多线程-JUC
简介
juc,java.util.concurrent包的简称,java1.5时引入。juc中提供了一系列的工具,可以更好地支持高并发任务
juc中提供的工具
可重入锁 ReentrantLock
可重入锁:ReentrantLock,可重入是指当一个线程获取到锁之后,可以再次获取到当前锁。可重入锁一定程度上防止了死锁。
ReentrantLock提供的功能:
- 可重入:在获取到锁之后还可以再次获取这把锁
- 可打断:获取锁时的阻塞状态可以被interrupt方法打断
- 可超时:可以指定阻塞时长
- 多条件变量:synchronized只支持一个条件变量,这里条件变量是指调用wait方法、notify方法的锁对象,ReentrantLock可以实现在多个条件变量上等待和唤醒
- 可以指定内部使用公平锁还是非公平锁,默认使用非公平锁
ReentrantLock和synchronized都支持可重入,但是synchronized没有ReentrantLock提供的其它功能
使用案例
案例1:基本使用
10个线程,同时对同一个int变量执行1000次加加,确认结果是否正确。
private static final ReentrantLock LOCK = new ReentrantLock();
private static int count = 0;public static void main(String[] args) {List<Thread> list = new ArrayList<>();for (int i = 0; i < 10; i++) {Thread thread = new Thread(() -> {// 加锁LOCK.lock();try {for(int j = 0; j < 1000; j++) {// 访问共享资源count++;}} finally {// 释放锁LOCK.unlock();}});list.add(thread);thread.start();}for (Thread thread : list) {try {thread.join();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}// 验证结果,结果正确System.out.println(count);
}
案例2:属性方法
获取ReentrantLock的状态
private static final ReentrantLock LOCK = new ReentrantLock();public static void main(String[] args) throws InterruptedException {// 等待锁的线程Thread thread2 = new Thread(() -> {LOCK.lock();try {for (int i = 0; i < 100000; i++) {}} finally {LOCK.unlock();}}, "t2");// 拥有锁的线程new Thread(() -> {try {LOCK.lock();// 拥有锁的情况下锁的状态System.out.println("---拥有锁---");System.out.println("锁是否被某个线程持有 = " + LOCK.isLocked()); // trueSystem.out.println("重入次数 = " + LOCK.getHoldCount()); // 1System.out.println("锁是否被当前线程持有 = " + LOCK.isHeldByCurrentThread()); // trueSystem.out.println("阻塞队列中是否有等待锁的线程 = " + LOCK.hasQueuedThreads()); // trueSystem.out.println("线程2是否在阻塞队列中 = " + LOCK.hasQueuedThread(thread2)); // trueSystem.out.println("阻塞队列的长度 = " + LOCK.getQueueLength()); // 1System.out.println("锁是不是公平锁 = " + LOCK.isFair()); // false// java.util.concurrent.locks.ReentrantLock@6a53a7e9[Locked by thread t1]System.out.println("锁.toString方法 = " + LOCK.toString()); Thread.sleep(200);} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();} finally {LOCK.unlock();}}, "t1").start();thread2.start();Thread.sleep(1000L);// 没有上锁的情况下ReentrantLock的状态System.out.println("---没有锁---");System.out.println("锁是否被某个线程持有 = " + LOCK.isLocked()); // falseSystem.out.println("重入次数 = " + LOCK.getHoldCount()); // 0System.out.println("锁是否被当前线程持有 = " + LOCK.isHeldByCurrentThread()); // falseSystem.out.println("阻塞队列中是否有等待锁的线程 = " + LOCK.hasQueuedThreads()); // falseSystem.out.println("线程2是否在阻塞队列中 = " + LOCK.hasQueuedThread(thread2)); // falseSystem.out.println("阻塞队列的长度 = " + LOCK.getQueueLength()); // 0System.out.println("锁是不是公平锁 = " + LOCK.isFair()); // false// java.util.concurrent.locks.ReentrantLock@6a53a7e9[Unlocked]System.out.println("锁.toString方法 = " + LOCK.toString());
}
案例3:可超时
可以指定超时时间,超过指定时长没有获取锁,算失败
private static final ReentrantLock LOCK = new ReentrantLock();// 测试tryLock方法
public static void main(String[] args) {// 先启动一个线程占用锁new Thread(() -> {LOCK.lock();try {Utils.println("当前线程获取锁");Thread.sleep(5000);} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {Utils.println("当前线程释放锁");LOCK.unlock();}}).start();boolean tryLock = false;try{tryLock = LOCK.tryLock(4, TimeUnit.SECONDS);if (tryLock) {Utils.println("当前线程获取锁成功");} else {Utils.println("当前线程获取锁失败");}} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {if (tryLock) {Utils.println("当前线程释放锁");LOCK.unlock();}}
}
案例4:可打断
使用lockInterruptibly方法获取锁,线程的等待状态可以被interrupt方法打断,普通的lock方法则不会。
线程在等待状态下,如果外部调用了线程对象的interrupt方法,线程会结束等待状态,如果是可打断地获取锁,此时会抛出InterruptedException,结束获取锁的操作,然后需要用户处理这个异常。
private static final ReentrantLock LOCK = new ReentrantLock();// 测试lockInterruptibly方法
public static void main(String[] args) throws InterruptedException {new Thread(() -> {// 主线程先占住锁资源Utils.println("当前线程获取锁");LOCK.lock();try {try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}} finally {if (LOCK.isHeldByCurrentThread()) {Utils.println("当前线程释放锁");LOCK.unlock();}}}, "线程0").start();Thread.sleep(500);// 可打断地抢占锁资源Thread thread = new Thread(() -> {try {LOCK.lockInterruptibly();Utils.println("当前线程获取锁");} catch (InterruptedException e) {e.printStackTrace();Utils.println("当前线程被打断");} finally {if (LOCK.isHeldByCurrentThread()) {Utils.println("当前线程释放锁");LOCK.unlock();}}}, "线程1");thread.start();Thread.sleep(500);// 打断线程1,在lockInterruptibly方法获取锁时调用线程的interrupt方法,// lockInterruptibly方法会抛出InterruptedExceptionthread.interrupt();
