数据库测试
TPCH 22条SQL语句分析 - xibuhaohao - 博客园
TPCH模型规范、测试说明及22条语句 - zhjh256 - 博客园
TPC-DS 性能比较:TiDB 与 Impala-PingCAP | 平凯星辰
揭秘Oracle TPC-H性能优化:如何提升数据库查询速度,揭秘实战技巧与挑战
引言
TPC-H(Transaction Processing Performance Council H-Scale Performance Benchmark)是一个广泛使用的数据库性能基准测试,用于衡量数据库系统在高并发和大规模数据集上的查询性能。Oracle数据库作为企业级数据库的佼佼者,其性能优化一直是数据库管理员和开发者关注的焦点。本文将深入探讨Oracle TPC-H性能优化,揭示提升数据库查询速度的实战技巧与挑战。
一、TPC-H基准测试简介
TPC-H基准测试模拟了典型的在线事务处理(OLTP)场景,包括订单处理、库存管理和客户服务等多个方面。它通过一系列复杂的SQL查询来测试数据库的性能。在TPC-H基准测试中,查询的性能是衡量数据库系统效率的重要指标。
二、TPC-H性能优化技巧
1. 索引优化
索引是提升查询性能的关键。以下是一些索引优化的技巧:
- 创建索引:针对查询中频繁使用的列创建索引,例如:
CREATE INDEX idx_order_date ON orders (order_date);
- 监控索引使用情况:定期检查索引的使用情况,确保索引被有效利用。
SELECT * FROM v$index_usage;
2. 查询优化
查询优化是提升性能的直接方法。以下是一些查询优化的技巧:
- 使用执行计划:通过分析执行计划,找出查询性能瓶颈。
EXPLAIN PLAN FOR SELECT * FROM orders WHERE order_date = '2021-01-01'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
- 优化子查询:将子查询转换为连接查询,以提高性能。
SELECT d.department_name, COUNT(e.employee_id) AS employee_count FROM departments d JOIN employees e ON d.department_id = e.department_id GROUP BY d.department_name;
3. 物理设计优化
- 分区表:将大表分区可以提高查询性能。
CREATE TABLE orders ( order_id NUMBER, order_date DATE, ... ) PARTITION BY RANGE (order_date) ( PARTITION p1 VALUES LESS THAN ('2021-01-01'), PARTITION p2 VALUES LESS THAN ('2022-01-01'), ... );
- 触发器和存储过程:合理使用触发器和存储过程可以提高数据一致性和查询性能。
CREATE OR REPLACE TRIGGER trig_after_insert_order AFTER INSERT ON orders FOR EACH ROW BEGIN -- 触发器逻辑 END;
三、实战案例
以下是一个实际的TPC-H性能优化案例:
假设在TPC-H基准测试中,查询Q1(找出每个供应商的总订单数)的执行时间过长。通过分析执行计划,我们发现orders表的supplier_id列未创建索引。在创建索引后,查询性能得到了显著提升。
四、挑战与展望
TPC-H性能优化面临以下挑战:
-
数据量庞大:随着数据量的增长,性能优化变得越来越复杂。
-
多并发查询:在高并发环境下,优化查询性能是一项挑战。
未来,随着数据库技术的发展,我们将有更多高效的工具和方法来提升TPC-H性能。
结语
Oracle TPC-H性能优化是数据库管理员和开发者必须掌握的技能。通过合理的索引优化、查询优化和物理设计优化,可以有效提升数据库查询速度。在实际项目中,不断总结经验,持续优化,是提升数据库性能的关键。
TiDB TPC-H 性能对比测试报告 - v5.4 MPP 模式对比 Greenplum 6.15.0 以及 Apache Spark 3.1.1
测试概况
本次测试对比了 TiDB v5.4 MPP 模式下和主流分析引擎例如 Greenplum 和 Apache Spark 最新版本在 TPC-H 100 GB 数据下的性能表现。结果显示,TiDB v5.4 MPP 模式下相对这些方案有 2-3 倍的性能提升。
TiDB v5.0 中引入的 TiFlash 组件的 MPP 模式大大幅增强了 TiDB HTAP 形态。本文的测试对象如下:
- TiDB v5.4 MPP 执行模式下的列式存储
- Greenplum 6.15.0
- Apache Spark 3.1.1 + Parquet
测试环境
硬件配置
| 实例类型 | 实例数 |
|---|---|
| PD | 1 |
| TiDB | 1 |
| TiKV | 3 |
| TiFlash | 3 |
- CPU:Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz,40 核
- 内存:189 GB
- 磁盘:NVMe 3TB * 2
软件版本
| 服务类型 | 软件版本 |
|---|---|
| TiDB | 5.4 |
| Greenplum | 6.15.0 |
| Apache Spark | 3.1.1 |
配置参数
TiDB v5.4 配置
v5.4 的 TiDB 集群除以下配置项外均使用默认参数配置。所有 TPC-H 测试表均以 TiFlash 列存进行同步,无额外分区和索引。
在 TiFlash 的 users.toml 配置文件中进行如下配置:
[profiles.default] max_memory_usage = 10000000000000
使用 SQL 语句设置以下会话变量:
set @@tidb_isolation_read_engines='tiflash'; set @@tidb_allow_mpp=1; set @@tidb_mem_quota_query = 10 << 30;
Greenplum 配置
Greenplum 集群使用额外的一台 Master 节点部署(共四台),每台 Segment Server 部署 8 Segments(每个 NVMe SSD 各 4 个),总共 24 Segments。存储格式为 append-only / 列式存储,分区键为主键。
log_statement = all gp_autostats_mode = none statement_mem = 2048MB gp_vmem_protect_limit = 16384
Apache Spark 配置
Apache Spark 测试使用 Apache Parquet 作为存储格式,数据存储在 HDFS 上。HDFS 为三节点,为每个节点指定两块 NVMe SSD 盘作为数据盘。通过 Standalone 方式启动 Spark 集群,使用 NVMe SSD 盘作为 spark.local.dir 本地目录以借助快速盘加速 Shuffle Spill 过程,无额外分区和索引。
--driver-memory 20G --total-executor-cores 120 --executor-cores 5 --executor-memory 15G
测试结果
注意
以下测试结果均为 3 次测试的平均值,单位均为秒。
| Query ID | TiDB v5.4 | Greenplum 6.15.0 | Apache Spark 3.1.1 + Parquet |
|---|---|---|---|
| 1 | 8.08 | 64.1307 | 52.64 |
| 2 | 2.53 | 4.76612 | 11.83 |
| 3 | 4.84 | 15.62898 | 13.39 |
| 4 | 10.94 | 12.88318 | 8.54 |
| 5 | 12.27 | 23.35449 | 25.23 |
| 6 | 1.32 | 6.033 | 2.21 |
| 7 | 5.91 | 12.31266 | 25.45 |
| 8 | 6.71 | 11.82444 | 23.12 |
| 9 | 44.19 | 22.40144 | 35.2 |
| 10 | 7.13 | 12.51071 | 12.18 |
| 11 | 2.18 | 2.6221 | 10.99 |
| 12 | 2.88 | 7.97906 | 6.99 |
| 13 | 6.84 | 10.15873 | 12.26 |
| 14 | 1.69 | 4.79394 | 3.89 |
| 15 | 3.29 | 10.48785 | 9.82 |
| 16 | 5.04 | 4.64262 | 6.76 |
| 17 | 11.7 | 74.65243 | 44.65 |
| 18 | 12.87 | 64.87646 | 30.27 |
| 19 | 4.75 | 8.08625 | 4.7 |
| 20 | 8.89 | 15.47016 | 8.4 |
| 21 | 24.44 | 39.08594 | 34.83 |
| 22 | 1.23 | 7.67476 | 4.59 |

