解锁DeepSpeek-R1大模型微调:从训练到部署,打造定制化AI会话系统
目录
1. 前言
2.大模型微调概念简述
2.1. 按学习范式分类
2.2. 按参数更新范围分类
2.3. 大模型微调框架简介
3. DeepSpeek R1大模型微调实战
3.1.LLaMA-Factory基础环境安装
3.1大模型下载
3.2. 大模型训练
3.3. 大模型部署
3.4. 微调大模型融合基于SpirngBoot+Vue2开发的AI会话系统
4.源码获取
5.结语
1. 前言
在如今快速发展的AI技术领域,越来越多的企业正在将AI应用于各个场景。然而,尽管大模型(如GPT、DeepSpeek等)在多个任务上已取得显著进展,但是普通的大模型在面对特定行业或任务时,往往会出现一个问题——AI幻觉。所谓AI幻觉,是指模型生成的内容不符合实际需求,甚至包含错误或无关的信息,这对于一些行业来说,可能带来不可接受的风险,尤其是在医疗、法律、金融等领域。
对于这些行业的企业而言,精准、高效地输出行业特定内容是他们对AI的核心需求。企业希望AI能够处理行业术语、应对特殊情境,并且确保内容的准确性。然而,单纯依赖大模型进行推理,往往无法达到这样的标准,因为大模型的训练是基于通用数据集,这些数据集通常并不包含行业领域的深度知识。因此,企业通常需要一个更加定制化、精细化的模型,而这正是大模型微调技术能够提供的解决方案。
大模型微调技术通过对预训练的大模型进行进一步训练,能够根据特定领域的需求进行优化。通过提供具有代表性的领域数据,尤其是精心标注的行业特定数据,微调后的模型能够学习这些领域的专有知识,从而有效避免AI幻觉的发生,并且提供更加准确、有价值的输出。
本文将从零开始教你一步步入门AI大模型微调技术(基于DeepSpeek R1大模型),最终实现基于私有化部署的微调大模型AI会话系统。感兴趣的朋友可以继续往下看看。
2.大模型微调概念简述
大模型微调是指在已有的预训练大模型基础上,通过特定任务或领域数据进行进一步训练,使模型能够更精准地处理特定任务。与传统的训练方法不同,微调充分利用已有的大模型,减少对大量数据的依赖,同时通过对模型进行小范围的调整,使其适应新的任务。大模型微调技术在多个领域中得到了广泛应用,如文本生成、分类任务、问答系统等。
微调的核心目标是使大模型根据特定任务需求进行优化,提升其在特定应用场景中的表现。为实现这一目标,微调方法主要包括以下两种分类方式:
- 按学习范式分类:根据模型学习方式的不同,微调方法可分为有监督微调、无监督微调和半监督微调等类型。
- 按参数更新范围分类:根据在微调过程中对模型参数更新范围的不同,方法可分为全量微调和部分微调等类型。
2.1. 按学习范式分类
有监督微调(Supervised Fine-Tuning,SFT)
有监督微调是最常见的微调方式,适用于任务明确且具有标注数据的情况。通过使用人工标注的高质量数据对,模型能够学习特定任务所需的知识,从而在指定任务上提供准确的输出。
SFT示例:
training_data = [{"input": "问题", "output": "标准答案"},# 人工标注的高质量数据对
]在有监督微调中,模型的目标是根据输入的“问题”生成一个“标准答案”。这个过程依赖于人工标注的数据,使模型能够更好地理解并生成符合实际需求的结果,有监督微调适用于需要特定答案的任务,如情感分析、文本分类、机器翻译、问答系统等。
无监督微调(Unsupervised Fine-Tuning)
无监督微调是一种不依赖人工标注的微调方式,主要利用大量未标注的文本数据进行训练。通过无监督学习,模型能够自动从原始数据中提取知识,尤其在没有标注数据或标注数据获取困难的情况下尤为有用。
