【Python爬虫】爬取公共交通路网数据
程序来自于Github,以下这篇博客作为完整的学习记录,也callback上一篇爬取公共交通站点的博文。
Bardbo/get_bus_lines_and_stations_data_from_gaode: 这个项目是基于高德开放平台和公交网获取公交线路及站点数据,并生成shp文件,代码相对粗糙,但简单可用![]() https://github.com/Bardbo/get_bus_lines_and_stations_data_from_gaode
https://github.com/Bardbo/get_bus_lines_and_stations_data_from_gaode
1. 导入库
首先是程序需要的python库。
import requests
import json
import pandas as pd
from lxml import etree
import time
from tqdm import tqdm-
requests:用于发送HTTP请求,获取网页内容或API数据。 -
json:用于处理JSON格式的数据。 -
pandas:用于数据处理和保存为CSV文件。 -
lxml:用于解析HTML内容。 -
time:用于控制爬取速度,避免过快请求导致被封禁。 -
tqdm:用于显示进度条,方便查看爬取进度。
2. 获取城市公交线路名称(get_bus_line_name 函数)
def get_bus_line_name(city_phonetic):url = 'http://{}.gongjiao.com/lines_all.html'.format(city_phonetic)r = requests.get(url).textet = etree.HTML(r)line_name = et.xpath('//div[@class="list"]//a/text()')return line_name这里同样也需要先爬取公交线路的名称,函数需要传入city_phonetic也就是城市的拼音(如 changsha、wuhan),函数会返回该城市所有公交线路的名称列表(line_name)。
3. 爬取公交路线(get_line_station_data 函数)
获取公交线路的url是高德的https://restapi.amap.com/v3/bus/linename?extensions=all&key={ak}&output=json&city={city}&offset=1&keywords={line_name}
那么先来看一下官方的介绍,这里使用的是公交路线关键字查询,也就是说我们要输入公交路线的关键字,例如15路等等。

