RAG外挂知识库
目录
RAG的工作流程
python实现RAG
1.引入相关库及相关准备工作
函数
1. 加载并读取文档
2. 文档分割
3. embedding
4. 向集合中添加文档
5. 用户输入内容
6. 查询集合中的文档
7. 构建Prompt并生成答案
主流程
附录
函数解释
1. open() 函数语法
2.client.embeddings.create()
3.collection.query()
完整代码
RAG的工作流程
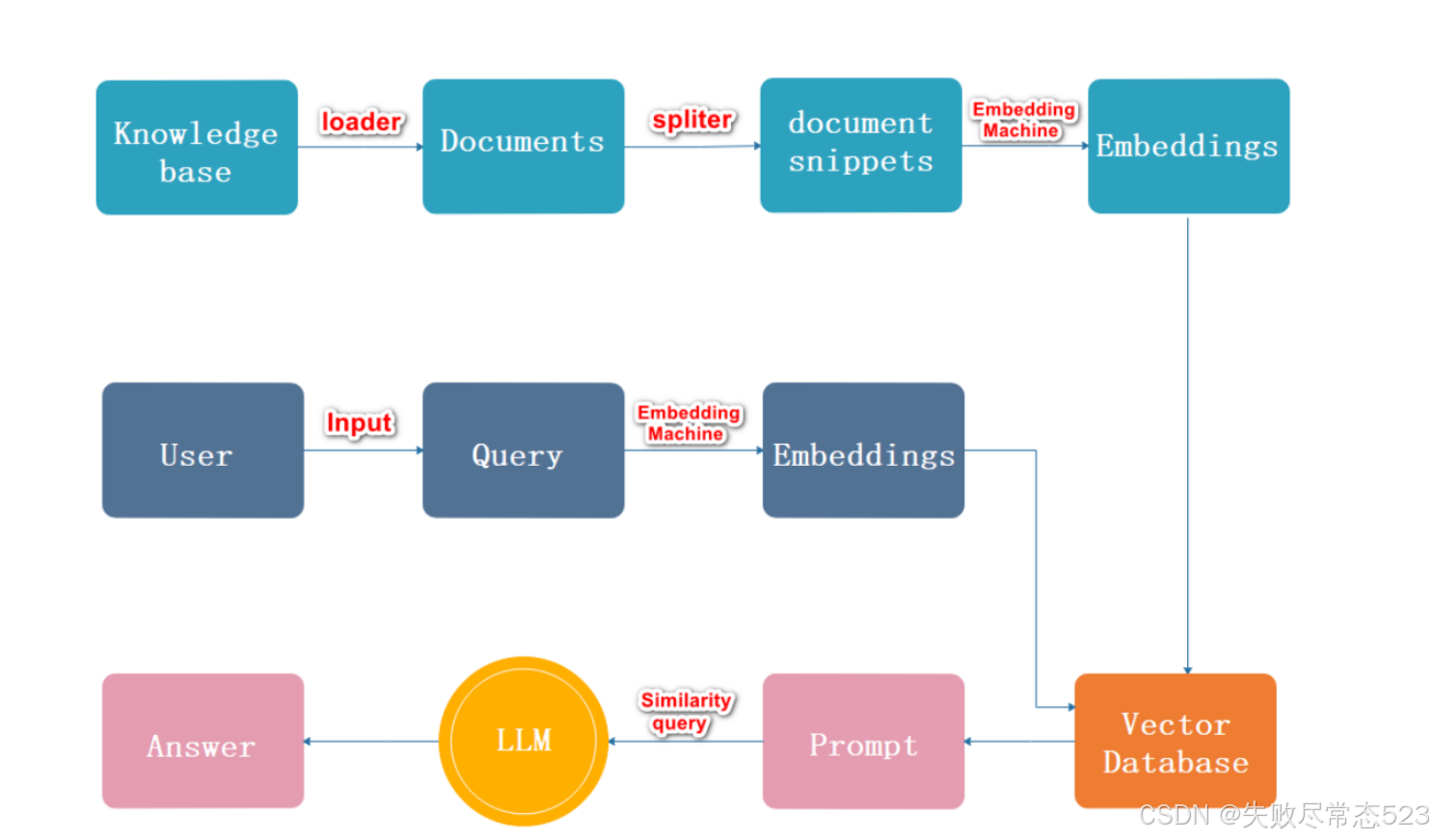
流程描述
加载,读取文档
文档分割
文档向量化
用户输入内容
内容向量化
文本向量中匹配出与问句向量相似的 top_k 个
匹配出的文本作为上下文和问题一起添加到 prompt 中
提交给 LLM 生成答案
Indexing过程