}
条件对象 Condition
Condition:联合锁对象一起使用,表示条件对象,提供了类似于Object类中的wait、notify等方法的功能。
- 当调用Condition实例中的await、signal方法时,如果当前线程没有持有锁资源,则抛出非法监视器状态异常;
- 当线程调用Condition中的await方法时,线程放弃锁资源,进入等待列表,如果在等待过程中被打断,抛出中断异常
通过Condition,可以支持在一个锁对象上操作多个条件变量
常用api:
- await:
void await() throws InterruptedException:相当于Object类中的wait方法 - signal:
void signal():相当于Object类中的notify方法 - signalAll:
void signalAll():相当于Object类中的notifyAll方法
案例1:多条件变量
类似于生产者/消费者模式,只不过这个案例中有两个生产者、两个消费者,它们一一对应。
private static final List<Integer> list = new ArrayList<>();
private static final List<Integer> list2 = new ArrayList<>();
private static final ReentrantLock LOCK = new ReentrantLock();
private static final Condition condition = LOCK.newCondition();
private static final Condition condition2 = LOCK.newCondition();public static void main(String[] args) throws InterruptedException {// 消费者1new Thread(() -> {while (true) {LOCK.lock();try {if (list.isEmpty()) {condition.await();} else {System.out.println(Thread.currentThread().getName() + " 消费数据 " + list);list.clear();}} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {LOCK.unlock();}try {Thread.sleep(1000L);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "消费者1").start();// 生产者1new Thread(() -> {while (true) {LOCK.lock();try {if (list.isEmpty()) {list.addAll(createIntegerList(10));System.out.println(Thread.currentThread().getName() + " 生产数据 " + list);condition.signal();}} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {LOCK.unlock();}try {Thread.sleep(3000L);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "生产者1").start();// 消费者2new Thread(() -> {while (true) {LOCK.lock();try {if (list2.isEmpty()) {condition2.await();} else {System.out.println(Thread.currentThread().getName() + " 消费数据 " + list2);list2.clear();}} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {LOCK.unlock();}try {Thread.sleep(1000L);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "消费者2").start();// 生产者2new Thread(() -> {while (true) {LOCK.lock();try {if (list2.isEmpty()) {list2.addAll(createIntegerList(100));System.out.println(Thread.currentThread().getName() + " 生产数据 " + list2);condition2.signal();}} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {LOCK.unlock();}try {Thread.sleep(3000L);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "生产者2").start();
}public static List<Integer> createIntegerList(int bound) {List<Integer> list = new ArrayList<>();Random random = new Random();list.add(random.nextInt(bound));list.add(random.nextInt(bound));list.add(random.nextInt(bound));return list;
}
总结:这个案例比较粗糙,只是演示了一个锁对象在支持多个条件变量的情况,要注意,如果是一个生产者对应多个消费者,signal方法会唤醒等待队列中的第一个线程。
读写锁 ReentrantReadWriteLock
ReentrantReadWriteLock:可重入的读写锁,读锁和写锁使用同一个同步器,读读不冲突,读写冲突。写锁是互斥锁,读锁是共享锁。如果同步队列中有写锁,读锁会排在写锁之后
读写锁的使用规则:
- 读读不冲突:多个线程是可以同时获取读锁而不需要阻塞等待
- 读写冲突:一个线程获取了读锁,那么其他的线程要获取写锁 需要等待;同样的,一个线程获取了写锁,另外的想要获取读锁或者写锁都需要阻塞等待
- 锁降级:一个获取写锁的线程是可以在释放写锁之前再次获取读锁的,这就是锁降级
案例:一个使用读写锁来保护数据的容器
第一步:数据容器:
public class DataContainer {private Object data;private final ReentrantReadWriteLock LOCK = new ReentrantReadWriteLock();private final ReentrantReadWriteLock.ReadLock READ_LOCK = LOCK.readLock(); // 获取读锁private final ReentrantReadWriteLock.WriteLock WRITE_LOCK = LOCK.writeLock(); // 获取写锁/*** 读取数据*/public Object read(){Utils.println("获取读锁...");READ_LOCK.lock();try{Utils.println("读取数据...");Thread.sleep(1000);return data;} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();} finally {Utils.println("释放读锁...");READ_LOCK.unlock();}return null;}/*** 写入数据*/public void write(Object data){Utils.println("获取写锁...");WRITE_LOCK.lock();try{this.data = data;Utils.println("写入数据...");} finally {Utils.println("释放写锁...");WRITE_LOCK.unlock();}}
}
第二步:测试,读读不冲突
public static void main(String[] args) {DataContainer container = new DataContainer();// 两个线程同时获取读锁,读读不冲突new Thread(() -> {Object read = container.read();System.out.println("read = " + read);}).start();new Thread(() -> {Object read = container.read();System.out.println("read = " + read);}).start();