返回的内容如下,status记录了查询成功与否,buslines中记录了查询成功的公交路线。

接下来来看代码:
def get_line_station_data(city, line_name, ak, city_phonetic):print(f'正在获取-->{line_name}')time.sleep(1)url = f'https://restapi.amap.com/v3/bus/linename?extensions=all&key={ak}&output=json&city={city}&offset=1&keywords={line_name}'r = requests.get(url).textrt = json.loads(r)try:if rt['buslines']:if len(rt['buslines']) == 0:print('no data in list..')else:dt = {}dt['line_name'] = rt['buslines'][0]['name']dt['polyline'] = rt['buslines'][0]['polyline']dt['total_price'] = rt['buslines'][0]['total_price']station_name = []station_coords = []for st in rt['buslines'][0]['busstops']:station_name.append(st['name'])station_coords.append(st['location'])dt['station_name'] = station_namedt['station_corrds'] = station_coordsdm = pd.DataFrame([dt])dm.to_csv(f'{city_phonetic}_lines.csv',mode='a',header=False,index=False,encoding='utf_8_sig')else:print('data not avaliable..')with open('data not avaliable.log', 'a') as f:f.write(line_name + '\n')except:print('error.. try it again..')time.sleep(2)get_line_station_data(city, line_name, ak, city_phonetic)函数通过高德地图API获取某条公交线路的详细信息,并保存到CSV文件中。通过构造API请求URL获取公交线路数据,解析响应并提取线路名称、路径、票价、站点名称和坐标,将数据保存到CSV文件,若数据不可用则记录日志,失败时等待2秒后重试。
如果爬取失败的话,检查一下key是否达到了限额,一天只能爬取5000次,爬取公交线路比较耗费次数。
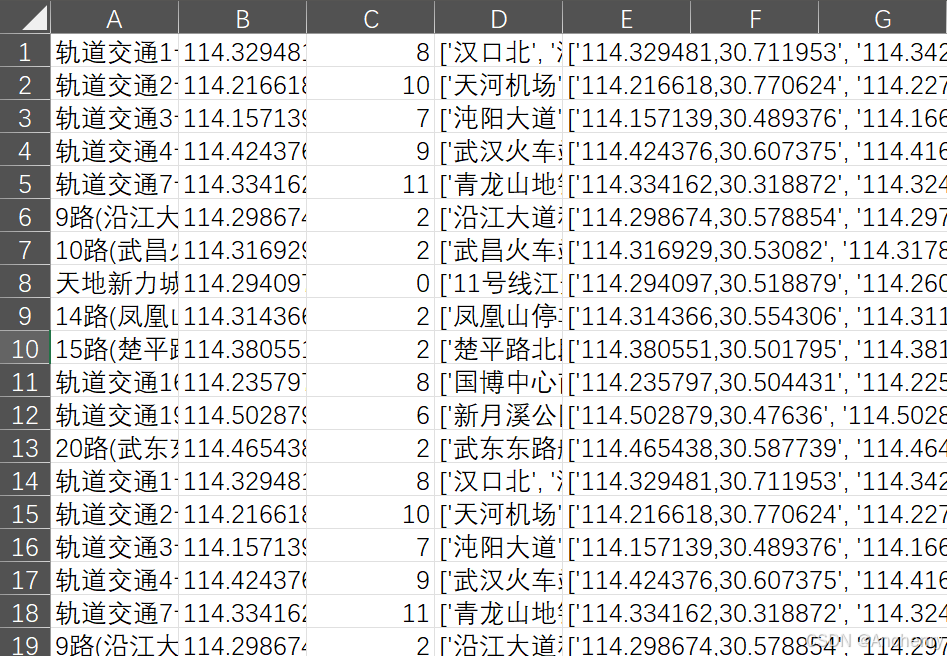
爬取完成后来看一下保存的csv,总共5列。
- A列:公交线路关键字(名称)
- B列:公交线路polyline,也就是线路途径的每个点(注意不是站点,公交线路的每个拐点都会被记录)
- C列:总价
- D列:途径站点关键字(名称)
- E列:途径站点经纬度坐标
4. 主程序调用
if __name__ == '__main__':city = '益阳'city_phonetic = 'yiyang'ak = '###' # 这里建议更改为自己的keystart_time = time.time()print(f'==========正在获取 {city} 线路名称==========')line_names = get_bus_line_name(city_phonetic)print(f'{city}在公交网上显示共有{len(line_names)}条线路')for line_name in tqdm(line_names):get_line_station_data(city, line_name, ak, city_phonetic)end_time = time.time()print(f'我爬完啦, 耗时{end_time - start_time}秒')自己需要设置的是最开始的city、city_phonetic、ak.
程序调用了上面的函数并记录了爬取的时间。
5. 线路、站点转成shp
那么有了这个csv怎么可视化呢?
那么作者就写了DataToShp这个 类用于将公交线路和站点数据从CSV文件转换为Shapefile格式,主要功能包括:
get_station_data:将站点坐标和名称从字符串格式转换为列表格式,将数据从横向展开为纵向,并去除重复项;
get_line_data:将线路的折线数据从字符串格式转换为列表格式;
create_station_shp:创建站点Shapefile,包含站点名称和坐标;
create_lines_shp:创建线路Shapefile,包含线路名称和折线坐标;
其实作者其实在这里还引入了从高德的火星坐标系转换为WGS_84的函数,但是大部分时候这种转换并不可靠,所以建议高德爬取的数据就搭配高德地图进行可视化使用。
# -*- coding: utf-8 -*-
# @Author: Bardbo
# @Date: 2020-11-09 21:09:12
# @Last Modified by: Bardbo
# @Last Modified time: 2020-11-09 21:59:35
import pandas as pd
import numpy as np
import shapefile
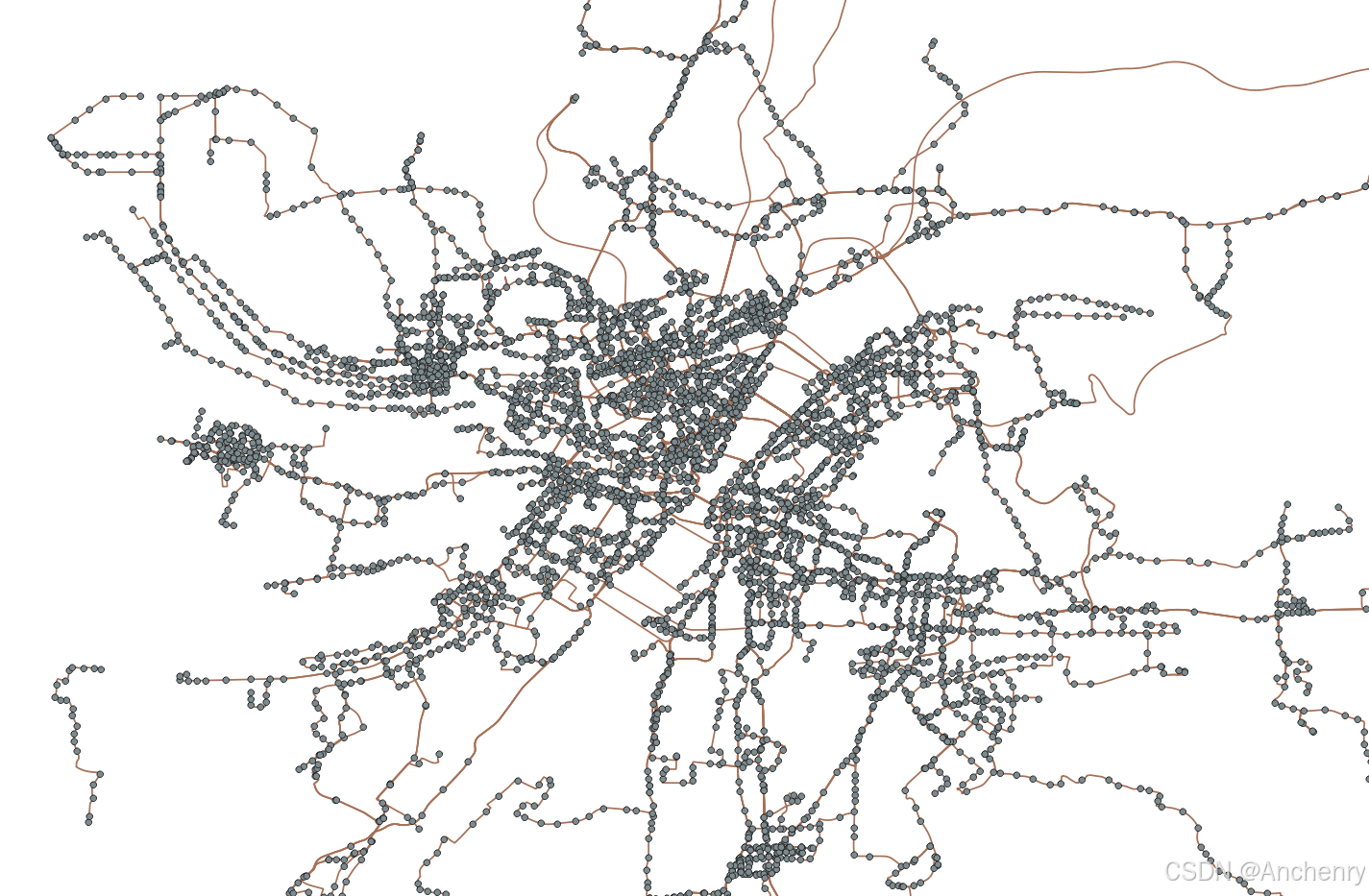
