Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览
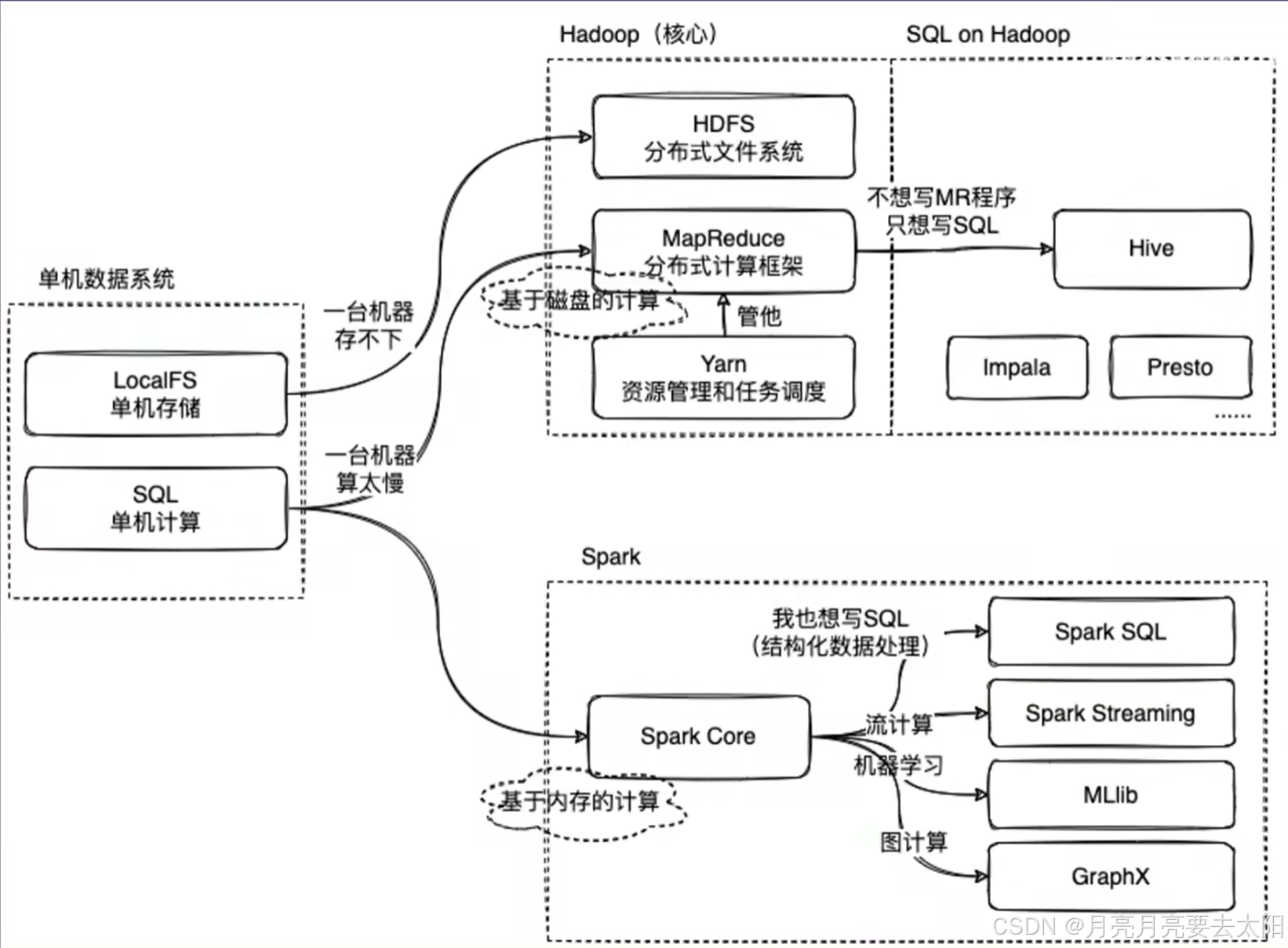
1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。
2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。
3、HIve中有metastore存储结构化信息,还有执行引擎将sql翻译成mapreduce,再把加工结果返回给用户。
Part2:十道Hadoop相关的题目
一、Hadoop生态系统简介:请简要描述Hadoop的核心组件及其作用。
Hadoop是一个开源的分布式计算框架,专门用于存储和处理大规模数据集(通常从TB到PB级别)。Hadoop的核心思想是分布式存储和分布式计算,通过将数据和计算任务分散到多个节点上,实现高性能和高容错性。
其核心组件包括HDFS、mapreduce、TARN.
(1)HDFS(Hadoop Distributed File System)
- 作用:HDFS是Hadoop的分布式文件系统,用于存储海量数据。
- 特点:
- 数据被分割成多个块(默认128MB或256MB),并分布存储在不同的节点上。
- 具有高容错性,数据会自动复制多份(默认3份)存储在不同的节点上。
- 关键角色:
- NameNode:管理文件系统的元数据(如文件目录结构、块的位置等)。
- DataNode:存储实际的数据块。
(2)MapReduce
- 作用:MapReduce是Hadoop的分布式计算框架(the same with Hadoop),用于处理大规模数据集。
- 工作原理:
- Map阶段:将输入数据分割成小块,并行处理并生成中间结果(键值对)。
- Reduce阶段:对Map阶段的中间结果进行汇总和计算,生成最终结果。
- 特点:
- 适合批处理任务,但不适合实时计算(因为mapreduce的机制)。
(3)YARN(Yet Another Resource Negotiator)
- 作用:YARN是Hadoop的资源管理系统,负责集群资源的调度和任务管理。
- 特点:
- 将资源管理和任务调度分离,支持多种计算框架(如MapReduce、Spark等)。
- 提高了集群的利用率和灵活性。
二、Hadoop的工作流程
1. 数据存储:
数据被上传到HDFS,分割成多个块并分布存储在不同的DataNode,NameNode记录文件的元数据和块的位置信息。
2. 数据处理:
用户提交一个MapReduce任务:YARN负责分配资源,启动Map任务和Reduce任务,Map任务读取HDFS上的数据,生成中间结果,Reduce任务对中间结果进行汇总,生成最终结果并写回HDFS。
三、HDFS:解释HDFS的架构,说明NameNode和DataNode的作用。
HDFS是Hadoop的核心组件,存储和管理大规模数据,具有高容错性和高吞吐量的特点。其架构采用主从模式,主要包括以下组件:
1. NameNode(主节点)
作用:
元数据管理:存储文件系统的元数据,如文件名、目录结构、文件块位置等。
协调客户端访问:处理客户端的读写请求,并协调DataNode的操作。
特点:
单点故障:NameNode是单点,故障会导致整个系统不可用。Hadoop 2.0通过备用NameNode解决这一问题。
内存存储:元数据存储在内存中,以加快访问速度。
2. DataNode(从节点)
作用:
数据存储:实际存储文件数据,文件被分割成多个块(默认128MB),并在多个DataNode上复制(默认3份)以实现容错。
数据块管理:负责数据块的创建、删除和复制,并定期向NameNode报告状态。
特点:
分布式存储:数据块分布在多个DataNode上,提供高吞吐量和容错性。
本地存储:数据块存储在本地文件系统中。
3. Secondary NameNode(辅助NameNode)
作用:
辅助NameNode:定期合并NameNode的编辑日志和镜像文件,减少NameNode的启动时间。
非备用NameNode:它不是NameNode的备用节点,不能直接接管NameNode的工作。
