深度学习模型Transformer初步认识整体架构
第一章:人工智能之不同数据类型及其特点梳理
第二章:自然语言处理(NLP):文本向量化从文字到数字的原理
第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)
第四章:循环神经网络RNN、LSTM以及GRU 对比(附代码)
第五章:理解Seq2Seq的工作机制与应用场景中英互译(附代码)
第六章:深度学习架构Seq2Seq-添加并理解注意力机制(一)
第七章:深度学习架构Seq2Seq-添加并理解注意力机制(二)
第八章:深度学习模型Transformer初步认识整体架构
一、Transformer 是什么?
Transformer 是 Google 在 2017 年提出的 基于自注意力机制(Self-Attention) 的深度学习模型,彻底摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),成为自然语言处理(NLP)领域的革命性架构。其核心思想是通过 全局依赖建模 和 并行计算 高效处理序列数据,广泛应用于机器翻译、文本生成、语音识别等任务。
典型应用
- BERT、GPT 等预训练模型均基于 Transformer。
- ChatGPT、DALL·E 等生成式 AI 的核心架构。
二、产生的背景
2.1. 传统模型的局限性
- RNN(LSTM/GRU):
- 序列依赖:必须逐时间步计算,无法并行训练。
- 长距离依赖:梯度消失/爆炸问题严重,难以捕捉远距离词的关系。
- CNN:
- 局部感受野:依赖卷积核大小,难以建模全局依赖。
- 位置敏感性:需堆叠多层才能扩大感受野,效率低。
2.2. 注意力机制的启发
- 2014 年,注意力机制首次在 Seq2Seq 模型中被提出,解决了编码器信息压缩的瓶颈。
- 但基于 RNN 的注意力模型依然无法完全并行,且长序列处理能力有限。
2.3. 硬件算力提升
- GPU/TPU 的普及使得大规模并行计算成为可能,推动了 Transformer 的可行性。