# import converterclass DataToShp:def __init__(self, filename):self.data = pd.read_csv(filename,names=['line_name', 'polyline', 'price','station_names', 'station_coords'])def get_station_data(self):df_stations = self.data[['station_coords', 'station_names']]# 将原本的一行字符串变为列表df_stations['station_coords'] = df_stations['station_coords'].apply(lambda x: x.replace('[', '').replace(']', '').replace('\'', '').split(', '))df_stations['station_names'] = df_stations['station_names'].apply(lambda x: x.replace('[', '').replace(']', '').replace('\'', '').split(', '))# 横置的数据变为纵向的数据station_all = pd.DataFrame(\np.column_stack((\np.hstack(df_stations['station_coords'].repeat(list(map(len, df_stations['station_coords'])))),np.hstack(df_stations['station_names'].repeat(list(map(len, df_stations['station_names'])))))),columns=['station_coords','station_names'])# 去除重复station_all = station_all.drop_duplicates()# # 坐标转换# station_all['st_coords_wgs84'] = station_all['station_coords'].apply(# self.stations_to_wgs84)station_all.reset_index(inplace=True)self.stations = station_alldef get_line_data(self):df_lines = self.data[['line_name', 'polyline']]df_lines['polyline'] = df_lines['polyline'].apply(lambda x: x.split(';'))# # 坐标转换# df_lines['lines_wgs84'] = df_lines['polyline'].apply(# self.lines_to_wgs84)df_lines.reset_index(inplace=True)self.lines = df_lines# def stations_to_wgs84(self, coor):# xy = coor.split(',')# lng, lat = float(xy[0]), float(xy[1])# return converter.gcj02_to_wgs84(lng, lat)## def lines_to_wgs84(self, coor):# ls = []# for c in coor:# xy = c.split(',')# lng, lat = float(xy[0]), float(xy[1])# ls.append(converter.gcj02_to_wgs84(lng, lat))# return lsdef create_station_shp(self, city_phonetic):w = shapefile.Writer(f'./data/{city_phonetic}_stations.shp')w.field('name', 'C')# 确保所有坐标都是浮动类型for i in range(len(self.stations)):coords = self.stations.loc[i, 'station_coords'].split(',') # 获取坐标lat = float(coords[0]) # 强制转换为浮动类型lon = float(coords[1]) # 强制转换为浮动类型# 确保坐标是浮动类型w.point(lat, lon) # 写入点w.record(self.stations.loc[i, 'station_names']) # 写入记录w.close()def create_lines_shp(self, city_phonetic):w = shapefile.Writer(f'./data/{city_phonetic}_lines.shp')w.field('name', 'C')for i in range(len(self.lines)):polyline = self.lines['polyline'][i]# 如果 polyline 是字符串,则使用 split();如果是列表,则直接使用if isinstance(polyline, list):polyline = [list(map(float, point.split(','))) for point in polyline]# 确保 polyline 是列表类型,进行写入w.line([polyline])w.record(self.lines['line_name'][i])w.close()if __name__ == '__main__':dts = DataToShp('yiyang_lines.csv')dts.get_station_data()dts.get_line_data()dts.create_station_shp()dts.create_lines_shp()print('shp文件创建完成')如下就是可视化后的效果【爬的时候无意中发现学校这多了两条公交,深入鄂州,win!】
相关文章:
【Python爬虫】爬取公共交通路网数据
程序来自于Github,以下这篇博客作为完整的学习记录,也callback上一篇爬取公共交通站点的博文。 Bardbo/get_bus_lines_and_stations_data_from_gaode: 这个项目是基于高德开放平台和公交网获取公交线路及站点数据,并生成shp文件,…...

