python爬虫--xpath模块简介
一、前言
前两篇博客讲解了爬虫解析网页数据的两种常用方法,re正则表达解析和beautifulsoup标签解析,所以今天的博客将围绕另外一种数据解析方法,它就是xpath模块解析,话不多说,进入内容:
一、简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
xpath是最常用且最便捷高效的一种解析方式,通用型强,其不仅可以用于python语言中,还可以用于其他语言中,数据解析建议首先xpath。
二、安装
pip3 install lxml
三、使用
1、导入
from lxml import etree
2、基本使用
实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中
调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
from lxml import etree
tree = etree.parse('./tree.html') #从本地加载源码,实例化一个etree对象。必须是本地的文件,不能是字符串
tree = etree.HTML(源码) #从互联网加载源码,实例化etree对象
# / 表示从从根节点开始,一个 / 表示一个层级,//表示多个层级
r = tree.xpath('//div//a') #以列表的形式返回div下的所有的a标签对象的地址
r = tree.xpath('//div//a')[1] #返回div下的第二个a标签对象地址
r = tree.xpath('//div[@class="tang"]') #以列表的形式返回tang标签地址
r = tree.xpath('//div[@class="tang"]//a') #以列表的形式返回tang标签下所有的a标签地址
#获取标签中的文本内容
r = tree.xpath('//div[@class="tang"]//a/text()') #以列表的形式返回所有a标签中的文本
#获取标签中属性值
r = tree.xpath('//div//a/@href') ##以列表的形式返回所有a标签中href属性值3、基本使用
from lxml import etreewb_data = """<div><ul><li><a href="link1.html">first item</a></li><li><a href="link2.html">second item</a></li><li><a href="link3.html">third item</a></li><li><a href="link4.html">fourth item</a></li><li><a href="link5.html">fifth item</a></ul></div>"""
html = etree.HTML(wb_data)
print(html)
result = etree.tostring(html)
print(result.decode("utf-8"))
从下面的结果来看,我们打印机html其实就是一个python对象,etree.tostring(html)则是补全html的基本写法,补全了缺胳膊少腿的标签。
<Element html at 0x39e58f0> <html><body><div><ul><li><a href="link1.html">first item</a></li><li><a href="link2.html">second item</a></li><li><a href="link3.html">third item</a></li><li><a href="link4.html">fourth item</a></li><li><a href="link5.html">fifth item</a></li></ul></div></body></html>
3、获取某个标签的内容(基本使用),注意,获取a标签的所有内容,a后面就不用再加正斜杠,否则报错。
写法一
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a')
print(html)
for i in html_data:print(i.text)# 打印结果如下:
<Element html at 0x12fe4b8>
first item
second item
third item
fourth item
fifth item
写法二(直接在需要查找内容的标签后面加一个/text()就行)
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()')
print(html)
for i in html_data:print(i)# 打印结果如下:
<Element html at 0x138e4b8>
first item
second item
third item
fourth item
fifth item
4、打开读取html文件
#使用parse打开html的文件
html = etree.parse('test.html')
html_data = html.xpath('//*')<br>#打印是一个列表,需要遍历
print(html_data)
for i in html_data:print(i.text)
html = etree.parse('test.html')
html_data = etree.tostring(html,pretty_print=True)
res = html_data.decode('utf-8')
print(res)打印:
<div><ul><li><a href="link1.html">first item</a></li><li><a href="link2.html">second item</a></li><li><a href="link3.html">third item</a></li><li><a href="link4.html">fourth item</a></li><li><a href="link5.html">fifth item</a></li></ul>
</div>
5、打印指定路径下a标签的属性(可以通过遍历拿到某个属性的值,查找标签的内容)
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/@href')
for i in html_data:print(i)打印:
link1.html
link2.html
link3.html
link4.html
link5.html
6、我们知道我们使用xpath拿到得都是一个个的ElementTree对象,所以如果需要查找内容的话,还需要遍历拿到数据的列表。
查到绝对路径下a标签属性等于link2.html的内容。
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a[@href="link2.html"]/text()')
print(html_data)
for i in html_data:print(i)打印:
['second item']
second item
7、上面我们找到全部都是绝对路径(每一个都是从根开始查找),下面我们查找相对路径,例如,查找所有li标签下的a标签内容。
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a/text()')
print(html_data)
for i in html_data:print(i)打印:
['first item', 'second item', 'third item', 'fourth item', 'fifth item']
first item
second item
third item
fourth item
fifth item
8、上面我们使用绝对路径,查找了所有a标签的属性等于href属性值,利用的是/—绝对路径,下面我们使用相对路径,查找一下l相对路径下li标签下的a标签下的href属性的值,注意,a标签后面需要双//。
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a//@href')
print(html_data)
for i in html_data:print(i)打印:
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
link1.html
link2.html
link3.html
link4.html
link5.html
9、相对路径下跟绝对路径下查特定属性的方法类似,也可以说相同。
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a[@href="link2.html"]')
print(html_data)
for i in html_data:print(i.text)打印:
[<Element a at 0x216e468>]
second item
10、查找最后一个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()]/a/text()')
print(html_data)
for i in html_data:print(i)打印:
['fifth item']
fifth item
11、查找倒数第二个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)
for i in html_data:print(i)打印:
['fourth item']
fourth item
四、案例
案例1:获取58商城房价单位:
import requests
from lxml import etree
url = "https://bj.58.com/ershoufang/p1/"
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}
pag_response = requests.get(url,headers=headers,timeout=3).text
#实例化一个etree对象
tree = etree.HTML(pag_response)
r = tree.xpath('//span[@class="content-title"]/text()') #获取所有//span标签为"content-title"的文本内容,列表形式
with open("58房价.txt",mode="w",encoding="utf-8") as fp:for r_list in r:fp.writelines(str(r_list))print(r_list)