总结
NameNode:负责管理元数据和协调客户端访问,是HDFS的核心。
DataNode:负责实际数据存储和块管理,分布在多个节点上以提供高吞吐量和容错性。
Secondary NameNode:辅助NameNode进行元数据管理,但不提供故障切换功能。
四、HDFS的工作流程
1. 文件写入:
客户端向NameNode请求写入文件;NameNode分配DataNode并返回其列表;客户端将数据写入第一个DataNode,该节点再将数据复制到其他DataNode。
2. 文件读取:
客户端向NameNode请求读取文件;NameNode返回存储该文件块的DataNode列表;客户端直接从DataNode读取数据。
3. 容错与复制:
每个数据块默认复制3份,存储在不同DataNode上;如果某个DataNode失效,NameNode会检测到并将数据块复制到其他节点。
五、MapReduce:描述其工作流程,并解释Mapper和Reducer作用。
MapReduce是一种用于大规模数据处理的编程模型,由Google提出,主要用于分布式计算。它将任务分解为两个主要阶段:Map和Reduce。
工作流程
1. 输入分片(Input Splitting):
输入数据被划分为多个分片(splits),每个分片由一个Mapper处理。
2. Map阶段:
每个Mapper处理一个输入分片,生成键值对(key-value pairs)作为中间结果。
3. Shuffle和Sort:
系统将Mapper输出的中间结果按键分组并排序,确保相同键的值被送到同一个Reducer。
4. Reduce阶段:
Reducer接收分组后的中间结果,进行汇总处理,生成最终输出。
5. 输出:
Reducer的输出写入存储系统,如HDFS。
Mapper的作用:
数据处理:Mapper读取输入分片,逐条处理并生成键值对。
并行处理:多个Mapper可以同时处理不同分片,提升效率。
中间结果生成:Mapper的输出是中间结果,供Reducer进一步处理。
Reducer的作用
数据汇总:Reducer对Mapper输出的中间结果进行汇总。
聚合计算:Reducer执行如求和、计数等聚合操作。
生成最终结果:Reducer的输出是最终结果,通常存储在分布式文件系统中。
示例:假设统计文本中单词的出现次数
1. Map阶段:每个Mapper读取一部分文本,生成形如`(word, 1)`的键值对。
2. Shuffle和Sort:系统将相同单词的键值对分组,如`("hello", [1, 1, 1])`。
3. Reduce阶段:Reducer对每个单词的计数求和,生成`("hello", 3)`。
4. 输出:最终结果写入文件,如`hello 3`。
总结
Mapper:负责数据的分片处理和中间结果的生成。
Reducer:负责中间结果的汇总和最终结果的生成。
六、MapReduce中,数据是如何进行分区和排序的?解释Partitioner和Combiner的作用。
在MapReduce中,数据的分区和排序的步骤主要由Partitioner和Combiner来完成。
数据分区(Partitioning)
Partitioner的作用
数据分配:Partitioner负责将Mapper输出的键值对分配到不同的Reducer。它通过哈希函数对键进行计算,决定数据应发送到哪个Reducer。
负载均衡:合理的分区策略可以确保各Reducer的负载均衡,避免某些Reducer过载。
分区过程:
1. Mapper输出:Mapper生成键值对后,Partitioner根据键的哈希值决定其所属分区。
2.分区数量:分区数量通常等于Reducer的数量。
3. 数据发送:每个分区的数据被发送到对应的Reducer。
默认Partitioner
HashPartitioner:MapReduce默认使用哈希分区器,通过`hash(key) % numReduceTasks`计算分区。
数据排序(Sorting)
排序过程
1. Mapper端排序:Mapper输出的键值对在发送到Reducer之前,会在本地进行排序。
2. Reducer端排序:Reducer在接收到所有Mapper的数据后,会再次进行全局排序,确保相同键的值按顺序处理。
