深度学习模型组件之优化器—Lookahead:通过“快慢”两组优化器协同工作,提升训练稳定性
深度学习模型组件之优化器—Lookahead:通过“快/慢”两组优化器协同工作,提升训练稳定性
文章目录
- 深度学习模型组件之优化器—Lookahead:通过“快/慢”两组优化器协同工作,提升训练稳定性
- 1. Lookahead优化器的背景
- 2. Lookahead优化器的原理
- 3. Lookahead优化器的优缺点
- 4. Lookahead优化器的代码实现
- 5. 论文实验结果
- 6.总结
在深度学习模型的训练过程中,优化算法的选择对模型的性能和收敛速度起着至关重要的作用。传统优化器如随机梯度下降(
SGD)和
Adam在许多场景中表现良好,但它们也存在一些局限性,如可能陷入局部最优或收敛不稳定。为了解决这些问题,研究者提出了
Lookahead优化器,它通过“快/慢”两组优化器的协同工作,提升了训练的稳定性和效率。
参考论文链接:Lookahead Optimizer: k steps forward, 1 step back
1. Lookahead优化器的背景
传统的优化算法在更新模型参数时,通常直接根据当前的梯度信息进行调整。然而,这种方法可能导致模型在训练过程中出现震荡或过拟合等问题。Lookahead优化器的提出,旨在通过引入一种新的更新机制,来改善这些问题。
2. Lookahead优化器的原理
Lookahead优化器的核心思想是同时维护两组权重:快速权重(fast weights)和慢速权重(slow weights)。其中,快速权重通过常规的优化器(如SGD或Adam)进行频繁更新,而慢速权重则在每经过固定次数的快速更新后,根据快速权重的状态进行一次更新。
具体而言,Lookahead优化器的工作流程如下:
-
初始化:设定初始的慢速权重(
slow weights)θs和快速权重(fast weights)θf,并选择基础优化器(如SGD或Adam)。 -
快速权重更新:使用基础优化器对快速权重
θf进行k次更新。 -
慢速权重更新:在每进行
k次快速更新后,按照以下公式更新慢速权重:
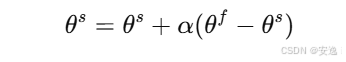
其中,
α为更新系数,控制慢速权重向快速权重靠近的程度。 -
同步权重:将更新后的慢速权重赋值给快速权重,即:
θf=θs,然后重复上述过程。
通过上述步骤,Lookahead优化器在训练过程中引入了一个“前瞻”机制,使得模型在参数空间中进行更稳定和高效的探索。
正如论文中所述:
“Lookahead improves the learning stability and lowers the variance of the stochastic gradients, leading to better generalization performance.”
(译:Lookahead提高了学习的稳定性,降低了随机梯度的方差,从而带来了更好的泛化性能。)
3. Lookahead优化器的优缺点
优点:
- 提高稳定性:通过慢速权重的引导,减少了训练过程中的震荡,使模型更稳定地收敛。
- 增强泛化能力:降低了过拟合的风险,提高了模型在未见数据上的表现。
- 兼容性强:Lookahead可以与各种基础优化器结合,如
SGD、Adam等,灵活性高。
缺点:
- 额外的计算开销:维护两组权重可能增加一定的内存和计算成本。
- 超参数选择:需要设定更新步数
k和更新系数α等超参数,可能需要根据具体任务进行调节。
4. Lookahead优化器的代码实现
以下是在PyTorch中实现Lookahead优化器的示例代码:
import torch
from torch.optim import Optimizerclass Lookahead(Optimizer):def __init__(self, base_optimizer, k=5, alpha=0.5):if not 0.0 <= alpha <= 1.0:raise ValueError(f'Invalid alpha: {alpha}')if not 1 <= k:raise ValueError(f'Invalid k: {k}')self.base_optimizer = base_optimizerself.k = kself.alpha = alphaself.state = {}# 初始化慢速权重for group in base_optimizer.param_groups:for p in group['params']:if p.requires_grad:self.state[p] = {'slow_param': p.data.clone()}def step(self):# 执行基础优化器的更新loss = self.base_optimizer.step()# 计数基础优化器的步数if not hasattr(self, 'step_counter'):self.step_counter = 0self.step_counter += 1# 每进行 k 次基础优化器的更新,更新慢速权重if self.step_counter % self.k == 0:for group in self.base_optimizer.param_groups:for p in group['params']:if p.requires_grad:slow_param = self.state[p]['slow_param']fast_param = p.data# 更新慢速权重slow_param += self.alpha * (fast_param - slow_param)# 将慢速权重赋值给快速权重p.data = slow_param.clone()return loss# 使用示例
model = torch.nn.Linear(10, 2)
base_optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
optimizer = Lookahead(base_optimizer, k=5, alpha=0.5)# 训练循环
for data, target in dataloader:optimizer.zero_grad()output = model(data)loss = loss_function(output, target)loss.backward()optimizer.step()
5. 论文实验结果
在 Michael R. Zhang 等人(2019)的实验中,Lookahead 在多个基准数据集(CIFAR-10、ImageNet、LSTM 任务)上的表现优于传统优化器,如 Adam 和 SGD。他们指出:
“Lookahead consistently improves both convergence speed and final generalization performance.”
——Michael R. Zhang et al.(2019)
以下是实验对比:
| 优化器 | CIFAR-10 Test Accuracy (%) | ImageNet Top-1 Accuracy (%) |
|---|---|---|
| SGD | 93.4 | 76.2 |
| Adam | 92.5 | 74.8 |
| Lookahead | 94.2 | 77.1 |
从表格中可以看出,Lookahead 在多个任务上提升了最终的泛化性能,并加快了收敛速度。
6.总结
| 优化器 | 主要特点 | 收敛速度 | 训练稳定性 | 超参数调节 |
|---|---|---|---|---|
| SGD | 使用固定学习率,更新方向基于当前梯度。 | 较慢 | 一般 | 需要精心调节 |
| Momentum | 在SGD基础上引入动量项,考虑历史梯度信息,加速收敛。 | 较快 | 较好 | 需要调节动量系数 |
| Adam | 结合了动量和自适应学习率,利用一阶和二阶矩估计调整学习率。 | 较快 | 一般 | 需要调节学习率和β参数 |
| NAdam | 在Adam基础上引入Nesterov加速梯度,进一步提高梯度估计精度。 | 较快 | 较好 | 需要调节学习率和β参数 |
| RAdam | 采用自适应学习率和Rectified Adam策略,旨在提高收敛性和稳定性。 | 较快 | 较好 | 需要调节学习率和β参数 |
| Lookahead | 通过维护慢权重和快权重,提升训练稳定性和收敛速度;可与任何基础优化器结合使用。 | 较快 | 较好 | 减少超参数调节需求 |
Lookahead与NAdam的比较
以下表格总结了Lookahead和NAdam优化器的主要特点:
| 优化器 | 主要特点 |
|---|---|
| Lookahead | 通过维护慢权重和快权重,提升训练稳定性和收敛速度;可与任何基础优化器结合使用。 |
| NAdam | 结合了Adam和Nesterov加速梯度的优点,自适应学习率并考虑动量项,旨在提供更精确的梯度估计。 |
需要注意的是,Lookahead和NAdam并非相互排斥的优化器。在实践中,可以将Lookahead与NAdam结合使用,以进一步提升模型的训练效果。
相关文章:
深度学习模型组件之优化器—Lookahead:通过“快慢”两组优化器协同工作,提升训练稳定性
深度学习模型组件之优化器—Lookahead:通过“快/慢”两组优化器协同工作,提升训练稳定性 文章目录 深度学习模型组件之优化器—Lookahead:通过“快/慢”两组优化器协同工作,提升训练稳定性1. Lookahead优化器的背景2. Lookahead优…...
Namespace)
K8s 1.27.1 实战系列(五)Namespace
Kubernetes 1.27.1 中的 Namespace(命名空间)是集群中实现多租户资源隔离的核心机制。以下从功能、操作、配置及实践角度进行详细解析: 一、核心功能与特性 1、资源隔离 Namespace 将集群资源划分为逻辑组,实现 Pod、Service、Deployment 等资源的虚拟隔离。例如,…...

