《FFTformer:基于频域的高效Transformer用于高质量图像去模糊》
paper:2211.12250
GitHub:kkkls/FFTformer: [CVPR 2023] Effcient Frequence Domain-based Transformer for High-Quality Image Deblurring
CVPR 2023
目录
摘要
1、介绍
2、相关工作
2.1 基于深度CNN的图像去模糊方法
2.2 Transformer及其在图像去模糊中的应用
2.3 基于频域的Transformer方法
3、方法
3.1 基于频域的自注意力求解器(FSAS)
3.2 判别性频域基前馈网络(DFFN)
3.3 非对称编码器-解码器网络
4、实验
4.1 数据集和参数设置
4.2 与现有方法的比较
4.3 消融实验
摘要
我们提出了一种有效且高效的方法,探索 Transformers 在频域中的属性,用于高质量图像去模糊。我们的方法受卷积定理的启发,即两个信号在空间域中的相关性或卷积等价于它们在频域中的逐元素乘积。这激发我们开发了一种高效的基于频域的自注意力求解器(FSAS),通过逐元素乘法操作估计缩放点积注意力,而不是在空间域中进行矩阵乘法。此外,我们注意到,仅仅使用传统的前馈网络(FFN)并不能生成良好的去模糊结果。为了解决这个问题,我们提出了一种简单但有效的区分性频域前馈网络(DFFN),在FFN中引入了基于联合图像专家组(JPEG)压缩算法的门控机制,用以区分性地决定应该保留哪些低频和高频信息,从而帮助恢复清晰的图像。我们将提出的FSAS和DFFN整合为一个基于编码器和解码器架构的非对称网络,其中FSAS仅在解码器模块中使用,以获得更好的图像去模糊效果。实验结果表明,所提出的方法在与最先进的方法相比时表现优越。
1、介绍
图像去模糊旨在从模糊的图像中恢复高质量的图像。由于各种有效的深度模型以及大规模训练数据集的发展,这个问题已经取得了显著的进展。大多数现有的图像去模糊方法主要基于深度卷积神经网络(CNNs)。这些方法的主要成功源于网络架构设计的进展,例如多尺度 [4,13,19] 或多阶段 [28,29] 网络架构,生成对抗学习 [8,9],受物理模型启发的网络结构 [14,30] 等。作为这些网络中的基本操作,卷积操作是一种空间不变的局部操作,它无法建模图像内容的空间变异特性。大多数方法通过增加更大的网络模型来弥补卷积的局限性。然而,仅仅增加深度模型的容量并不总是能带来更好的性能,如 [14,30] 所示。
不同于卷积操作模型局部连接,Transformers 能够通过计算一个token与其他所有tokens的相关性来建模全局上下文。Transformers 已被证明在许多高层次视觉任务中是有效的,并且具有成为深度CNN模型替代品的巨大潜力。在图像去模糊任务中,基于Transformers 的方法 [24,27] 相比于基于CNN的方法也取得了更好的性能。然而,Transformers 中缩放点积注意力的计算会导致空间和时间复杂度随着tokens数量的增加而呈二次增长。虽然使用更小且更少的tokens可以减少空间和时间复杂度,但这种策略不能很好地建模特征的长程信息,并且在处理高分辨率图像时通常会导致显著的伪影,从而限制了性能的提升。
为了解决这个问题,大多数方法采用下采样策略来降低特征的空间分辨率 [23]。然而,减少特征的空间分辨率会导致信息丢失,从而影响图像去模糊。一些方法通过计算基于特征数量的缩放点积注意力来降低计算成本 [26,27]。虽然计算成本有所降低,但空间信息没有得到充分探索,可能会影响去模糊效果。
在本文中,我们提出了一种有效且高效的方法,探索 Transformers 的属性来进行高质量的图像去模糊。我们注意到,缩放点积注意力的计算实际上是在估算一个token与所有键的tokens之间的相关性。通过重新排列tokens的排列,这个过程可以通过卷积操作来实现。基于这一观察,以及卷积定理(即空间域中的卷积等同于频域中的逐点乘法),我们提出了一种高效的基于频域的自注意力求解器(FSAS),通过逐元素乘法操作来估算缩放点积注意力,而不是使用矩阵乘法。因此,空间和时间复杂度可以降低到O(N) O(N logN)(每个特征通道),其中N是像素数量。
此外,我们注意到,仅仅使用 [27] 中的前馈网络(FFN)并不能生成良好的去模糊结果。为了生成更好的特征以恢复清晰图像,我们提出了一种简单却有效的区分性频域前馈网络(DFFN)。我们的DFFN受JPEG压缩算法的启发,在FFN中引入了门控机制,用来区分性地确定应该保留哪些低频和高频信息,以帮助恢复清晰图像。
我们将提出的FSAS和DFFN整合为一个端到端可训练的网络,基于编码器和解码器架构来解决图像去模糊问题。然而,我们发现,由于浅层的特征通常包含模糊效果,将缩放点积注意力应用于浅层特征并不能有效地探索全局清晰内容。由于深层的特征通常比浅层更清晰,我们开发了一个非对称网络架构,其中FSAS仅在解码器模块中使用,以实现更好的图像去模糊。我们分析认为,探索 Transformers 在频域中的特性有助于去除模糊。实验结果表明,所提出的方法在准确性和效率上都优于现有的最先进方法(见图1)。

