大数据技术架构(组件)34——Spark:Spark SQL--Optimize
2.2.3、Optimize
2.2.3.1、SQL
3.3.1.1、RB
1、Join选择
在Hadoop中,MR使用DistributedCache来实现mapJoin。即将小文件存放到DistributedCache中,然后分发到各个Task上,并加载到内存中,类似于Map结构,然后借助于Mapper的迭代机制,遍历大表中的每一条记录,并查找是否在小表中,如果不在则省略。
而Spark是使用广播变量的方式来实现MapJoin.
2、谓词下推
3、列裁剪
4、常量替换
5、分区剪枝
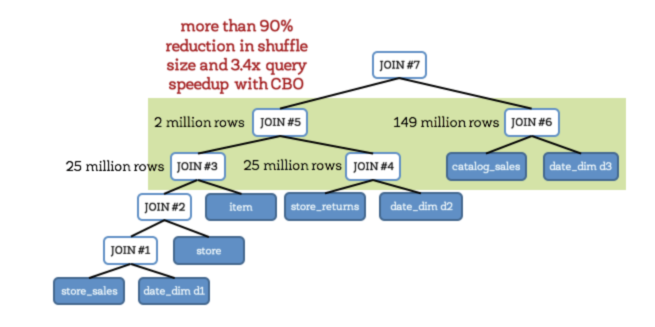
3.3.1.2、CBO
开启cbo之后(通过配置spark.sql.cbo.enabled),有以下几个优化点:
1、Build选择

