【Python爬虫(60)】解锁社交媒体数据宝藏:Python爬虫实战攻略
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取,还涉及数据处理与分析。无论是新手小白还是进阶开发者,都能从中汲取知识,助力掌握爬虫核心技能,开拓技术视野。
目录
- 一、某博数据爬取
- 1.1 准备工作
- 1.2 获取用户信息
- 1.3 某博内容爬取
- 1.4 评论获取
- 二、某音数据爬取
- 2.1 环境搭建
- 2.2 视频信息提取
- 2.3 用户粉丝关系获取
- 2.4 点赞评论数据爬取
- 三、应对反爬虫机制
- 3.1 某博反爬虫策略及应对
- 3.2 某音反爬虫策略及应对
- 四、数据隐私问题处理
- 4.1 法律法规遵守
- 4.2 数据脱敏处理
- 五、总结与展望
一、某博数据爬取
1.1 准备工作
在进行某博数据爬取之前,我们需要准备好一些必要的工具,主要是安装和导入相关的 Python 库。首先是requests库,它是一个用于发送 HTTP 请求的强大库,使用它可以方便地与某博服务器进行交互,获取网页内容。通过pip install requests命令即可完成安装,安装完成后在代码中使用import requests导入。
BeautifulSoup库也是不可或缺的,它主要用于解析 HTML 和 XML 文档,能够帮助我们从获取到的网页内容中提取出我们需要的数据,比如某博的用户信息、某博内容等。安装命令为pip install beautifulsoup4 ,导入方式是from bs4 import BeautifulSoup。
另外,如果需要处理 JSON 数据格式(某博 API 返回的数据很多是 JSON 格式),还需要用到 Python 内置的json库,直接使用import json导入即可。
1.2 获取用户信息
获取某博用户信息有两种常见的方式,一种是通过某博 API,另一种是通过网页解析。
使用某博 API 获取用户信息,首先需要在某博开放平台注册并创建应用,获取 App Key、App Secret 等认证信息。以获取用户基本信息(如昵称、粉丝数、关注数等)为例,使用weibo库(需提前安装,pip install weibo ),代码示例如下:
from weibo import APIClientAPP_KEY = '你的App Key'
APP_SECRET = '你的App Secret'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html'client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
# 获取授权码等步骤省略
access_token = '你的access_token'
client.set_access_token(access_token, '123456') # 假设用户ID为123456
user_info = client.users.show.get(uid='123456')
nickname = user_info['screen_name']
followers_count = user_info['followers_count']
friends_count = user_info['friends_count']
print(f"昵称: {nickname}, 粉丝数: {followers_count}, 关注数: {friends_count}")
如果通过网页解析获取用户信息,可以先发送 HTTP 请求获取用户主页内容,然后使用BeautifulSoup进行解析。例如:
url = 'https://weibo.com/u/123456' # 假设用户ID为123456
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
nickname = soup.find('a', class_='name').text
followers_count = soup.find('li', class_='followed').find('em').text
friends_count = soup.find('li', class_='following').find('em').text
print(f"昵称: {nickname}, 粉丝数: {followers_count}, 关注数: {friends_count}")
1.3 某博内容爬取
爬取某博内容同样可以通过 API 或网页解析实现。通过 API 获取某博内容时,以获取某个用户发布的某博列表为例:
statuses = client.statuses.user_timeline.get(uid='123456', count=20) # 获取20条某博
for status in statuses['statuses']:text = status['text']pic_urls = status.get('pic_urls', [])created_at = status['created_at']print(f"某博内容: {text}, 图片链接: {pic_urls}, 发布时间: {created_at}")
通过网页解析爬取某博内容时,要注意某博内容很多是动态加载的。以抓取某个用户的某博内容为例,可能需要分析网页的 XHR(XMLHttpRequest)请求,找到加载某博内容的接口。假设找到接口为https://m.weibo.cn/api/container/getIndex ,参数type=uid ,value=123456 (用户 ID),containerid=107603123456 :
url = 'https://m.weibo.cn/api/container/getIndex'
params = {'type': 'uid','value': '123456','containerid': '107603123456'
}
response = requests.get(url, params=params)
data = response.json()
for card in data['data']['cards']:if 'mblog' in card:mblog = card['mblog']text = mblog['text']pic_urls = mblog.get('pic_urls', [])created_at = mblog['created_at']print(f"某博内容: {text}, 图片链接: {pic_urls}, 发布时间: {created_at}")
