【时序预测】时间序列有哪些鲁棒的归一化方法
时间序列数据在金融、气象、医疗等领域中广泛存在,而股票数据作为典型的时间序列之一,具有非平稳性、噪声多、波动大等特点。为了更好地进行数据分析和建模,归一化是一个重要的预处理步骤。然而,由于时间序列数据的特殊性,传统的归一化方法可能无法很好地应对异常值、分布偏移等问题。本文将由浅入深地探讨几种鲁棒的归一化方法,并分析其适用场景。
1. 归一化的意义与挑战
1.1 为什么要归一化?
归一化是将数据缩放到特定范围或标准化到某种分布的过程,其主要目的是:
- 消除量纲影响:不同特征的数值范围可能差异巨大,例如股票价格与交易量。
- 加速模型收敛:许多机器学习算法(如梯度下降法)对输入数据的尺度敏感。
- 提高模型性能:某些算法(如KNN、SVM)依赖于距离度量,归一化可以避免大尺度特征主导结果。
1.2 时间序列归一化的挑战
时间序列数据的特点使得归一化面临以下挑战:
- 非平稳性:均值和方差可能随时间变化。
- 异常值:股票市场中可能出现极端波动(如黑天鹅事件)。
- 分布偏移:数据分布可能在训练集和测试集中不一致。
因此,我们需要选择鲁棒的归一化方法,以应对这些挑战。
2. 常见的归一化方法及其局限性
2.1 最小-最大归一化 (Min-Max Scaling)
公式:
x ′ = x − x min x max − x min x' = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}} x′=xmax−xminx−xmin
- 优点:简单直观,将数据映射到固定范围(通常为[0, 1])。
- 缺点:对异常值敏感,因为极值会显著影响缩放范围。
2.2 Z-Score 标准化 (Standardization)
公式:
x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ
- 优点:假设数据服从正态分布时效果较好,能够消除均值和方差的影响。
- 缺点:对异常值仍然敏感,且需要计算全局均值和标准差。
这两种方法虽然常用,但在面对时间序列数据时往往表现不佳,尤其是在存在异常值或分布偏移的情况下。
3. 鲁棒的归一化方法
为了克服传统方法的局限性,以下几种方法更适合时间序列数据:
3.1 基于分位数的归一化 (Quantile Normalization)
分位数归一化利用数据的分位数信息,而非均值和标准差,从而减少异常值的影响。
方法描述:
- 计算数据的分位数(如25%、50%、75%)。
- 将每个数据点映射到对应的分位数位置。
- 缩放到目标范围(如[0, 1])。
优点:
- 对异常值鲁棒,因为分位数不受极端值影响。
- 能够处理非正态分布的数据。
应用场景:
适用于股票收益率等分布偏斜的数据。
3.2 滑动窗口归一化 (Rolling Window Normalization)
滑动窗口归一化是一种局部归一化方法,特别适合非平稳时间序列。
方法描述:
- 定义一个固定大小的滑动窗口(如30天)。
- 在每个窗口内计算局部均值和标准差。
- 使用局部统计量进行归一化:
x t ′ = x t − μ window σ window x'_t = \frac{x_t - \mu_{\text{window}}}{\sigma_{\text{window}}} xt′=σwindowxt−μwindow
优点:
- 能够捕捉时间序列的局部特性。
- 对非平稳性和分布偏移具有较好的适应性。
注意事项:
- 窗口大小的选择至关重要,过小可能导致噪声放大,过大则失去局部特性。
应用场景:
适用于股票价格等具有趋势和周期性的数据。
3.3 中位数绝对偏差归一化 (Median Absolute Deviation, MAD)
MAD是一种基于中位数的鲁棒统计量,用于衡量数据的离散程度。
方法描述:
- 计算数据的中位数 ( \text{median}(x) )。
- 计算每个数据点与中位数的绝对偏差:
MAD = median ( ∣ x − median ( x ) ∣ ) \text{MAD} = \text{median}(|x - \text{median}(x)|) MAD=median(∣x−median(x)∣) - 归一化公式:
x ′ = x − median ( x ) MAD x' = \frac{x - \text{median}(x)}{\text{MAD}} x′=MADx−median(x)
优点:
- 对异常值完全鲁棒,因为中位数和MAD都不受极端值影响。
- 不依赖于数据的分布假设。
应用场景:
适用于含有大量异常值的高频交易数据。
3.4 自适应归一化 (Adaptive Normalization)
自适应归一化结合了多种统计量,动态调整归一化参数。
方法描述:
- 动态计算局部均值、标准差、中位数等统计量。
- 根据数据特性选择合适的归一化策略(如Z-Score或MAD)。
- 实时更新归一化参数以适应数据的变化。
优点:
- 具有高度的灵活性和适应性。
- 能够处理复杂的非平稳时间序列。
应用场景:
适用于实时交易系统或在线学习模型。
4. 实践中的选择与优化
在实际应用中,选择归一化方法需要综合考虑以下因素:
- 数据特性:是否存在异常值?是否具有非平稳性?
- 任务需求:是预测未来趋势还是分类异常模式?
- 计算复杂度:滑动窗口和自适应归一化可能增加计算开销。
此外,可以通过以下方式进一步优化归一化效果:
- 结合领域知识:例如,在股票数据中,可以针对不同的时间段(如牛市和熊市)分别归一化。
- 交叉验证:通过实验对比不同方法的效果,选择最优方案。
5. 总结
时间序列数据的归一化是一个关键但复杂的预处理步骤。传统方法如最小-最大归一化和Z-Score标准化虽然简单易用,但在面对异常值和非平稳性时表现不佳。相比之下,基于分位数的归一化、滑动窗口归一化、MAD以及自适应归一化等方法更具鲁棒性,能够有效应对时间序列数据的挑战。
在实际应用中,建议根据数据特性和任务需求灵活选择归一化方法,并通过实验验证其效果。希望本文能为读者提供启发,帮助大家更好地处理时间序列数据!
相关文章:

【时序预测】时间序列有哪些鲁棒的归一化方法
时间序列数据在金融、气象、医疗等领域中广泛存在,而股票数据作为典型的时间序列之一,具有非平稳性、噪声多、波动大等特点。为了更好地进行数据分析和建模,归一化是一个重要的预处理步骤。然而,由于时间序列数据的特殊性…...

nlp第九节——文本生成任务
一、seq2seq任务 特点:输入输出均为不定长的序列 自回归语言模型: 由前面一个字预测下一个字的任务 encoder-decoder结构: Encoder-Decoder结构是一种基于神经网络完成seq2seq任务的常用方案 Encoder将输入转化为向量或矩阵,其…...

STM32MP1xx的启动流程
https://wiki.st.com/stm32mpu/wiki/Boot_chain_overview 根据提供的知识库内容,以下是STM32 MPU启动链的详细解析: 1. 通用启动流程 STM32 MPU启动分为多阶段,逐步初始化外设和内存,并建立信任链: 1.1 ROM代码&…...

wgcloud-server端部署说明
Wgcloud 是一款开源的轻量级服务器监控系统,支持多平台,可对服务器的 CPU、内存、磁盘、网络等指标进行实时监控。 以下是 Wgcloud Server端的详细部署步骤: 环境准备 服务器: 至少准备两台服务器,一台作为监控端&a…...
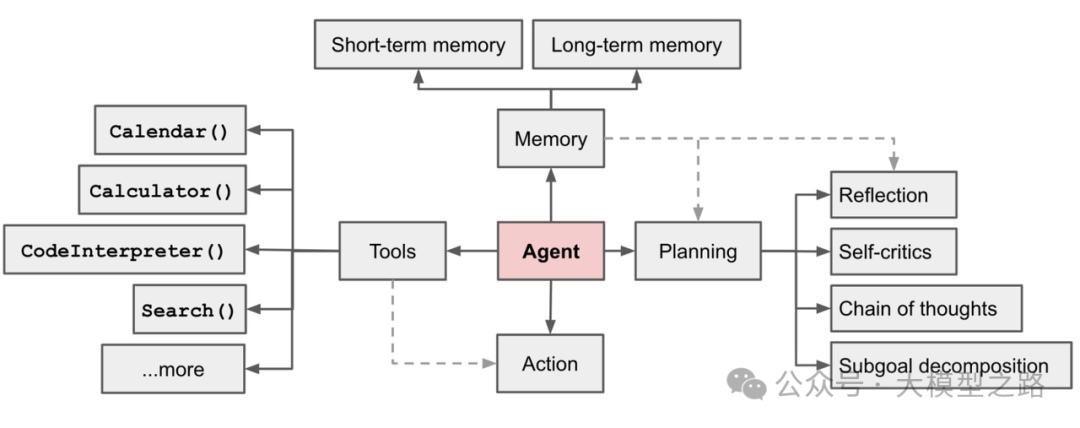
大模型Agent:人工智能的崭新形态与未来愿景
在人工智能技术高歌猛进的当下,大模型 Agent 作为 AI 领域的关键研究方向,正日益彰显出其独有的魅力以及广阔无垠的应用前景。大模型 Agent 不但具备对环境的感知、自主的理解、决策的制定以及行动的执行能力,而且能够游刃有余地应对繁杂任务…...