Retrieval过程
python实现RAG
1.引入相关库及相关准备工作
import chromadb # 导入 chromadb 库
from openai import OpenAI # 导入 OpenAI 库client = OpenAI() # 创建一个 OpenAI 客户端实例file_path = "./巴黎奥运会金牌信息.txt"# 创建一个 chroma 客户端实例
chroma_client = chromadb.Client()# 创建一个名为 "my_collection" 的集合
collection = chroma_client.create_collection(name="my_collection")函数
1. 加载并读取文档
# 1. 加载并读取文档
def load_document(filepath):with open(filepath, 'r', encoding='utf-8') as file:document = file.read()return documentdef load_document(filepath):
定义一个名为 load_document 的函数,并接收一个参数 filepath,表示要读取的文件路径。
with open(filepath, 'r', encoding='utf-8') as file:
使用 open() 函数打开 filepath 指定的文件。
'r' 表示以只读模式打开文件。
encoding='utf-8' 指定UTF-8 编码,以确保能够正确处理包含中文或其他特殊字符的文件。
with 语句用于上下文管理,可以在读取文件后自动关闭文件,防止资源泄露。
document = file.read()
2. 文档分割
# 2. 文档分割
def split_document(document):# 使用两个换行符来分割段落chunks = document.strip().split('\n\n')return chunks # 返回包含所有文本块的列表1. def split_document(document):
- 这是一个函数定义,
document是输入的文本(字符串类型)。 - 该函数的作用是按照段落分割文本。
2. document.strip()
strip()方法用于去掉字符串开头和结尾的空白字符(包括空格、换行符\n、制表符\t等)。- 这样可以避免因为文本头尾的换行符导致分割时出现空字符串。
3. .split('\n\n')
split('\n\n')按照两个连续的换行符分割文本。\n代表换行,而\n\n代表两个换行符,通常用于分隔不同的段落。- 这个方法会返回一个列表,其中每个元素是一个段落。
4. return chunks
chunks是分割后的文本块列表,返回它供后续使用。
3. embedding
# 3. embedding
def get_embedding(texts, model="text-embedding-3-large"):result = client.embeddings.create(input=texts,model=model)return [x.embedding for x in result.data]封装embedding模型。
4. 向集合中添加文档
# 4. 向集合中添加文档
def add_documents_to_collection(chunks):embeddings = get_embedding(chunks) # 获取文档块的嵌入collection.add(documents=chunks, # 文档内容embeddings=embeddings, # 文档对应的嵌入向量ids=[f"id{i+1}" for i in range(len(chunks))] # 生成文档 ID)这段代码定义了 add_documents_to_collection 函数,用于将文档(chunks)添加到一个集合(collection)中,并为每个文档计算嵌入(embedding)。这个过程通常用于向量数据库(如 FAISS、ChromaDB 或 Pinecone),以支持向量搜索、相似性检索和信息检索。