1.4 评论获取
获取某博评论可以通过分析评论页面的网络请求来实现。一般来说,某博评论也是通过 AJAX 请求动态加载的。例如,对于某条某博,其评论接口可能是https://m.weibo.cn/comments/hotflow ,参数包括某博的id等。
weibo_id = '4900000000000000' # 某博ID
url = 'https://m.weibo.cn/comments/hotflow'
params = {'id': weibo_id,'mid': weibo_id,'max_id_type': '0'
}
response = requests.get(url, params=params)
data = response.json()
for comment in data['data']['data']:comment_text = comment['text']comment_user = comment['user']['screen_name']comment_created_at = comment['created_at']print(f"评论内容: {comment_text}, 评论者: {comment_user}, 评论时间: {comment_created_at}")
在实际获取评论时,还需要解决评论与某博内容对应的问题。可以在获取某博内容时,记录下每条某博的唯一标识(如某博 ID),在获取评论时,通过评论接口中的参数(如某博 ID)来确保获取的评论是对应某博的 。同时,由于某博评论可能较多,可能需要分页获取,通过修改请求参数中的max_id等实现分页。
二、某音数据爬取
2.1 环境搭建
要进行某音数据爬取,首先需要搭建合适的环境。Python 的requests库是必不可少的,用于发送 HTTP 请求,和某音服务器进行通信,通过pip install requests进行安装。
BeautifulSoup库用于解析 HTML 和 XML 文档,方便从某音网页中提取数据,安装命令为pip install beautifulsoup4 。
如果需要进行模拟浏览器操作,比如处理登录、获取动态加载的数据等,Selenium库是个不错的选择。Selenium可以驱动真实的浏览器,如 Chrome、Firefox 等,安装方式为pip install selenium 。同时,还需要下载对应浏览器的驱动,例如 Chrome 浏览器需要下载 ChromeDriver,将其路径添加到系统环境变量中。
此外,由于某音数据很多以 JSON 格式返回,json库(Python 内置)用于处理 JSON 数据,直接导入即可使用。
2.2 视频信息提取
获取某音视频信息有多种途径。如果是通过网页端获取,首先要分析某音网页的结构。在浏览器中打开某音视频页面,按F12键打开开发者工具,切换到 “Network” 选项卡,刷新页面,就可以看到浏览器与服务器之间的通信请求。
通过分析这些请求,我们可以找到包含视频信息的接口。例如,某个视频的信息可能在一个类似https://www.douyin.com/aweme/v1/aweme/detail/?aweme_id=视频ID的接口中返回,其中aweme_id是视频的唯一标识。使用requests库发送请求获取该接口的数据:
import requestsaweme_id = '6900000000000000000'
url = f'https://www.douyin.com/aweme/v1/aweme/detail/?aweme_id={aweme_id}'
response = requests.get(url)
if response.status_code == 200:data = response.json()video_title = data['aweme_detail']['desc']digg_count = data['aweme_detail']['statistics']['digg_count']comment_count = data['aweme_detail']['statistics']['comment_count']share_count = data['aweme_detail']['statistics']['share_count']print(f"视频标题: {video_title}, 点赞数: {digg_count}, 评论数: {comment_count}, 转发数: {share_count}")
如果是从 APP 端获取视频信息,可以使用抓包工具,如 Fiddler、Charles 等。以 Fiddler 为例,首先需要将手机和电脑连接到同一局域网,然后配置手机的代理为电脑的 IP 和 Fiddler 的端口(默认 8888) 。在手机上打开某音 APP,播放视频,Fiddler 就能捕获到手机与某音服务器之间的通信数据包。通过分析这些数据包,找到包含视频信息的请求,提取其中的数据。
2.3 用户粉丝关系获取
获取某音用户粉丝关系可以通过某音 API 或者特定的网页分析方法。
使用某音 API 获取粉丝列表和关注列表时,需要先在某音开放平台注册并创建应用,获取相关的认证信息。以获取用户粉丝列表为例,假设 API 接口为https://api.amemv.com/aweme/v1/user/follower/list/ ,参数包括user_id(用户 ID)、max_time(获取列表的最后一条数据的创建时间,用于分页)、count(每页返回的数据量)等。代码示例如下:
import requests
import jsonuser_id = '123456789'
max_time = 0
count = 20