2、优化Join类型

3、优化多Join顺序

3.3.1.3、AE
3.3.1.3.1、Auto Setting The Shuffle Partition Number
Property Name | Default | Meaning |
spark.sql.adaptive.enabled | false | 设置为true,开启自适应机制 |
spark.sql.adaptive.minNumPostShufflePartitions | 1 | 自适应机制下最小的分区数,可以用来控制最小并行度 |
spark.sql.adaptive.maxNumPostShufflePartitions | 500 | 自适应机制下最大的分区数,可以用来控制最大并行度 |
spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 67108864 | 动态reducer端每个Task最少处理的数据量. 默认为 64 MB. |
spark.sql.adaptive.shuffle.targetPostShuffleRowCount | 20000000 | 动态调整每个task最小处理 20000000条数据。该参数只有在行统计数据收集功能开启后才有作用 |
3.3.1.3.2、Optimizing Join Strategy at Runtime
Property Name | Default | Meaning |
spark.sql.adaptive.join.enabled | true | 运行过程是否动态调整join策略的开关 |
spark.sql.adaptiveBroadcastJoinThreshold | equals to spark.sql.autoBroadcastJoinThreshold | 运行过程中用于判断是否满足BroadcastJoin条件。如果不设置,则该值等于 spark.sql.autoBroadcastJoinThreshold. |
3.3.1.3.3、Handling Skewed Join
Property Name | Default | Meaning |
spark.sql.adaptive.skewedJoin.enabled | false | 运行期间自动处理倾斜问题的开关 |
spark.sql.adaptive.skewedPartitionFactor | 10 | 如果一个分区的大小大于所有分区大小的中位数而且大于spark.sql.adaptive.skewedPartitionSizeThreshold,或者分区条数大于所有分区条数的中位数且大于spark.sql.adaptive.skewedPartitionRowCountThreshold,那么就会被当成倾斜问题来处理 |
spark.sql.adaptive.skewedPartitionSizeThreshold | 67108864 | 倾斜分区大小不能小于该值 |
spark.sql.adaptive.skewedPartitionRowCountThreshold | 10000000 | 倾斜分区条数不能小于该值 |
spark.shuffle.statistics.verbose | false | 启用后MapStatus会采集每个分区条数信息,用来判断是否倾斜并进行相应的处理 |
2.2.3.2、Compute
2.2.3.2.1、Dynamic Executor Allocation
2.2.3.2.2、Paralliesm
2.2.3.2.3、Data Skew/Shuffle
其除了手段和Spark文章中提到的倾斜一样,这里不再叙述
2.2.3.2.4、Properties
更多配置见
Property Name | Default | Meaning |
spark.sql.inMemorycolumnarStorage.compressed | true | 内存中列存储压缩 |
spark.sql.codegen | false | 设置为true,可以为大型查询快速编辑创建字节码 |
spark.sql.inMemoryColumnarStorage.batchSize | 10000 | 默认列缓存大小为10000,增大该值可以提高内存利用率,但要避免OOM问题 |
spark.sql.files.maxPartitionBytes | 134217728 (128 MB) | The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. |
spark.sql.files.openCostInBytes | 4194304 (4 MB) | The estimated cost to open a file, measured by the number of bytes could be scanned in the same time. This is used when putting multiple files into a partition. It is better to over-estimated, then the partitions with small files will be faster than partitions with bigger files (which is scheduled first). This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. |
spark.sql.files.minPartitionNum | Default Parallelism | The suggested (not guaranteed) minimum number of split file partitions. If not set, the default value is `spark.default.parallelism`. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. |
spark.sql.broadcastTimeout | 300 | Timeout in seconds for the broadcast wait time in broadcast joins |
spark.sql.autoBroadcastJoinThreshold | 10485760 (10 MB) | Configures the maximum size in bytes for a table that will be broadcast to all worker nodes when performing a join. By setting this value to -1 broadcasting can be disabled. Note that currently statistics are only supported for Hive Metastore tables where the command ANALYZE TABLE <tableName> COMPUTE STATISTICS noscan has been run. |
spark.sql.shuffle.partitions | 200 | Configures the number of partitions to use when shuffling data for joins or aggregations |
spark.sql.sources.parallelPartitionDiscovery.threshold | 32 | Configures the threshold to enable parallel listing for job input paths. If the number of input paths is larger than this threshold, Spark will list the files by using Spark distributed job. Otherwise, it will fallback to sequential listing. This configuration is only effective when using file-based data sources such as Parquet, ORC and JSON. |
spark.sql.sources.parallelPartitionDiscovery.parallelism | 10000 | Configures the maximum listing parallelism for job input paths. In case the number of input paths is larger than this value, it will be throttled down to use this value. Same as above, this configuration is only effective when using file-based data sources such as Parquet, ORC and JSON. |