embeddings = get_embedding(chunks) # 获取文档块的嵌入
- 调用
get_embedding(chunks),为chunks中的每个文本计算嵌入(embedding)。 embeddings是一个嵌入向量列表,每个向量对应chunks里的一个文本片段。
collection.add(
collection是一个数据库或向量存储集合,可以是 ChromaDB、FAISS、Pinecone 等向量数据库对象。.add()方法用于向集合中添加数据,包括原始文档、嵌入向量和唯一 ID。
ids=[f"id{i+1}" for i in range(len(chunks))] # 生成文档 ID
ids是文档唯一标识符,用于在数据库中区分不同文档。f"id{i+1}"生成 "id1", "id2", "id3" 这样的字符串 ID。for i in range(len(chunks))依次编号,确保每个文档有唯一 ID。
示例
输入
假设 chunks 是:
chunks = ["文本片段1", "文本片段2", "文本片段3"]
执行:
add_documents_to_collection(chunks)
执行过程
1.计算 chunks 的嵌入:
embeddings = get_embedding(chunks)
假设返回:
[[0.1, 0.2, 0.3], # 文本片段1的嵌入[0.4, 0.5, 0.6], # 文本片段2的嵌入[0.7, 0.8, 0.9] # 文本片段3的嵌入
]
2.添加到 collection:
collection.add(documents=["文本片段1", "文本片段2", "文本片段3"],embeddings=[[0.1, 0.2, 0.3],[0.4, 0.5, 0.6],[0.7, 0.8, 0.9]],ids=["id1", "id2", "id3"]
)
5. 用户输入内容
def get_user_input():return input("请输入您的问题: ")6. 查询集合中的文档
# 6. 查询集合中的文档
def query_collection(query_embeddings, n_results=1):results = collection.query(query_embeddings=[query_embeddings], # 查询文本的嵌入n_results=n_results # 返回的结果数量)return results['documents']collection.query(...):对collection进行查询,基于嵌入向量 执行相似度检索。query_embeddings=[query_embeddings]:将单个查询嵌入封装在列表中,确保符合 API 要求。n_results=n_results:指定要返回的最相似的n_results个文档。
return results['documents']
results是collection.query(...)的返回结果,它应该是一个 字典,其中包含多个字段(如documents,embeddings , ids 等)。results['documents']获取查询返回的文档列表并返回。
7. 构建Prompt并生成答案
# 7. 构建Prompt并生成答案
def get_completion(prompt, model='gpt-3.5-turbo'):message = [{"role": "user", "content": prompt}]result = client.chat.completions.create(model=model,messages=message)return result.choices[0].message.content主流程