followers = []while True:url = f'https://api.amemv.com/aweme/v1/user/follower/list/?user_id={user_id}&max_time={max_time}&count={count}'response = requests.get(url)if response.status_code == 200:data = json.loads(response.text)has_more = data.get('has_more')if not has_more:breakmax_time = data.get('max_time')followers += data.get('followers', [])else:breakfor follower in followers:follower_nickname = follower['nickname']follower_uid = follower['uid']print(f"粉丝昵称: {follower_nickname}, 粉丝ID: {follower_uid}")
通过网页分析方法获取粉丝关系时,需要分析用户主页的 HTML 结构和相关的 JavaScript 代码。在用户主页中,粉丝列表和关注列表通常是通过 AJAX 请求动态加载的。通过查找这些 AJAX 请求的接口,发送请求并解析返回的数据,从而获取粉丝和关注者的信息。同时,可以通过分析粉丝和关注者之间的相互关系,比如 A 关注了 B,B 是否也关注了 A,统计出互相关注的用户数量等。
2.4 点赞评论数据爬取
获取某音视频点赞用户列表、评论内容及评论者信息可以通过以下方法。
对于点赞用户列表,同样可以通过分析某音网页或 APP 的请求来获取。在网页端,点赞用户列表可能在一个类似https://www.douyin.com/aweme/v1/aweme/digg/list/?aweme_id=视频ID的接口中返回,通过发送请求并解析 JSON 数据,可以获取点赞用户的信息:
import requests
import jsonaweme_id = '6900000000000000000'
url = f'https://www.douyin.com/aweme/v1/aweme/digg/list/?aweme_id={aweme_id}'
response = requests.get(url)
if response.status_code == 200:data = response.json()for digg_user in data['digg_list']:digg_user_nickname = digg_user['nickname']digg_user_uid = digg_user['uid']print(f"点赞用户昵称: {digg_user_nickname}, 点赞用户ID: {digg_user_uid}")
获取评论内容及评论者信息时,在网页端,评论数据可能在https://www.douyin.com/aweme/v1/comment/list/?aweme_id=视频ID接口中返回。并且由于评论可能较多,需要处理分页问题,通过修改请求参数中的cursor(游标,用于标识下一页的起始位置)和count(每页评论数量)来获取下一页的评论数据:
import requests
import jsonaweme_id = '6900000000000000000'
cursor = 0
count = 20while True:url = f'https://www.douyin.com/aweme/v1/comment/list/?aweme_id={aweme_id}&cursor={cursor}&count={count}'response = requests.get(url)if response.status_code == 200:data = response.json()for comment in data['comments']:comment_text = comment['text']comment_user_nickname = comment['user']['nickname']print(f"评论内容: {comment_text}, 评论者昵称: {comment_user_nickname}")has_more = data['has_more']if not has_more:breakcursor = data['cursor']else:break
在 APP 端,同样可以使用抓包工具捕获评论相关的请求,按照类似的方法提取评论数据。
三、应对反爬虫机制
3.1 某博反爬虫策略及应对
某博作为一个拥有庞大用户群体和海量数据的社交媒体平台,为了保护自身数据安全和服务器稳定,采取了一系列严格的反爬虫机制。
IP 限制是某博常用的反爬虫手段之一。当某博服务器检测到某个 IP 在短时间内发送大量请求时,会认为该 IP 可能是爬虫程序,进而对其进行限制,比如限制该 IP 的访问频率,或者直接封禁该 IP 一段时间。例如,若一个 IP 在 1 分钟内对某博接口发起超过 100 次请求,就可能会被限制访问。
验证码机制也是某博反爬虫的重要组成部分。当某博怀疑某个请求可能来自爬虫时,会弹出验证码要求用户输入。验证码的形式多种多样,有数字字母混合的图片验证码,也有滑动拼图验证码等。比如在获取大量某博评论时,频繁请求可能就会触发验证码。
User - Agent 检测同样不可忽视。某博服务器会检查请求头中的 User - Agent 字段,判断请求是否来自真实的浏览器。如果 User - Agent 字段不符合常见浏览器的特征,或者多个请求的 User - Agent 字段完全相同,就可能被判定为爬虫请求。
针对某博的这些反爬虫机制,我们可以采取相应的应对策略。使用代理 IP 是突破 IP 限制的有效方法。通过搭建代理 IP 池,每次请求时随机从代理 IP 池中获取一个 IP,这样可以避免因单个 IP 请求过于频繁而被限制。例如,可以使用知名的代理 IP 服务提供商,如阿布云、讯代理等,获取高质量的代理 IP。
设置合理请求头也至关重要。在请求头中,除了设置随机的 User - Agent,还可以添加其他常见的字段,如 Accept、Accept - Encoding、Accept - Language 等,使其更接近真实浏览器的请求。比如:
headers = {'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept - Encoding': 'gzip, deflate, br','Accept - Language': 'zh - CN,zh;q=0.9'
}
模拟用户行为同样能有效应对反爬虫。在请求之间设置合理的时间间隔,模拟真实用户浏览网页的速度。比如,在获取某博内容时,每次请求后随机等待 3 - 5 秒再发送下一次请求,避免短时间内的大量集中请求。
