从 GitHub 批量下载项目各版本的方法
一、脚本功能概述
这个 Python 脚本的主要功能是从 GitHub 上下载指定项目的各个发布版本的压缩包(.zip 和 .tar.gz 格式)。用户需要提供两个参数:一个是包含项目信息的 CSV 文件,另一个是用于保存下载版本信息的 CSV 文件。脚本会遍历项目列表,访问每个项目的 tags 页面,下载所有可用的版本压缩包,并记录相关信息到指定的 CSV 文件中。
二、脚本使用说明
在运行脚本前,请确保你已经安装了 requests 和 beautifulsoup4 库。如果未安装,可以使用以下命令进行安装:
bash
pip install requests beautifulsoup4
运行脚本时,在命令行中输入以下格式的命令:
bash
python script.py project_list.csv save_info.csv
其中,script.py 是脚本文件名,project_list.csv 是包含项目信息的 CSV 文件,save_info.csv 是用于保存下载版本信息的 CSV 文件。
下面是完整的脚本。
import requests
from bs4 import BeautifulSoup
import os
import csv
import sys
import time
import random
from urllib.error import HTTPError
import signal
# 设置GitHub API的个人访问令牌
# 从这里获取:https://github.com/settings/tokens
access_token = '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'
# 分页参数
page = 1
num = 0
savelastfilename =""
lastfilename = ""
url_with_page = ""
fieldnames = ['项目名称', 'tags', '版本号', '压缩包名','是否有发布']
file = None
writer = None
proxies = {
"https1": "https://182.204.177.61:4331",
"https2": "https://140.255.150.253:4361",
"https3": "https://113.231.18.51:4334",
"https4": "https://116.7.192.240:43581",
"https5": "https://121.61.160.170:43311",
"https6": "https://124.231.69.245:43311",
"https7": "https://183.128.97.139:43251",
"https8": "https://124.94.188.113:43341",
"https9": "https://1.82.107.78:4389",
"https10": "https://1.82.107.49:4379",
}
headers = {
'User-Agent': 'Mozilla/5.0',
'Authorization': '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',
'Content-Type': 'text/html',
'Accept': 'application/json'
}
# 定义信号处理函数
def signal_handler(sig, frame):
print("\n收到了中断信号,程序退出!!!")
sys.exit(0)
# 注册信号处理函数
signal.signal(signal.SIGINT, signal_handler)
def get_html_url_with_tags(file_name):
html_urls = []
Name = ''
with open(file_name, 'r', newline='') as file:
reader = csv.DictReader(file)
for row in reader:
Name = row.get('Name')
html_url = row.get('HTML URL')
if html_url:
new_html_url = html_url + "/tags"
html_urls.append(new_html_url)
#print("Name="+ Name +" url=" + new_html_url)
return Name,html_urls
def download_file(url, save_path, timeout=20, max_retries=3):
retries = 0
while retries < max_retries:
try:
# 发送GET请求获取文件内容,设置超时时间
#@retry(tries=3, delay=2) # 重试3次,每次间隔2秒
#response = requests.get(url, proxies=proxies, headers=headers, timeout=15)
response = requests.get(url, proxies=proxies, timeout=15)
# 检查响应状态码
if response.status_code == 200:
# 写入文件
print(f"正在下载文件{save_path}...",end='')
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"...文件下载完成")
return True
else:
print(f"下载失败:状态码 {response.status_code}")
#print("下载失败:超过最大重试次数")
check_connection_error(response)
except requests.exceptions.Timeout:
print(f"请求超时,正在尝试重试...", end="")
except requests.exceptions.RequestException as e:
print(f"请求异常:{e}", end="")
retries += 1
print(f"重试次数:{retries}")
return False
def check_connection_error(response):
"""检查是否由于连接问题而无法访问 GitHub"""
if response.status_code == 200:
print("返回200!")
return True
if response.status_code == 403:
print("已达到 GitHub API 请求限制!")
return False
elif response.status_code == 400:
print("服务器无法理解请求!")
return False
elif response.status_code == 502:
print("远程服务器关闭了连接。")
return False
elif response.status_code == 404:
print("未找到请求的资源。")
return False
elif response.status_code == 407:
print("代理服务器需要身份验证!")
return False
elif response.status_code == 406:
print("客户端请求问题,可能是代理失效,建议更换代理IP列表")
return False
elif response.status_code == 429:
print("请求过多,请稍后重试。")