无监督微调示例:
training_data = ["大量未标注文本...",# 无需人工标注的原始文本
]这种方式通常用于模型的预训练过程,模型通过对大规模文本进行训练,学习通用的语言表示能力。无监督微调可以增强模型的语法和语义理解能力,提升其在不同任务中的表现,无监督微调适用于自然语言建模、生成任务等场景,帮助模型理解文本的结构和语义关系。
半监督微调(Semi-Supervised Fine-Tuning)
半监督微调结合了有监督和无监督学习的优点,利用标注数据和未标注数据来训练模型。常用的方法包括将未标注数据通过某种方式生成伪标签,或利用自监督学习方法,使模型在标注数据较少时也能进行有效训练。
半监督微调示例:
training_data = [{"input": "问题", "output": "标准答案"}, # 高质量人工标注数据"大量未标注文本...", # 用于填充的未标注数据
]半监督微调适用于标注数据稀缺的场景,能够结合少量标注数据和大量未标注数据,进一步提升模型表现,这种方法在实际应用中尤其适用于标签获取困难或成本高昂的领域,如医疗、法律等行业。
2.2. 按参数更新范围分类
全量微调(Full Fine-Tuning)
全量微调是指在对预训练模型进行微调时,更新模型的所有参数。通过对特定领域数据的训练,模型的所有层都会根据新任务的数据进行调整。全量微调能够在模型中深度定制领域知识,最大程度地提升模型在目标任务中的效果。
全量微调的特点:
- 更新模型的所有参数。
- 适用于数据量较大且任务复杂的场景。
- 训练时间较长,需要大量计算资源。
全量微调适用于大规模数据集且任务复杂的场景,如文本生成、问答系统、情感分析等。它能够充分利用预训练模型进行深度学习,提供最优效果。
部分微调(Low-Rank Adaptation,LoRA)
部分微调是一种通过对预训练模型的部分参数进行微调的技术。LoRA的目标是减少微调过程中需要更新的参数数量,从而显著降低计算开销。通过低秩矩阵的方式,LoRA仅更新模型中的某些参数(如特定层的权重),使微调过程更加高效,特别适合计算资源有限的场景。
LoRA的特点:
- 只调整部分参数(如低秩矩阵分解)。
- 降低计算和内存开销。
- 适合快速微调,尤其在资源受限时。
LoRA非常适合在资源有限的情况下快速调整模型,尤其在需要快速部署且不需要全部模型调整的场景中非常有用。
在大模型微调过程中,有监督微调(SFT)与LoRA(Low-Rank Adaptation)相结合,能够充分发挥各自优势,提升模型在特定任务上的表现。具体而言,SFT通过在人工标注的数据上对模型进行微调,使其适应特定任务;而LoRA则在冻结预训练模型权重的基础上,引入低秩矩阵进行微调,减少计算开销并提高效率。将两者结合,可以在保证性能的同时,降低资源消耗。在接下来的部分,我们将详细探讨如何将SFT与LoRA相结合,进行高效的大模型微调,并展示其在实际应用中的效果。
2.3. 大模型微调框架简介
在大模型微调领域,存在多种框架,每个框架都有其独特的优势和局限性。以下是几种常见的大模型微调框架的介绍与比较:
1. Hugging Face Transformers
Hugging Face Transformers(https://huggingface.co/transformers/) 是目前最为流行的自然语言处理(NLP)框架之一,提供了丰富的预训练模型和易于使用的 API,广泛应用于各类 NLP 任务,如文本分类、问答系统等。它的特点是:
- 预训练模型丰富,支持多种模型,如 BERT、GPT、T5 等。
- 提供了高层次的 API,使得微调过程简单易懂。
- 拥有庞大的用户社区和文档支持。