三、发展历史
| 时间 | 里程碑 |
|---|---|
| 2017 | Transformer 诞生:论文《Attention Is All You Need》提出纯注意力架构。 |
| 2018 | BERT:基于 Transformer 的双向预训练模型,刷新多项 NLP 任务记录。 |
| 2018 | GPT:基于 Transformer 的单向生成式预训练模型,开启大模型时代。 |
| 2020 | Vision Transformer (ViT):将 Transformer 应用于计算机视觉领域。 |
| 2022 | ChatGPT:基于 Transformer 的对话模型,引发生成式 AI 的爆发。 |
四、Transformer 的优缺点
优点
| 特性 | 说明 |
|---|---|
| 并行计算 | 所有位置同时计算,训练速度远超 RNN/CNN。 |
| 长距离依赖建模 | 自注意力直接捕捉任意位置的关系,避免梯度消失。 |
| 可扩展性 | 通过堆叠多层和多头注意力,轻松扩展模型容量。 |
| 多模态支持 | 统一处理文本、图像、语音等不同模态数据(如 ViT、Whisper)。 |
缺点
| 局限性 | 说明 |
|---|---|
| 计算复杂度高 | 自注意力复杂度为 O ( N 2 ) O(N^2) O(N2),长序列(如文档)计算成本剧增。 |
| 显存占用大 | 存储注意力矩阵需大量显存,限制输入长度。 |
| 数据需求高 | 依赖海量训练数据,小数据场景易过拟合。 |
五、Transformer 整体架构
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 堆叠组成,
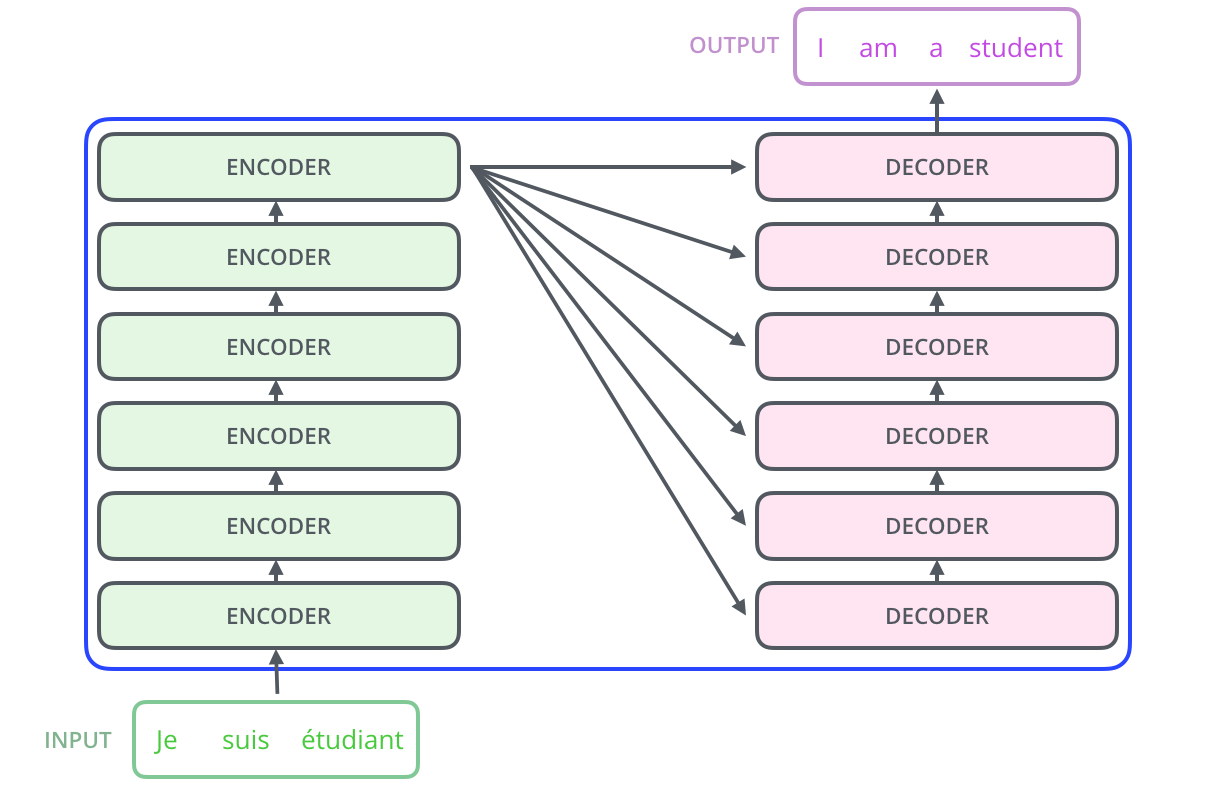
而每一个编码器或者解码器内部,又由不同的组件构成。
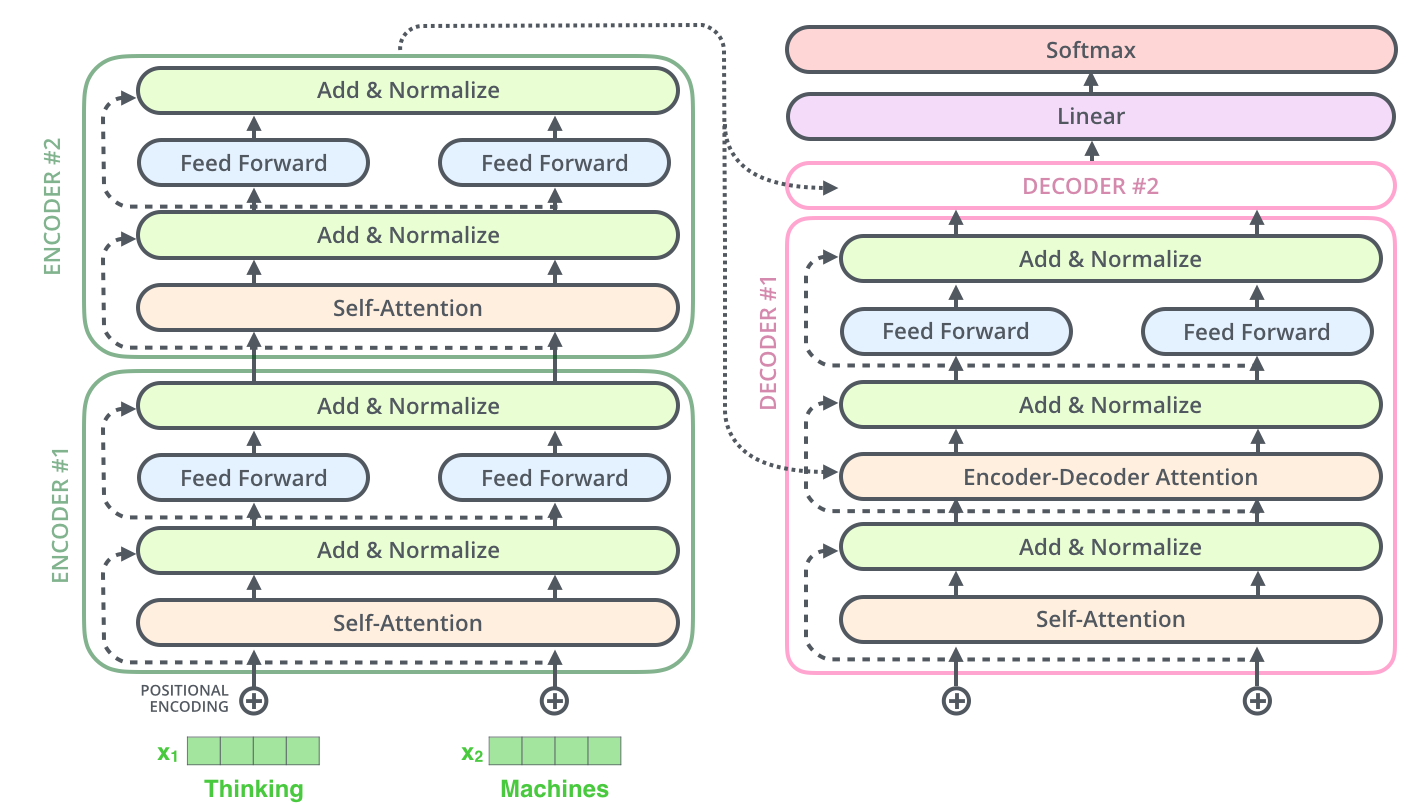
编码器(Encoder)