}
加戳的读写锁 StampedLock
StampedLock:自jdk8加入,对于读写锁的进一步优化。它提供了一种乐观读技术,读取完毕后需要做一次戳校验,如果校验通过,表示这期间确实没有写操作,数据可以安全使用,如果校验没有通过,需要重新获取锁,保证数据安全。适合于读多写少的场景
案例:
第一步:一个使用加戳读写锁保护的容器
public class DataContainerStamped {private Object data;private final StampedLock LOCK = new StampedLock();public Object read() {// 第一步:乐观地读取数据Object result = null;// 获取乐观读锁long stamp = LOCK.tryOptimisticRead();Utils.println("乐观地读取数据,stamp = " + stamp);try {Thread.sleep(3000L);result = data;} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}// 第二步:读完数据之后对戳进行校验if (LOCK.validate(stamp)) {Utils.println("乐观地读完数据,stamp = " + stamp);return result;}// 第三步:如果时间戳变了,证明数据有更新,需要重新读取数据Utils.println("更新读锁,stamp = " + stamp);try {stamp = LOCK.readLock();Utils.println("获取读锁, stamp = " + stamp);try {Thread.sleep(3000L);result = data;} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}} finally {Utils.println("释放读锁, stamp = " + stamp);LOCK.unlockRead(stamp);}return result;}public void write(Object newData) {long stamp = LOCK.writeLock();Utils.println("获取写锁,stamp = " + stamp);try {try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}this.data = newData;} finally {Utils.println("释放写锁,stamp = " + stamp);LOCK.unlockWrite(stamp);}}
}
第二步:验证乐观读,在读取数据的时候写入数据。结论是,写入数据会改变数据戳,乐观读完数据需要会校验戳,如果数据戳被改变,需要再次重新读取。
public static void main(String[] args) {DataContainerStamped container = new DataContainerStamped();new Thread(() -> {Object read = container.read();System.out.println("read = " + read);}).start();try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}new Thread(() -> container.write(10)).start();
}
原子类
原子类内部维护了一个数据,并且通过cas算法来操作这个数据,确保对这个数据的操作是线程安全的,同时又避免了锁竞争。
原子类适合处理单个变量需要在线程间共享的情况。
CAS算法
cas:compare and swap,比较和交换,实现无锁同步的一种算法
工作机制:CAS算法维护了3个变量:内存位置、预期原值、新值,它会使用预期原值和内存位置存储的值相比较,如果相同:进行交换操作,如果不同则不进行,整个比较并交换的操作是原子性的。
底层原理:在语法上,CAS算法操作的变量必须被volatile修饰,CAS算法的底层是基于CPU的原语支持,能够保证 “比较-交换”操作是原子性的。
CAS算法的优缺点:
- 优点:可以避免阻塞,CAS算法适合多核、并发量不高的情况
- 缺点:
- 只能保证一个共享变量的原子操作,如果是多个的话,就需要使用锁了。
- ABA问题:如果先将预期值A给成B,再改回A,那CAS操作就会误认为A的值从来没有被改变过,这时其他线程的CAS操作仍然能够成功。通过加入一个版本号来解决这个问题
- 如果并发量很大,CAS算法的性能可能会降低。因为如果并发量很大,重试必然频繁发生,这会导致效率降低
案例:
import sun.misc.Unsafe;
import java.lang.reflect.Field;public class CasTest {private volatile int a = 10;public static void main(String[] args) throws Exception {new CasTest().test();}public void test() throws Exception {Field field = Unsafe.class.getDeclaredField("theUnsafe");field.setAccessible(true);Unsafe unsafe = (Unsafe) field.get(null);// 获取字段a的内存偏移量Field fieldI = CasTest.class.getDeclaredField("a");long fieldIOffset = unsafe.objectFieldOffset(fieldI);// cas操作// 参数1:操作哪个对象// 参数2:操作对象上的哪个字段// 参数3:预期值// 参数4:新值boolean b = unsafe.compareAndSwapInt(this, fieldIOffset, 10, 11);assert b;assert a == 11;}
}
常用的原子类
AtomicInteger
内部维护了一个int类型的数据,对这个int类型的数据的所有操作都是原子性的。
案例1:两个线程同时修改原子类变量,只有一个可以修改成功
public static void main(String[] args) {AtomicInteger i = new AtomicInteger(10);int intValue = i.get();new Thread(() -> {boolean b = i.compareAndSet(intValue, 11);// 底层调用cas算法System.out.println(Thread.currentThread().getName() + " b = " + b);}, "t1").start();new Thread(() -> {boolean b = i.compareAndSet(intValue, 12);System.out.println(Thread.currentThread().getName() + " b = " + b);}, "t1").start();System.out.println("i = " + i.get()); // 11
}
案例2:10个线程,对一个原子类的变量各加加1000次,判断最终结果是否正确
public static void main(String[] args) throws InterruptedException {AtomicInteger i = new AtomicInteger(0);List<Thread> threads = new ArrayList<>();for (int j = 0; j < 10; j++) {Thread thread = new Thread(() -> {for (int k = 0; k < 1000; k++) {int i1 = i.getAndIncrement();}});threads.add(thread);thread.start();}// 等待线程执行结束for (Thread thread : threads) {thread.join();}System.out.println("i = " + i.get()); // 10000,结果正确
}
AtomicReference
内部维护了一个普通JavaBean的原子类,对这个bean的操作是原子性的,但是,不支持单独操作bean中的某个字段,必须整体替换bean。
案例:两个线程同时修改原子类变量,只有一个可以修改成功
public static void main(String[] args) throws InterruptedException {AtomicReference<User> userAtomicReference = new AtomicReference<>(new User("张三", 18));User user = userAtomicReference.get();new Thread(() -> {boolean b = userAtomicReference.compareAndSet(user, new User("李四", 19));System.out.println(Thread.currentThread().getName() + " b = " + b);}, "t1").start();new Thread(() -> {boolean b = userAtomicReference.compareAndSet(user, new User("王五", 20));System.out.println(Thread.currentThread().getName() + " b = " + b);}, "t2").start();Thread.sleep(1000);System.out.println("user = " + userAtomicReference.get()); // 李四 19