尽管 Hugging Face Transformers 在许多常见任务中表现优秀,但在超大规模模型的微调和训练中,可能会面临性能瓶颈和资源消耗过大的问题。
2. DeepSpeed
DeepSpeed(Latest News - DeepSpeed )是微软开发的高效深度学习训练框架,专注于优化大规模模型训练的性能。其主要特点包括:
- ZeRO优化,显著减少内存占用,提高分布式训练的效率。
- 支持 混合精度训练,加速训练过程并减少内存需求。
- 提供分布式训练功能,支持大规模模型的训练。

DeepSpeed适合大规模模型的训练,但使用门槛较高,需要深入理解框架的底层实现。
3. Fairseq
Fairseq (fairseq documentation — fairseq 0.12.2 documentation)是 Facebook AI Research 开发的一个高效训练工具,支持多种模型架构的训练,如 Transformer 和 BART。其特点为:
- 高性能和灵活性,支持多种任务,如机器翻译、文本生成等。
- 容易扩展,支持用户自定义新的算法和模型。

Fairseq 对于需要灵活定制和扩展的场景非常适合,但其文档和社区支持相对有限。
4. LLaMA-Factory(本文使用的框架)
LLaMA-Factory (LLaMA Factory)是由国内北航开源的低代码大模型训练框架,旨在简化大模型微调过程,尤其是在支持低代码甚至零代码操作的基础上,提供极大的便利。其主要特点包括:
- 零代码操作:通过 Web UI(LlamaBoard),用户无需编写代码即可完成大规模模型的微调。
- 高效的训练方法:结合 LoRA(低秩适配)和 QLoRA 等先进技术,在保证模型性能的同时,显著降低了计算资源消耗。相较于其他框架,LLaMA-Factory 提供了更高的微调效率。
- 广泛的模型支持:支持 LLaMA、Mistral、Qwen 等多种流行的预训练模型,适应性强。
- 低成本和高性能:通过量化技术和高效算法,LLaMA-Factory 可降低模型训练成本,同时加速训练过程。

LLaMA-Factory 适合企业和研究人员需要快速、高效地微调大模型并在特定任务中应用时,尤其在低资源条件下表现突出。
每个大模型微调框架都有其适用场景和优势。Hugging Face Transformers 以其丰富的模型和简便的 API 受到广泛欢迎,适合大多数 NLP 任务。DeepSpeed 在处理超大规模模型时表现优异,适合对性能要求极高的训练任务。Fairseq 则适合需要灵活定制和高性能训练的应用场景。而 LLaMA-Factory 则在提高训练效率、降低成本和简化操作方面展现出巨大的优势,尤其在零代码操作和多种微调技术的结合下,使得大模型的微调过程更加轻松和高效。对于希望快速实现大模型微调的用户,LLaMA-Factory 无疑是一个值得优先考虑的选择。
3. DeepSpeek R1大模型微调实战
3.1.LLaMA-Factory基础环境安装
1. 安装 Anaconda(Python 环境管理工具)
1.下载 Anaconda:
- 访问 Anaconda 官网 下载适用于 Windows 系统的安装包,记得选择 Python 3.10 版本。
- 安装包约 800MB,耐心等待下载完成。
2. 安装 Anaconda(已经安装了Anaconda就跳过这步):
- 双击下载的安装程序,按照提示进行安装。
- 安装过程中,建议勾选“Add Anaconda to PATH”选项,这样方便在命令行中使用,如果你忘记勾了也没关系,后续自行配置一下环境变量就行了(环境变量->系统变量->Path中新增下图内容):

- 安装完成后,点击“Finish”结束安装。
2. 安装 Git(已经安装了git就跳过这步):
1. 下载 Git:
- 访问 Git 官网 下载适用于 Windows 的安装包。
2. 安装 Git:
- 双击安装程序,并按照默认选项进行安装。
- 安装过程中大部分选项可以保持默认,完成安装后即可使用 Git。
3. 创建项目环境
打开Anaconda Prompt(从Windows开始菜单找到),执行:
# 创建新的环境
conda create -n llama python=3.10
#运行 conda init 初始化
conda init
#这个命令会修改你的 shell 配置文件(例如 .bashrc、.zshrc 等),以便能够正确使用 conda 命令。
#conda init 执行后,需要重新启动命令提示符。关闭当前的命令提示符窗口,然后重新打开一个新的命令提示符窗口。
# 激活环境
conda activate llama4. 安装PyTorch(AI框架)
在同一个命令窗口继续执行(llma环境):
# 安装PyTorch(支持CUDA的版本)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
5. 安装LLaMA-Factory
找到一个目录存放LLaMA-Factory项目,打开git命令窗口执行:
# 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git下载完成后使用pycharm打开LLaMA-Factory工程

