浅谈C++函数特性
C++的函数特性
前言
在C++中,函数加入了许多特性,例如:a、函数缺省参数 b、函数重载 c、内联函数 等等……,这里我会和大家详细去探讨这些特性。以及探讨这些特性的一些细节,同时在内联部分,我们还会把C语言的宏再拿来和内联进行对比,提出一些可行性建议!
1. 函数缺省参数
1.1 缺省参数
缺省,缺省顾名思义,就是缺省函数的形参参数。我们先来看这样的场景:
//在使用C语言写一个栈的时候,会这个样初始化
typedef int STDataType;typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;void InitST(ST* p,int DefaultCapacity)
{STDataType* tmp = (STDataType*)malloc(sizeof(STDataType) * DefaultCapacity);if (tmp == NULL){perror("malloc");return;}p->a = tmp;p->top = 0;p->capacity = DefaultCapacity;
}
这样写就会让我们每次都传初始化的栈大小,对于我们来说是否是太过麻烦了。C++就引入了函数缺省参数的性质。可以让我们在传参的时候,可以不用进行传递一些参数。例如:
void InitST(ST* p,int DefaultCapacity = 10) // 声明的同时定义函数
{STDataType* tmp = (STDataType*)malloc(sizeof(STDataType) * DefaultCapacity);if (tmp == NULL){perror("malloc");return;}p->a = tmp;p->top = 0;p->capacity = DefaultCapacity;
}
我们就可以使用默认的参数值10了,如果我们确定我们需要的空间大小,直接显示传递就行。
函数缺省参数也有两种类型:
- 全缺省。全缺省:就是指将函数全部参数都给默认值,这样我们调用这个函数就可以像无参的函数一样调用了。同时也要求了,函数参数需要从左向右传递,且不能跳过。例如:
#include<iostream>
using namespace std;
void Print(int a = 10, int b = 20, int c = 30)
{cout << "a == " << a << endl;cout << "b == " << b << endl;cout << "c == " << c << endl;
}int main()
{Print(1,2,3);cout << endl;// 不完全传参:Print(1,2);cout << endl;Print(1);cout << endl;Print();cout << endl;return 0;// 规定:不能跳过传参 -- 只能从左往右依次传参//Print(1, , 3);
}
- 半缺省。半缺省:就是函数参数部分给了默认值。由于我们函数传参顺序(这里的传参不是指调用的时候在栈里形参入栈的时候顺序)是从左向右传递,所以缺省参数也要求,函数形参的默认值的缺省是从右向左给。这样就能保持一致性。
#include<iostream>
using namespace std;
void Print(int a, int b = 20, int c = 30)
{cout << "a == " << a << endl;cout << "b == " << b << endl;cout << "c == " << c << endl;
}int main()
{Print(1,2,3);cout << endl;Print(1,2);cout << endl;Print(1);cout << endl;return 0;
}
1.2 声明和定义分离
对于函数的缺省参数,还需要注意的是:不能声明和定义处同时给缺省。(上面的例子都是声明和定义没有分离)要求的是在声明处给缺省值。这是为什么呢?
很显然的是,举个例子:
#include<iostream>
using namespace std;
int ADD(int a, int b = 4); //声明int main()
{int ret = ADD(1);cout << ret << endl;return 0;
}int ADD(int a, int b = 8) //定义
{return a + b;
}
看了上面这个例子,很快就能明白:如果在函数的声明和定义处都给了缺省值是不是会造成参数的二义性?编译器到底是听声明的还是听定义的?对于这样的情况,编译器是会直接报错的,直接杜绝这种情况。了解了编译链接过程后我们知道,声明就是一个承诺,而定义就是实现承诺的方法。在编译过程,编译器是向上去寻找是否声明了调用的函数的,具体的实现过程是在链接过程需要看函数是如何定义的。这样以来,体会一下下面这个例子:
#include<iostream>
using namespace std;
int ADD(int a, int b);int main()
{int ret = ADD(1); //--> ADD(1,4)cout << ret << endl;return 0;
}int ADD(int a, int b = 4)
{return a + b;
}
根据编译链接过程我们不难推断出,这样的语法是存在问题的。为什么?在main函数内调用了Add函数,那么在编译过程中,编译器就往上找Add函数的声明,结果是找到了,再检查参数类型、数量…结果很显然:编译器发现实参和形参个数不匹配!!所以编译器选择了报错。
对于上面的示例:这里给出正确的示范
#include<iostream>
using namespace std;
int ADD(int a, int b = 4);int main()
{int ret = ADD(1);cout << ret << endl;return 0;
}int ADD(int a, int b = 4)
{return a + b;
}
我们还是需要牢记以下缺省参数的语法特性:
- 函数缺省参数从右向左。
- 函数传递参数从左向右。
- 函数缺省参数,声明定义分离,声明给缺省,定义不给缺省。
紧接着我们来看下面一个特性:函数重载
2. 函数重载
再进入函数重载之前,我们来看这样的场景。如果现在我想写一个打印函数,可以打印类型:int,double,float,char…如果是C语言我们只能这样操作
#include<stdio.h>void Print_Int(int /*...*/)
{//...
}
void Print_Double(double /*...*/)
{//...
}
//...
这样的命名方式真的叫人头大!!C++为了方便使用,推出了一种新的语法:函数重载。下面来具体介绍(实际上对于这样的函数我们采用函数模板更好,把这些活交给编译器来干,但是这里是为了举例,所以例子可能不太恰当)
2.1 函数重载
所谓函数重载(overloading):在同一作用域下(这一点十分重要,因为在后面继承多态部分会用其它概念综合)多个函数的函数名相同,但是这些函数的参数列表不同的情况。我们称为函数重载。
首先来看第一个问题:什么是参数列表?参数列表包括:a、参数个数 b、参数类型 c、参数顺序
下面来举个例子讲解:
#include<iostream>
using namespace std;void func() //1
{cout << "func()" << endl;
}
void func(int a)//2
{cout << "func(int a)" << endl;
}
void func(int a, char c)//3
{cout << "func(int a, char c)" << endl;
}void func(char c, int a)//4
{cout << "func(char c, int a)" << endl;
}int main()
{func(); //调用1func(1,'a'); //调用3func('a',1);//调用4func(1);//调用2return 0;
}
同时在这里指出一些细节:
- 函数重载会走类型最匹配的函数,例如:
#include<iostream>
using namespace std;
void func(int a)//1
{cout << "func(int a)" << endl;
}
void func(char a)//2
{cout << "func(char a)" << endl;
}int main()
{char c = 1;func(c);return 0;
}如果上面函数没有匹配char类型的,我们的func©当然可以走类型int型的,注意整型提升。
- 当无参的函数和全缺省的函数在一起的时候,会造成调用歧义
#include<iostream>
using namespace std;
void f()
{cout << "f()" << endl;
}void f(int a = 10)
{cout << "f(int a = 10)" << endl;
}int main()
{func();return 0;
}思考一下,这里会调用那个函数呢?编译器会报错,直接说明调用歧义的,因为我们从调用的角度来看,无法说明到底是调用无参的还是全缺省的。
- 函数调用的时候,如果不需要使用形参,可以不需要具体形参接受传参,以类型接受即可。
#include<iostream>
using namespace std;
void func(int)//1
{cout << "func(int)" << endl;
}
void func(char)//2
{cout << "func(char)" << endl;
}int main()
{char c = 'a';func(c);return 0;
}
当然上面的这种写法,肯定还是不允许以类型来作为实参传递的!只是说不会以实际的形参去接受实参,而是单纯地匹配类型。
2.2 函数重载的原因
为什么C语言不支持函数同名,而C++支持函数同名呢?
回顾编译链接过程,编译器会在链接时候形成一个符号表 – 记录全局的变量、函数名及其地址,如果C语言的函数名冲突,那么在符号表内的函数调用就会不明确。因为编译器是通过函数名来找到对应的函数的地址的。
例如:

那么C语言是无法做到的。C++是如何做到的呢?我们可以简单地制造一些错误。(这里是故意制造的,因为VS2022包装比较厉害,从汇编代码看不出太大的区别)
//这里是对下面函数的声明,但是没有进行实现
//在链接的时候符号表类就没有对应的函数地址,就会报链接错误,这个时候方便我们看无法解析的外部符号(函数名)
void func(int x);void func(char x);int main()
{func(1);func('a');return 0;
}

仔细对比这个错误提示。函数名是什么呢?上面的函数名是:?func@@YAXH@Z 和 ?func@@YAXN@Z。对比这两个函数名:发现它们其实是不一样的!!所以我们有理由大胆地猜想:C++是通过一套函数名修饰规则让C++的同名函数在符号表内呈现出不同的名字。而这套函数名修饰规则依靠的是:参数列表。事实证明确实是如此的。同时我们提出一个疑问:是否可以将函数的返回值纳入到函数名修饰规则来呢?为什么?这里的答案当然是不可以…原因也很简单:我们无法从调用的函数的方式上体现返回类型,C++语法也不支持。这样就导致编译器无法识别到底调用的哪个函数…
最后在这里小结一下:
- 函数重载三要素:a、同一作用域下 b、同函数名 c、不同参数列表
- 注意点:a、避免调用歧义 b、注意参数传递可以不用接受
- 函数重载的原因:函数名修饰规则 – 函数是在编译时确定调用的
3. 内联函数
3.1 内联函数
在谈论内联函数之前我们需要先回忆宏。宏可以进行文本替换。但是带有副作用(特别是带有参数的宏)
宏的优点:
- 不消耗空间,效率高
宏的缺点:
- 没有类型检查
- 不方便调试
- 可读性差,容易出错
- …
宏的缺点还是特别明显的,举个例子:
#define MAX(a,b) a > b ? a : b
该宏是为了选出a,b中的更最大值,却不乏有人这样调用:
int a = 2, b = 1;
MAX(a++, ++b);
MAX(1 + 5, 2 * 4);
MAX(MAX(a + 1), b + 3);
//...
很多调用都会让上面的宏出现很多问题,所以为了优先级,我们决定加上括号:
#define MAX(a,b) ((a) > (b) ? (a) : (b))
这样写就看起来就特别麻烦,在一些复杂的宏中,我们要了解其功能就特别麻烦了…有什么办法可以适当解决宏这个麻烦呢?
C++中内联函数应运而生!内联函数非常完美地解决了宏的缺点。语法如下:
关键字inline
inline Max(int a, int b) //一般宏喜欢全大写
{return a > b ? a : b
}
这样以来,我们定义了一个内联函数Max,作用是返回a,b之中的较大值。那么内联函数的原理是什么呢?我们探讨一下。我们都知道调用函数的时候汇编代码是执行call指令的,所以对于普通的函数,在汇编代码中都是执行的call指令,而对比宏,则是直接的文本替换,并没有执行call指令。我们的内联函数也是类似于宏一样也不执行call指令,直接在调用的地方展开。来看下面一个程序的反汇编
#include<iostream>
using namespace std;
inline int Max(int a, int b)
{return a > b ? a : b;
}void Func()
{}int main()
{Func();Max(1, 2);return 0;
}