spark.sql.adaptive.coalescePartitions.enabled | true | When true and spark.sql.adaptive.enabled is true, Spark will coalesce contiguous shuffle partitions according to the target size (specified by spark.sql.adaptive.advisoryPartitionSizeInBytes), to avoid too many small tasks |
spark.sql.adaptive.coalescePartitions.minPartitionNum | Default Parallelism | The minimum number of shuffle partitions after coalescing. If not set, the default value is the default parallelism of the Spark cluster. This configuration only has an effect when spark.sql.adaptive.enabled and spark.sql.adaptive.coalescePartitions.enabled are both enabled. |
spark.sql.adaptive.coalescePartitions.initialPartitionNum | (none) | The initial number of shuffle partitions before coalescing. If not set, it equals to spark.sql.shuffle.partitions . This configuration only has an effect when spark.sql.adaptive.enabled and spark.sql.adaptive.coalescePartitions.enabled are both enabled. |
spark.sql.adaptive.advisoryPartitionSizeInBytes | 64 MB | The advisory size in bytes of the shuffle partition during adaptive optimization (when spark.sql.adaptive.enabled is true). It takes effect when Spark coalesces small shuffle partitions or splits skewed shuffle partition. |
spark.sql.adaptive.localShuffleReader.enabled | true | 开启自适应执行后,spark会使用本地的shuffle reader读取shuffle数据。这种情况只会发生在没有shuffle重分区的情况 |
spark.sql.adaptive.skewJoin.enabled | true | When true and spark.sql.adaptive.enabled is true, Spark dynamically handles skew in sort-merge join by splitting (and replicating if needed) skewed partitions. |
spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5 | A partition is considered as skewed if its size is larger than this factor multiplying the median partition size and also larger than spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes. |
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 256MB | A partition is considered as skewed if its size in bytes is larger than this threshold and also larger than spark.sql.adaptive.skewJoin.skewedPartitionFactor multiplying the median partition size. Ideally this config should be set larger than spark.sql.adaptive.advisoryPartitionSizeInBytes 、. |
spark.sql.optimizer.maxIterations | 100 | The max number of iterations the optimizer and analyzer runs |
spark.sql.optimizer.inSetConversionThreshold | 10 | The threshold of set size for InSet conversion |
spark.sql.inMemoryColumnarStorage.partitionPruning | true | When true,enable partition pruning for in-memory columnar tables |
spark.sql.inMemoryColumnarStorage.enableVectorizedReader | true | Enables vectorized reader for columnar caching |
spark.sql.columnVector.offheap.enabled | true | When true, use OffHeapColumnVector in ColumnarBatch. |
spark.sql.join.preferSortMergeJoin | true | When true, prefer sort merge join over shuffle hash join |
spark.sql.sort.enableRadixSort | true | When true, enable use of radix sort when possible. Radix sort is much faster but requires additional memory to be reserved up-front. The memory overhead may be significant when sorting very small rows (up to 50% more in this case) |
spark.sql.limit.scaleUpFactor | 4 | Minimal increase rate in number of partitions between attempts when executing a take on a query. Higher values lead to more partitions read. Lower values might lead to longer execution times as more jobs will be run |
spark.sql.hive.advancedPartitionPredicatePushdown.enabled | true | When true, advanced partition predicate pushdown into Hive metastore is enabled |
spark.sql.subexpressionElimination.enabled | true | When true, common subexpressions will be eliminated |
spark.sql.caseSensitive | false | Whether the query analyzer should be case sensitive or not. Default to case insensitive. It is highly discouraged to turn on case sensitive mode |
spark.sql.crossJoin.enabled | false | When false, we will throw an error if a query contains a cartesian product without explicit CROSS JOIN syntax. |