专题二最大连续1的个数|||
1.题目 题目分析: 给一个数字k,可以把数组里的0改成1,但是只能改k次,然后该变得到的数组能找到最长的子串且都是1。 2.算法原理 这里不用真的把0变成1,因为改了比较麻烦,下次用就要改回成1,这…...

【ORACLE】ORACLE19C在19.13版本前的一个严重BUG-24761824
背景 最近在某客户的ORACLE开发环境(oracle 19.10)中,发现一个非常奇怪情况, 开发人员反馈,有一条SQL,查询了两个sum函数作为两个字段, select sum(c1),sum(c2) from ...当两个sum一起出现时,第一个sum的结果不对&am…...

2025国家护网HVV高频面试题总结来了03(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 0x1 高频面试题第一套 0x2 高频面试题第二套 0x3 高频面试题第三套 0x4高频面试题第四套 0x1 高频面试题…...

CentOS vs Ubuntu - 常用命令深度对比及最佳实践指南20250302
CentOS vs Ubuntu - 常用命令深度对比及最佳实践指南 引言 在 Linux 服务器操作系统领域,CentOS 和 Ubuntu 是广泛采用的发行版。它们在命令集、默认工具链及生态系统方面各有特点。本文深入剖析 CentOS 与 Ubuntu 在常用命令层面的异同,并结合实践案例…...

SQL命令详解之常用函数
目录 1 简介 2 字符串函数 2.1 字符串函数语法 2.2 字符串函数练习 3 数学函数 3.1 数学函数语法 3.2 数学函数练习 4 日期时间函数 4.1 日期时间函数语法 4.2 日期时间函数练习 5 条件函数 5.1 条件函数语法 5.2 条件函数练习 6 总结 1 简介 在SQL中我们经常会用…...

IndexError: index 0 is out of bounds for axis 1 with size 0
IndexError: index 0 is out of bounds for axis 1 with size 0 欢迎来到英杰社区,这里是博主英杰https://bbs.csdn.net/topics/617804998 报错原因 数组或数据结构为空 如果数组或 DataFrame 在指定的维度上没有任何元素(例如,没有列&#x…...

C++学习之C++初识、C++对C语言增强、对C语言扩展
一.C初识 1.C简介 2.第一个C程序 //#include <iostream> //iostream 相当于 C语言下的 stdio.h i - input 输入 o -output 输出 //using namespace std; //using 使用 namespace 命名空间 std 标准 ,理解为打开一个房间,房间里有我们所需…...
)
k8s面试题总结(八)
1.K8s部署服务的时候,pod一直处于pending状态,无法部署,说明可能的原因 Node节点的资源不足,yaml文件资源限制中分配的内存,cpu资源太大,node宿主机资源没那么大,导致无法部署。部署pod的yaml文…...

《今日-AI-编程-人工智能日报》
一、AI行业动态 荣耀发布“荣耀阿尔法战略” 荣耀在“2025世界移动通信大会”上宣布,将从智能手机制造商转型为全球领先的AI终端生态公司,并计划未来五年投入100亿美元建设AI设备生态。荣耀展示了基于GUI的个人移动AI智能体,并推出多款AI终端…...

Koupleless 2024 年度报告 2025 规划展望
Koupleless 2024 年度报告 & 2025 规划展望 赵真灵 (花名:有济) Koupleless 负责人 蚂蚁集团技术专家 Koupleless 社区的开发和维护者,曾负责基于 K8s 的应用研发运维平台、Node/Pod 多级弹性伸缩与产品建设,当前主…...

C与C++中inline关键字的深入解析与使用指南
文章目录 引言一、历史背景与设计哲学1.1 C中的inline1.2 C中的inline 二、核心机制对比2.1 编译行为2.2 链接模型2.3 存储类说明符(详细解析)C的灵活组合C的限制原理 补充说明: 三、典型应用场景3.1 C中的使用场景3.2 C中的使用场景 四、现代…...

记录linux安装mysql后链接不上的解决方法
首先确保是否安装成功 systemctl status mysql 如果没有安装的话,执行命令安装 sudo apt install mysql-server 安装完成后,执行第一步检测是否成功。 通常初始是没有密码的,直接登陆 sudo mysql -u root 登录后执行以下命令修改密码&…...

