6.过拟合处理:确保模型泛化能力的实践指南——大模型开发深度学习理论基础
在深度学习开发中,过拟合是一个常见且具有挑战性的问题。当模型在训练集上表现优秀,但在测试集或新数据上性能大幅下降时,就说明模型“记住”了训练数据中的噪声而非学习到泛化规律。本文将从实际开发角度系统讲解如何应对过拟合,包括 Dropout、数据增强、L1/L2 正则化等多种方法,同时讨论其他辅助策略,确保模型在训练集与测试集上均能保持良好表现。
一、引言
-
背景说明
- 过拟合定义:模型在训练集上取得极高精度,但在未见数据上表现较差。
- 重要性:提升模型泛化能力是实际应用中成功部署深度学习模型的关键。
-
本文目标
- 探讨多种应对过拟合的策略。
- 结合实际工具与代码示例,帮助开发者灵活应对过拟合问题。
二、过拟合概述
2.1 过拟合的成因
-
模型复杂度过高
模型参数过多或网络层数太深,容易导致对训练数据的噪声进行拟合。 -
训练数据不足
数据样本量较少时,模型容易学习到数据中的随机误差。 -
训练时间过长
过度训练可能使模型逐步记忆训练数据的细节,而忽略了数据的普遍模式。
2.2 过拟合的表现
- 训练损失持续下降,而验证损失开始上升。
- 在测试集上的预测准确率显著低于训练集。
三、过拟合处理方法
3.1 Dropout
概念与原理
- 定义:在训练过程中,随机将部分神经元的输出设置为零,迫使网络不依赖于单一特征组合。
- 作用:通过随机丢弃神经元,减少模型内部的相互依赖性,提高网络的鲁棒性和泛化能力。
实践建议
- 常用的 Dropout 比例在 0.2 至 0.5 之间,根据模型复杂度和任务需求调整。
- 一般放置在全连接层中,对卷积层则可采用 Spatial Dropout。
工具支持
- PyTorch:使用
nn.Dropout或nn.Dropout2d。 - TensorFlow/Keras:使用
tf.keras.layers.Dropout。
3.2 数据增强
概念与原理
- 定义:通过对原始训练数据进行变换(如旋转、缩放、裁剪、颜色变换等)生成更多的训练样本。
- 作用:扩充数据集规模,使模型在面对多样化样本时能够学到更为鲁棒的特征,降低过拟合风险。
实践建议
- 根据任务选择合适的数据增强方法,例如图像任务常用随机翻转、旋转、裁剪;文本任务可采用同义词替换、随机插入等。
- 确保数据增强后的样本仍保持合理的语义或视觉信息。
工具支持
- PyTorch:使用
torchvision.transforms模块中的多种数据增强方法。 - TensorFlow/Keras:使用
tf.image模块或tf.keras.preprocessing.image.ImageDataGenerator。
3.3 L1/L2 正则化
概念与原理
- L1 正则化
- 通过在损失函数中加入权重绝对值之和的惩罚项,使得部分权重趋于零,起到特征选择作用。
- L2 正则化
- 通过加入权重平方和的惩罚项,使得权重趋于较小的值,防止参数过大导致过拟合。
实践建议
- 根据模型特点选择正则化方法:L1 正则化适合特征稀疏性要求较高的任务;L2 正则化更普遍,适用于大多数模型。
- 在调优过程中调整正则化系数(weight decay)以达到最佳平衡。
工具支持
- PyTorch:在优化器中设置
weight_decay参数(通常对应于 L2 正则化),或自定义正则化项实现 L1 正则化。 - TensorFlow/Keras:使用
kernel_regularizer参数,如tf.keras.regularizers.l2(0.01)。
3.4 其他辅助方法
模型简化
- 通过降低模型复杂度(减少层数、参数数量)来减少过拟合风险。
交叉验证
- 利用交叉验证技术在多个数据子集上评估模型性能,确保模型泛化能力。
提前停止训练
- 结合 Early Stopping 策略,在验证集损失不再下降时及时停止训练,防止过度拟合。
四、实践案例与代码示例