Spring Boot整合ArangoDB教程
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、环境准备 JDK 17Maven 3.8Spring Boot 3.2ArangoDB 3.11(本地安装或Docker运行) Docker启动ArangoDB docker run -d --name ar…...

虚幻基础:动画层接口
文章目录 动画层:动画图表中的函数接口:名字,没有实现。动画层接口:由动画蓝图实现1.动画层可直接调用实现功能2.动画层接口必须安装3.动画层默认使用本身实现4.动画层也可使用其他动画蓝图实现,但必须在角色蓝图中关联…...

从 GitHub 批量下载项目各版本的方法
一、脚本功能概述 这个 Python 脚本的主要功能是从 GitHub 上下载指定项目的各个发布版本的压缩包(.zip 和 .tar.gz 格式)。用户需要提供两个参数:一个是包含项目信息的 CSV 文件,另一个是用于保存下载版本信息的 CSV 文件。脚本…...

一、对lora_sx1278v1.2模块通信记录梳理
一、通信测试: 注意: 1、检查供电是否满足。 2、检测引脚是否松动或虚焊。 3、检测触发是否能触发。 引脚作用: SPI:通信(仅作一次初始化,初始化后会进行模块通信返回测试,返回值和预定值相否即…...

Java在word中动态增加表格行并写入数据
SpringBoot项目中在word中动态增加表格行并写入数据,不废话,直接上配置和代码: 模板内容如下图所示: 模板是一个空word表格即可,模板放在resources下的自定义目录下,如下图示例。 实体类定义如下: @Data @AllArgsConstructor @NoArgsConstructor public class Person …...