以上性能图中蓝色为 TiDB v5.4,红色为 Greenplum 6.15.0,黄色为 Apache Spark 3.1.1,纵坐标是查询的处理时间。纵坐标数值越低,表示 TPC-H 性能越好。
TiDB TPC-H 性能对比测试报告 - v4.0 对比 v3.0
测试目的
对比 TiDB v4.0 和 v3.0 OLAP 场景下的性能。
因为 TiDB v4.0 中新引入了 TiFlash 组件增强 TiDB HTAP 形态,本文的测试对象如下:
- v3.0 仅从 TiKV 读取数据。
- v4.0 仅从 TiKV 读取数据。
- v4.0 通过智能选择混合读取 TiKV、TiFlash 的数据。
测试环境 (AWS EC2)
硬件配置
| 服务类型 | EC2 类型 | 实例数 |
|---|---|---|
| PD | m5.xlarge | 3 |
| TiDB | c5.4xlarge | 2 |
| TiKV & TiFlash | i3.4xlarge | 3 |
| TPC-H | m5.xlarge | 1 |
软件版本
| 服务类型 | 软件版本 |
|---|---|
| PD | 3.0、4.0 |
| TiDB | 3.0、4.0 |
| TiKV | 3.0、4.0 |
| TiFlash | 4.0 |
| tiup-bench | 0.2 |
配置参数
v3.0
v3.0 的 TiDB 和 TiKV 均为默认参数配置。
变量配置
set global tidb_distsql_scan_concurrency = 30; set global tidb_projection_concurrency = 16; set global tidb_hashagg_partial_concurrency = 16; set global tidb_hashagg_final_concurrency = 16; set global tidb_hash_join_concurrency = 16; set global tidb_index_lookup_concurrency = 16; set global tidb_index_lookup_join_concurrency = 16;
v4.0
v4.0 的 TiDB 为默认参数配置。
TiKV 配置
readpool.storage.use-unified-pool: false readpool.coprocessor.use-unified-pool: true
PD 配置
replication.enable-placement-rules: true
TiFlash 配置
logger.level: "info" learner_config.log-level: "info"
变量配置
注意
部分参数为 SESSION 变量。建议所有查询都在当前 SESSION 中执行。
set global tidb_allow_batch_cop = 1; set session tidb_opt_distinct_agg_push_down = 1; set global tidb_distsql_scan_concurrency = 30; set global tidb_projection_concurrency = 16; set global tidb_hashagg_partial_concurrency = 16; set global tidb_hashagg_final_concurrency = 16; set global tidb_hash_join_concurrency = 16; set global tidb_index_lookup_concurrency = 16; set global tidb_index_lookup_join_concurrency = 16;
测试方案
硬件准备
为了避免 TiKV 和 TiFlash 争抢磁盘和 I/O 资源,把 EC2 配置的两个 NVMe SSD 盘分别挂载为 /data1 及 /data2,把 TiKV 的部署至 /data1,TiFlash 部署至 /data2。