if __name__ == "__main__":# 步骤1 => 加载文档document = load_document(file_path)# 步骤2 => 文档分割chunks = split_document(document)# 步骤3 => embeddingadd_documents_to_collection(chunks) # 在分割后立即添加文档# 步骤4 => 用户输入内容user_input = get_user_input()# 步骤5 => 将用户输入的问题进行embeddinginput_embedding = get_embedding(user_input)[0] # 获取用户问题的嵌入# 步骤6 => 查询集合中的文档context_texts = query_collection(input_embedding, n_results=1) # 查询相关文档print(context_texts)# 步骤7 => 构建Prompt并生成答案prompt = f"上下文: {context_texts}\n\n问题: {user_input}\n\n请提供答案:"answer = get_completion(prompt)print(answer)附录
函数解释
1. open() 函数语法
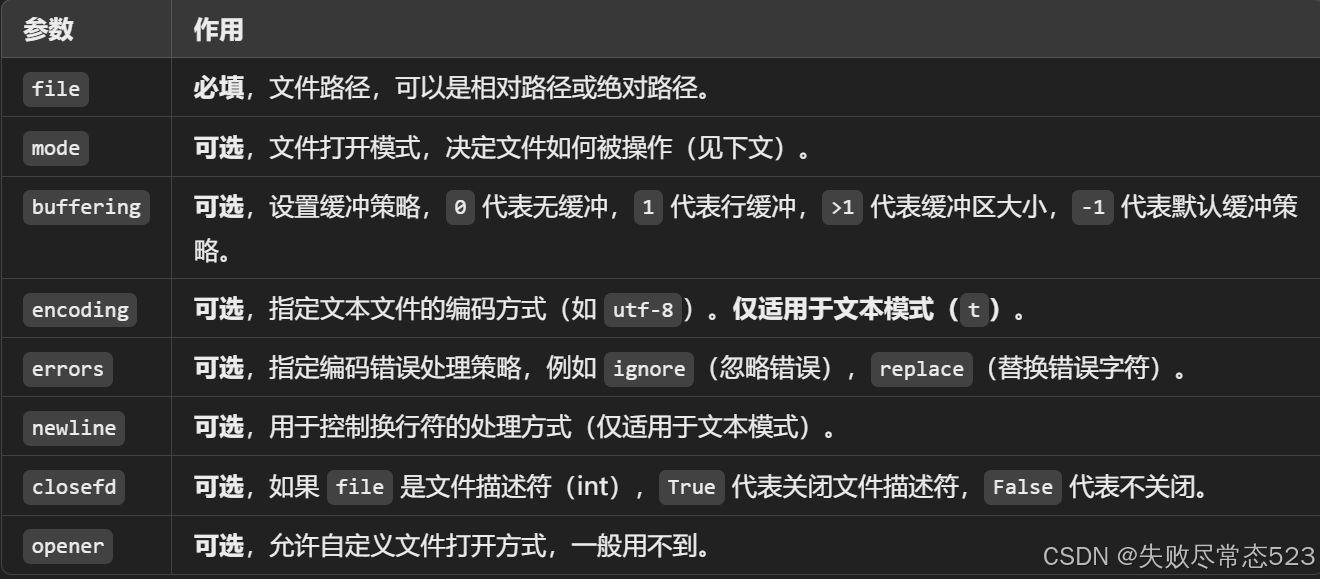
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明
常见 mode(模式)
组合模式示例:
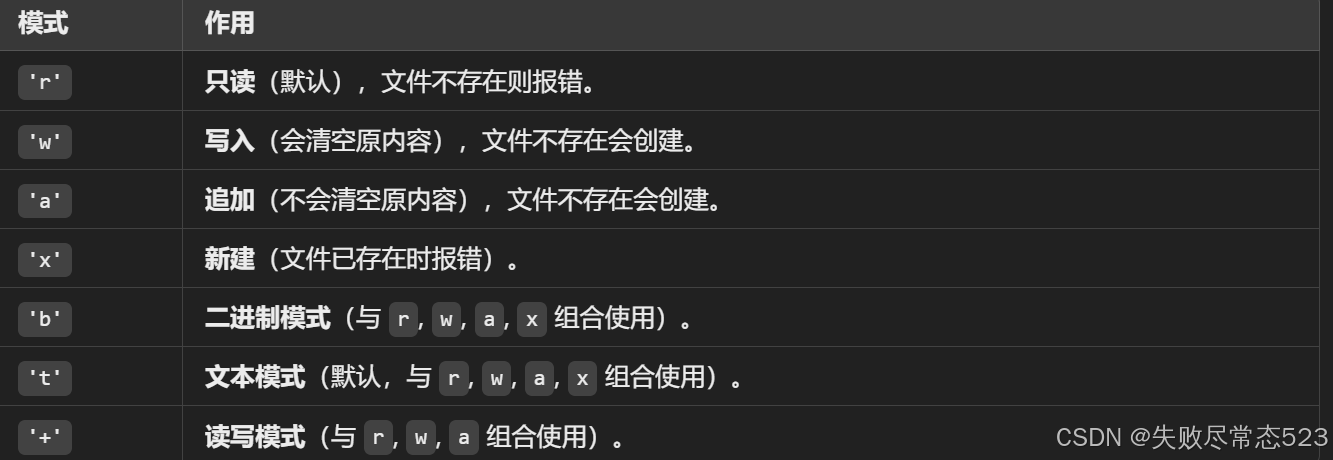
'rb':以 二进制模式 读取文件。'wt':以 文本模式 写入文件。'a+':以 读写模式 打开文件,并在文件末尾追加内容。
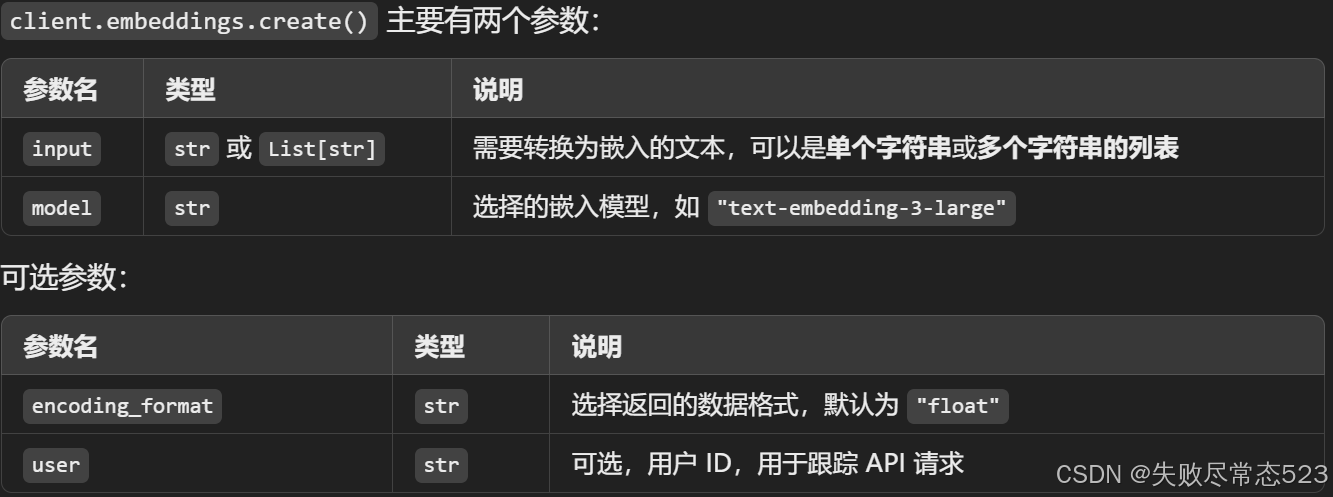
2.client.embeddings.create()
client.embeddings.create() 是 OpenAI API 提供的一个函数,用于生成文本的嵌入(embedding)向量。它将文本转换为高维数值向量,通常用于相似性计算、文本分类、搜索、推荐系统等 NLP 任务。
基本使用
import openai# 创建 OpenAI 客户端(需要提供 API Key)
client = openai.OpenAI(api_key="your-api-key")# 生成文本嵌入
response = client.embeddings.create(input=["Hello world", "How are you?"], # 输入文本,可以是单个字符串或字符串列表model="text-embedding-3-large" # 选择的嵌入模型
)
参数说明
3.collection.query()
collection.query() 是一个用于查询向量数据库的函数,主要用于 基于向量嵌入(embeddings)的相似性搜索。它通常用于检索与查询向量最接近的文档或数据点。
results = collection.query(query_embeddings=[query_vector], # 查询向量(必须是列表)n_results=3 # 需要返回的最相似的结果数量
)
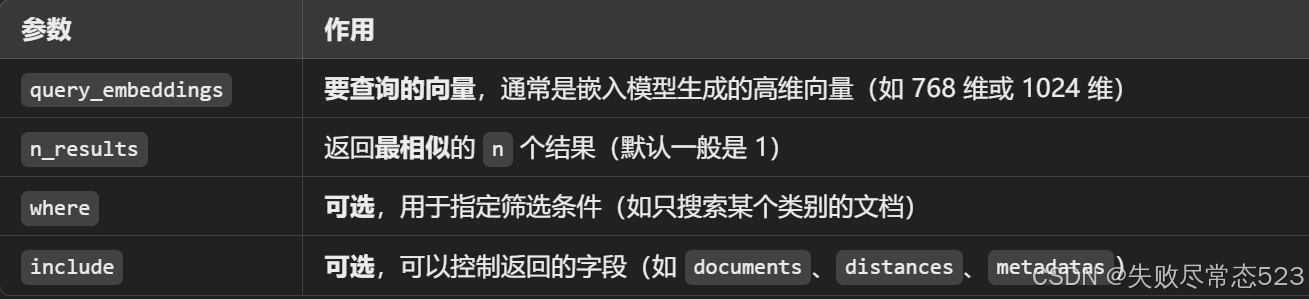
collection.query() 的返回结果
查询后的 results 变量通常是一个 字典,常见的字段包括:
{"documents": [["文档1内容"], ["文档2内容"], ["文档3内容"]],"distances": [[0.12], [0.15], [0.18]],"metadatas": [{"id": "doc1"}, {"id": "doc2"}, {"id": "doc3"}]
}