案例2:获取豆瓣top榜电影信息(这个是老生常谈的话题了)
import re
from time import sleep
import requests
from lxml import etree
import random
import csvdef main(page,f):url = f'https://movie.douban.com/top250?start={page*25}&filter='headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',}resp = requests.get(url,headers=headers)tree = etree.HTML(resp.text)# 获取详情页的链接列表href_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/@href')# 获取电影名称列表name_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')for url,name in zip(href_list,name_list):f.flush() # 刷新文件try:get_info(url,name) # 获取详情页的信息except:passsleep(1 + random.random()) # 休息print(f'第{i+1}页爬取完毕')def get_info(url,name):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36','Host': 'movie.douban.com',}resp = requests.get(url,headers=headers)html = resp.texttree = etree.HTML(html)# 导演dir = tree.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]# 电影类型type_ = re.findall(r'property="v:genre">(.*?)</span>',html)type_ = '/'.join(type_)# 国家country = re.findall(r'地区:</span> (.*?)<br',html)[0]# 上映时间time = tree.xpath('//*[@id="content"]/h1/span[2]/text()')[0]time = time[1:5]# 评分rate = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]# 评论人数people = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span/text()')[0]print(name,dir,type_,country,time,rate,people) # 打印结果csvwriter.writerow((name,dir,type_,country,time,rate,people)) # 保存到文件中if __name__ == '__main__':# 创建文件用于保存数据with open('03-movie-xpath.csv','a',encoding='utf-8',newline='')as f:csvwriter = csv.writer(f)# 写入表头标题csvwriter.writerow(('电影名称','导演','电影类型','国家','上映年份','评分','评论人数'))for i in range(10): # 爬取10页main(i,f) # 调用主函数sleep(3 + random.random())

相关文章:
python爬虫--xpath模块简介
一、前言 前两篇博客讲解了爬虫解析网页数据的两种常用方法,re正则表达解析和beautifulsoup标签解析,所以今天的博客将围绕另外一种数据解析方法,它就是xpath模块解析,话不多说,进入内容: 一、简介 XPat…...