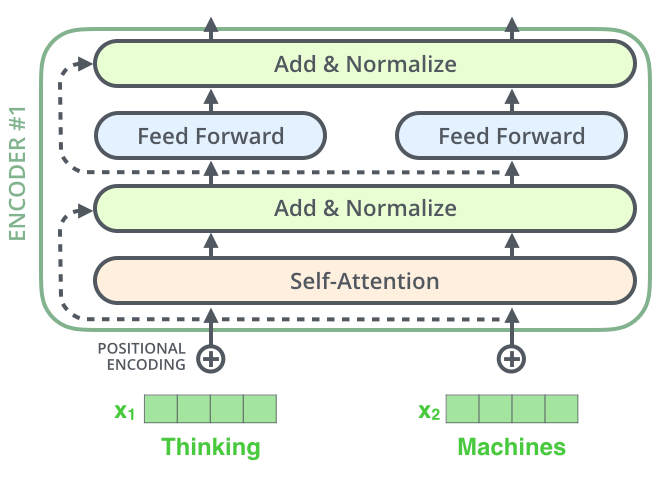
- 编码器(Encoder)包含 N 个相同层,每层由以下组件构成:
- 多头自注意力(Multi-Head Self-Attention)
- 前馈网络(Feed-Forward Network)
- 残差连接(Residual Connection) 和 层归一化(LayerNorm)
解码器(Decoder)
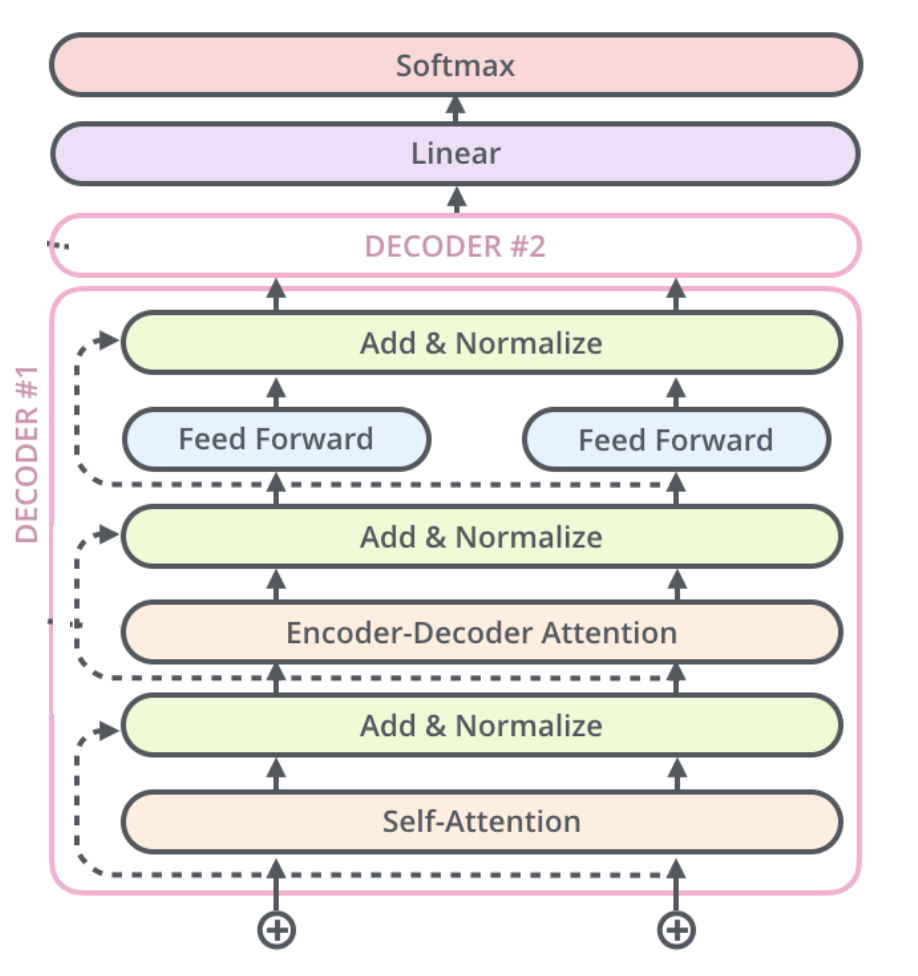
- 解码器(Decoder)包含 N 个相同层,每层在编码器基础上增加:
- 掩码多头自注意力(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力(Encoder-Decoder Attention)
六、核心组件
6.1. 自注意力机制(Self-Attention)
目标:为序列中每个位置生成加权表示,反映全局依赖关系。
计算步骤:
- 生成 Q、K、V 矩阵:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV - 计算注意力分数:
Attention ( Q , K , V ) = Softmax ( Q K ⊤ d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQK⊤)V- 缩放点积:除以 d k \sqrt{d_k} dk 防止梯度爆炸。
- Softmax:归一化为概率分布。
6.2. 多头注意力(Multi-Head Attention)
- 并行计算:将 Q、K、V 拆分为多个子空间(头),分别计算注意力后拼接:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO- 优势:捕捉不同子空间的语义特征(如语法、语义)。
6.3. 位置编码(Positional Encoding)
- 目标:为输入序列注入位置信息(替代 RNN 的时序性)。
- 公式(正弦/余弦函数):