完整代码
import chromadb # 导入 chromadb 库
from openai import OpenAI # 导入 OpenAI 库
client = OpenAI() # 创建一个 OpenAI 客户端实例file_path = "./巴黎奥运会金牌信息.txt"# 创建一个 chroma 客户端实例
chroma_client = chromadb.Client()# 创建一个名为 "my_collection" 的集合
collection = chroma_client.create_collection(name="my_collection")# 1. 加载并读取文档
def load_document(filepath):with open(filepath, 'r', encoding='utf-8') as file:document = file.read()return document# 2. 文档分割
def split_document(document):# 使用两个换行符来分割段落chunks = document.strip().split('\n\n')return chunks # 返回包含所有文本块的列表# 3. embedding
def get_embedding(texts, model="text-embedding-3-large"):result = client.embeddings.create(input=texts,model=model)return [x.embedding for x in result.data]# 4. 向集合中添加文档
def add_documents_to_collection(chunks):embeddings = get_embedding(chunks) # 获取文档块的嵌入collection.add(documents=chunks, # 文档内容embeddings=embeddings, # 文档对应的嵌入向量ids=[f"id{i+1}" for i in range(len(chunks))] # 生成文档 ID)# 5. 用户输入内容
def get_user_input():return input("请输入您的问题: ")# 6. 查询集合中的文档
def query_collection(query_embeddings, n_results=1):results = collection.query(query_embeddings=[query_embeddings], # 查询文本的嵌入n_results=n_results # 返回的结果数量)return results['documents']# 7. 构建Prompt并生成答案
def get_completion(prompt, model='gpt-3.5-turbo'):message = [{"role": "user", "content": prompt}]result = client.chat.completions.create(model=model,messages=message)return result.choices[0].message.content# 主流程
if __name__ == "__main__":# 步骤1 => 加载文档document = load_document(file_path)# 步骤2 => 文档分割chunks = split_document(document)# 步骤3 => embeddingadd_documents_to_collection(chunks) # 在分割后立即添加文档# 步骤4 => 用户输入内容user_input = get_user_input()# 步骤5 => 将用户输入的问题进行embeddinginput_embedding = get_embedding(user_input)[0] # 获取用户问题的嵌入# 步骤6 => 查询集合中的文档context_texts = query_collection(input_embedding, n_results=1) # 查询相关文档print(context_texts)# 步骤7 => 构建Prompt并生成答案prompt = f"上下文: {context_texts}\n\n问题: {user_input}\n\n请提供答案:"answer = get_completion(prompt)print(answer)相关文章:
RAG外挂知识库
目录 RAG的工作流程 python实现RAG 1.引入相关库及相关准备工作 函数 1. 加载并读取文档 2. 文档分割 3. embedding 4. 向集合中添加文档 5. 用户输入内容 6. 查询集合中的文档 7. 构建Prompt并生成答案 主流程 附录 函数解释 1. open() 函数语法 2.client.embe…...