排序机制
按键排序:MapReduce框架默认按键进行排序,确保Reducer处理时键是有序的。
自定义排序:可以通过实现`WritableComparable`接口自定义排序逻辑。
示例:假设统计文本中单词的出现次数:
1. Map阶段:
Mapper生成键值对,如`("hello", 1)`。
2. Combiner阶段:
Combiner对Mapper的输出进行局部聚合,如将`("hello", [1, 1, 1])`合并为`("hello", 3)`。
3. Partitioner阶段:
Partitioner根据键的哈希值决定数据发送到哪个Reducer。
4. Sort阶段:
数据在发送到Reducer之前进行排序,确保相同键的值按顺序处理。
5. Reduce阶段:
Reducer对接收到的数据进行最终聚合,生成`("hello", 3)`。
总结:
Partitioner:负责将Mapper输出的键值对分配到不同的Reducer,确保负载均衡。
Combiner:在Mapper端进行局部聚合,减少数据传输量,优化性能。
七、YARN在Hadoop中的作用,及其与MapReduce的关系
YARN是Hadoop 2.0引入的核心组件,用于资源管理和作业调度。它的主要作用是解耦资源管理和数据处理逻辑,使得MapReduce只需专注于数据处理,同时支持其他计算框架。
YARN的架构
YARN主要由以下几个组件组成:
1. ResourceManager (RM):全局资源管理+启动ApplicationMaster。
2. NodeManager (NM):节点资源管理+向ResourceManager报告资源使用情况和任务状态。
3. ApplicationMaster (AM):
- 作业管理:每个应用程序都有一个ApplicationMaster,负责与ResourceManager协商资源,与NodeManager协作执行任务。
- 任务调度:ApplicationMaster负责将任务调度到合适的容器中执行。
4. Container:理解为资源的封装,任务在Container中执行,由NodeManager监控。
YARN与MapReduce的关系:
1. 解耦资源管理和作业调度:
- 在Hadoop 1.0中,MapReduce既负责资源管理又负责作业调度,导致扩展性和灵活性受限。
- YARN将资源管理和作业调度解耦,使得MapReduce只需专注于数据处理逻辑。
2. MapReduce作为YARN的一个应用程序:
- 在YARN架构下,MapReduce作为一个应用程序运行,由ApplicationMaster负责作业的管理和任务调度。
- MapReduce的ResourceManager和JobTracker功能被YARN的ResourceManager和ApplicationMaster取代。
3. 支持多计算框架:
YARN不仅支持MapReduce,还支持其他计算框架如Spark、Flink等,使得Hadoop成为一个通用的数据处理平台。
示例:一个MapReduce作业
用户提交MapReduce作业到YARN的ResourceManager,ResourceManager为该作业分配资源,并启动一个ApplicationMaster,ApplicationMaster与ResourceManager协商资源,将Map和Reduce任务调度到各个NodeManager的Container中执行,NodeManager监控任务的执行情况,并向ApplicationMaster报告状,ApplicationMaster在作业完成后,向ResourceManager注销并释放资源。
八、Hadoop MapReduce和Apache Spark都是大数据处理框架,请简要说明它们的主要区别。
1. 数据处理模型
Hadoop MapReduce:批处理,适合静态数据;数据处理分为Map和Reduce两个阶段,中间结果需要写入磁盘。
Apache Spark:支持批处理、流处理、交互式查询和机器学习等多种数据处理模式;利用内存进行计算,减少磁盘I/O,显著提高性能。
2. 性能