Java 大视界 -- Java 大数据在智能金融反欺诈中的技术实现与案例分析(114)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

01_NLP基础之文本处理的基本方法
自然语言处理入门 自然语言处理(Natural Language Processing, 简称NLP)是计算机科学与语言学中关注于计算机与人类语言间转换的领域,主要目标是让机器能够理解和生成自然语言,这样人们可以通过语言与计算机进行更自然的互动。 …...

(十 六)趣学设计模式 之 责任链模式!
目录 一、 啥是责任链模式?二、 为什么要用责任链模式?三、 责任链模式的实现方式四、 责任链模式的优缺点五、 责任链模式的应用场景六、 总结 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,…...

【热门开源项目下载】yolo-onnx-java
【热门开源项目下载】yolo-onnx-java 1. 项目基础介绍与编程语言 yolo-onnx-java 是一个基于Java语言开发的轻量级AI模型调用框架,专注于为Java开发者提供高效、便捷的深度学习模型推理能力。项目通过ONNX(Open Neural Network Exchange)格式…...

Dream框架核心概念解析:Handler、Middleware与Router的完美协作
Dream框架核心概念解析:Handler、Middleware与Router的完美协作 【免费下载链接】dream Tidy, feature-complete Web framework 项目地址: https://gitcode.com/gh_mirrors/dre/dream Dream作为一款功能完备的Web框架,其核心架构围绕Handler、Mid…...

为什么顶级作曲家都在弃用Shazam转投Perplexity?——基于127万条音乐查询日志的权威对比报告
更多请点击: https://codechina.net 第一章:Perplexity音乐知识搜索的崛起背景与行业影响 近年来,音乐产业正经历从“内容分发”向“知识理解”的范式迁移。传统搜索引擎在处理音乐相关查询时,常受限于语义模糊性——例如用户输入…...

5分钟掌握HTML转Word:html-to-docx让文档格式转换变得简单高效
5分钟掌握HTML转Word:html-to-docx让文档格式转换变得简单高效 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx 还在为HTML内容无法完美转换为Word文档而烦恼吗?html-to-docx是…...

2026年AI Agent正在变成企业的数字员工
本文探讨了技术圈对AI关注焦点的转变,从单纯关注模型能力转向关注AI Agent的实际应用价值。通过引用Anthropic和Material联合调研报告,文章指出AI Agent已广泛应用于多阶段工作流、生产代码开发、数据分析和内部流程自动化,并带来可衡量的经济…...
:输入拍摄意图→自动匹配最优镜头词+推荐--stylize值+规避AI视觉歧义)
Midjourney镜头类型选择终极决策树(附可下载PDF流程图):输入拍摄意图→自动匹配最优镜头词+推荐--stylize值+规避AI视觉歧义
更多请点击: https://kaifayun.com 第一章:Midjourney镜头类型选择终极决策树概览 在 Midjourney V6 中,镜头类型(Lens Type)并非独立参数,而是通过组合 --style raw、 --s 750 及语义化摄影术语提示词协…...

Play Integrity API Checker:如何快速检测Android设备完整性的专业指南
Play Integrity API Checker:如何快速检测Android设备完整性的专业指南 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-check…...

【技术剖析】AI-RPA 的“眼睛”:详解 DOM 树精简与 OmniParser 屏幕解析技术
引言:当 RPA 遇上 AI,谁来做机器的“眼睛”? 2026 年,AI 与 RPA 的融合正在经历一场深刻的技术重构。根据市场研究数据,AIRPA 全球市场规模预计从 2025 年的 47.9 亿美元增长至 2026 年的 56 亿美元,复合年…...
)
告别Modelsim命令行!用Notepad++插件NppExec一键检查Verilog语法(附详细配置命令)
硬件工程师的效率革命:Notepad与Verilog语法检查的终极整合方案 在数字电路设计领域,Verilog作为主流硬件描述语言,其语法检查是每位工程师日常工作中不可或缺的环节。传统工作流程中,工程师们不得不在文本编辑器与EDA工具之间频繁…...

给地球做CT时,那些‘捣乱’的波都是什么来头?聊聊地震勘探里的‘噪音’家族
给地球做CT时,那些‘捣乱’的波都是什么来头?聊聊地震勘探里的‘噪音’家族 想象一下医生用CT扫描人体时,如果患者不停移动或周围有手机干扰,图像就会出现模糊和伪影。地球物理学家用地震波给地球做"CT扫描"时…...