smolagents学习笔记系列(八)Examples - Master you knowledge base with agentic RAG
这篇文章锁定官网教程中 Examples 章节中的 Master you knowledge base with agentic RAG 文章,主要介绍了如何将 agent 和 RAG 结合使用。
- 官网链接:https://huggingface.co/docs/smolagents/v1.9.2/en/examples/rag;
Agentic RAG
在之前的几篇文章中介绍了如何使用Agent对你的问题进行代理、访问网页内容后回答问题、从SQL数据库中检索内容等功能,到这一步看似已经功能齐全了,因为常规需求也就这几种:
- 直接对LLM进行询问并根据回答展开多轮询问;
- 需要LLM在拥有某些知识背景下回答问题;
第一点我们已经很熟悉了,你平时使用的GPT也是通过模型本身具有的知识库进行问答,对于第二点而言无非就下面两种手段:
- 针对你提供的知识库对模型进行微调;
- 在你提问时将知识库中的信息传递给模型;
方案一当然是最理想的手段,因为可以得到一个指定领域的专家模型,但成本与代价也是极高的,这里的成本与代价不仅仅是数据采集与标注,更多的是你需要不断试探出模型的跷跷板,大多数模型在过多训练一个领域的知识后会丢失一些其他领域的技能。这种方案对普通人或小公司而言不划算;
方案二就需要你提供外部信息了,好像只要不停提供外部信息源即可,例如给一组网页或文本链接然后让Agent一口气向LLM进行询问。这样处理简单直接,但实际上对LLM并不友好,因为如果一次提供过多的信息内容可能会导致以下问题:
- 需要参数量更大的模型来理解的输入;
- 知识库中参杂无用信息会导致LLM回答跑偏;
- 过长的信息会让LLM忘记最早的一些内容;
这个其实也符合我们的生活常识,即如果一个人一口气说了很多话或者看了一整本书,你会很难提炼里面的中心思想,对于大语言模型而言也是同样的道理,加上你提供的知识库信息本身就可能非常庞大,如果不对这些信息进行筛选或者精炼的话LLM的回答效果也会变得不理想。
此时 Retrieval-Augmented-Generation (RAG) 就诞生了,它的作用就是先对你提供的知识库进行一次筛洗,将你知识库中最重要的内容提炼出来再喂给LLM,这个筛选可以通过词向量的方式也可以通过另一个LLM完成,感兴趣的话可以看下面两篇博客:
- 一文读懂:LLM大模型RAG;
- LangChain教程 | Retrival之Retrievers详解 | 检索器教程;
此时我们的核心目的变成了 通过RAG将外部知识库中精炼的内容传递给LLM。
官网的示例需要安装以下依赖,实现的功能是通过阅读 huggingface 的一个文档后在此基础上回答你的问题:
$ pip install smolagents pandas langchain langchain-community sentence-transformers datasets python-dotenv rank_bm25 --upgrade -q
总体步骤分为以下几步:
- 使用
LangChain库中的相关工具对知识库进行筛洗; - 定义
Tool与Agent; - 执行问答;
此处不过多介绍 LangChain 这个库,这个库是学习语言模型必须掌握的内容,感兴趣的可以自己下去查阅,如果完全没接触过也不用担心,你可以认为涉及这部分的代码就是帮你完成了一次知识筛洗;完整代码如下:
import datasets
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.retrievers import BM25Retriever
from smolagents import Tool
from smolagents import HfApiModel, CodeAgent# Step1. 使用 LangChain 对知识库进行筛洗
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")
knowledge_base = knowledge_base.filter(lambda row: row["source"].startswith("huggingface/transformers"))source_docs = [Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]})for doc in knowledge_base
]text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50,add_start_index=True,strip_whitespace=True,separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = text_splitter.split_documents(source_docs)# Step2. 定义 Tool 与 Agent
class RetrieverTool(Tool):name = "retriever"description = "Uses semantic search to retrieve the parts of transformers documentation that could be most relevant to answer your query."inputs = {"query": {"type": "string","description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",}}output_type = "string"def __init__(self, docs, **kwargs):super().__init__(**kwargs)self.retriever = BM25Retriever.from_documents(docs, k=10)def forward(self, query: str) -> str:assert isinstance(query, str), "Your search query must be a string"docs = self.retriever.invoke(query,)return "\nRetrieved documents:\n" + "".join([f"\n\n===== Document {str(i)} =====\n" + doc.page_contentfor i, doc in enumerate(docs)])retriever_tool = RetrieverTool(docs_processed)agent = CodeAgent(tools=[retriever_tool], model=HfApiModel(), max_steps=4, verbosity_level=2
)# Step3. Agent执行问答任务
agent_output = agent.run("For a transformers model training, which is slower, the forward or the backward pass?")print("Final output:")
print(agent_output)
运行结果如下:
$ python demo.py