3.2 某音反爬虫策略及应对
某音作为短视频领域的巨头,其反爬虫机制也相当复杂和严格。
设备指纹识别是某音独特的反爬虫手段之一。某音会收集设备的各种信息,如设备型号、操作系统版本、屏幕分辨率、浏览器信息等,生成一个唯一的设备指纹。如果发现多个请求来自具有相同设备指纹但行为异常(如请求频率过高)的设备,就可能判定为爬虫行为。
频繁请求限制也是某音常用的反爬虫策略。某音会对每个设备或 IP 的请求频率进行监控,当请求频率超过一定阈值时,就会限制该设备或 IP 的访问。例如,若一个设备在 10 分钟内请求某音视频接口超过 500 次,就可能被限制访问。
为了应对某音的反爬虫机制,使用无头浏览器是一种可行的方法。无头浏览器可以在没有图形界面的情况下运行浏览器,模拟真实用户的操作。比如使用 Puppeteer(Node.js 库)或 Selenium 配合 Chrome 无头浏览器,通过编写脚本模拟用户登录、浏览视频页面等操作,获取所需数据。以 Puppeteer 为例:
const puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch({headless: true});const page = await browser.newPage();await page.goto('https://www.douyin.com');// 在这里进行数据提取等操作await browser.close();
})();
随机化请求参数也能降低被检测到的风险。在发送请求时,对请求参数进行随机化处理,如添加随机的时间戳、随机的请求 ID 等。例如,在请求某音视频接口时,将时间戳参数timestamp设置为当前时间加上一个随机的毫秒数:
import random
import timetimestamp = int(time.time() * 1000) + random.randint(100, 999)
params = {'aweme_id': '视频ID','timestamp': timestamp
}
控制请求频率同样重要。根据某音的请求频率限制,合理设置请求间隔,避免频繁请求。可以使用 Python 的time.sleep()函数,在每次请求后等待一定时间,如每次请求后等待 5 - 10 秒再发送下一次请求。
四、数据隐私问题处理
4.1 法律法规遵守
在社交媒体数据爬取过程中,严格遵守相关法律法规是首要原则。以我国为例,《中华人民共和国个人信息保护法》明确规定了个人信息的收集、使用、存储等各个环节的规范 。该法律强调,收集个人信息应当遵循合法、正当、必要和诚信原则,不得通过误导、欺诈、胁迫等方式获取个人信息。
在爬取某博和某音数据时,我们只能获取公开的数据,对于用户设置为隐私的数据,绝对不能通过不正当手段获取。例如,在爬取某博用户信息时,对于用户未公开的私信内容、地理位置等敏感信息,不能进行爬取。在某音数据爬取中,对于用户未公开的收藏列表、历史浏览记录等也应予以尊重,不进行非法获取。
同时,要遵守平台自身的使用条款和服务协议。某博和某音都在其平台规则中明确了数据的使用范围和方式,我们在爬取数据时必须严格按照这些规则进行操作。如果违反平台规则,可能会面临法律风险,同时也会损害自身的声誉和利益。
4.2 数据脱敏处理
对爬取到的数据进行脱敏处理是保护用户隐私的重要手段。在某博数据中,对于用户的真实姓名、身份证号(若有涉及)、手机号码等敏感信息,可以采用替换的方法进行脱敏。比如将真实姓名替换为 “[用户姓名]”,将手机号码替换为 “[手机号码]”。
对于某音数据,若爬取到用户的身份证号,可以采用部分隐藏的方式,将中间几位数字用星号代替,如 “110101********1234”。对于用户的家庭住址等敏感信息,如果在数据中存在,可进行模糊化处理,只保留城市名称,如将 “北京市海淀区中关村大街 1 号” 脱敏为 “北京市” 。
在实际操作中,可以使用 Python 的正则表达式库re来实现数据脱敏。以替换手机号码为例:
import rephone_number = "13800138000"
masked_phone = re.sub(r'\d{4}\d{4}\d{4}', '**** **** ****', phone_number)
print(masked_phone)
对于一些包含敏感信息的文本内容,如某博评论、某音视频描述等,可以使用自然语言处理技术,先识别出其中的敏感信息,再进行相应的脱敏处理。例如,使用预训练的命名实体识别模型(如基于 BERT 的命名实体识别模型),识别出文本中的人名、地名、组织机构名等敏感信息,然后进行脱敏。
五、总结与展望
社交媒体数据爬取是一个充满挑战与机遇的领域。通过对某博和某音等社交媒体平台的数据爬取,我们能够获取到丰富的用户信息、内容数据以及社交关系数据,这些数据为市场分析、舆情监测、用户行为研究等提供了重要的支持。在爬取过程中,掌握某博和某音的数据爬取方法,包括获取用户信息、内容、评论以及粉丝关系等,是实现数据收集的基础。
同时,我们必须重视并有效应对社交媒体平台严格的反爬虫机制。通过使用代理 IP、设置合理请求头、模拟用户行为、使用无头浏览器、随机化请求参数以及控制请求频率等策略,能够在一定程度上突破反爬虫限制,确保数据爬取的顺利进行。
在数据隐私问题上,遵守法律法规是不可逾越的底线,对爬取到的数据进行脱敏处理是保护用户隐私的必要手段。只有在合法合规且尊重用户隐私的前提下进行数据爬取和使用,才能实现数据的价值最大化。
展望未来,随着社交媒体平台的不断发展和技术的进步,社交媒体数据爬取将面临更多的挑战。一方面,平台的反爬虫机制会不断升级,可能会采用更先进的技术手段来检测和阻止爬虫行为,这就要求我们不断探索新的反反爬虫技术和策略。另一方面,数据隐私和安全问题将受到越来越严格的监管,我们需要更加深入地研究如何在满足数据需求的同时,更好地保护用户隐私和数据安全。
随着人工智能和大数据技术的不断融合,社交媒体数据爬取与分析也将迎来新的发展机遇。例如,利用深度学习技术实现更精准的验证码识别、更智能的反爬虫规避策略,以及对海量社交媒体数据进行更深入的挖掘和分析,为各领域的决策提供更有价值的参考。
相关文章:
】解锁社交媒体数据宝藏:Python爬虫实战攻略)
【Python爬虫(60)】解锁社交媒体数据宝藏:Python爬虫实战攻略
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...