贡献总结:
-
我们提出了一种高效的基于频域的自注意力求解器,用于估算缩放点积注意力。我们的分析表明,使用基于频域的求解器可以降低空间和时间复杂度,且更加有效和高效。
-
我们提出了一种简单但有效的区分性频域前馈网络(DFFN),基于JPEG压缩算法,区分性地决定哪些低频和高频信息应被保留,以恢复清晰图像。
-
我们开发了一个基于编码器和解码器网络的非对称网络架构,其中基于频域的自注意力求解器仅在解码器模块中使用,以更好地进行图像去模糊。
-
我们分析了探索变换器在频域中的特性有助于去除模糊,并展示了我们的方法在与最先进方法的对比中表现优异。
2、相关工作
2.1 基于深度CNN的图像去模糊方法
近年来,随着不同深度卷积神经网络(CNN)模型的出现,图像去模糊技术取得了显著进展。例如,Nah等人提出了一种基于多尺度框架的深度CNN,用于直接从模糊图像中估计清晰图像。为了更好地利用多尺度框架中的每个尺度信息,Tao等人开发了有效的尺度递归网络。Gao等人提出了一种选择性网络参数共享方法,旨在提高[13, 19]方法的性能。
由于使用更多尺度并未显著提高性能,Zhang等人提出了一种基于多 patch 策略的有效网络,去模糊过程逐步进行。为了更好地探索不同阶段的特征,Zamir等人提出了跨阶段特征融合方法。此外,Cho等人提出了一种多输入多输出的网络,以减少基于多尺度框架方法的计算成本。Chen等人则分析了基准模块并简化它们以提高图像恢复效果。正如[27]中所示,卷积操作具有空间不变性,无法有效地建模全局上下文信息,从而限制了去模糊性能。
2.2 Transformer及其在图像去模糊中的应用
Transformer能够建模全局上下文,并且在许多高层视觉任务中取得了显著进展(例如图像分类[11]、目标检测[1, 31]、语义分割[25, 32])。它已经被应用于解决图像超分辨率[10]、图像去模糊[21, 27]和图像去噪[2, 24]等问题。为了减少Transformer的计算成本,Zamir等人[27]提出了一种高效的Transformer模型,通过在特征深度域计算缩放点积注意力来有效探索不同特征的信息。然而,这种方法并没有充分探索对于图像恢复至关重要的空间信息。
Tsai等人[21]通过构建条带内和条带间的token来简化自注意力的计算,以替代全局注意力。Wang等人[24]提出了一种基于UNet的Transformer,采用非重叠窗口的自注意力进行单幅图像去模糊。尽管使用分割策略减少了计算成本,但粗糙的分割方式并不能充分探索每个补丁的信息。并且,这些方法中的缩放点积注意力通常需要复杂的矩阵乘法,其空间和时间复杂度为二次方。
2.3 基于频域的Transformer方法
与这些方法不同,本文提出了一种高效的基于Transformer的方法,探索频域的特性,从而避免了计算缩放点积注意力时的复杂矩阵乘法。
3、方法