测试过程
-
通过 TiUP 部署 TiDB v4.0 和 v3.0。
-
通过 TiUP 的 bench 工具导入 TPC-H 10G 数据。
-
执行以下命令将数据导入 v3.0:
tiup bench tpch prepare \ --host ${tidb_v3_host} --port ${tidb_v3_port} --db tpch_10 \ --sf 10 \ --analyze --tidb_build_stats_concurrency 8 --tidb_distsql_scan_concurrency 30 -
执行以下命令将数据导入 v4.0:
tiup bench tpch prepare \ --host ${tidb_v4_host} --port ${tidb_v4_port} --db tpch_10 --password ${password} \ --sf 10 \ --tiflash \ --analyze --tidb_build_stats_concurrency 8 --tidb_distsql_scan_concurrency 30
-
-
运行 TPC-H 的查询。
-
下载 TPC-H 的 SQL 查询文件:
git clone https://github.com/pingcap/tidb-bench.git && cd tpch/queries -
查询并记录耗时。
- 对于 TiDB v3.0,使用 MySQL 客户端连接到 TiDB,然后执行查询,记录 v3.0 查询耗时。
- 对于 TiDB v4.0,使用 MySQL 客户端连接到 TiDB,再根据测试的形态,选择其中一种操作:
- 设置
set @@session.tidb_isolation_read_engines = 'tikv,tidb';后,再执行查询,记录 v4.0 仅从 TiKV 读取数据的查询耗时。 - 设置
set @@session.tidb_isolation_read_engines = 'tikv,tiflash,tidb';后,再执行查询,记录 v4.0 通过智能选择从 TiKV 和 TiFlash 混合读取数据的查询耗时。
- 设置
-
-
提取整理耗时数据。
测试结果
注意
本测试所执行 SQL 语句对应的表只有主键,没有建立二级索引。因此以下测试结果为无索引结果。
| Query ID | v3.0 | v4.0 TiKV Only | v4.0 TiKV / TiFlash Automatically |
|---|---|---|---|
| 1 | 7.78s | 7.45s | 2.09s |
| 2 | 3.15s | 1.71s | 1.71s |
| 3 | 6.61s | 4.10s | 4.05s |
| 4 | 2.98s | 2.56s | 1.87s |
| 5 | 20.35s | 5.71s | 8.53s |
| 6 | 4.75s | 2.44s | 0.39s |
| 7 | 7.97s | 3.72s | 3.59s |
| 8 | 5.89s | 3.22s | 8.59s |
| 9 | 34.08s | 11.87s | 15.41s |
| 10 | 4.83s | 2.75s | 3.35s |
| 11 | 3.98s | 1.60s | 1.59s |
| 12 | 5.63s | 3.40s | 1.03s |
| 13 | 5.41s | 4.56s | 4.02s |
| 14 | 5.19s | 3.10s | 0.78s |
| 15 | 10.25s | 1.82s | 1.26s |
| 16 | 2.46s | 1.51s | 1.58s |
| 17 | 23.76s | 12.38s | 8.52s |
| 18 | 17.14s | 16.38s | 16.06s |
| 19 | 5.70s | 4.59s | 3.20s |
| 20 | 4.98s | 1.89s | 1.29s |
| 21 | 11.12s | 6.23s | 6.26s |
| 22 | 4.49s | 3.05s | 2.31s |