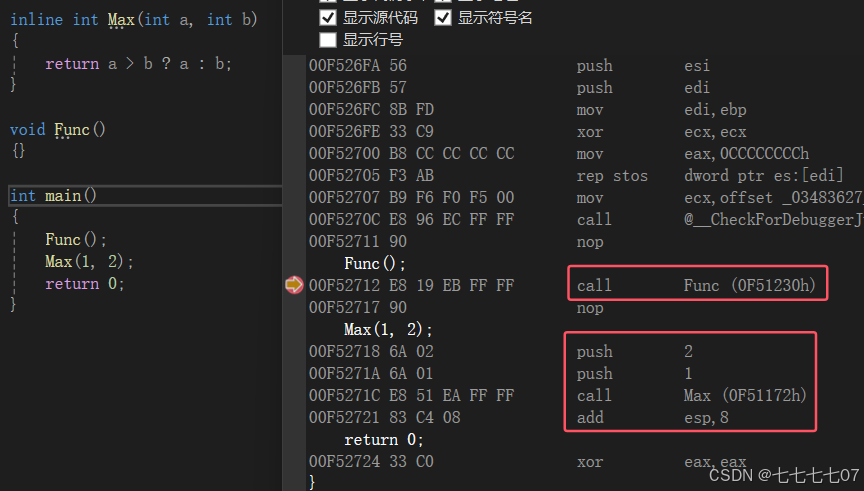
结果是不是令人大吃一惊?这个Max仍然调用了call指令啊?但是这是为什么呢?这就需要提出内联函数的其它特性了…根据宏的缺点,我们看到了内联函数可以解决:a、类型检查 b、可读性差 c、调试…没错,我们上面的程序正在进入调试,在调试(DEBUG)的状态下如果不执行call指令,我们怎么调试?可以思考一下,所以在这里我想说的是:内联函数在DEBUG版本下是不起作用的 – 因为我们需要调试;但是在RELEASE版本下就是有效的!
其次还需要补充的点是:
- 内联函数使用短小且经常调用的函数。为什么呢?原因是这样的,因为内联函数是以指令展开的形式进行的,所以很显然的是:如果一个内联函数的指令太多了,且调用次数很多,会发生什么呢?假设现有一个内联函数的指令有50语句,现在这个项目调用了10000行这个内联函数。对于内联函数来说:调用了多少指令?10000 * 50 = 50w行指令;对于普通调用来说:调用了多少指令? 10000 + 50 = 10050…这个差距也很明显了…这会导致最后可执行程序所占空间变大。这是十分不合理的,所以呢?编译器才不会冒这个风险,它不相信你能把握好这个度,所以内联函数对于编译器来说只是一个建议,最后是否成为内联函数还是由编译器决定。不能成为内联函数的几种函数:a、函数指令较多 b、递归函数。
- 内联函数是不可以声明定义分离的。为什么呢?这又要谈到我们的编译链接过程了。还记得符号表吗? 还记得内联函数是在调用出展开吗?很显然内联函数不执行call指令,所以他是不会进入符号表的,符号表内是不会存内联函数的地址的 所以想要在链接过程调用,是不可能的。所以建议:将内联函数的声明定义在同一个头文件中。
- …
* 3.2 尽量用const、enum、inline代替#define
这条建议是由衷的建议。
- 用const修饰。因为#define是不会被编译器看见的。例如:
#define PI 3.1415926
标记PI文本替换为3.1415926,但是如果PI发生报错了,我们的编译器的不会反馈出PI这个标识符,而是其它内容…为什么呢?因为我们的PI没有进入符号表内,在预处理阶段就被文本替换了。所以为了让编译器更能识别,建议:
const double Pi = 3.1415926;
- 建议使用enum。因为enum和#define很类似在int类型方面,例如:
enum Number
{N = 100;
}#define N 100
上面两种定义具有类似的效果:a、都可以作为整型使用 b、都不可以取地址…
但是很有区别的是:
枚举类型会 a、会类型检查 b、会注重作用域(#define只能通过#undef取消替换)…
- 使用inline代替宏。这个就不再赘述了,上面也探讨了内联的好处。
总体来说:C++推出内联函数这个语法极大的解决了宏的问题,使代码可以更好的维护…
到这里内容就结束了,但是实际上内联函数还有很多细节,比如说在类、多态(虚函数) 中就还有很多细节,到时候再处理。如果有什么错误失误,欢迎读者指出,作者虚心接受多多改进!!
本文章有参考:《Effective C++》
相关文章:
浅谈C++函数特性
C的函数特性 前言 在C中,函数加入了许多特性,例如:a、函数缺省参数 b、函数重载 c、内联函数 等等……,这里我会和大家详细去探讨这些特性。以及探讨这些特性的一些细节,同时在内联部分,我们还会把C语言的…...