spark.sql.files.ignoreCorruptFiles | false | Whether to ignore corrupt files. If true, the Spark jobs will continue to run when encountering corrupted files and the contents that have been read will still be returned. |
spark.sql.files.ignoreMissingFiles | false | Whether to ignore missing files. If true, the Spark jobs will continue to run when encountering missing files and the contents that have been read will still be returned. |
spark.sql.files.maxRecordsPerFile | 0 | Maximum number of records to write out to a single file.If this value is zero or negative, there is no limit. |
spark.sql.cbo.enabled | false | Enables CBO for estimation of plan statistics when set true. |
spark.sql.cbo.joinReorder.enabled | false | Enables join reorder in CBO |
spark.sql.cbo.joinReorder.dp.threshold | 12 | The maximum number of joined nodes allowed in the dynamic programming algorithm |
spark.sql.cbo.joinReorder.card.weight | 0.7 | The weight of cardinality (number of rows) for plan cost comparison in join reorder: rows * weight + size * (1 - weight). |
spark.sql.cbo.joinReorder.dp.star.filter | false | Applies star-join filter heuristics to cost based join enumeration |
spark.sql.cbo.starSchemaDetection | false | When true, it enables join reordering based on star schema detection |
spark.sql.cbo.starJoinFTRatio | 0.9 | Specifies the upper limit of the ratio between the largest fact tables for a star join to be considered |
spark.sql.windowExec.buffer.in.memory.threshold | 4096 | Threshold for number of rows guaranteed to be held in memory by the window operator |
2.2.3.3、Storage
2.2.3.3.1、Small File
小文件的危害就不再叙述了,这个时候就要思考什么时候会产生小文件。其产生的地方有:
1、源头:如果原始文件就存在小文件,那么就需要先进行合并,然后再计算,避免产生大量的task造成资源浪费
2、计算过程中:这个时候就要结合实际的数据量大小和分布,以及分区数进行调整。
3、写入:写入文件的数量跟reduce/分区的个数有关系,可以根据实际的数据量进行调整并行度或者配置自动合并
2.2.3.3.2、Cold And Hot Data
2.2.3.3.3、Compress And Serializable
1、文件采用合适的存储类型以及压缩格式
2、使用合适高效的序列化器,如kryo
Property Name | Default | Meaning |
spark.sql.parquet.compression.codec | snappy | parquet存储类型文件的压缩格式,默认为snappy |
spark.sql.sources.fileCompressionFactor | 1.0 | When estimating the output data size of a table scan, multiply the file size with this factor as the estimated data size, in case the data is compressed in the file and lead to a heavily underestimated result |
spark.sql.parquet.mergeSchema | false | When true, the Parquet data source merges schemas collected from all data files, otherwise the schema is picked from the summary file or a random data file if no summary file is available |
spark.sql.parquet.respectSummaryFiles | false | When true, we make assumption that all part-files of Parquet are consistent with summary files and we will ignore them when merging schema. Otherwise, if this is false, which is the default, we will merge all part-files. This should be considered as expert-only option, and shouldn't be enabled before knowing what it means exactly |
spark.sql.parquet.binaryAsString | false | Some other Parquet-producing systems, in particular Impala and older versions of Spark SQL, do not differentiate between binary data and strings when writing out the Parquet schema. This flag tells Spark SQL to interpret binary data as a string to provide compatibility with these systems |
spark.sql.parquet.filterPushdown | true | Enables Parquet filter push-down optimization when set to true |
spark.sql.parquet.columnarReaderBatchSize | 4096 | The number of rows to include in a parquet vectorized reader batch. The number should be carefully chosen to minimize overhead and avoid OOMs in reading data. |
2.2.3.4、Other
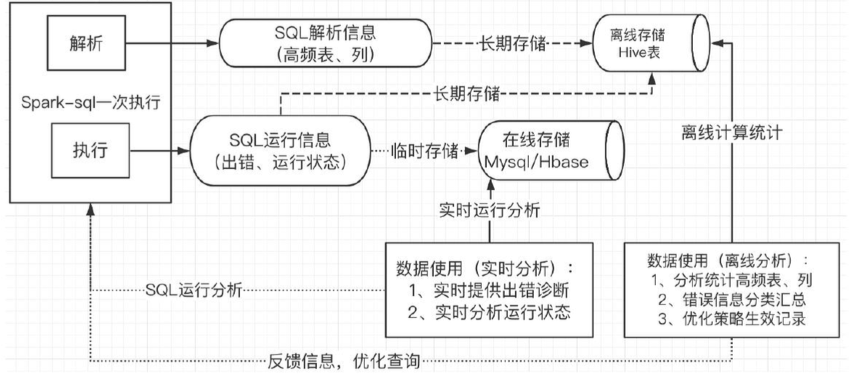
2.2.3.4.1、Closed Loop FeedBack
2.2.3.4.1.1、实时运行信息分析
2.2.3.4.1.2、运行信息离线统计分析
高频表、列统计,错误信息汇总,策略生效情况记录等。
相关文章:
大数据技术架构(组件)34——Spark:Spark SQL--Optimize
2.2.3、Optimize2.2.3.1、SQL3.3.1.1、RB1、Join选择在Hadoop中,MR使用DistributedCache来实现mapJoin。即将小文件存放到DistributedCache中,然后分发到各个Task上,并加载到内存中,类似于Map结构,然后借助于Mapper的迭…...
Zookeeper实现分布式锁
文章目录ZK节点类型watch监听机制Zookeeper实现分布式锁锁原理创建锁的过程释放锁的过程ZK锁的种类代码实现Zookeeper是一个开源的分布式协调服务,是一个典型的分布式数据一致性解决方案。 分布式应用程序可以基于Zookeeper实现诸如数据发布/订阅,负载均…...