以上性能图中蓝色为 v3.0,红色为 v4.0(仅从 TiKV 读),黄色为 v4.0(从 TiKV、TiFlash 智能选取),纵坐标是查询的处理时间。纵坐标越低,表示性能越好。
- v4.0(仅从 TiKV 读取数据),即 TiDB 仅会从 TiKV 中读取数据。将该结果与 v3.0 的结果对比可得知,TiDB、TiKV 升级至 4.0 版本后,TPC-H 性能得到的提升幅度。
- v4.0(从 TiKV、TiFlash 智能选取),即 TiDB 优化器会自动根据代价估算选择是否使用 TiFlash 副本。将该结果与 v3.0 的结果对比可得知,在 v4.0 完整的 HTAP 形态下,TPC-H 性能得到的提升幅度。
【数据库】TiDB 5.3 TPCH 100G测试及思考
一、环境
tpc-H 100G数据 2.8版本
22个场景sql:
<https://github.com/pingcap/tidb-bench/tree/master/tpch/queries>
官方:
节点数量:3
CPU:Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz,40 核
内存:189 GB
磁盘:NVMe 3TB * 2
华为云:
kc1.4xlarge.4
节点数量:6
CPU:16vCPUs(kunpeng 920)
内存:64 GB
磁盘:极速SSD(fio bs=1M job=10 w=8783MiB/s,8782 IOPS)
布局:tikv和tiflash同一主机*3,tidb和pd在同一主机*3,绑2node
普通SSD:
TaiShan
节点数量:6
CPU:128 CPU(kunpeng 920)
内存:512 GB
磁盘:普通SSD(fio bs=16k w=250MB/s)
布局:
1、每台主机4块数据SSD,共同加到一个tiflash中
2、24*TiDB,3*PD,24Tikv,6Tiflash,每个server端单独绑一个node(一个node 32CPU)
二、参数设置
tiup cluster edit-config t1
tiflash:
profiles.default.max_memory_usage = 10000000000000
set global tidb_allow_mpp=1;
set @@tidb_isolation_read_engines='tiflash';
set @@tidb_mem_quota_query = 10 << 30;
因为tidb_isolation_read_engines只能session级别,通过mysql客户端登陆调用本地脚本方式执行
mysql -h127.0.0.1 -uroot -P4000 -D tpch <<!
\\. 1.sql
!
执行多次,直到sql执行时间趋于稳定
三、测试结果
官方数据 华为云3副本Tiflash 华为云3副本tikv+tiflash 普通SSD 6副本tikv+tiflash
Q1 8.08 6.6 1.68
Q2 2.53 2.48 3.09
Q3 4.84 4.649 15.76
Q4 10.94 5.589 19.1 8.27
Q5 12.27 11.02 6.97
Q6 1.32 1 0.55
Q7 5.91 4.0666 7.59
Q8 6.71 7.1 14.91
Q9 44.19 30.334 12.87
Q10 7.13 4.4 41.04
Q11 2.18 1.771 3.03
Q12 2.88 2.885 2.47
Q13 6.84 4.9 72.62
Q14 1.69 1.5 1.51
Q15 3.29 2.5-2.7 2.5-2.9 13.75
Q16 5.04 1.1 2.07
Q17 11.7 7.9 24.89
Q18 12.87 11.1 14.17
Q19 4.75 3.05 1.38
Q20 8.89 2.4 24.62
Q21 24.44 12.4 15.47
Q22 1.23 1.167 1.4
四、结果说明及一些猜想
Q4:
select
o_orderpriority,count(*) as order_count
from
orders
where
o_orderdate >= '1995-01-01'
and o_orderdate < date_add('1995-01-01', interval '3' month)
and exists (
select * from lineitem
where
l_orderkey = o_orderkey
and l_commitdate < l_receiptdate
)
group by o_orderpriority
order by o_orderpriority;
tiflash:5.589s
tikv+tiflash+tidb(默认配置):19.1s
explain analyze执行计划,默认配置下表lineitem走了cache:
Selection_24(Probe) | 3.98 | 14185840 | cop[tikv] | |time:5m56.6s, **loops:16883**,
cop_task: {num: 3827, max: 697.5ms, min: 585.8µs, avg: 133ms, p95: 340ms, max_proc_keys: 17867, p95_proc_keys: 15901, tot_proc: 7m13.6s, tot_wait: 1m6.1s, rpc_num: 3827, rpc_time: 8m29s, copr_cache_hit_ratio: 0.24}, tikv_task:{proc max:530ms, min:0s, p80:180ms, p95:280ms, iters:39261, tasks:3827}, scan_detail: {total_process_keys: 21217578, total_process_keys_size: 4216268171, total_keys: 25622316, rocksdb: {delete_skipped_count: 0, key_skipped_count: 20513898,
block: {**cache_hit_count: 32099284, read_count: 1750183, read_byte: 29.1 GB**}}}
| lt(tpch.lineitem.l_commitdate, tpch.lineitem.l_receiptdate)
在强制tiflash下,优化器重组了sql,两张表直接做hashjoin
HashJoin_42 | 4471364.76 | batchCop[tiflash] || semi join, equal:[eq(tpch.orders.o_orderkey, tpch.lineitem.l_orderkey)]
一些猜想:
1、TiDB优化器中cache hit权重更高?
2、TiDB优化器之后是否会像Oracle加入硬件性能参数计算代价?(参考aux_stats$)
Q9:
tiflash和tikv+tiflash差距不大;表supplier在tikv中走的点查,非常快
耗时上,默认配置总时间更短
其他:
AP还是看存储,多盘在某些场景下貌似不能弥补性能上的差距
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/xyq172291/article/details/122281719
相关文章:
数据库测试
TPCH 22条SQL语句分析 - xibuhaohao - 博客园 TPCH模型规范、测试说明及22条语句 - zhjh256 - 博客园 TPC-DS 性能比较:TiDB 与 Impala-PingCAP | 平凯星辰 揭秘Oracle TPC-H性能优化:如何提升数据库查询速度,揭秘实战技巧与挑战 引言 T…...