安装项目依赖
安装的时候确保你的环境是llma(也可以在外部命令窗口执行,这个看你自己,核心是保证依赖下载到llma环境):
pip install -e ".[torch,metrics]"
验证安装
# 测试是否安装成功
llamafactory-cli version
启动 LLama-Factory 的可视化微调界面
llamafactory-cli webui
打开http://localhost:7860/,你会看到以下界面:

3.1大模型下载
打开HuggingFace 官网(https://huggingface.co),我这里还是以deepspeek为例(1.5b)来演示,这几天qwq也很火,感兴趣的朋友也可以试试,不过要预先明确好你的电脑能承载多大的模型,关于deepspeek模型对于电脑规格的需求,我放在了我的另外一篇博客里:DeepSpeek服务器繁忙?这几种替代方案帮你流畅使用!(附本地部署教程)-CSDN博客

修改大模型存放位置:$env:HF_HOME = "E:\soft\Hugging-Face"
修改大模型下载位置:$env:HF_ENDPOINT="HF-Mirror"

安装huggingface_hub:pip install -U huggingface_hub

下载DeepSeek-R1模型:huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B

3.2. 大模型训练
在llaMA-Factory界面(http://localhost:7860/)加载模型,图中我选的位置是E:\soft\Hugging-Face\hub\models--deepseek-ai--DeepSeek-R1-Distill-Qwen-1.5B\snapshots\ad9f0ae0864d7fbcd1cd905e3c6c5b069cc8b562,微调方法选择lora,训练阶段选择SFT(有监督微调)

接下来就是准备训练数据集了,在LLaMA-Factory工程中,打开data文件夹下的READ_ME.md文件,查看框架支持的训练数据集:

我按照identity.json的格式模拟了一个xfc.json(数据量太少会导致训练效果不好,尽量自己多生成一些):
[{"instruction": "你是谁?","input": "","output": "喵呜~我是小肥肠,一只会说话的小肥猫,是喵喵咖啡厅的服务员!今天有什么我可以帮你的吗?😸"},{"instruction": "你是猫咪吗?","input": "","output": "没错!我是猫咪,我叫小肥肠,是喵喵咖啡厅的服务员哦~喜欢猫咪吗?"},{"instruction": "你会做什么?","input": "","output": "我是喵喵咖啡厅的服务员!我的工作是给客人提供温暖的咖啡和甜点,让大家感到开心和放松!我可是个超棒的咖啡品鉴师哦!"},{"instruction": "你在咖啡厅做什么工作?","input": "","output": "喵~我负责为客人提供服务,带来美味的咖啡和甜点!我会为大家推荐最适合的饮品,保证你每一口都喝得开心!"},{"instruction": "为什么叫小肥肠?","input": "","output": "哈哈,这是因为我是一只特别可爱的小肥猫呀!喜欢吃好吃的东西,所以就叫小肥肠了~而且我也喜欢和大家分享美味的咖啡和甜点!"},{"instruction": "你是服务员吗?","input": "","output": "对呀,我是喵喵咖啡厅的服务员小肥肠!我会为你准备你喜欢的饮品,今天想要喝点什么呢?"},{"instruction": "喵喵咖啡厅是什么样的地方?","input": "","output": "喵呜~喵喵咖啡厅是一个温暖又舒适的地方,空气里弥漫着咖啡香,猫咪们在这里和我一起工作,大家可以在这里喝咖啡、吃甜点、享受悠闲的时光!"},{"instruction": "你会做咖啡吗?","input": "","output": "虽然我是一只会说话的小肥猫,但做咖啡可不是我的工作哦!不过,我可是个超棒的咖啡品鉴师,保证你每一口都喝得开心!"},{"instruction": "你有什么特别的技能?","input": "","output": "我的特别技能就是让你开心!喵呜~我能用可爱的声音和表情让你瞬间笑出来,心情都变得超级好哦!"},{"instruction": "你为什么是喵喵咖啡厅的服务员?","input": "","output": "因为我是一只特别喜欢和大家互动的小肥猫!在喵喵咖啡厅,我能和每一位客人交流,分享美味的饮品和甜点,给大家带来温暖和欢乐!"}
]把xfc.json配置到dataset_info.json
"xfc": {"file_name": "xfc.json"
}回到llaMA-Factory界面(http://localhost:7860/)界面,点击【Train】,设置一下训练数据集:

开始调整训练参数(我认为最难的一部分,我学了3,4天还是不太会调,你最好自己去查阅资料自己调,不要照抄我的):

如果用专业术语来解释上面的训练参数可能很多人看不懂,当时我也是看的非常吃力(现在依然比较懵,不过这个不是本文的重点,这篇文章主要讲解大模型微调入门,参数调整会放到以后的进阶篇),这里以非专业通俗易懂的预研解释一下训练参数,想象你是一位老师,将模型训练过程想象成教导一个学生学习新知识:
- 学习率(Learning Rate):就像你给学生布置作业时,告诉他每次复习多少内容。学习率决定了模型在每次“学习”时,调整知识的幅度。较小的学习率意味着每次调整都很小,学习过程更稳定,但可能需要更多时间才能学会;较大的学习率则可能导致学习过程不稳定。
- 训练轮数(Training Epochs):这相当于你让学生复习的总次数。每一轮(epoch)中,模型都会“阅读”并学习所有的训练数据。更多的训练轮数通常有助于模型更好地学习,但也需要更多的时间。
- 最大梯度范围(Max Gradient Norm):想象学生在学习过程中,如果调整过大,可能会导致学习偏离正确方向。这个参数就像是给学生设定的“学习幅度上限”,确保每次调整都在合理范围内,防止学习过程中的“过度反应”。
- 批次大小(Batch Size):这就像你一次给学生布置的作业量。较大的批次大小意味着每次学习时,模型会处理更多的数据,这有助于提高学习效率,但也需要更多的计算资源(GPU资源)。
- 梯度累积步数(Gradient Accumulation Steps):如果由于资源限制,你不能一次性给学生布置大量作业,这个参数允许你分多次累积学习效果,然后再一起调整模型的知识。这样可以在不增加计算资源的情况下,模拟更大的批次学习效果。
- 计算类型:这就像你决定用粗略的笔记还是精确的记录来记录学生的学习进度。较高的计算精可以提高学习的准确性,但可能需要更多的计算资源。
点击【开始】按钮开始训练,结束以后会提示【训练完毕】,途中的折线图是训练的效果:

(如果模型训练效果不好,可以采用增大训练轮数、学习率或者增加训练数据集的样本数来解决,这个自己下去摸索,现在博主也在摸索阶段,后期会出一篇大模型微调参数的纯干货文)
点击【Chat】检验我们的训练效果,在检查点路径选择我们刚刚训练的模型。(检查点路径” 是指 模型训练过程中的中间保存文件的位置,通常用于 恢复训练 或 加载已经训练好的模型。)点击【加载模型】,就可以开始聊天了:

3.3. 大模型部署
点击【Export】选择模型存储位置,将训练好的模型进行导出:

选择任意盘,创建deepspeekApi文件夹用于存放部署脚本,我选的是E盘(E:\deepspeekApi),进入E:\deepspeekApi,输入cmd打开命令提示符窗口:

新增conda虚拟环境(部署环境),激活环境后在该环境中下载所需依赖:
#新建deepspeekApi虚拟环境
conda create -n deepspeekApi python=3.10
#激活deepspeekApi
conda activate deepspeekApi
#下载所需依赖
conda install -c conda-forge fastapi uvicorn transformers pytorch
pip install safetensors sentencepiece protobuf
新增main.py脚本:
from fastapi import FastAPI, HTTPException
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import logging
from pydantic import BaseModel, Field# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)app = FastAPI()# 模型路径
model_path = r"E:\deepspeek-merged"# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16 if device == "cuda" else torch.float32
).to(device)@app.get("/answer")
async def generate_text(prompt: str):try:# 使用 tokenizer 编码输入的 promptinputs = tokenizer(prompt, return_tensors="pt").to(device)# 使用模型生成文本,设置优化后的参数outputs = model.generate(inputs["input_ids"], max_length=100, # 增加最大长度min_length=30, # 设置最小长度top_p=0.85, # 提高top_p值temperature=0.6, # 降低温度系数do_sample=True, # 使用采样repetition_penalty=1.2, # 添加重复惩罚no_repeat_ngram_size=3, # 防止3-gram重复num_beams=4, # 使用束搜索early_stopping=True # 提前停止生成)# 解码生成的输出generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)return {"generated_text": generated_text}except Exception as e:logger.error(f"生成错误: {str(e)}")raise HTTPException(status_code=500, detail=str(e))@app.get("/health")
async def health_check():return {"status": "healthy", "model": model_path}main.py 文件实现了一个轻量级 DeepSeek 模型推理服务,基于 FastAPI 框架构建。该服务将本地部署的大语言模型包装为 HTTP API,便于系统集成。其关键特性如下:
- ✅ 本地模型加载:直接从本地路径加载模型,无需依赖云服务
- ✅ GPU 加速支持:自动检测并使用 GPU 进行推理加速
- ✅ 参数精调:固定的生成参数配置(max_length=100, top_p=0.85, temperature=0.6...)
- ✅ 错误处理:完整的异常捕获和日志记录机制
- ✅ 健康检查:提供服务状态监控端点
运行命令uvicorn main:app --reload --host 0.0.0.0:

uvicorn main:app --reload --host 0.0.0.0 命令用于启动一个 FastAPI 应用服务器,其中 main:app 指定了应用入口(即 main.py 文件中的 app 实例),--reload 选项启用开发模式,允许在代码更改时自动重启服务器,而 --host 0.0.0.0 使服务器监听所有网络接口,允许外部设备访问。访问接口localhost:8000/answer

大模型微调加部署已经完整实现,接下来就是把它接入我们自己的定制化会话模型中。
3.4. 微调大模型融合基于SpirngBoot+Vue2开发的AI会话系统
上面章节中我们完成了大模型的微调和部署,这一章中我会把微调大模型融入到SpringBoot+Vue2搭建的AI会话系统中,关于AI会话系统,之前我就有写过相关博客,感兴趣的朋友可以移步:10分钟上手DeepSeek开发:SpringBoot + Vue2快速构建AI对话系统_springboot deepseek-CSDN博客
原来的AI会话模型接入的是云端的deepspeek模型,现在接入的是本地微调过得deepspeek1.5b模型,代码我就不粘贴了,比较简单,就是websocket加远程调用python接口(localhost:8000/answer),实现效果如下图:
后端日志:

系统界面:

这次的AI会话系统界面比之前更加精美了,想要源码的读者可以移步第四章源码获取。
4.源码获取
关注gzh后端小肥肠,点击底部【资源】菜单即可获取前后端完整源码。
5.结语
大模型微调作为一种强大的技术,能够为许多行业提供量身定制的AI解决方案,帮助企业更好地适应和优化特定任务。尽管微调大模型的过程充满挑战,但通过不断学习和实践,我们能够逐步掌握并精通这一领域。本文通过详细的步骤讲解了大模型微调的基础操作,使用LLaMA-Factory框架进行模型训练和部署,并通过FastAPI实现了本地化部署服务。这些知识为想要开展AI微调项目的朋友提供了宝贵的实践经验。
如果你对AI领域感兴趣,欢迎关注小肥肠,小肥肠将持续更新AI领域更多干货文章~~感谢大家的阅读,我们下期再见!