3.1 基于频域的自注意力求解器(FSAS)
给定具有空间分辨率为H×W像素和C通道的输入特征X,现有的视觉Transformer通常首先通过对X应用线性变换、
和
来计算特征
、
和
。然后,它们对特征
、
和
应用展开函数,提取图像补丁
,其中N表示提取的 patch 数量。通过对提取的patch 应用重塑操作,可以得到查询Q、键K和值V,公式如下:
其中,R 表示重塑函数,确保,
和
分别表示提取patch 的高度和宽度。基于得到的查询Q、键K和值V,缩放点积注意力通过以下公式计算:
注意力映射的计算涉及矩阵乘法,其空间复杂度和时间复杂度分别为O(N²)和O(N²C)。当图像分辨率和提取的 patch 数量较大时,计算开销非常高。虽然通过下采样操作减少图像分辨率或使用非重叠方法提取较少的补丁可以缓解问题,但这些策略会导致信息丢失,并限制建模补丁内外细节的能力[26]。
我们注意到, 的每个元素是通过内积得到的:
其中 和
分别是
和
中的第 i 个和第 j 个补丁的向量化形式。基于公式(3),如果我们分别对
和所有补丁
应用重塑函数,则
的所有第i列元素可以通过卷积操作得到,即:
,其中
和
分别表示重塑后的
和
;
表示卷积操作。
根据卷积定理,空间域中两个信号的相关性或卷积等价于它们在频域中的逐元素乘积。因此,一个自然的问题是:我们能否通过在频域中进行逐元素乘积操作来有效地估计注意力图,而不是在空间域中计算QK的矩阵乘法?
为此,我们开发了一种有效的基于频域的自注意力求解器。具体而言,我们首先通过1×1点卷积和3×3深度卷积获得。然后,我们对估计的特征
和
应用快速傅里叶变换(FFT),并通过以下公式估计
和
在频域中的相关性:
其中,表示FFT操作,
表示逆FFT操作,
表示逐元素乘积操作。
(在SA 里面加了一层傅里叶变换)
最后,我们通过以下公式估计聚合特征:
其中, 表示用于归一化 A 的层归一化操作,之后与
做点积。最终,我们通过以下公式生成FSAS的输出特征:
其中,表示1×1像素的卷积操作。提出的FSAS的详细网络架构如图2(b)所示。

3.2 判别性频域基前馈网络(DFFN)
前馈网络(FFN)用于通过缩放点积注意力来改进特征。因此,开发一个有效的前馈网络以生成有助于潜在清晰图像重建的特征是非常重要的。由于并非所有低频信息和高频信息都对潜在清晰图像的恢复有帮助,我们开发了一种判别性频域前馈网络(DFFN),它可以自适应地决定应该保留哪些频率信息。然而,如何有效地确定哪些频率信息是重要的呢?受到JPEG压缩算法启发,我们引入了一个可学习的量化矩阵W,并通过JPEG压缩的逆方法来学习它,从而确定应该保留哪些频率信息。
提出的DFFN可以通过以下公式进行表述:
其中,和
分别表示JPEG压缩方法中的补丁展开和折叠操作;
表示[16]中的GEGLU函数。提出的DFFN的详细网络架构如图2(c)所示。

3.3 非对称编码器-解码器网络
我们将提出的FSAS和DFFN嵌入到一个基于编码器-解码器架构的网络中。我们注意到,大多数现有方法通常使用对称的架构,在编码器和解码器模块中使用相同的组件。例如,如果FSAS和DFFN被用在编码器模块中,它们也会出现在解码器模块中。然而,编码器模块提取的特征是浅层特征,相较于解码器模块中的深层特征,它们通常包含模糊效果。然而,模糊通常会改变清晰特征中两个相似 patch 的相似性。因此,在编码器模块中使用FSAS可能无法正确估计相似性,从而影响图像恢复。为了解决这个问题,我们将FSAS嵌入到解码器模块中,这导致了一个非对称的架构,从而实现更好的图像去模糊。图2(a)展示了提出的非对称编码器-解码器网络的架构。
最后,给定一张模糊图像B,通过非对称编码器-解码器网络估计恢复后的图像I:
其中,N表示非对称编码器-解码器网络。
4、实验
4.1 数据集和参数设置
数据集
我们在常用的图像去模糊数据集上评估我们的方法,包括GoPro数据集[13]、HIDE数据集[17]和RealBlur数据集[15]。我们遵循现有方法的协议进行公平比较。
参数设置
我们使用与[4]相同的损失函数来约束网络,并使用默认参数的Adam优化器[7]进行训练。学习率的初始值为 ,并在600,000次迭代后采用余弦退火策略进行更新。学习率的最小值为
。补丁大小经验设定为 256×256 像素,批次大小为16。我们在训练过程中采用与[27]相同的数据增强方法。权重矩阵估计的 patch 大小根据JPEG压缩方法经验设定为 8×8 。类似地,我们在计算自注意力(公式(4))时也使用 8×8 像素的 patch 。由于页面限制,我们在补充材料中包含了更多的实验结果。
4.2 与现有方法的比较
我们将我们的方法与现有的最先进方法进行比较,并使用PSNR和SSIM来评估恢复图像的质量。
在GoPro数据集上的评估
我们首先在常用的GoPro数据集[13]上评估我们的方法。为了公平比较,我们遵循该数据集的协议,并重新训练或微调那些未在该数据集上训练的深度学习方法。表1展示了定量评估结果。我们的方法生成了具有最高PSNR和SSIM值的结果。与现有的基于CNN的方法NAFNet[3]相比,我们的方法在PSNR上至少比NAFNet高0.5dB,同时我们提出的模型的参数数量仅为NAFNet的四分之一。此外,与基于Transformer的方法[21,24,27]相比,我们的方法在模型参数最少的情况下,表现更好。