Nodejs-逐行读取文件【简易版】
“勤奋就是成功之母。” —— 茅以升 目录 逐行读取文件四种方法:Node.js 逐行读取文件的核心方法:同步读取(适用于小文件):异步流式处理(推荐用于大文件):[使用 readline 模块](h…...

上海市计算机学会竞赛平台2024年5月月赛丙组城市距离之和
城市距离之和 内存限制: 256 Mb时间限制: 1000 ms 题目描述 设 (x,y)(x,y) 与 (x′,y′)(x′,y′) 是平面上的两个点的坐标,它们之间的城市距离定义为 ∣x−x′∣∣y−y′∣∣x−x′∣∣y−y′∣ 给定 nn 个点,请计算所有点对之间的城市距离之和。 …...

穷举vs暴搜vs深搜vs回溯vs剪枝(典型算法思想)—— OJ例题算法解析思路
回溯算法的模版 void backtrack(vector<int>& path, vector<int>& choice, ...) {// 满⾜结束条件if (/* 满⾜结束条件 */) {// 将路径添加到结果集中res.push_back(path);return;}// 遍历所有选择for (int i 0; i < choices.size(); i) {// 做出选择…...

在ubuntu 24.04.2 通过 Kubeadm 安装 Kubernetes v1.31.6
文章目录 1. 简介2. 准备3. 配置 containerd4. kubeadm 安装集群5. 安装网络 calico 插件 1. 简介 本指南介绍了如何在 Ubuntu 24.04.2 LTS 上安装和配置 Kubernetes 1.31.6 集群,包括容器运行时 containerd 的安装与配置,以及使用 kubeadm 进行集群初始…...

基于Python socket库构建的基于 P2P 的文件共享系统示例
基于 P2P 的文件共享系统 实现方式: 使用 Python 的socket库构建 P2P 网络,节点之间通过 TCP 或 UDP 协议进行通信。每个节点维护一个文件列表,并向其他节点广播自己拥有的文件信息。当一个节点需要某个文件时,它会向网络中的其…...

JavaScript 函数重载:灵活应对多场景的编程技巧
在 JavaScript 中,函数重载(Function Overloading)是一个常见的需求。尽管 JavaScript 本身并不支持传统意义上的函数重载(即在同一个作用域内定义多个同名函数,根据参数的不同调用不同的函数),…...

通过 PromptTemplate 生成干净的 SQL 查询语句并执行SQL查询语句
问题描述 在使用 LangChain 和 Llama 模型生成 SQL 查询时,遇到了 sqlite3.OperationalError 错误。错误信息如下: OperationalError: (sqlite3.OperationalError) near "sql SELECT Name FROM MediaType LIMIT 5; ": syntax error [SQL: …...

用大白话解释缓存Redis +MongoDB是什么有什么用怎么用
Redis和MongoDB是什么? Redis:像你家的“小冰箱”,专门存高频使用的食物(数据)。它是基于内存的键值数据库,读写速度极快(每秒超10万次操作)。比如你每次打开手机App,用…...

计算机毕业设计SpringBoot+Vue.js汽车销售网站(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【0010】HTML水平线标签详解
如果你觉得我的文章写的不错,请关注我哟,请点赞、评论,收藏此文章,谢谢! 本文内容体系结构如下: 一、水平线标签概述 在HTML中,<hr>标签用于在网页上插入一条水平线,其主要…...

FastExcel与Reactor响应式编程深度集成技术解析
一、技术融合背景与核心价值 在2025年企业级应用开发中,大规模异步Excel处理与响应式系统架构的结合已成为技术刚需。FastExcel与Reactor的整合方案,通过以下技术协同实现突破性性能: 内存效率革命:FastExcel的流式字节操作与Re…...

Netty是如何实现零拷贝的?
大家好,我是锋哥。今天分享关于【Netty是如何实现零拷贝的?】面试题。希望对大家有帮助; Netty是如何实现零拷贝的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Netty是一个高性能的Java网络应用框架,它…...

【大模型➕知识图谱】大模型结合医疗知识图谱:解锁智能辅助诊疗系统新范式
【大模型➕知识图谱】大模型结合医疗知识图谱:解锁智能辅助诊疗系统新范式 大模型结合医疗知识图谱:解锁智能辅助诊疗系统新范式引言一、系统架构1.1 系统架构图1.2 架构模块说明1.2.1 用户输入1.2.2 大模型(语义理解与意图识别)1.2.3 Agent(问题解析与任务分配)1.2.4 问…...

