型特别擅长理解图像与文本之间的语义关联&…...

Arm AArch64寄存器体系与性能优化实战
1. Arm AArch64寄存器体系概览作为现代处理器架构的核心组成部分,寄存器在Armv8/v9架构中扮演着关键角色。AArch64作为Arm的64位执行状态,其寄存器设计体现了从传统嵌入式系统到云计算基础设施的全场景适应能力。与x86等CISC架构不同,Arm采用…...

Dify+农业知识库落地全流程:从零搭建高可用知识系统,7天交付可商用版本
第一章:Dify农业知识库项目背景与架构概览随着智慧农业加速落地,基层农技人员与新型经营主体对实时、精准、可解释的农业知识服务需求日益迫切。传统静态文档库与通用大模型问答存在专业性不足、数据更新滞后、推理过程不可控等问题。Dify农业知识库项目…...

LM镜像多场景应用:游戏原画初稿、服装面料模拟、虚拟偶像建模辅助
LM镜像多场景应用:游戏原画初稿、服装面料模拟、虚拟偶像建模辅助 1. LM镜像核心能力介绍 LM是基于Tongyi-MAI/Z-Image底座的文生图镜像,专为创意设计领域打造。这个开箱即用的解决方案已经完成模型预加载和Web页面封装,用户无需编写任何代码…...
)
Blazor WebAssembly性能突破78%!2026企业刚需:如何用Server-Side Hybrid模式重构ERP前端(附Gartner验证基准)
第一章:Blazor WebAssembly性能突破78%的底层机制解析Blazor WebAssembly 的性能跃升并非源于单一优化,而是由运行时、加载策略与执行模型三重协同驱动的系统性突破。核心在于 .NET IL 解释器(WebAssembly AOT 编译器)与浏览器 We…...

毕业季如何应对“双重危机”?百考通AI的查重与降AIGC解题思路
在2026年的学术赛道上,一个工具就能精准锁定重复率与AI痕迹,让你从焦虑走向从容 凌晨三点,宿舍里的灯光依旧亮着,屏幕上光标在修改了数次的段落间反复跳动。重复率居高不下,AIGC 检测预警频闪——这已成为 2026 年毕业…...