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right), \quad PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos),PE(pos,2i+1)=cos(100002i/dpos) - 效果:使模型能区分不同位置的词(如“猫追狗” vs “狗追猫”)。
6.4. 前馈网络(Feed-Forward Network)
- 结构:两层全连接层 + 激活函数(如 ReLU):
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2 - 作用:增强模型非线性表达能力。
6.5. 残差连接与层归一化
- 残差连接:缓解梯度消失,公式为 x + Sublayer ( x ) x + \text{Sublayer}(x) x+Sublayer(x)。
- 层归一化:加速训练,稳定梯度。
6.6. 编码器-解码器注意力
- 解码器在生成每个词时,通过 编码器-解码器注意力层 关注编码器的输出:
- Q 来自解码器的上一状态。
- K、V 来自编码器的输出。
- 作用:动态对齐输入与输出序列(如机器翻译中的词对齐)。
七、总结
Transformer 通过 自注意力机制 和 并行计算架构,解决了传统模型的序列处理瓶颈,成为 AI 领域的基石技术。尽管存在计算资源消耗大的问题,但其在长距离依赖建模、多模态支持等方面的优势,使其在 NLP、CV、语音等领域持续引领技术突破。
下一章详细介绍Transformer的几个核心组件,自注意力推导示例、什么是多头注意力、为什么要添加位置编码等
相关文章:
深度学习模型Transformer初步认识整体架构
第一章:人工智能之不同数据类型及其特点梳理 第二章:自然语言处理(NLP):文本向量化从文字到数字的原理 第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码) 第四章:循环神经网络RNN、LSTM以及GR…...