}
AtomicIntegerArray
操作数组的原子类,支持原子性地修改数组中的某个元素
案例:两个线程同时更新数组中某个下标处的值
public static void main(String[] args) throws InterruptedException {int[] intArr = new int[10];AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(intArr);new Thread(() -> {boolean b = atomicIntegerArray.compareAndSet(1, 0, 11);System.out.println(Thread.currentThread().getName() + " b = " + b);}).start();new Thread(() -> {boolean b = atomicIntegerArray.compareAndSet(1, 0, 12);System.out.println(Thread.currentThread().getName() + " b = " + b);}).start();Thread.sleep(100L);// 结论:只有一个线程可以更新成功,而且AtomicIntegerArray维护的是数组的拷贝而不是元数据,// 所以在原数组中看不出更新内容System.out.println("intArr[1] = " + atomicIntegerArray.get(1)); // 11System.out.println("intArr[1] = " + intArr[1]); // 0
}
AtomicStampedReference
使用一个版本号来解决ABA问题,每次操作都需要手动更新版本号。
案例:在主线程对变量进行修改的时候,发生了ABA问题
public static void main(String[] args) throws InterruptedException {AtomicReference<String> ref = new AtomicReference<>("A");// 主线程修改数据String prev = ref.get();// ABA操作:将数据从A改为B,再改回来new Thread(() -> Utils.println("change A -> B: "+ ref.compareAndSet("A", "B")), "t1").start();Thread.sleep(100L);new Thread(() -> Utils.println("change B -> A: "+ ref.compareAndSet("B", "A")), "t2").start();Thread.sleep(1000);Utils.println("change A -> C: " + ref.compareAndSet(prev, "C"));
}
案例:使用AtomicStampedReference解决ABA问题
public static void main(String[] args) throws InterruptedException {AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 1);// 主线程执行更新操作String prev = ref.getReference();int stamp = ref.getStamp(); // 1// 在这个过程中,其它线程执行了ABA操作new Thread(() -> {int stamp1 = ref.getStamp();Utils.println("change A -> B: "+ ref.compareAndSet("A", "B", stamp1, stamp1 + 1));}, "t1").start();Thread.sleep(100);new Thread(() -> {int stamp1 = ref.getStamp();Utils.println("change B -> A: "+ ref.compareAndSet("B", "A", stamp1, stamp1 + 1));}, "t2").start();Thread.sleep(1000);// 结果:主线程更新失败,解决了ABA问题Utils.println("change A -> C: "+ ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
累加器 LongAdder LongAccumulator
它们都是Java 8引入的高性能累加器,原理几乎一样,内部维护了一个base变量和Cell数组,将累加操作分散到多个槽中,减少竞争,需要累加值的时候,调用sum方法,把Cell数组中每个槽中的数据相加。累加器用于替换AtomicLong,它们更加适合高并发场景,因为CAS在高并发场景下性能可能会降低。它们的不同之处在于,LongAdder适合于简单的计算,LongAccumulator适合于需要复杂计算的累加场景,它可以定制计算规则
案例:LongAdder
public static void main(String[] args) {LongAdder longAdder = new LongAdder();longAdder.increment(); // 增加 1longAdder.add(10); // 增加 10System.out.println("总计数值: " + longAdder.sum()); // 输出:11longAdder.reset(); // 重置计数器System.out.println("重置后总值: " + longAdder.sum()); // 输出:0
}
案例:LongAccumulator
public static void main(String[] args) {// 定义累加规则为加法LongAccumulator longAccumulator = new LongAccumulator(Long::sum, 0);for (int i = 0; i < 10; i++) {new Thread(() -> {longAccumulator.accumulate(10);}).start();}System.out.println("longAccumulator.get() = " + longAccumulator.get()); // 100
}
总结
原子类通常以Atomic开头
juc中提供的原子类:
- 基本类型原子类:AtomicInteger、AtomicLong、AtomicBoolean
- 引用类型原子类:AtomicReference、AtomicStampedReference(解决ABA问题)
- 数组类型原子类:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
- 累加器:LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator
源码解析
原子类的源码比较简单,它的内部调用了Unsafe类的cas算法,通过它来保证线程安全,这里以AtomicInteger为例,了解原子类的工作机制,
public class AtomicInteger extends Number implements java.io.Serializable {// 封装了int类型的变量,并且变量被volatile修饰private volatile int value;// 获取int类型的变量在对象中的内存偏移量private static final Unsafe unsafe = Unsafe.getUnsafe();private static final long valueOffset;static {try {valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));} catch (Exception ex) { throw new Error(ex); }}// 通过cas算法,更新value字段的值public final boolean compareAndSet(int expect, int update) {return unsafe.compareAndSwapInt(this, valueOffset, expect, update);}
}
总结:原子类中封装的变量使用volatile修饰,使用cas算法来更新,保证线程的安全性
信号量
信号量:Semaphore,用来限制并发度的工具,避免并发了过大,从而达到保护程序的目的
使用案例:使用semaphore来线程线程的并发数量,同一时刻只能有三个线程同时运行