Rust语言:开启高效编程之旅
目录 一、Rust 语言初相识 二、Rust 语言的独特魅力 2.1 内存安全:消除隐患的护盾 2.2 高性能:与 C/C++ 并肩的实力 2.3 强大的并发性:多线程编程的利器 2.4 跨平台性:适配多环境的优势 三、快速上手 Rust 3.1 环境搭建:为开发做准备 3.2 第一个 R…...

蓝桥杯备考:图论初解
1:图的定义 我们学了线性表和树的结构,那什么是图呢? 线性表是一个串一个是一对一的结构 树是一对多的,每个结点可以有多个孩子,但只能有一个父亲 而我们今天学的图!就是多对多的结构了 V表示的是图的顶点集…...

Codeforces Round 502 E. The Supersonic Rocket 凸包、kmp
题目链接 题目大意 平面上给定两个点集,判定两个点集分别形成的凸多边形能否通过旋转、平移重合。 点集大小 ≤ \leq ≤ 1 0 5 10^{5} 105,坐标范围 [0, 1 0 8 10^{8} 108 ]. 思路 题意很明显,先求出凸包再判断两凸包是否同构。这里用…...

机器人匹诺曹机制,真话假话平衡机制
摘要: 本文聚焦于机器人所采用的一种“匹诺曹机制”,该机制旨在以大概率保持“虚拟鼻子”(一种象征虚假程度的概念)不会过长,通过在对话中夹杂真话与假话来实现。文章深入探讨了这一机制的原理,分析其背后的…...

用Python分割并高效处理PDF大文件
在处理大型PDF文件时,将它们分解成更小、更易于管理的块通常是有益的。这个过程称为分区,它可以提高处理效率,并使分析或操作文档变得更容易。在本文中,我们将讨论如何使用Python和为Unstructured.io库将PDF文件划分为更小的部分。…...
【RAG】混合检索(Hybrid Search) 提高检索精度
1.问题:向量检索也易混淆,而关键字会更精准 在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有利弊。 举个具体例子,比如文档中包含很长的专有名词, 关…...

CTFHub-FastCGI协议/Redis协议
将木马进行base64编码 <?php eval($_GET[cmd]);?> 打开kali虚拟机,使用虚拟机中Gopherus-master工具 Gopherus-master工具安装 git clone https://github.com/tarunkant/Gopherus.git 进入工具目录 cd Gopherus 使用工具 python2 "位置" --expl…...