Hadoop MapReduce:磁盘I/O性能相对较低,适合高延迟的批处理作业。
Apache Spark:内存计算+低延迟。
3. 易用性
Hadoop MapReduce:编程模型相对复杂+API限制(API较为底层,开发效率较低)
Apache Spark:高级API(Spark提供了丰富的高级API(如Scala、Java、Python、R),易于使用。)+开发效率高。
4. 生态系统
Hadoop MapReduce:MapReduce是Hadoop生态系统的一部分,依赖HDFS进行数据存储,
Hadoop生态系统成熟稳定,适合大规模批处理。
Apache Spark: Spark有自己的生态系统(独立),支持多种数据源(如HDFS、S3、Cassandra)。+丰富库:Spark提供了丰富的库(如Spark SQL、Spark Streaming、MLlib、GraphX),支持多种数据处理需求。
总结:
Hadoop MapReduce:适合大规模批处理和高容错性需求的场景,但性能较低,编程复杂。
Apache Spark:适合实时数据处理、迭代计算和多种数据处理模式,性能高,易于使用。
九、在配置Hadoop集群时的关键配置参数
1. dfs.replication:
◦ 作用:指定HDFS中每个数据块的副本数量。
◦ 解释:默认值为3,表示每个数据块会在集群中存储3个副本。增加副本数可以提高数据的可靠性和容错性,但也会增加存储开销。
2.mapreduce.tasktracker.map.tasks.maximum和 mapreduce.tasktracker.reduce.tasks.maximum:
◦ 作用:分别指定每个NodeManager上可以同时运行的Map任务和Reduce任务的最大数量。
◦ 解释:这些参数影响集群的并发处理能力。合理设置这些参数可以优化资源利用率和作业执行效率。
3. yarn.scheduler.maximum-allocation-mb:
◦ 作用:指定YARN可以为每个容器分配的最大内存量。
◦ 解释:这个参数决定了单个任务可以使用的最大内存资源。合理设置可以防止单个任务占用过多资源,影响其他任务的执行。
十、数据本地性优化:在Hadoop中,数据本地性(Data Locality)是什么?为什么它对性能优化至关重要?
**数据本地性(Data Locality)**是指计算任务在数据所在的节点上执行,尽量减少数据的网络传输。
• 重要性:
◦ 减少网络开销:数据本地性可以减少数据在网络中的传输,降低网络带宽的消耗。
◦ 提高性能:本地数据处理速度远快于通过网络传输数据后再处理,显著提高作业的执行效率。
◦ 负载均衡:数据本地性有助于均衡集群中各节点的负载,避免某些节点过载。
十一、Hadoop故障处理:在Hadoop集群中,如果某个DataNode宕机,系统会如何处理?NameNode在这个过程中扮演了什么角色?
1. 检测故障:
◦ NameNode通过心跳机制检测到DataNode宕机。
2. 副本复制:
◦ NameNode会检查宕机DataNode上存储的数据块,发现副本数量不足时,会启动副本复制过程,将数据块复制到其他健康的DataNode上。
3. 更新元数据:
◦ NameNode更新元数据信息,记录新的数据块副本位置。
NameNode的角色:
• 元数据管理:NameNode负责管理文件系统的元数据,包括文件到数据块的映射和数据块的位置信息。
• 故障检测与恢复:NameNode通过心跳机制检测DataNode的状态,并在DataNode宕机时协调数据块的复制和恢复。
十二、Hadoop应用场景
应用场景:日志分析
• 场景描述:大型互联网公司每天生成大量的日志数据,需要对这些日志进行分析,以提取用户行为、系统性能等信息。(大规模数据处理+成本效益+高容错性+批处理)
相关文章:
Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览 1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。 2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。 3、HIv…...