Python----数据分析(Matplotlib三:绘图二:箱图,散点图,饼图,热力图,3D图)
一、箱图 箱图(Box Plot),又称为箱形图、箱线图、盒式图、盒状图或盒须图,是一种用于展示数据分布情况的统计图表 箱图通过显示数据的中位数、上下四分位数(Q1和Q3)、异常值和数据的分布范围,提…...

高性能PHP框架webman爬虫引擎插件,如何爬取数据
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

【2025年后端开发终极指南:云原生、AI融合与性能优化实战】
一、2025年后端开发的五大核心趋势 1. 云原生架构的全面普及 云原生(Cloud Native)已经成为企业级应用的核心底座。通过容器化技术(DockerKubernetes)和微服务架构,开发者能够实现应用的快速部署、弹性伸缩和故障自愈…...

健康养生:开启活力人生的钥匙
在这个瞬息万变的时代,人们愈发珍视健康。健康养生,宛如一把神奇的钥匙,为我们打开通往活力人生的大门,全方位呵护身心,提升生活品质。 从饮食层面看,均衡膳食是核心。每餐力求包含碳水化合物、蛋白质、脂…...

vue2+ele-ui实践
前言:真理先于实践,实践发现真理,再实践检验真理 环境:vue2 & element-ui 正片: Select 选择器 简称 下拉框 下拉框完整的使用循环 下拉框 → 点击下拉框 → 展示数据 → 选择数据 → 下拉框显示数据 核心具有…...