下面提供一个简单的 PyTorch 示例,展示如何在训练过程中应用 Dropout、数据增强和正则化来处理过拟合问题。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader# 定义一个简单的卷积网络,并在全连接层中应用 Dropout 与 L2 正则化
class SimpleCNN(nn.Module):def __init__(self, dropout_rate=0.5):super(SimpleCNN, self).__init__()self.conv = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.fc = nn.Sequential(nn.Dropout(dropout_rate), # 应用 Dropoutnn.Linear(32 * 16 * 16, 10))def forward(self, x):x = self.conv(x)x = x.view(x.size(0), -1)x = self.fc(x)return x# 数据增强:随机水平翻转、随机裁剪
transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomCrop(32, padding=4),transforms.ToTensor(),
])# 加载 CIFAR10 数据集(仅作为示例)
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 模型、损失函数与优化器
model = SimpleCNN(dropout_rate=0.5)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # L2 正则化通过 weight_decay 实现# 简单训练循环示例
num_epochs = 5
for epoch in range(num_epochs):model.train()running_loss = 0.0for inputs, targets in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()running_loss += loss.item() * inputs.size(0)epoch_loss = running_loss / len(train_dataset)print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}")
代码说明
-
网络设计
- 采用简单的卷积神经网络,包含一个卷积层和一个全连接层。
- 在全连接层前添加 Dropout,用于随机丢弃部分神经元输出,降低模型对单一特征的依赖。
-
数据增强
- 使用
torchvision.transforms对 CIFAR10 数据进行随机水平翻转与随机裁剪,扩充训练样本,提升模型泛化能力。
- 使用
-
正则化
- 在优化器中设置
weight_decay参数,实现 L2 正则化,有助于控制模型权重的大小。
- 在优化器中设置
-
训练循环
- 简单的训练循环展示如何结合以上策略进行模型训练,实时监控损失变化,调整参数。
五、总结
过拟合是深度学习中常见的问题,但通过合理的策略可以有效缓解。本文详细介绍了三大主要方法:
- Dropout:通过随机丢弃部分神经元,减少模型对局部特征的依赖,从而提高泛化能力。
- 数据增强:通过对训练数据进行变换扩充数据集,帮助模型学习到更多样化的特征。
- L1/L2 正则化:通过在损失函数中加入惩罚项,控制模型参数大小,防止过度拟合。
此外,辅助方法如模型简化、交叉验证和提前停止训练,也在实际开发中发挥着重要作用。通过综合运用这些策略,并利用现代深度学习框架(如 PyTorch 与 TensorFlow)的内置工具,开发者可以构建出既高效又稳健的深度学习模型。
附录
- 工具资源
- PyTorch 官方文档:pytorch.org
- TensorFlow 官方文档:tensorflow.org
相关文章:

6.过拟合处理:确保模型泛化能力的实践指南——大模型开发深度学习理论基础
在深度学习开发中,过拟合是一个常见且具有挑战性的问题。当模型在训练集上表现优秀,但在测试集或新数据上性能大幅下降时,就说明模型“记住”了训练数据中的噪声而非学习到泛化规律。本文将从实际开发角度系统讲解如何应对过拟合,…...

【玩转23种Java设计模式】结构型模式篇:组合模式
软件设计模式(Design pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。 汇总目录链接&…...

专业工具,提供多种磁盘分区方案
随着时间的推移,电脑的磁盘空间往往会越来越紧张,许多人都经历过磁盘空间不足的困扰。虽然通过清理垃圾文件可以获得一定的改善,但随着文件和软件的增多,磁盘空间仍然可能显得捉襟见肘。在这种情况下,将其他磁盘的闲置…...

SELinux 概述
SELinux 概述 概念 SELinux(Security-Enhanced Linux)是美国国家安全局在 Linux 开源社区的帮助下开发的一个强制访问控制(MAC,Mandatory Access Control)的安全子系统。它确保服务进程仅能访问它们应有的资源。 例…...

【十三】Golang 通道
💢欢迎来到张胤尘的开源技术站 💥开源如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 通道通道声明初始化缓冲机制无缓冲通道代码示例 带…...
DeepSeek专题:DeepSeek-V2核心知识点速览
AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等…...
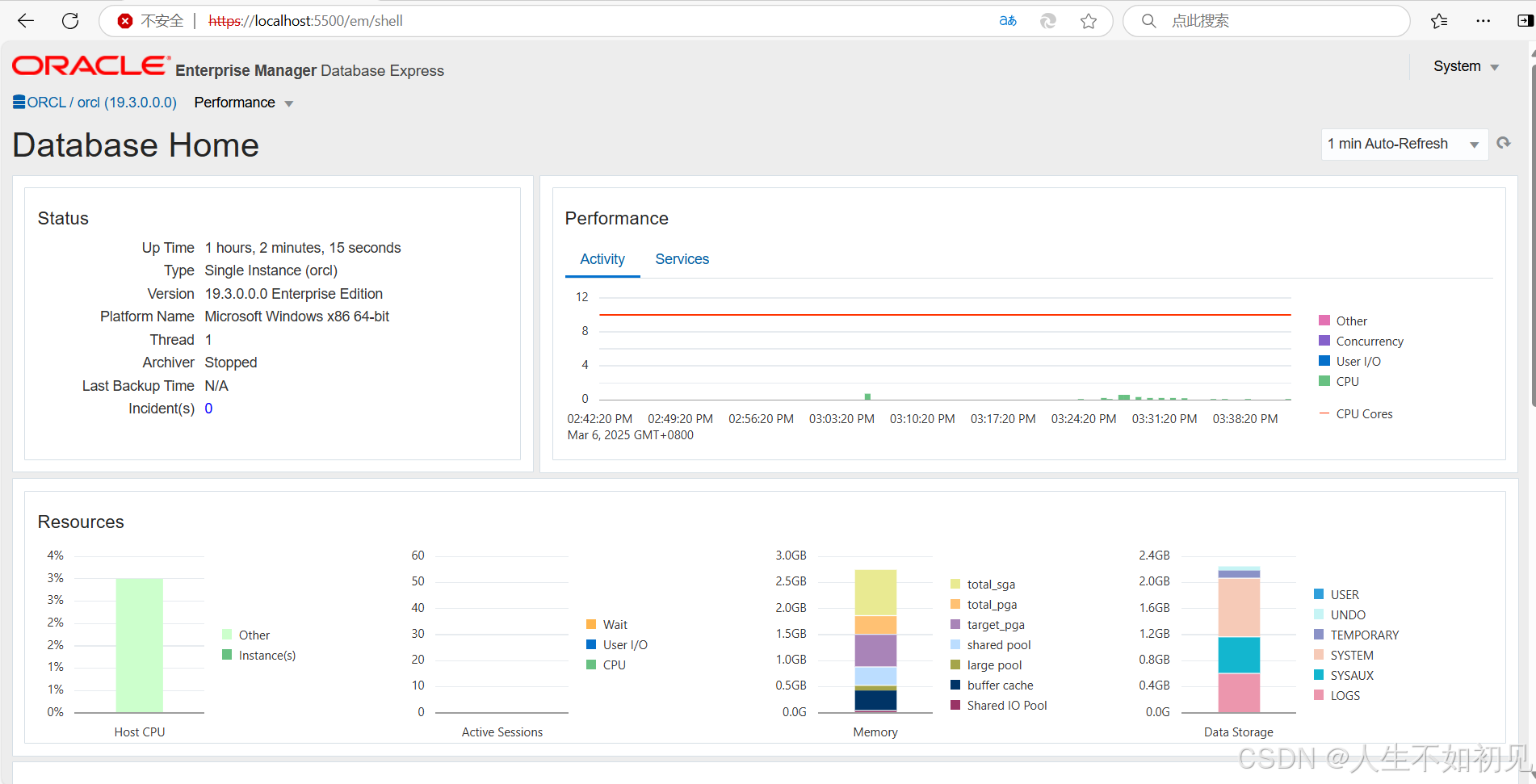
Oracle19c进入EM Express(Oracle企业管理器)详细步骤
以下是使用Oracle 19c进入Oracle Enterprise Manager Database Express(EM Express)的详细步骤: ### **步骤 1:确认EM Express配置状态** 1. **登录数据库服务器** 使用Oracle用户或管理员权限账户登录操作系统。 2. **查看EM…...