【算法day4】最长回文子串——动态规划方法
最长回文子串 给你一个字符串 s,找到 s 中最长的 回文 子串。 https://leetcode.cn/problems/longest-palindromic-substring/submissions/607962358/ 动态规划: 回文串即是从前面开始读和从后面开始读,读出来的字符串均相同的字符串&#…...

C++之“string”类的模拟实现
🌹个人主页🌹:喜欢草莓熊的bear 🌹专栏🌹:C入门 前言 hello ,大家又来跟着bear学习了。一起奔向更好的自己,上篇博客已经讲清楚了string的一些功能的使用。我们就实现一些主要的功…...
?)
请谈谈 HTTP 中的安全策略,如何防范常见的Web攻击(如XSS、CSRF)?
一、Web安全核心防御机制 (一)XSS攻击防御(跨站脚本攻击) 1. 原理与分类 存储型XSS:恶意脚本被持久化存储在服务端(如数据库)反射型XSS:脚本通过URL参数或表单提交触发执行…...

Python Flask 渲染静态程动态页面
Python Flask 渲染静态程动态页面 Python Flask 渲染静态程动态页面 Python Flask 渲染静态程动态页面 对网页应用程序来说,静态内容是重要的,因为它们包括 CSS 和 JavaScript 文件。静态文件可以直接由网页服务器提供。如果我们在我们的项目中创建一个…...

Unity大型游戏开发全流程指南
一、开发流程与核心步骤 1. 项目规划与设计阶段 需求分析 明确游戏类型(MMORPG/开放世界/竞技等)、核心玩法(战斗/建造/社交)、目标平台(PC/移动/主机)示例:MMORPG需规划角色成长树、副本Boss…...

Unity场景制作
一、关于后处理效果 然后可在后处理组件中添加各种效果 ACES : 电影感的强对比效果 添加了ACES后场景明显变暗,所以可以提高曝光度 Post-exposure 二、添加雾效 在Window的项目栏中选择Render中的Lighting 在环境属性中的其他设置中可勾选雾效,为场景中添…...

PCIE接口
PCIE接口 PIC接口介绍PIC总线结构PCI总线特点PCI总线的主要性能PIC的历程 PCIE接口介绍PCIe接口总线位宽PCIE速率GT/s和Gbps区别PCIE带宽计算 PCIE架构PCIe体系结构端到端的差分数据传递PCIe总线的层次结构事务层数据链路层物理层PCIe层级结构及功能框图 PCIe链路初始化PCIe链路…...

Leetcode 3479. Fruits Into Baskets III
Leetcode 3479. Fruits Into Baskets III 1. 解题思路2. 代码实现 题目链接:3479. Fruits Into Baskets III 1. 解题思路 这一题思路本质上就是考察每一个水果被考察时找到第一个满足条件且未被使用的basket。 因此,我们只需要将basket按照其capacit…...

小程序 -- uni-app开发微信小程序环境搭建(HBuilder X+微信开发者工具)
目录 前言 一 软件部分 1. 微信开发者工具 2. HBuilder X 开发工具 二 配置部分 1. 关于 HBuilder X 配置 2. 关于 微信开发工具 配置 三 运行项目 1. 新建项目 2. 代码编写 3. 内置浏览器 编译 4. 配置小程序 AppID获取 注意 四 实现效果 前言 uni-app开发小程…...

深度学习PyTorch之13种模型精度评估公式及调用方法
深度学习pytorch之22种损失函数数学公式和代码定义 深度学习pytorch之19种优化算法(optimizer)解析 深度学习pytorch之4种归一化方法(Normalization)原理公式解析和参数使用 深度学习pytorch之简单方法自定义9类卷积即插即用 实时…...

《云原生监控体系构建实录:从Prometheus到Grafana的观测革命》
PrometheusGrafana部署配置 Prometheus安装 下载Prometheus服务端 Download | PrometheusAn open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.https://prometheus.io/…...

GHCTF2025--Web
upload?SSTI! import os import refrom flask import Flask, request, jsonify,render_template_string,send_from_directory, abort,redirect from werkzeug.utils import secure_filename import os from werkzeug.utils import secure_filenameapp Flask(__name__)# 配置…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...