public static void main(String[] args) {Semaphore semaphore = new Semaphore(3);for (int i = 0; i < 10; i++) {new Thread(() -> {try {semaphore.acquire();} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}try {Utils.println("running...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}Utils.println("end...");} finally {semaphore.release();}}).start();}
}
常用api:
- acquire:
void acquire():从信号量获取一个许可,如果无可用许可前将一直阻塞等待 - acquire:
void acquire(int permits):获取指定数目的许可,如果无可用许可前也将会一直阻塞等待 - tryAcquire:
boolean tryAcquire():从信号量尝试获取一个许可,如果无可用许可,直接返回false,不会阻塞。它的重载方法可以获取指定数目的许可,也可以指定阻塞的时间 - release:
public void release():释放一个许可证,计数器加1
使用方式总结:
- 在构造信号量对象时,指定许可证数量,一个许可证对应一个线程,表示最多有多少个线程可以执行任务,
- 在每个线程中,执行任务前,调用acquire方法,获取许可证,semaphore对象中许可证数量减1
- 执行完任务后,调用release方法,释放许可证,semaphore对象中许可证数量加1
- 如果semaphore对象中许可证数量为0,线程调用acquire方法时会进入阻塞状态,直到其它线程释放许可证
- 通过这种方式,实现控制并发度的功能
LockSupport
用于创建锁和同步类的基本线程阻塞原语。当前线程调用LockSupport的park方法,可以进入阻塞状态,在线程外可以调用unpark方法,同时传入线程实例,可以让指定线程退出阻塞状态。
park和unpark与wait和notify的区别:
- wait、notify必须在同步块内调用,park、unpark不必
- notify和notifyAll无法精确控制唤醒哪一个线程,park和unpark可以
案例1:基本使用
// 先调用park方法
public static void main(String[] args) {Thread thread = new Thread(() -> {Utils.println("start");LockSupport.park();Utils.println("end");});thread.start();try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}Utils.println("解除指定线程的阻塞状态");// 再调用unpark方法LockSupport.unpark(thread);
}
案例2:在park方法之前调用unpark方法会怎么样?
public static void main(String[] args) {Thread thread = new Thread(() -> {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}Utils.println("start");LockSupport.park();Utils.println("end");});thread.start(); // 注意,线程必须先启动,否则针对它调用unpark方法没有效果。Utils.println("解除指定线程的阻塞状态");LockSupport.unpark(thread); // LockSupport类似于只有一张许可证的Semaphore
}
结论:先调用unpark方法会,park方法不会阻塞线程
LockSupport的源码非常简单,它的底层是基于Unsafe类的park、unpark方法,它只是直接调用了这两个方法,然后再传入其它必要的参数,比如超时时间。
倒计时锁
CountdownLatch:倒计时锁,做线程间的同步协作,在某个位置等待所有线程完成倒计时,然后再向下执行。
案例:使用CountDownLatch,实现主线程等待所有子线程执行完成后在执行的效果
public static void main(String[] args) {CountDownLatch latch = new CountDownLatch(3);new Thread(() -> {Utils.println("开始执行任务");Utils.sleep(1000);Utils.println("执行完成");latch.countDown();}).start();new Thread(() -> {Utils.println("开始执行任务");Utils.sleep(2000);Utils.println("执行完成");latch.countDown();}).start();new Thread(() -> {Utils.println("开始执行任务");Utils.sleep(1500);Utils.println("执行完成");latch.countDown();}).start();Utils.println("等待中");try {latch.await();} catch (InterruptedException e) {e.printStackTrace();Thread.currentThread().interrupt();}Utils.println("等待结束");
}
使用方式总结:
- 第一步:构建倒计时锁,构造函数中指定需要等待多少个任务完成
- 第二步:主线程调用await方法,进入阻塞,用来等待计数器归零
- 第三步:执行任务的线程,执行完任务后,调用countDown方法,计数器减1,表示执行完一个任务了
- 结果:当所有任务都执行完后,await方法结束阻塞
循环栅栏
循环栅栏:CyclicBarrier,允许一组线程互相等待,直到到达某个公共屏障点,并且在释放等待线程后可以重用。CyclicBarrier的字面意思是可循环使用的屏障。它要做的事情是,让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
作用:适用于一组线程中的每一个线程需要都等待所有线程完成任务后再继续执行下一次任务的场景
CountDownLatch和CyclicBarrier的异同:
- 相同点:都有让多个线程等待同步然后再开始下一步动作的意思
- 不同点:
- CountDownLatch的下一步的动作实施者是主线程,具有不可重复性;
- CyclicBarrier的下一步动作实施者还是“其他线程”本身,具有往复多次实施动作的特点。
案例:
public static void main(String[] args) {// 第一步:指定需要同步的线程数和所有线程都到达同步点之后需要执行的方法CyclicBarrier barrier = new CyclicBarrier(2, // 只有所有线程到达同步点之后,才会执行这个任务() -> Utils.println("任务结束"));ExecutorService pool = Executors.newFixedThreadPool(2);pool.submit(() -> {try {Thread.sleep(1000L);} catch (InterruptedException e) {throw new RuntimeException(e);}Utils.println("任务1执行");try {// 第二步:执行任务的线程到达同步点barrier.await();} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();Thread.currentThread().interrupt();}Utils.println("任务1执行完成");});pool.submit(() -> {try {Thread.sleep(2000L);} catch (InterruptedException e) {throw new RuntimeException(e);}Utils.println("任务2执行");try {// 第二步:执行任务的线程到达同步点。barrier.await();} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();Thread.currentThread().interrupt();}Utils.println("任务2执行完成");});pool.shutdown();
}
源码解析
循环栅栏不像其他工具类那样,内部依赖AQS,它的内部只使用了可重入锁。线程会阻塞在wait方法,直到所有的线程都执行到wait方法,再一起向下执行,接下来看一下它是如何做到的?
核心代码:
// wait方法的内部会调用dowait方法