【论文阅读】基于意图的网络(Intent-Based Networking,IBN)研究综述
IBN研究综述一、IBN体系结构1.1 体系结构:1.2 闭环流程:1.3 IBN的自动化程度(逐步向前演进):二、IBN 的实现方式2.1 意图获取:2.1.1 YANG、NEMO2.1.2 Frenetic、NetKAT、LAI2.2 意图转译:2.2.1 iNDIRA系统2.2.2 基于模…...
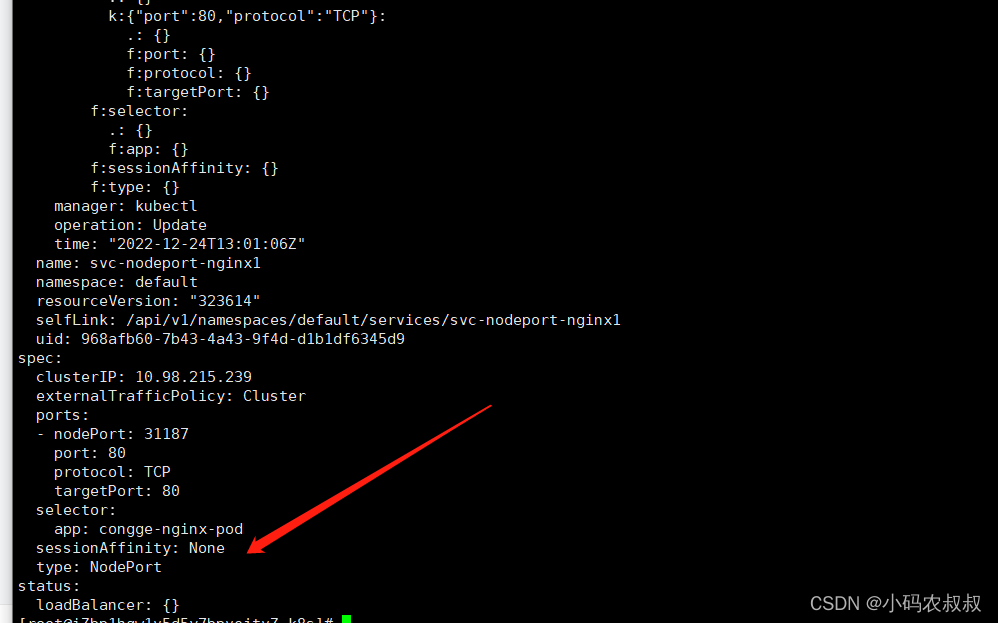
【云原生kubernetes】k8s service使用详解
一、什么是服务service? 在k8s里面,每个Pod都会被分配一个单独的IP地址,但这个IP地址会随着Pod的销毁而消失,重启pod的ip地址会发生变化,此时客户如果访问原先的ip地址则会报错 ; Service (服务)就是用来解决这个问题的…...

Python 数据可视化的 3 大步骤,你知道吗?
Python实现可视化的三个步骤: 确定问题,选择图形转换数据,应用函数参数设置,一目了然 1、首先,要知道我们用哪些库来画图? matplotlib Python中最基本的作图库就是matplotlib,是一个最基础的Python可视…...

CSS基础:盒子模型和浮动
盒子模型 所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用 CSS盒模型本质上是一个盒子,封装HTML元素。 它包括:外边距(margin),边框(bord…...
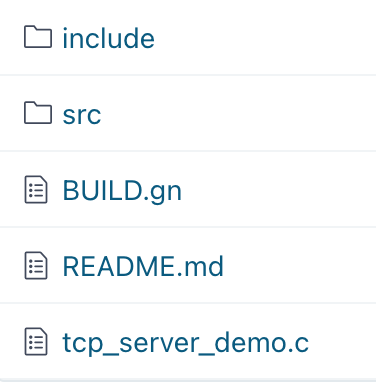
OpenHarmony使用Socket实现一个TCP服务端详解
点击获取BearPi-HM_Nano源码 ,以D4_iot_tcp_server为例: 点击查看:上一篇关于socket udp实现的解析 查看 TCPServerTask 方法实现: static void TCPServerTask(void) {//连接WifiWifiConnect("TP-LINK_65A8",...

kafka监控工具安装和使用
1. KafkaOffsetMonitor 该监控是基于一个jar包的形式运行,部署较为方便。只有监控功能,使用起来也较为安全(1)消费者组列表 (2)查看topic的历史消费信息. (3)每个topic的所有parition列表(topic,pid,offset,logSize,lag,owner) (4)对consumer消费情况进…...