基于Matlab的人脸识别的二维PCA
一、基本原理 传统 PCA 在处理图像数据时,需将二维图像矩阵拉伸为一维向量,这使得数据维度剧增,引发高计算成本与存储压力。与之不同,2DPCA 直接基于二维图像矩阵展开运算。 它着眼于图像矩阵的列向量,构建协方差矩阵…...

SSM架构 +Nginx+FFmpeg实现rtsp流转hls流,在前端html上实现视频播放
序言: 本文介绍通过SSM架构 NginxFFmpeg实现rtsp流转hls流,在前端html上实现视频播放功能。此方法可用于网络摄像头RTSP视频流WEB端实时播放。(海康和大华都可以),我使用的是海康 步骤一:安装软件 FFmpeg…...

【实战ES】实战 Elasticsearch:快速上手与深度实践-3.2.3 案例:新闻搜索引擎的相关性优化
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 Elasticsearch新闻搜索引擎相关性优化实战3.2.3 案例:新闻搜索引擎的相关性优化项目背景1. 相关性问题诊断与分析1.1 初始查询DSL示例1.2 问题诊断矩阵1.3 性能基…...

SQL经典查询
查询不在表里的数据,一张学生表,一张学生的选课表,要求查出没有选课的学生? select students.student_name from students left join course_selection on students.student_idcourse_selection.student_id where course_selecti…...