return False
elif response.status_code == 504:
print("网关超时,等等并重试或更换其它代理!")
return False
elif response.status_code >= 500:
print("远程服务器内部错误。")
return False
else:
try:
print("远程服务器返回未知错误,正在尝试获取更多详细信息...")
response.raise_for_status() # 如果请求失败,这将抛出一个 HTTPError 异常
print("获取详细信息失败,当前状态码为:", response.status_code)
return False # 如果无法获取详细信息,则返回 False,表示请求失败
except HTTPError as e:
print("发生了 HTTPError 异常:", e)
return False # 如果抛出 HTTPError 异常,则返回 False,表示请求失败
except ConnectionError as ce:
print("连接被远程服务器关闭,没有返回任何响应。")
return False # 如果捕获到 ConnectionError 异常,则返回 False,表示请求失败
except requests.exceptions.Timeout:
print("连接超时:可能是由于网络问题导致的连接失败")
return False
except requests.exceptions.ConnectionError:
print("连接错误:无法连接到服务器")
return False
except requests.exceptions.RequestException as e:
print("请求异常,最可能是代理问题:", e)
return False
def wait_and_retry(wait_time=30):
"""等待一段时间后重试请求"""
print(f"等待 {wait_time} 秒后重试...")
time.sleep(wait_time)
def get_github_rate_limit(headers):
url = "https://api.github.com/rate_limit"
headers = {
'User-Agent': 'Mozilla/5.0',
'Authorization': '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',
'Content-Type': 'text/html',
'Accept': 'application/json'
}
#response = requests.get(url, proxies=proxies, headers=headers)
response = requests.get(url, proxies=proxies)
data = response.json()
limit = data["rate"]["limit"]
remaining = data["rate"]["remaining"]
reset_time = data["rate"]["reset"]
print(f"限速检查完成...")
return limit, remaining, reset_time
def update_ifcheck_value(file_name, Name):
"""打开 CSV 文件,将指定 Name 对应的行的 ifcheck 字段值修改为 1"""
rows = []
with open(file_name, 'r', newline='') as file:
reader = csv.DictReader(file)
fieldnames = reader.fieldnames # 获取表头字段名
for row in reader:
if row.get('Name') == Name:
row['ifcheck'] = '1' # 将 ifcheck 字段值修改为 1
rows.append(row)
# 写回 CSV 文件
with open(file_name, 'w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(rows)
def renamefile(name,filename):
current_path = os.getcwd()
old_name = filename
# 设置新的文件名
new_name = name + "_" + filename
# 构建新文件的完整路径
new_path = os.path.join(current_path, new_name)
# 构建旧文件的完整路径
old_path = os.path.join(current_path, old_name)
# 重命名文件
if os.path.isfile(new_path):
return False
else:
os.rename(old_path, new_path)
return True
def analyze_download_links(Name, url):
global lastfilename,num,headers
global writer,file
while True:
#判断是否为多页
if num == 20:
url_with_page = url + "?after=" + lastfilename
num = 0
else:
url_with_page = url
print("访问的url=" + url_with_page)
#判断是否被限速,被限速的话,等待10~20秒
limit, remaining, reset_time=get_github_rate_limit(headers)
if remaining == 0:
count = 1
time.sleep(random.randint(10, 20))
print("剩余请求次数为 0 了,现在更新header" )
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Authorization': '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',
'Content-Type': 'text/html',
'Accept': 'application/json'
}
#通过一个代理列表中中的一个代理获取当前url项目的tags页面
#response = requests.get(url_with_page,proxies=proxies, headers=headers)
#直接获取当前url项目的tags页面
response = requests.get(url_with_page,proxies=proxies)
#进行容错判断,如果链接错误,则等一会重新链接
print("进行服务器返回检查中..." )
if False == check_connection_error(response):
wait_and_retry()
print("服务器返回错误,请稍等一会..." )
#time.sleep(random.randint(10, 20))
headers = {
'User-Agent': 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Authorization': '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',
'Content-Type': 'text/html',
'Accept': 'application/json'
}
continue