Excel·VBA江西省预算一体化工资表一键处理
每月制作工资表导出为Excel后都需要调整格式,删除0数据的列、对工资表项目进行排序、打印设置等等,有些单位还分有“行政”、“事业”2个工资表就需要操作2次。显然,这种重复操作的问题,可以使用VBA代码解决 目录 代码使用说明1&a…...
23种设计模式简介
一、创建型(5种) 1.工厂方法 总店定义制作流程,分店各自实现特色披萨(北京店-烤鸭披萨,上海店-蟹粉披萨) 2.抽象工厂 套餐工厂(家庭装含大披萨薯条,情侣装含双拼披萨红酒&#…...

python fire 库与 sys.argv 处理命令行参数
fire库 Python Fire 由Google开发,它使得命令行接口(CLI)的创建变得容易。使用Python Fire,可以将Python对象(如类、函数或字典)转换为可以从终端运行的命令行工具。这能够以一种简单而直观的方式与你的Py…...

PDF处理控件Aspose.PDF,如何实现企业级PDF处理
PDF处理为何成为开发者的“隐形雷区”? “手动调整200页PDF目录耗时3天,扫描件文字识别错误导致数据混乱,跨平台渲染格式崩坏引发客户投诉……” 作为开发者,你是否也在为PDF处理的复杂细节消耗大量精力?Aspose.PDF凭…...
Spring(1)——mvc概念,部分常用注解
1、什么是Spring Web MVC? Spring MVC 是一种基于 Java 的实现了 MVC(Model-View-Controller,模型 - 视图 - 控制器)设计模式的 Web 应用框架,它是 Spring 框架的一个重要组成部分,用于构建 Web 应用程序。…...
C语言(23)
字符串函数 11.strstr函数 1.1函数介绍: 头文件:string.h char *strstr ( const char * str1,const char *str2); 作用:在一个字符串(str1)中寻找另外一个字符串(str2)是否出现过 如果找到…...
Immich自托管服务的本地化部署与随时随地安全便捷在线访问数据
文章目录 前言1.关于Immich2.安装Docker3.本地部署Immich4.Immich体验5.安装cpolar内网穿透6.创建远程链接公网地址7.使用固定公网地址远程访问 前言 小伙伴们,你们好呀!今天要给大家揭秘一个超炫的技能——如何把自家电脑变成私人云相册,并…...
基于SpringBoot的在线付费问答系统设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