Spring Boot @Component注解介绍
Component 是 Spring 中的一个核心注解,用于声明一个类为 Spring 管理的组件(Bean)。它是一个通用的注解,可以用于任何层次的类(如服务层、控制器层、持久层等)。通过 Component 注解,Spring 会…...
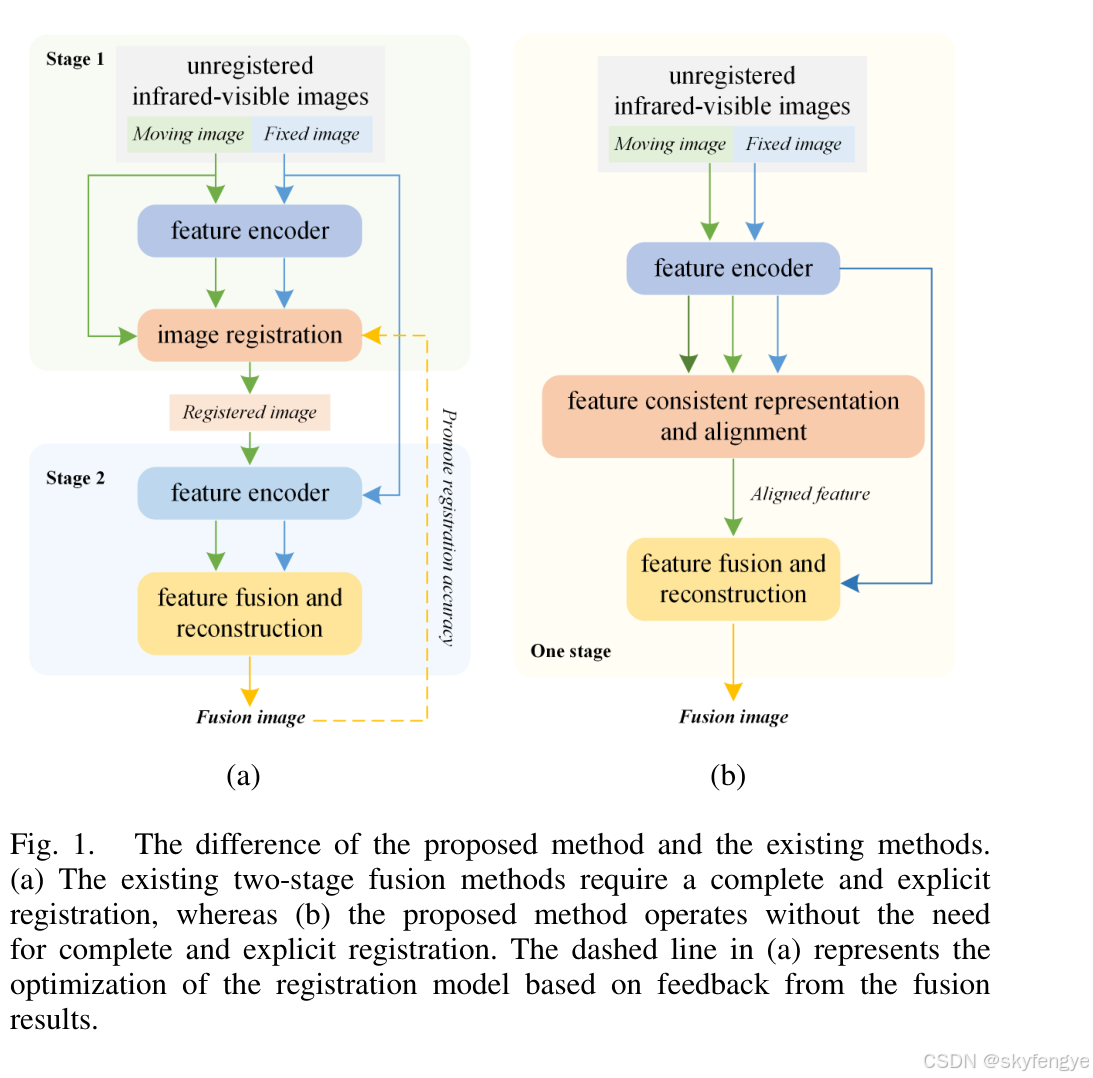
MulFS-CAP: Multimodal Fusion-supervisedCross-modal
一种用于无注册红外-可见图像融合的单阶段框架。与传统的两阶段方法不同,MulFS-CAP结合了隐式注册和融合,简化了处理流程并增强了实用性。该方法使用共享的浅层特征编码器,同时进行特征对齐和图像融合。通过引入可学习的模态字典,…...
WordPress多语言插件GTranslate
GTranslate是一个免费的WordPress多语言插件,它允许您将网站内容翻译成多种语言。这个插件提供了一个简单易用的界面,让您可以在WordPress后台直接进行翻译操作。以下是GTranslate插件的一些主要特点: 免费使用:GTranslate插件完…...

wordpress子分类调用父分类名称和链接的3种方法
专为导航而生,在wordpress模板制作过程中常常会在做breadcrumbs导航时会用到,子分类调用父分类的名称和链接,下面这段简洁的代码,可以完美解决这个问题。 <?php echo get_category_parents( $cat, true, » ); ?…...