#如果没有响应,则10~20秒,更换header重新链接
if response is None:
# Exit loop if HTTP Error 422
print("GitHub 未响应")
time.sleep(random.randint(10, 20))
headers = {
'User-Agent': 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Authorization': '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',
'Content-Type': 'text/html',
'Accept': 'application/json'
}
continue
#如果返回200,说明请求正确,处理返回数据
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
#如果项目tags中没有版本,则返回
if "There aren’t any releases here" in response.text:
with open(save_file_name, 'a', newline='') as file:
writer = csv.writer(file)
writer.writerow([Name, url, '', '','0'])
print("当前项目tags下无发布版本")
break
#H抓取tags页面中所有的下载链接
download_links = soup.find_all('a', href=lambda href: href and (href.endswith('.zip') or href.endswith('.tar.gz')))
#print("所有链接:" + download_links)
if len(download_links) == 0:
print("当前项目tags下无发布版本")
break
#分析每一个链接
for link in download_links:
#print("Found download link:", link['href'])
file_name = os.path.basename(link['href']) #file_name是压缩包名字
if os.path.isfile(file_name):
print("该项目版本已经下载,略过!")
continue
if download_file("https://github.com/" + link['href'], file_name): #拼接为完整下载链接后下载文件
#print(f"确认文件已下载完成")
renamefile(Name,file_name)
lastfilename, _ = os.path.splitext(file_name) #lastfilename 是去掉.zip或.gz后的文件名
if lastfilename.endswith('.tar'): #如果后面还有tar后缀
lastfilename, _ = os.path.splitext(lastfilename) #lastfilename 文件名称,实际上版本号
#项目名称,tags url、版本号和压缩包文件名,是否找到发布包写入文件。1表示有发布包
with open(save_file_name, 'a', newline='') as file:
writer = csv.writer(file)
writer.writerow([Name, url, lastfilename, file_name,'1'])
num = num + 1 #当前下载文件数加1
else:
headers = {
'User-Agent': 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Authorization': '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',
'Content-Type': 'text/html',
'Accept': 'application/json'
}
print(f"更换header重新下载...")
download_file("https://github.com/" + link['href'], file_name) #拼接为完整下载链接后下载文件
if num == 20:
continue
#如果有多页,每页返回10个版本,一共20个压缩包,如果不到20表示版本页面不到一页,
if num < 20:
break
#user_input = input("请输入任意内容,按 Enter 键结束程序:")
#if user_input:
# print("用户输入了ctrl+C:", user_input)
#
#break
else:
print(f'页面返回不是200时,返回状态码是: {response.status_code}')
continue
# 测试程序
if __name__ == "__main__":
if len(sys.argv) != 3:
print("请提供两个参数:第一个参数是项目列表;第二个需要创新的文件用来保存该项目版本信息")
sys.exit(1)
file_name = sys.argv[1]
if not file_name.endswith('.csv'):
print("Please provide a CSV file.")
sys.exit(1)
if os.path.exists(file_name):
print("打开文件,开始分析...")
else:
print("输入文件不存在,请确认")
sys.exit(1)
save_file_name = sys.argv[2]
if not save_file_name.endswith('.csv'):
print("Please provide a CSV save file.")
sys.exit(1)
#如果保存文件不存在,则创建文件,添加表头
if os.path.exists(save_file_name):
print("保存文件已经存在,会在文件后面追加数据")
else:
with open(save_file_name, 'a', newline='') as file:
writer = csv.writer(file)
writer.writerow(fieldnames)
#Name,html_urls = get_html_url_with_tags(file_name)
#for url in html_urls:
Name = ''
with open(file_name, 'r', newline='') as file:
reader = csv.DictReader(file)
for row in reader:
ifcheck = row.get('ifcheck')
Name = row.get('Name')
html_url = row.get('HTML URL')
if ifcheck == '0' and html_url:
new_html_url = html_url + "/tags"
analyze_download_links(Name,new_html_url)
update_ifcheck_value(file_name, Name)
#user_input = input("您的输入中断了下载,按Ctrl+C键结束程序,其它键继续下载")
#if user_input:
# print("用户输入了:", user_input)
# break
print("检测完成!")
————————————————————————————————
相关文章:

从 GitHub 批量下载项目各版本的方法
一、脚本功能概述 这个 Python 脚本的主要功能是从 GitHub 上下载指定项目的各个发布版本的压缩包(.zip 和 .tar.gz 格式)。用户需要提供两个参数:一个是包含项目信息的 CSV 文件,另一个是用于保存下载版本信息的 CSV 文件。脚本…...

一、对lora_sx1278v1.2模块通信记录梳理
一、通信测试: 注意: 1、检查供电是否满足。 2、检测引脚是否松动或虚焊。 3、检测触发是否能触发。 引脚作用: SPI:通信(仅作一次初始化,初始化后会进行模块通信返回测试,返回值和预定值相否即…...

Java在word中动态增加表格行并写入数据
SpringBoot项目中在word中动态增加表格行并写入数据,不废话,直接上配置和代码: 模板内容如下图所示: 模板是一个空word表格即可,模板放在resources下的自定义目录下,如下图示例。 实体类定义如下: @Data @AllArgsConstructor @NoArgsConstructor public class Person …...

[通讯协议]232通信
RS-232 简介 RS-232是一种广泛应用的串行通信接口标准,使用的协议就是串口协议。 通信能力 单端信号传输:信号以地线为参考,逻辑“1”为-3V至-15V,逻辑“0”为3V至15V。点对点通信:仅支持两个设备之间的通信&#x…...

Refreshtoken 前端 安全 前端安全方面
网络安全 前端不需要过硬的网络安全方面的知识,但是能够了解大多数的网络安全,并且可以进行简单的防御前两三个是需要的 介绍一下常见的安全问题,解决方式,和小的Demo,希望大家喜欢 网络安全汇总 XSSCSRF点击劫持SQL注入OS注入请求劫持DDOS 在我看来,前端可以了解并且防御前…...

EasyRTC嵌入式音视频通话SDK:基于ICE与STUN/TURN的实时音视频通信解决方案
在当今数字化时代,实时音视频通信技术已成为人们生活和工作中不可或缺的一部分。无论是家庭中的远程看护、办公场景中的远程协作,还是工业领域的远程巡检和智能设备的互联互通,高效、稳定的通信技术都是实现这些功能的核心。 EasyRTC嵌入式音…...

AI终章.展望未来2026-2030年预测与DeepSeek的角色
人工智能(AI)近年来发展迅速,正在改变行业、商业模式以及我们与技术互动的方式。展望2026-2030年,预计在多模态AI、自主代理和自动化驱动的新职业创造方面将出现革命性发展。本章将探讨这些趋势,以及DeepSeek将如何在这…...

PyTorch系列教程:编写高效模型训练流程
当使用PyTorch开发机器学习模型时,建立一个有效的训练循环是至关重要的。这个过程包括组织和执行对数据、参数和计算资源的操作序列。让我们深入了解关键组件,并演示如何构建一个精细的训练循环流程,有效地处理数据处理,向前和向后…...

【面试】Zookeeper
Zookeeper 1、ZooKeeper 介绍2、znode 节点里面的存储3、znode 节点上监听机制4、ZooKeeper 集群部署5、ZooKeeper 选举机制6、何为集群脑裂7、如何保证数据一致性8、讲一下 zk 分布式锁实现原理吧9、Eureka 与 Zk 有什么区别 1、ZooKeeper 介绍 ZooKeeper 的核心特性 高可用…...

电力系统中各参数的详细解释【智能电表】
一、核心电力参数 电压 (Voltage) 单位:伏特(V) 含义:电势差,推动电流流动的动力 类型:线电压(三相系统)、相电压,如220V(家用)或380Vÿ…...
)
前端系统测试(单元、集成、数据|性能|回归)
有关前端测试的面试题 系统测试 首先,功能测试部分。根据资料,单元测试是验证最小可测试单元的正确性,比如函数或组件。都提到了单元测试的重要性,强调其在开发早期发现问题,并通过自动化提高效率。需要整合我搜索到的资料中的观点,比如单元测试的方法(接口测试、路径覆…...