private int dowait(boolean timed, long nanos)throws InterruptedException, BrokenBarrierException,TimeoutException {final ReentrantLock lock = this.lock;lock.lock(); // 加锁try {final Generation g = generation; // 代表循环栅栏的一次运行if (g.broken)throw new BrokenBarrierException();if (Thread.interrupted()) {breakBarrier();throw new InterruptedException();}// 所有线程都会执行wait方法,--count,表示当前线程执行到了wait方法,数值减1int index = --count;// 如果count等于0,表示所有线程都执行到了wait方法,执行预先定义好的异步任务if (index == 0) { // trippedboolean ranAction = false;try {final Runnable command = barrierCommand;if (command != null)command.run();ranAction = true;nextGeneration(); // 循环栅栏的下一次运行return 0;} finally {if (!ranAction)breakBarrier(); // 打破屏障,唤醒进入等待状态的线程}}// 如果count不等于0,证明需要等待,在上面count=0的分支中,会唤醒等待中的线程// loop until tripped, broken, interrupted, or timed outfor (;;) { // 自旋try {// 进入等待状态if (!timed)trip.await();else if (nanos > 0L)nanos = trip.awaitNanos(nanos);} catch (InterruptedException ie) {if (g == generation && ! g.broken) {breakBarrier();throw ie;} else {// We're about to finish waiting even if we had not// been interrupted, so this interrupt is deemed to// "belong" to subsequent execution.Thread.currentThread().interrupt();}}if (g.broken)throw new BrokenBarrierException();if (g != generation)return index;// 如果等待超时,同样打破屏障if (timed && nanos <= 0L) {breakBarrier();throw new TimeoutException();}}} finally {lock.unlock();}
}// 打破屏障
private void breakBarrier() {generation.broken = true;count = parties;trip.signalAll();
}
总结:wait方法表示屏障点,线程会被阻塞在wait方法处,直到所有线程都执行到wait方法,会执行指定的异步任务,然后唤醒阻塞的线程。
线程安全的集合类
jdk1.8之前提供的安全集合:HashTable、Vector,它们的实现比较粗糙,直接使用synchronized关键字修饰整个方法。
使用Collections工具类中提供的方法,修饰一个集合。案例:List<String> list = Collections.synchronizedList(new ArrayList<String>()),使用一个线程安全的集合来包装用户提供的集合,但是线程安全的集合中,所有的方法都是被synchronized修饰的,效率比较低下。
juc的安全集合:
- BlockingXXX:LinkedBlockingQueue、ArrayBlockingQueue,基于JUC中提供的锁,线程池使用这两个个队列作为阻塞队列
- CopyOnWriteXXX:CopyOnWriteArrayList、CopyOnWriteArraySet,基于锁,写时复制,适合读多写少的场景。
- ConcurrentXXX:ConcurrentHashMap,通过cas算法和局部加锁的方式优化了性能
ArrayBlockingQueue
基于数组的同步队列,内部使用ReentrantLock,所有的读写操作全部加锁
// 元素入队的方法
public boolean offer(E e) {checkNotNull(e);// 加锁final ReentrantLock lock = this.lock;lock.lock();try {if (count == items.length)return false;else {enqueue(e); // 入队return true;}} finally {lock.unlock(); // 释放锁}
}// 查看队列头部的元素,内部也会加锁
public E peek() {final ReentrantLock lock = this.lock;lock.lock();try {return itemAt(takeIndex); // null when queue is empty} finally {lock.unlock();}
}
CopyOnWriteArrayList
copy on write,写时复制,当对集合进行修改操作时,不会直接修改原数组,而是创建一个新的数组副本,在副本上进行修改,然后将原数组替换为新数组。这种机制确保了在修改过程中,读操作不会受到影响,因为读操作始终基于原数组进行。
适用于读多写少的场景:由于写操作需要创建数组副本,写操作的性能开销较大,但读操作的性能非常高效,因此,非常适合读操作频繁且写操作较少的场景
// 向集合中添加数据的源码
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock(); // 加锁try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1); // 创建原先数组的复制品newElements[len] = e;setArray(newElements); // 使用复制好的数组替换原数组return true;} finally {lock.unlock();}
}
ConcurrentHashMap
使用方法和HashMap相同,但它是线程安全的。通过cas算法和局部加锁(只锁住某个节点)的方式,尽可能的避免锁和减小锁的粒度,以此来优化性能。这里简单了解一下它的工作机制
// 首先,存储数据的数组,使用volatile修饰,确保修改可以立刻被其他线程看到
transient volatile Node<K,V>[] table;
添加元素的核心方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();// 计算key的哈希值int hash = spread(key.hashCode());int binCount = 0;// 死循环,自旋for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 如果存储元素的数组为null,初始化数组,这里就是在第一次put元素的时候初始化数组if (tab == null || (n = tab.length) == 0)tab = initTable();// 根据哈希值计算元素的下标,如果下标处没有值,进入当前分支else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 使用cas算法,更新下标处的值,如果更新成功,退出,// 这个过程是不加锁的,使用cas算法可以保证线程安全if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// 判断是否正在扩容,如果是,帮助扩容else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {// 下标处有值,发生哈希冲突V oldVal = null;// 只在这一个节点上加锁synchronized (f) {// 再次判断,判断当前节点没有发生变化,否则它有可能已经被其他线程更新了。if (tabAt(tab, i) == f) {// 处理链表if (fh >= 0) { // 哈希值大于0,证明它没有在扩容,并且不是树节点binCount = 1;// 遍历链表for (Node<K,V> e = f;; ++binCount) { K ek;// 如果找到相同的key,更新valueif (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}// 将新节点挂载到链表的尾部Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 处理红黑树else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 判断是否需要扩容if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i); // 扩容,或者将链表转换为红黑树if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}
总结:通过cas算法来向数组中写入元素,写元素时如果发生哈希冲突,只在发生冲突的节点上加锁,尽可能减小锁的粒度。
读取元素是不需要加锁的,因为元素使用volatile修饰,其它线程可以立刻看到元素的变化
相关文章:

多线程-JUC
简介 juc,java.util.concurrent包的简称,java1.5时引入。juc中提供了一系列的工具,可以更好地支持高并发任务 juc中提供的工具 可重入锁 ReentrantLock 可重入锁:ReentrantLock,可重入是指当一个线程获取到锁之后&…...

DeepSeek:中国AGI先锋,用技术重塑通用人工智能的未来
在ChatGPT掀起全球大模型热潮的背景下,中国AI领域涌现出一批极具创新力的技术公司,深度求索(DeepSeek)便是其中的典型代表。这家以“探索未知、拓展智能边界”为使命的AI企业,凭借长文本理解、逻辑推理与多模态技术的…...

Vue 框架深度解析:源码分析与实现原理详解
文章目录 一、Vue 核心架构设计1.1 整体架构流程图1.2 模块职责划分 二、响应式系统源码解析2.1 核心类关系图2.2 核心源码分析2.2.1 数据劫持实现2.2.2 依赖收集过程 三、虚拟DOM与Diff算法实现3.1 Diff算法流程图3.2 核心Diff源码 四、模板编译全流程剖析4.1 编译流程图4.2 编…...

Python爬虫获取淘宝快递费接口的详细指南
在电商运营中,快递费用的透明化和精准计算对于提升用户体验、优化物流成本以及增强市场竞争力至关重要。淘宝提供的 item_fee 接口能够帮助开发者快速获取商品的快递费用信息。本文将详细介绍如何使用 Python 爬虫技术结合 item_fee 接口,实现高效的数据…...