近期工作感悟
从应届生变为社畜已经半年了,在这里吐槽一下自己的所想给自己看。 首先是心理层面上的,初期大大增加的压力。 我觉得应届生能够来到大厂的,基本都是在大学有去规划学习,对自己技能比较认可的。比如我在学校自学游戏开发ÿ…...
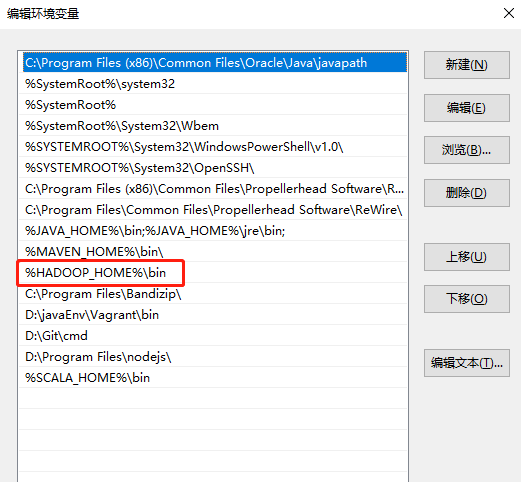
大数据框架之Hadoop:HDFS(三)HDFS客户端操作(开发重点)
3.1 HDFS客户端环境准备 1.根据自己电脑的操作系统拷贝对应的编译后的hadoop jar包到非中文路径(例如:D:\javaEnv\hadoop-2.77),如下图所示。 2.配置HADOOP_HOME环境变量,如下图所示。 3&#…...
多模式支持无线监控技术:主动式定位、被动式定位
物联网空间信息与数字技术发展至今,已经催生了一大批优秀的践行者。在日常与商业应用中,室内外定位领域依托于这一技术的发展,更是在近几年风光无限。但是并不是说室内定位与室外定位都已经相当成熟,相对来说,室内定位…...
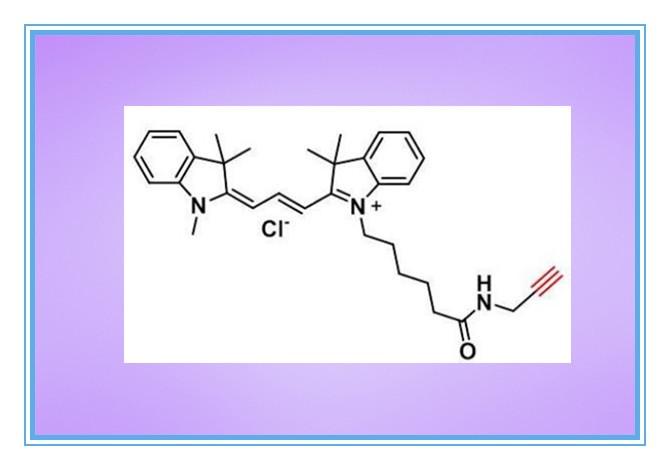
Cy5 Alkyne,1223357-57-0,花青素Cyanine5炔基,氰基5炔烃
CAS号:1223357-57-0 | 英文名: Cyanine5 alkyne,Cy5 Alkyne | 中文名:花青素CY5炔基CASNumber:1223357-57-0Molecular formula:C35H42ClN3OMolecular weight:556.19Purity:95%Appear…...
【MySQL】MySQL 中 WITH 子句详解:从基础到实战示例
文章目录一、什么是 WITH 子句1. 定义2.用途二、WITH 子句的语法和用法1.语法2.使用示例3.优点三、总结"梦想不会碎,只有被放弃了才会破灭。" "Dreams wont break, only abandoned will shatter."一、什么是 WITH 子句 1. 定义 WITH 子句是 M…...
c/c++开发,无可避免的模板编程实践(篇一)
一、c模板 c开发中,在声明变量、函数、类时,c都会要求使用指定的类型。在实际项目过程中,会发现很多代码除了类型不同之外,其他代码看起来都是相同的,为了实现这些相同功能,我们可能会进行如下设计…...