图3展示了我们的方法与评估方法在GoPro数据集上的视觉比较。如[27]所示,基于CNN的方法[3,4]未能有效地探索非局部信息用于潜在清晰图像的恢复。因此,这些方法[3,4]恢复的图像仍然存在显著的模糊效果,如图3(c)和(g)所示。基于Transformer的方法[5,21,27]能够建模图像去模糊的全局上下文,但一些主要结构(如人物和椅子)没有得到很好的恢复(见图3(d)-(f))。与现有的基于空间域的Transformer方法不同,我们开发了一个高效的基于频域的Transformer,提出的DFFN能够有选择性地估计对潜在清晰图像恢复有用的频率信息。因此,去模糊的结果具有清晰的结构,人物更加清晰,如图3(h)所示。

在RealBlur数据集上的评估
我们进一步在RealBlur数据集[15]上评估我们的方法,并遵循该数据集的协议进行公平比较。[15]的测试集包括来自原始图像的RealBlur-R测试集和来自JPEG图像的RealBlur-J测试集。表2总结了上述测试集的定量评估结果。我们提出的方法生成了具有更高PSNR和SSIM值的结果。

在HIDE数据集上的评估
然后,我们在HIDE数据集[17]上评估我们的方法,该数据集主要包含人物。与现有的最先进方法[4,28]类似,我们直接使用评估方法的模型,这些模型是在GoPro数据集上训练的用于测试。表3显示,我们的方法生成的去模糊图像质量优于评估方法,表明我们的模型在未在此数据集上训练的情况下具有更好的泛化能力。

我们在图5中展示了一些视觉比较。我们注意到,评估的方法未能很好地恢复人物。而我们的方式生成的图像效果更好。例如,人物的面部和衣服的拉链更加清晰。

4.3 消融实验
我们已经展示了在频域中探索Transformer的属性相较于现有最先进方法能产生更优的结果。本节中,我们将进一步分析所提出方法的效果,并展示主要组件的影响。为了进行消融实验,我们在GoPro数据集上训练我们的方法以及所有基准方法,批次大小设置为8,以说明每个组件在方法中的作用。
FSAS的效果
提出的FSAS用于减少计算成本。根据FFT的属性,FSAS的空间和时间复杂度分别为 O(N)和 O(NClogN),这比原始的缩放点积注意力计算的 和
要低得多,其中 C 是特征的数量。我们进一步检查了FSAS和基于窗口的策略[11,24]的空间和时间复杂度。表4显示,使用提出的FSAS比基于窗口的策略[24]需要更少的GPU内存,并且更加高效。

此外,由于提出的 FSAS 是在频域中执行的,可能会有人质疑在空间域中执行的缩放点积注意力是否效果更好。为了解答这个问题,我们将FSAS与在空间域中执行的基准方法进行比较(简称“SAw/SD”)。由于原始的缩放点积注意力的空间复杂度是 ,因此在与提出的FSAS相同的设置下训练“SAw/SD”是不可行的。我们使用Swin Transformer[11]进行比较,因为它更高效。表5展示了GoPro数据集上的定量评估结果。计算空间域中的缩放点积注意力的方法生成的去模糊结果不佳,其PSNR值比“FSAS+DFFN”低0.27(参见表5中“SAw/SD”和“FSAS+DFFN”的比较)。