MFC 添加重新启动管理器支持
重启管理器是添加到 Visual Studio for Windows Vista 或更高版本操作系统的功能 如果发生意外关闭或重启,重新启动管理器将为你的应用程序添加支持。 重新启动管理器的行为取决于应用程序的类型。 如果你的应用程序是文档编辑器,则重新启动管理器让应用…...

一文带你深刻的进入Python,并且了解Python的优缺点
最近几年Python被吹的神乎其神,很多同学都不清楚Python到底能干什么?就盲目去学习Python,今天我就Python的应用领域来简单盘点一下,让想学习Python 的同学找对方向不迷茫。 2. Python 的特点 这里就谈谈自己的看法,首先 Python是…...

别具一格,原创唯美浪漫情人节表白专辑,(复制就可用)(html5,css3,svg)表白爱心代码(4)
别具一格,独此一家,原创唯美浪漫情人节表白专辑 不一样的惊喜哦~!(html5,css3,svg)表白爱心代码(复制就可用)(4) 目录 款式四:时光的记忆款 1、拷贝完整源代码 2、更新时光盒所…...

编译原理—翻译方案、属性栈代码
系列文章戳这里👇 什么是上下文无关文法、最左推导和最右推导如何判断二义文法及消除文法二义性何时需要消除左递归什么是句柄、什么是自上而下、自下而上分析什么是LL(1)、LR(0)、LR(1)文法、LR分析表LR(0)、SLR(1)、LR(1)、LALR(1)文法之间的关系编译原理第三章习…...

链表
一、从尾到头打印链表题目:输入一个链表,按链表从尾到头的顺序返回一个ArrayList。解题思路:使用栈作为中转,可以实现倒置打印classSolution { public:vector<int> printListFromTailToHead(ListNode* head){//使用栈完成中…...

CSS 样式优先级
CSS 样式优先级决定了最终呈现在浏览器中的样式是哪一组样式,在多组样式中有冲突时,最终呈现在浏览器中的样式是具有最高优先级的样式。 CSS 样式优先级顺序如下: 内联样式 > 内部样式 > 外部样式 !important > 内联样式 > ID…...

SpingMVC获取请求参数
通过ServletAPI获取请求参数将HttpServletRequest作为控制器方法的形参,此时HttpServletRequest类型的参数表示封装了当前请求的请求报文的对象。html<form th:action"{/param/servletAPI}" method"post">用户名:<input ty…...
微搭使用笔记(二)微搭低代码平台介绍及基础使用
概述 官网地址: 官网 官方文档: 官方文档 FAQ: FAQ 腾讯云微搭低代码是一个高性能的低代码开发平台,用户可通过拖拽式开发,可视化配置构建 PC Web、H5 和小程序应用。支持打通企业内部数据,轻松实现企业微信管理、工…...

CountDownLatch的定义、使用 、原理
一、定义 CountDownLatch的作用很简单,就是一个或者一组线程在开始执行操作之前,必须要等到其他线程执行完才可以。我们举一个例子来说明,在考试的时候,老师必须要等到所有人交了试卷才可以走。此时老师就相当于等待线程ÿ…...
《Terraform 101 从入门到实践》 Terraform在公有云Azure上的应用
《Terraform 101 从入门到实践》这本小册在南瓜慢说官方网站和GitHub两个地方同步更新,书中的示例代码也是放在GitHub上,方便大家参考查看。 简介 Azure是微软的公有云,它提供了一些免费的资源,具体可以查看: https:/…...
别具一格,原创唯美浪漫情人节表白专辑,(复制就可用)(html5,css3,svg)表白爱心代码(3)
别具一格,原创唯美浪漫情人节表白专辑, (复制就可用)(html5,css3,svg)表白爱心代码(3) 目录 款式三:心形实时显示认识多长时间桃花飞舞(猫咪)款 1、拷贝完整源代码 2、拷贝完整js代码 3、修改时间 4、…...

Linux 删除修改日期大于某一天的文件
在服务器运维过程中,我们往往会产生大量的日志文件. 如果日志文件命名能看出日志产生的时间,这些文件是很好删除的. 但有时,我们可能有成千上万的没有命名规律日志文件 下面的方法可以根据日志最后修改时间 批量删除这些文件 先给出完整命令: find /mydir -mtime 10 -name &…...

【算法题】1845. 座位预约管理系统
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 请你设计一个管理 n 个座位预约的系…...

【专业认知】保研北大金融 / 入职腾讯产品经理
2023.02.11 一. 朱博文学长分享——关于大学生活的一点思考 1. 自我介绍 大数据18级 经济学双学位 保研至北大金融硕士 “多思考、多感受、兼听则明” 2. 大学生活 2.1 为什么要上大学 1:追求美好生活的需要 “美好”难以量化,因为每个人对生活…...