mulesoft MCIA 破釜沉舟备考 2023.02.13.04
mulesoft MCIA 破釜沉舟备考 2023.02.13.03 1. An integration Mule application consumes and processes a list of rows from a CSV file.2. One of the backend systems involved by the API implementation enforces rate limits on the number of request a particle clie…...
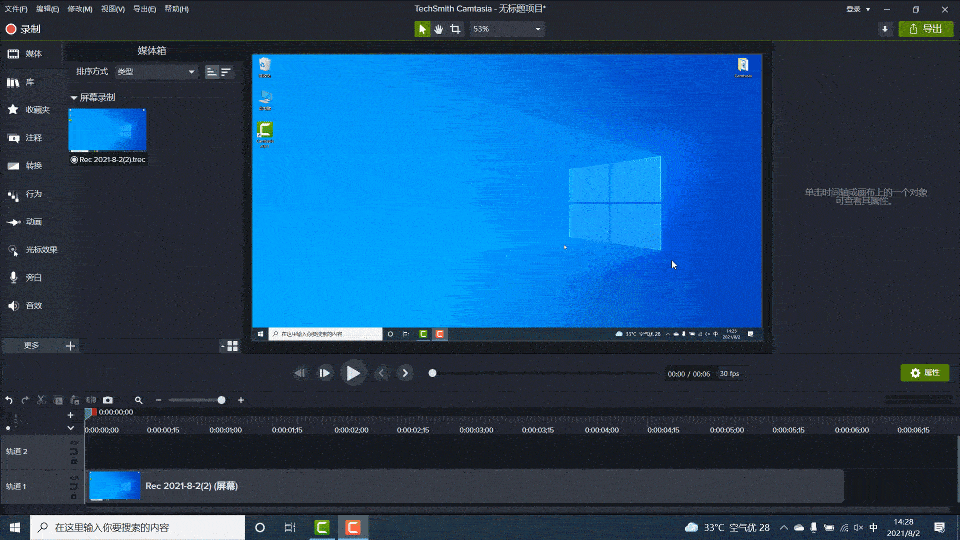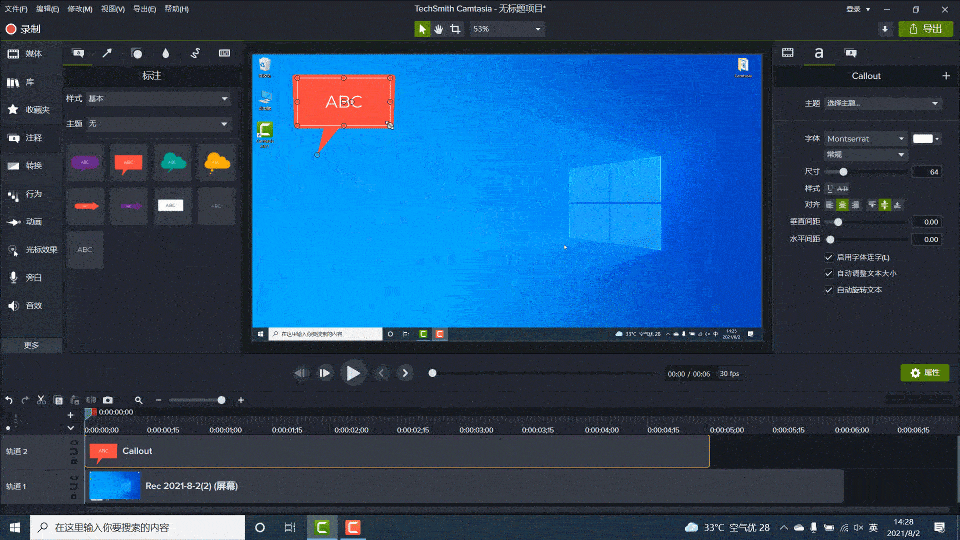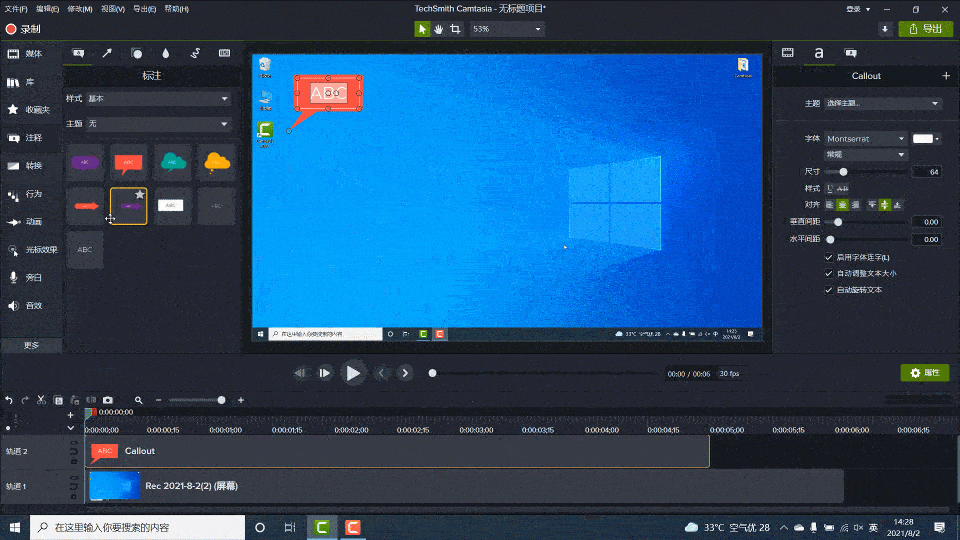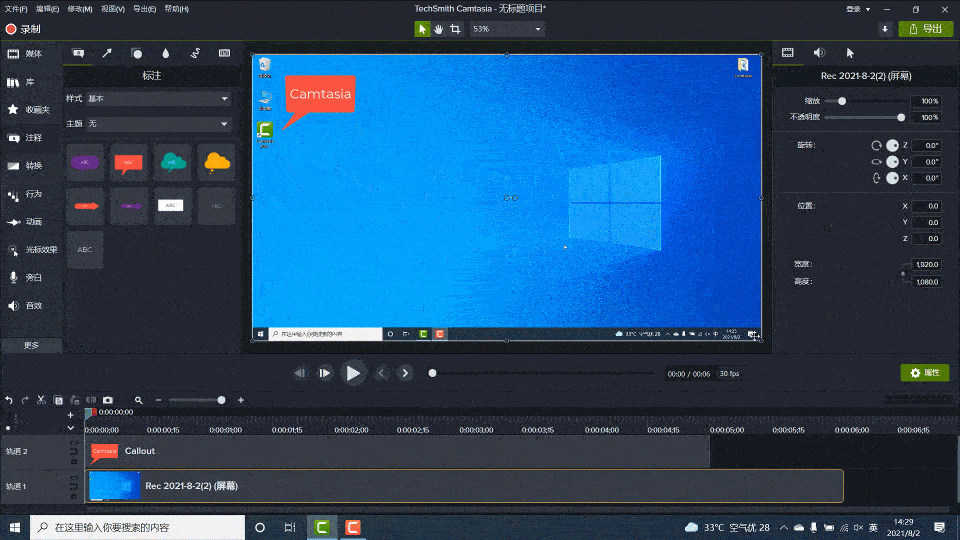