游戏引擎学习第140天
回顾并为今天的内容做准备 目前代码的进展到了声音混音的部分。昨天我详细解释了声音的处理方式,声音在技术上是一个非常特别的存在,但在游戏中进行声音混音的需求其实相对简单明了,所以今天的任务应该不会太具挑战性。 今天我们会编写一个…...

C++--迭代器(iterator)介绍---主要介绍vector和string中的迭代器
目录 一、迭代器(iterator)的定义 二、迭代器的类别 三、使用迭代器 3.1 迭代器运算符 3.2 迭代器的简单应用:使用迭代器将string对象的第一个字母改为大写 3.3 将迭代器从一个元素移动到另外一个元素 3.4 迭代器运算 3.5 迭代器的复…...
RuleOS:区块链开发的“新引擎”,点燃Web3创新之火
RuleOS:区块链开发的“新引擎”,点燃Web3创新之火 在区块链技术的浪潮中,RuleOS宛如一台强劲的“新引擎”,为个人和企业开发去中心化应用(DApp)注入了前所未有的动力。它以独特的设计理念和强大的功能特性&…...
机器学习之强化学习
引言 在人工智能的众多分支中,强化学习(Reinforcement Learning, RL) 因其独特的学习范式而备受关注。与依赖标注数据的监督学习或探索数据结构的无监督学习不同,强化学习的核心是智能体(Agent)通过与环境…...
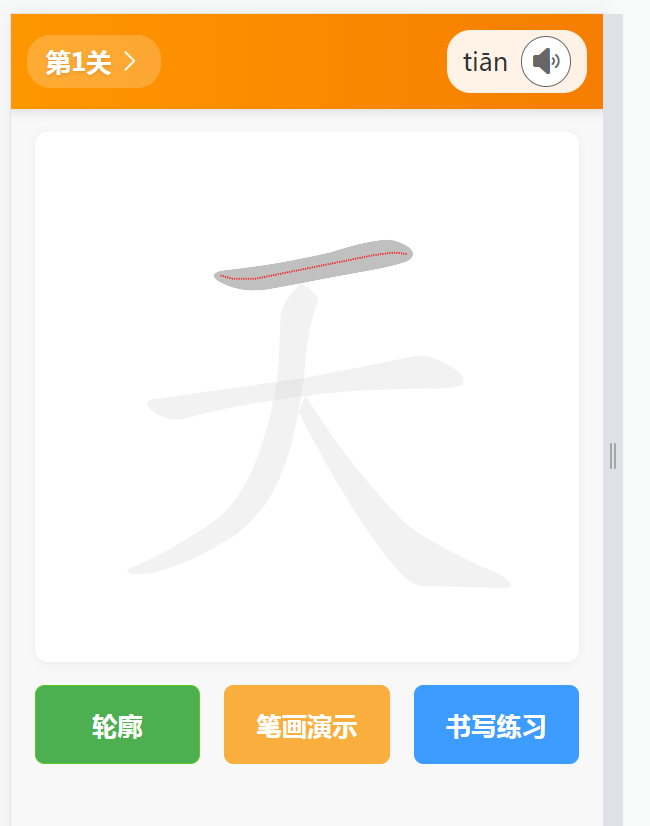
基于 uni-app 和 Vue3 开发的汉字书写练习应用
基于 uni-app 和 Vue3 开发的汉字书写练习应用 前言 本文介绍了如何使用 uni-app Vue3 uview-plus 开发一个汉字书写练习应用。该应用支持笔画演示、书写练习、进度保存等功能,可以帮助用户学习汉字书写。 在线演示 演示地址: http://demo.xiyueta.com/case/w…...