主要原因是,尽管使用了位移窗口分区方法来减少计算成本,但它并没有充分探索不同窗口之间有用的信息。相比之下,提出的FSAS的空间复杂度是 O(N) ,且不需要作为近似的位移窗口分区方法,因此生成了更好的去模糊结果。图6(b)进一步展示了在空间域中将位移窗口分区作为缩放点积注意力的近似方法时,去模糊效果不佳。而提出的FSAS生成了更清晰的图像。

此外,与仅使用FFN的基准方法(“w/ only FFN”)相比,使用提出的FSAS的结果明显更好,PSNR值提高了0.42dB(参见表5中“w/ only FFN”和“FSAS+FFN”的比较)。图7(b)和(c)的视觉比较进一步证明了使用提出的FSAS有助于去除模糊效果,图像边界恢复得很好,如图7(c)所示。

DFFN的效果
提出的DFFN用于区分性地估计有用的频率信息,从而恢复潜在的清晰图像。为了展示其在图像去模糊中的效果,我们将提出的方法与两个基准进行比较。
第一个基准,我们比较仅使用DFFN的提出方法(简称“w/ only DFFN”)和仅使用原始FFN的提出方法(简称“w/ only FFN”)。
第二个基准,我们比较提出的方法与在提出的方法中将DFFN替换为原始FFN的情况(“FSAS+FFN”)。
表5中的“w/ only DFFN”和“w/ only FFN”的比较表明,使用提出的DFFN能够生成更好的结果,PSNR值提高了0.36dB。此外,表5中的“FSAS+FFN”和“FSAS+DFFN”的比较表明,使用提出的DFFN进一步提高了性能。
非对称编码器-解码器网络的效果
如第3.3节所示,编码器模块提取的浅层特征通常包含模糊效应,这会影响FSAS的估计。因此,我们将FSAS嵌入到解码器模块中,从而形成一个非对称的编码器-解码器网络,以获得更好的图像去模糊效果。为了检验这种网络设计的效果,我们将FSAS同时放入编码器和解码器模块进行比较(表6中的“FSAS in enc&dec”)。表6显示,将FSAS放入解码器模块能够生成更好的结果,PSNR值至少高0.17dB。图9(b)和(c)的视觉比较进一步证明,将FSAS放入解码器模块能够生成更清晰的图像。

相关文章:
《FFTformer:基于频域的高效Transformer用于高质量图像去模糊》
paper:2211.12250 GitHub:kkkls/FFTformer: [CVPR 2023] Effcient Frequence Domain-based Transformer for High-Quality Image Deblurring CVPR 2023 目录 摘要 1、介绍 2、相关工作 2.1 基于深度CNN的图像去模糊方法 2.2 Transformer及其在图…...

std::call_once
std::call_once 是 C11 标准库中提供的一个线程安全的一次性调用机制,位于 <mutex> 头文件中。它用于确保在多线程环境中,某个函数(或可调用对象)仅被调用一次,无论有多少线程尝试调用它。这种机制常用于实现线程…...

网络安全研究
1.1 网络安全面临的威胁 网络安全面临的威胁呈现出多样化和复杂化的趋势,给个人、企业和国家的安全带来了严峻挑战。以下是当前网络安全面临的主要威胁: 1.1.1 数据泄露风险 数据泄露是当前网络安全的重大威胁之一。根据国家互联网应急中心发布的《20…...

【软考网工】华为交换机命令
目录 1、华为交换机命令行的三种视图2、修改交换机名称3、关闭和开启信息中心4、vlan附录: 交换机型号:S5700 1、华为交换机命令行的三种视图 <Huaweu> #用户视图。特征:尖括号、用户名。 [Huawei] #系统视图。特…...

【行业解决方案篇十八】【DeepSeek航空航天:故障诊断专家系统 】
引言:为什么说这是“航天故障终结者”? 2025年春节刚过,航天宏图突然官宣"DeepSeek已在天权智能体上线",这个搭载在卫星和空间站上的神秘系统,号称能提前48小时预判99.97%的航天器故障。这不禁让人想起年初NASA禁用DeepSeek引发的轩然大波,更让人好奇:这套系…...