【Tips】:对于参数量越小的模型而言,RAG的作用越大,超大规模语言模型如 GPT-4o 已经涵盖了很多领域的知识,对其进行微调提示的投入产出比远小于小型模型。。RAG也是普通人在不进行微调前提下得到一个最适合自己的Agent手段。
相关文章:
smolagents学习笔记系列(八)Examples - Master you knowledge base with agentic RAG
这篇文章锁定官网教程中 Examples 章节中的 Master you knowledge base with agentic RAG 文章,主要介绍了如何将 agent 和 RAG 结合使用。 官网链接:https://huggingface.co/docs/smolagents/v1.9.2/en/examples/rag; Agentic RAG 在之前的…...
满血版DeepSeek R1使用体验
硅基流动的满血版DeepSeek,通过CheeryStudio可以轻松访问,告别DeepSeek官网服务器繁忙,https://cloud.siliconflow.cn/i/ewlWR6A9 即可注册 https://cloud.siliconflow.cn/i/ewlWR6A9https://cloud.siliconflow.cn/i/ewlWR6A9 一、硅基流动平…...

Java类中的this操作
在Java中,`this` 是一个关键字,用于引用当前对象的实例。它通常在类的方法或构造器中使用,主要有以下几种用途: 1. 区分成员变量和局部变量 当成员变量与局部变量同名时,使用 `this` 可以明确引用当前对象的成员变量。 public class Person { private String name; …...

LeetCode刷题---双指针---532
数组中的 k-diff 数对 532. 数组中的 k-diff 数对 - 力扣(LeetCode) 题目 给你一个整数数组 nums 和一个整数 k,请你在数组中找出 不同的 k-diff 数对,并返回不同的 k-diff 数对 的数目。 k-diff 数对定义为一个整数对 (nums[…...
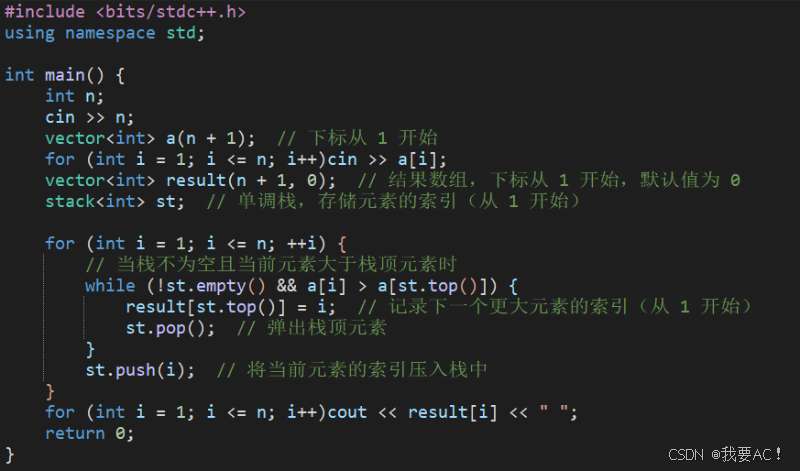
cpp单调栈模板
题目如下 如果利用暴力解法,时间复杂度是O(n^2) 只能过60%的数据 AC解法: 利用单调栈的算法,单调栈里存的是之前遍历过的元素的下标,如果满足while的条件就将栈顶元素记录,然后将其弹出&#x…...

PyCharm 的使用 + PyCharm快捷键 + 切换中文界面
2025 - 02 - 27 - 第 62 篇 Author: 郑龙浩 / 仟濹 【PyCharm的使用】 文章目录 如何使用Pycharm1 新建工程,新建 .py 文件,运行2 常用快捷键3 其他快捷键 - DeepSeek 总结如下**代码编辑****导航与定位****查找与替换****运行与调试****代码重构****其…...

SSL/TLS 协议、SSL证书 和 SSH协议 的区别和联系
下面是 SSL/TLS 协议、SSL证书 和 SSH协议 的区别和联系,包含它们的英文全称和中文全称: 属性SSL/TLS 协议SSL证书SSH 协议英文全称Secure Sockets Layer / Transport Layer SecuritySecure Sockets Layer CertificateSecure Shell Protocol中文全称安全…...