软件开发过程总揽
开发模型 传统开发模型 瀑布模型 #mermaid-svg-yDNBSwh3gDYETWou {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-yDNBSwh3gDYETWou .error-icon{fill:#552222;}#mermaid-svg-yDNBSwh3gDYETWou .error-text{fill:#…...

VBA第二十期 VBA最简单复制整张表格Cells的用法
前面讲过复制整张表格的方法,使用语句Workbooks("实例.xlsm").Sheets("表格1").Copy Workbooks(wjm).Sheets(1)实现,这里用我们熟悉的Cells属性也可以实现整表复制。实例如下: Sheets("全部").Activate Cells…...

Redis为什么要自定义序列化?如何实现自定义序列化器?
在 Redis中,通常会使用自定义序列化器,那么,Redis为什么需要自定义序列化器,该如何实现它? 1、为什么需要自定义序列化器? 整体来说,Redis需要自定义序列化器,主要有以下几个原因&…...

Matlab:矩阵运算篇——矩阵数学运算
目录 1.矩阵的加法运算 实例——验证加法法则 实例——矩阵求和 实例——矩阵求差 2.矩阵的乘法运算 1.数乘运算 2.乘运算 3.点乘运算 实例——矩阵乘法运算 3.矩阵的除法运算 1.左除运算 实例——验证矩阵的除法 2.右除运算 实例——矩阵的除法 ヾ( ̄…...

手写一个Tomcat
Tomcat 是一个广泛使用的开源 Java Servlet 容器,用于运行 Java Web 应用程序。虽然 Tomcat 本身功能强大且复杂,但通过手写一个简易版的 Tomcat,我们可以更好地理解其核心工作原理。本文将带你一步步实现一个简易版的 Tomcat,并深…...

开发ai模型最佳的系统是Ubuntu还是linux?
在 AI/ML 开发中,Ubuntu 是更优选的 Linux 发行版,原因如下: 1. 开箱即用的 AI 工具链支持 Ubuntu 预装了主流的 AI 框架(如 TensorFlow、PyTorch)和依赖库,且通过 apt 包管理器可快速部署开发环境。 提…...

Scala 中生成一个RDD的方法
在 Scala 中,生成 RDD(弹性分布式数据集)的主要方法是通过 SparkContext(或 SparkSession)提供的 API。以下是生成 RDD 的常见方法: 1. 从本地集合创建 RDD 使用 parallelize 方法将本地集合(如…...
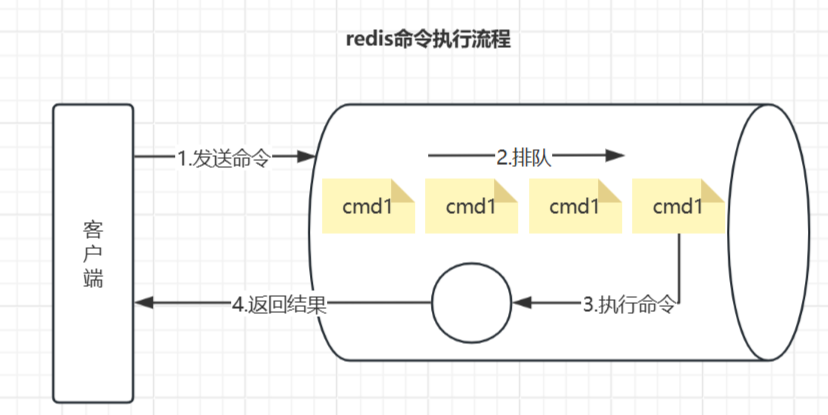
【redis】慢查询分析与优化
慢查询指在Redis中执行时间超过预设阈值的命令,其日志记录是排查性能瓶颈的核心工具。Redis采用单线程模型,任何耗时操作都可能阻塞后续请求,导致整体性能下降。 命令的执行流程 根据Redis的核心机制,命令执行流程可分为以下步骤…...

P8925 「GMOI R1-T2」Light 题解
P8925 「GMOI R1-T2」Light 让我们好好观察样例解释的这一张图: 左边第 1 1 1 个像到 O O O 点的距离 : L 2 2 L L\times22L L22L 右边第 1 1 1 个像到 O O O 点的距离 : R 2 2 R R\times22R R22R 左边第 2 2 2 个像到 O O O 点…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...