三维重建(十五)——多尺度(coarse-to-fine)
文章目录 一、多尺度与图像金字塔:从全局结构到局部细节二、特征提取与匹配2.1 从数据采集的角度2.2 从数据增强的角度2.3 从特征提取的方式三、以多尺度的方式使用特征3.1 特征提取与匹配3.1.1 多尺度特征检测3.1.2 金字塔匹配3.2 深度估计与立体匹配3.2.1 多尺度立体匹配3.2…...

SparkStreaming之04:调优
SparkStreaming调优 一 、要点 4.1 SparkStreaming运行原理 深入理解 4.2 调优策略 4.2.1 调整BlockReceiver的数量 案例演示: object MultiReceiverNetworkWordCount {def main(args: Array[String]) {val sparkConf new SparkConf().setAppName("Networ…...

勿以危小而为之勿以避率而不为
《故事汇之:所见/所闻/所历/所想》:《公园散步与小雨遇记》(二) 就差一点到山顶了,路上碰到一阿姨,她说等会儿要下大雨了,让我不要往上走了,我犹豫了一会儿,还是听劝地返…...

JavaWeb后端基础(4)
这一篇就开始是做一个项目了,在项目里学习,我主要记录在学习过程中遇到的问题,以及一些知识点 Restful风格 一种软件架构风格 在REST风格的URL中,通过四种请求方式,来操作数据的增删改查。 GET : 查询 …...

SpringBoot调用DeepSeek
引入依赖 <dependency><groupId>io.github.pig-mesh.ai</groupId><artifactId>deepseek-spring-boot-starter</artifactId><version>1.4.5</version> </dependency>配置 deepseek:api-key: sk-******base-url: https://api.…...
记录一下本地部署Dify的坑
1. 截止2025-3-4为止,请注意,不要直接拉Dify的1.0.0版本。请先试用0.15.3版本。1.0.0有一个bug需要解决。[PANIC]failed to init dify plugin db: failed to connect to hostdb userpostgres databasepostgres Issue #14707 langgenius/dify GitHub …...

LC109. 有序链表转换平衡二叉搜索树
LC109. 有序链表转换平衡二叉搜索树 题目要求(一)快慢指针1. 理解问题2. 解决思路3. 具体步骤4. 代码实现5. 复杂度分析6. 示例解释7. 总结 LC109. 有序链表转换平衡二叉搜索树 题目要求 (一)快慢指针 要将一个按升序排列的单链表转换为平衡的二叉搜索树(BST&…...

Hutool一个类型转换工具类 `Convert`,
Hutool 是一个非常实用的Java工具库,旨在简化Java开发中的常见任务。它包含了一个类型转换工具类 Convert,可以帮助开发者轻松地进行各种类型之间的转换。以下是一些使用 Convert 类进行类型转换的例子: 基本类型转换 假设你需要将一个字符…...

基于eRDMA实测DeepSeek开源的3FS
DeepSeek昨天开源了3FS分布式文件系统, 通过180个存储节点提供了 6.6TiB/s的存储性能, 全面支持大模型的训练和推理的KVCache转存以及向量数据库等能力, 每个客户端节点支持40GB/s峰值吞吐用于KVCache查找. 发布后, 我们在阿里云ECS上进行了快速的复现, 并进行了性能测试, ECS…...

【Linux篇】第一个系统程序 - 进度条
文章目录 1.回车与换行2.行缓冲区3.倒计时程序4.进度条 1.回车与换行 回车的概念: 回到当前行的最开始 \r换行的概念: 换到当前行的下一行\n 2.行缓冲区 当我们运行下面这段程序时,我们会发现屏幕上首先会打印出hello world!,再过两秒后程序结束。 当我们把\n去掉…...

VLM-E2E:通过多模态驾驶员注意融合增强端到端自动驾驶
25年2月来自香港科大广州分校、理想汽车和厦门大学的论文“VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion”。 人类驾驶员能够利用丰富的注意语义,熟练地应对复杂场景,但当前的自动驾驶系统难以复制这种能…...

如何将飞书多维表格与DeepSeek R1结合使用:效率提升的完美搭档
将飞书的多维表格与DeepSeek R1结合使用,就像为你的数据管理和分析之旅装上一台涡轮增压器。两者的合作,不仅仅在速度上让人耳目一新,更是将智能化分析带入了日常的工作场景。以下是它们如何相辅相成并改变我们工作方式的一些分享。 --- 在…...