Camtasia2023最新版本新功能及快捷键教程
使用Camtasia,您可以毫不费力地在计算机的显示器上录制专业的活动视频。除了录制视频外,Camtasia还允许您从外部源将高清视频导入到录制中。Camtasia的独特之处在于它可以创建包含可单击链接的交互式视频,以生成适用于教室或工作场所的动态视…...
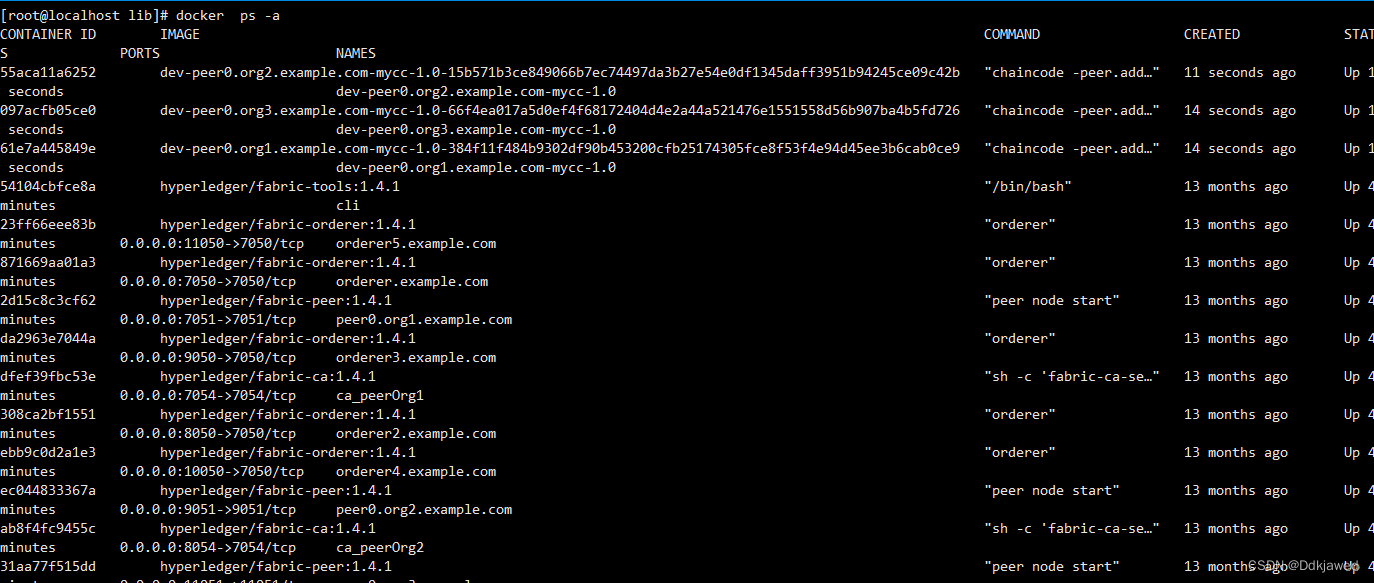
Fabric磁盘扩容后数据迁移
线上环境原来的磁盘比较小,随着业务数据的增多,磁盘需要扩容,因此需要把原来docker数据转移至新的数据盘。 数据迁移 操作系统: centOS 7 docker默认的数据目录为/var/lib/docker 创建一个新的目录/opt/dockerdata&…...