[通讯协议]232通信
RS-232 简介 RS-232是一种广泛应用的串行通信接口标准,使用的协议就是串口协议。 通信能力 单端信号传输:信号以地线为参考,逻辑“1”为-3V至-15V,逻辑“0”为3V至15V。点对点通信:仅支持两个设备之间的通信&#x…...

Refreshtoken 前端 安全 前端安全方面
网络安全 前端不需要过硬的网络安全方面的知识,但是能够了解大多数的网络安全,并且可以进行简单的防御前两三个是需要的 介绍一下常见的安全问题,解决方式,和小的Demo,希望大家喜欢 网络安全汇总 XSSCSRF点击劫持SQL注入OS注入请求劫持DDOS 在我看来,前端可以了解并且防御前…...

EasyRTC嵌入式音视频通话SDK:基于ICE与STUN/TURN的实时音视频通信解决方案
在当今数字化时代,实时音视频通信技术已成为人们生活和工作中不可或缺的一部分。无论是家庭中的远程看护、办公场景中的远程协作,还是工业领域的远程巡检和智能设备的互联互通,高效、稳定的通信技术都是实现这些功能的核心。 EasyRTC嵌入式音…...

AI终章.展望未来2026-2030年预测与DeepSeek的角色
人工智能(AI)近年来发展迅速,正在改变行业、商业模式以及我们与技术互动的方式。展望2026-2030年,预计在多模态AI、自主代理和自动化驱动的新职业创造方面将出现革命性发展。本章将探讨这些趋势,以及DeepSeek将如何在这…...

PyTorch系列教程:编写高效模型训练流程
当使用PyTorch开发机器学习模型时,建立一个有效的训练循环是至关重要的。这个过程包括组织和执行对数据、参数和计算资源的操作序列。让我们深入了解关键组件,并演示如何构建一个精细的训练循环流程,有效地处理数据处理,向前和向后…...

【面试】Zookeeper
Zookeeper 1、ZooKeeper 介绍2、znode 节点里面的存储3、znode 节点上监听机制4、ZooKeeper 集群部署5、ZooKeeper 选举机制6、何为集群脑裂7、如何保证数据一致性8、讲一下 zk 分布式锁实现原理吧9、Eureka 与 Zk 有什么区别 1、ZooKeeper 介绍 ZooKeeper 的核心特性 高可用…...

电力系统中各参数的详细解释【智能电表】
一、核心电力参数 电压 (Voltage) 单位:伏特(V) 含义:电势差,推动电流流动的动力 类型:线电压(三相系统)、相电压,如220V(家用)或380Vÿ…...
)
前端系统测试(单元、集成、数据|性能|回归)
有关前端测试的面试题 系统测试 首先,功能测试部分。根据资料,单元测试是验证最小可测试单元的正确性,比如函数或组件。都提到了单元测试的重要性,强调其在开发早期发现问题,并通过自动化提高效率。需要整合我搜索到的资料中的观点,比如单元测试的方法(接口测试、路径覆…...

软件开发过程总揽
开发模型 传统开发模型 瀑布模型 #mermaid-svg-yDNBSwh3gDYETWou {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-yDNBSwh3gDYETWou .error-icon{fill:#552222;}#mermaid-svg-yDNBSwh3gDYETWou .error-text{fill:#…...

VBA第二十期 VBA最简单复制整张表格Cells的用法
前面讲过复制整张表格的方法,使用语句Workbooks("实例.xlsm").Sheets("表格1").Copy Workbooks(wjm).Sheets(1)实现,这里用我们熟悉的Cells属性也可以实现整表复制。实例如下: Sheets("全部").Activate Cells…...

Redis为什么要自定义序列化?如何实现自定义序列化器?
在 Redis中,通常会使用自定义序列化器,那么,Redis为什么需要自定义序列化器,该如何实现它? 1、为什么需要自定义序列化器? 整体来说,Redis需要自定义序列化器,主要有以下几个原因&…...

Matlab:矩阵运算篇——矩阵数学运算
目录 1.矩阵的加法运算 实例——验证加法法则 实例——矩阵求和 实例——矩阵求差 2.矩阵的乘法运算 1.数乘运算 2.乘运算 3.点乘运算 实例——矩阵乘法运算 3.矩阵的除法运算 1.左除运算 实例——验证矩阵的除法 2.右除运算 实例——矩阵的除法 ヾ( ̄…...

手写一个Tomcat
Tomcat 是一个广泛使用的开源 Java Servlet 容器,用于运行 Java Web 应用程序。虽然 Tomcat 本身功能强大且复杂,但通过手写一个简易版的 Tomcat,我们可以更好地理解其核心工作原理。本文将带你一步步实现一个简易版的 Tomcat,并深…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...