一个典型的要求: Python | C#实现年月日创建文件夹 时分秒对应文件名的保存路径
赶时间先说python: 用年月日作为文件夹: 年月日 时分秒 保存文件的路径根据年月日 创建文件夹 年里面包含月 月里面包含日 检查是否存在 没有就去创建 最后文件名用 时分秒毫秒.txt 这是一个典型的要求: import os from datetime import datetimenow datetime.now()# 获取当…...

知识库功能测试难点
图表交互功能测试难点 知识库图表类型多,每种图表交互功能不同。像柱状图,可能有点击柱子查看详细数据、鼠标悬停显示数据提示等交互;折线图除了这些,还可能支持缩放查看不同时间段数据。多种交互操作在不同图表间存在差异&#x…...

如何实现某短视频平台批量作品ID的作品详情采集
声明: 本文仅供学习交流使用,请勿用于非法用途。 在短视频平台的数据分析和内容监测中,批量采集作品详情是一个常见的需求。本文将介绍如何使用 Python 编写一个高效的爬虫程序,根据批量作品 ID 实现作品详情的批量采集。 1. 需求分析 输入:一批作品 ID。输出:每个作品 …...

uniapp中使用leaferui使用Canvas绘制复杂异形表格的实现方法
需求: 如下图,要实现左图的样式,先实现框架,文字到时候 往里填就行了,原来的解决方案是想用css,html来实现,发现实现起来蛮麻烦的。我也没找到合适的实现方法,最后换使用canvas来实现ÿ…...

判别分析:原理推导、方法对比与Matlab实战
内容摘要 本文深入解析判别分析的三大核心方法——距离判别、Fisher判别与Bayes判别,结合协方差估计、投影优化及贝叶斯决策理论,系统阐述数学原理与实现细节。通过气象数据春早预测、产品厂家分类及城市竞争力评估三大实战案例,完整演示数据…...

PMP项目管理—整合管理篇—4.管理项目知识
文章目录 基本信息知识的分类显性知识隐性知识 如何分享知识?4W1HITTO输入工具与技术输出 经验教训登记册 基本信息 知识管理指管理显性知识和隐性知识,旨在重复使用现有知识并生成新知识。有助于达成这两个目的的关键活动是知识分享和知识集成…...

Makefile编写和相关语法规则
makefile基本概念 Makefile 本质上是一个文本文件,它包含了一系列规则和指令,用于告诉构建工具(如 make)如何编译和链接程序,以及如何处理项目中的各种文件。其核心思想是通过定义目标(target)…...

点云 PCL 滤波在自动驾驶的用途。
1.直通滤波 2.体素滤波...

NL2SQL的应用-长上下文模型在处理NL2SQL任务时,相较于传统模型,有哪些显著的优势
大家好,我是微学AI,今天给大家介绍一下NL2SQL的应用-长上下文模型在处理NL2SQL任务时,相较于传统模型,有哪些显著的优势。NL2SQL(自然语言转SQL)技术旨在将用户自然语言提问自动转换为结构化查询语句&#…...

图像处理基础(8):图像的灰度直方图、直方图均衡化、直方图规定化(匹配)
本文主要介绍了灰度直方图相关的处理,包括以下几个方面的内容: • 利用OpenCV计算图像的灰度直方图,并绘制直方图曲线 • 直方图均衡化的原理及实现 • 直方图规定化(匹配)的原理及实现 图像的灰度直方图 一…...

探寻数组中两个不重复数字的奥秘:C 语言实战之旅
在编程的世界里,经常会遇到各种各样有趣的问题,今天我们就来探讨一个经典的题目:在一个整数数组中,除了两个数字只出现一次,其余数字都出现了两次,如何高效地找出这两个只出现一次的数字呢?我们…...

Mercury、LLaDA 扩散大语言模型
LLaDA 参考: https://github.com/ML-GSAI/LLaDA https://ml-gsai.github.io/LLaDA-demo/ 在线demo: https://huggingface.co/spaces/multimodalart/LLaDA Mercury 在线demo: https://chat.inceptionlabs.ai/ 速度很快生成...

【ESP32S3接入讯飞在线语音识别】
视频地址: 【ESP32S3接入讯飞在线语音识别】 1. 前言 使用Seeed XIAO ESP32S3 Sense开发板接入讯飞实现在线语音识别。自带麦克风模块用做语音输入,通过串口发送字符“1”来控制数据的采集和上传。 语音识别对比 平台api教程评分百度...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...