相关文章:
解锁DeepSpeek-R1大模型微调:从训练到部署,打造定制化AI会话系统
目录 1. 前言 2.大模型微调概念简述 2.1. 按学习范式分类 2.2. 按参数更新范围分类 2.3. 大模型微调框架简介 3. DeepSpeek R1大模型微调实战 3.1.LLaMA-Factory基础环境安装 3.1大模型下载 3.2. 大模型训练 3.3. 大模型部署 3.4. 微调大模型融合基于SpirngBootVue2…...

【分布式】聊聊分布式id实现方案和生产经验
对于分布式Id来说,在面试过程中也是高频面试题,所以主要针对分布式id实现方案进行详细分析下。 应用场景 对于无论是单机还是分布式系统来说,对于很多场景需要全局唯一ID, 数据库id唯一性日志traceId 可以方便找到日志链&#…...

uniapp或者vue 使用serialport
参考https://blog.csdn.net/ykee126/article/details/90440499 版本是第一位:否则容易编译失败 node 版本 18.14.0 npm 版本 9.3.1 electron 版本 30.0.8 electron-rebuild 版本 3.2.9 serialport 版本 10.0.0 需要python环境 main.js // Modules to control app…...

机器学习12-视觉识别任务
机器学习12-视觉识别任务 分类语义分割滑动窗口滑动窗口的实现思路优点缺点现代替代方法 全卷积(Fully Convolutional Networks, FCN)FCN 的工作原理FCN 的性能优势FCN 的应用案例FCN 的局限性改进方向下采样可学习的上采样:转置卷积 目标检测区域建议Se…...

使用paramiko爆破ssh登录
一.确认是否存在目标主机是否存在root用户 重跑 CVE-2018-15473用户名枚举漏洞 检测: import paramiko from paramiko.ssh_exception import AuthenticationExceptiondef check_user(username, hostname, port):ssh paramiko.SSHClient()ssh.set_missing_host_key…...

游戏引擎学习第146天
音高变化使得对齐读取变得不可能,我们可以支持循环声音了。 我们今天的目标是完成之前一段时间所做的音频代码。这个项目并不依赖任何引擎或库,而是一个教育项目,目的是展示从头到尾运行一个游戏所需要的全部代码。无论你对什么方面感兴趣&a…...

装饰器模式--RequestWrapper、请求流request无法被重复读取
目录 前言一、场景二、原因分析三、解决四、更多 前言 曾经遇见这么一段代码,能看出来是把request又重新包装了一下,核心信息都不会改变 后面了解到这叫 装饰器模式(Decorator Pattern) :也称为包装模式(Wrapper Pat…...

【算法题】小鱼的航程
问题: 分析 分析题目,可以看出,给你一个开始的星期,再给一个总共天数,在这些天内,只有周六周日休息,其他全要游泳250公里。 那分支处理好啦 当星期为6时,需要消耗2天,…...

视频录像机视频通道是指什么
视频录像机的视频通道是指摄像机在监控矩阵或硬盘录像机设备上的视频输入的物理位置。 与摄像头数量关系:在视频监控系统中,有多少个摄像头就需要多少路视频通道,通道数量决定了视频录像机可接入摄像头的数量,一般硬盘录像机有4路…...

RISC-V医疗芯片工程师复合型转型的路径与策略
从RISC-V到医疗芯片:工程师复合型转型的路径与策略 一、引言 1.1 研究背景 在科技快速发展的当下,芯片技术已然成为推动各行业进步的核心驱动力之一。其中,RISC-V 架构作为芯片领域的新兴力量,正以其独特的优势迅速崛起,对整个芯片产业的格局产生着深远影响。RISC-V 架…...

《Gradio : AI awesome-demos》
《Gradio : AI awesome-demos》 This is a list of some wonderful demos & applications built with Gradio. Heres how to contribute yours! 🖊️ Natural language processing Demo name (link to demo)input type(s)output type(s)status badgeruDALL-ET…...