体验开源openeuler openharmony stratovirt模拟器
文档 openeuler社区面向数字基础设施的开源操作系统 openharmony社区 OpenHarmony是由开放原子开源基金会(OpenAtom Foundation)孵化及运营的开源项目, 目标是面向全场景、全连接、全智能时代、基于开源的方式,搭建一个智能终端设备操作系统…...
【C++】:STL详解 —— 红黑树
目录 平衡二叉查找树 红黑树的概念 红黑树的五大性质 红黑树的效率 红黑树和AVL树的比较 插入与删除操作 内存与实现复杂度 经典性能数据对比 总结 对旋转的基本理解 旋转的作用 左旋(Left Rotation) 右旋(Right Rotation…...
)
蓝桥试题:蓝桥勇士(LIS)
一、题目描述 小明是蓝桥王国的勇士,他晋升为蓝桥骑士,于是他决定不断突破自我。 这天蓝桥首席骑士长给他安排了 N 个对手,他们的战力值分别为 a1,a2,...,an,且按顺序阻挡在小明的前方。对于这些对手小明可以选择挑战…...

Trae IDE新建C#工程
目录 1 结论 2 项目结构 3 项目代码 1 结论 新建C#工程来说,Trae的Chat比DeepSeek的Coder好用。 2 项目结构 MyWinFormsApp/ │ ├── Program.cs ├── Form1.cs ├── Form1.Designer.cs ├── MyResources/ │ └── MyResources.resx └── MyWin…...

Linux基础--进程管理
目录 静态查看进程 使用命令: ps 动态查看进程 使用命令: top 关闭进程: 使用命令: kill 查看进程占用端口 使用命令: ss 编辑 查看某端口是否被进程占用 使用命令: lsof 作业管理 进程后台运行: 使用命令: jobs 将后台进程调回前台 使用指令: fg 将前台进…...
)
Java面向对象(详细解释)
第一章 Static关键字 1.static的介绍以及基本使用 1.概述:static是一个静态关键字 2.使用: a.修饰一个成员变量: static 数据类型 变量名 b.修饰一个方法: 修饰符 static 返回值类型 方法名(形参){…...

qt ui相关的第三方库插件库
Qt UI相关的第三方库和插件库有很多,能帮助开发者提高开发效率,扩展UI功能,增强可用性和美观度。以下是一些常见的第三方库和插件: 1. QCustomPlot 功能:用于在Qt应用程序中创建交互式的二维绘图。特点:支…...

详解动态规划算法
动态规划 一、动态规划的核心思想二、动态规划的步骤1. 定义状态(State)2. 确定状态转移方程(State Transition Equation)3. 确定边界条件(Base Case)4. 填表(Table Filling)或递归计…...

LINUX网络基础 [五] - HTTP协议
目录 HTTP协议 预备知识 认识 URL 认识 urlencode 和 urldecode HTTP协议格式 HTTP请求协议格式 HTTP响应协议格式 HTTP的方法 HTTP的状态码 编辑HTTP常见Header HTTP实现代码 HttpServer.hpp HttpServer.cpp Socket.hpp log.hpp Makefile Web根目录 H…...

慕慕手记项目日志 项目从开发到部署多环境配置 2025-3-8
慕慕手记项目日志 项目从开发到部署多环境配置 2025-3-8 现在是已经到了课程的第十章了,开始进行配置项目环境了。现在要完成的任务是项目可以正常运行,而且可以自由切换配置,开发/测试。 下面是当前的目录结构图: 现在来解释一…...

华为配置篇-OSPF基础实验
OSPF 一、简述二、常用命令总结三、实验3.1 OSPF单区域3.2 OSPF多区域3.3 OSPF 的邻接关系和 LSA 置底 一、简述 OSPF(开放式最短路径优先协议) 基本定义 全称:Open Shortest Path First 类型:链路状态路由协议(IGP&…...

闭包:JavaScript 中的隐形大杀器
你可能已经在很多地方听说过闭包这个词,尤其是涉及到 JavaScript 的作用域和异步操作时。闭包是 JavaScript 中非常核心的概念,然而它又非常容易让开发者感到困惑。今天我们就来深入剖析闭包,帮助你真正理解它的工作原理,以及如何…...

【消息队列】数据库的数据管理
1. 数据库的选择 对于当前实现消息队列这样的一个中间件来说,具体要使用哪个数据库,是需要稍作考虑的,如果直接使用 MySQL 数据库也是能实现正常的功能,但是 MySQL 也是一个客户端服务器程序,也就意味着如果想在其他服…...