输入菜单关键字,遍历匹配到 menuIds,展开 匹配节点 的所有父节点以及 匹配节点 本身,高亮 匹配节点
菜单检索,名称、地址、权限标志 等 关键字匹配、展开、高亮(全程借助 DeepSeek ) 便捷简洁的企业官网 的后台菜单管理,图示: 改造点: (1)修改 bootstrapTreeTable 的节点class命名方式为:treeg…...

【Blender】二、建模篇--07,置换修改器
0 00:00:03,620 --> 00:00:08,620 大家好 这张课呢 我们来讲建模篇的最后一个重点修改器 置换修改器 1 00:00:08,980 --> 00:00:17,580 把它放在最后 不是因为它最难 而是因为它很常用 尤其大家以后做材质的时候 我们可以用一张贴图把一个平面做出来凹凸的感觉 2 00:00…...

玩转 Java 与 Python 交互,JEP 库来助力
文章目录 玩转 Java 与 Python 交互,JEP 库来助力一、背景介绍二、JEP 库是什么?三、如何安装 JEP 库?四、JEP 库的简单使用方法五、JEP 库的实际应用场景场景 1:数据处理场景 2:机器学习场景 3:科学计算场…...

鸿蒙学习-
鸿蒙数据传值 //* 传值 //* State /**State创建一个响应式的数据,但不是所有的更改都会引起刷新,只有被框架观察到的修改才会被刷新UI* 1. 基本数据类型如 number string boolean等值的变化修改* 2. Object类型,只会观察到第一层的数据变化或…...

list结构刨析与模拟实现
目录 1.引言 2.C模拟实现 2.1模拟实现结点 2.2模拟实现list前序 1)构造函数 2)push_back函数 2.3模拟实现迭代器 1)iterator 构造函数和析构函数: *操作符重载函数: 前置/后置/--: /!操作符重载…...

机器人部分专业课
华东理工 人工智能与机器人导论 Introduction of Artificial Intelligence and Robots 必修 考查 0.5 8 8 0 1 16477012 程序设计基础 The Fundamentals of Programming 必修 考试 3 64 32 32 1 47450012 算法与数据结构 Algorithm and Data Structure 必修 考试 3 56 40 …...

流行粗野主义几何风现代曲线标题logo设计psai无衬线英文字体安装包 Mortend – Extended Family
介绍我们名为 Mortend 的新探索,这是一个强大的扩展字体系列。Mortend 的设计具有几何形状、大胆、强烈的曲线和现代感。灵感来自当今流行的粗野主义海报和极简主义设计,让您有更多机会表达您的创造力。这个字体系列带来了强烈的感觉而优雅的外观&#x…...