【从模仿到超越:AIGC的崛起与AGI的终极梦想】
一、基本概念 1. AIGC(人工智能生成内容) 定义:基于人工智能技术生成文本、图像、音频、视频等数字内容的方法。技术基础:依赖深度学习模型(如GPT、DALL-E、Stable Diffusion)和自然语言处理(…...

标量、向量、矩阵与张量:从维度理解数据结构的层次
在数学和计算机科学中,维度描述了数据结构的复杂性,而标量、向量、矩阵、张量则是不同维度的数据表示形式。它们的关系可以理解为从简单到复杂的扩展,以下是详细解析: 1. 标量(Scalar):0维数据 …...

windows 上删除 node_modules
在 Windows 11 上,你可以通过命令行来删除 node_modules 文件夹并清除 npm 缓存。以下是具体步骤: 删除 node_modules 打开命令提示符(Command Prompt)或终端(PowerShell)。 导航到项目目录。你可以使用 …...
单例模式的五种实现方式
1、饿汉式 ①实现:在类加载的时候就初始化实例 ②优点:线程安全 ③缺点:实例在类加载的时候创建,可能会浪费资源 //饿汉式 public class EagerSingleton{private EagerSingleton(){} //私有构造方法private static EagerSingle…...

启智平台华为昇腾910B使用MS-Swift微调Janus-Pro-7/1B
最近想要微调一下DeepSeek出品的Janus多模态大模型 利用启智平台的昇腾910B国产计算卡进行大模型的微调 查看了一下MS-Swift支持了Janus模型的微调,LLamafactory好像暂时还不支持该模型的微调 看到了MS-Swift有单独对昇腾的支持,因此首先要安装swift&…...
)
蓝桥试题:传球游戏(二维dp)
一、题目描述 上体育课的时候,小蛮的老师经常带着同学们一起做游戏。这次,老师带着同学们一起做传球游戏。 游戏规则是这样的:n 个同学站成一个圆圈,其中的一个同学手里拿着一个球,当老师吹哨子时开始传球࿰…...

迷你世界脚本小地图接口:Mapmark
小地图接口:Mapmark 彼得兔 更新时间: 2023-10-25 10:33:48 具体函数名及描述如下: 序号 函数名 函数描述 1 newShape(...) 新增一个形状(线,矩形,圆形) 2 deleteShape(...) 删除一个形状 3 setShapeColor(...) 设置…...

从零开始在Windows使用VMware虚拟机安装黑群晖7.2系统并实现远程访问
文章目录 前言1.软件准备2. 安装VMware17虚拟机3.安装黑群晖4. 安装群晖搜索助手5. 配置黑群晖系统6. 安装内网穿透6.1 下载cpolar套件6.2 配置群辉虚拟机6.3 配置公网地址6.4 配置固定公网地址 总结 前言 本文主要介绍如何从零开始在Windows系统电脑使用VMware17虚拟机安装黑…...

Qt6.8.2创建WebAssmebly项目使用FFmpeg资源
Qt6新出了WebAssmebly功能,可以将C写的软件到浏览器中运行,最近一段时间正在研究这方便内容,普通的控件响应都能实现,今天主要为大家分享如何将FFmpeg中的功能应用到浏览器中。 开发环境:window11,Qt6.8.2…...