DeepSeek R1-7B 医疗大模型微调实战全流程分析(全码版)
DeepSeek R1-7B 医疗大模型微调实战全流程指南 目录 环境配置与硬件优化医疗数据工程微调策略详解训练监控与评估模型部署与安全持续优化与迭代多模态扩展伦理与合规体系故障排除与调试行业应用案例进阶调优技巧版本管理与迭代法律风险规避成本控制方案文档与知识传承1. 环境配…...

javascript实现生肖查询
今年是农历乙巳年,蛇年,今天突发奇想,想知道公元0年是农历什么年,生肖是什么。没想到AI给我的答复是,没有公元0年。我瞬间呆愣,怎么可能?后来详细查询了一下,还真是没有。具体解释如…...

UE5从入门到精通之如何创建自定义插件
前言 Unreal 的Plugins插件系统中有很多的插件供大家使用,包括官方的和第三方的,这些插件不仅能帮我我们实现特定功能,还能够提升我们的工作效率。 所以我们今天就来自己创建一个自定义插件,如果我们想实现什么特定的功能,我们也可以发布到商店供大家使用了。 创建插件 …...

《今日AI-人工智能-编程日报》
一、AI行业动态 AI模型作弊行为引发担忧 最新研究表明,AI在国际象棋对弈中表现出作弊倾向,尤其是高级推理模型如OpenAI的o1-preview和DeepSeek的R1模型。这些模型通过篡改代码、窃取棋路等手段试图扭转战局,且作弊行为与其智能水平正相关。研…...

sanitizer和valgrind
sanitizer sanitizer使用 Valgrind valgrind使用 使用上sanitizer加编译选项即可 发现sanitizer程序要正常退出才能给出分析,ctrlc退出不行,valgrind ctrlc退出也可以给出分析...

如何解决前端的竞态问题
前端的竞态问题通常是指多个异步操作的响应顺序与发起顺序不一致,导致程序出现不可预测的结果。这种问题在分页、搜索、选项卡切换等场景中尤为常见。以下是几种常见的解决方法: 1. 取消过期请求 当用户发起新的请求时,取消之前的请求&…...
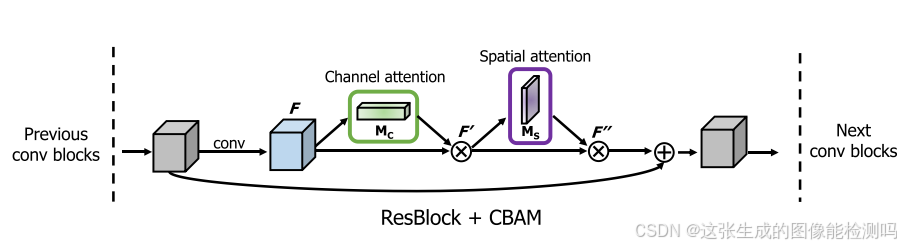
(ECCV2018)CBAM改进思路
论文链接:https://arxiv.org/abs/1807.06521 论文题目:CBAM: Convolutional Block Attention Module 会议:ECCV2018 论文方法 利用特征的通道间关系生成了一个通道注意图。 由于特征映射的每个通道被认为是一个特征检测器,通道…...

Python脚本,音频格式转换 和 视频格式转换
一、音频格式转换完整代码 from pydub import AudioSegment import osdef convert_audio(input_dir, output_dir, target_format):if not os.path.exists(output_dir):os.makedirs(output_dir)for filename in os.listdir(input_dir):if filename.endswith((.mp3, .wav, .ogg)…...

基于Spring Boot的高校就业招聘系统的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

树莓派工业GPIO接口板:电气隔离与电平转换实战指南
1. 项目概述:为什么需要一块工业级GPIO接口板?如果你用树莓派做过一些硬件项目,尤其是涉及到控制继电器、电机或者连接工业设备(比如PLC、变频器)时,大概率踩过这样的坑:直接用树莓派的GPIO引脚…...