OpenHarmony使用Socket实现一个UDP客户端详解
一、前言 我们在这里介绍Socket的使用,是为了后面的一篇文章实现设备配网做铺垫。 二、示例详解 点击获取BearPi-HM_Nano源码 ,以D3_iot_udp_client为例: 示例本身很简单,只需要修改 udp_client_demo.c 的2处代码,就能测试了: //连接WIFI,参数1是:WIFI名称,参数2是:…...
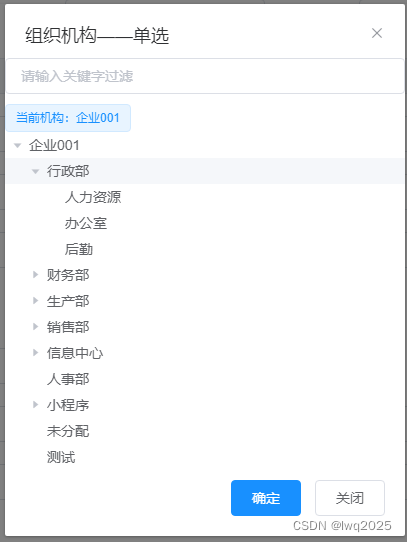
使用VUE自定义组件封装部门选择功能
背景 照惯例,先交待下背景,从真实需求出发,讲述实现效果、设计思路和实现方式。 软件系统中,会有一些常见常用的选择功能,如部门选择、人员选择等,用于填报表单,使用频率很高。直接使用一方面会…...
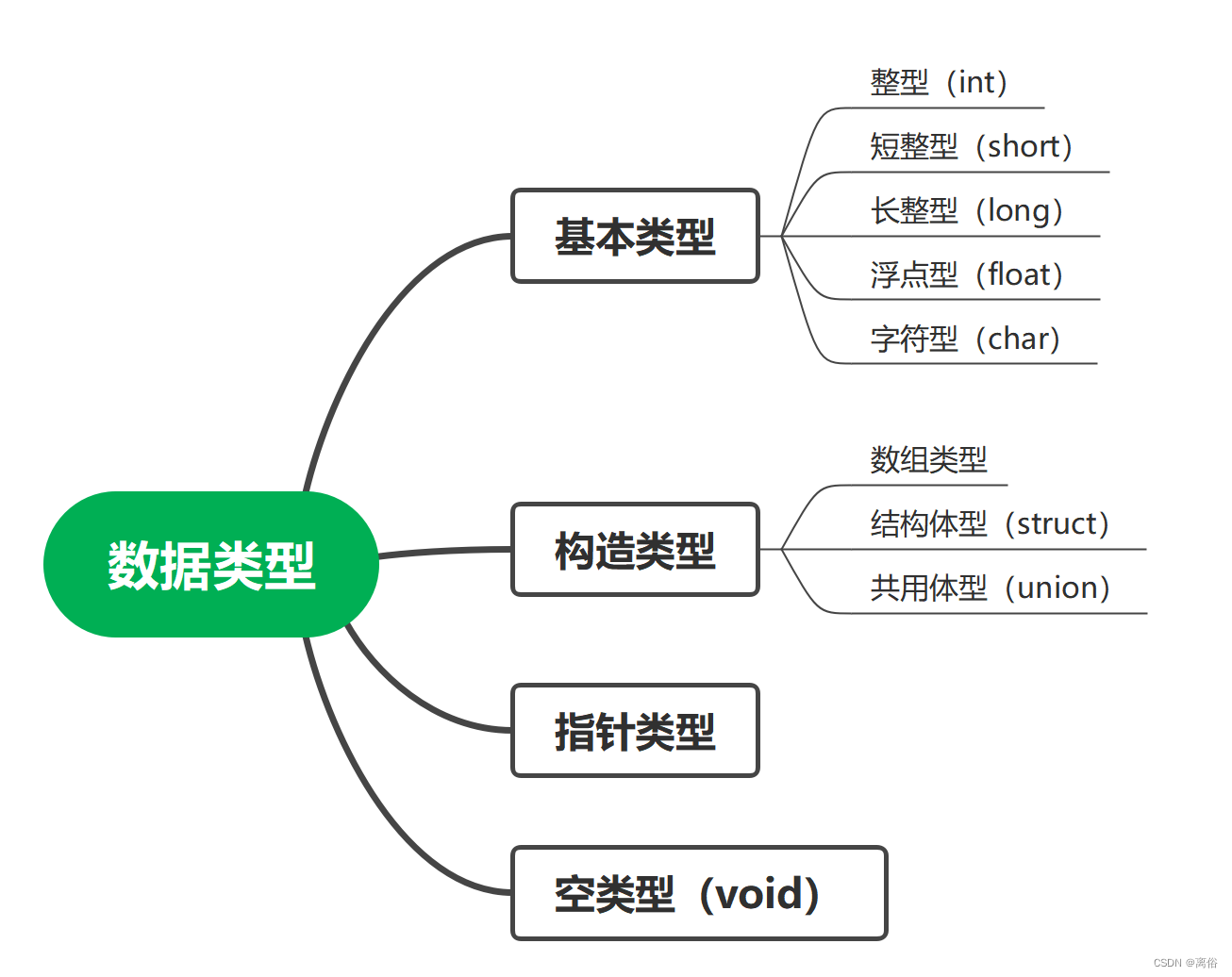
C语言基础应用(一)数据类型
一、数据类型 1、数据类型的分类 2、常量 常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。 2.1 常量举例 // 整型常量 举例 /*718 十进制0213 八进制0x4b 十六进制30u 无符号整数30l 长整型30ul 无符号长整型*/ // 浮点常量…...