C++ 继承,多态
看前须知: 本篇博客是作者听课时的笔记,不喜勿喷,若有疑问可以评论区一起讨论。 继承 定义: 继承机制是⾯向对象程序设计使代码可以复⽤的最重要的⼿段,它允许我们在保持原有 类特性的基础上进⾏扩展,增…...

Java中的Stream API:从入门到实战
引言 在现代Java开发中,Stream API 是处理集合数据的强大工具。它不仅让代码更加简洁易读,还能通过并行处理提升性能。本文将带你从基础概念入手,逐步深入Stream API的使用,并通过实战案例展示其强大功能。 1. 什么是Stream API…...

QPainter绘制3D 饼状图
先展示图片 核心代码如下: pie.h #ifndef Q3DPIE_H #define Q3DPIE_H#include <QtGui/QPen> #include <QtGui/QBrush>class Pie { public:double value; QBrush brush; QString description; double percentValue;QString p…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Live View Kit (1)
1.问题描述: 客户端创建实况窗后,通过Push kit更新实况窗内容,这个过程是自动更新的还是客户端解析push消息数据后填充数据更新?客户端除了接入Push kit和创建实况窗还需要做什么工作? 解决方案: 通过Pu…...

数据治理与管理
引入 上一篇我们聊了数仓架构设计,它是企业构建数据中台的基石。其本质就是构建一个可靠易用的架构,可以借此将原始数据汇聚、处理,最终转换成可消费使用的数据资源。 在拥有数据资源以后,我们就需要考虑如何利用它,为企业创造价值,让它变成企业的资产而不是负担。也就…...