每天五分钟深度学习PyTorch:向更深的卷积神经网络挑战的ResNet
本文重点 ResNet大名鼎鼎,它是由何恺明团队设计的,它获取了2015年ImageNet冠军,它很好的解决了当神经网络层数过多出现的难以训练的问题,它创造性的设计了跳跃连接的方式,使得卷积神经网络的层数出现了大幅度提升,设置可以达到上千层,可以说resnet对于网络模型的设计具…...
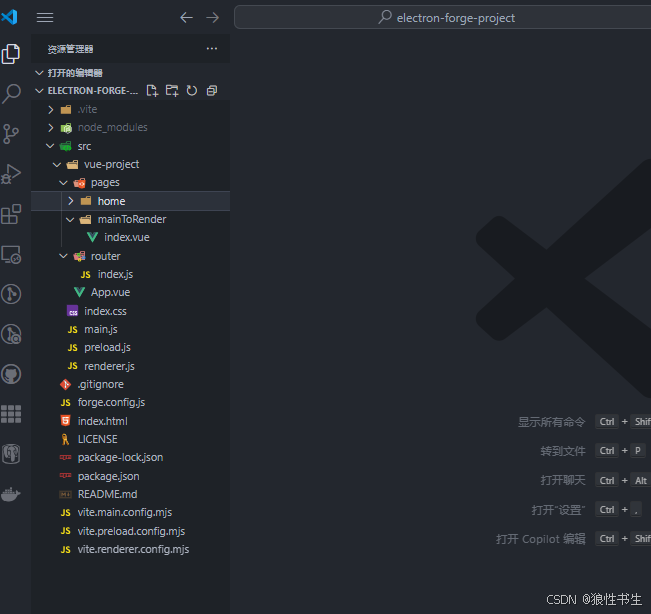
electron + vue3 + vite 主进程到渲染进程的单向通信
用示例讲解下主进程到渲染进程的单向通信 初始版本项目结构可参考项目:https://github.com/ylpxzx/electron-forge-project/tree/init_project 主进程到渲染进程(单向) 以Electron官方文档给出的”主进程主动触发动作,发送内容给渲…...

《白帽子讲 Web 安全》之身份认证
目录 引言 一、概述 二、密码安全性 三、认证方式 (一)HTTP 认证 (二)表单登录 (三)客户端证书 (四)一次性密码(OTP) (五)多因…...