算法笔记(三)—— 桶排序及排序总结
堆 逻辑上是一棵完全二叉树(依次遍满或者全满)。 数组可以转为完全二叉树,完全二叉树某结点左孩子(2*i1),右孩子(i*22),父结点((i-1/)2),根节点的父还是自己。 如何将数组转化为堆(大根堆&…...

Spratt Skills:基于LLM规划与代码执行的OpenClaw家庭自动化架构实践
1. 项目概述:Spratt Skills,一个为OpenClaw打造的家庭自动化基础设施套件 如果你正在使用OpenClaw,并且已经厌倦了让LLM(大语言模型)去处理那些它天生就不擅长的事情——比如定时发送消息、轮询航班状态、或者可靠地写…...

在株洲如何选择护脊透气的床垫?
引言在现代社会,随着生活节奏的加快和工作压力的增加,越来越多的人开始关注睡眠质量。而床垫作为影响睡眠质量的重要因素之一,其选择显得尤为重要。特别是对于需要护脊和透气功能的床垫,如何选择成为了一个关键问题。本文将结合德…...
算力优化细节详解)
DeepSeek(V3为主、兼顾V2/R1)算力优化细节详解
DeepSeek(V3为主、兼顾V2/R1)算力优化细节详解以下是针对核心优化模块的深入技术拆解,包含MLA数学原理、FP8精准实现、无辅助损失负载均衡、R1-GRPO算法核心,内容基于DeepSeek-V3官方技术报告及2026年5月公开权威分析。DeepSeek系…...

TextInputLayout实战:从属性解析到自定义样式进阶
1. TextInputLayout基础入门:从零开始掌握Material输入框 第一次接触TextInputLayout时,我被它丝滑的浮动提示动画惊艳到了。相比传统的EditText,这个Material Design组件确实能让表单界面瞬间提升好几个档次。记得去年做登录页面重构时&…...

Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值
Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related a…...

AgenticROS:用自然语言操控ROS2机器人的AI Agent接口实践
1. 项目概述:当AI大模型遇见机器人操作系统如果你和我一样,既对AI大模型的能力着迷,又对机器人开发充满兴趣,那么你肯定想过一个问题:能不能让Claude、Gemini这样的AI,像我们人类工程师一样,直接…...

3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南
3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南 【免费下载链接】SubtitleOCR 快如闪电的硬字幕提取工具。仅需苹果M1芯片或英伟达3060显卡即可达到10倍速提取。A very fast tool for video hardcode subtitle extraction 项目地址: https://gitcode.com/g…...

体验Taotoken多模型聚合在内容生成任务中的效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型聚合在内容生成任务中的效果差异 在实际的开发与创作工作中,我们常常面临一个选择:针对…...

Selenium自动化ChatGPT:绕过API限制,实现Web端高效批量交互
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Michelangelo27/chatgpt_selenium_automation”。光看名字,你大概能猜到它想做什么:用Selenium自动化操作ChatGPT。这听起来是不是有点“用大炮打蚊子”的感觉?毕…...

为Claude Code配置Taotoken解决封号与Token不足困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决封号与Token不足困扰 应用场景类,针对频繁使用Claude Code作为编程助手但受限于官方限制…...