基于BMO磁性细菌优化的WSN网络最优节点部署算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 无线传感器网络(Wireless Sensor Network, WSN)由大量分布式传感器节点组成,用于监测物理或环境状况。节点部署是 WSN 的关键问…...

Android Activity的启动器ActivityStarter入口
Activity启动器入口 Android的Activity的启动入口是在ActivityStarter类的execute(),在该方法里面继续调用executeRequest(Request request) ,相应的参数都设置在方法参数request中。代码挺长,分段现在看下它的实现,分段一&#x…...

Python深度学习算法介绍
一、引言 深度学习是机器学习的一个重要分支,它通过构建多层神经网络结构,自动从数据中学习特征表示,从而实现对复杂模式的识别和预测。Python作为一门强大的编程语言,凭借其简洁易读的语法和丰富的库支持,成为深度学…...

关于sqlalchemy的使用
关于sqlalchemy的使用 说明一、sqlachemy总体使用思路二、安装与创建库、连结库三、创建表、增加数据四、查询记录五、更新或删除六、关联表定义七、一对多关联查询八、映射类定义与添加记录 说明 本教程所需软件及库python3.10、sqlalchemy安装与创建库、连结库创建表、增加数…...
利用LLMs准确预测旋转机械(如轴承)的剩余使用寿命(RUL)
研究背景 研究问题:如何准确预测旋转机械(如轴承)的剩余使用寿命(RUL),这对于设备可靠性和减少工业系统中的意外故障至关重要。研究难点:该问题的研究难点包括:训练和测试阶段数据分布不一致、长期RUL预测的泛化能力有限。相关工作:现有工作主要包括基于模型的方法、数…...

深度学习 PyTorch 中 18 种数据增强策略与实现
深度学习pytorch之简单方法自定义9类卷积即插即用 数据增强通过对训练数据进行多种变换,增加数据的多样性,它帮助我们提高模型的鲁棒性,并减少过拟合的风险。PyTorch 提供torchvision.transforms 模块丰富的数据增强操作,我们可以…...

视觉图像处理
在MATLAB中进行视觉图像处理仿真通常涉及图像增强、滤波、分割、特征提取等操作。以下是一个分步指南和示例代码,帮助您快速入门: 1. MATLAB图像处理基础步骤 1.1 读取和显示图像 % 读取图像(替换为实际文件路径) img = imread(lena.jpg); % 显示原图 figure; subplot(2…...

深度学习与普通神经网络有何区别?
深度学习与普通神经网络的主要区别体现在以下几个方面: 一、结构复杂度 普通神经网络:通常指浅层结构,层数较少,一般为2-3层,包括输入层、一个或多个隐藏层、输出层。深度学习:强调通过5层以上的深度架构…...

Vue3、vue学习笔记
<!-- Vue3 --> 1、Vue项目搭建 npm init vuelatest cd 文件目录 npm i npm run dev // npm run _ 这个在package.json中查看scripts /* vue_study\.vscode可删 // vue_study\src\components也可删除(基本语法,不使用组件) */ // vue_study\.vscode\lau…...

python中C#类库调用+调试方法~~~
因为开发需要,我们经常会用C#来写一些库供python调用,但是在使用过程中难免会碰到一些问题,需要我们抽丝剥茧来解决~~~ 首先,我们在python中要想调用C#(基于.net)的dll,需要安装一个库,它就是 pythonnet …...

L33.【LeetCode笔记】循环队列(数组解法)
目录 1.题目 2.分析 方法1:链表 尝试使用单向循环链表模拟 插入节点 解决方法1:开辟(k1)个节点 解决方法2:使用变量size记录队列元素个数 获取队尾元素 其他函数的实现说明 方法2:数组 重要点:指针越界的解决方法 方法1:单独判断 方法2:取模 3.数组代码的逐步实现…...

css实现元素垂直居中显示的7种方式
文章目录 * [【一】知道居中元素的宽高](https://blog.csdn.net/weixin_41305441/article/details/89886846#_1) [absolute 负margin](https://blog.csdn.net/weixin_41305441/article/details/89886846#absolute__margin_2) [absolute margin auto](https://blog.csdn.net…...

【Python】Django 中的算法应用与实现
Django 中的算法应用与实现 在 Django 开发中,算法的应用可以极大地扩展 Web 应用的功能和性能。从简单的数据处理到复杂的机器学习模型,Django 都可以作为一个强大的后端框架来支持这些算法的实现。本文将介绍几种常见的算法及其在 Django 中的使用方法…...

Docker 运行 GPUStack 的详细教程
GPUStack GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。它具有广泛的硬件兼容性,支持多种品牌的 GPU,并能在 Apple MacBook、Windows PC 和 Linux 服务器上运行。GPUStack 支持各种 AI 模型,包括大型语言模型(LLMs&am…...
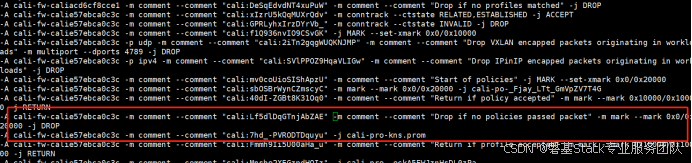
Kubernetes中的 iptables 规则介绍
#作者:邓伟 文章目录 一、Kubernetes 网络模型概述二、iptables 基础知识三、Kubernetes 中的 iptables 应用四、查看和调试 iptables 规则五、总结 在 Kubernetes 集群中,iptables 是一个核心组件, 用于实现服务发现和网络策略。iptables 通…...
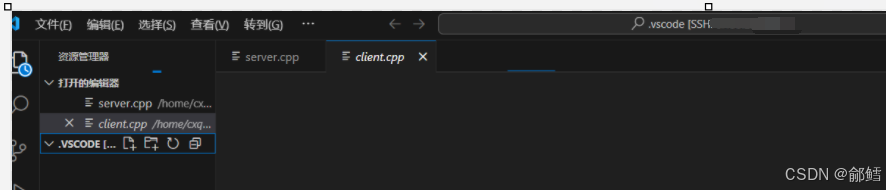
解决VScode 连接不上问题
问题 :VScode 连接不上 解决方案: 1、手动杀死VS Code服务器进程,然后重新尝试登录 打开xshell ,远程连接服务器 ,查看vscode的进程 ,然后全部杀掉 [cxqiZwz9fjj2ssnshikw14avaZ ~]$ ps ajx | grep vsc…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...