postgrel
首先按照惯例,肯定是需要对PostgreSQL数据库进行一系列信息收集的,常用的命令有以下这些:-- 版本信息select version();show server_version;select pg_read_file(PG_VERSION, 0, 200);-- 数字版本信息包括小版号SHOW server_version_num;SEL…...
)
Java基础——java8+新特性——方法引用(::)
1. 什么是方法引用? 定义:Java 8 引入的语法糖,用于 简化 Lambda 表达式,直接引用已有的方法。 符号:使用 :: 双冒号操作符。 本质:将方法作为函数式接口的实例传。 2. 方法引用的四种类型 类型 语法 …...
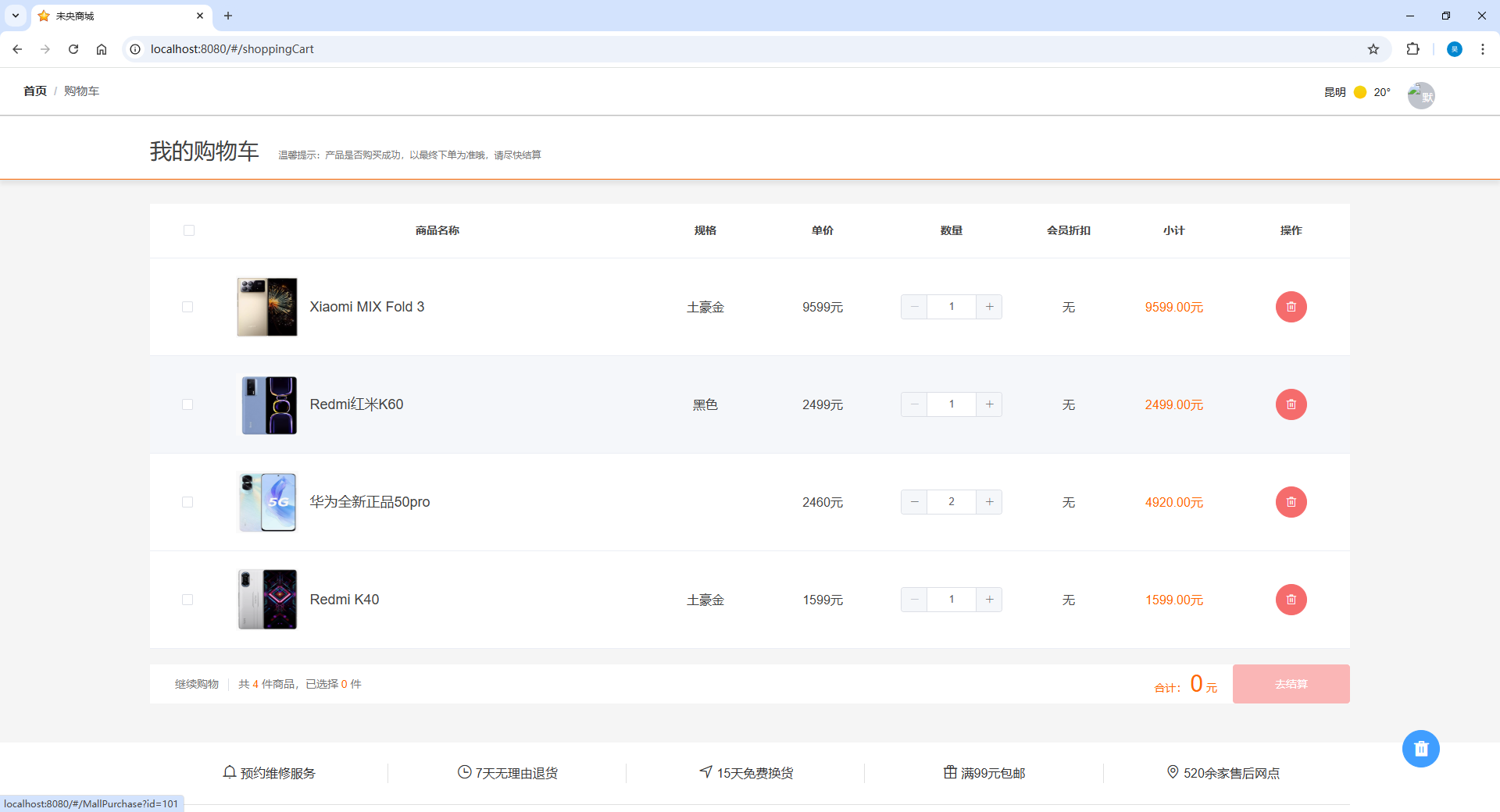
基于SpringBoot的商城管理系统(源码+部署教程)