什么是HTTP/2协议?NGINX如何支持HTTP/2并提升网站性能?
HTTP/2是一种用于在Web浏览器和服务器之间进行通信的协议,旨在提高网站性能和加载速度。它是HTTP/1.1的继任者,引入了许多优化和改进,以适应现代Web应用的需求。HTTP/2的主要目标是减少延迟、提高效率,以及更好地支持并发请求。 …...

安全运维,等保测试常见解决问题。
1. 未配置口令复杂度策略。 # 配置密码安全策略 # vi /etc/pam.d/system-auth # local_users_only 只允许本机用户。 # retry 3 最多重复尝试3次。 # minlen12 最小长度为12个字符。 # dcredit-1 至少需要1个数字字符。 # ucredit-1 至少需要1个大…...
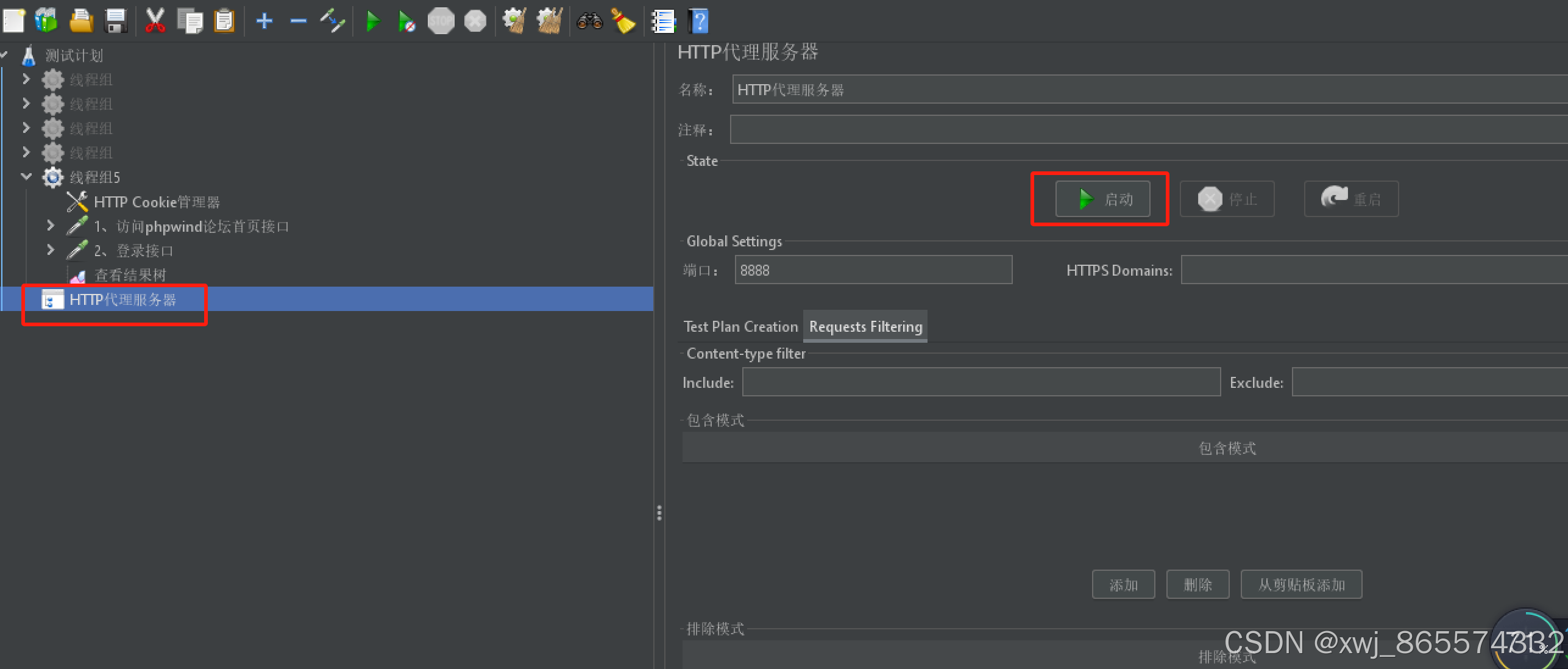
jmeter接口测试(二)
一、不同参数类型的接口测试 二、动态参数接口处理 随机数 工具——>函数助手对话框(Random 1000-10000之间的随机数 变量名为rdn)如下图所示 把上图生成的函数字符串复制到想要使用的地方如下图 三、断言 1、状态断言,200 不能证明…...