Kali CentOs 7代理
工具v2↓ kali_IP段v2端口例子<1> kali_IP段v2端口例子<2> CentOs 7 //编辑配置文件 vi /etc/profile//在该配置文件的最后添加代理配置 export http_proxyhttp://ip:port //代理服务器ip地址和端口号 export https_proxyhttp://ip:port //代理服务器ip地址和…...

Zookeeper 的核心引擎:深入解析 ZAB 协议
#作者:张桐瑞 文章目录 前言ZAB 协议算法崩溃恢复选票结构选票筛选消息广播 前言 ZooKeeper 最核心的作用就是保证分布式系统的数据一致性,而无论是处理来自客户端的会话请求时,还是集群 Leader 节点发生重新选举时,都会产生数据…...
)
从点灯到AI:用高云Tang Nano 4K玩转FPGA+MCU混合开发(附避坑指南)
从点灯到AI:高云Tang Nano 4K混合架构开发实战与避坑指南 在嵌入式AI和边缘计算领域,FPGA凭借其并行计算能力和低功耗特性,正成为越来越多开发者的选择。而高云Tang Nano 4K这款搭载Cortex-M3硬核的FPGA开发板,以其独特的"FP…...

如何为 OpenClaw 配置 Taotoken 以实现高效的 Agent 工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为 OpenClaw 配置 Taotoken 以实现高效的 Agent 工作流 基础教程类,面向使用 OpenClaw 框架构建 AI Agent 的开发者…...

RISC-V双芯架构在智慧燃气报警器中的系统级设计与工程实践
1. 项目概述:当RISC-V芯遇上智慧燃气最近在深圳的智慧燃气发展论坛上,我注意到一家叫微五科技的芯片设计公司,他们带来了一套挺有意思的解决方案。核心不是别的,正是当下在嵌入式领域越来越火的RISC-V架构。他们这次重点展示的&am…...

喜马拉雅音频下载终极指南:免费解锁付费内容的桌面神器
喜马拉雅音频下载终极指南:免费解锁付费内容的桌面神器 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 你是否曾因网络…...
:覆盖LoRA适配器、MoE路由层、Tokenizer预处理3大高危模块)
【独家首发】DeepSeek官方未公开的DRY检查白皮书(v2.3.1内测版):覆盖LoRA适配器、MoE路由层、Tokenizer预处理3大高危模块
更多请点击: https://codechina.net 第一章:DeepSeek DRY原则检查的演进脉络与核心定义 DRY(Don’t Repeat Yourself)作为软件工程基石性原则,在DeepSeek大模型推理与代码生成场景中已从静态语法检查逐步演化为语义感…...
安装ROCm 4.5.2驱动及完整工具链)
保姆级教程:在Ubuntu 22.04上为DCU-Z100(ZiFang)安装ROCm 4.5.2驱动及完整工具链
国产AI加速卡DCU-Z100(ZiFang)全栈部署指南:从驱动安装到开发环境配置 在人工智能计算领域,国产硬件正逐步崭露头角。DCU-Z100(代号ZiFang)作为一款自主研发的深度学习计算单元,为开发者提供了全…...

PyTorch矩阵乘法进阶:用torch.matmul高效实现一个简易的Transformer注意力头
PyTorch矩阵乘法进阶:用torch.matmul高效实现一个简易的Transformer注意力头 在深度学习领域,矩阵乘法是构建复杂模型的基石操作。PyTorch作为当前最流行的深度学习框架之一,其torch.matmul函数在实现高效矩阵运算方面发挥着关键作用。本文将…...

别再只当Atlas是元数据仓库了!手把手教你用它的UI搞定数据分类与血缘追溯
别再只当Atlas是元数据仓库了!手把手教你用它的UI搞定数据分类与血缘追溯 数据治理工具常被视为"高大上"的架构师专属玩具,但Apache Atlas的UI界面却藏着连一线工程师都能立刻上手的实用功能。上周排查一个报表异常时,我发现团队里…...
)
WordPress密码忘了别慌!5种找回方法保姆级教程(含MySQL命令行和functions.php修改)
WordPress密码重置全攻略:从基础操作到高级解决方案 1. 紧急情况下的密码恢复策略 遇到WordPress后台密码丢失的情况,首先需要保持冷静。作为全球使用最广泛的内容管理系统之一,WordPress提供了多种密码恢复机制,适用于不同技术水…...

OBS智能跟拍插件:3分钟实现直播自动追踪的终极指南
OBS智能跟拍插件:3分钟实现直播自动追踪的终极指南 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 您是否在直播时经常为手动调整摄像头而烦恼?是否希望…...