运行环境 数据库:MySql 编译器:Intellij IDEA 前端运行环境:node.js v12.13.0 JAVA版本:JDK 1.8 主要功能 基于Springboot的商城管理系统包含管理端和用户端两个部分,主要功能有: 管理端 首页商品列…...
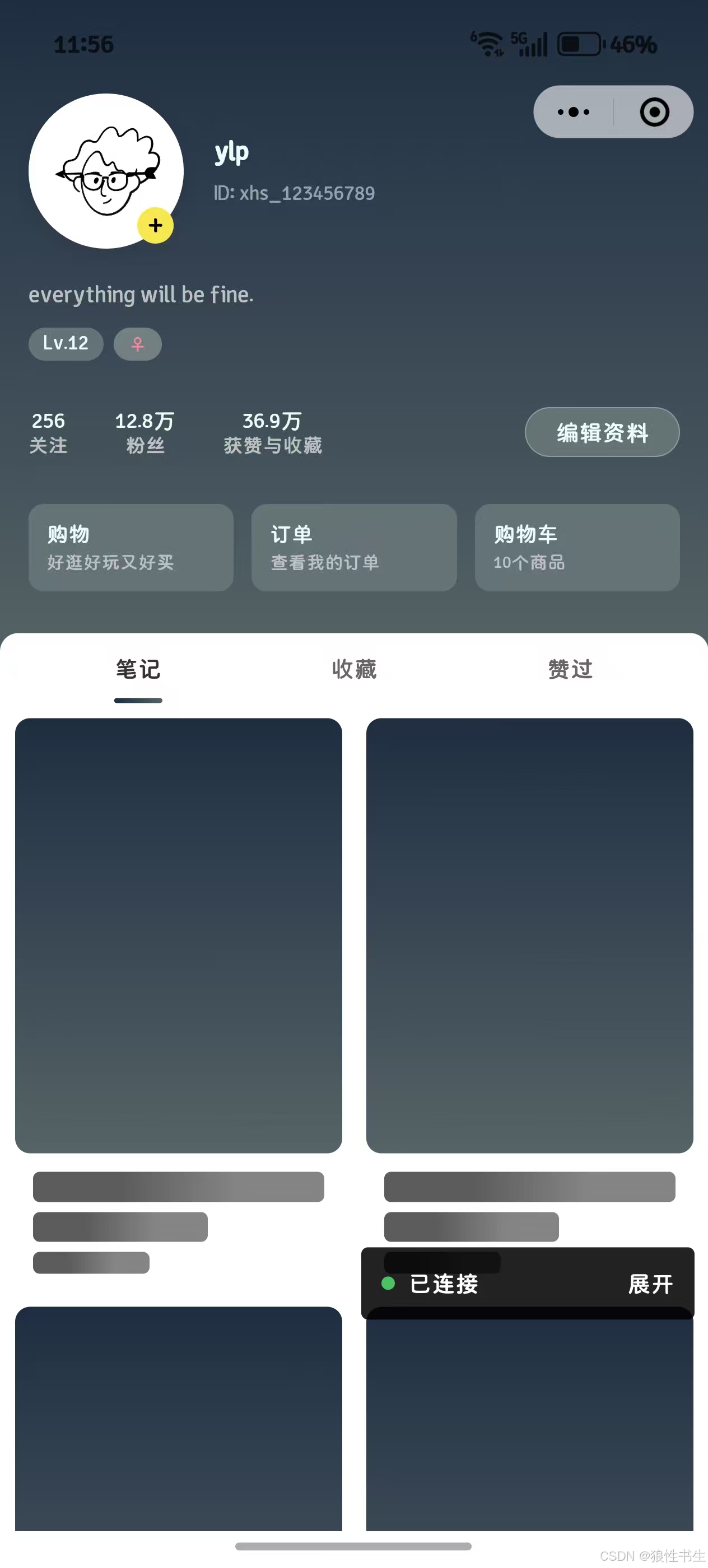
uniapp实现的个人中心页面(仿小红书)
采用 uniapp 实现的一款仿小红书个人中心页面模板,支持vue2、vue3, 同时适配H5、小程序等多端多应用。 简约美观大方 可到插件市场下载尝试: https://ext.dcloud.net.cn/plugin?id22516 示例...
)
K8s面试题总结(十一)
1.如何优化docker镜像的大小? 使用多阶段构建(multi-stage build)选择更小的基础镜像(如alpine)减少镜像层数,合并RUN命令 2.请解释Docker中的网络模式(如bridge,host,none) Bridgeÿ…...