Keil ARM Complier Missing Compiler Version 5
使用Keil软件时出现了编译时报错,找不到对应的ARM版本,报错Target Target 1 uses ARM-Compiler Default Compiler Version 5 which is not available. *** Please review the installed ARM Compiler Versions: Manage Project Items - Folders/Extensions to manage ARM Compi…...

【僵尸进程】
【僵尸进程】 目录:知识点1. 僵尸进程的定义2. 僵尸进程产生的原因3. 僵尸进程的危害4. 如何避免僵尸进程 代码示例产生僵尸进程的代码示例避免僵尸进程的代码示例(父进程主动回收)避免僵尸进程的代码示例(信号处理) 运…...

【框架】参考 Spring Security 安全框架设计出,轻量化高可扩展的身份认证与授权架构
关键字:AOP、JWT、自定义注解、责任链模式 一、Spring Security Spring Security 想必大家并不陌生,是 Spring 家族里的一个安全框架,特别完善,但学习成本比较大,不少开发者都觉得,这个框架“很重” 他的…...

【Git 学习笔记_27】DIY 实战篇:利用 DeepSeek 实现 GitHub 的 GPG 密钥创建与配置
文章目录 1 前言2 准备工作3 具体配置过程3.1. 本地生成 GPG 密钥3.2. 导出 GPG 密钥3.3. 将密钥配置到 Git 中3.4. 测试提交 4 问题排查记录5 小结与复盘 1 前言 昨天在更新我的第二个 Vim 专栏《Mastering Vim (2nd Ed.)》时遇到一个经典的 Git 操作问题:如何在 …...

微信小程序地图map全方位解析
微信小程序地图map全方位解析 微信小程序的 <map> 组件是一个功能强大的工具,可以实现地图展示、定位、标注、路径规划等多种功能。以下是全方位解析微信小程序地图组件的知识点: 一、地图组件基础 1. 引入 <map> 组件 在页面的 .wxml 文…...

调试无痛入手
在调试过程中,Step In、Step Over 和 Step Out 是控制代码执行流程的常用操作,帮助开发者逐行或逐块检查代码行为。以下是它们的详细介绍及使用方法: 1. Step In 功能:进入当前行的函数或方法内部,逐行执行其代码。使…...

【蓝桥杯集训·每日一题2025】 AcWing 6135. 奶牛体检 python
6135. 奶牛体检 Week 1 2月21日 农夫约翰的 N N N 头奶牛站成一行,奶牛 1 1 1 在队伍的最前面,奶牛 N N N 在队伍的最后面。 农夫约翰的奶牛也有许多不同的品种。 他用从 1 1 1 到 N N N 的整数来表示每一品种。 队伍从前到后第 i i i 头奶牛的…...

AI发展迅速,是否还有学习前端的必要性?
今天有个小伙伴跟我讨论:“现在 AI 发展迅速,是否还有学习 JS 或者 TS 及前端知识的必要?” 我非常肯定地说: 是的,学习 JavaScript/TypeScript 以及前端知识仍然非常必要,而且在可预见的未来,…...

【数据标准】数据标准化是数据治理的基础
导读:数据标准化是数据治理的基石,它通过统一数据格式、编码、命名与语义等,全方位提升数据质量,确保准确性、完整性与一致性,从源头上杜绝错误与冲突。这不仅打破部门及系统间的数据壁垒,极大促进数据共享…...