前端常见面试题-2025
vue4.0 Vue.js 4.0 是在 2021 年 9 月发布。Vue.js 4.0 是 Vue.js 的一个重要版本,引入了许多新特性和改进,旨在提升开发者的体验和性能。以下是一些关键的更新和新特性: Composition API 重构:Vue 3 引入了 Composition API 作为…...
高通Camera点亮3——Camera Module
Camera点亮除了Sensor之外还需要配置module、EEPROM等,multicamera;配置好编译设置。 Module <?xml version"1.0" encoding"utf-8" ?> <cameraModuleData<!--Module group can contain either 1 module or 2 modules…...
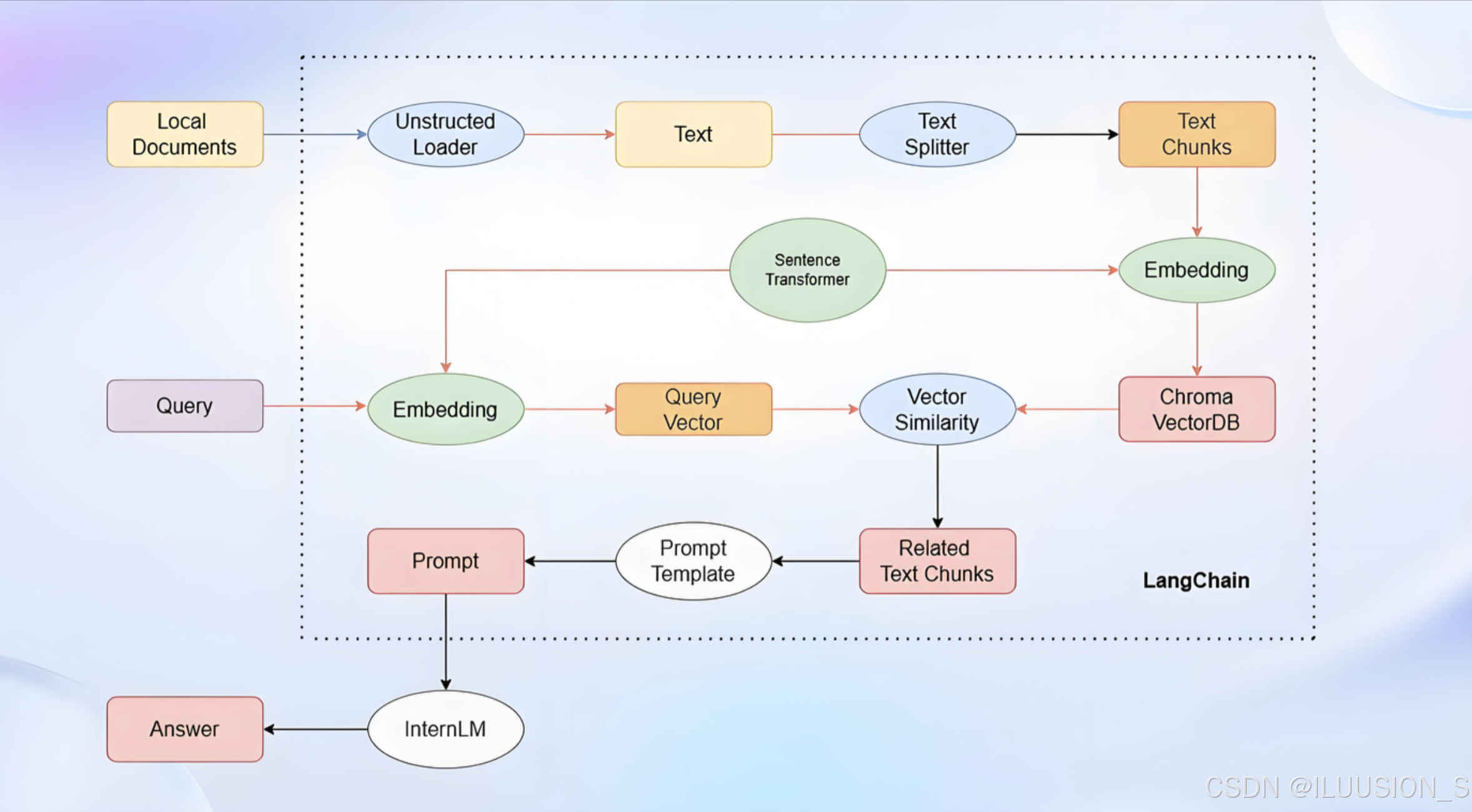
学习路程二 LangChain基本介绍
前面简单调用了一下deepseek的方法,发现有一些疑问和繁琐的问题,需要更多的学习,然后比较流行的就是LangChain这个东西了。 目前大部分企业都是基于 LangChain 、qwen-Agent、lammaIndex框架进行大模型应用开发。LangChain 提供了 Chain、To…...

Docker-技术架构演进之路
目录 一、概述 常见概念 二、架构演进 1.单机架构 2.应用数据分离架构 3.应用服务集群架构 4.读写分离 / 主从分离架构 5.引入缓存 —— 冷热分离架构 6.垂直分库 7.业务拆分 —— 微服务 8.容器化引入——容器编排架构 三、尾声 一、概述 在进行技术学习过程中&am…...

API接口设计模式:从分层架构到CQRS的实战应用
以下将从分层架构和 CQRS(命令查询职责分离)的基本概念入手,为你阐述从分层架构到 CQRS 的实战应用相关内容: 分层架构 概念:分层架构是将系统按照功能划分为不同的层次,每个层次负责特定的职责,…...

【机器学习】【KMeans聚类分析实战】用户分群聚类详解——SSE、CH 指数、SC全解析,实战电信客户分群案例
1.引言 在实际数据分析中,聚类算法常用于客户分群、图像分割等场景。如何确定聚类数 k 是聚类分析中的关键问题之一。本文将以“用户分群”为例,展示如何通过 KMeans 聚类,利用 SSE(误差平方和,也称 Inertiaÿ…...