Java阻塞队列深度解析:高并发场景下的安全卫士
一、阻塞队列的核心价值 在电商秒杀系统中,瞬时涌入的10万请求如果直接冲击数据库,必然导致系统崩溃。阻塞队列如同一个智能缓冲带,通过流量削峰和异步解耦两大核心能力,成为高并发系统的核心组件。 二、Java阻塞队列实现类对比 …...

软件信息安全性测试流程有哪些?专业软件测评服务机构分享
在数字化时代,软件信息安全性测试的重要性愈发凸显。尤其是对于企业来说,确保软件的安全性不仅是维护用户信任的关键,也是满足合规要求的必要条件。 软件信息安全性测试是指通过一系列系统化的测试手段,评估软件应用在受到攻击时…...
)
Linux - 网络基础(应用层,传输层)
一、应用层 1)发送接收流程 1. 发送文件 write 函数发送数据到 TCP 套接字时,内容不一定会立即通过网络发送出去。这是因为网络通信涉及多个层次的缓冲和处理,TCP 是一个面向连接的协议,它需要进行一定的排队、确认和重传等处理…...

C++11新特性:auto遇上const时的推导规则
当auto推导变量类型时,const修饰符会影响推导结果,我们具体看一下有哪些影响 1、普通变量 例如: const int ci 42; auto a ci; // a 的类型是 int (顶层 const 被忽略) const auto ca ci; // ca 的类型是 const int (顶层 const 被…...

hom_mat2d_to_affine_par 的c#实现
hom_mat2d_to_affine_par 的c#实现 背景:为课室贡献一个通用函数,实现halcon算子的同等效果,查询csdn未果,deepseek二哥与chtgpt大哥给不了最终程序,在大哥与二哥帮助下,最终实现同等效果。 踩坑…...

相机几何与标定:从三维世界到二维图像的映射
本系列课程将带领读者开启一场独特的三维视觉工程之旅。我们不再止步于教科书式的公式推导,而是聚焦于如何将抽象的数学原理转化为可落地的工程实践。通过解剖相机的光学特性、构建成像数学模型、解析坐标系转换链条,直至亲手实现参数标定代码࿰…...
GPTQ - 生成式预训练 Transformer 的精确训练后压缩
GPTQ - 生成式预训练 Transformer 的精确训练后压缩 flyfish 曾经是 https://github.com/AutoGPTQ/AutoGPTQ 现在是https://github.com/ModelCloud/GPTQModel 对应论文是 《Accurate Post-Training Quantization for Generative Pre-trained Transformers》 生成式预训练Tr…...

【Python项目】基于深度学习的电影评论情感分析系统
【Python项目】基于深度学习的电影评论情感分析系统 技术简介:采用Python技术、Flask框架、MySQL数据库、Word2Vec模型等实现。 系统简介:该系统基于深度学习技术,特别是Word2Vec模型,用于分析电影评论的情感倾向。系统分为前台…...

Redis特性总结
一、速度快 正常情况下,Redis 执⾏命令的速度⾮常快,官⽅给出的数字是读写性能可以达到 10 万 / 秒,当然这也取决于机器的性能,但这⾥先不讨论机器性能上的差异,只分析⼀下是什么造就了 Redis 如此之快,可以…...

深入理解PHP的内存管理与优化技巧
深入理解PHP的内存管理与优化技巧 PHP作为一种广泛使用的服务器端脚本语言,其内存管理机制对于应用程序的性能和稳定性至关重要。本文将深入探讨PHP的内存管理机制,并提供一些优化技巧,帮助开发者更好地理解和优化PHP应用程序的内存使用。 …...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...

轻量级工作流引擎pro-workflow:Go语言实现与实战解析
1. 项目概述:一个为专业开发者量身打造的工作流引擎如果你是一名开发者,尤其是经常需要处理复杂业务逻辑、数据流转或自动化任务的后端或全栈工程师,那么你一定对“工作流”这个概念不陌生。从简单的审批流到复杂的微服务编排,工作…...

终极指南:如何为你的Mac鼠标安装强大定制功能
终极指南:如何为你的Mac鼠标安装强大定制功能 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命性的开源工具…...
)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码) 科研图表的美观程度直接影响论文的第一印象,而三维柱状图在展示多维度数据时尤为常见。传统手动调整每个柱体的颜色、透明度、光照效果不仅耗时&#…...