VS2022配置FFMPEG库基础教程
1 简介 1.1 起源与发展历程 FFmpeg诞生于2000年,由法国工程师Fabrice Bellard主导开发,其名称源自"Fast Forward MPEG",初期定位为多媒体编解码工具。2004年后由Michael Niedermayer接任维护,逐步发展成为包含音视频采…...
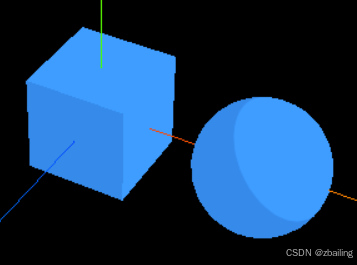
three.js之特殊材质效果
*案例42 创建一个透明的立方体 <template><div ref"container" className"container"></div> </template><script setup> import * as THREE from three; import WebGL from three/examples/jsm/capabilities/WebGL.js // 引…...

遥感数据处理避坑指南:MOD13A1 NDVI计算植被覆盖度,我踩过的这些坑你别再踩
遥感数据处理实战:MOD13A1 NDVI高效计算植被覆盖度的7个关键技巧 第一次处理MOD13A1数据时,我盯着屏幕上那些不完整的镶嵌结果和莫名其妙的负值,差点把键盘摔了。后来才发现,这些看似玄学的问题,其实都有明确的技术根源…...
)
《JAVA面经实录》- 设计模式面试题(一)
《JAVA面经实录》- 设计模式面试题(一)这份是设计模式面试题・标准答案背诵版语言精炼、口语化、不啰嗦,面试官最爱听,直接背就能过。一、基础必问题(标准答案)1.设计模式三大类?创建型:控制对象创建&#…...

小米社区自动化任务终极指南:如何用Python脚本解放你的双手
小米社区自动化任务终极指南:如何用Python脚本解放你的双手 【免费下载链接】miui-auto-tasks 一个自动化完成小米社区任务的脚本 项目地址: https://gitcode.com/gh_mirrors/mi/miui-auto-tasks 还在为每天重复的小米社区签到任务而烦恼吗?你是否…...

DDrawCompat:三步搞定经典DirectX游戏兼容性问题的终极方案
DDrawCompat:三步搞定经典DirectX游戏兼容性问题的终极方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/D…...

告别小程序富文本难题:mp-html组件实战指南
告别小程序富文本难题:mp-html组件实战指南 【免费下载链接】mp-html 小程序富文本组件,支持渲染和编辑 html,支持在微信、QQ、百度、支付宝、头条和 uni-app 平台使用 项目地址: https://gitcode.com/gh_mirrors/mp/mp-html 在小程序…...

Qt5/6项目实战:告别中文乱码,从编辑器设置到源码编码的完整避坑指南
Qt5/6中文编码实战:从源码到编译器的全链路避坑手册 第一次在Qt项目中看到满屏的"锟斤拷"时,我盯着屏幕愣了三分钟。这不是简单的技术问题,而是跨平台开发中字符编码的"百慕大三角"——编译器、IDE、操作系统和Qt版本在这…...

如何彻底清理macOS应用残留?Pearcleaner给你答案
如何彻底清理macOS应用残留?Pearcleaner给你答案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经遇到过这样的困扰:删除了…...

Framework Laptop 13 Pro 发布:升级主板与部件,更重视 Linux 支持
Framework Laptop 13 Pro:升级主板与部件Framework 此次更新最大亮点是配备英特尔酷睿 Ultra 3 系列处理器的升级版主板,它既可以安装到现有的 Framework Laptop 13 中,也能作为新的 Framework Laptop 13 Pro 的一部分购买。同时,…...

3个简单技巧快速掌握League-Toolkit:终极英雄联盟游戏体验提升方案
3个简单技巧快速掌握League-Toolkit:终极英雄联盟游戏体验提升方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟…...

GEO优化服务评测
当用户不再打开搜索引擎,而是直接询问豆包、文心一言、Kimi时,一场关于品牌“AI可见性”的战争已经悄然打响。你的官网内容再精美,产品介绍再详尽,如果无法被主流AI模型精准识别和引用,就等于在全新的流量分配体系中被…...