大厂光环下的功能测试,出去面试自动化一问三不知
在一家公司待久了技术能力反而变弱了,原来的许多知识都会慢慢遗忘,这种情况并不少见。一个京东员工发帖吐槽:感觉在大厂快待废了,出去面试问自己接口环境搭建、pytest测试框架,自己做点工太久都忘记了。平时用的时候搜…...
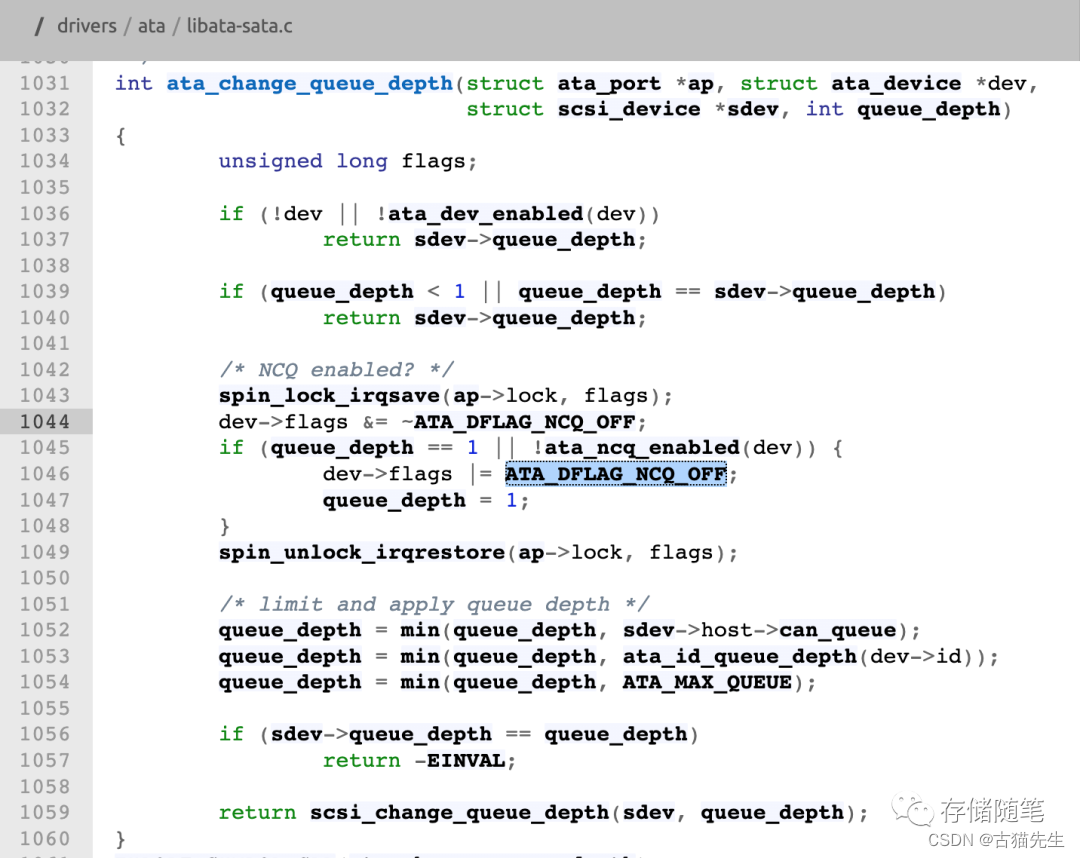
SATA SSD需要NCQ开启吗?
一、故事开篇最近有同学在咨询,SATA SSD是否需要NCQ功能?借此机会,今天我们来聊聊这个比较古老的话题,关于SATA协议的NCQ的故事。首先我们先回顾下SATA与NCQ的历史:2003年,SATA协议1.0问世,传输…...