【C++】 时间库chrono计算程序运行时间
C 时间库chrono计算程序运行时间 本文总结了chrono库的引入方法以及计算程序片段运行时间的方法 一、chrono库的引入方法(注意事项) 首先chrono是属于std命名空间的。 所以在程序中应该这样包含头文件: #include <chrono> using n…...
)
PCL 边界体积层次结构(Boundary Volume Hierarchy, BVH)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 边界体积层次结构(Boundary Volume Hierarchy, BVH) 是一种高效的空间数据结构,广泛应用于计算机图形学、计算机视觉、机器人学、物理仿真等领域。它的核心思想是通过将空间递归地划分为层次化的包围体(通常是轴…...

数学建模小白必看:从组队到拿奖,避开这5个坑你也能成大神
数学建模竞赛避坑指南:从组队到获奖的实战策略 第一次参加数学建模竞赛时,我和两位室友组队,信心满满地选了最短的题目——结果三天后交了一篇连格式都没调好的论文。那次惨痛经历让我明白,数学建模远不止解题那么简单。本文将分…...
)
SAP采购订单行项目增强实战:用BADI ME_GUI_PO_CUST添加自定义字段(避坑指南)
SAP采购订单行项目增强实战:用BADI ME_GUI_PO_CUST添加自定义字段(避坑指南) 在SAP标准采购订单(ME21N/ME22N/ME23N)中扩展行项目字段是常见的业务需求,比如添加"紧急程度"或"内部备注"…...

CV炼丹师的效率神器:5分钟看懂CBAM注意力机制,轻松提升你的模型精度
CV炼丹师的效率神器:5分钟看懂CBAM注意力机制,轻松提升你的模型精度 深夜的实验室里,显示器泛着幽幽蓝光。你盯着训练曲线已经三个小时,准确率卡在89.7%纹丝不动。隔壁组的实习生刚把模型精度提升了2.3%,组长看你的眼神…...

DDrawCompat终极指南:3步快速修复Windows老游戏兼容性问题 [特殊字符]
DDrawCompat终极指南:3步快速修复Windows老游戏兼容性问题 🎮 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh…...
)
别再只盯着GPU了!聊聊手机里那个能效比爆表的CGRA NPU(以华为麒麟为例)
别再只盯着GPU了!聊聊手机里那个能效比爆表的CGRA NPU(以华为麒麟为例) 当你用手机拍下一张夜景照片,AI算法在毫秒间完成降噪、HDR合成和细节增强——这背后不是GPU在发力,而是一个名为NPU的专用处理器正在以极低功耗高…...
)
企业级容器网络合规最后一道防线(Docker 27强制隔离模式启用倒计时72小时)
第一章:Docker 27强制网络隔离的合规背景与战略意义Docker 27 引入的强制网络隔离机制并非单纯的技术演进,而是对全球日益严苛的数据治理框架的主动响应。GDPR、CCPA、中国《数据安全法》及等保2.0均明确要求“最小化网络暴露面”与“逻辑域间访问可控”…...

RPG Maker MV/MZ 资源解锁指南:3分钟学会游戏资源解密与加密
RPG Maker MV/MZ 资源解锁指南:3分钟学会游戏资源解密与加密 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://g…...

从一个小D触发器开始:手把手带你用Quartus Prime Power Analyzer完成你的第一个芯片功耗评估报告
从D触发器到功耗分析:Quartus Prime Power Analyzer实战指南 在FPGA设计流程中,功耗分析往往是被初学者忽视却又至关重要的一环。想象一下,你精心设计的电路在仿真时表现完美,但实际部署后却因为功耗问题导致发热严重或电池续航大…...

用Python复现SRM隐写分析:从残差计算到34671维特征提取的保姆级教程
用Python复现SRM隐写分析:从残差计算到34671维特征提取的保姆级教程 在数字图像安全领域,SRM(Spatial Rich Model)作为空域富模型隐写分析的黄金标准,其高达34671维的特征向量构建过程常令研究者望而生畏。本文将用Pyt…...

Driver Store Explorer:Windows驱动存储管理的开源系统优化工具终极指南
Driver Store Explorer:Windows驱动存储管理的开源系统优化工具终极指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统中不断膨胀的驱动存储而烦恼&…...