量子金融强化学习:FinRL-Library实现AI量化交易的终极指南
量子金融强化学习:FinRL-Library实现AI量化交易的终极指南 【免费下载链接】FinRL FinRL: Financial Reinforcement Learning. 🔥 项目地址: https://gitcode.com/gh_mirrors/fi/FinRL-Library FinRL-Library作为金融强化学习领域的开源框架&…...

Cursor Rules:为AI编程时代量身定制的代码规范集实战指南
1. 项目概述:Cursor Rules,一个为AI编程时代量身定制的代码规范集如果你和我一样,是Cursor编辑器的重度用户,那你一定体验过它那令人惊叹的AI辅助编程能力。它能帮你生成代码、重构函数、甚至解释复杂的逻辑。但不知道你有没有遇到…...
)
避坑!Altium Designer 21.6 这几个Preference设置千万别乱动(附最佳实践)
Altium Designer 21.6 关键Preference设置避坑指南与高效配置策略 在电子设计自动化(EDA)领域,Altium Designer作为行业标杆工具,其强大的功能背后隐藏着诸多可能影响工作效率的"设置陷阱"。本文将从实际工程经验出发&…...

NCE外汇:平台稳定性与用户体验的全面观察
金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。NCE外汇经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的解读,呈现一个具有结构感的平台画像…...

golang如何处理PostgreSQL JSONB字段_golang PostgreSQL JSONB字段处理方法
PostgreSQL的jsonb字段在Go中需用json.RawMessage或自定义struct接收,不可直接scan到string或sql.NullString;写入NULL须用nil指针,查询时应避免SELECT 配合[]interface{}。PostgreSQL 的 jsonb 字段在 Go 中不能直接 scan 到 stringPostgreS…...

AI编程助手技能化:开源agent-skills项目实战指南
1. 项目概述:为AI编程助手注入“专业技能包” 如果你和我一样,日常重度依赖 Claude Code、Cursor 这类 AI 编程助手来辅助开发和研究,那你肯定遇到过这样的场景:想让 AI 帮你深入理解一篇复杂的数学论文,或者验证一个…...

AI系统行为治理:构建确定性护栏与运行时安全控制
1. 项目概述:为AI系统构建确定性的行为护栏如果你正在构建一个会“动手”的AI应用——无论是能帮你写代码的智能助手,还是能操作数据库的自动化流程,甚至是部署在物理设备上的机器人——那么你迟早会面临一个核心问题:如何确保它只…...

电动汽车充电站控制系统的Intel处理器实践与优化
1. 电动汽车充电站的技术架构解析电动汽车充电站作为新型能源基础设施的核心节点,其技术实现远比传统加油站复杂。一个完整的充电站系统通常包含三个层级:电力转换模块(AC/DC)、控制管理系统(CMS)和云端服务…...

27岁裸辞转网安:从传统行业到网安,我踩通了这条路
27 岁女生从传统行业裸辞转网络安全,3 个月拿到大厂 offer:这行真的没你想的那么难 后台经常收到私信,问我一个做了 4 年传统行业(之前是线下品牌运营)的女生,为什么突然 “跨界” 转做网络安全࿱…...

从TTP223到JL523:低成本电容触摸按钮的选型与实战
1. 电容触摸按钮入门:从原理到选型 第一次接触电容触摸按钮是在五年前的一个智能台灯项目上。当时为了给台灯添加一个酷炫的触摸开关,我试遍了市面上各种方案,最终锁定了TTP223这颗经典芯片。没想到几年后,国产的JL523给了我更大的…...