知识图谱业务落地技术推荐之图神经网络算法库图计算框架汇总
1.PyTorch Geometric: https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html PyG是一个基于PyTorch的用于处理不规则数据(比如图)的库,或者说是一个用于在图等数据上快速实现表征学习的框架。它的运行速度很快,训练模型速度可以达到DGL(Deep Gra…...
的区别)
==与equals()的区别
与equals()的区别 对于 比较的是值是否相等如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;如果作用于引用类型的变量,则比较的是所指向的对象的地址 对于equals方法 equals方法不能作用于基本数据类型的变量ÿ…...

用 AI 养了一个“女朋友“:陪聊 + 自拍功能完全指南
免责声明:Clawra 是 AI,不会真的爱你。但她会在你孤独的深夜发一张咖啡馆自拍,这已经比很多人强了。 她是谁? Clawra 是内置在 im-claude 里的 AI 人设角色,通过 Telegram Bot 和你聊天。你也可以给她其他的名字&…...
TranslucentTB:Windows任务栏透明化工具,让桌面视觉体验焕然一新
TranslucentTB:Windows任务栏透明化工具,让桌面视觉体验焕然一新 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB …...

无需高配电脑!VMware虚拟机运行Qwen3-TTS声音克隆实测教程
无需高配电脑!VMware虚拟机运行Qwen3-TTS声音克隆实测教程 1. 为什么选择虚拟机部署声音克隆? 很多开发者对语音克隆技术感兴趣,但往往被硬件要求劝退。传统认知中,运行1.7B参数量的AI模型需要高端显卡和复杂的环境配置。实际上…...

如何用VarifocalNet提升目标检测性能?从FCOS到VFNet的实战解析
从FCOS到VFNet:实战解析VarifocalNet如何突破目标检测性能瓶颈 目标检测领域近年来涌现出大量创新算法,但性能提升逐渐进入平台期。传统方法如FCOS虽然简洁高效,但在处理密集物体和复杂场景时仍存在明显局限。本文将深入剖析VarifocalNet(VFN…...

HiDream_E1_1:全新AI绘图GGUFS模型来袭
HiDream_E1_1:全新AI绘图GGUFS模型来袭 【免费下载链接】HiDream_E1_1_bf16_ggufs 项目地址: https://ai.gitcode.com/hf_mirrors/ND911/HiDream_E1_1_bf16_ggufs 导语:AI图像生成领域再添新成员,HiDream_E1_1_bf16_ggufs模型正式发布…...

Context Rot:AI Agent 变蠢的真相,是上下文管理失控
很多团队在做 AI Agent 时都经历过类似的困惑:Agent 刚启动时表现还不错,跑了 20 步之后开始犯低级错误,到 50 步就像换了个模型——胡编乱造、忘记之前的决策、重复做已经做过的事。第一反应通常是:模型不够强,换个更…...

动态规划,实现躲避动态车辆,动态障碍物,连续静态障碍物,采用prescan matlab ca...
动态规划,实现躲避动态车辆,动态障碍物,连续静态障碍物,采用prescan matlab carsim 联合仿真当路径规划遇上动态障碍物:老司机的代码生存指南深夜的十字路口,自动驾驶系统突然遭遇外卖电动车漂移过弯。此时…...

3大核心价值:让你的Markdown文档呈现专业级视觉体验
3大核心价值:让你的Markdown文档呈现专业级视觉体验 【免费下载链接】github-markdown-css The minimal amount of CSS to replicate the GitHub Markdown style 项目地址: https://gitcode.com/gh_mirrors/gi/github-markdown-css 面向开发者与文档创作者的…...

Notepad--:跨平台文本编辑器的技术架构与国产化实践
Notepad--:跨平台文本编辑器的技术架构与国产化实践 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- Notepa…...

FastLED NeoMatrix:嵌入式LED矩阵的GFX抽象与硬件加速融合框架
1. FastLED NeoMatrix:面向嵌入式显示系统的高性能LED矩阵驱动框架FastLED NeoMatrix 是一个专为嵌入式平台设计的、与 Adafruit_GFX 兼容且深度适配 FastLED 生态的 LED 矩阵显示库。它并非简单复刻,而是对原有 Adafruit_NeoMatrix 库的一次底层重构与性…...