【Linux】信号处理以及补充知识
目录 一、信号被处理的时机: 1、理解: 2、内核态与用户态: 1、概念: 2、重谈地址空间: 3、处理时机: 补充知识: 1、sigaction: 2、函数重入: 3、volatile&…...

pandas——to_datatime用法
Pandas中pd.to_datetime的用法及示例 pd.to_datetime 是 Pandas 库中用于将字符串、整数或列表转换为日期时间(datetime)对象的核心函数。它在处理时间序列数据时至关重要,能够灵活解析多种日期格式并统一为标准时间类型。以下是其核心用法及…...

《DataWorks 深度洞察:量子机器学习重塑深度学习架构,决胜复杂数据战场》
在数字化浪潮汹涌澎湃的当下,大数据已然成为推动各行业发展的核心动力。身处这一时代洪流,企业对数据的处理与分析能力,直接关乎其竞争力的高低。阿里巴巴的DataWorks作为大数据领域的扛鼎之作,凭借强大的数据处理与分析能力&…...

Java 大视界 -- 基于 Java 的大数据实时数据处理框架性能评测与选型建议(121)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

多线程-JUC
简介 juc,java.util.concurrent包的简称,java1.5时引入。juc中提供了一系列的工具,可以更好地支持高并发任务 juc中提供的工具 可重入锁 ReentrantLock 可重入锁:ReentrantLock,可重入是指当一个线程获取到锁之后&…...

DeepSeek:中国AGI先锋,用技术重塑通用人工智能的未来
在ChatGPT掀起全球大模型热潮的背景下,中国AI领域涌现出一批极具创新力的技术公司,深度求索(DeepSeek)便是其中的典型代表。这家以“探索未知、拓展智能边界”为使命的AI企业,凭借长文本理解、逻辑推理与多模态技术的…...

Vue 框架深度解析:源码分析与实现原理详解
文章目录 一、Vue 核心架构设计1.1 整体架构流程图1.2 模块职责划分 二、响应式系统源码解析2.1 核心类关系图2.2 核心源码分析2.2.1 数据劫持实现2.2.2 依赖收集过程 三、虚拟DOM与Diff算法实现3.1 Diff算法流程图3.2 核心Diff源码 四、模板编译全流程剖析4.1 编译流程图4.2 编…...

Python爬虫获取淘宝快递费接口的详细指南
在电商运营中,快递费用的透明化和精准计算对于提升用户体验、优化物流成本以及增强市场竞争力至关重要。淘宝提供的 item_fee 接口能够帮助开发者快速获取商品的快递费用信息。本文将详细介绍如何使用 Python 爬虫技术结合 item_fee 接口,实现高效的数据…...

基于BMO磁性细菌优化的WSN网络最优节点部署算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 无线传感器网络(Wireless Sensor Network, WSN)由大量分布式传感器节点组成,用于监测物理或环境状况。节点部署是 WSN 的关键问…...

Android Activity的启动器ActivityStarter入口
Activity启动器入口 Android的Activity的启动入口是在ActivityStarter类的execute(),在该方法里面继续调用executeRequest(Request request) ,相应的参数都设置在方法参数request中。代码挺长,分段现在看下它的实现,分段一&#x…...

Python深度学习算法介绍
一、引言 深度学习是机器学习的一个重要分支,它通过构建多层神经网络结构,自动从数据中学习特征表示,从而实现对复杂模式的识别和预测。Python作为一门强大的编程语言,凭借其简洁易读的语法和丰富的库支持,成为深度学…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

自动加字幕软件推荐:口播视频如何批量加字幕过
口播视频加字幕,为什么越做越累?一位知识类博主连续两周日更3条口播视频,每条12–18分钟,需手动校对字幕、拆分金句切片、补气口停顿、匹配背景音乐——最后一条视频发布时,字幕错漏率达17%,平台审核未过。…...

免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南
免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...

Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼
Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/sh…...

LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环
更多请点击: https://codechina.net 第一章:LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环 核心架构概览 Claude端到端测试架构采用三层解耦设计:输入层(动态用…...