玩转ChatGPT:GPT 深入研究功能
一、写在前面 民间总结: 理科看Claude 3.7 Sonnet 文科看DeepSeek-R1 那么,ChatGPT呢? 看Deep Research(深入研究)功能。 对于科研狗来说,在这个文章爆炸的时代,如何利用AI准确、高效地收…...

Centos8部署mongodb报错记录
使用mongo ops安装mongodb6.0.4副本集报错 error while loading shared libraries: libnetsnmpmibs.so.35: cannot open shared object file: No such file or directory 解决 yum install net-snmp net-snmp-devel -y建议:初始化系统时把官网上的依赖包都装一遍 即…...

STM32F4用HAL库驱动MPU6050,从引脚重映射到数据读取的保姆级避坑指南
STM32F4 HAL库驱动MPU6050全流程实战:从引脚重映射到数据解析的深度避坑指南 第一次接触STM32F4和MPU6050的组合时,我花了整整三天时间才让传感器吐出第一个有效数据。不是I2C通信失败,就是数据全为零,最崩溃的是明明按照教程操作…...

Fusion 360安装后想改位置?别重装!试试这个Windows符号链接‘乾坤大挪移’
Fusion 360安装路径迁移:无需重装的Windows符号链接实战指南 你是否遇到过这样的困扰——Fusion 360默认安装在C盘,随着项目文件增多,宝贵的SSD空间被快速吞噬?传统认知告诉我们,软件一旦安装就无法更改路径࿰…...

Vue二维码扫描组件:3种实战场景深度解析
Vue二维码扫描组件:3种实战场景深度解析 【免费下载链接】vue-qrcode-reader A set of Vue.js components for detecting and decoding QR codes. 项目地址: https://gitcode.com/gh_mirrors/vu/vue-qrcode-reader 在现代Web应用中,二维码扫描功能…...

为啥大模型都要用 Token 调用,不能直接扒网页端接口?
1. 网页端接口是「给人用的」,随时会改 网页版(比如官网聊天页)的接口: 参数、请求头、加密算法、签名天天变 前端一改版,接口地址、加密方式直接作废 你好不容易扒完,过两天就挂,还要重新抓包、逆向 而官方开放的 API + Token 是稳定商用接口,几年都不换格式,专门给…...

告别内网穿透:OpenWrt软路由IPv6配置实战与DDNS部署指南
1. 为什么我们需要IPv6? 最近几年,越来越多的朋友发现家里的宽带已经拿不到IPv4公网地址了。我自己用的移动宽带就是这样,光猫改桥接后用软路由拨号,拿到的永远是个100开头的内网IP。打电话给运营商,客服很客气地告诉我…...

MATLAB 2024 升级指南:彻底卸载旧版,高效部署新版
1. 为什么需要彻底卸载旧版MATLAB? 每次MATLAB大版本更新都会带来新功能和性能优化,但很多用户直接覆盖安装后常遇到各种奇怪问题。我去年帮实验室处理过几十台电脑的升级故障,90%的问题都源于旧版残留文件。比如有位同学复现图像处理代码时&…...

5分钟让您的PS3手柄在Windows上重获新生:DsHidMini驱动完全指南
5分钟让您的PS3手柄在Windows上重获新生:DsHidMini驱动完全指南 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 还在为闲置的索尼DualShock 3手柄…...

Dify应用开发入门:通过示例项目快速掌握低代码AI工作流构建
1. 项目概述:一个开箱即用的Dify应用示例最近在折腾AI应用开发,发现很多朋友对Dify这个平台很感兴趣,但往往卡在“从零到一”的第一步。看到一个叫“chen-banxia/dify-application-sample”的项目,感觉它正好解决了这个痛点。这本…...

基于大语言模型的智能BI工具:从自然语言到SQL与可视化的工程实践
1. 项目概述:一个开源的商业智能对话工具最近在折腾数据分析和可视化,发现一个挺有意思的开源项目,叫openchatbi。简单来说,它就是一个能让你用自然语言跟数据库“聊天”的工具。你不需要写复杂的 SQL 语句,直接问“上…...

LRCGET:如何用500行代码重定义你的离线音乐体验
LRCGET:如何用500行代码重定义你的离线音乐体验 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 在数字音乐流媒体盛行的时代,我…...