Prometheus + Grafana 监控
Prometheus Grafana 监控 官网介绍:Prometheus 是一个开源系统 监控和警报工具包最初由 SoundCloud 构建。自 2012 年成立以来,许多 公司和组织已经采用了 Prometheus,并且该项目具有非常 活跃的开发人员和用户社区。它现在是一个独立的开源…...

初学STM32之简单认识IO口配置(学习笔记)
在使用51单片机的时候基本上不需要额外的配置IO,不过在使用特定的IO的时候需要额外的设计外围电路,比如PO口它是没有内置上拉电阻的。因此若想P0输出高电平,它就需要外接上拉电平。(当然这不是说它输入不需要上拉电阻,…...

Gemini 3.5破解50年数学猜想,数学家紧急复核
AI 攻克人类智慧高地?Gemini 3.5 传出“破解 50 年数学猜想”重大突破,数学家:正在紧急复核!2026年伊始,科技界与学术界共同迎来了一场堪称“地震级”的重磅新闻。据权威学术预印本网站及谷歌 DeepMind 团队透露&#…...

AI Agent Harness Engineering 生态系统:基础设施、工具与应用层
AI Agent Harness Engineering 生态系统全解:基础设施、工具链与生产级应用落地 一、引言 钩子 你有没有过这样的经历:花了3天时间调好了一个支持多工具调用的AI Agent Demo,演示的时候能自动查订单、退运费、生成工单,效果惊艳到老板当场拍板要上线。结果真到生产环境跑…...

Mac上高效调试HTTPS流量:Charles抓包配置与SSL解密实战
1. 为什么Mac用户绕不开Charles——它不是“又一个抓包工具”,而是调试链路的中枢神经在Mac上做前端联调、App接口验证、小程序网络行为分析,甚至排查第三方SDK异常请求时,我见过太多人卡在第一步:看不到真实发出去的请求。有人用…...

函数指针调用的两种语法及其在嵌入式C中的应用
1. 函数指针调用:两种语法背后的故事在嵌入式C开发中,函数指针是实现回调机制、插件架构和动态行为的关键技术。最近有工程师发现,通过函数指针调用函数时存在两种看似不同的语法形式:(*ptr)(); // 传统间接调用语法 ptr(); …...

AI 术语通俗词典:RAG
RAG 是大语言模型、自然语言处理、知识问答、智能客服、企业知识库和 AI 应用开发中非常重要的一个术语,全称是 Retrieval-Augmented Generation,通常翻译为“检索增强生成”。它用来描述一种让大语言模型先从外部资料中检索相关内容,再基于这…...

阴阳师智能自动化脚本:5个步骤实现游戏任务全托管
阴阳师智能自动化脚本:5个步骤实现游戏任务全托管 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师中重复的日常任务感到厌倦吗?每天花费数小…...

鸿蒙健身计划页面构建:动作清单与训练部位分布模块详解
鸿蒙健身计划页面构建:动作清单与训练部位分布模块详解 前言 在 HarmonyOS 6.0 应用开发中,健身类页面的训练动作展示和训练部位分析是用户执行训练计划的核心参考模块。本文将以“健身计划”应用中的“动作清单”垂直列表模块和“训练部位分布”进度条网…...
torchvision transforms 报错怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 torchvision.transforms报错大揭秘:一招解决90%的坑目录torchvision.transforms报错大揭秘:一招解决90%的…...

自适应能量对齐:提升电子态密度机器学习预测精度的关键技术
1. 项目概述:为什么电子态密度的机器学习预测需要“自适应对齐”?在计算材料科学领域,电子态密度(DOS)是一个核心的物理量。它描绘了材料中电子能级随能量的分布情况,就像一张材料的“电子身份证”。通过这…...

【车辆路径规划】基于RRT算法的车辆导航工具箱实现附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...